









В июне этого года мне предложили выступить на конференции. Тайминг был 25 минут, поэтому я подготовил выступление из двух частей, первая - о проекте, а вторая - о том, как мы понимаем и используем DevOps. В самый последний момент время на выступление сократили в два раза, из-за чего я рассказал только первую часть, а вторая пылилась на яндекс-диске. Сейчас, разбирая залежи я случайно наткнулся на презентацию и расшифровку, которую планировал читать. Не пропадать же добру? Наверное статья кому-то покажется сырой, ведь фактически формат предполагал быстренько рассказать "а как у нас", а потом уже в кулуарах обсудить детали. Кто-то попрекал меня, что я превращаю инфостарт в личный дневник. Пожалуйста, закройте страницу и не читайте дальше. Дальше будет жесткое IMHO!
Так как изначально это была презентация - я сохраню формат, сначала слайд - потом текст.
Так получилось, что месяц назад мне пришлось подумать, есть ли у нас элементы DevOps. DevOps это стильно, модно, молодежно. Давайте попробуем рассказать что из DevOps есть у нас.
Интеграция команд
Начнем с определения взятого с википедии:
DevOps -набор практик, нацеленных на активное взаимодействие специалистов по разработке со специалистами по информационно-технологическому обслуживанию и взаимную интеграцию их рабочих процессов друг в друга. Базируется на идее о тесной взаимозависимости разработки и эксплуатации программного обеспечения и нацелен на то, чтобы помогать организациям быстрее создавать и обновлять программные продукты и услуги.» Пожалуй тут стоит рассказать о том, как у нас устроен выпуск релиза.
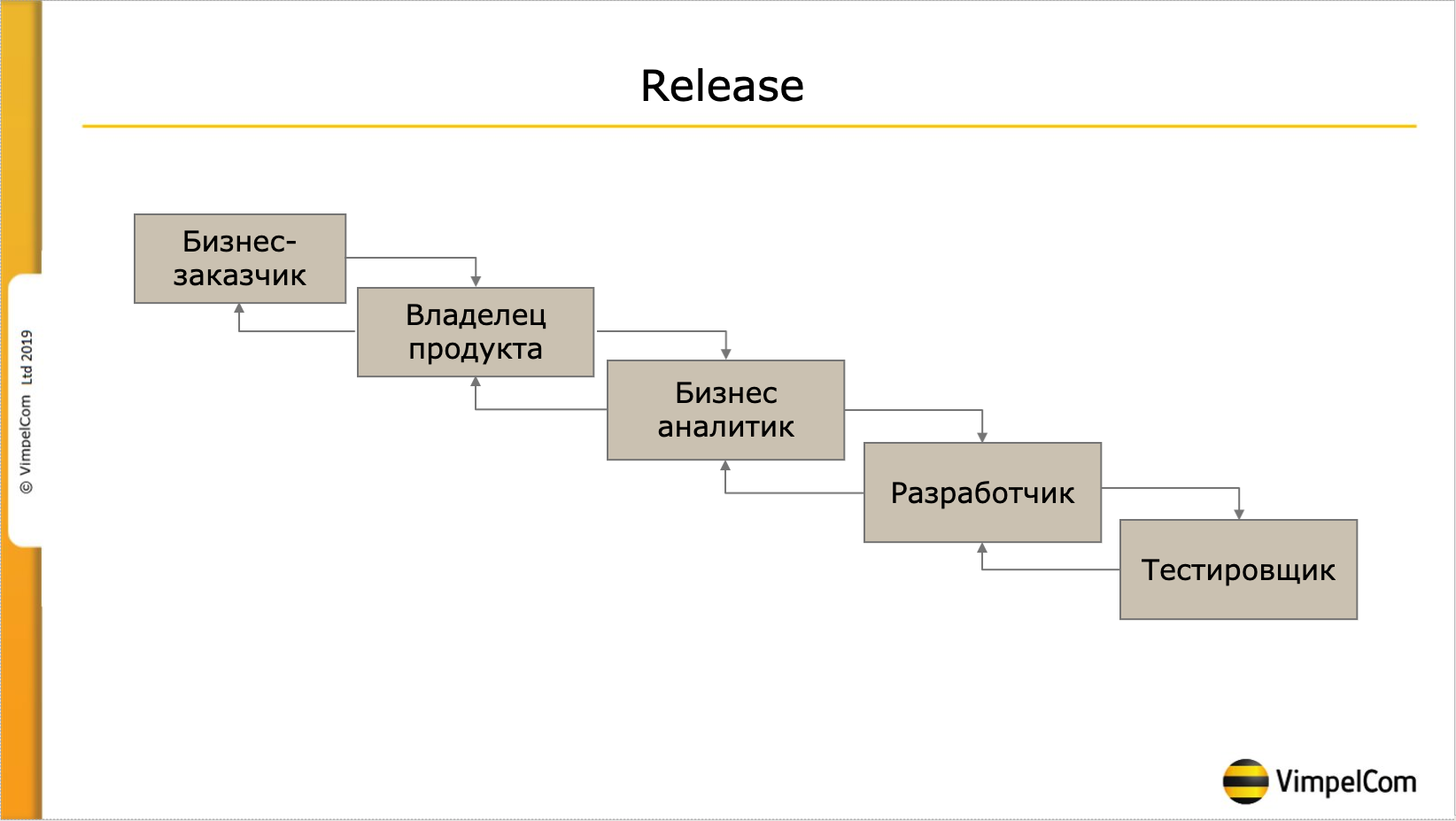
Бизнес заводит Запрос на изменение в специальной системе, так называемый RFC. RFC поступает к владельцу продукта. Все приложение поделено на 5 условных частей и есть соответственно 5 scrum-команд:
-
Продажи
-
Товародвижение
-
B2B
-
Дилеры
-
Интернет-магазин.
Что значит эти команды и чем занимаются для нашего рассказа не важно, не буду заострять на этом внимание. Итак, задача поступает к владельцу продукта, он ставит ее в беклог. Каждые две недели выполняется так называемый грумминг, когда RFC делятся на мелкие задачи, которые можно поручить одному человеку, будь то бизнес-аналитик, разработчик, тестировщик или администратор. Администраторы, кстати не относятся ни к какой команде, а привлекаются по мере необходимости. Затем уже прогрумленные задачи включаются в спринт. Таким образом в спринт может, например войти – «провести анализ по RFC», следовательно над задачей уже работают, но в релиз она не войдет. По окончании разработки, но до передачи задачи в тестирование проводится УАТ, приемочное тестирование, на котором заказчик смотрит, что сделали именно то, что он хотел. В УАТ обязательно участвует сотрудник технической поддержки и как раз вот этот момент – это чистый DevOps. Сотрудник техподдержки так же как и заказчик может сразу высказать свои замечания, например сообщить, что вот эти моменты нужно переделать, здесь обязательно добавить логирование, уточнить по планируемой нагрузке на систему в условных попугаях и дать предположение о необходимости оптимизации решения ДО его выпуска в продуктив.
Перед выпуском релиза команда сообщает список задач, которые готовы к выпуску в релиз и помещает весь готовый к выпуску в продуктив код в релизное хранилище. Я не буду тут углубляться в технические детали, сколько у нас хранилищ, кто и когда помещает в них код, это для данной темы не очень важно. После сборки релиза все тестировщики перестают быть членами скрам-команд и превращаются в команду тестировщиков. Начинается регрессионное тестирование. На текущий момент оно длится около полутора дней и состоит примерно из 240 регрессионных тестов. По окончании регрессионного тестирования принимается решение о выпуске релиза. После выпуска релиза свою работу начинает техподдержка, анализируются основные показатели работоспособности системы, такие как APDEX, нагрузка на систему, анализ технологического журнала на количество эксепшенов, время ожиданий на блокировках и еще несколько десятков параметров. Кроме того внимательно изучаются все поступающие инциденты. На основании полученных данных заводятся дефекты с критичностью от 1 до 4, где 1 – полная остановка системы в результате дефекта, а 4 – есть ошибка на неосновном функционале имеющая обходное решение.
Таким образом можно сказать, что в имеющихся условиях (например мы по закону не имеем права предоставлять разработчикам доступ в продуктивную систему, а так же сотрудник, который пишет код – не имеет права самостоятельно его тестировать), так вот, в имеющихся условиях мы смогли обеспечить максимальную интеграцию всех участников процесса. Ставим Check.
СI/CD.
Священная корова DevOps.
Начнем с неприятного. Мы не используем EDT. Причины со сцены я озвучивать не буду. Примем как данность. Значит у нас нет гита.
Continuous Integration.
У нас нет автоматической сборки проекта, однако часть CI присутствует. На проекте работают 12-15 разработчиков, которые ежедневно, а иногда и несколько раз в день помещают свой код в хранилище разработки, из которой уже обновляются базы, в которых работают тестировщики. Статистика показала, что в день проходит примерно 20-40 таких пул-реквестов. 5-10 раз в сутки основная база для тестирования обновляется из хранилища разработки. Каждую ночь запускаются автотесты, по результатам выполнения которых тестировщики заводят дефекты. Пока вручную. Можно ли считать это непрерывной сборкой? Считаю что да.

