Сегодня я хочу рассказать про TRUE-разработку, про то, как мы разрабатываем в EDT:
-
Немного расскажу про конфигуратор и EDT – как мы переходили, какие нюансы были;
-
EDT + GIT;
-
Расскажу о вариантах процесса командной разработки;
-
Про тестирование;
-
И в конце приведу немного полезной информации.
Что такое EDT? Первое впечатление
EDT – это надстройка над Eclipse, написанная на Java. Использование этой среды имеет определенные плюсы и минусы. С одной стороны, все прекрасно знают старый добрый проверенный конфигуратор, у которого есть свои «скелеты в шкафу». А с другой стороны, выступает новая среда разработки со своими новыми возможностями и перспективами.
Некоторые разработчики настороженно смотрят на EDT, боятся его. Тем не менее, в EDT есть та же структура конфигурации и даже лучше – вы можете загрузить несколько проектов. Там есть тот же редактор форм, тот же конструктор запроса, вы можете редактировать те же модули объекта и модули менеджера. Достаточно два-три дня, и вы сможете в нем разрабатывать. Это похоже на то, как вы пересаживаетесь с машины, где установлена механическая коробка передач на автоматическую. Вроде все то же самое, но немного по-другому.
Однако есть свои нюансы: в конфигураторе было хранилище, а в EDT есть очень мощный и классный механизм распределенной системы управления версиями – Git. Как только возможность командной разработки через Git в EDT была анонсирована, мы сразу поняли, что это – наше, и мы должны здесь разрабатывать. Тем более, что 1С активно продвигает и разрабатывает этот новый инструмент.

Что думает сообщество? Я провел некоторый опрос – в основном, все относятся настороженно и пока что выжидают. Одна из существующих проблем заключается в том, что 1С только недавно выложила какие-то обучающие материалы о том, как с работать с EDT, и пояснила некоторые нюансы разработки.

Что думаем про EDT мы?
Для нас это удобно. Управляемость процессом разработки – супер. Особенно с учетом того, что у нас в компании есть как локальные, так и удаленные сотрудники, использование возможностей EDT – большой плюс.

Немного про то, чего в EDT нам не хватает?
Есть проблемы неполноценной поддержки функциональности конфигуратора, это обещали исправить еще в версии 1.9. Сейчас ждем 2.0 (а скорее всего 3.0), чтобы наконец-то работать полноценно.
Пока еще мало плагинов. Если взять другие языки, которые поддерживаются в среде разработки Eclipse, то там очень много разных готовых инструментов – очень удобных и “приятных”.
Процесс перехода на EDT. С чего мы начали?

Первый вопрос, который возник у нас по поводу нового инструмента – как обучить сотрудников порядку работы с ним? Как в нем работать? Поскольку видеоуроки по работе в EDT начали появляться только сейчас, а когда мы переходили, их еще не было, то решили стартовать с пилотного проекта. Выделили пилотный проект, выделили пилотных разработчиков, назначили ответственное лицо для контроля и управления процессом разработки в среде EDT. И запустили процедуру внедрения. И через некоторое время на базе удачного опыта мы подключили к этому процессу других разработчиков – таким образом мы вовлекли практически весь коллектив.

У нас есть как удаленные, так и локальные разработчики, и, поскольку в процессе перехода возникали нюансы, нам нужно было осуществлять обмен мнениями. Для этого мы организовывали вебинары и локальные обсуждения средствами Webex, Skype и Microsoft Teams.
По итогам успеха пилотного проекта я организовал вебинар для остальных сотрудников. И после обсуждения у большинства из них «загорелись глаза».
Какие преимущества дает использование Git при разработке в EDT?

Хранилище – это система с пессимистическими блокировками, которая по умолчанию считает, что все будет плохо, и не позволяет работать с объектом более чем одному разработчику. А поскольку у нас большая компания с большим количеством процессов, “иногда” несколько разработчиков хотят работать с одним и тем же объектом одновременно – но нельзя. Даже если это как-то распараллелить – все равно, эта ситуация возникает довольно часто. Думаю, с такой же проблемой сталкивается большинство из присутствующих.
Соответственно, когда мы рассматриваем Git – то в нем уже используется оптимистическая система блокировок. Это значит, что она считает, что все будет хорошо, а если и возникнут какие-то проблемы, то они будут решены в конце, когда мы будем осуществлять слияние.

Какие средства командной разработки мы можем использовать совместно с Git?
Есть хранилища в облаках – GitHub, ButBucket, GitLab и т.д. – они здесь приведены в порядке уменьшения популярности.
Плюс вы можете использовать как локальное хранилище 1С, так и локальный Git-сервер. Мы используем GitHub, BitBucket и еще локальный Git-сервер внутри.
Варианты организации процесса разработки с помощью Git
Если у вас нет хранилища, нет порядка работы – ваш процесс разработки выглядит с моей стороны очень странно, очень плохо, по принципу «И так сойдет».

