



{kind=link}
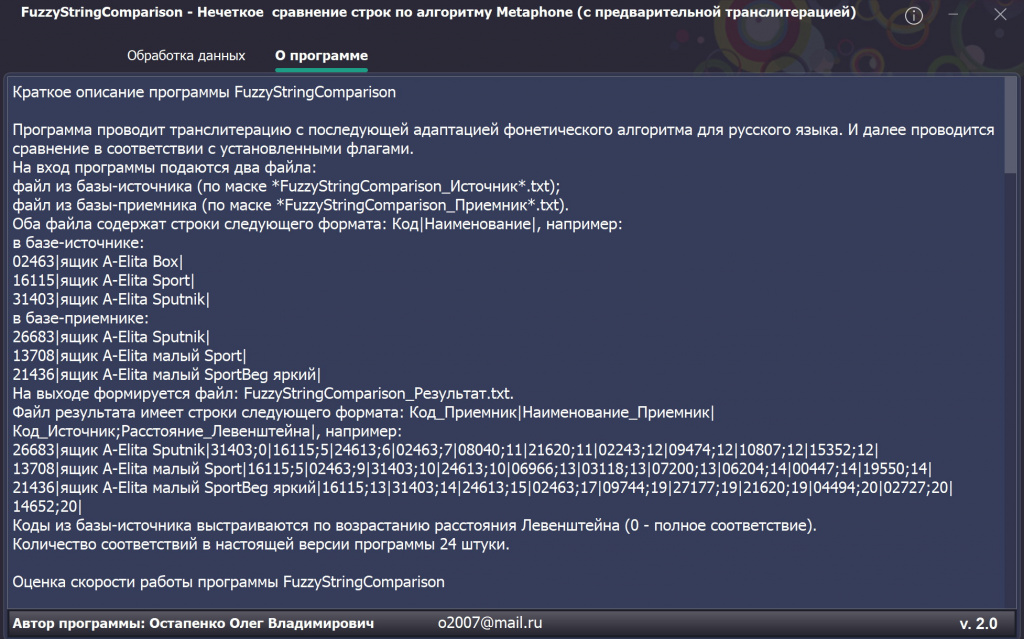
Краткое описание программы FuzzyStringComparison
Важно ! Кодировка в обрабатываемых файлах должны быть Windows-1251 (ANSI).
Программа проводит транслитерацию с последующей адаптацией фонетического алгоритма для русского языка. И далее проводится сравнение в соответствии с установленными флагами.
На вход программы подаются два файла:
файл из базы-источника (по маске *FuzzyStringComparison_Источник*.txt);
файл из базы-приемника (по маске *FuzzyStringComparison_Приемник*.txt).
Оба файла содержат строки следующего формата: Код|Наименование|, например:
в базе-источнике:
02463|ящик A-Elita Box|
16115|ящик A-Elita Sport|
31403|ящик A-Elita Sputnik|
в базе-приемнике:
26683|ящик A-Elita Sputnik|
13708|ящик A-Elita малый Sport|
21436|ящик A-Elita малый SportBeg яркий|
На выходе формируется файл: FuzzyStringComparison_Результат_Дата_Время.txt (например: FuzzyStringComparison_Результат_20240411_202132.txt).
Файл результата имеет строки следующего формата: Код_Приемник|Наименование_Приемник|Код_Источник;Расстояние_Левенштейна|, например:
26683|ящик A-Elita Sputnik|31403;0|16115;5|24613;6|02463;7|08040;11|21620;11|02243;12|09474;12|10807;12|15352;12|
13708|ящик A-Elita малый Sport|16115;5|02463;9|31403;10|24613;10|06966;13|03118;13|07200;13|06204;14|00447;14|19550;14| 21436|
ящик A-Elita малый SportBeg яркий|16115;13|31403;14|24613;15|02463;17|09744;19|27177;19|21620;19|04494;20|02727;20|14652;20|
Коды из базы-источника выстраиваются по возрастанию расстояния Левенштейна (0 - полное соответствие).
Количество соответствий в настоящей версии программы 24 штуки.
