Этот вопрос возник у нас на проекте по внедрению ЗУП2.5 с численностью 20000 и максимальным количеством одновременных пользовательских сессий 200.
На этапе опытной эксплуатации при расчете зарплаты пользователи начали интенсивно работать с документами «Начисление зарплаты сотрудникам организаций». Количество строк документов доходило до 2500 строк. У пользователей начали появляться сообщения «Конфликт блокировок при выполнении транзакции», и расчет приходилось запускать заново.
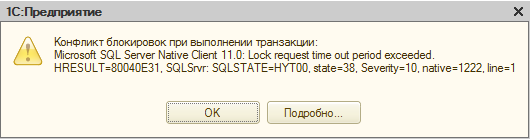
Стали разбираться. Оказалось, мы столкнулись с эффектом «Избыточной блокировки». Обычно этот эффект появляется при параллельном проведении документов. Если объяснять по-простому, один из документов блокирует большой объем данных на все время проведения документа. Эта блокировка задерживает проведение остальных документов, которые пытаются прочитать заблокированные данные. Это мешает параллельной работе пользователей и замедляет рабочий процесс. Вообще блокировка данных при проведении документов вещь полезная, она сохраняет целостность данных и гарантирует правильность выполнения расчетных алгоритмов. Но бывает так, что либо объем заблокированных данных чрезмерен, либо время блокировки слишком велико. В результате мы имеем многопользовательскую систему, которая по сути является однопользовательской: вместо параллельного проведения документов - последовательное.
Рассмотрим два примера с необходимой блокировкой и с избыточной.
Представим такую ситуацию – есть два документа «Начисление зарплаты сотрудникам организаций», в которых указан одинаковый налоговый период, а на закладке НДФЛ указаны одинаковые физлица. Гипотетически допустим, что расчет и проведение следуют один за другим в одной транзакции. Рассмотрим случай, когда блокировка вообще отсутствует. Если последовательно запускать расчет и проведение сначала одного, а затем другого документа, то в первом сумма НДФЛ посчитается правильно, а во втором будет равна нулю, т.к. расчетный и фактически начисленный НДФЛ на момент проведения второго документа будут совпадать. Но если обрабатывать эти документы параллельно, то они одновременно начислят НДФЛ, не подозревая о существовании друг друга, и в результате налог удвоится. Но если блокировка настроена верно, то первый документ успеет раньше прочитать и заблокировать данные о фактически начисленном налоге в регистре «НДФЛ расчеты с бюджетом» по сотруднику Пушкину А.С. Из этого запроса будет видно, что фактический налог за январь пока не начислялся и значит надо его рассчитать и выполнить движение по регистру. Блокировка будет отпущена только после завершения записи в регистре. Второй документ, дойдя до запроса чтения фактически начисленного налога будет поставлен системой на ожидание до тех пор, пока первый документ не закончит транзакцию проведения, после чего он прочитает в запросе, что налог уже начислен и поймет, что расчет выполнять не надо. Это необходимая блокировка.
Конечно, этот пример притянут за уши для простоты объяснения. На самом деле логика ЗУП 2.5 такова, что для задвоения НДФЛ пользователям не нужно прикладывать особых усилий. НДФЛ рассчитывается до проведения документа, а при проведении содержимое табличной части просто заносится в регистры без всякой проверки. Пользователям между расчетом и проведением предоставляется возможность посмотреть будущий результат и при необходимости поправить руками. Конечно это большой плюс в пользу гибкости ЗУПа, но предъявляет высокие требования к профессиональному уровню расчетчиков. Поэтому вопрос предотвращения задвоения НДФЛ решается организационным путем или с помощью дополнительных проверочных отчетов. Конечно, в ЗУП2.5 есть регистры, которые рассчитываются и записываются одновременно при проведении документа, например «НДФЛ к зачету», но этот пример пришлось бы дольше объяснять ;).
