Что такое инцидент? Как взаимосвязаны изменения и инциденты?
 Для начала давайте разберемся в том, что же такое инцидент.
Для начала давайте разберемся в том, что же такое инцидент.
- Если переводить с латыни буквально, слово incidens – это «падающий». Это вполне актуально для IT– периодически «падает» софт, «падают» сервера.
- Если обратиться к толковому словарю Ушакова, то инцидент – это недоразумение, неприятное происшествие.
- А мы для себя сформулировали такое определение:
«Инцидент – это любой сбой в нормальном течении процесса» - вообще любой сбой. - И одновременно с этим инцидент – это немаловажный источник знаний о несовершенстве процесса, то, что позволяет нам понять, что что-то пошло не так, увидеть проблему (узнать о ее существовании) и попытаться ее решить.
 Из понятия инцидента логичным образом вытекает понятие изменений, потому что если инцидент произошел, значит, что-то нужно поменять.
Из понятия инцидента логичным образом вытекает понятие изменений, потому что если инцидент произошел, значит, что-то нужно поменять.
Что такое изменения?
- Это любые действия, направленные на преобразование технологии, конструкции, инфраструктуры или порядка выполнения любых видов работ.
- Изменения в любом случае необходимы. Если ничего не менять – это прямой путь «в никуда», к завершению, к закрытию бизнеса – нельзя оставаться на одном месте. Мир вокруг нас меняется, конкуренты не спят, нужно всегда двигаться вперед, нужно постоянно меняться.
- Но одновременно с этим любое изменение – это источник инцидентов, потому что что-то начинает делаться не так, как раньше.
Для того, чтобы изменения не стали источником проблем, процессом изменений нужно управлять. Естественно, мы можем управлять только теми изменениями, которые происходят внутри нашей компании, но в любом случае управление изменениями обязательно должно быть частью процесса управления инцидентами.
Процесс управления инцидентами
Вообще само по себе управление инцидентами не является каким-то «ноу-хау» – чем-то таким новым, чего раньше никто не делал. Все, кто внедрял у себя ISO9001 (та самая система менеджмента качества), знают, что один из обязательных процессов, который должен быть задействован – это процесс «Корректирующие и предупреждающие действия» – об этом процессе в стандарте ISO9001 достаточно хорошо и подробно описано.
И я расскажу о том, каким образом этот процесс запускался у нас, в нашей реально работающей большой организации: с какими проблемами мы столкнулись, как мы их решали, и какие подходы были найдены. Надеюсь, это будет полезно.

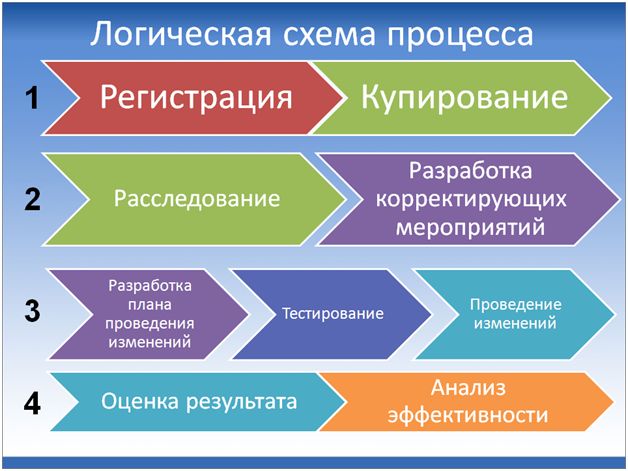
На слайде показано, как выглядит логическая схема процесса по управлению инцидентами: регистрация, купирование, расследование, разработка корректирующих мероприятий и т.д. – это та последовательность шагов, которая должна быть выполнена для того, чтобы была пройдена одна итерация процесса.
Сейчас мы более подробно рассмотрим, что представляетсобой каждый из этих шагов, и какие у них есть ключевые особенности, на которые нужно обращать внимание. Я также расскажу, с какими проблемами мы столкнулись при работе с инцидентами и что вообще с этим делать. И, в завершение, мы попытаемся разобраться, какие есть инструменты, позволяющие сделать управление инцидентами проще, лучше, понятнее.