Что нужно сделать, чтобы было правильно и хорошо?
Нужно ввести правила внесения изменений. Без правил – бардак. Непонятно, что, откуда брать, как мержить изменения – кто-то описывает реализованные задачи в Excel, кто-то в письмах по почте, кто-то на бумажке – даже на столе на пыли пишет. Это неправильно. Необходимо использовать правила разработки внутри команды. Это касается как больших, так и маленьких команд.
Мы выделяем три самых популярных процесса разработки. Есть еще четвертый, который называется 1C-flow, про него вы можете почитать на сайте «1С:ИТС», я о нем рассказывать не буду.
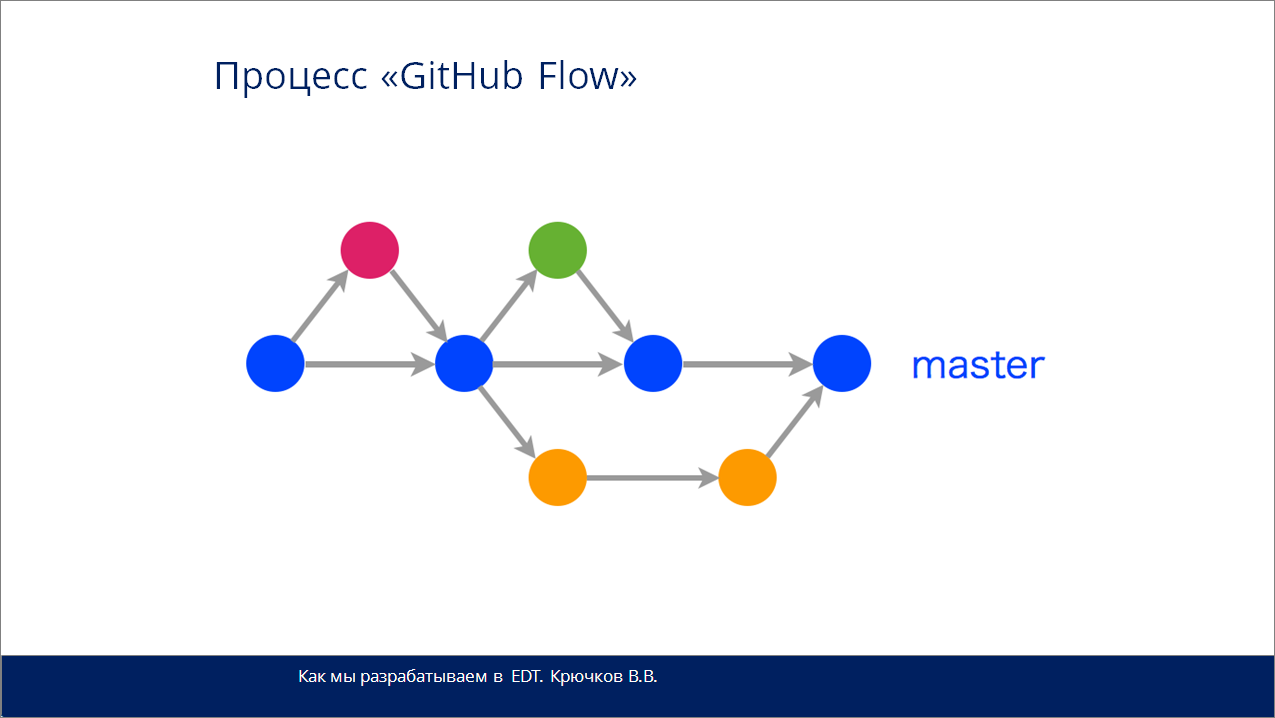
Наиболее простой процесс разработки – это “GitHub Flow”. Основное его назначение – это с максимальной скоростью донести изменения в Production.
Здесь у нас с вами есть основная ветка “master” - эта ветка (фактически для всех схем) должна иметь рабочий код. Если по каким-то причинам код в ней стал не рабочим, то часто делают откат на предыдущую версию. Из нее отпочковываются (выходят) ветки равные решаемым задачам (feature-ветки), которые в конце разработки сливаются обратно в ветку master. В результате вы получаете готовые релизы каждый раз при коммите.
Недостаток этого процесса в том, что он является наименее управляемым с точки зрения большой компании и большого продукта уровня ERP. Его, в основном, используют в OpenSource-проектах и, как сказано было ранее, если требуется наибыстрейшее внесение доработок в конечный продукт.
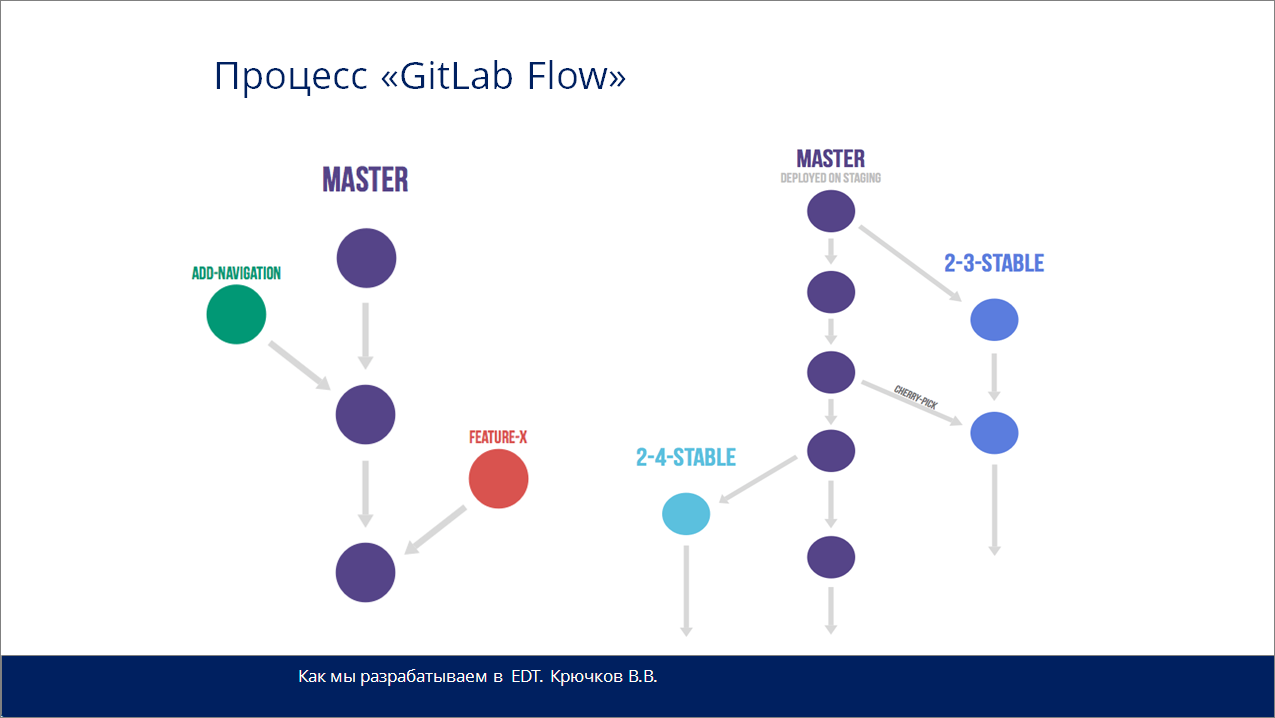
Следующий процесс разработки – это “GitLab Flow”. Он немного отличается от “GitHub Flow” тем, что у вас появляются версии со стабильными релизами.
Приведу пример – у 1С есть версии 8.2, 8.3, 8.4. Все изменения также помещаются в ветку master (где у вас Production). А в случае выпуска какого-то стабильного релиза – версии 2.3, 2.4, получается вечноживущая ветка релиза. Она больше не разрабатывается, вы можете поместить туда только какие-то супернужные исправления с помощью cherry-pick.
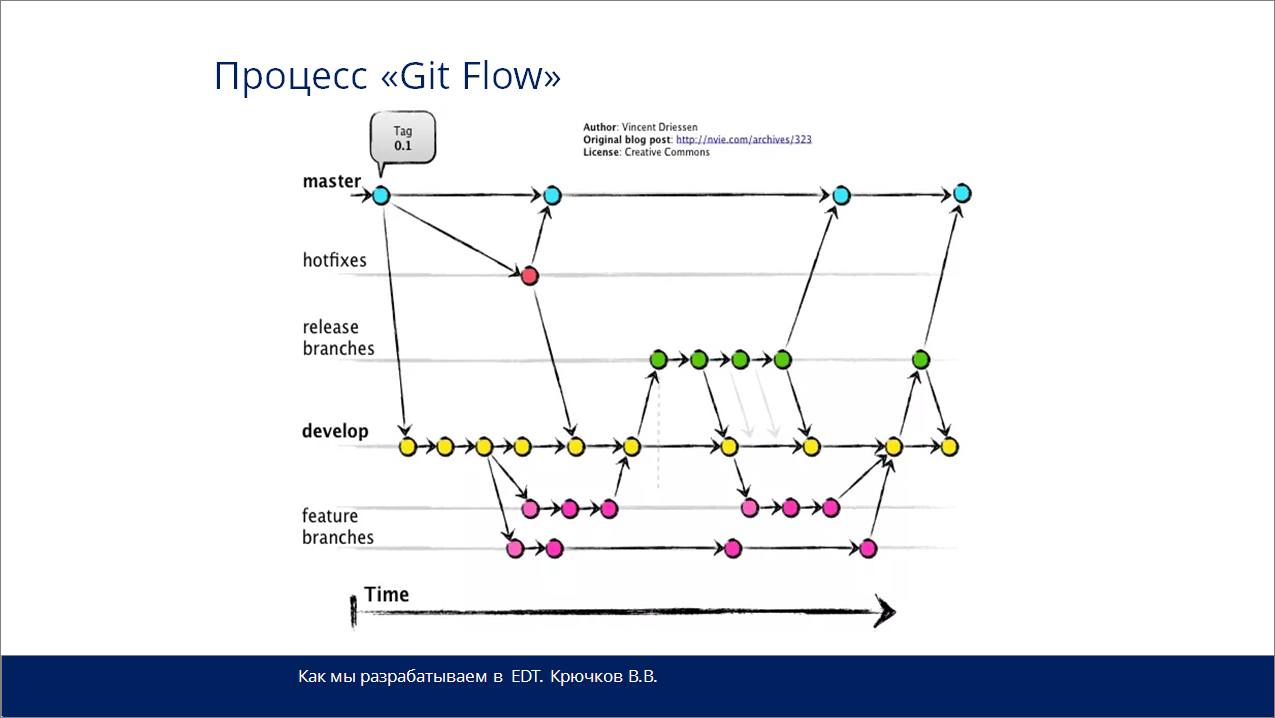
И, наконец, самый сложный и “правильный” процесс управления – это “GitFlow”.
-
Здесь у вас есть ветка master – основная ветка продукта. В ней всегда расположен работающий код.
-
И есть ветка develop – ветка разработки, где вы сливаете решение всех задач по текущему релизу - ведется процесс разработки.
-
Как только вы определились, что выпускаете релиз для вашего проекта (все задачи завершены), то вы завершаете фактическую работу с веткой develop и формируете из нее ветку релиза. Тут проводите тестирование и вносите исправления, т.е. добиваетесь полноценного рабочего кода. В случае успеха:
-
ветка релиза сливается в ветку master;
-
и также автоматически ею заменяется ветка develop.
-
-
Если у вас внезапно появляются какие-то серьезные баги после релиза, вы что-то упустили (как всегда “накосячили”), то вы из ветки master создаете новую ветку hotfix, исправляете, проверяете. А затем это исправление возвращаете синхронно в ветку master, и в ветку develop.
Рекомендации при работе с Git