А теперь представим другую ситуацию. При проведении документа выполняется запрос, который должен отобрать документы, в которых присутствуют сотрудники из этого документа. Но запрос написан так, что сервер SQL вынужден находить нужные документы методом перебора. Для эксперта по технологическим вопросам это означает, что вместо INDEX SEEK выполняется TABLE SCAN, т.е. вместо поиска по таблице индексов происходит последовательный перебор записей в самой таблице. Причем в процессе перебора блокируются все записи, к которым прикоснулся запрос, даже те, в которых отсутствуют искомые сотрудники. И эта блокировка будет действовать до конца завершения проведения документа, что будет препятствовать параллельному проведению документов с другими сотрудниками. Это избыточная блокировка.
Лечение избыточных блокировок может идти двумя путями. Первый - это оптимизация запросов, выполняемых внутри транзакций и добавление необходимых табличных индексов в конфигураторе. Второй - это перевод выполнения SQL-запросов на самый низкий уровень изоляции, когда при выполнении запросов записи в таблицах блокируются только на момент выполнения самого запроса, либо не блокируются вовсе. А необходимые блокировки устанавливаются средствами объекта «БлокировкаДанных» и выполняются на стороне сервера 1С.
Теперь немного теории про уровни изоляции на SQL сервере:
- В автоматическом режиме в транзакциях используется уровень изоляции SERIALIZABLE. Этот уровень накладывает на таблицы с данными блокировку типа S (запрещает запись и проверяет нет ли в этот момент параллельных записей) до конца транзакции на все данные, которых коснулись запросы, и блокировку типа X (запрещает чтение и запись) на все данные, по которым произошла запись. На таблицы индексов также до конца транзакции накладываются блокировки типа RangeS в запросах, и RangeX при записи.
- В управляемом режиме в транзакциях используется уровень изоляции READ COMMITTED. Этот уровень на записанные данные также устанавливает блокировку типа X до конца транзакции. Но при выполнении запросов на данные накладывает блокировку типа S, а при завершении запроса блокировка снимается не дожидаясь завершения транзакции. На таблицы индексов никаких блокировок не накладывается.
- Если база данных переведена в режим READ COMMITTED SNAPSHOT, то в управляемом режиме при чтении данных не накладывается блокировка типа S, есть только блокировка типа X при записи.
Тоже самое чуть более подробно в таблице:
|
Транзакция |
Уровень изоляции |
Действие |
Блокировка |
|
Вне транзакции |
READ UNCOMMITTED |
Чтение |
- |
|
Управляемая транзакция |
READ COMMITTED SNAPSHOT |
Чтение |
- |
|
Запись |
X |
||
|
READ COMMITTED |
Чтение |
S (запрос) |
|
|
Запись |
X |
||
|
Автоматическая транзакция |
REPEATABLE READ |
Чтение объектов |
S |
|
Чтение объектов «Для изменения» |
U |
||
|
Запись объектов |
X |
||
|
SERIALIZABLE |
Чтение регистров |
S, RangeS |
|
|
Чтение регистров «Для изменения» |
U, RangeU |
||
|
Запись регистров |
X, RangeX |
Обычно лечение начинают с понижения уровня изоляции, т.к. это не особо трудозатратно и дает быстрый эффект. Достаточно перевести конфигурацию из «Автоматического» режима управления блокировкой данных в «Управляемый», и транзакции начнут выполняться на уровне изоляции типа READ COMMITTED, вместо SERIALIZABLE или REPEATABLE READ.