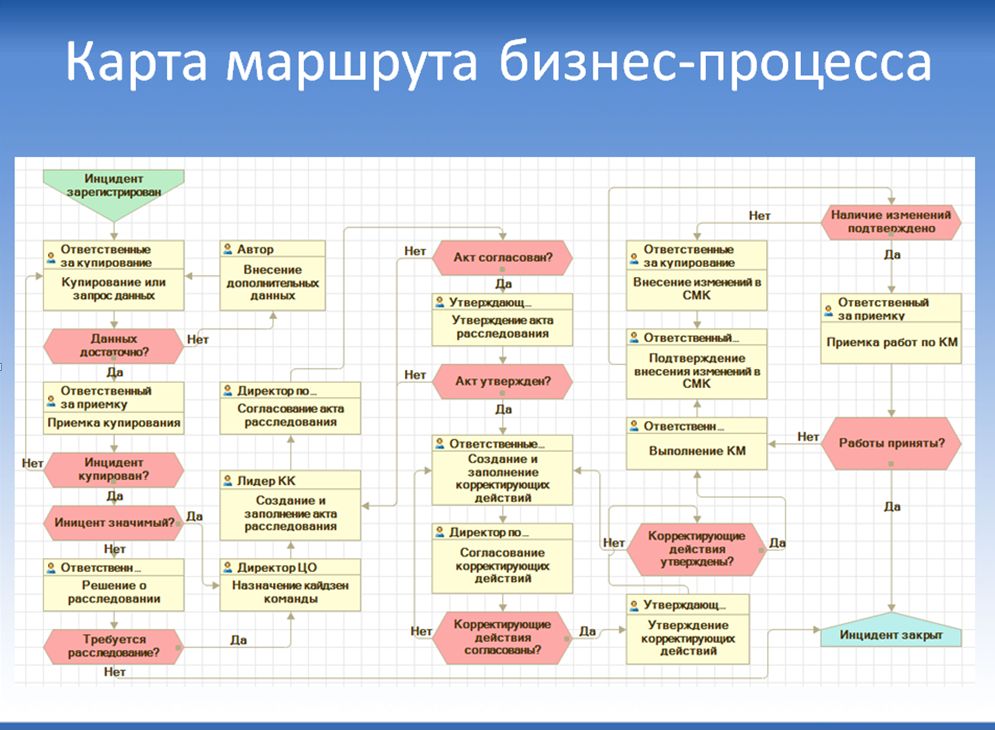
Итак, мы для себя полностью автоматизировали управление инцидентами на платформе 1С в самописной конфигурации, написанной с нуля.
Карта маршрута получившегося бизнес-процесса показана на слайде – она полностью соответствует описанной ранее логической схеме, но несколько сложнее.
Почему мы выбрали именно такую реализацию для процесса? На самом деле – это частности, потому что не так важно, каким образом процесс работает: он может вестись на бумаге, в Excel, на корпоративном портале, в 1С, на любой другой системе – главное, чтобы процесс работал. Просто когда все данные находятся в автоматизированной системе – это удобно.
Регистрация и купирование инцидентов
 По поводу регистрации инцидентов.
По поводу регистрации инцидентов.
Первое (и самое сложное), с чего нужно начать, – это начать регистрировать инциденты.
Оказывается, убедить людей в том, что они должны это делать, иногда бывает очень сложно. Почему это проблема? Потому что для того, чтобы зарегистрировать инцидент – встать и сказать, что «у меня произошел сбой» – нужно признать, что инцидент произошел, что был сбой в работе процесса. А поскольку у многих людей в голове существует стереотип, что сбои происходят из-за плохой работы, и если бы они работали хорошо, то сбоя бы не было, то им достаточно сложно признать факт того, что в их зоне ответственности что-то пошло не так.
Следовательно, нужно прививать культуру регистрации инцидентов: у сотрудников должен быть рефлекс " инцидент произошел -> его нужно зарегистрировать".
