Рассмотрим конкретный пример.
Возьмем регистр накопления "ПартииТоваровНаСкладах" и получим из него остатки с отбором по Номенклатуре и Складу.
Текст запроса:

(во временных таблицах с номенклатурой и складами значений немного)
Структура регистра:
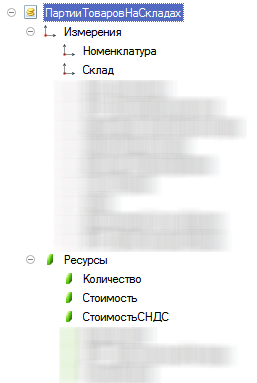
Есть дополнительный индекс по измерению Склад.
В самой таблице движений 38,7 миллионов записей за Январь-Май 2015 г.
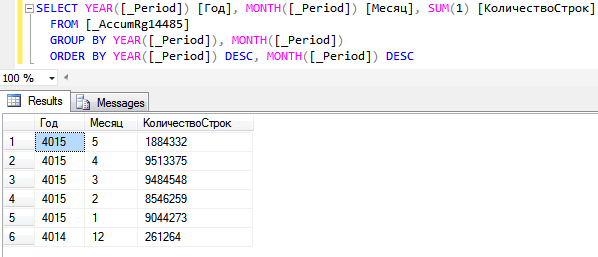
Граница рассчитанных итогов - конец Апреля 2015 г.
Выполняем запрос с разным значением параметра "период":
- первый и второй раз укажем позицию документа с датой "15.04.2015 4:02:33";
- третий и четвертый раз укажем просто дату "15.04.2015 4:02:33".

Выполняем эти запросы несколько раз и получаем следующие результаты:
| MAXDOP = 0 | MAXDOP = 2 | MAXDOP = 1 | |
| 1 запрос | 4.497 | 7.751 | 13.877 |
| 2 запрос | 4.212 | 8.630 | 13.833 |
| 3 запрос | 1.740 | 1.758 | 1.720 |
| 4 запрос | 1.615 | 1.641 | 1.665 |
Замеры сделаны для 3х разных значений "Max Degree of Parallelism" сервера MSSQL.
Есть разные мнения по поводу параметра MAXDOP. 1С-ники чаще склоняются к установке единицы. А вот, например, мнение DBA, которые администрируют другие виды приложений :).
Но вопрос в другом.
Во всех 4х случаях платформа генерирует примерно одинаковые запросы с двумя частями:
1) выборка из таблицы итогов регистра накопления на "будущую" дату "01.05.2015";
2) выборка строк из таблицы движений за период с "15.04.2015 4:02:33" по "01.05.2015 00:00:00".
Конечный остаток получается разницей этих двух таблиц.
С выборкой итогов в части быстродействия все хорошо - в таблице есть кластерный индекс со всеми измерениями, для которого условия запроса хорошо подходят.
А вот с выборкой из таблицы движений явно есть проблема.
Для условия с позицией документа запрос имеет вид:
SELECT
...
FROM dbo._AccumRg14485 T6
WHERE (T6._Period > '4015-04-15 04:02:33' OR T6._Period = '4015-05-01 00:00:00' AND (T6._RecorderTRef > 0x00000135 OR T6._RecorderTRef = 0x00000135 AND T6._RecorderRRef >= 0x80D9005056B6018411E4E33ED0E5D9C0)) AND T6._Period < '4015-05-01 00:00:00'
AND T6._Active = 0x01
AND ...
Для условия с датой запрос имеет вид:
SELECT
...
FROM dbo._AccumRg14485 T6
WHERE T6._Period >= '4015-04-15 04:02:33' AND T6._Period < '4015-05-01 00:00:00'
AND T6._Active = 0x01
AND ...
Явно в первом случае запрос более сложный для восприятия оптимизатором.
Вынесем оба подзапроса в SQL Server management Studio и посмотрим как они выполняются:
Статистика ввода/вывода и длительность выполнения:

