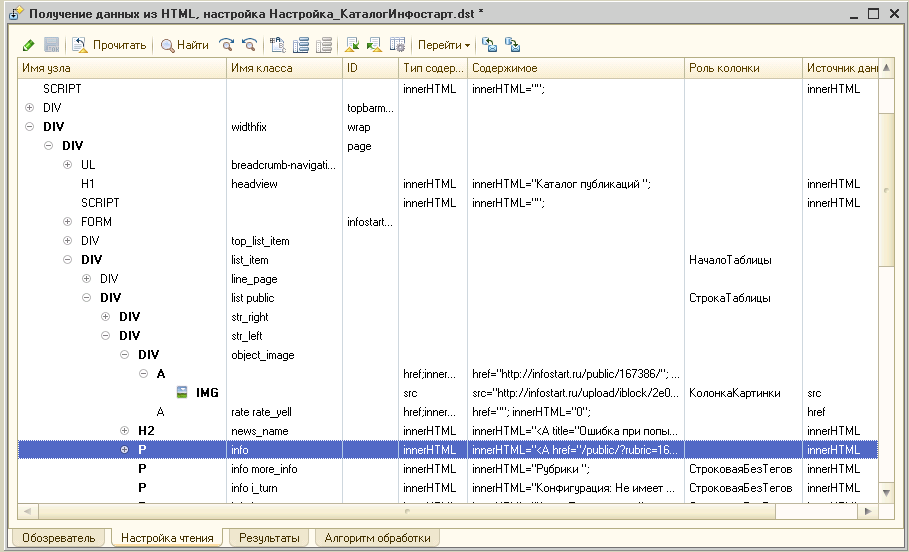
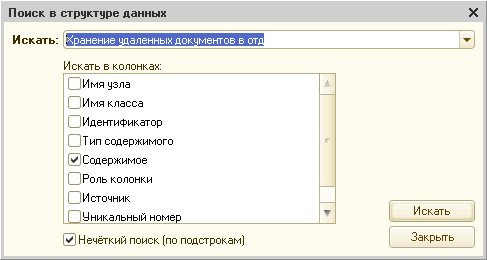









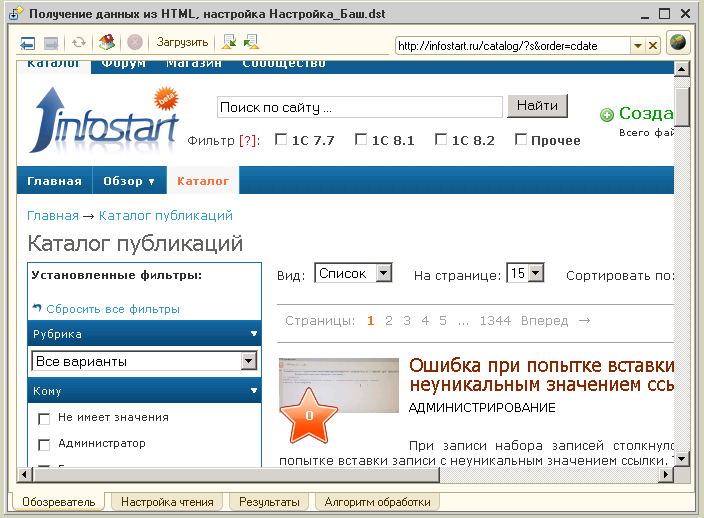
Что позволяет обработка: 1) посмотреть структуру HTML-страницы; 2) настроить интерпретацию узлов так, чтобы прочесть данные в таблицу значений; 3) с определённой степенью надёжности делать постоянные настройки чтения; 4) обрабатывать прочитанное произвольным алгоритмом.