С чем мы столкнулись? Оказалось, что инциденты, произошедшие в смежных подразделениях, люди регистрировали достаточно охотно, потому что «это не я виноват, это они накосячили», а инциденты, произошедшие в зоне своей ответственности, регистрировать не хотели, потому что для этого нужно было признать что есть проблема. Вместо этого сотрудники пытались как-то спрятать инцидент, "не выносить сор из избы" и пр.
Каким образом мы с этим боролись?
- Здесь важный момент – для того, чтобы процесс работал хорошо, качественно – инциденты должны регистрироваться на всех уровнях – не только на уровне высшего руководства (генерального, функционального директоров, линейных руководителей). Процесс заработает по-настоящему хорошо только тогда, когда инциденты будут регистрировать все, вплоть до рядовых сотрудников.
- Во-вторых, должны быть созданы списки значимых инцидентов для каждой должности подразделения – это те инциденты, которые подлежат обязательной регистрации – хочешь ты или не хочешь, их нужно регистрировать.
Что это может быть?
Инцидент может иметь общий характер. Например, промышленная компания выпускает какой-то серийный продукт, и по результатам его приемо-сдаточных испытаний в произведенной серии продукции выявляется массовый брак. Это всегда инцидент. Причем, в зависимости от масштаба проблемы один и тот же инцидент может быть транслирован на разные уровни:- Например, выявление массового брака в серийно производимой продукции свыше 3% – это инцидент уровня генерального директора, который требует полной остановки конвейера, полноценного расследования и выяснения причин.
- А тот же самый инцидент, но с процентом брака более 1%, но менее 3 %– уже относится к уровню директора по качеству или начальника ОТК (то есть, генеральный здесь еще не подключается). Инцидент такого уровня в целом будет возникать чаще, чем на уровне генерального.
- А инцидент уровня конкретного контролера ОТК – это, например, выявление более 10 приборов в партии или более 3 приборов подряд.
Здесь суть не в конкретных цифрах, а в самом подходе – инцидент может быть одного плана, но в зависимости от тяжести его последствий его нужно рассматривать на разных уровнях. И если на самом нижнем уровне (уровне простого персонала) он может быть просто купирован, то на верхнем уровне он обязательно должен быть расследован, потому что если инцидент дошел до такого уровня, значит проблема есть и она носит системный характер. И если не найти её причину инцидент будет повторяться вновь и вновь.
Списки инцидентов должны быть у всех руководителей – от уровня генерального директора до линейных руководителей и начальников отделов.
- У каждой зоны ответственности должны быть свои списки инцидентов:
- Для IT туда может входить, например, сбой в работе серверного оборудования или недоступность информационной системы.
- Для уровня директора по IT – недоступность информационной системы более одного часа в рабочее время.
- Для начальника отдела сисадминов это может быть вообще любой сбой в работе оборудования, даже если этот сбой не привел ни к каким проблемам для бизнеса (даже если, например, просто не отработал регламент резервного копирования в ночное время). Выяснять причины нестабильности работы оборудования необходимо в любых случаях, поэтому инцидентом этой зоны ответственности должно быть любое отклонение.
- В первую очередь в эти списки нужно вносить те инциденты, которые имеют наиболее серьезные последствия для бизнеса – с этогонужно начать. Конечно, пока люди сами к этому еще не готовы, им необходимо дать толчок, каким-то образом их заставить – ввести специальный регламент для регистрации инцидентов. А когда процесс пойдет, это давление можно ослабить.
- Значимые инциденты регистрируются абсолютно всегда. Лучше, если система учета инцидентов автоматизирована и связана с системами оперативного управленческого учета, потому что тогда можно будет настроить какие-то триггеры, какие-то события, по которым регистрация будет происходить полностью автоматически.
- Следующий момент – купирование инцидента. После того, как инцидент зарегистрирован, его нужно купировать. Здесь все просто: если произошел пожар – его нужно потушить. Если остановился конвейер – его нужно запустить. Все остальное нужно отложить «на потом».
Поэтому первое, что мы должны сделать, – это устранить сам инцидент и его непосредственную причину, затем необходимо восстановить нормальное течение процесса, а сразу после того, как течение процесса восстановлено, нужно приступить к расследованию инцидента.

