





{kind=link}
Платформа воспроизведения: 1С:Предприятие 8.3 (8.3.6.2237)
Конфигурация: Управление торговлей, редакция 11.1 (11.1.9.56)
Сервер обработки:
Процессор: 2х Intel Xeon X5660 2.8 ГГц
ОЗУ: 96 ГБ.
ОС:Win server 2008 R2 enterprise SP1 64x
MS SQL Server 2012. Выделено памяти 50 ГБ.
1С Сервер 64 (8.3.6.2237)
Все статистики и индексы абсолютно обновлены + полнотекстовые. В базе только один я, то есть никаких данных не добавляется и не изменяется. Никаких больше фонновых заданий не запущено.
Вступная часть:
Все начинается как обычно с маленького вопроса и как обычно перерастает в целый ряд вопросов "почему?"...
У пользователей было замечено частое подвисание ДС (динамический список). Со слов пользователя, крутятся часики и программа замирает.
Расследование:
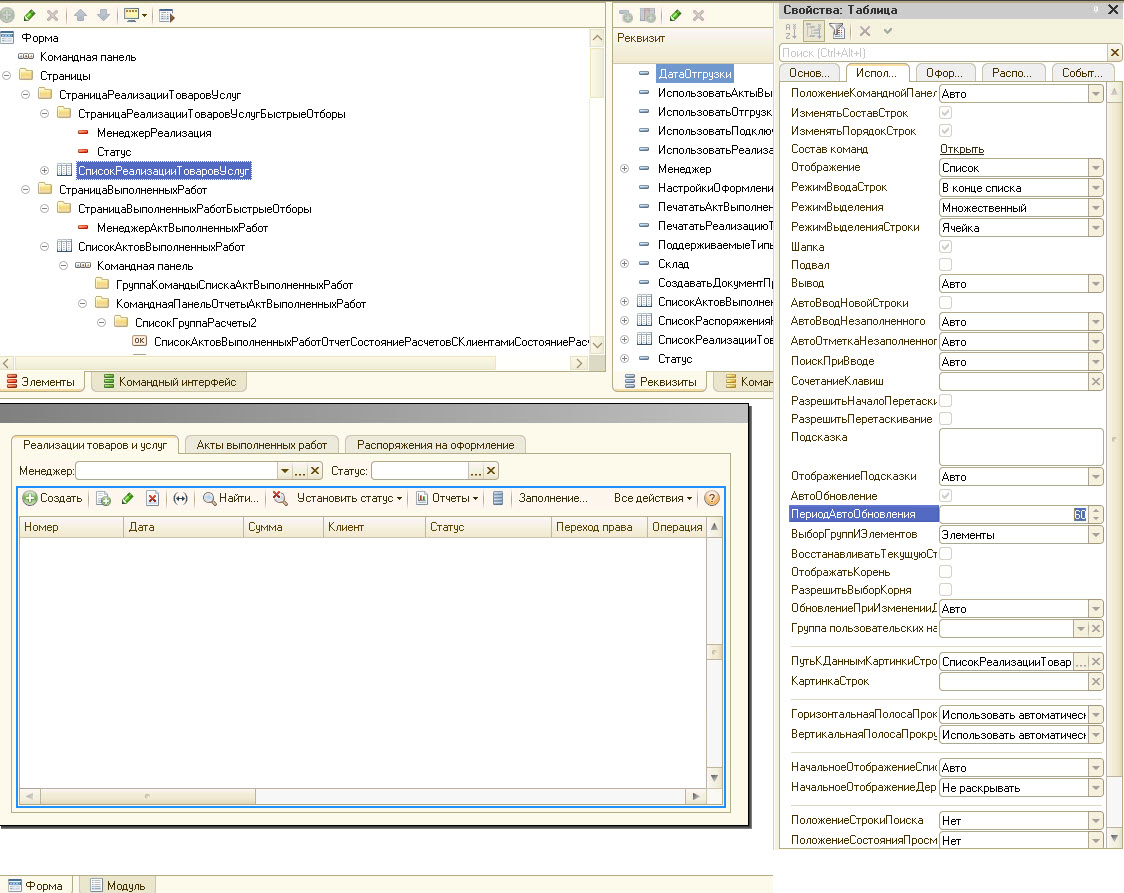
