





Распознавание картинки подсмотрел в 1С:Документооборот (1С:ДО) и сделал внешней обработкой для своего ТЗ.
Для работы необходимо установить программу "Cuneiform", т.к. 1С:ДО использует её функционал для распознавания (бесплатна).
Обработка полностью заточена под мою задачу, но кому-то может пригодиться сама реализация распознавания, как это сделано в 1С:ДО (Процедура Распознать());
Тестировалась на 11.1.2.27 (8.3.4.496)
Суть:
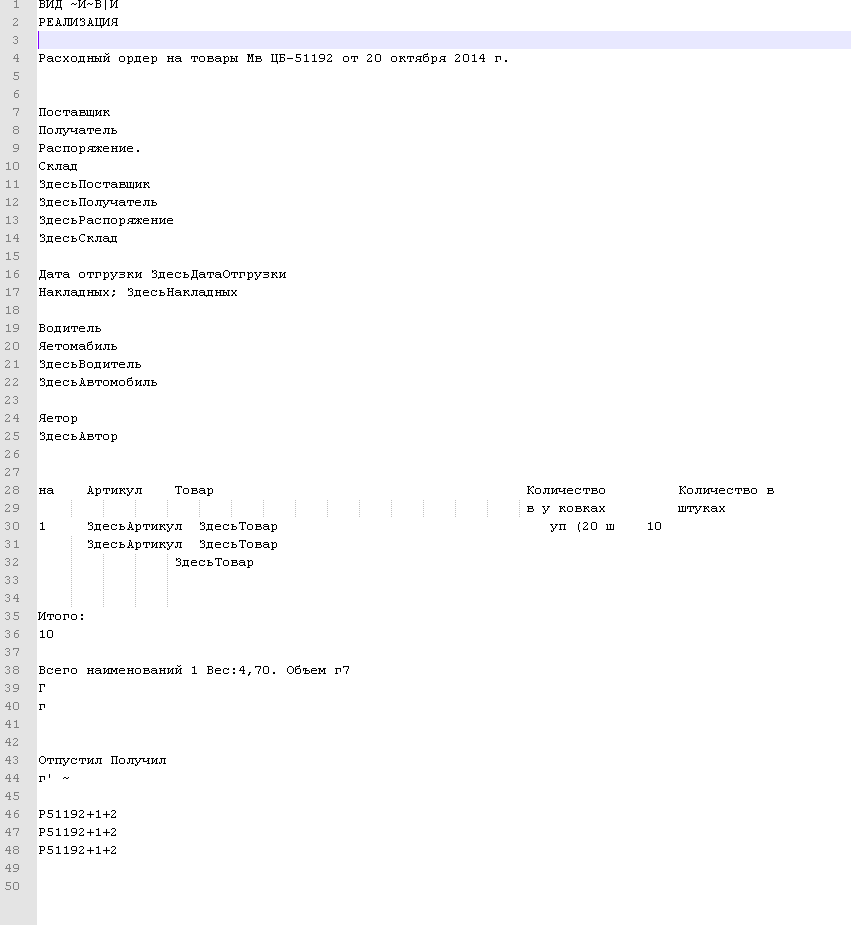
Ответственный распечатывает РасходныйОрдер (РО) и отдаёт на склад на сборку;
После сборки РО возвращается кладовщику с различными пометками;
После того, как кладовщик обработал документ РО в базе в соответствии с вернувшейся печатной формой, сдаёт его в архив.
Задача:
Каждый вернувшийся бланк РО отсканировать и закрепить за документом Реализация товаров и услуг в базе.