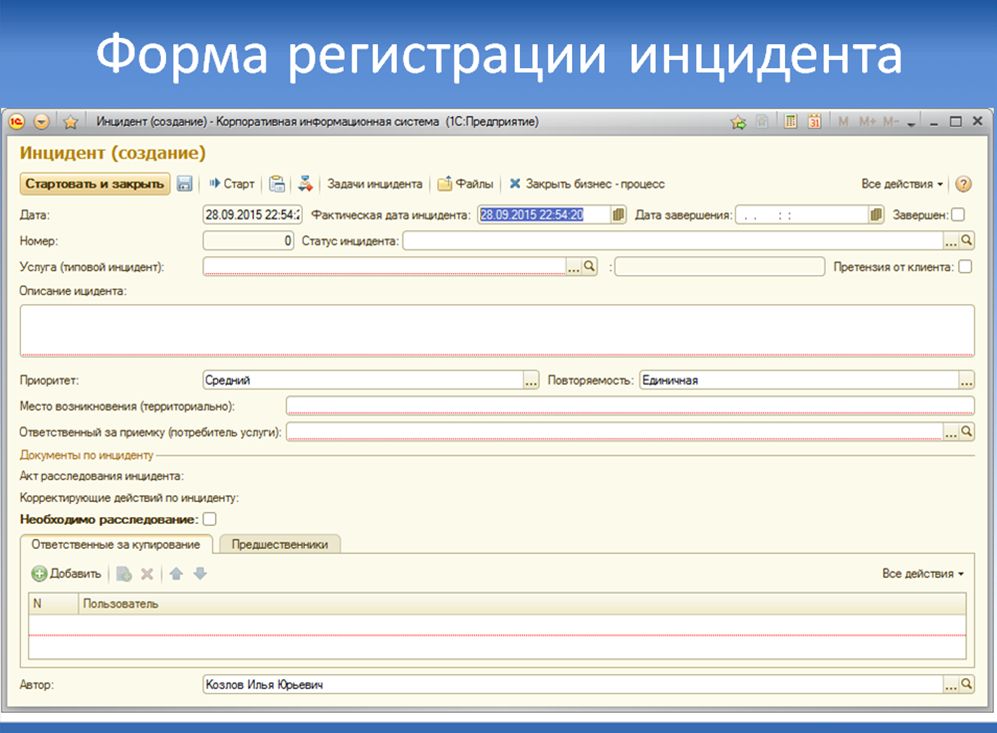
У нас в системе форма регистрации инцидента выглядит так, как показано выше.
Расследование инцидентов
 Теперь о том, что касается расследования инцидента.
Теперь о том, что касается расследования инцидента.
Все инциденты, входящие в список значимых, расследуются в обязательном порядке. Это расследование заключается в выявлении причины появления инцидента: пытаемся разобраться, какие наши действия привели к тому, что этот инцидент произошел.
Здесь хочу отметить важный момент – проблему, с которой мы столкнулись в процессе своей работы: мы вроде добились того, что люди начали регистрировать у себя инциденты и начали их расследовать, но делали они это только внутри своего центра ответственности. То есть, когда произошел какой-то сбой, начальник отдела позвал ответственного за это сотрудника, они там десять минут посидели, какую-то бумажку написали – все, расследование закончилось.
Так нельзя, это не будет работать – нужно обязательно создать рабочую группу, в которую будут входить сотрудники из разных подразделений:
- Там обязательно должен быть сотрудник поставщика услуги;
- Там должен быть сотрудник потребителя услуги, по которой произошел сбой;
- И, по необходимости, туда можно приглашать еще и экспертов, которые смогут разъяснить какие-то технические детали.
Количество людей в такой группе должно быть 5-6 человек – больше не нужно, иначе эффективность начнет падать.
К расследованию нужно приступить сразу после возникновения инцидента. Чем раньше мы это сделаем, тем выше вероятность, что расследование будет проведено качественно, и мы правильно определим причины, потому что особенность человеческой памяти – все имеет свойство забываться. Поэтому в течение первой недели расследования рабочая группа должна собираться как минимум два-три раза в неделю – это позволит эффективнее расследовать инцидент «по свежим следам». И желательно, чтобы это расследование было завершено в срок не более 10 дней.
