



Стек
Стек - это абстрактный тип данных, представляющий собой список элементов, организованных по принципу ЛИФО ("последним пришел - первым вышел").
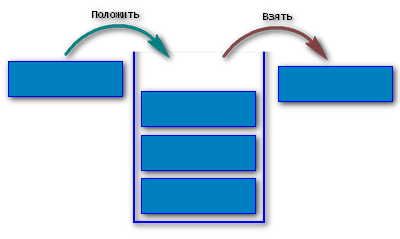
Основные операции со стеком это:
-
Push – вставка элемента наверх стека;
-
Top – получение верхнего элемента без удаления;
-
Pop – получение верхнего элемента и его удаление;
-
isEmpty – возвращает true, если стек пуст.
Для реализации стека будем использовать тип данных Массив. Реализуем вышеописанные операции:
#Область Стек
Функция Стек_Новый()
Возврат Новый Массив;
КонецФункции
// Push
Процедура Стек_Положить(Стек, Значение)
Стек.Добавить(Значение);
КонецПроцедуры
// Top
Функция Стек_ВзятьБезУдаления(Стек)
Возврат Стек[Стек.ВГраница()];
КонецФункции
// Pop
Функция Стек_Взять(Стек)
ИндексПоследнегоЭлемента = Стек.ВГраница();
Значение = Стек[ИндексПоследнегоЭлемента];
Стек.Удалить(ИндексПоследнегоЭлемента);
Возврат Значение;
КонецФункции
// isEmpty
Функция Стек_Пустой(Стек)
Возврат Стек.Количество() = 0;
КонецФункции
#КонецОбласти
Эти операции работают как в тонком так и в других клиентах.
Вроде все просто и быстро работает.
Очередь
Очередь - это абстрактный тип данных, представляющий собой список элементов, организованных по принципу ФИФО ("первый пришел - первый вышел").
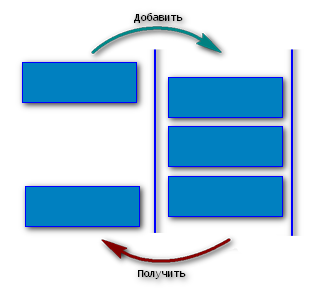
Основные операции с очередью это:
-
Добавить элемент в конец очереди;
-
Получить элемент из начала очереди (без удаления из очереди);
-
Получить элемент из начала очереди (с удалением из очереди);
-
Проверка пустая ли очередь.
Так же как и для стека будем использовать тип данных Массив. Реализуем вышеописанные операции.
#Область Очередь
Функция Очередь_Новый()
Возврат Новый Массив;
КонецФункции
Процедура Очередь_Добавить(Очередь, Значение)
Очередь.Добавить(Значение);
КонецПроцедуры
Функция Очередь_ПолучитьБезУдаления(Очередь)
Возврат Очередь[0];
КонецФункции
Функция Очередь_Получить(Очередь)
Значение = Очередь[0];
Очередь.Удалить(0);
Возврат Значение;
КонецФункции
Функция Очередь_Пустой(Очередь)
Возврат Очередь.Количество() = 0;
КонецФункции
#КонецОбласти
Здесь тоже все просто, но что по скорости? Поскольку отличие в только в способе получения элемента данных, то сравним скорость работы функции Очередь_Получить(Очередь) с Стек_Взять(Стек). Замеры производительности показали:
| Строка кода | 10 000 элементов | 50 000 элементов | 100 000 элементов | |||
| Время чистое | % | Время чистое | % | Время чистое | % | |
| Стек (Стек_Взять(Стек)) | 0,170986 | 43,97 | 0,877694 | 21,25 | 1,703886 | 14,30 |
| ИндексПоследнегоЭлемента = Стек.ВГраница(); | 0,064098 | 16,48 | 0,330289 | 8,00 | 0,639357 | 5,37 |
| Значение = Стек[ИндексПоследнегоЭлемента]; | 0,047934 | 12,33 | 0,244083 | 5,91 | 0,475707 | 3,99 |
| Стек.Удалить(ИндексПоследнегоЭлемента); | 0,058954 | 15,16 | 0,303322 | 7,34 | 0,588822 | 4,94 |
| Очередь (Очередь_Получить(Очередь)) | 0,217842 | 56,03 | 3,253449 | 78,75 | 10,2105 | 85,70 |
| Значение = Очередь[0]; | 0,058589 | 15,07 | 0,333911 | 8,08 | 0,535987 | 4,50 |
| Очередь.Удалить(0); | 0,159253 | 40,96 | 2,919538 | 70,67 | 9,674513 | 81,20 |
| Итого | 0,388828 | 100,00 | 4,131143 | 100,00 | 11,914386 | 100,00 |
Динамика ожидаемая. Поскольку при получении элемента очереди из массива удаляется нулевой элемент, то и работает это дольше из-за того, что массив каждый раз "сдвигает" индексы. Но оказалось, что в 1С метод массива ВГраница() "не дешевый".