Долго не пришлось искать, поскольку конфигурация давно уже изменена (не типовая на 100%), то кто-то постарался и установил у пользователей автоматическое обновление в 10 секунд, при этом на уровне конфигурации. Если кто не в курсе, это находится здесь:
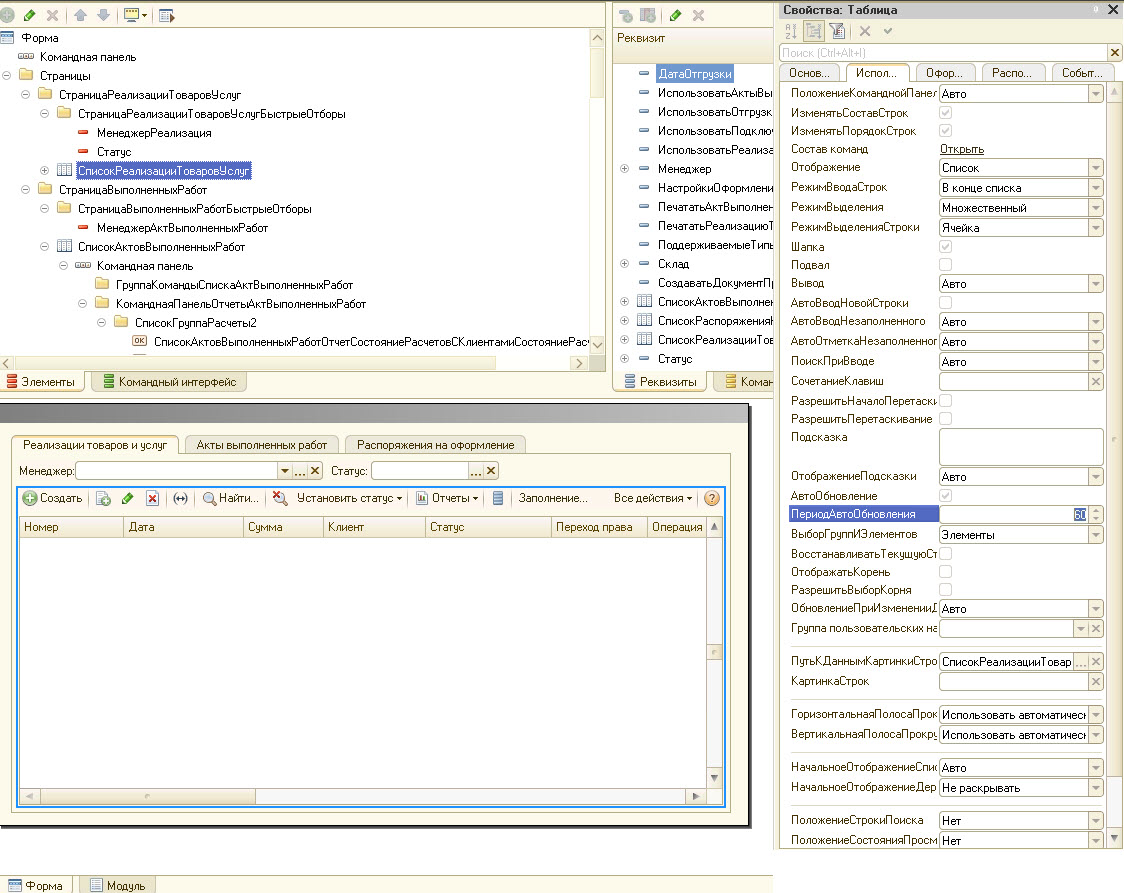
На этом не все, часики, конечно, мы устранили. Но в процессе поиска и оптимизации долгих запросов на сервисах Гилева, попадаются опять же наши запросы и наш список, но с использованием оператора поиска LIKE "%%", то есть пользователи осуществляли поиск по части строки. А сервис регистрирует какие-то космические цифры от 10 секунд до (кто бы подумал) 600 секунд. Усомниться в сервисе нет причин, проверено запросом в процессе работы пользователей:
Top запросов, создающих нагрузку на CPU на сервере СУБД за последний час
SELECT
SUM(qs.max_elapsed_time) as elapsed_time,
SUM(qs.total_worker_time) as worker_time
into T1 FROM (
select top 100000 * from