Инструменты для расследования инцидентов

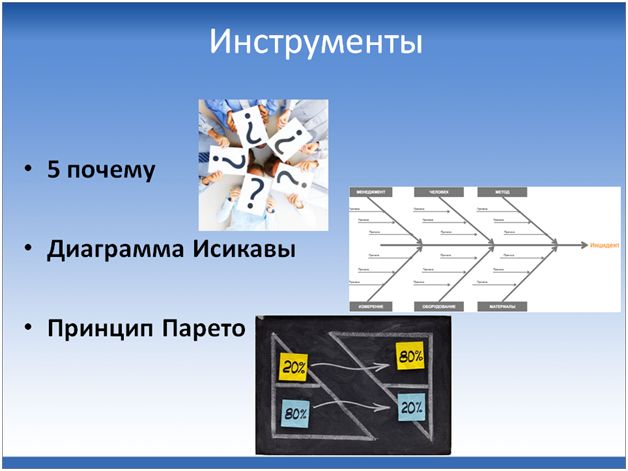
Какие есть инструменты для выявления причин инцидентов?
Инструментов, в принципе, достаточно много. Но я вам расскажу про те, которые показали эффективность по нашему опыту внедрения. Это:
- Инструмент «Пять почему»
- Диаграмма Исикавы
- И принцип Парето
Про каждый из них - чуть подробнее.
5 «почему»


Что такое «5 почему»?
Если задать вопрос «Почему» несколько раз подряд, каждый раз спрашивая про предыдущий ответ, мы можем быстро докопаться до причины. На слайде приведена небольшая стихотворная иллюстрация по этому поводу.
Диаграмма Исикавы

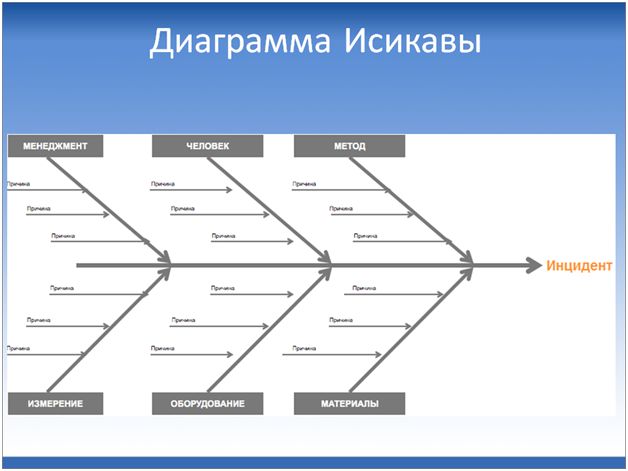
Диаграмма Исикавы – это, по сути, те же самые «5 почему», только усложненный вариант.
Диаграмму Исикавы удобнее использовать, когда причин много и мы классифицируем их по группам, относящимся к оборудованию, к материалам, к методам выполнения работ, к персоналу.
Как ее использовать? Рисуем квадратик, в котором коротко сообщаем суть инцидента, и от него начинаем рисовать вот такую диаграмму (она еще называется «рыбья кость»), на каждой линии которой мы будем размещать вот эти «5 почему», группируя их причины по зонам.
Принцип Парето
А принцип Парето, я думаю, и так уже многим известен: 80% результата можно получить, приложив 20% усилий, а оставшиеся 80% усилий дадут только 20% результата.
Принцип Парето применим в случае, когда инцидент произошел в ходе процесса, на который влияет очень много факторов, и для того, чтобы разобраться, какой из них конкретно вызвал инцидент, мы должны часть факторов отбросить и оставить только те 20% из них, которые дают 80% влияния на результат.
Классификация причин инцидентов.
Корневые причины и корректирующие мероприятия – взаимосвязь с регламентом


Сами причины инцидента делятся на три группы – корневые, сопутствующие и непосредственные. Что здесь важно?
- Важно всегда определить корневую причину, потому что после устранения корневой причины инцидент не должен повторяться.
- Непосредственная причина – это то действие, которое вызывало сам инцидент. Это может быть, например, нажатие какой-то кнопки, действие либо бездействие – это та "соломинка, которая переломила спину верблюда".