Если размер очереди не превышает 10 000 элементов, то разница в скорости между очередью и стеком не заметна, т.е. такая реализация Очереди работает также быстро как и Стек. В остальном же, чем больше элементов в очереди, тем медленнее будет работать операция получения. А что делать, если у нас могут быть очереди огромных размеров? Способ известен, избавляемся от удаления нулевого элемента в массиве и у нас получается следующее:
#Область Очередь
Функция Очередь_Новый()
Возврат Новый Структура("Данные, Голова, Хвост", Новый Массив, 0, 0)
КонецФункции
Процедура Очередь_Добавить(Очередь, Значение)
Очередь.Данные.Добавить(Значение);
Очередь.Хвост = Очередь.Хвост + 1;
КонецПроцедуры
Функция Очередь_ПолучитьБезУдаления(Очередь)
Возврат Очередь.Данные[Очередь.Голова];
КонецФункции
Функция Очередь_Получить(Очередь)
Значение = Очередь.Данные[Очередь.Голова];
Очередь.Голова = Очередь.Голова + 1;
Возврат Значение;
КонецФункции
Функция Очередь_Пустой(Очередь)
Возврат Очередь.Голова = Очередь.Хвост;
КонецФункции
#КонецОбласти
Сравним скорость работы со стектом
| Строка кода | 10 000 элементов | 50 000 элементов | 100 000 элементов | |||
| Время чистое | % | Время чистое | % | Время чистое | % | |
| Стек | 0,330505 | 43,37 | 1,633625 | 44,14 | 3,288941 | 43,81 |
| Возврат Новый Массив; | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000015 | 0,00 |
| Стек.Добавить(Значение); | 0,069462 | 9,11 | 0,340238 | 9,19 | 0,680083 | 9,06 |
| ИндексПоследнегоЭлемента = Стек.ВГраница(); | 0,063925 | 8,39 | 0,321949 | 8,70 | 0,649467 | 8,65 |
| Значение = Стек[ИндексПоследнегоЭлемента]; | 0,047449 | 6,23 | 0,239641 | 6,47 | 0,477748 | 6,36 |
| Стек.Удалить(ИндексПоследнегоЭлемента); | 0,05953 | 7,81 | 0,29952 | 8,09 | 0,597924 | 7,96 |
| Возврат Стек.Количество() = 0; | 0,090125 | 11,83 | 0,432263 | 11,68 | 0,883704 | 11,77 |
| Очередь | 0,431625 | 56,63 | 2,067537 | 55,86 | 4,219035 | 56,19 |
| Возврат Новый Структура("Данные, Голова, Хвост", Новый Массив, 0, 0) | 0,000054 | 0,01 | 0,000046 | 0,00 | 0,000049 | 0,00 |
| Очередь.Данные.Добавить(Значение); | 0,09672 | 12,69 | 0,442808 | 11,96 | 0,943409 | 12,57 |
| Очередь.Хвост = Очередь.Хвост + 1; | 0,096046 | 12,60 | 0,4312 | 11,65 | 0,857976 | 11,43 |
| Значение = Очередь.Данные[Очередь.Голова]; | 0,075233 | 9,87 | 0,37646 | 10,17 | 0,752637 | 10,02 |
| Очередь.Голова = Очередь.Голова + 1; | 0,083533 | 10,96 | 0,418471 | 11,31 | 0,835261 | 11,12 |
| Возврат Очередь.Голова = Очередь.Хвост; | 0,080039 | 10,50 | 0,398552 | 10,77 | 0,829703 | 11,05 |
| Итого | 0,76213 | 100,00 | 3,701162 | 100,00 | 7,507976 | 100,00 |
Конечно, очередь все равно работает чуть медленнее стека, но разница не так заметна и она уже не растет при размере более 10 000. Но у нас растет размер массива.