Continuous Delivery.
Тут сложней. Несмотря на то, что динамическое обновление присутствует в 1С уже очень давно – мы его не используем. К счастью, 1С придумала расширения. Одной из самых важных причин перехода с 8.3.10 на 8.3.12 было исправление ошибок по работе с расширениями. На текущий момент все дефекты более-менее высокого приоритета исправляются расширением, новый функционал не выпускается расширениями только из-за бюрократических препон. Технических ограничений выпускать новый функционал по мере готовности никаких нет.

Automated Testing
Процесс обкладывания кода автотестами в среде 1С несильно распространен, поэтому данная практика оказалась одной из самых сложных в проекте. Однако опыт, накопленный «Серебряной пулей» позволил нам в течение 3 месяцев подготовить стенд и обучить сотрудников группы тестирования созданию автотестов. На текущий момент порядка 220 кейсов обложены автотестами (см. выше), кроме того после выхода новых задач появляются кейсы в регрессионном тесте, которые так же кладутся в скоуп задач по созданию автотестов. По мере возможности тестировщики берут и разрабатывают автотест для конкретных кейсов.
Внедрение автотестирования позволило сократить регрессионное тестирование перед выпуском релиза с 90 до 35 человекочасов (с 1.5 до 0.5 рабочего дня при участии 7 тестировщиков)
Инфраструктура как код (Infrastructure as Code)
На текущий момент не используется.

Continuous Deployment
Не так давно (меньше года назад) 1С представила свой новый продукт: «Центр администрирования». Он позволяет автоматизировать то, что раньше делалось вручную, писались разрозненные скрипты или использовались продукты других компаний. На текущий момент Центр администрирования встроен в Центр контроля качества, который мы активно используем в качестве CMDB и системы мониторинга, поэтому сразу после появления данного продукта наши администраторы начали менять свои самописные скрипты на сценарии в данном продукте. На текущий момент уже выполнена автоматизация установки продуктивного релиза которая включает в себя блокировку базы, перезапуск служб и очистку сеансовых данных, подключение к релизному хранилищу и обновление основной и конфигурации базы данных. Участие человека сводится к запуску скрипта, которая нужна лишь для соблюдения регламента компании.

Load Testing
Для проведения нагрузочного тестирования есть специальный стенд, состоящий из 6 физических серверов, полностью повторяющих продуктивную среду. После того, как релиз-менеджер дает отмашку о готовности релиза конфигурация, полностью соответствующая той, что выйдет в продуктив устанавливается на нагрузочный стенд, после чего в течение 6-8 часов 8 тысяч клиентских сессий эмулируют типовую нагрузку на систему, пробивают чеки, проводят накладные на поступление товара и прочее. По итогу нагрузочного теста формируется сводная оценка APDEX согласно методике, рекомендованной компанией 1С. Оценка считается от 0 до 1, где 1 – падения производительности не зафиксировано, а 0 – система фактически не работоспособна. На основании полученной оценке принимается решение о выпуске релиза.
В ближайшее время планируется использовать нагрузочный стенд не только перед выпуском релиза, но и в процессе непрерывной поставки, то есть выполнять нагрузочный тест каждую ночь базируясь на конфигурации релизного хранилища.
Application Performance Monitoring
В системе регистрируется время всех основных операций, на текущий момент их около 40. По каждой из операций с бизнес-подразделениями компании заключен формальный договор, какое среднее время операции считать хорошим, какое приемлемым, а какое плохим. Мониторинг в системе настроен таким образом, что если время какой-либо операции отклоняется от «хороших» значений об этом немедленно оповещаются администраторы и в системе ServiceDesk заводится инцидент. В зависимости от количества операций и от степени их отклонения от нормы приоритет инцидента может быть повышен вплоть до критического (система недоступна для работы).
Выводы
Несомненно разработка в 1С накладывает определенные ограничения для использования современных технологий разработки, однако все эти технологии имеют несколько вариантов прочтения и прикрыв глаза ладошками можно гордо заявить - мы внедрили DevOps :)
Технологический консалтинг и DevOps для 1С
Мы решаем проблемы производительности, инфраструктуры и автоматизации разработки на 1С
Вступайте в нашу телеграмм-группу Инфостарт