Всё началось с необходимости загрузить данные с Яндекс.Маркета. Нашёл было пару обработок, да вот беда - они устарели и нормально не читают, потому что на яндексе уже другие теги, чуть-чуть другая разметка, и всё. И хоть делай заново. Потом я подумал: структура DOM, пусть в самом общем виде, может быть прочитана. И, значит, маркирована так, чтобы дать понять обработке, откуда брать данные. Тут, правда, обнаружился неприятный сюрприз (из-за которого, в общем, полезность моей разработки существенно падает) – уникальная идентификация большинства узлов структуры страницы невозможна. Не по чему их идентифицировать, к сожалению. Поэтому все предлагаемые для примера настройки – с известной степенью точности. Может понадобиться доработка настроек «напильником». Но именно настроек, а не обработки как таковой. Так что теперь, пусть Яндекс.Маркет меняет формат данных хоть раз в неделю. 5 минут подстройки – и можно опять грузить нужные данные.
Обработка – не то чтобы «готовое решение», а инструмент. Позволяет «пристреляться» к странице и сайту. Позволяет малыми усилиями обеспечить разовое, а чуть большими – постоянное чтение данных с сайта. Для примера к публикации прилагаю настройки, демонстрирующие работу с несколькими общеизвестными сайтами.
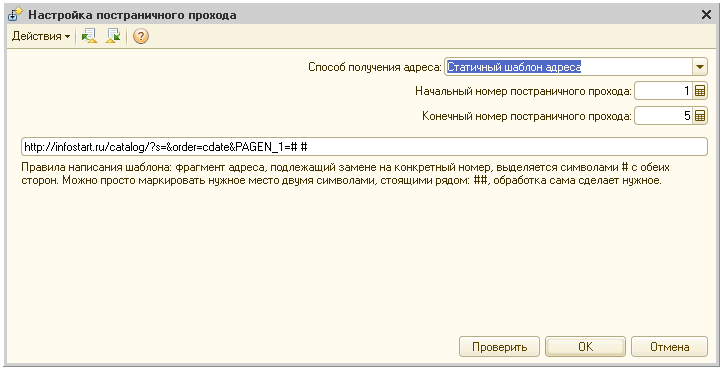
UPD: Добавлена возможность пакетного чтения и загрузки с нескольких страниц, имеющих однотипные URL. Предусмотрен шаблон или произвольный алгоритм для получения URL, задание границ цикла. Добавлена форма настройки и справка по ней.
UPD 2: В версии 1.5 добавлена возможность "идти глубже". Если есть ссылка - задайте настройку для чтения той страницы, куда эта ссылка ведёт, и обработка автоматически прочитает и её содержимое тоже. Глубина погружения теоретически любая (на практике 3 уровня работают ОК). Зачем это: например, на том же Яндексе нужна детализация (со страницы конкретного товара), т.е. большая картинка, характеристики и тд. Теперь это возможно без особенных усилий, главное - 1 раз сделать настройки чтения. Результаты представляются как таблицы значений внутри ячеек более "общих" таблиц значений. В архиве ParsInto находятся 3 файла для Яндекс-Маркета - настройка чтения списка товаров, настройка чтения карточки товара (шаг №1, из списка) и настройка чтения характеристик (шаг № 2, из карточки). Ахтунг! Пути, указанные в полях, надо будет переписать под ваш случай, имена файлов можно не менять. В справку обработки внесены сведения о том, как это делается.
Работает эта штука на асинхронной загрузке, поэтому может эффектно выкобениваться с точки зрения интерфейса, но у меня стабильно даёт нормальный результат.
UPD: Доделал пакетную загрузку по ссылкам, многостраничную загрузку. Сделана возможность ручной "добивки" неудачно загруженных данных по ссылкам. Повышена избирательность загрузки, точность считывания при одинаковых свойствах ветви. В модуль добавлены полезняшки для работы с html. Исправлена пара багов.
Кто найдёт баги/глюки - пожалуйста, сообщайте, это приветствуется! Буду исправлять оперативно.
UPD: Добавил версию для чтения именно html-таблиц, в ячейках которых маленькие подветки dom-объектов как деревья значений. Всё в виде таблиц значений, структур и прочая, для желающих написать свой механизм настроек интерпретации или просто использовать для прямого чтения, или как пример. В отличие от первой обработки, использует не DOM через ActiveX окна, а штатные средства 1С (построитель DOM).

{kind=link}