А теперь – основные нюансы, которые следует обязательно соблюдать:
-
Первое – master-ветка (ваш Production) всегда должна быть работоспособна. Какой бы коммит вы не взяли, он всегда должен быть работоспособен.
-
Имя ветки = номер задачи + понятное краткое наименование. Если вы используете систему багтрекинга (учета задач, управления задачами), то при создании feature-ветки в ее имя нужно добавлять номер задачи. После этого вы сможете легко понять, что это за задача решалась.
-
Используйте тайники (stash) - это очень удобная и практичная вещь. Приведу пример, что насколько это удобно. Допустим, вы разрабатываете какую-то задачу, и в этот момент к вам приходят с жалобами на ошибку в Production, для которой нужно срочно сделать хотфикс. Чтобы сохранить свои незакоммиченные изменения по задаче перед переключением на другую ветку, их нужно куда-нибудь скопировать или удалить (заметьте, мы не делаем commit, не помещаем в ветку что-то неработающее, плохое). Здесь нам на помощь приходит «тайник» – с помощью команды git stash мы все эти изменения сохраняем, делаем хотфикс в ветку master, а потом возвращаемся, берем наши изменения из «тайника» и спокойно продолжаем работу. Это удобно.
-
Доверяй, но проверяй. Обычно процесс работы построен по системе багтрекинга (управления задачами) и вы разработчику доверяете. Однако, как известно, «доверяй, но проверяй», поэтому я рекомендую использовать возможности облачных хранилищ:
-
Используйте pull-request’ы, чтобы исключить непосредственные коммиты в master-ветку.
-
Требуйте проведения code-review для pull-request’ов. Мой совет – обязательно проводите code-review. На том же GitHub есть защита pull-request’ов с помощью заданного количества code-review. Вы можете поставить ограничение, что коммит не зайдет, пока два разработчика не скажут, что с кодом все хорошо.
-
И дополнительно – нужны права доступа. Это, в основном, актуально для OpenSource-проектов.
-
Как мы переходили из конфигуратора в EDT?
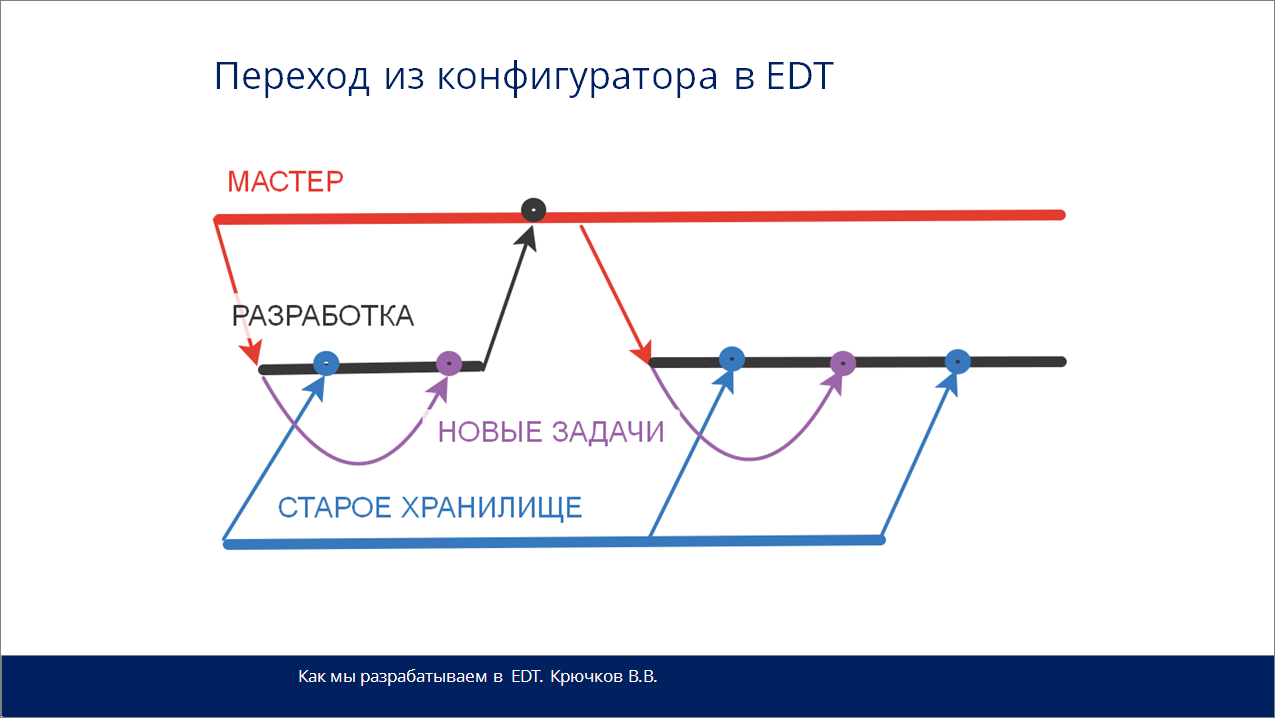
После того, как мы узнали, как разрабатывать в EDT, следующий вопрос, который нас тревожил, – как туда перейти? У нас было два случая, как мы переходили.
Первый случай касался разработки нашей OpenSource-конфигурации «Тестирование 3.0». Что мы сделали? Мы остановили разработку, импортировали конфигурацию в EDT, сделали ветку и “поехали” дальше.
Во втором случае мы переходили на EDT в серьезном проекте, где задачи интенсивно накапливались. На этом проекте мы в процессе своей работы используем два хранилища:
-
Первое – это хранилище разработки, где разработчики добавляют свои задачи, ведется разработка;
-
И второе – это т.н. Production-хранилище, где происходит процесс сборки. Туда попадает последний коммит хранилища разработки, где мы ставим «Версия такая-то». Такое небольшое упрощение.
Как мы в этом случае перешли?
-
В ветку «Мастер» мы выгрузили данные из Production-хранилища
-
Потом на основе ветки «Мастер» сделали ветку «Разработка»,
-
И в ветку «Разработка» вливаются реализации новых задач (они на слайде показаны фиолетовыми стрелочками).
-
И тут возникает вопрос, что делать с задачами, которые в релиз не вошли, и есть только в старом хранилище разработки? Мы сделали отдельную ветку, которую так и назвали «Старое хранилище» (а те разработчики, кто не использует хранилище, могут сделать для каждой разработческой базы с реализованными задачами отдельные ветки «Старое 1», «Старое 2» и т.д.).
Здесь возникает вопрос – как забрать из старого хранилища ту или иную задачу? Первый вариант. Вы в процессе разработки «в один клик» переключаетесь на ветку старого хранилища, обновляете базу, а затем возвращаетесь на ветку разработки и средствами EDT пытаетесь обновиться из ветки хранилища. И тут у вас появляется диалоговое окно – «Обновить базу целиком, либо интегрировать изменения в текущую ветку?». Вы выбираете «Интегрировать в текущую ветку», вам откроется окошко, вы выбираете, что нужно поместить, помещаете и таким образом частично переносите старые изменения. В какой-то момент ветка старого хранилища просто «умрет», вы ее удалите и забудете о ней, как о страшном сне.
Второй вариант - это сделать выгрузку старого хранилища в отдельную файловую конфигурацию с помощью EDT и уже с ней сравнивать в процессе вытягивания старых изменений.
Как еще используем Git?