Приоритетная очередь
Приоритетная очередь — это абстрактная структура данных, где у каждого элемента есть приоритет. Элемент с более высоким приоритетом находится перед элементом с более низким приоритетом. Если у элементов одинаковые приоритеты, они располагаются в зависимости от своей позиции в очереди.

Очередь с приоритетом использует такие же операции что и обычная очередь:
-
Добавить элемент в конец очереди;
-
Получить элемент из начала очереди (без удаления из очереди);
-
Получить элемент из начала очереди (с удалением из очереди);
-
Проверка пустая ли очередь.
Какой же тип выбрать для этой структуры данных? Теперь наряду с элементом, необходимо хранить приоритет. Простым способом будет выбрать тип, у которого есть методы сортировки. Очевидно, что массив не подойдет. Что мы имеем:
- Соответствие - при добавлении элемента сортирует данные по ключу, но ключ должен быть уникальным. Нам не подходит, потому как могут быть элементы с одинаковым приоритетом. На самом деле можно сделать ключ уникальным и "правильным" для нас образом сортируемым. Но сейчас я не буду рассматривать его как претендента для реализации приоритетной очереди.
- ТаблицаЗначений - есть метод Сортировать(), а также можно добавлять сколь угодно колонок. Подходит, но есть ограничение - не работает в тонком клиенте.
- СписокЗначений - есть методы СортироватьПоПредставлению() и СортироватьПоЗначению(). Подходит, работает как в тонком, так и в других клиентах.
Поскольку метод сортировки может занимать много времени, то заранее продумаем способ лишний раз его не вызывать. Так же обратим внимание на то, что элементы с одинаковым приоритетом должны располагаться в зависимости от своей позиции в очереди, а методы сортировки таблицы значений и списка значений такого делать не умеют. После сортировки элементов с одинаковым приоритетом позиции будут "случайными". Поэтому нам необходимо хранить позцию в очереди и производить сортировку по ней тоже.
Реализуем приоритетную очередь используя тип ТаблицаЗначений:
#Область ПриоритетнаяОчередь_ТаблицаЗначений
Функция ПриоритетнаяОчередь_Новый()
Очередь = Новый Структура;
Очередь.Вставить("Отсортировано", Истина);
Очередь.Вставить("Данные", Новый ТаблицаЗначений);
Очередь.Данные.Колонки.Добавить("Значение");
Очередь.Данные.Колонки.Добавить("Приоритет", Новый ОписаниеТипов("Число"));
Очередь.Данные.Колонки.Добавить("Позиция", Новый ОписаниеТипов("Число"));
Очередь.Вставить("Позиция", 0);
Возврат Очередь;
КонецФункции
Процедура ПриоритетнаяОчередь_Добавить(Очередь, Значение, Приоритет)
Очередь.Отсортировано = Ложь;
НоваяСтрока = Очередь.Данные.Добавить();
НоваяСтрока.Значение = Значение;
НоваяСтрока.Приоритет = Приоритет;
НоваяСтрока.Позиция = Очередь.Позиция + 1;
Очередь.Позиция = НоваяСтрока.Позиция;
КонецПроцедуры
Функция ПриоритетнаяОчередь_ПолучитьБезУдаления(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.Сортировать("Приоритет, Позиция");
КонецЕсли;
Возврат Данные[0].Значение;
КонецФункции
Функция ПриоритетнаяОчередь_Получить(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.Сортировать("Приоритет, Позиция");
КонецЕсли;
Значение = Данные[0].Значение;
Данные.Удалить(0);
Возврат Значение;
КонецФункции
Функция ПриоритетнаяОчередь_Пустой(Очередь)
Возврат Очередь.Данные.Количество() = 0;
КонецФункции
#КонецОбласти
Стоит отметить, что удаление строки из таблицы значений по нулевому индексу работает немного быстрее, чем удаление последней строки. Т.е. таблица значенией не имеет проблемы "сдвигов" индекса. Таблица значений похожа на структуру данных Связанный список.
Далее реализуем приоритетную очередь на списке значений и уже там сравним скорость работы.