Чтобы переключить базу данных в режим READ COMMITTED SNAPSHOT (RCSI) необходимо в «SQL Server Management Studio» в свойствах базы данных установить параметр "Is Read Committed Snapshot On" в значение "True":
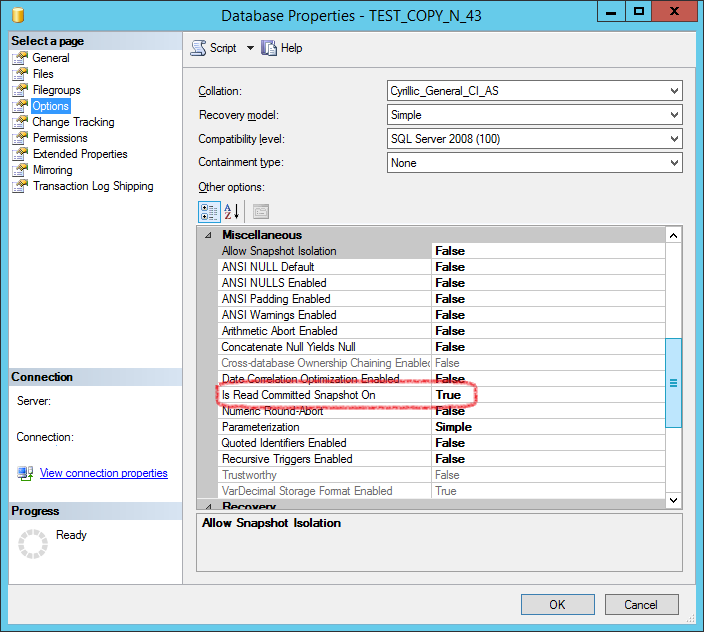
В некоторых источниках предлагают установить параметр "Allow Snapshot Isolation" в значение "True", но в этом нет необходимости, т.к. это приведет к включению другого режима изоляции SNAPSHOT, который не поддерживается платформой 1С (На момент написания статьи релиз платформы 8.3.9).
Режим управления блокировкой данных задается для неявных транзакций, которые выполняются при записи или при проведении документов, т.е. внутри предопределенных процедур типа ПриЗаписи() или ОбработкаПроведения(). Но большинство «тяжелых» вычислений в типовой конфигурации ЗУП2.5 происходит при выполнении команды «Рассчитать». При этом в модуле объекта запускается процедура РассчитатьВсе(), внутри которой неоднократно повторяется конструкция НачатьТранзакцию() …ЗафиксироватьТранзакцию(). Это явно указанные транзакции, внутри которых происходит запись и очистка регистров, выполняются запросы. Нам необходимо убедиться, что при переключении конфигурации в управляемый режим в процедуре «РассчитатьВсе()» явно указанные транзакции также начинают выполняться на уровне READ COMMITTED.
Для этого проведем небольшой эксперимент:
- Запустим SQL Server Profiler.
- Запустим «NEW TRACE».
- Выполним подключение к серверу SQL.
- В окне «Trace Properties» на закладке «General» выберем «Use the template» = «Blank», а на закладке «Events Selections» раскроем группу «Stored Procedures» и выберем «RPC:Complited». По кнопке «Column Filters» укажем имя базы и длительность выполнения запросов более 1.
