
{kind=link}
Пост уважаемого Elisy о парсере сайтов для 1С:Предприятия заслуживает на мой взгляд большего внимания, в связи с чем решил написать о своем опыте парсинга HTML и о том, зачем для этого использовались компоненты ElisyNetBridge и HtmlAgilityPack.
Зачем это нужно?
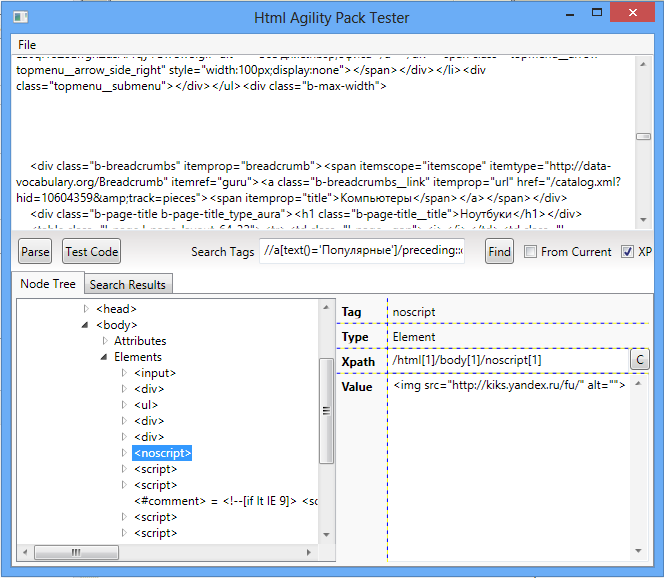
XPath позволяет простым способом получить перечисления нужных элементов HTML страницы, например список популярных категорий товаров (вверху заглавной страницы Яндекс.Маркет) можно получить так:
Разделы = HAP.DocumentNode.SelectNodes("//ul[@class='b-flex-gridb-popular-categories']");
мы получим контейнер, хранящий объекты категорий
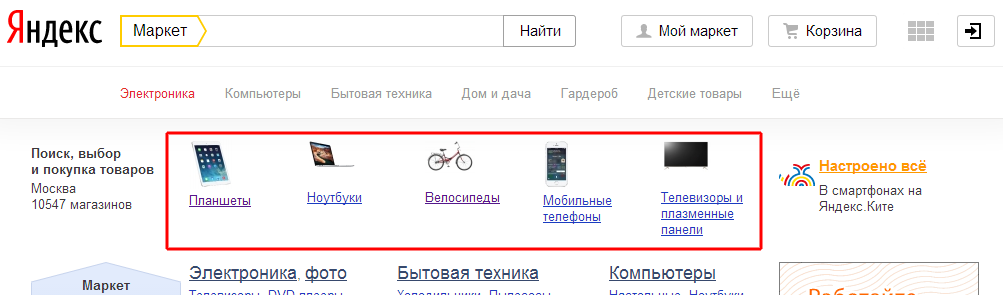
соответственно код
Подразделы = Разделы.get_Item(0).SelectNodes(".//a[@class='name']"); Для i = 0 По Подразделы.Count - 1 Цикл Раздел = СокрЛП(Подразделы.get_Item(i).InnerHtml); Ссылка = СокрЛП(Подразделы.get_Item(i).Attributes.get_Item(1).value); КонецЦикла;
Вернет названия и ссылки на все категории популярных товаров с заглавной страницы. Перейдя по ссылке категории и выполнив код
Для Каждого ЭлементНоды Из СписокНодРаздела Цикл HAP.LoadHtml(appIE.Document.documentElement.innerHTML); КонтейнерПроизводителей = HAP.DocumentNode.SelectNodes("//a[text()='Популярные']/preceding::div[1]"); Производители = КонтейнерПроизводителей.get_Item(0).SelectNodes(".//li[@class='pop-vendors__vendor']"); Для e = 0 По Производители.Count - 1 Цикл Сообщить("Производитель №" + СокрЛП(e + 1) + " " + СокрЛП(Производители.get_Item(e).InnerHtml)); КонецЦикла; КонецЦикла;
Можно получить всех текущих производителей данной категории со ссылками на страницы с перечнем их товаров
Почему не RegEx?
Почему не стоит использовать регулярные выражения для парсинга HTML хорошо написано тут.
Зачем HtmlAgilityPack?
XPath может работать только с валидным XML, каковым HTML страница в большинстве случаев не является, т. к. браузеры не требовательны к валидности XML - достаточно одного <br> и стандартные компоненты для работы с XPath просто не смогут загрузить документ для дальнейшей обработки.
Зачем ElisyNetBridge?
Не уверен, есть ли варианты проще для подключения HtmlAgilityPack в 1С, кроме ElisyNetBridge. Ссылка на бесплатную версию компоненты любезно выложена автором в его статье, компонента также есть в приложенной обработке.
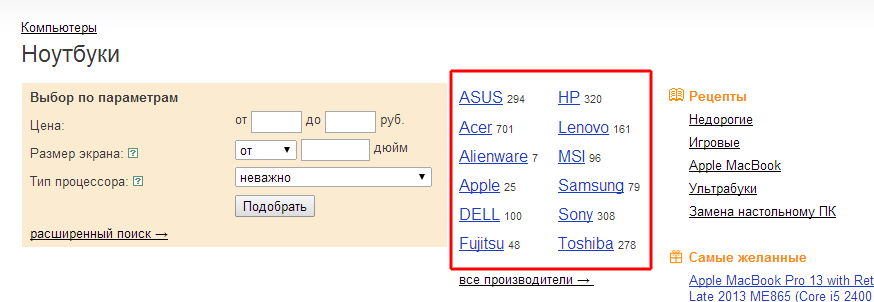
Как тестировать выражения XPath?
В состав HtmlAgilityPack входит HAP Explorer (на скриншоте), загрузив в него HTML исходной страницы можно тестировать различные выражения и смотреть полученные результаты. Правда бывает падает при сложных выражениях :)
Вроде бы все понятно, но…
К статье прикреплена обработка с примером использования ElisyNetBridge и HtmlAgilityPack. Прошу не судить строго за синтаксис XPath - перебор категорий популярных товаров сделан для примера, XPath предлагает широкие возможности для перебора нужных элементов, наверняка есть варианты получше.