Реализуем приоритетную очередь используя тип СписокЗначений:
В Списке значений для хранения Приоритета будем использовать Представление. И вот здесь наталкиваемся на ограничение - Представление имеет тип Строка, а Приоритет у нас Число. Таким образом Приоритет из Числа преобразуется в Строку и метод СортироватьПоПредставлению() неправильно будет работать для нашей цели (например строки 1, 2, 10, 20, 100, 200 будут упорядочены сделующим образом 1, 10, 100, 2, 20, 200). Чтобы добиться "правильной" сортировки нам необходимо число привести в соответствующий строковый вид, например, числа 1, 2, 10, 20, 100, 200 приводим к строкам 001, 002, 010, 020, 100, 200. Для этого нам необхомо с определиться с длиной (разрядностью) и "дорисовать" лидирующие нули. Длина влияет на скорость сортировки, поэтому будем реализовывать так, чтобы можно было заранее указать разрядность. Вспоминаем еще один момент со "сдвигами" индексов, список значений эту "проблему" имеет, поэтому сортируем по убыванию, а получаем элемент сверху. В результате получаем следующее:
#Область ПриоритетнаяОчередь_СписокЗначений
&НаКлиенте
Функция ПриоритетнаяОчередь_Новый(РазрядностьПриоритета = 16, РазрядностьПозиции = 16)
Очередь = Новый Структура;
Очередь.Вставить("Отсортировано", Истина);
Очередь.Вставить("Данные", Новый СписокЗначений);
Очередь.Вставить("ФорматнаяСтрокаПриоритета", "ЧЦ=" + РазрядностьПриоритета + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("ФорматнаяСтрокаПозиции", "ЧЦ=" + РазрядностьПозиции + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("Позиция", 0);
Возврат Очередь;
КонецФункции
&НаКлиенте
Процедура ПриоритетнаяОчередь_Добавить(Очередь, Значение, Приоритет)
Очередь.Отсортировано = Ложь;
Очередь.Позиция = Очередь.Позиция + 1;
ПриоритетСтрока = Формат(Приоритет, Очередь.ФорматнаяСтрокаПриоритета) + Формат(Очередь.Позиция, Очередь.ФорматнаяСтрокаПозиции);
Очередь.Данные.Добавить(Значение, ПриоритетСтрока);
КонецПроцедуры
&НаКлиенте
Функция ПриоритетнаяОчередь_ПолучитьБезУдаления(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.СортироватьПоПредставлению(НаправлениеСортировки.Убыв);
КонецЕсли;
ИндексПоследнегоЭлемента = Данные.Количество() - 1;
Возврат Данные[ИндексПоследнегоЭлемента].Значение;
КонецФункции
&НаКлиенте
Функция ПриоритетнаяОчередь_Получить(Очередь)
Данные = Очередь.Данные;
Если Не Очередь.Отсортировано Тогда
Очередь.Отсортировано = Истина;
Данные.СортироватьПоПредставлению(НаправлениеСортировки.Убыв);
КонецЕсли;
ИндексПоследнегоЭлемента = Данные.Количество() - 1;
Значение = Данные[ИндексПоследнегоЭлемента].Значение;
Данные.Удалить(ИндексПоследнегоЭлемента);
Возврат Значение;
КонецФункции
&НаКлиенте
Функция ПриоритетнаяОчередь_Пустой(Очередь)
Возврат Очередь.Данные.Количество() = 0;
КонецФункции
#КонецОбласти
Если удобней передавать максимальное число, а не разрядность то фукнция ПриоритетнаяОчередь_Новый() будет выглядеть так:
&НаКлиенте
Функция ПриоритетнаяОчередь_Новый(МаксимальноеЧислоПриоритета = Неопределено, МаксимальноеЧислоПозиции = Неопределено)
РазрядностьПриоритета = ?(МаксимальноеЧислоПриоритета = Неопределено, 16, СтрДлина(Формат(МаксимальноеЧислоПриоритета, "ЧГ=0")));