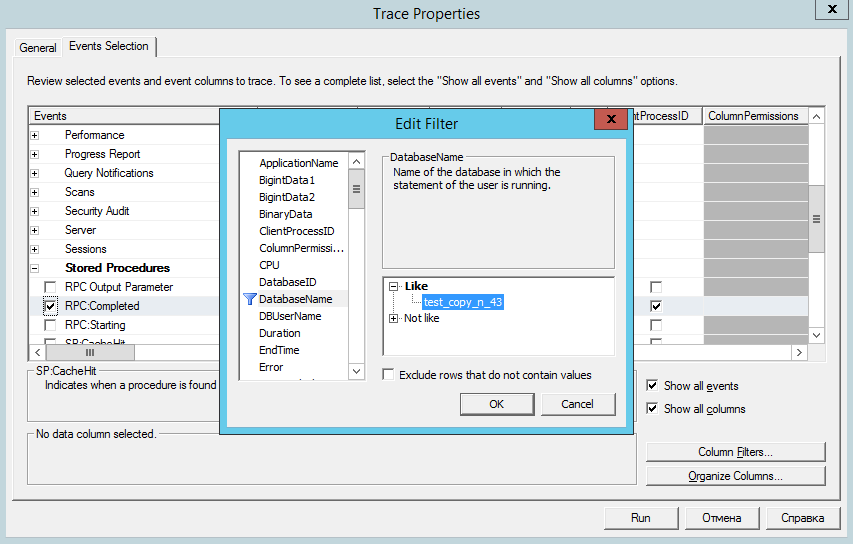
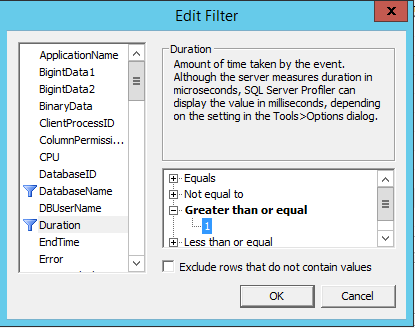
- Кнопку RUN пока нажимать не будем, т.к. нам надо сначала запустить базу данных в режиме отладки и остановить выполнение расчета документа «Начисление зарплаты сотрудникам организаций» перед выполнением самого массивного запроса. Например, это будет команда
«Результат = Запрос.ВыполнитьПакет();» в функции «ПолучитьДанныеНДФЛПоРегистратору» в общем модуле «ПроведениеРасчетов». Здесь происходит выполнение основного запроса для расчета НДФЛ. Поставим на ней точку останова отладчика и запустим расчет в документе.
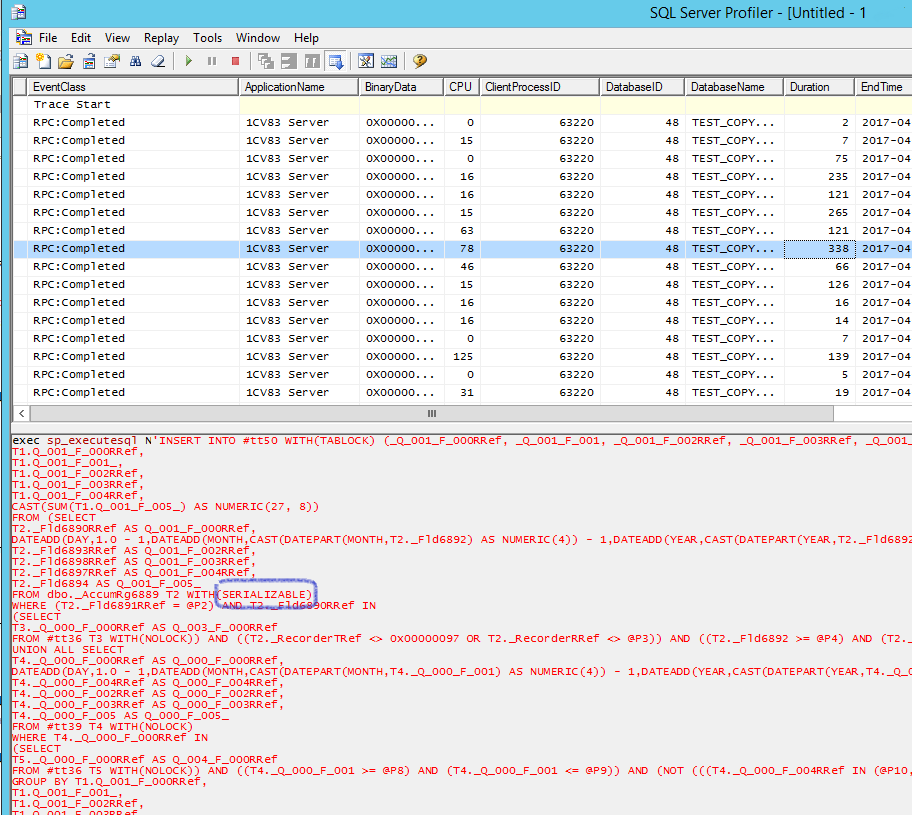
- После того как отладчик остановится, нажмем кнопку RUN в Профайлере.