Как мы еще используем Git?
-
В Git мы параллельно храним обработки и отчеты;
-
Храним тесты – у нас для тестов используется специальный фреймворк. Разработку тестов мы ведем по GitHub Flow, поэтому изменения тестов у нас сразу же становятся доступны для проверки «ночных сборок».
-
Также в Git можно хранить документацию.
Как решать конфликты?

Мы поговорили про то, как перешли. Теперь про сам процесс взаимодействия в команде и ситуации возникновения конфликтов:
-
Часть конфликтов возникает в процессе создания и назначения задач от бизнеса, проводником которых является менеджер проекта. Это конфликты, связанные с менеджментом.
-
Где еще могут быть конфликты? Они могут быть из-за костыльной разработки, из-за самих разработчиков. Это конфликты методики разработки.
-
И самое последнее – это технические конфликты, когда мы начинаем непосредственное слияние кода, и там возникают конфликты.

Как решать конфликты?
-
Большинство, может быть интуитивно, разделяют разработчиков по направлениям, по подсистемам (по производству, по бухгалтерии, по продажам). Таким образом разработчики перестают конфликтовать между собой.
-
Дальше – разделение задач одного и того же направления с точки зрения времени взятия их в работу. Если мы все задачи этого направления сейчас возьмем в работу, они могут между собой сконфликтовать.
-
Самое мое любимое – это использование стандартов разработки от 1С. Некоторые говорят: «Да в типовых конфигурациях 1С эти стандарты постоянно нарушаются, почему я должен их соблюдать? Я что, лучше их, что ли?» Давайте не поддаваться на такие провокации. Скажу даже больше, нужно соблюдать общие принципы применения паттернов SOLID и GRASP, которые пришли к нам к нам из объектно-ориентированного программирования.
-
Что такое SOLID? Буква S в этой аббревиатуре означает Single Responsibility Principle (Принцип единой ответственности) – не старайтесь впихнуть в одну функцию множество различных значений. А буква O в этой аббревиатуре означает принцип Open-Closed Principle (Принцип открытости-закрытости). Этот принцип говорит о том, что при разработке новой функциональности нужно стараться не влиять на то, что уже разработано. Если вы по такому принципу будете подходить, у вас все будет просто – вы не будете переписывать старое. Про расшифровку остальных букв читайте в глобальной сети.
-
Далее – интересный момент из принципа GRASP. Сильное сопряжение и слабое связывание. Сильное сопряжение заключается в том, что, когда вы программируете, вы помещаете свои разработанные объекты в логически связанные цели, задачи. Если делаете задачу по бизнес-процессу «Продажа», то поместите свой код в общий модуль в подсистемы «Продажи» и назовите его соответствующим образом. Не помещайте его в подсистему «Производство», где его никто не найдет. Не нужно создавать проблемы для следующего разработчика, потому что он может не найти места (да в принципе не обязан искать по всей конфигурации), где вы описали свою функциональность, и начать писать что-то свое. А принцип слабого связывания заключается в том, что нужно стараться как можно меньше связывать функции друг с другом. Не нужно из подсистемы «Продажи» вызывать функции подсистемы «Производства», и наоборот. В 1С, кстати, я смотрел в конфигурации БСП3.0 – они там в этом направлении двигаются. В этом есть серьезный плюс.
-
-
Применяйте у себя code-review. Это обязательно. У нас оно есть. Оно предоставляет нам фантастический профит. Есть разработчик, который что-то закоммитил, а есть другой человек, который посмотрит, что было в коммите, и может найти какие-то вещи, которые разработчик пропустил.
-
И вторая важная вещь – делайте рефакторинг. Не нужно делать кучу ненужных функций. Пытайтесь их разгрести, расчистить «макароны» в коде и архитектуре. Хороший принцип разработки – когда вы чувствуете, что начали дублировать код, сразу же выносите его в функцию. Это вам даст профит в дальнейшем.

Мы добрались до последней части в разрешении конфликтов. В этом у нас в EDT тоже есть плюс. Если в метаданных при слиянии веток конфликтов нет, система может выполнить объединение автоматически. А если есть пересечение объектов, то открывается редактор сравнения/объединения, и вы уже сами выбираете, как что объединить.
Процесс разработки. Правила и договоренности