Оценка скорости работы программы FuzzyStringComparison
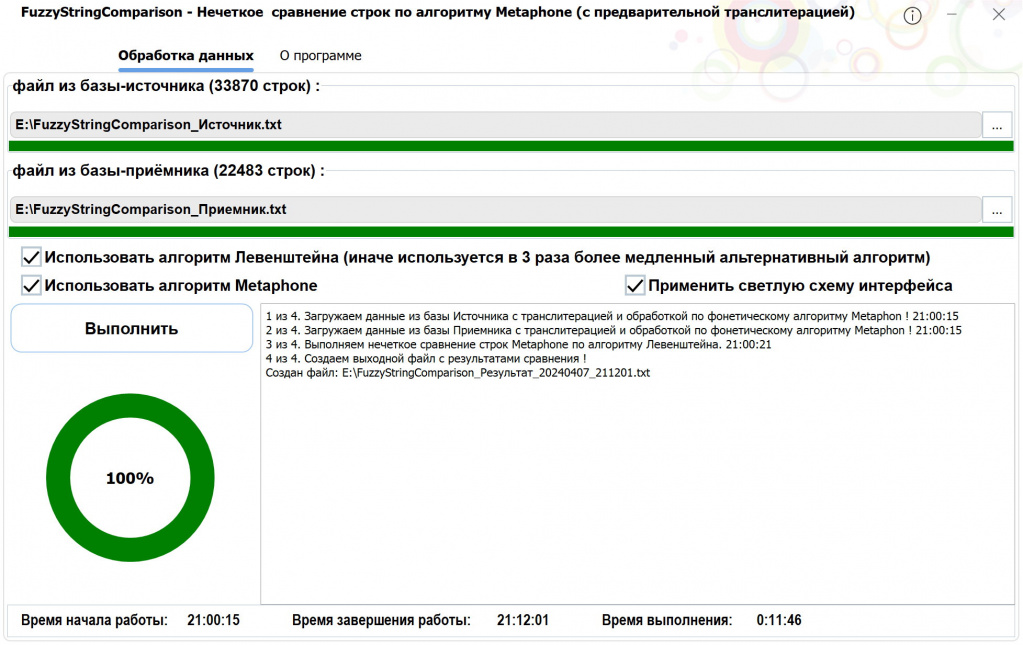
При использовании двух флагов "Использовать алгоритм Левенштейна" и "Использовать алгоритм Metaphone" при сопоставлении двух баз по 30000 строк время обработки около 12 минут на процессоре AMD Ryzen 9 5950X.
Качество сопоставления
Traper кормушка фидер "Methody" 25-50гр 2шт. = Traper кормушка Feeder Metody 2шт 25/30/35/40/50gr
кембрик Фламинго силикон.цветной d.1,0-2,0мм 1м. = Flamingo кембрик силикон дл.1м д.1,0-2,0мм
блесна Меппс Аглия Хэви Лонг №2Tiger = блесна Mepps Heavy Aglia Long №2 Tiger
При этом следует понимать, что расстояние Левенштейна между указанными строками достаточно большое, но тем не менее алгоритм позволил сопоставить эти строки как наименее расходящиеся по сравнению с остальными.
Примечание
С остальными сочетаниями флагов можете экспериментировать на свое усмотрение. Но при этом важно отметить, что если снят флаг "Использовать алгорим Левенштейна", тогда используется алтернативный алгоритм (в три раза более медленный) и соответствие строк выражается в процентах (100 - полное соответствие).
Примеры обработок 1С можно посмотреть здесь: //infostart.ru/public/442670/.
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ АЛГОРИТМОВ
Что такое расстояние (метрика) Левенштейна?
В 1965 году советский математик Владимир Иосифович Левенштейн разработал алгоритм, который позволяет оценить, насколько похожа одна строка на другую. Алгоритм Левенштейна позволяет получить именно численную оценку похожести строк. Основная идея алгоритма состоит в том, чтобы посчитать минимальное количество операций удаления, вставки и замены, которые нужно сделать над одной из строк, чтобы получить вторую. Допустим, у нас есть слова Машка и Миша. Попробуем преобразовать одно слово в другое, используя только удаление, добавление и замену.
Машка Миша — исходное состояние
Мишка Миша — шаг 1 (замена)
Миша Миша — шаг 2 (удаление)
Нам потребовалось два шага, значит, расстояние Левенштейна от строки Машка до строки Миша равно 2.
