Добрый день! Тема CI/CD в мире 1С при разработке решений на платформе 1С обсуждается в последнее время достаточно активно. Некоторые уже пошли по пути внедрения, а кто-то еще только задумывается об этом. Некоторые команды, которые встали на этот путь внедрения, столкнулись с проблемами, которые либо замедлили этот процесс, либо вообще его, по сути, приостановили. Зачастую это связано с тем, что нет готовых примеров, знания разрозненны, либо не могут ничего найти в связке с 1С.
В своем сегодняшнем докладе я хочу рассмотреть процесс CI/CD и некоторые инструменты, которые, на мой взгляд, помогут пройти этот не очень легкий путь, чтобы достаточно быстро получить положительный эффект, снизив время на изучение. При подготовке доклада у меня не получилось уложить в 30 минут все, что мне хотелось рассказать, мне пришлось некоторые блоки обрезать и упростить. Поэтому я буду акцентировать внимание на наиболее сложных, интересных, важных и ключевых вещах.

В моем докладе, по сути, будет три части:
-
Первая часть – это обсуждение некоторых подготовительных действий, которые необходимо выполнить перед началом внедрения практик CI/CD.
-
Далее мы рассмотрим инструменты и технологии, которые будут использоваться в этом процессе
-
И в основной части мы коснемся настройки инструментов и технологий для построения конвейера, а также особенностей их использования.
В рамках доклада я акцентирую внимание на том, как этим управлять в одиночку, с минимальным вовлечением команд, без обязательного изучения внутренностей этого всего.
Подготовка

Все всегда начинается с подготовки. Минимальным условием запуска практик CI/CD должно быть желание и готовность вносить изменения в свои процессы, в свою жизнь. Так как вы здесь собрались, то, как минимум, интерес у вас есть.
Итак, какие минимальные требования должны быть исполнены?
-
Разработка должна вестись с использованием системы контроля версий Git. По сути, существует два основных способа работы:
-
Первый вариант – полноценный, когда разработка ведется в EDT или в конфигураторе, никаких хранилищ нет, все изменения помещаются напрямую в Git-репозиторий.
-
И второй вариант, когда вы продолжаете работать с хранилищем конфигурации, откуда у вас фоново происходит экспорт файлов и выгрузка их в репозиторий.
-
В принципе, можно построить процесс разработки и так, и так. Но первый вариант, конечно, более предпочтительный.
-
Желательно, чтобы у команды, которая будет внедрять практики CI/CD, было несколько решений. Это нужно, чтобы прочувствовать всю силу этих паттернов для тиражирования, потому что при разработке одного продукта эффект от применения практик не так заметен, потому что работу все равно, как минимум, один раз придется выполнить.
-
И немаловажно будет наличие человека, который будет исполнять функцию DevOps-инженера, управляя всеми этими конвейерами и их настройками.
Если у вас это все есть, или вы готовы, чтобы все это появилось, то можно перейти дальше.

При внедрении любых технологий и использовании новых практик нужно определиться, зачем мы это делаем и какие цели хотим достичь. Я определил три минимальные цели:
-
Как минимум, мы хотим автоматизировать процесс сборки и тестирования приложений на платформе 1С:Предприятие. В идеале, конечно, хорошо бы дойти до деплоя на окружение препрод/прод.
-
Необходимо, чтобы используемые инструменты достаточно просто использовались, настраивались и конфигурировались с минимальными телодвижениями. И конвейер также был достаточно понятен и прозрачен.
-
Кроме этого, важно, чтобы «тайные знания» были аккумулированы в основном, на одном человеке, чтобы не было необходимости всю команду (n человек) обучать этим непростым премудростям.
С подготовкой на этом закончим. Перейдем непосредственно уже к инструментам.