Следующая важная вещь в процессе разработки – когда вы приняли, что теперь будете разрабатывать правильно, вы должны договориться об основных правилах работы:
-
Проговорите последовательность действий;
-
Определитесь, у кого какие роли и какие обязанности;
-
Напишите краткие инструкции, на которые можно потом ссылаться при разборках с начальством;
-
Самое лучшее – если вы нарисуете схему процесса, где можно увидеть, кто как работает. Чтобы разработчику сразу стало понятно, что после коммита его код идет на code-review, если оно проходит неуспешно, задача возвращается в работу, если все успешно, то код попадает в ветку master.
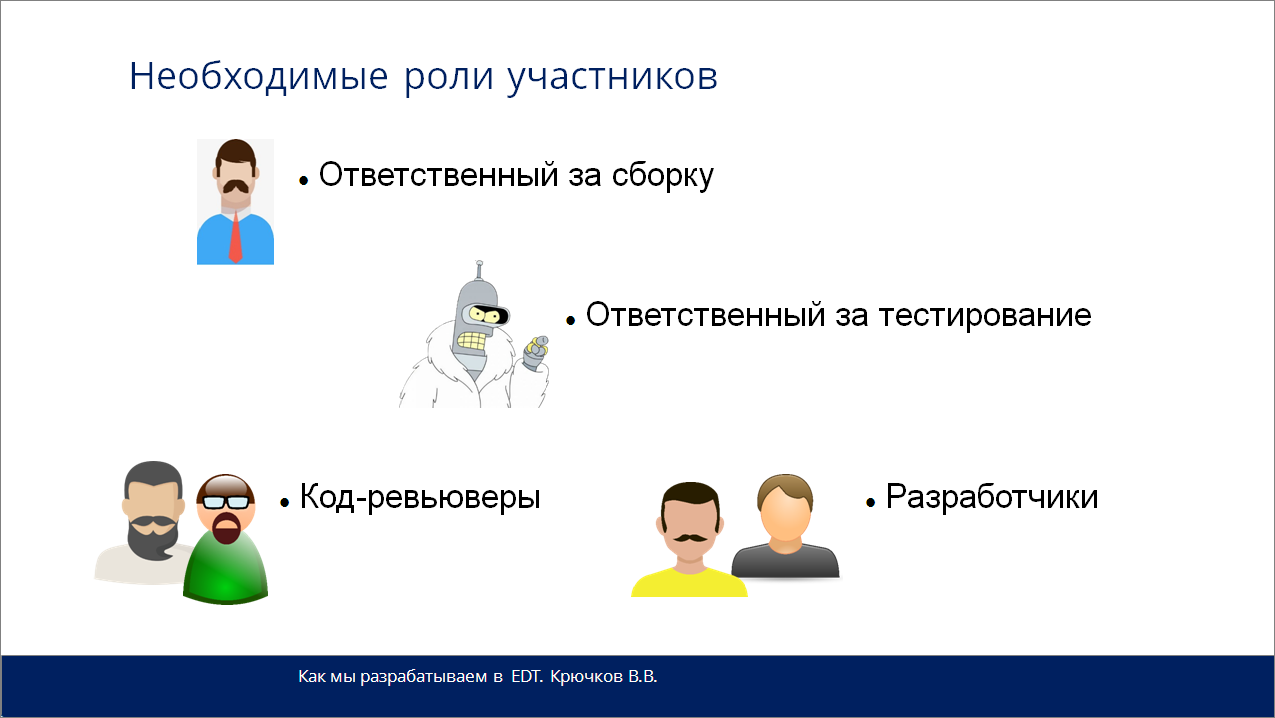
В процессе разработки у вас обязательно должны быть следующие роли. Они могут принадлежать одному или нескольким людям.
-
Первая роль – это ответственный за сборку. За это обязательно должен кто-то отвечать. Не должно быть хаоса.
-
Должен быть ответственный за тестирование, который говорит, что все хорошо. Он ставит резюме.
-
И два типа – код-ревьюверы и разработчики. Я специально выделил их отдельно, потому что я считаю, что все же код-ревьюверами должны быть не все, а только наиболее опытные сотрудники. И вот по уровню «бороды» они становятся код-ревьюверами.
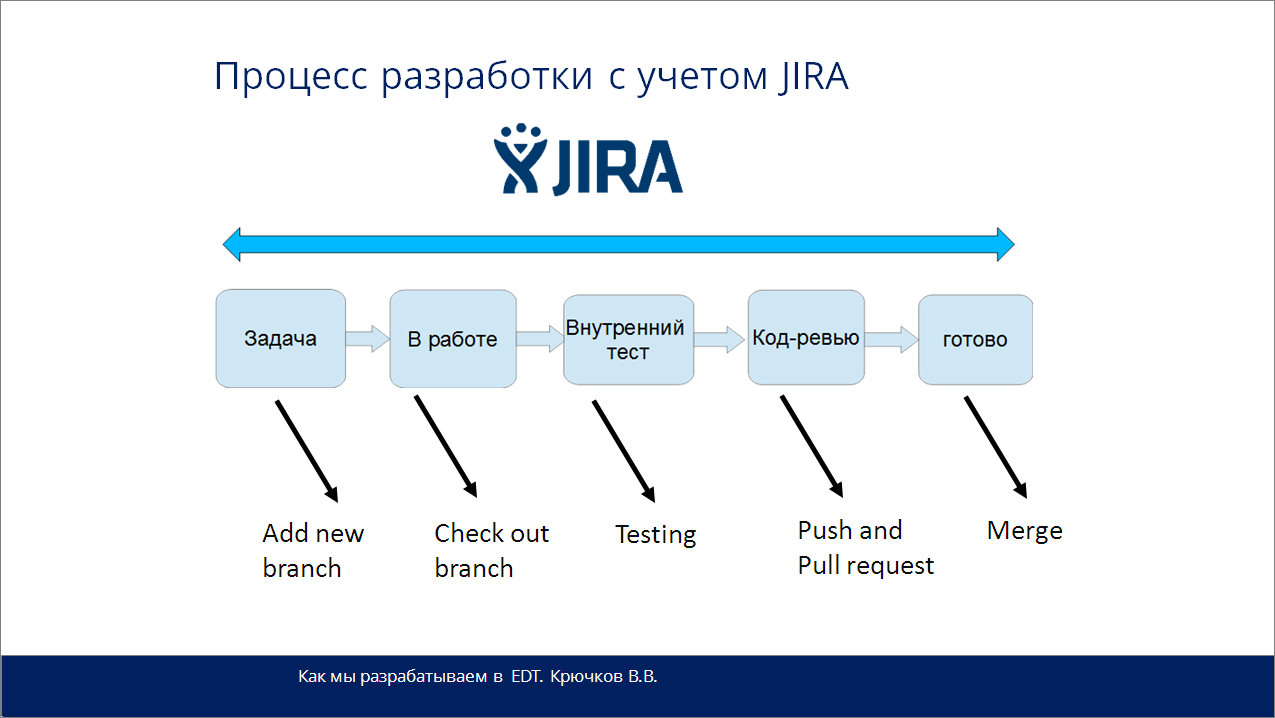
По процессу разработки – мы разрабатываем в системе Jira, и процесс у нас выглядит следующим образом:
-
под задачу открывается новая ветка;
-
командой check out branch мы берем задачу в работу;
-
потом разрабатываем, тестим;
-
протестированный код уходит на код-ревью;
-
и если все успешно, происходит мерж.
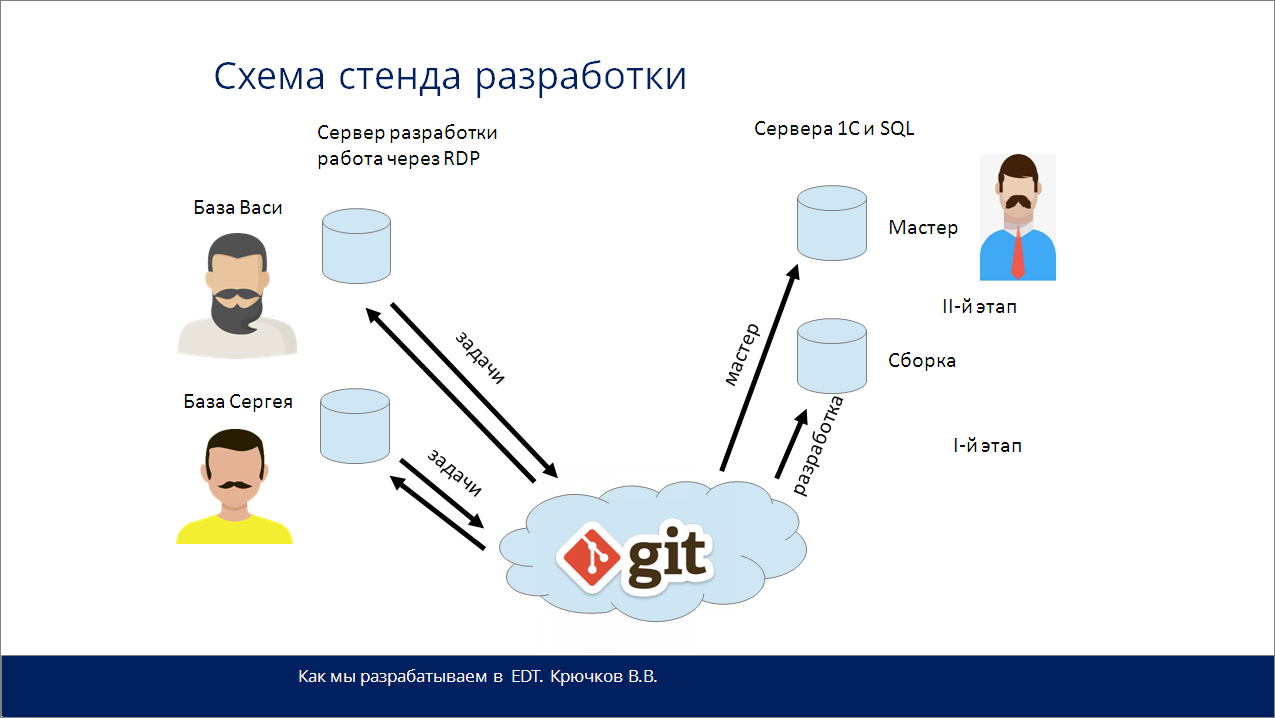
Вот таким образом у нас организован стенд разработки.
-
Есть сервер разработки, где мы все сидим через RDP.
-
Есть ответственный, который контролирует сборку веток «Мастер» и «Разработка».
Несколько кейсов использования EDT