Фонетический алгоритм Metaphone
Фонетические алгоритмы сопоставляют двум словам со схожим произношением одинаковые коды, что позволяет осуществлять сравнение и индексацию множества таких слов на основе их фонетического сходства. Для английского языка давно существуют и активно используются алгоритмы Soundex и Metaphone, которые создают для слова ключ, причём похожим словам или неверным написаниям одного слова будет соответствовать один ключ. Если кассир в банке наберёт вашу фамилию неверно, она всё равно получит доступ к вашей записи в базе данных, так как поиск ведётся по ключам. Например, ключ MetaPhone для Gustavson и Gustafson - KSTFS. Ключ SoundEx для тех же фамилий - G312. Уже отсюда можно видеть, что MetaPhone убирает гласные, преобразует строку в верхний регистр и пишет одну букву F вместо двух одинаково читающихся F и V. Более простой алгоритм SoundEx записывает первую букву, затем номера групп последующих согласных (B, F, P, V - первая группа; C, G, J, K, Q, S, X, Z - вторая; D, T - третья; L - четвёртая; M, N - пятая и R - шестая). Из повторяющихся номеров остаётся только один; всего записывается не более четырёх номеров.
Транслитерация кириллицы в латынь по правилам ГОСТа Р 7.0.34-2014 (упрощенная транслитерация)
Преобразование строки вида 'Транслитерация' в 'Transliteraciya' по правилам ГОСТа Р 7.0.34-2014 (упрощенная транслитерация)
Отличия ГОСТа Р 7.0.34-2014 от ГОСТа 7.79-2000:
"Ь" будeт заменен на одинарный апостроф ' вместо (одинарного грависа) `
"Ъ" будeт заменен на двойной апостроф '' вместо (двойного грависа) ``
"Ы" будeт заменен на Y вместо Y` (Y с грависом)
"Э" будeт заменен на E вместо E` (E с грависом)
rus: string = 'абвгдеёжзийклмнопрстуфхцчшщьыъэюяАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЪЭЮЯ';
lat: array[1..66] of string = ('a', 'b', 'v', 'g', 'd', 'e', 'yo', 'zh', 'z', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'f', 'x', 'c', 'ch', 'sh', 'shh', '''', 'y', '''','e', 'yu', 'ya', 'A', 'B', 'V', 'G', 'D', 'E', 'Yo', 'Zh', 'Z', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'R', 'S', 'T', 'U', 'F', 'X', 'C', 'Ch', 'Sh', 'Shh', '''', 'Y', '''', 'E', 'Yu','Ya');
Адаптация фонетического алгоритма для русского языка
Переводим всё слово в один регистр, например в нижний, и заменяем одни буквы или комбинации букв их «фонетическими соответствиями», т.е., попросту, другими буквами (много реже — комбинациями).
Приблизительная таблица «фонетических соответствий» для русского языка:
Во первых – всевозможные сдвоенные согласные. Убираем, одной вполне достаточно:
bb=b; kk=k; rr=r; cc=c; ll=l; ss=s; dd=d; mm=m; tt=t; ff=v; nn=n; zz=z; hh=h; pp=p
Далее — разнообразные шипяще-свистящие:
sh=s; zch=s ; ck=k ; ch=c ; sch=s ; ks=x; shh=s; csh=s ; ts=c; zhch=s; zh=z ; tc=c
Потом остальные фирменные фишки русского языка, такие как «ю», «я», «ё», «й», «ф» и т.п.:
yu=u; je=e; oy=oi; ju=u; oj=oi; ey=ei; ph=f; ya=a; ej=ei ; yy=i; ja=a; yo=e ; ii=i; ia=a; io=e; iy=i; ye=e; jo=e ; y=i; ie=e
Ну и прочее, оставшееся:
kh=h; gh=g; '=
Метод n-грамм, метод триад
Это семейство методов основано на следующем наблюдении: модифицированное и исходное слова должны обладать общими подстроками. Пусть, к примеру, "полоса" в результате ошибки (скажем при оптическом распознавании) трансформировалась в слово "пороса". Тогда оба слова обладают общей подстрокой: оса. В общем случае, можно использовать следующее свойство: пусть слово и получено из слова V в результате к операций редактирования (типа удаление, замена или вставка), тогда, если представить слово и в виде последовательности (k+1) подстроки, то хотя бы одна из этих подстрок будет также являться подстрокой исходного слова V.