sys.dm_exec_query_stats qs
where qs.last_execution_time > (CURRENT_TIMESTAMP - '01:00:00.000')
order by qs.total_worker_time desc
--order by qs.max_elapsed_time desc
) as qs;
select top 100
(qs.max_elapsed_time) as elapsed_time,
(qs.total_worker_time) as worker_time,
qp.query_plan,
st.text,
dtb.name,
qs.*,
st.dbid
INTO T2
FROM
sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
left outer join sys.databases as dtb on st.dbid = dtb.database_id
where qs.last_execution_time > (CURRENT_TIMESTAMP - '01:00:00.000')
order by qs.total_worker_time desc
--order by qs.max_elapsed_time desc;
select
(T2.elapsed_time*100/T1.elapsed_time) as percent_elapsed_time,
(T2.total_worker_time*100/T1.worker_time) as percent_worker_time,
T2.*
from
T2 as T2
INNER JOIN T1 as T1
ON 1=1
order by T2.total_worker_time desc
--order by T2.max_elapsed_time desc;
drop table T2;
drop table T1;
Я понимаю вашу терпеливость и жажду "запрос в студию", но, обещаю, мы к этому обязательно подойдем, и они еще успеют надоесть :)
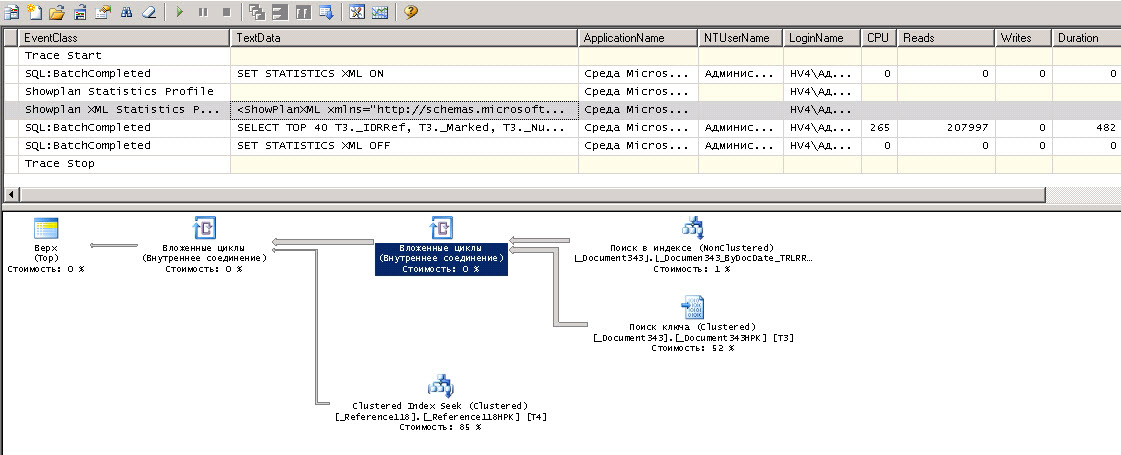
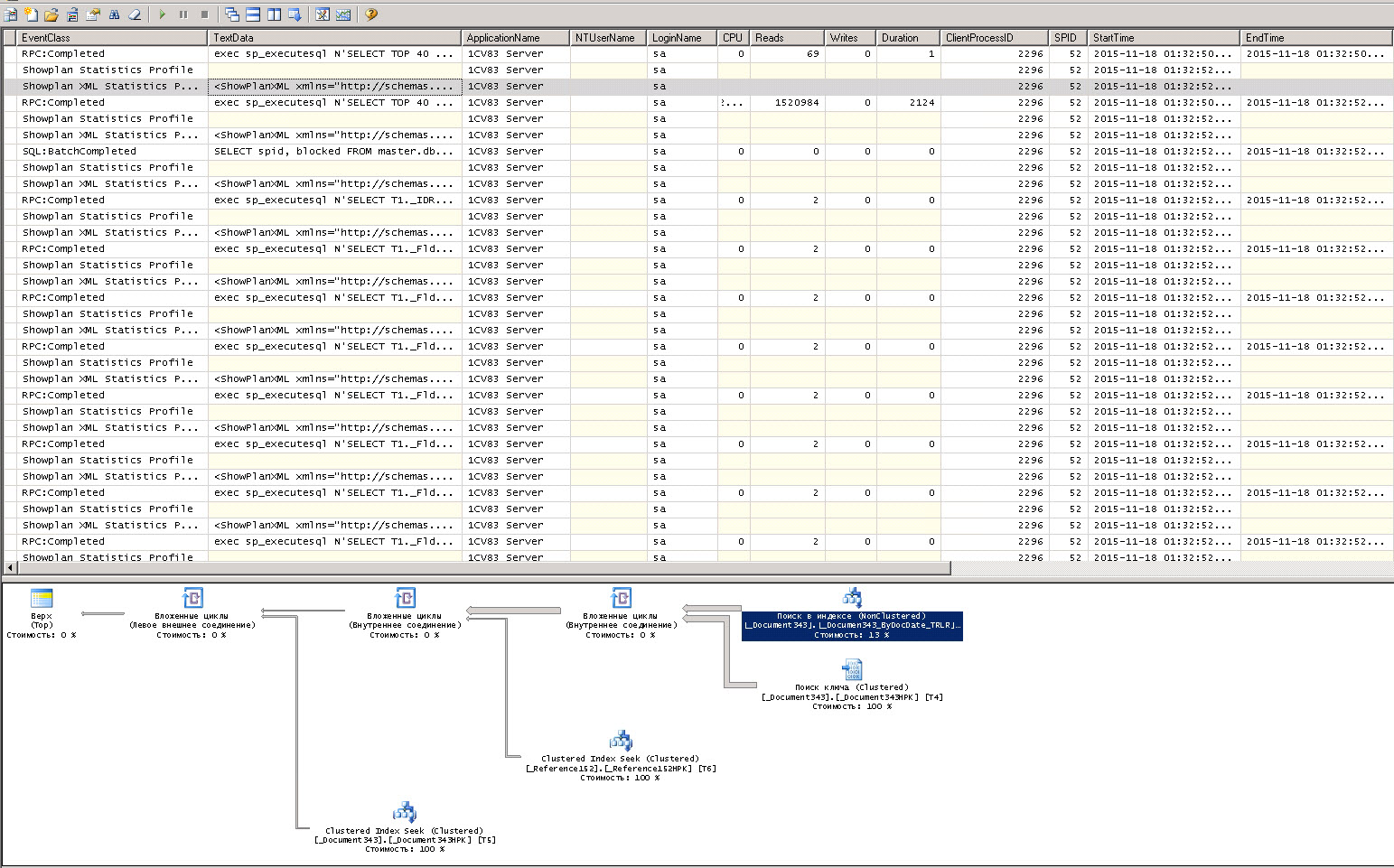
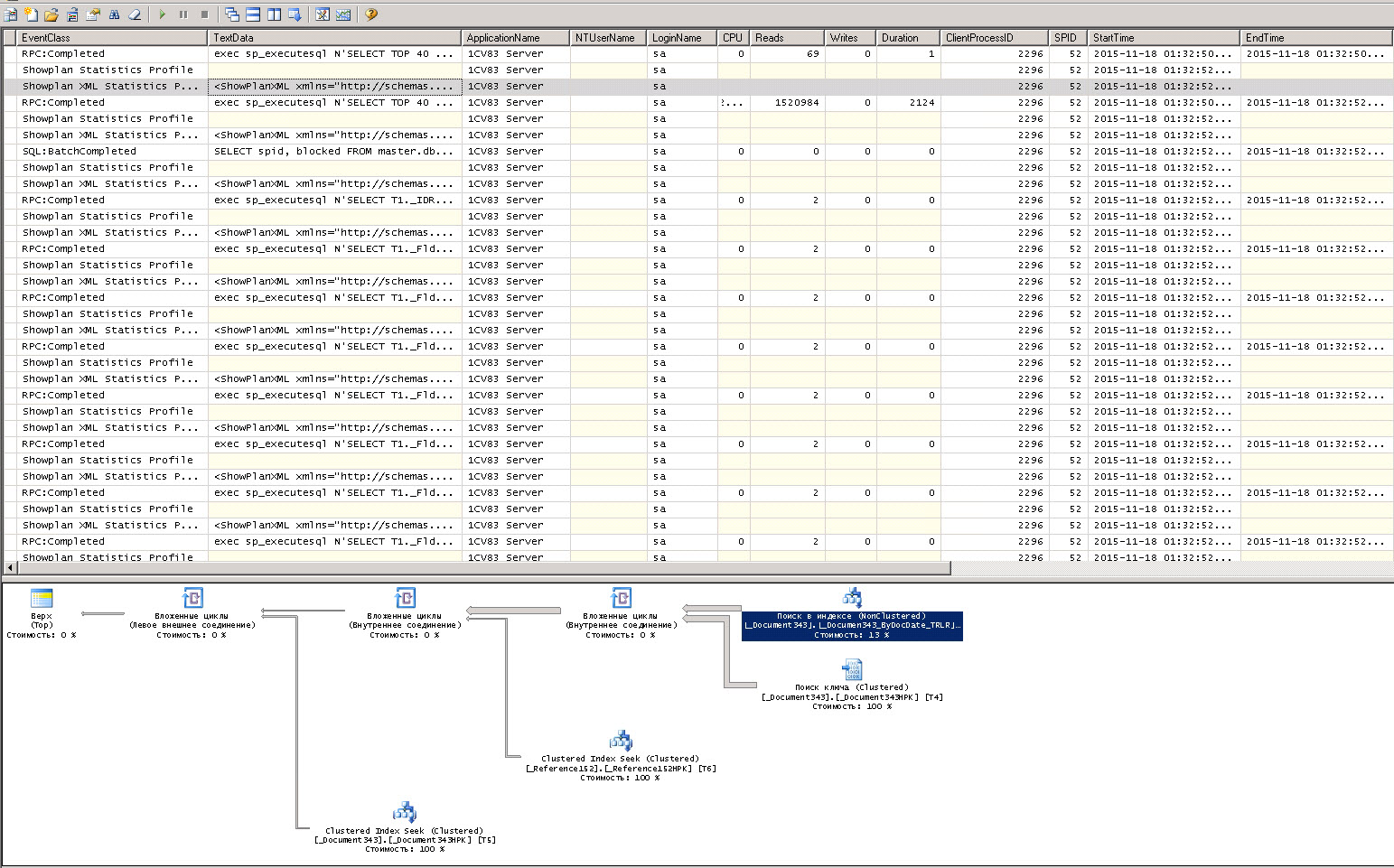
Ну вот, почти добрались, запускаем первую трассировку по ДС. Я для себя сделал открытие, ну я в принципе понимал модель работы ДС, но никогда не видел этого на уровне трассировки. Так вот, на этом уровне к базе идет четыри похожих запроса, разница между ними только в условиях. Для проверки приложил их тексты отдельно (Query1.txt - Query4.txt). Кстати, когда открыть список на форме впервые, то запрос будет только один.

Здесь, как видим, нет никаких операторов LIKE. Собственно, это правильно, поскольку это просто обновили список без условий. А теперь представляем ту ситуацию, что была прежде, уровень