Рассмотрим несколько кейсов использования EDT.
Для разработки нашего легковесного OpenSource-проекта «Тестирование 3.0» мы используем GitHub Flow и инструменты:
-
Встроенный баг трекинг от GitHub;
-
Разработку ведем по методике KANBAN.
Если кто хочет посмотреть, на GitHub вы можете найти репозиторий и присоединиться. Я за OpenSource.
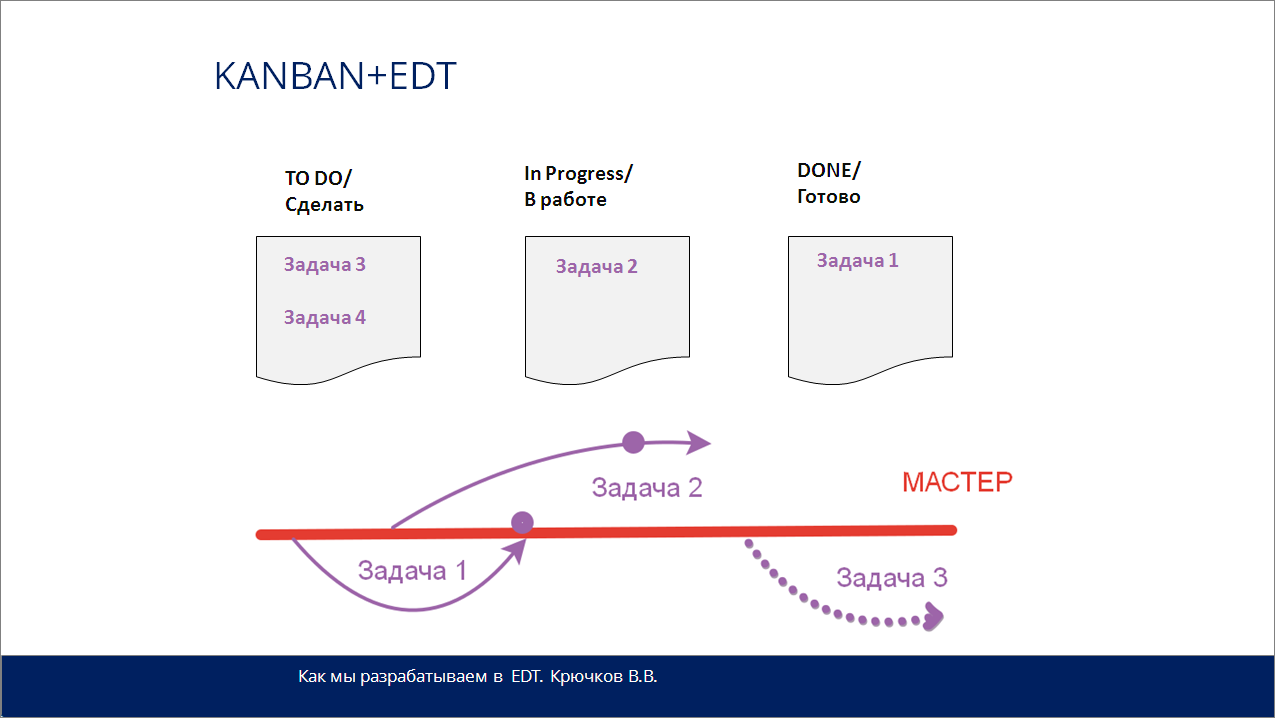
Вот так выглядит канбан-доска проекта «Тестирование 3.0»:
-
Есть список «To Do/Нужно сделать»;
-
Есть «Задача 1», которая уже готова;
-
Есть «Задача 2», в разработке;
-
И есть задачи в будущем.