Инструменты
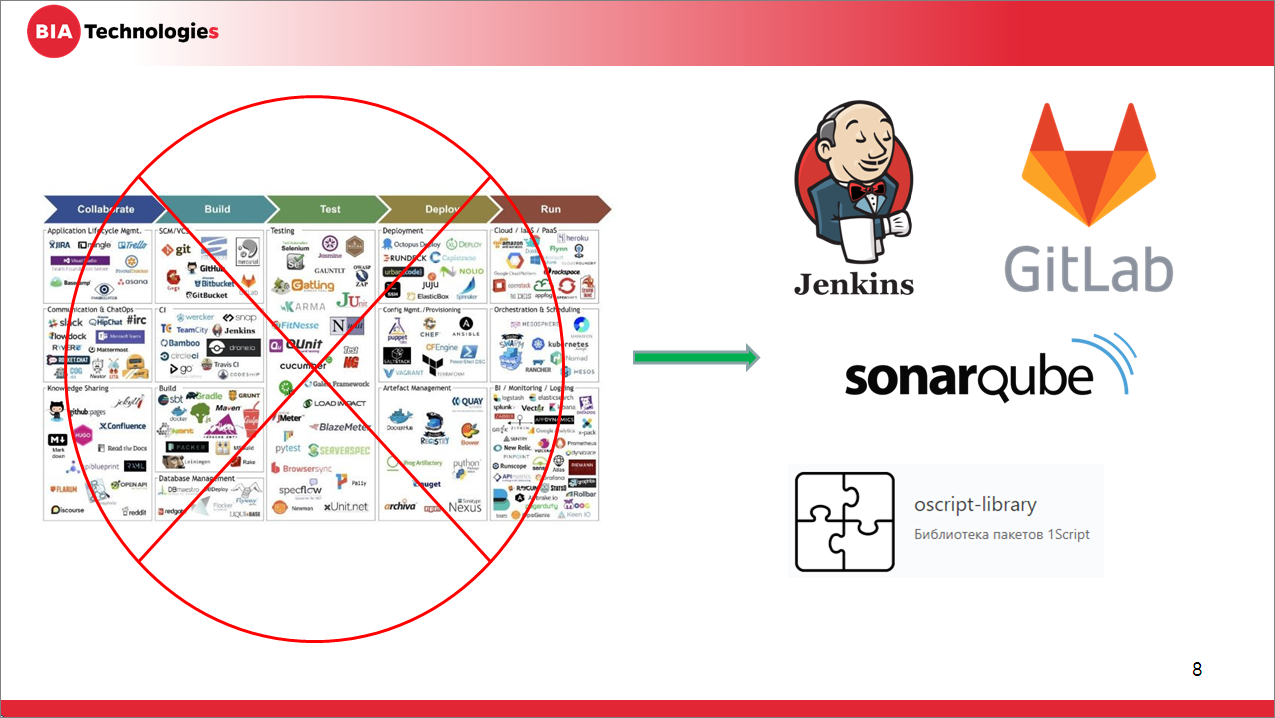
Человек, который встает на нелегкий путь внедрения инженерных практик CI/CD, в первую очередь сталкивается с тем, что в мире существует большое количество применяемых для этих целей инструментов.
Многие инструменты похожи по функциональности и, пытаясь их проанализировать, читая статьи в интернете, сложно выбрать, какой же из них лучше. Опытные DevOps инженеры уже знают, какие инструменты нужны для какой задачи – но новичку выбрать достаточно сложно. Притом, что зачастую сравнение инструментов – это холивары. Кому-то нравится Mac, кому-то Windows...
Я предлагаю не анализировать все, что есть на рынке, а просто взять готовый список инструментов, который точно работает и подходит для решения поставленных задач и достижения целей. Все эти инструменты опробованы мною лично и подходят под решение задач. Это:
-
Сервер автоматизации Jenkins, выполняющий, в том числе, роль билд-сервера. По сути, стандарт индустрии.
-
Сервер управления репозиториями GitLab – очень удобное решение для разворачивания в локальной сети, достаточно простой и могучий по настройкам. Особенно, если приобрести коммерческую версию. Но в принципе, на первом этапе достаточно и Community-версии.
-
Для анализа качества вашего кода (кода, который внесли разработчики) стоит использовать платформу SonarQube и бесплатный плагин для нее – 1С(BSL) Community Plugin.
-
И немаловажным является использование библиотек движка OneScript. Почему – об этом скажу чуть позднее.

Кроме программного обеспечения необходимо будет и железо. Да, можно все ПО поставить на машину разработчика или выделить под это небольшой компьютер, но рекомендую изначально выделить под каждый сервер отдельные машины. Впоследствии это поможет вам отмасштабировать железо и легче балансировать при увеличении нагрузки.
На слайде показана минимальная конфигурация, которая вам подойдет:
-
отдельный сервер под GitLab,
-
отдельный сервер под SonarQube,
-
отдельный сервер под голову мастер-ноды Jenkins
-
и отдельно под сборочные ноды.
Сборочную ноду я привел на примере Windows-решений, потому что в основном разработка конфигураций ведется под управлением операционной системы Windows. Но если у вас есть Linux, то, в принципе, не меняя голову Jenkins, подключайте ноду на Linux-платформе с операционной системой Centos, Ubuntu – какую вы используете. И без особой переделки все у вас точно так же будет работать.
С основным обзором инструментов закончу. Настройку конфигурирования этих инструментов я сегодня, к сожалению, не смогу рассмотреть подробно. Но могу сказать, что на старте вам будет достаточно установки по схеме «Далее-Далее-Установить». В каждом из инструментов на странице установки есть мануал, по которому можно все это выполнить и настроить. Там простой технический английский, либо даже есть перевод на русский язык. Тюнинг и расширенная настройка вам потребуются чуть позднее, когда вы точно поймете, чего вам еще не хватает и что необходимо дотюнить.
