
{kind=link}
Поступило задание на парсинг страницы сайта. Например, нам нужна ссылка на основное фото. Для начала, узнаем имя этого атрибута. Если вы используете браузер Мозилла (в других, по-другому), достаточно в открытой странице на элементе вызвать контекстное меню и выбрать пункт Inspect element:
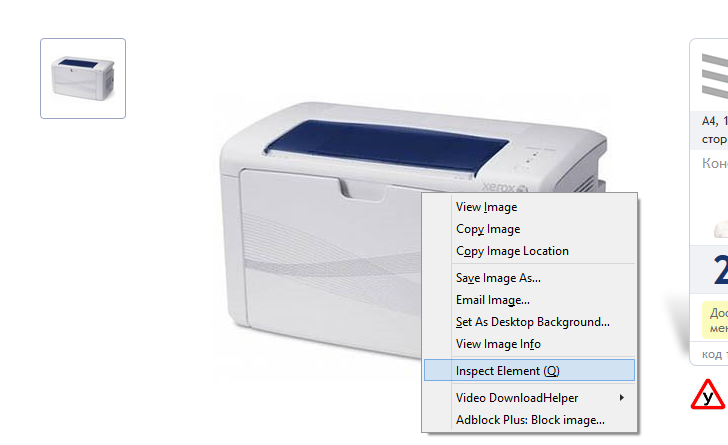
После этого в появившимся окне спотрим, как называется текущий атрибут. В нашем случае, "large_picture_container":
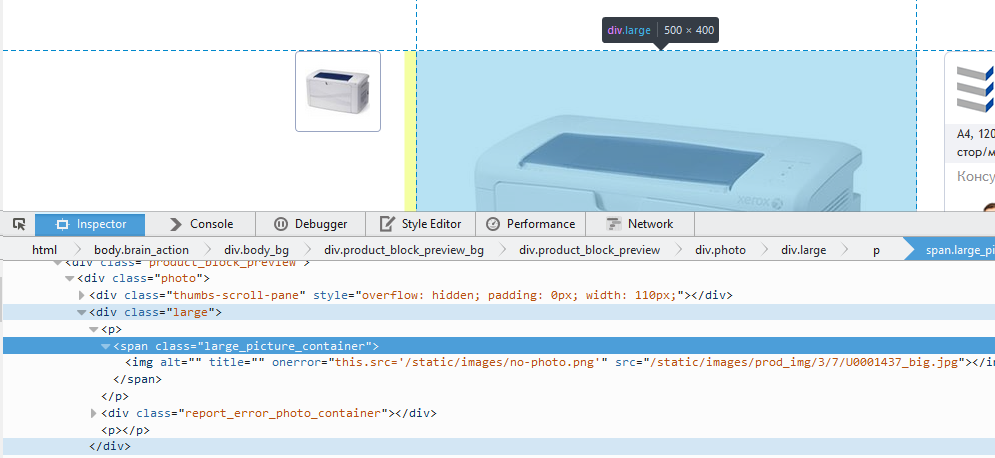
Дальше пишем простенький код на примере нашего сайта:
Функция Парсинг(Ссылка)
ЧтениеHTML = Новый ЧтениеHTML;
ЧтениеHTML.ОткрытьФайл(Ссылка);
ПостроительDOM = Новый ПостроительDOM;
ДокументHTML = ПостроительDOM.Прочитать(ЧтениеHTML);
ЭлементыDOM = ДокументHTML.ПолучитьЭлементыПоИмени("span");
СсылкаВрем = "";
Для Каждого ЭлементDOM Из ЭлементыDOM Цикл
Если ЭлементDOM.ИмяКласса = "large_picture_container" Тогда
Для каждого ДочУзл Из ЭлементDOM.ДочерниеУзлы Цикл
Если ДочУзл.ИмяУзла = "img" Тогда
СсылкаВрем = ДочУзл.Источник;
Возврат (ЗначениеЗаполнено(СсылкаВрем), "http://brain.com.ua" + СсылкаВрем ,"");
КонецЕсли;
КонецЦикла;
СсылкаВрем = ЭлементDOM
КонецЕсли;
КонецЦикла;
Возврат "";
КонецФункции