- И сопутствующие причины – это те причины, которые усугубили инцидент – они либо усложнили его купирование, либо привели к более тяжелым последствиям.
После того, как причины определены, их всегда необходимо правильно классифицировать, чтобы понять, какая из них является корневой.
 Что здесь поможет?
Что здесь поможет?
Есть критерий определения корневой причины: корневая причина всегда связана либо с нарушением регламента, либо с его отсутствием, либо с некорректностью самого регламента.
- Ситуация может быть такая – есть регламент, в котором написано, как делать. Люди обучены и действовали в соответствии с регламентом. Но инцидент возник. Значит, регламент неправильный.
- Если регламента нет вообще – люди как-то делают, но это их внутреннее тайное знание. Значит, причина – это отсутствие регламента (люди не знают, как делать правильно).
- И третий вариант – это когда и регламент есть, и люди обучены, и регламент правильный, но инцидент все равно произошел. Значит, эти люди регламент нарушили.
Теперь по поводу корректирующих мероприятий. После выявления причин и их классификации нужно разработать корректирующие мероприятия, которые будут направлены на устранение этих причин. Очень важно, что правильно составленные корректирующие мероприятия обязательно должны завершаться внесением изменений в какие-то регламенты (или их созданием). Фактически, мы должны изменить течение процесса, зафиксировать эти изменения в документации и обучить людей, как действовать правильно.
Акт расследования
 Как произвести расследование и правильно составить акт?
Как произвести расследование и правильно составить акт?
- Нужно записать сам инцидент: что произошло.
- Затем нужно коротко указать события, которые предшествовали инциденту и могли привести к его появлению.
- Далее – нужно расписать хронологию развития инцидента. В хронологии для каждого действующего лица нужно обязательно четко указывать дату, время, фамилию, должность – не просто «Сотрудник склада» или «Ответственный», а конкретно указать фамилию и должность этого человека. Это очень важно, потому что когда мы говорим о конкретных людях, о конкретных должностях, всегда возникает вопрос: а как он должен был поступать в этой ситуации, а что написано в его рабочей инструкции, а вообще где-то, в принципе, написано, что он должен был делать?
- После этого необходимо указать последствия инцидента;
- Зафиксировать причины и классифицировать их;
- И в завершение акта нужно сформулировать новые знания, которые были получены – определить, что же конкретно в процессе шло не так, что привело к появлению инцидента.
Процесс внедрения корректирующих изменений
 После того как составлен акт расследования инцидента, он передается на подписание руководителю рабочей группы, которая проводила расследование. И только после этого рабочая группа приступает к разработке корректирующих мероприятий.
После того как составлен акт расследования инцидента, он передается на подписание руководителю рабочей группы, которая проводила расследование. И только после этого рабочая группа приступает к разработке корректирующих мероприятий.
Следует отметить, что мероприятия по купированию (по прекращению инцидента) не являются корректирующими. Корректирующие мероприятия всегда направлены на устранение именно выявленных причин. Для планирования таких мероприятий разрабатывается отдельный самостоятельный документ, который не является частью акта.
Как правильно внедрять те корректирующие мероприятия, которые были запланированы?
- Например, если в партии был обнаружен брак, и мы для его исправления выбрали какое-то техническое решение, нельзя запускать процесс этого исправления сразу массово. Нужно провести тестирование: взять какую-то опытную партию и на нескольких позициях проверить, сможет ли выбранное корректирующее мероприятие нам помочь в действительности или нет?
- Далее, если первоначальное тестирование прошло успешно, нужно подготовить необходимые ресурсы для полномасштабного внедрения.
- После подготовки мы, наконец, сможем произвести окончательные изменения.
- Важный момент – обязательно до начала изменений нужно составить небольшой документ (он может быть буквально на полстраницы текста), в котором сформирован план возврата к первоначальному состоянию.
Что-то аналогичное применяется и в IT-разработке: прежде чем накатить новый релиз на живую базу, сначала делают бэкап и убеждаются, что этот бэкап работает, а потом пишут себе короткий план из трех пунктов, как можно вернуть базу в исходное рабочее состояние, если вдруг что-то пошло не так.