Решение:
Сканируются бланки РО в сетевую папку (своими силами)
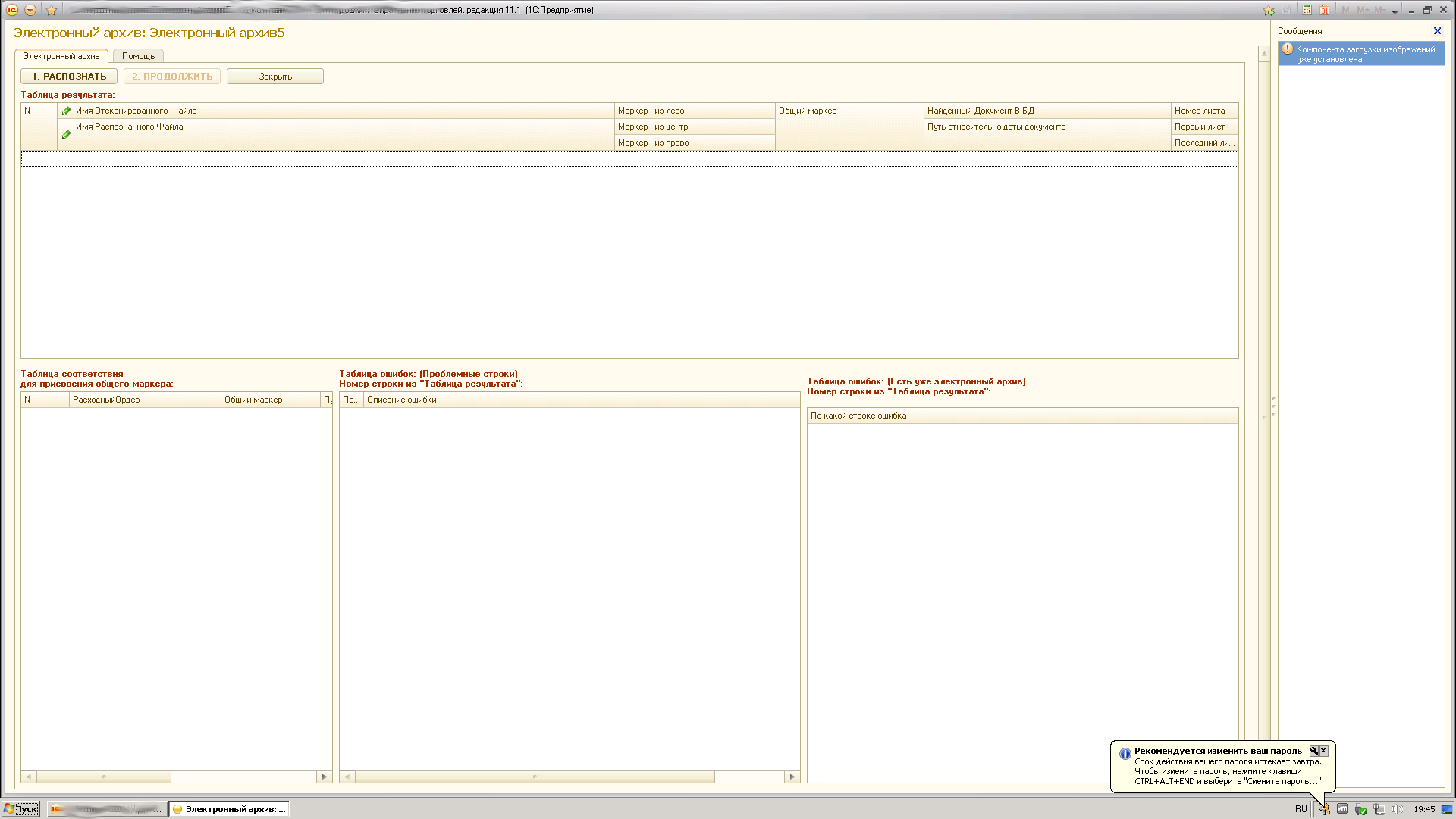
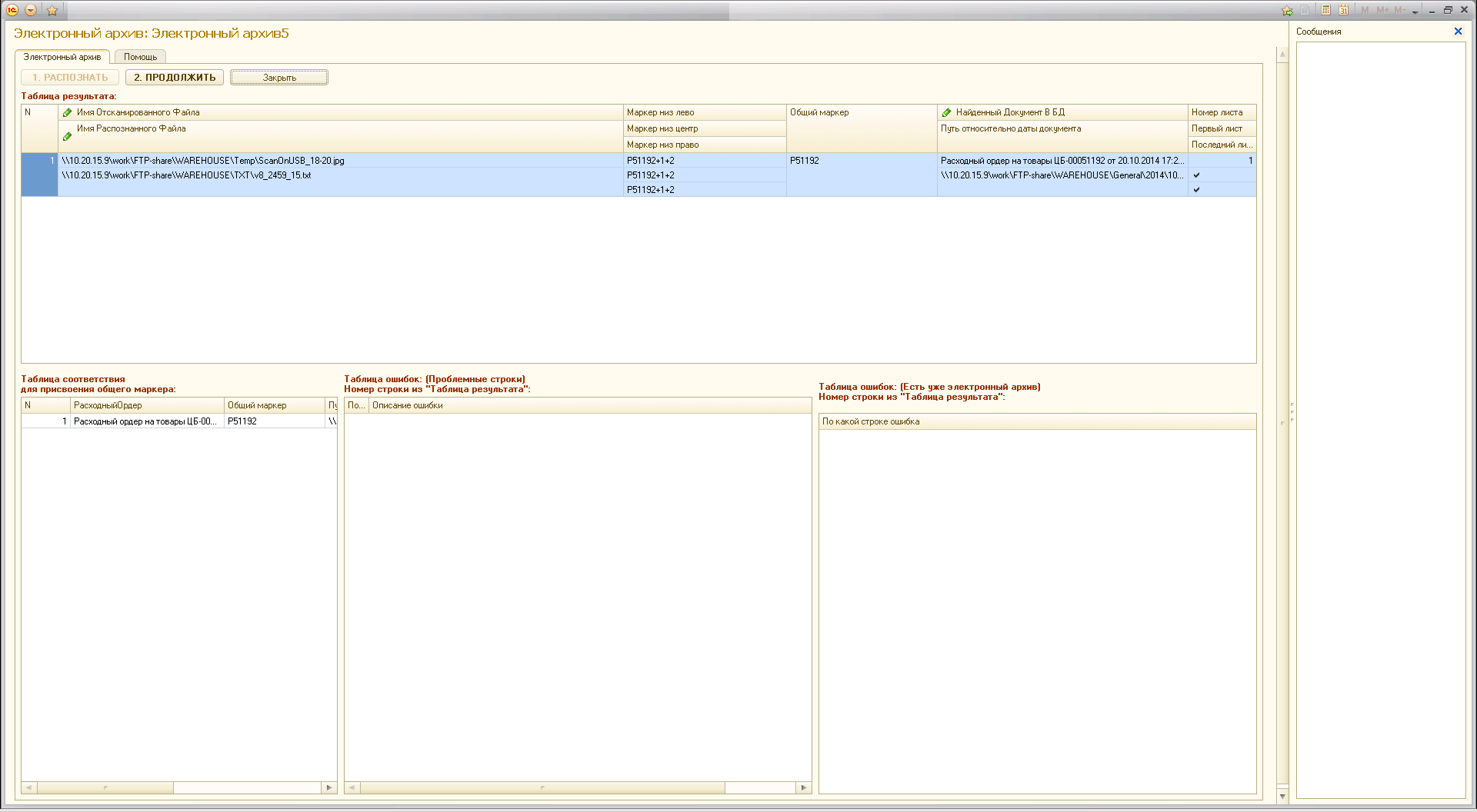
Кладовщик запускает обработку.
Обработка обрабатывает картинки по маркерам (пришлось делать некие уникальные идентификаторы, которые находятся в нижних колонтитулах Слева/Центр/Справа для того, чтобы понять - если листов больше чем 1 то к какому документу они принадлежат).
Сопоставление происходит по наименованию документа и его номеру (происходит разбор строки).
Когда документ найден, в дополнительные реквизиты записываются данные Лист1, Лист2 и т.д.
Эти данные (тип: Строка) содержат просто путь к файлу, который лежит в своей папке с годом -> месяц -> день
Дополнение:
- чуткий механизм распознавания, поэтому в коде параметр ЯзыкРаспознавания = 3(русский), а не 7(русско-английский);
- из-за чуткости куча проверок на сопоставления и шаблонные ошибки при распознавании, поэтому и три маркера;
- если ни один маркер не был распознан, можно руками поправить уже сформировавшийся текстовый файл из обработки;
- чем больше символов на странице, тем выше вероятность неправильного распознавания;
- процент правильности распознавания не мятого листа 95-100%%;
- при сканировании важно, чтобы справа/слева не было чёрных полос (я использовал только автоподатчик);
Отвечу на вопросы по мере возможности и компетентности
Электронный Архив
Функциональные - Документооборот и делопроизводство (СЭД)
См. также
SALE! 30%
Распознавание и загрузка сканов в 1С "одним нажатием": УПД, ТОРГ-12, накладные, счета, номенклатура, заказы и т.д.
6000
5520 руб.
04.06.2019 101790 298 173
ЭДО: организация архива оригиналов первичных документов, комплексный отчет по ошибкам
14880 руб.
17.12.2018 44390 58 51
1С:Бухгалтерия 3.0 ПРОФ + 1С:Документооборот. Модуль интеграции 1С:БП и 1С:ДО (ПРОФ или КОРП)
30000 руб.
23.05.2017 53980 34 67






{kind=link}