РазрядностьПозиции = ?(МаксимальноеЧислоПозиции = Неопределено, 16, СтрДлина(Формат(МаксимальноеЧислоПозиции, "ЧГ=0")));
Очередь = Новый Структура;
Очередь.Вставить("Отсортировано", Истина);
Очередь.Вставить("Данные", Новый СписокЗначений);
Очередь.Вставить("ФорматнаяСтрокаПриоритета", "ЧЦ=" + РазрядностьПриоритета + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("ФорматнаяСтрокаПозиции", "ЧЦ=" + РазрядностьПозиции + "; ЧН=; ЧВН=; ЧГ=0");
Очередь.Вставить("Позиция", 0);
Возврат Очередь;
КонецФункции
Сравним обе реализиции приоритетной очереди по скорости:
| Строка кода | 10 000 элементов | 50 000 элементов | 100 000 элементов | |||
| Время чистое | % | Время чистое | % | Время чистое | % | |
| Приоритетная очередь (таблица значений) | 1,1063 | 35,81 | 6,100376 | 37,26 | 12,214519 | 37,28 |
| Очередь = Новый Структура; | 0,000014 | 0,00 | 0,000013 | 0,00 | 0,000014 | 0,00 |
| Очередь.Вставить("Отсортировано", Истина); | 0,000023 | 0,00 | 0,000022 | 0,00 | 0,000022 | 0,00 |
| Очередь.Вставить("Данные", Новый ТаблицаЗначений); | 0,000025 | 0,00 | 0,000023 | 0,00 | 0,000024 | 0,00 |
| Очередь.Данные.Колонки.Добавить("Значение"); | 0,000049 | 0,00 | 0,000071 | 0,00 | 0,000046 | 0,00 |
| Очередь.Данные.Колонки.Добавить("Приоритет", Новый ОписаниеТипов("Число")); | 0,000049 | 0,00 | 0,000049 | 0,00 | 0,000048 | 0,00 |
| Очередь.Данные.Колонки.Добавить("Позиция", Новый ОписаниеТипов("Число")); | 0,00004 | 0,00 | 0,000041 | 0,00 | 0,000041 | 0,00 |
| Очередь.Вставить("Позиция", 0); | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000014 | 0,00 |
| Очередь.Отсортировано = Ложь; | 0,059319 | 1,92 | 0,296483 | 1,81 | 0,599376 | 1,83 |
| НоваяСтрока = Очередь.Данные.Добавить(); | 0,128262 | 4,15 | 0,758155 | 4,63 | 1,073491 | 3,28 |
| НоваяСтрока.Значение = Значение; | 0,066091 | 2,14 | 0,332992 | 2,03 | 0,672613 | 2,05 |
| НоваяСтрока.Приоритет = Приоритет; | 0,060047 | 1,94 | 0,305085 | 1,86 | 0,610112 | 1,86 |
| НоваяСтрока.Позиция = Очередь.Позиция + 1; | 0,098084 | 3,17 | 0,461481 | 2,82 | 0,903573 | 2,76 |
| Очередь.Позиция = НоваяСтрока.Позиция; | 0,060872 | 1,97 | 0,298918 | 1,83 | 0,616223 | 1,88 |
| Данные = Очередь.Данные; | 0,06077 | 1,97 | 0,305511 | 1,87 | 0,603819 | 1,84 |
| Если Не Очередь.Отсортировано Тогда | 0,050897 | 1,65 | 0,252758 | 1,54 | 0,499659 | 1,52 |
| Очередь.Отсортировано = Истина; | 0,000004 | 0,00 | 0,000005 | 0,00 | 0,000004 | 0,00 |
| Данные.Сортировать("Приоритет, Позиция"); | 0,127592 | 4,13 | 1,042711 | 6,37 | 2,588318 | 7,90 |
| КонецЕсли; | 0,029566 | 0,96 | 0,148514 | 0,91 | 0,290742 | 0,89 |
| Значение = Данные[0].Значение; | 0,10961 | 3,55 | 0,583075 | 3,56 | 1,152302 | 3,52 |
| Данные.Удалить(0); | 0,142949 | 4,63 | 0,738205 | 4,51 | 1,485553 | 4,53 |
| Возврат Очередь.Данные.Количество() = 0; | 0,112023 | 3,63 | 0,57625 | 3,52 | 1,118525 | 3,41 |
| Приоритетная очередь (список значений) | 1,983387 | 64,19 | 10,273666 | 62,74 | 20,553372 | 62,72 |
| Очередь = Новый Структура; | 0,000016 | 0,00 | 0,000016 | 0,00 | 0,000025 | 0,00 |
| Очередь.Вставить("Отсортировано", Истина); | 0,000022 | 0,00 | 0,000023 | 0,00 | 0,000024 | 0,00 |