автообновления 10 секунд и поиск по части строки, который работает крайне интересно. То есть мы уже приблизились к тому, что нагружает сервер СУБД. Забегая наперед, сейчас вообще думаем у части пользователей поубирать автообновления ДС, зачем нагружать сервер лишними пакетами запросов.
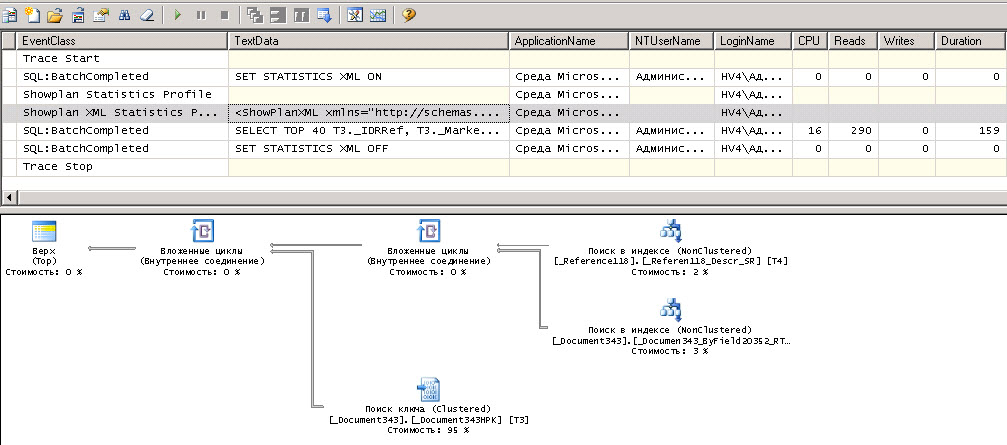
После экспериментов на реквизиты, по которым делали пользователи поиск, накладываем Индексировать с доп. упорядочиванием, чем-таки вырываем частичную победу в производительности:
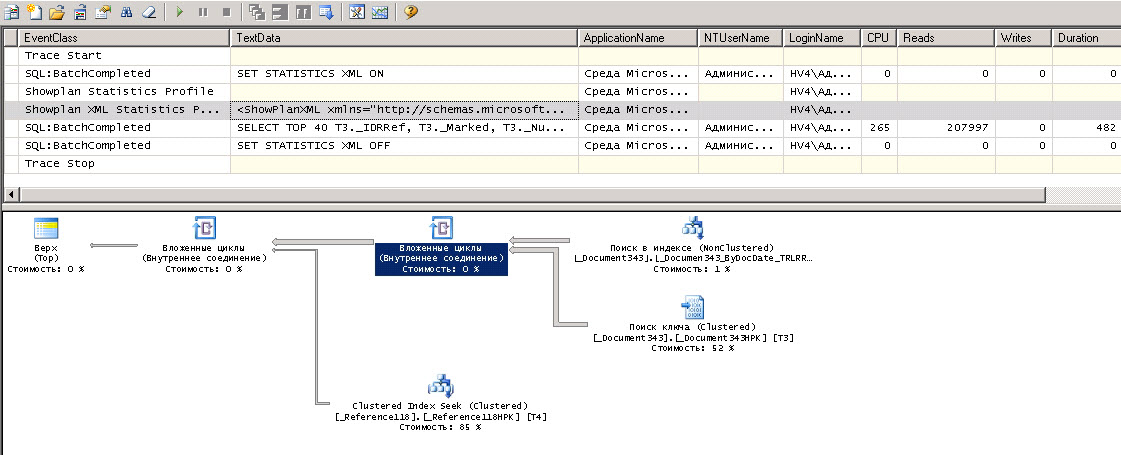
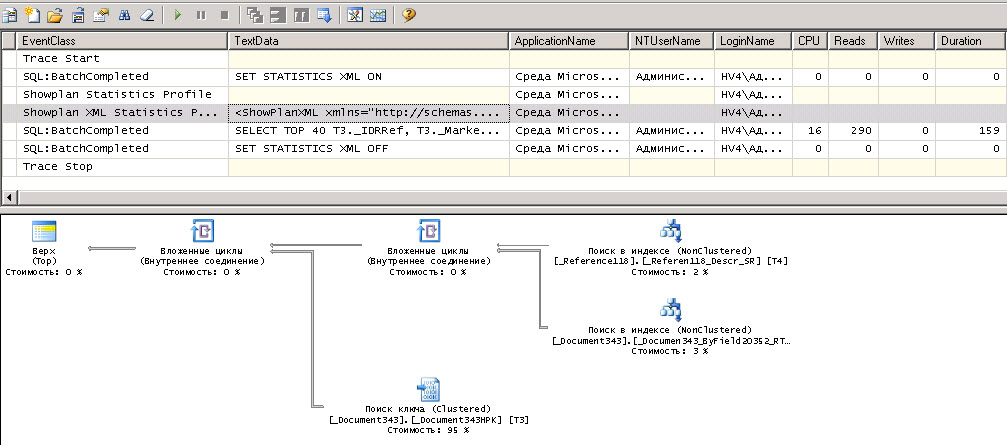
Что здесь сразу не нравится, так это две вещи. Это поиск ключа и жирные линии. Кстати, они были более жирными, когда у нас не было индекса по реквизиту, там READS превышало 1.5 млн. чтений и выше. То есть индекс нам помог, но проблемы еще остались. А проблемы в операторе ORDER BY, который платформа сама старательно добавляет, и неважно, что сортировка вообще пользователем не указана. Меняю текст запроса в MStudio (просто ремарим сортировку). Поиск в ключе остается из-за условия по дате, но вот стоимость и количество уменьшилось существенно. Осталось только ждать и надеяться, что 1С все-таки согласится исправить такое поведение ДС.
Выводы:
- Проверяем автообновление ДС. По возможности вообще отказываемся, если особенно есть большие соединения в ДС.
- Если получится, то искать не по части строки, а по началу строки, так индекс накладывается, или по полному соответствию.
- Добавляем индекс по реквизитам Индексировать с доп. упорядочиванием.
- В данном случае, оптимизировать запрос средствами 1С больше некуда. Поскольку мы уперлись в оператор ORDER BY, который платформа сама добавляет. Стоит только обращаться в 1С и просить как-то исправить поведение ДС.