Порядок
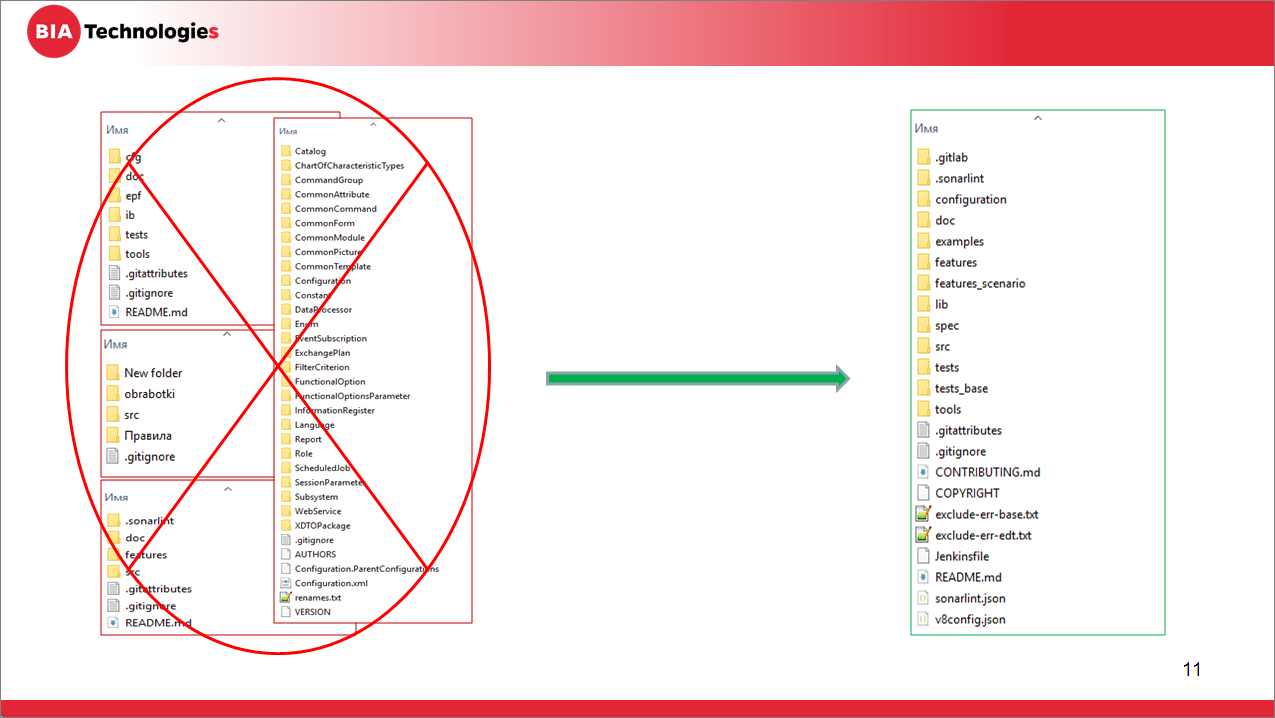
Перед тем, как начать уже непосредственно настройку и использование, нам необходимо навести порядок, потому что бардак автоматизировать сложно.
Что мы понимаем под порядком? Нужно привести в порядок репозитории. Потому что, если вы уже начали работать с Git, вы столкнулись с тем, что в отличие от других технологий (в мире Java, dotNET и т.д.) вендор не предоставляет готовых шаблонов ведения репозитория. Что положить, куда положить? Поэтому команды, зачастую, складывают файлы/папки – у кого как получилось. Кто просто исходники в корень выбросил, кто создал какие-то папочки (src, source, configuration, Конфигурация и т.д.).
Чтобы сократить затраты на поддержку конвейеров, собирающих решения, структура репозиториев у вас должна быть унифицирована, идентична во всех репозиториях. Это не просто набор папочек. Если вы работали с хранилищем, то у вас есть просто магическая черная коробка, в которой лежит конфигурация – вендор ее туда как-то положил, вот и все.
Когда вы начинаете работать с системой контроля версий Git и принимаете все парадигмы, то вам в репозитории необходимо хранить не только конфигурацию, но и все, что необходимо для сборки проекта:
-
исходники внешних обработок;
-
правила обмена;
-
сценарии тестирования;
-
тесты;
-
документация;
-
набор каких-то конфигурационных файлов, с помощью которых вы будете описывать правила развертывания;
-
настройки портов и т.д.
Все должно быть в одном проекте.
Поэтому DevOps-инженеру нужно будет поработать вместе с командой – взять все ваши репозитории (если они у вас уже существуют), определить, почему вы сложили так или иначе, и выбрать ту структуру, которая будет наиболее оптимальна для последующей автоматизации.