Для сложных проектов мы используем GitFlow, Jira и методику Scrum.
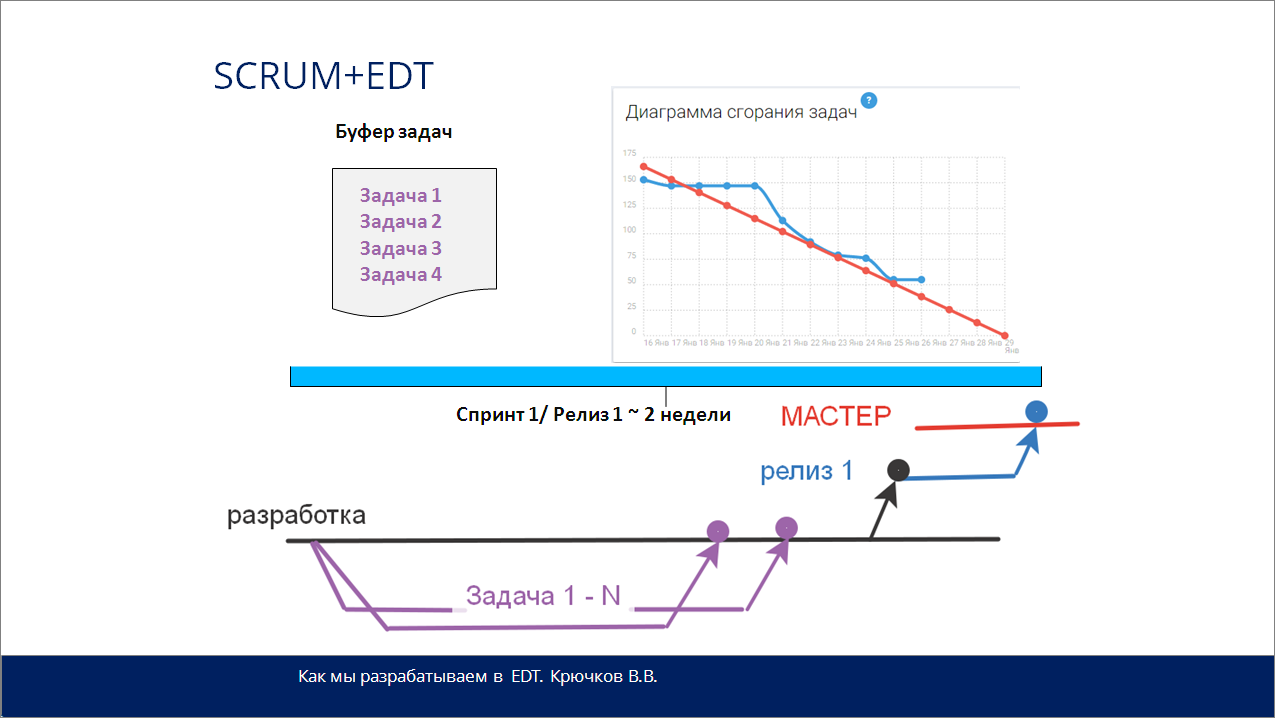
Есть пул задач, который мы определяем. Этот пул задач должен в конце попасть в релиз. Потом формируется ветка релиза и в случае успеха уходит в «Мастер».
И на слайде вы видите диаграмму сгорания задач.
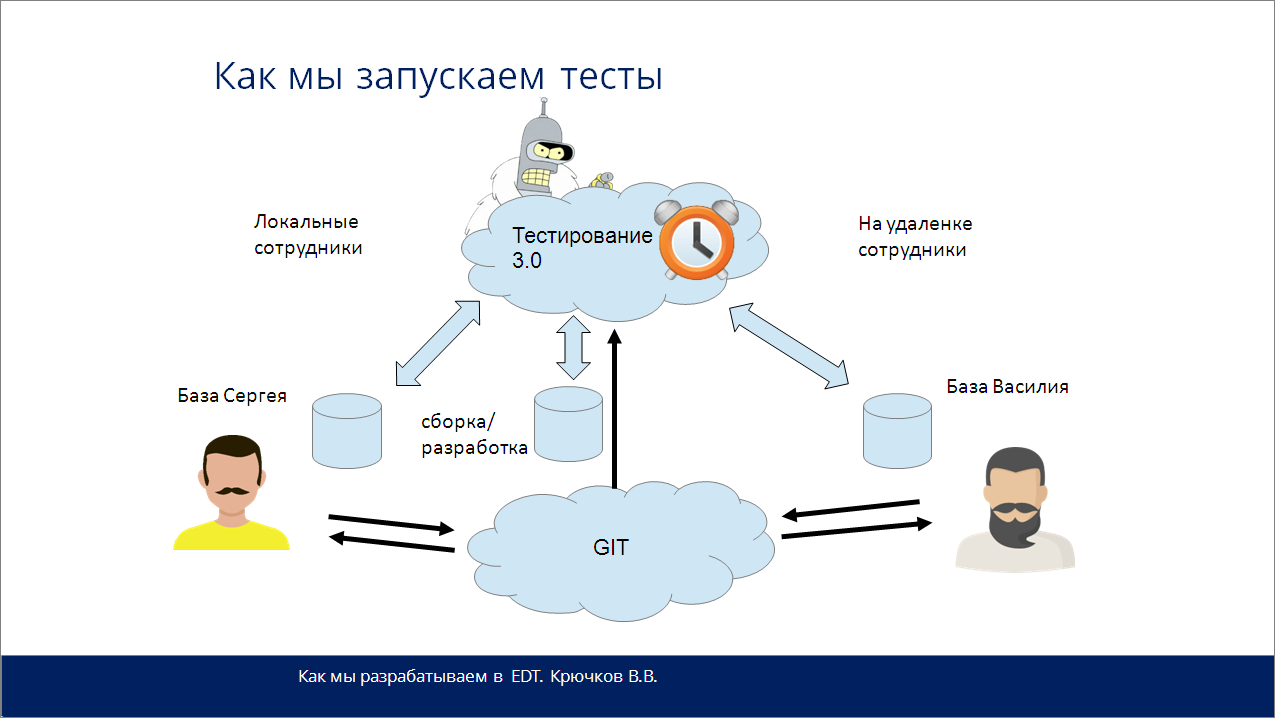
Как мы запускаем тесты при разработке в EDT?
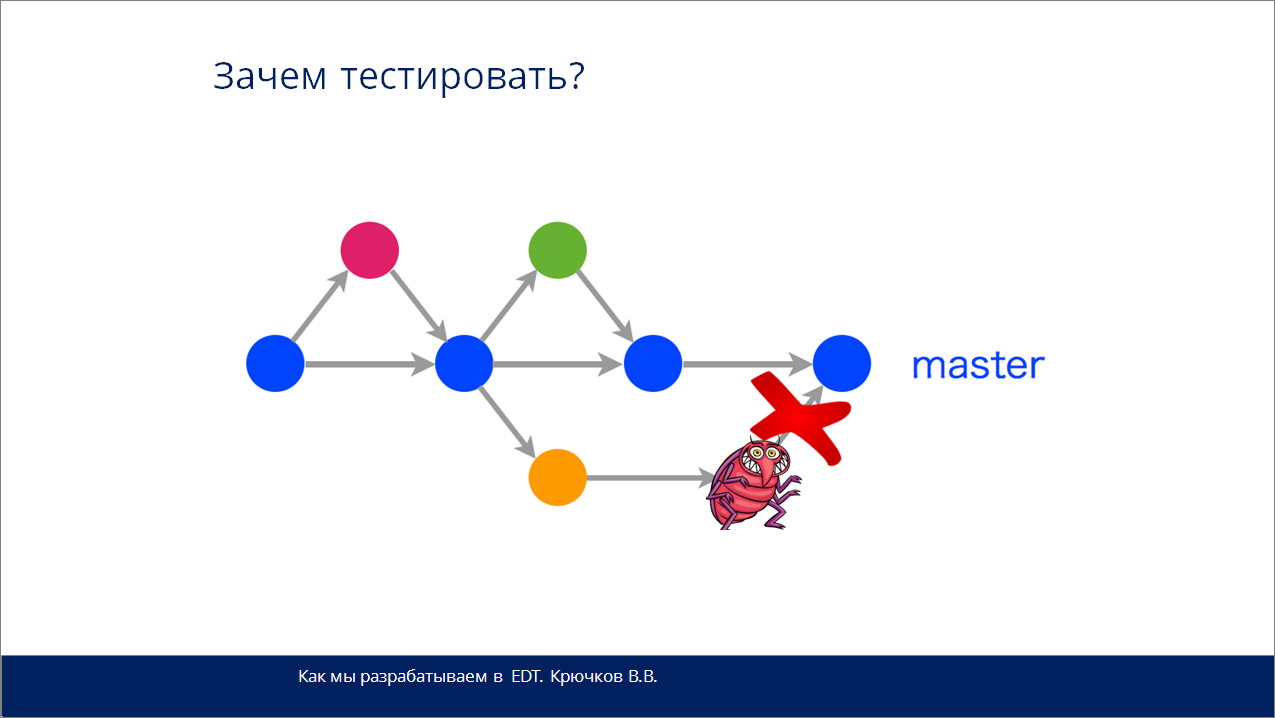
Интересный момент – я очень рад, что поднимается тема тестирования, и все начинают активно двигаться в этом направлении. Это очень хорошо, потому что отсутствие тестов чревато серьезными проблемами.
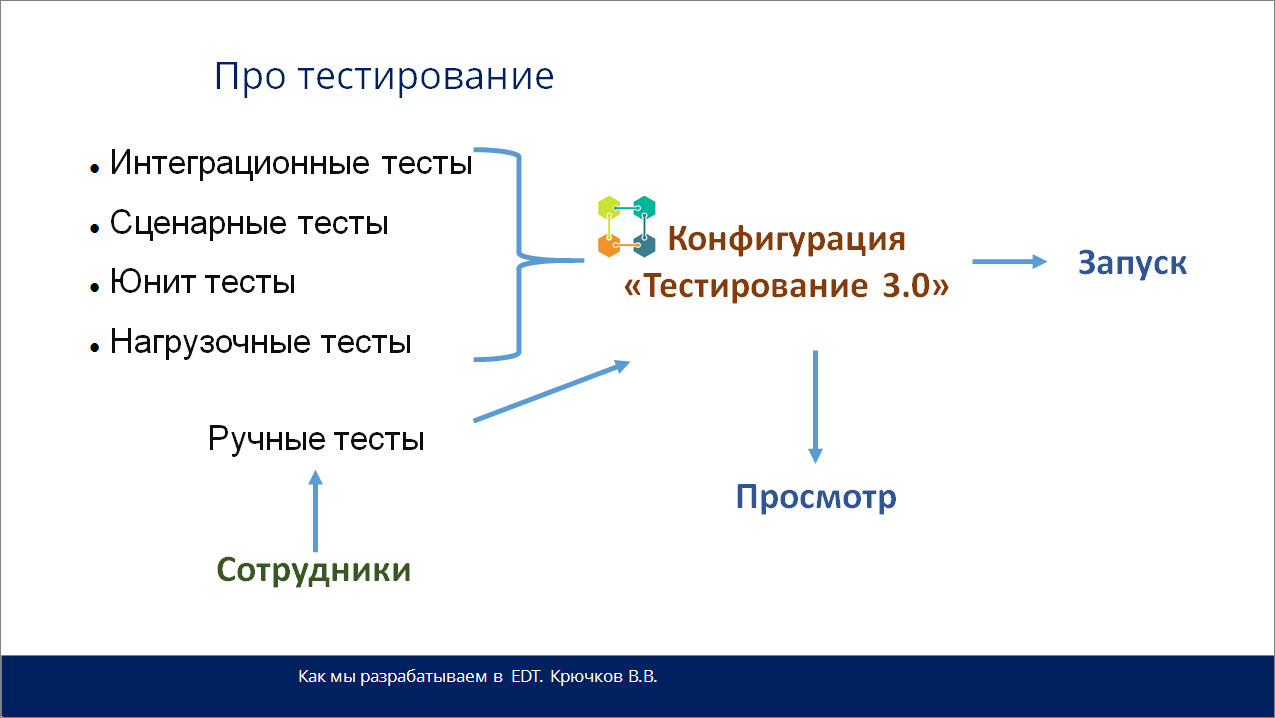
Прежде всего нам самим нужно сломать свое представление, потому что процесс разработки сам включает в себя тестирование.
Мы не должны говорить: «Мы не пишем тесты, потому что мне начальник не сказал». Мы должны писать тесты в процессе.
Мы используем систему «Тестирование 3.0» с интеграцией xUnit (ADD) и другие сопутствующие инструменты.