Первый запрос (с позиций по документу) выполнился в 4,5 раза дольше второго и потребовал в 8 раз больше логических чтений.
Планы запросов:
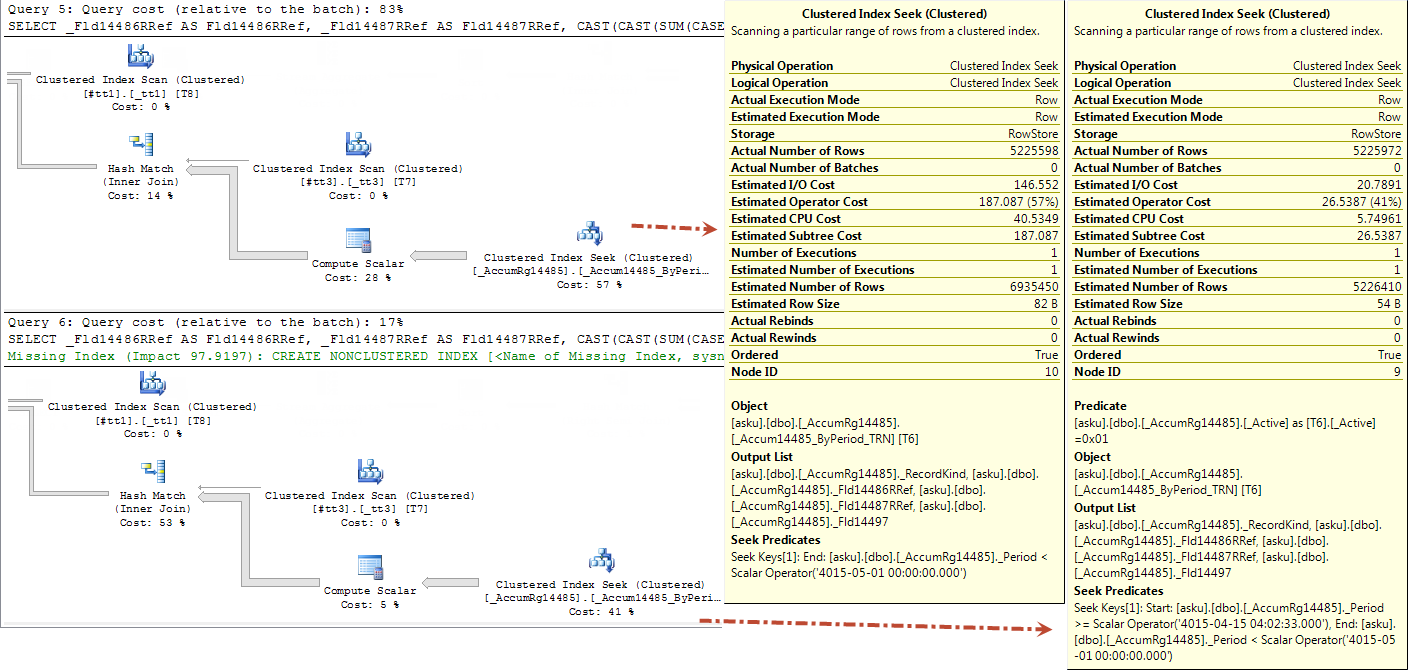
Структура идентичная, но используемые параметры разные.
Для первого запроса Seek Predicate указан только один (период меньше 1 мая), а для второго - оба ограничения по периоду.
Вариант решения проблемы:
Если проблема у вас подтверждается, то желательно по максимуму отказаться от использования Границы и МоментаВремени при отборе по периоду в запросах к виртуальным таблицам. Если подобный запрос есть в процедуре проведения документа, то отбор остатков по позиции документа нужен не всегда, а только тогда, когда документ НЕ является первым в секунде и документы влияют друг на друга. В зависимости от интенсивности документооборота, это может существенно снизить количество выполняемых запросов с нежелательными параметрами.
Например, при записи документа контролировать - есть ли записи в регистре в данной секунде ранее текущего документа по такому же Складу. Если нет, то отбирать остатки по дате, если да - по позиции документа:
Запрос = Новый Запрос(
"ВЫБРАТЬ ПЕРВЫЕ 1
| 1 КАК Поле1
|ИЗ
| РегистрНакопления.ПартииТоваровНаСкладах КАК ПартииТоваровНаСкладах
|ГДЕ
| ПартииТоваровНаСкладах.Период = &Период
| И НЕ ПартииТоваровНаСкладах.Регистратор = &Регистратор
| И ПартииТоваровНаСкладах.Склад = &Склад
| И ПартииТоваровНаСкладах.МоментВремени < &МоментВремени");
Запрос.УстановитьПараметр("Период", Дата);
Запрос.УстановитьПараметр("Регистратор", Ссылка);
Запрос.УстановитьПараметр("Склад", Склад);
Запрос.УстановитьПараметр("МоментВремени", МоментВремени());
ДокументЕдинственныйВПериоде = Запрос.Выполнить().Пустой());
....
Если ДокументЕдинственныйВПериоде Тогда
СтруктураПараметровДляЗапросаКОстаткам.Вставить("Период", Дата);
Иначе
СтруктураПараметровДляЗапросаКОстаткам.Вставить("Период", МоментВремени());
КонецЕсли;
При этом вариант упрощения запроса с позицией документа, который позволит устранить эту проблему, существует. К сожалению, сделать это могут только разработчики платформы.
Я описал эту ситуацию и вариант оптимизации в партнерской конференции.
У кого есть доступ - буду благодарен за "+1" в той теме.