Или можно воспользоваться приведенным мною примером. На слайде показана структура репозитория для конфигурации, разрабатываемой под EDT.
После того, как вы определитесь со структурой, рекомендую создать пустой репозиторий, в котором эту структуру разместить, в каждом каталоге кинуть файл Readme.md и описать, для чего нужен этот каталог, почему он здесь находится. И в корень положить отдельно инструкцию – какой конфигурационный файл для чего нужен и как им пользоваться. Это, опять же, вам поможет на следующих этапах.
Приведя структуру репозитория в порядок, идем дальше – нам нужно определиться с конвейером.
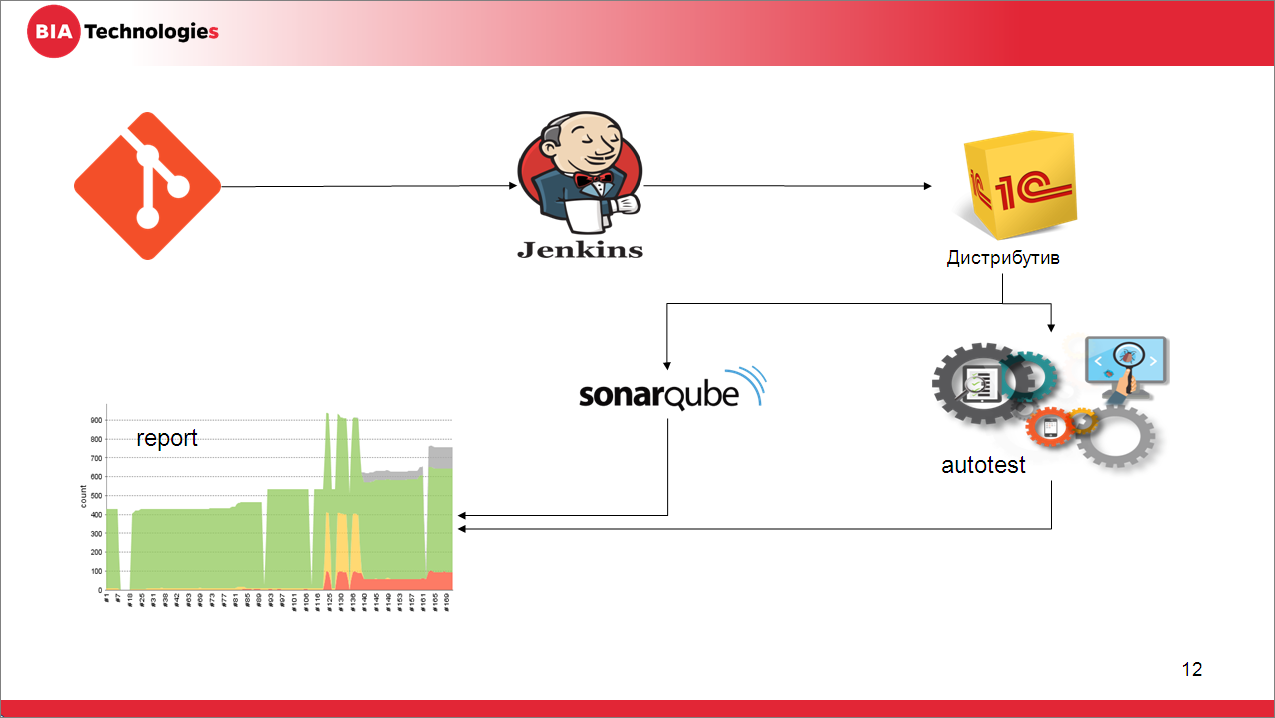
Одна из ошибок, с которой я сталкивался в своей практике – это когда пытаются сразу построить какой-то сумасшедший конвейер с 10 параллельными потоками и какой-то магией. На старте не нужно этого делать. Выберите самый простой вариант, который у вас заведется. А все накрутки и расширения будут делаться потом.
Например, вот такой простой вариант, когда:
-
разработчик делает коммит, отправляет его на сервер,
-
сервер GitLab ловит это событие, с помощью хука передает управление Jenkins,
-
тот запускает задачу по выкачиванию исходников, сборки из них файлов конфигураций, расширений, обработок и т.д. (артефактов).
-
После этого запускается процесс тестирования.
-
Параллельно запускается анализ кода.
-
И в конце полученный результат агрегирует и формирует отчеты.
Простой процесс.
Предвижу, что многие сейчас представили себе такого «сферического коня в вакууме», потому что в реальности унифицировать процессы разработки не получается – всегда есть какой-то супер-проект, который не ляжет в эту канву. Тестов мы не пишем. Нашему решению много лет, и если мы его сейчас засунем в SonarQube, она нам покажет миллиард ошибок, которые никто никогда не будет править.