Немного магии…

Добавим немного магии для 1С:EDT.
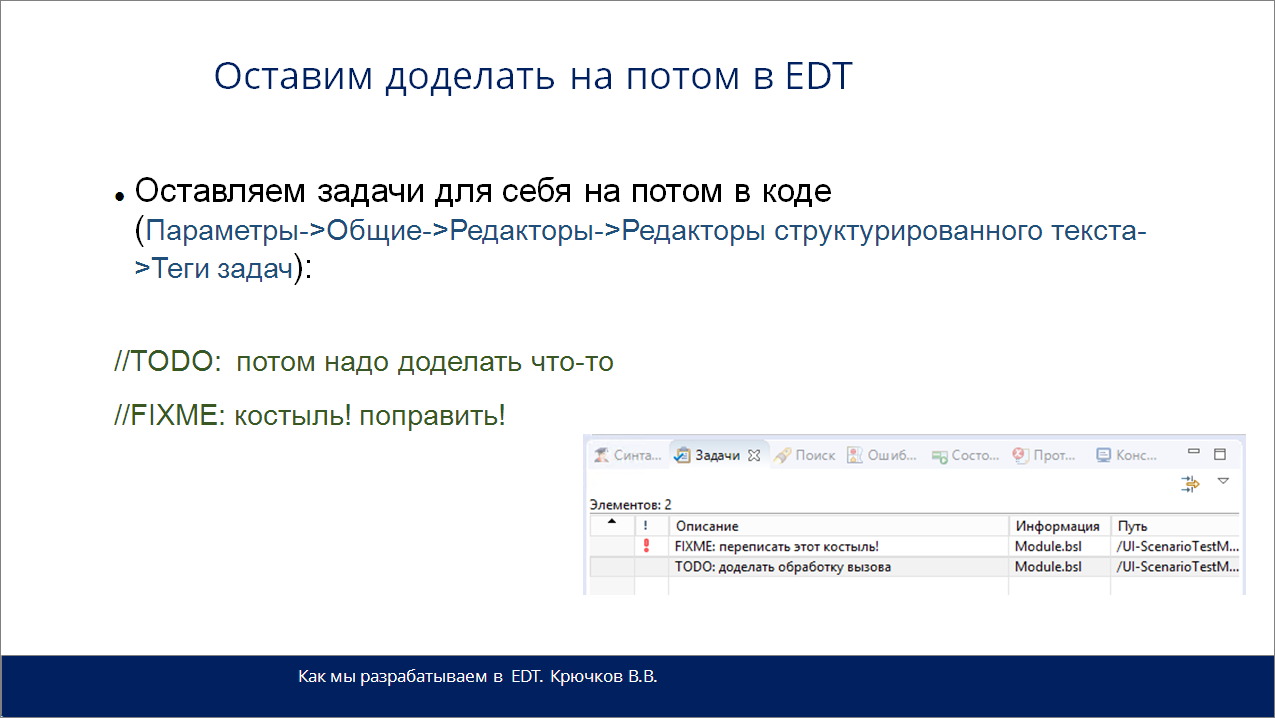
Первое – в EDT есть хорошая возможность – оставление с помощью заданных тегов задач «на потом» с возможностью просмотреть их список. Используйте, очень удобно.

Следующий момент – горячие клавиши. Я здесь выбрал самые основные сочетания, которые позволят вам эффективно работать.

Немного про Git
Скажу сразу – чтобы у вас не было проблем, перед началом работы всегда делайте fetch. Захватите все из основного хранилища, чтобы потом не было больно. Потому что, если не захватили и начали разрабатывать, то, когда вы хотите поместить, получится конфликт из-за неактуальной версии хранилища.

Немного про то, как работать с Jira из командной строки.

И командная строка Git – чем она может быть нам полезна.

В частности, пример, применения cherry-pick – если вы любите командную оболочку bash больше, чем графический интерфейс, вы можете выборочно получать нужные вам коммиты.
Это в целом все, что я хотел рассказать. Я надеюсь, вы поняли, что EDT – это потенциально классная штука.
Вопросы:
-
Доклад называется «Как мы разрабатываем в EDT», но вы очень много рассказывали именно про Git, про Work Flow, про Jira, и очень мало про EDT. Скажите, с какими серьезными проблемами вы столкнулись именно в разработке EDT?
-
EDT - это тот же конфигуратор. Если вы знаете конфигуратор, то и в новом инструменте сможете работать. Тут есть тот же редактор кода, редактор форм, дерево конфигурации и т.п. А вот про новые особенности и вопросы взаимодействия вы наверняка не знали. Важно понять как использовать все это вместе с GIT, понять процесс, окружение - это все является частью того как мы ведем разработку в EDT.
-
Как изменилось рабочее место разработчика в связи с переходом на EDT? Известно же, что EDT требует намного больше ресурсов, чем конфигуратор.
-
Я перед конференцией написал статью (Взгляд на практику разработки в EDT из зазеркалья), где уже отвечал на этот вопрос - компьютер довольно мощный. У вас будет своя конфигурация компьютера. Можете подсмотреть там, какую конфигурацию мы выбрали.
-
Насколько оправданно использование ветки на каждую задачу?
-
100% оправдано. Когда у вас есть ветка, вы, используя Jira, можете получить информацию о том, какие задачи были в коммите, автоматически определить их в Git, соединить и сделать мерж. Что такое задача в Jira? В Jira есть отдельные эпики, из которых выходят задачи. Jira Flow пропагандирует, что задача – это запрос на некую фичу, новую функциональность. Эта логика также очень хорошо укладывается, если мы говорим про фиче-бранчинг для EDT – это очень удобно, меньше конфликтов. В дальнейшем ветки под каждую задачу будут нашим основным инструментом.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.

Вступайте в нашу телеграмм-группу Инфостарт