- Теперь сделаем один шаг в отладчике кнопкой F11. Когда запрос будет выполнен и отладчик перейдет на следующий шаг, остановим чтение Профайлера кнопкой «Pause Selected Trace».
- Теперь найдем самый длительный запрос по колонке Duration и внимательно изучим текст запроса. Если при обращении к реальной (а не временной) таблице после слова WITH стоит SERIALIZABLE, то мы имеем дело с автоматическим режимом блокировки. Если ничего не стоит – то с управляемым.
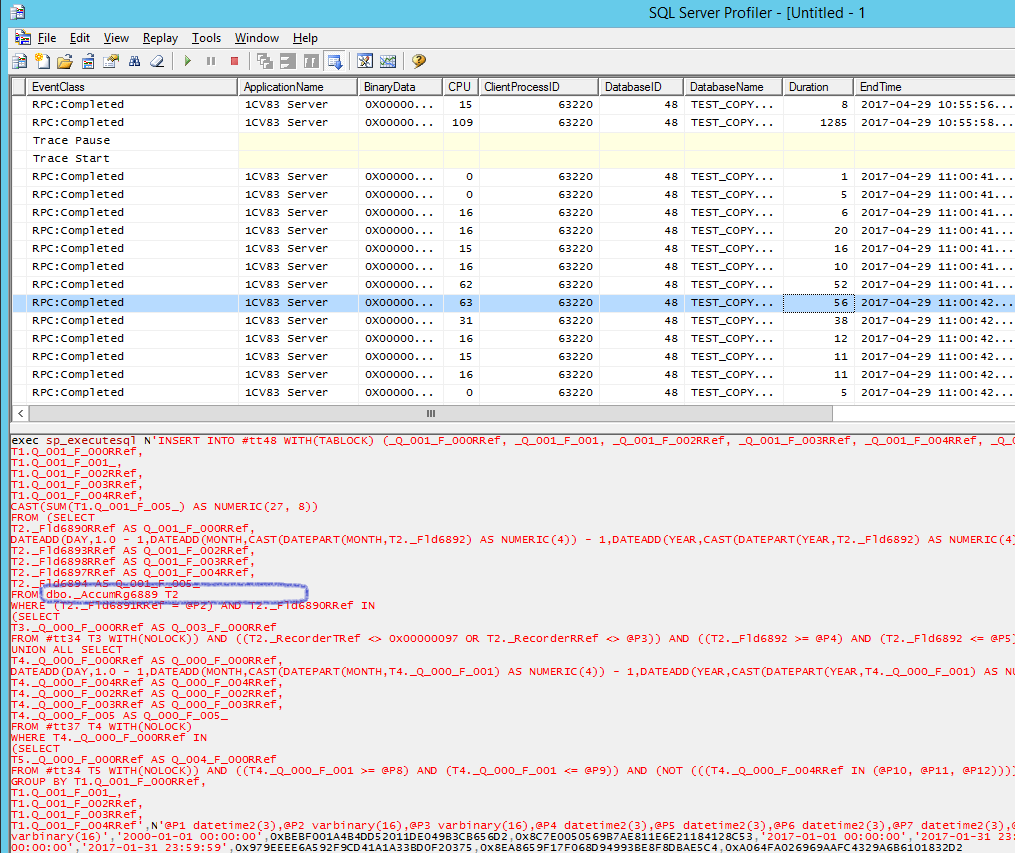
Если в хинте запроса (Hint – это параметр после слова WITH, позволяющий влиять на план выполнения запроса) не указан уровень изоляции, то выполняется уровень изоляции, установленный по умолчанию для текущей SQL-сессии. Определить уровень изоляции, действующий по умолчанию для текущих сессий можно, например, с помощью команды в «SQL Server Management Studio»:
SELECT CASE transaction_isolation_level
WHEN 0 THEN 'Unspecified'
WHEN 1 THEN 'Read Uncommitted'
WHEN 2 THEN 'Read Committed'
WHEN 3 THEN 'Repeatable'
WHEN 4 THEN 'Serializable'
WHEN 5 THEN 'Snapshot' END AS TRANSACTION_ISOLATION_LEVEL
FROM sys.dm_exec_sessions
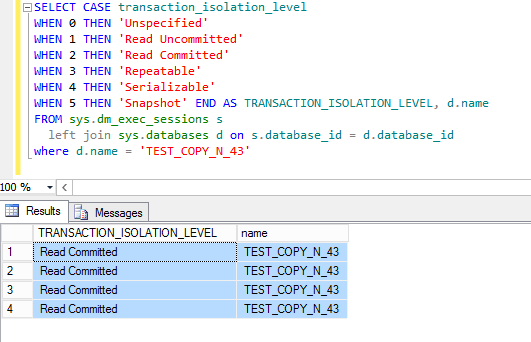
В управляемом режиме для всех сессий будет указан режим Read Committed.
Таким образом мы получили экспериментальное подтверждение того, что после перевода в управляемый режим всей конфигурации, в этом режиме начинают работать не только процедуры записи и проведения, но и процедуры расчета документов ЗУП. А это значит, что количество сообщений о конфликте блокировок будет существенно снижено, а параллельность работы с базой данных увеличится.
После того, как включили управляемый режим блокировки мы должны убедиться, что избавившись от избыточных блокировок, мы не ушли в другую крайность и не потеряли необходимые блокировки, которые защищают систему от нарушения целостности данных при активной параллельной работе пользователей.