Давайте не будем пессимистами.
-
Если говорить о тестах – на старте, когда вы все это запускаете, нам не нужно сразу иметь набор готовых тестов и не нужно сразу заставлять команду их писать. Начнем с того, что уже есть – это:
-
как минимум, готовые дымовые тесты, использование которых скажет вам, в принципе, приложение запускается или нет;
-
у вас есть проверка средствами конфигуратора (платформенная проверка);
-
у вас есть проверка EDT;
-
и есть инструменты, которые умеют запускать все эти тесты в автоматическом режиме и анализировать их результаты.
-
-
Если мы говорим про Sonar – да, у вас легаси-решение. У меня такие тоже есть. Sonar позволяет установить дату, ранее которой все замечания он, конечно же, видит, но, в принципе, не будет их учитывать в расчете порога качества вашего решения. И в дальнейшем задача команды будет – не увеличивать количество замечаний и, как минимум, поддерживать их на том же уровне, которое было на момент старта.
-
Что же касается непонятного, страшного проекта – исключите его из первого этапа внедрения. Пока у вас нет опыта, и вы его боитесь, отодвиньте его. Подключите его чуть позднее. Чуть позже расскажу – как.
Настройка и использование
Разобравшись и наведя порядок, давайте попробуем уже перейти непосредственно к настройке и использованию этих инструментов.
Итак, конвейер мы будем строить с использованием сервера автоматизации Jenkins. Это очень интересный комбайн, в котором предусмотрено множество готовых типов задач, с помощью которых можно автоматизировать выполнение какого-то конвейера.
По опыту, для решений автоматизации сборки и тестирования приложения на платформе 1С отлично подходят задачи типа pipeline, где подразумевается наличие в репозитории специального файла под названием jenkinsfile, в котором на DSL-языке Jenkins (на Groovy) написан скрипт, где описана последовательность выполняемых действий, шаги и вызываемые команды, и обработка результатов. Но мы задачи типа pipeline использовать не будем. Почему не будем?
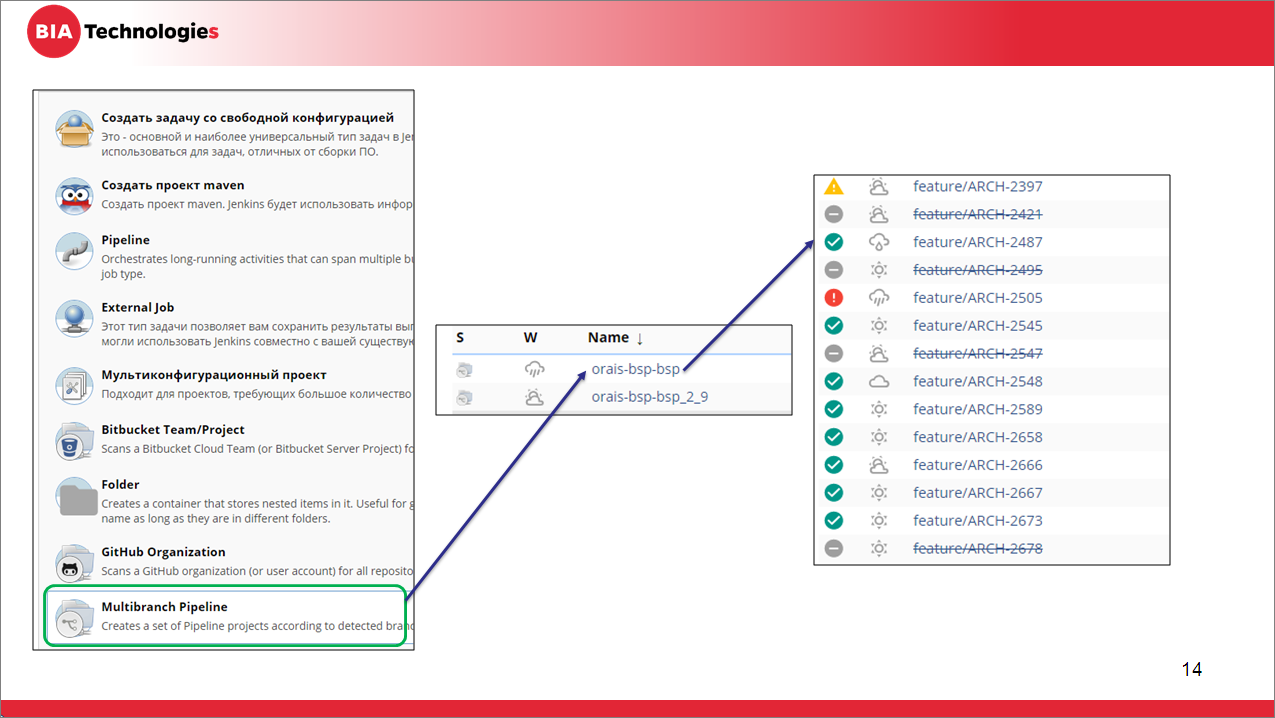
Так как мы разрабатываем в Git, мы любим много веток (у нас GitFlow и фиче-бранчинг), поэтому, чтобы иметь возможность корректировать конвейер исходя из типа ветки и ее назначения, мы будем использовать тип задачи multibranch pipeline. Он представляет собой, по сути, контейнер pipeline-задач.