Пример расследования инцидента


Коротко – пример реального живого расследования инцидента, который произошел совсем недавно. В чем заключалась его суть?
Поступила претензия от клиента о выявлении брака. В ходе расследования было выявлено, что еще до того, как поступила эта претензия, у данной серии приборов обнаружилась проблема, связанная с ошибкой встроенного ПО. Для исправления этой ошибки была выпущена новая версия ПО, и на завод (в производство и на склад готовой продукции) были направлены электронные письма, в которых говорилось о том, что производство этих приборов нужно остановить, а те приборы, которые лежат на складе, нужно вернуть на доработку, чтобы заменить им программное обеспечение. В итоге, несмотря на все эти действия, клиенту все-таки ушли приборы с версией ПО, которая содержала ошибку.

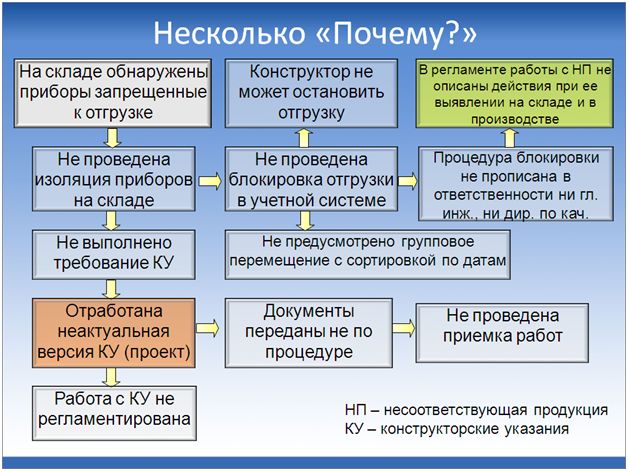
Какие здесь могут быть причины?
- Собственно, с чего все началось? С того, что на складе были обнаружены приборы, которые отгружать нельзя.
- Что произошло дальше (точнее, чего не произошло)? Эти приборы не были физически изолированы, не были как-то промаркированы – их нужно было забрать, увезти, наклеить на них красные ярлычки – этого сделано не было.
- Что дальше? В учетной системе не была произведена процедура блокировки – ни физически на складе, ни в учетной системе не заблокировали.
- Вопрос – почему не заблокировали в учетной системе? А потому, что нет в учетной системе режима блокировки, потому что приборы данного типа нужно было заблокировать не все (там их несколько типов было – это не конкретный артикул номенклатуры был, а это была целая серия артикулов, причем только произведенные после определенной даты) – такого режима не было.
- Дальше вопрос – почему не была проведена блокировка запланированной отгрузки? – потому что конструкторы не могут останавливать ни отгрузку, ни производство: нет у них такого режима, когда конструктор при выявлении ошибки может дать команду на остановку конвейера.
- Почему не была проведена физическая изоляция приборов? Потому что не было выполнено указание конструкторов, содержащее команду на эту изоляцию.
- А почему оно не было выполнено? Потому что оно пришло по электронной почте, да еще и оказалось, что в нем содержались не окончательные указания, а всего лишь их проект, и поэтому исполнитель приборы все-таки заблокировал, но не те.
И вот такая серия из «Почему?» позволила нам узнать, из-за чего в результате клиенту все-таки ушел брак. И корневой причиной явилось то, что в письме, которое содержало документацию по описанию работы с данной несоответствующей продукцией, ни слова не было сказано о том, как нужно было действовать, если эта продукция обнаружена на складе. Там очень подробно было все расписано – кто, как, в какой последовательности, что делает, кому передает. Но как поступить с бракованной продукцией, выявленной на складе, как ее изолировать и что с ней делать дальше, там указано не было.
Заключение


Собственно, на слайде указано, какие проблемы вас ждут, если вы решитесь у себя это внедрить.
Как с этим бороться и наш опыт того, как мы с этим боролись, я уже рассказал.
****************
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2015 CONNECTION 15-17 октября 2015 года.
Приглашаем вас на новую конференцию INFOSTART EVENT 2019 INCEPTION.