Настройка управляемых блокировок – это тема для отдельной статьи. Вкратце скажу, что программно управляемые блокировки устанавливаются с помощью объекта «БлокировкаДанных». Сами управляемые блокировки работают уже не на уровне SQL сервера, как в случае с автоматическими блокировками, а на уровне сервера 1С. Для определения необходимых и достаточных управляемых блокировок надо понимать логику программы одновременно на уровне бизнес-процессов и на уровне архитектуры таблиц СУБД.
Но на мой взгляд, для таких конфигураций, как ЗУП2.5 вообще нет смысла использовать какие-либо блокировки, лучше использовать проверочные отчеты для выявления нарушения целостности данных - на практике это самый быстрый способ расчета зарплаты. Особенно на крупных предприятиях, где точно есть сотрудники с внутренним совмещением в обособленных подразделениях, а за каждым ОП закреплен отдельный расчетчик, что и является причиной задвоения НДФЛ. Какой бы не был вышколенный персонал, сама идеология конфигурации допускает возможность задвоения НДФЛ. Поэтому лучше не мешать пользователям работать параллельно во время массированных месячных расчетов, а по завершении точечно и быстро исправить небольшой процент ошибок, чем заставлять их сидеть и нервничать в очереди из-за страха допустить хотя бы одну ошибку. В этом проекте мы использовали самописный отчет «Проверка НДФЛ», который отображал сотрудников с некорректным НДФЛ.
Так же на этом проекте мы столкнулись с эффектом «Эскалация блокировок», когда SQL сервер сам принимает решение, что надо укрупнить область наложения блокировок вплоть до блокировки целиком всей таблицы. В результате работа пользователей останавливается, и все ждут завершения проведения одного документа – виновника эскалации, либо когда по таймауту снимутся взаимные блокировки, либо произойдет перезагрузка сервера. В каких случаях возникает эскалация и как с этим бороться тоже тема для отдельной статьи.
PS1. По многочисленным просьбам выложен упомянутый самописный отчет "Контроль НДФЛ" в отдельной статье.