Это позволит не повышать нагрузку на поддерживающего человека, чтобы ему не приходилось под каждую ветку постоянно либо создавать отдельные задачки для ее сборки, либо выстраивать эти задачки в очередь.
Задачи типа multibranch pipeline мы конфигурируем один раз, а потом уже Jenkins самостоятельно контролирует наличие веток, запускает для них эти задачи, а также контролирует жизненный цикл этих задач (если ветка удалилась, задача для нее тоже будет удалена в соответствии с настройками – по умолчанию, там стоит 30 дней, но можно корректировать). Допустим, если вы ветку уже удалили, но хотите посмотреть вчерашние результаты – вот эти перечеркнутые задачи на скриншоте – это задачи по веткам, которые уже удалены.
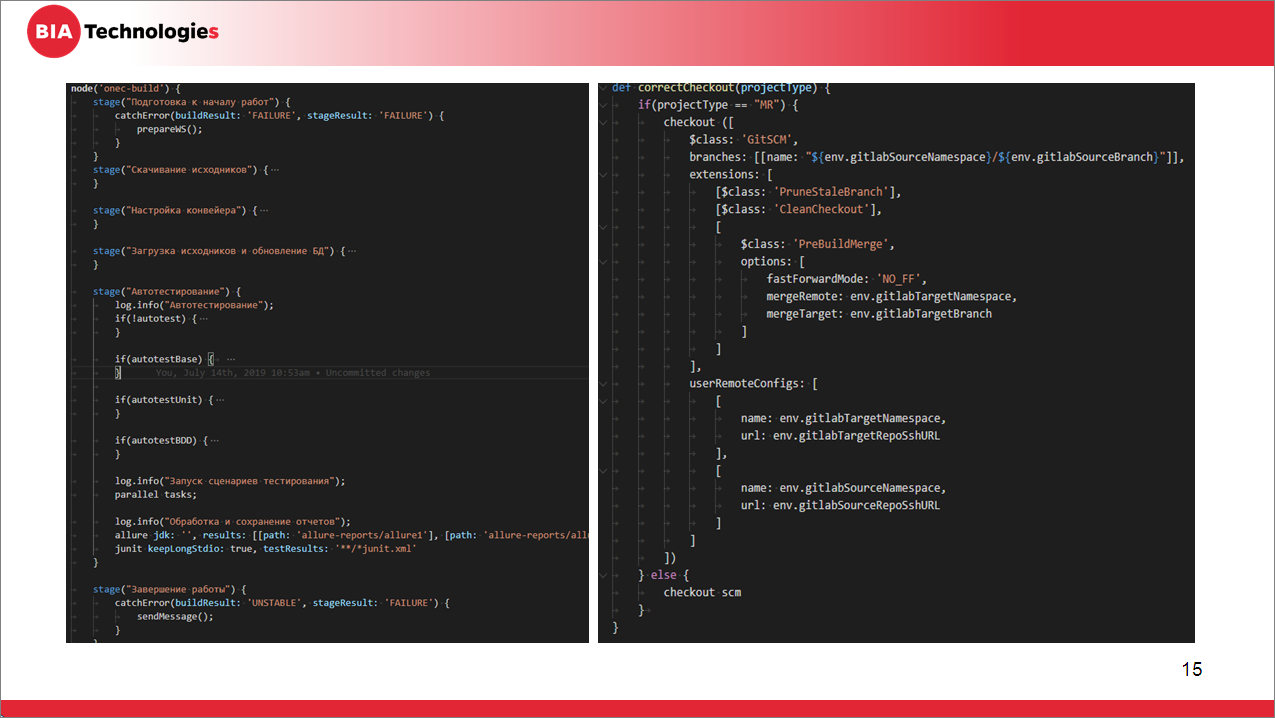
Текстовый файл jenkinsfile выглядит примерно так, как на слайде:
-
сначала указывается секция указания ноды, на которой будет запускаться скрипт;
-
и далее идет набор шагов.
А справа приведен пример одного из методов, который выполняет корректное переключение на нужную ветку для скачивания исходников. Работает этот метод, правда, только в связке с GitLab EE.