Организация списка ключевых слов в виде инвертированного файла, в котором роль терминов играют подстроки длины n (так называемые "n-граммы"), позволяет вести поиск по сходству и по подстроке, в большинстве случаев - без сканирования словаря. Предположим, нужно найти все термины, отличающиеся от n не более чем на k операций редактирования. Представим и в виде суммы k+1 подстрок, каждая из которых не короче n. Если такое разбиение невозможно - сканируем словарь. Если же возможно - то все подстроки разбиения обладают префиксом длины n. Для каждого префикса (являющегося как раз n-граммой) нужно считать соответствующий инвертированный список (где хранятся ссылки на слова, содержащие эту n-грамму), и для каждого слова из инвертированного списка непосредственно проверить, действительно ли оно отличается от поискового термина и не более чем на к операций редактирования.
Чтобы избежать сканирования словаря в случае коротких поисковых терминов - желательно также инвертировать и "синтетические" n-граммы, то есть подстроки вида $s и i$, где s и i, соответственно, начала и окончания слов длины n-1, а $ - специальный символ, не входящий в алфавит. Модификация метода n-грамм Вилбура-Ховайко, которую сами авторы называют методом триад (используются 3-граммы или "триады"), была разработана для минимизации числа обращений к словарю. Авторы метода предложили строить полное множество терминов, имеющих общие триады с ключевыми словами запроса, но затем - с помощью весового "коэффициента похожести" терминов словаря и запроса - на этапе чтения инвертированных списков "отсекать" малоперспективные варианты (для которых коэффициент похожести будет меньше заданного порогового значения). При этом какие-то термины могут быть пропущены; налицо компромисс между эффективностью поиска и его полнотой.
Про альтернативный метод поиска в программе FuzzyStringComparison
В программе FuzzyStringComparison используется модифицированный метод триад, предложенный в 1998 году Владимиром Кива.
Предположим есть такой текст:
По рзелульаттам илссеовадний одонго анлигйсокго унвиертисета, не иеемт занчнеия, вкокам пряокде рсапожолены бкувы в солве. Галвоне, чотбы преавя и пслоендяя бквуы блыи на мсете. Осатьлыне бкувы мгоут селдовтаь в плоонм бсепордяке, все-рвано ткест чтаитсея без побрелм. Пичрионй эгото ялвятеся то, что мы не чиатем кдаужю бкуву по отдльенотси, а все солво цликеом.
Попробуем формализовать интуитивный процесс, благодаря которому мы поняли, что здесь написано. Определим коэффициент "похожести" двух слов, подсчитав, сколько символов из первого слова содержаться во втором. Но такой алгоритм не способен различать анаграммы и перевертыши. Например, слова "колесо", "оселок", "окосел" будут восприняты, как одинаковые.
Усложним процедуру, добавив проверку на присутствие 2-буквенных подстрок первого слова во втором. Потом 3-х буквенных... не пора ли остановиться? Средняя длина слова в русском языке - 6 букв. Хотите верьте, хотите нет, но перебором 3-х буквенных подстрок (ровно половина от 6) можно ограничиться. Число успешных поисков поделим на общее число подстрок - это и будет показатель сходства.
Примеры:
КОЛЕСО, ОКОСЕЛ. По отдельным буквам 6 попаданий из 6. 2-х буквенные: КО, ОЛ, ЛЕ, ЕС, СО - 1 из 5. 3-х буквенные: КОЛ, ОЛЕ, ЛЕС, ЕСО - 0 из 4. Результат: (6+1+0)/(6+5+4) = 0.467.
АРБУЗ, ТАРАКАН. 2 из 5; 1 из 4; 0 из 3. Результат: 3/12 = 0.250.
ТАРАКАН, АРБУЗ. 4 из 7; 1 из 6; 0 из 5. Результат: 5/18 = 0.278.
Видим, что "сходство", вообще говоря, не транзитивно. Поменяв порядок сравнения, можно получить иной результат. Чтобы побороть такой эффект, будем вычислять "коэффициент сходства", усредненный по обоим словам. Общее число совпадающих подстрок разделим на общее число подстрок: (3+5)/(12+18) = 0.267.