| Очередь.Вставить("Данные", Новый СписокЗначений); | 0,000019 | 0,00 | 0,000019 | 0,00 | 0,000019 | 0,00 |
|
Очередь.Вставить("ФорматнаяСтрокаПриоритета", "ЧЦ=" + РазрядностьПриоритета + "; ЧН=; ЧВН=; ЧГ=0"); |
0,000063 | 0,00 | 0,000052 | 0,00 | 0,000051 | 0,00 |
| Очередь.Вставить("ФорматнаяСтрокаПозиции", "ЧЦ=16; ЧН=; ЧВН=; ЧГ=0"); | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000014 | 0,00 |
| Очередь.Вставить("Позиция", 0); | 0,000014 | 0,00 | 0,000014 | 0,00 | 0,000014 | 0,00 |
| Очередь.Отсортировано = Ложь; | 0,056188 | 1,82 | 0,284132 | 1,74 | 0,560949 | 1,71 |
| Очередь.Позиция = Очередь.Позиция + 1; | 0,104786 | 3,39 | 0,443424 | 2,71 | 0,866142 | 2,64 |
|
ПриоритетСтрока = Формат(Приоритет, Очередь.ФорматнаяСтрокаПриоритета)+ Формат(Очередь.Позиция, Очередь.ФорматнаяСтрокаПозиции); |
0,951056 | 30,78 | 4,927951 | 30,10 | 9,781007 | 29,85 |
| Очередь.Данные.Добавить(Значение, ПриоритетСтрока); | 0,125726 | 4,07 | 0,630631 | 3,85 | 1,257842 | 3,84 |
| Данные = Очередь.Данные; | 0,052208 | 1,69 | 0,261573 | 1,60 | 0,51975 | 1,59 |
| ИндексПоследнегоЭлемента = Данные.Количество() - 1; | 0,092614 | 3,00 | 0,508852 | 3,11 | 0,949622 | 2,90 |
| Если Не Очередь.Отсортировано Тогда | 0,049787 | 1,61 | 0,239129 | 1,46 | 0,478487 | 1,46 |
| Очередь.Отсортировано = Истина; | 0,000005 | 0,00 | 0,000005 | 0,00 | 0,000005 | 0,00 |
| Данные.СортироватьПоПредставлению(НаправлениеСортировки.Убыв); | 0,1789 | 5,79 | 1,101879 | 6,73 | 2,400442 | 7,33 |
| КонецЕсли; | 0,027553 | 0,89 | 0,134654 | 0,82 | 0,271737 | 0,83 |
| Значение = Данные[ИндексПоследнегоЭлемента].Значение; | 0,069322 | 2,24 | 0,344562 | 2,10 | 0,690922 | 2,11 |
| Данные.Удалить(ИндексПоследнегоЭлемента); | 0,159925 | 5,18 | 0,774589 | 4,73 | 1,612728 | 4,92 |
| Возврат Очередь.Данные.Количество() = 0; | 0,115169 | 3,73 | 0,622147 | 3,80 | 1,163592 | 3,55 |
| Итого | 3,089687 | 100,00 | 16,374042 | 100,00 | 32,767891 | 100,00 |
Важное замечание - метод сортировки во всех случаях запускался 1 раз. Сначала набиралась очередь до нужного количества элементов (10 000, 50 000 или 100 000), а потом при при первом получении происходила сортировка. Как видим, что сортировка занимает не мало времени.
У списка значений большую часть времени зняло вычисление проиоритета - перевода чисел в строку. При тестировнии я не указывал разрядность и она по умолчанию была 16, т.е. длина сортировочной строки была 32 символа (16 приоритет и 16 позиция в очереди). В тестируемых примерах я мог указать разрядность 6 и тогда сортировочная строка была бы 12 символов, что, в свою очередь, должно положительно сказаться на сортировке (а может еще и на вычислении приоритетной строки).
ПС: тесты проводились на платформе 1С 8.3.10 в файловом режиме и на процессоре Core 2 Duo 2,33GHz. И соответственно, при тестировании на другом компьютере чистое время будет другим, но процентное соотношение должно остаться прежним.
ПСС: Конструктивная критика приветствуется.
Обновлено: избавился в коде от конструкции Попытка - Исключение. Считаю, что проверка на пустую коллекцию лишняя, потому как у каждой структуры данных есть метод Пустой(), которым и должен пользоваться разработчик.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}