Конечно же, DevOps-инженер, почитав документацию по Jenkins, по Groovy, проанализировав описание платформы и поняв, как ею пользоваться, написать скрипы для CI/CD самостоятельно на любом языке, который ему нравится (на Powershell, groovy, cmd). Но я рекомендую использовать инструменты, которые уже разработало сообщество OneScript.
Упомяну несколько из них, которые, как раз, позволят переиспользовать опыт и сократить время на разработку. Это:
-
Vanessa-runner – мощная выполнялка различных действий, связанных с платформой, начиная от выгрузки конфигурации до запусков фреймворков тестирования
-
Два фреймворка тестирования, кому какой нравится – Vanessa-automation и Vanessa ADD
-
И библиотека Messenger для отправки уведомлений в различные каналы, будь то почта, SMS, Telegram и т.д.
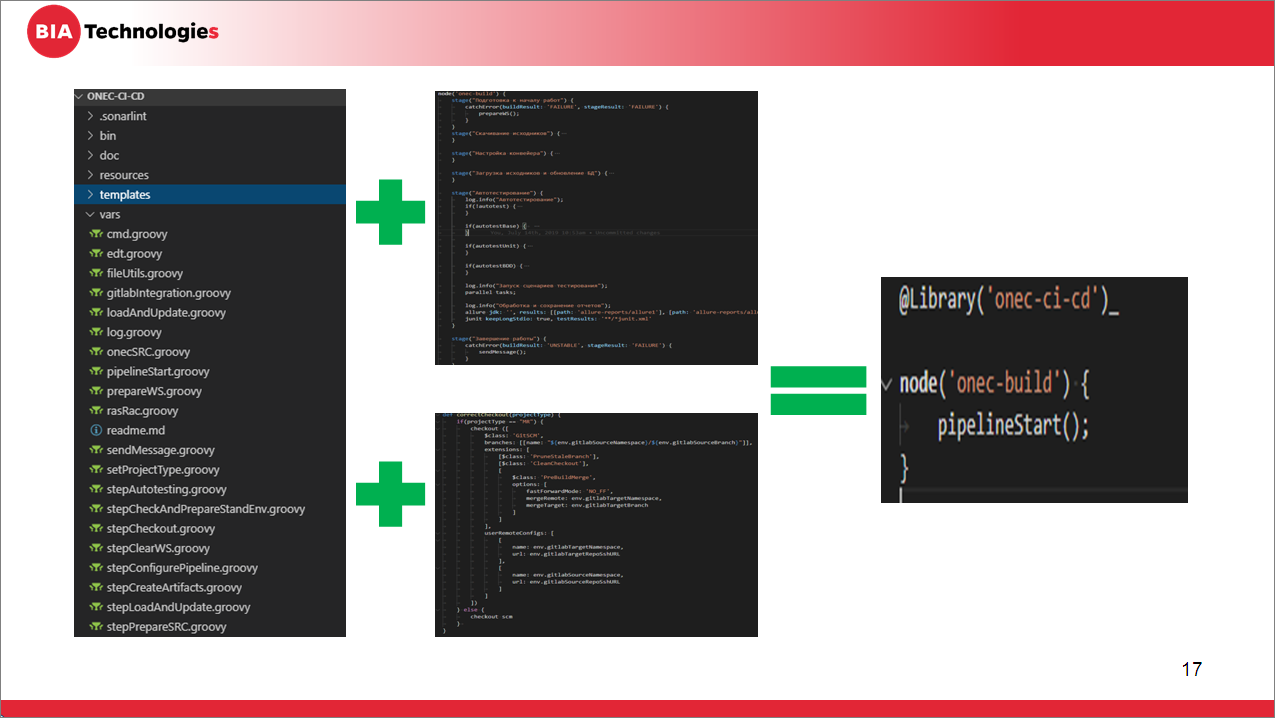
Мы вроде все настроили, соединили посредством хуков задачу в Jenkins с GitLab – вроде все завелось, все хорошо. Но есть нюанс. Те, кто это делали, уже наверняка сталкивались.
Так как jenkinsfile – это, по сути, файл, который находится в Git и подчиняется всем правилам системы контроля версий, то, если вам необходимо изменить какую-то настройку в конвейере (шаг поменять или ошибку исправить), то вам необходимо клонировать этот репозиторий, внести правку в этот файл, закоммитить и отправить его.
Что получится в результате? В этой ветке у вас будет исправленная версия, в соседних ветках этих исправлений нет. Таким образом, вам необходимо будет пройтись по всем веткам и всем поправить. Если у вас 10 репозиториев или 100, то это нужно будет выполнить в каждом репозитории (если вы поменяли какую-то общую часть). Радости это не добавляет. Но Jenkins предоставляет возможность, которой стоит воспользоваться – перейти на использование библиотек.
Как это выглядит?
Это – отдельный репозиторий, содержащий набор скриптов, в которых описаны непосредственно шаги и методы приложения, которыми мы уже будем пользоваться.
В него мы как раз и перенесем весь код, написанный на предыдущем этапе в Jenkins-файле, разделим его на кусочки, выделив каждый шаг в отдельный скрипт.
На слайде показан пример такого репозитория. Файлы, у которых префикс «step» – это шаги. А остальные файлы – это методы.
И тогда ваш jenkinsfile превращается в такую конструкцию из четырех строк, которая практически никогда у вас меняться не будет.
Таким образом, у DevOps-инженера появляется отдельный репозиторий, за который он отвечает и который он контролирует.
Пользуясь возможностями Jenkins-библиотек (Shared Library), DevOps-инженер может разрабатывать новую функциональность, не ломая существующие конвейеры, потому что библиотеки поддерживают версионность и в конкретном тестовом репозитории он может воспользоваться другой версией. Ему не потребуется править все 100 тысяч репозиториев.
А разработчикам подключаться к конвейеру очень просто – мы кидаем файлик, подключаем хук. Все, мы подключились.

Но у такого решения, если на этом остановиться, опять же, есть минус, потому что в случае, если у нас все-таки есть репозитории, которые отличаются, нам туда надо передавать 100 миллионов параметров:
-
Например, у вас есть репозиторий в формате EDT, а рядом – в формате конфигуратора.
-
Либо в одном проекте вы выполняете обычное тестирование, а другой проект у вас необходимо дополнительно проверять средствами автоматизированной проверки конфигурации на 1С-Совместимо.
-
Либо разные версии платформы и т.д.
Все это нужно покрывать каким-то набором переменных и т.д., потому что конвейеры все-таки отличаются.
Что можно сделать?
Можно написать несколько библиотек либо написать несколько методов стартера в одной библиотеке, но все это немного усложняет поддержку.
Но опять же, есть соседний мир – мы у себя уже много лет используем конструкцию, которую вам, в принципе, тоже хочу порекомендовать.
-
разбить конвейер на атомарные шаги;
-
определить набор параметров для каждого шага и для конвейера в целом;
-
все эти настройки вписать в конфигурационном файле.
-
и реализовать метод загрузки этого конфигурационного файла.
Конфигурационный файл должен будет лежать в каждом репозитории и содержать те настройки, которые необходимы конкретной команде для их проекта. Включены те шаги, которые нам нужны, и переданы переменные, которые нам требуются именно в конкретном проекте.
Рекомендую загрузку (чтение этого конфигурационного файла) настраивать таким образом, чтобы предусматривалось отсутствие параметров (чтение по умолчанию), потому что JSON, в принципе, позволяет добавлять отдельные параметры, не ломая общую структуру, в отличие от той же XML со своей схемой.

Тогда команда со своей стороны будет делать следующее – она будет брать конфигурационный файл по умолчанию, и вносить в него соответствующие правки.
Вот пример из реального проекта – здесь мы видим, что заданы уже конкретные значения и некоторые секции отсутствуют (то, что не указано, берет настройки по умолчанию).
Таким образом, мы немного приближаемся к правильному использованию этих решений. Мы полностью убрали от конечных пользователей команды необходимость знать, как работает этот конвейер. Они только читают инструкции по конфигурационным файлам, которые подготовил для них DevOps-инженер и положил в репозиторий.
А задачей DevOps-инженера будет только поддержание всех этих конфигурационных файлов в актуальном состоянии.
Заключение
На этом мне хотелось бы завершить. Надеюсь, несмотря на сжатость доклада, тот самый Inception произошел, и вам это поможет.
Отдельно хочу упомянуть несколько ссылок, где вы можете прочитать более подробно информацию о том, что я упоминал.
-
https://jenkins.io/doc/book/pipeline/shared-libraries/ – это непосредственно описание самого Jenkins по использованию библиотек.
-
https://habr.com/ru/post/338032/ – хорошая статья на Хабре по поводу использования библиотек Jenkins.
-
https://jenkins.io/doc/tutorials/ – отдельное руководство, как работать с Jenkins, очень грамотный туториал. Единственный минус Jenkins – его документация немного не успевает за выпуском релизов, поэтому могут быть небольшие расхождения.
-
https://xdd.silverbulleters.org/ – форум «Серебряной пули», где собираются все релиз-инженеры и обсуждают некоторые темы. Там вы можете задать вопрос и, скорее всего, получить на него полезный ответ.
-
https://github.com/oscript-library/ – библиотека скриптов.
-
https://www.livelib.ru/book/1002871437/about-posobie-relizinzhenera-1s-i-ne-tolko-gryzlov-na – отдельно выделяю книжку «Пособие релиз-инженера 1С и не только» под авторством Никиты Грызлова. Начинающему – маст хэв.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.


Вступайте в нашу телеграмм-группу Инфостарт