- Введение
- Использованные словари
- Объединение словарей
- Нормализация данных
- Строковые литералы
- Полезные команды
- Дальнейшие планы
- Приложение
Введение
В первой части статьи был составлен русско-английский словарь для перевода метаданных с помощью сопоставления двух конфигураций: УНФ и её переведённого на английский язык "родственника" Company Management. А сейчас рассмотрим составление более обширного словаря путём компиляции других имеющихся переводов.
Будем использовать несколько существующих словарей перевода кода 1С на английский язык, они составлялись в разное время и разными людьми. Качество словарей тоже отличается, какие-то слова переведены по-разному, в некоторых словарях есть дубли.
В статье показано как можно собрать информацию из разных источников и составить словарь для перевода конкретной конфигурации на примере УНФ 1.6. Предлагаются подходы и инструменты для нормализации словаря.
Приведённая методика будет полезна в дальнейшей работе по переводу конфигураций.
1. Использованные словари
- 0_dict_uid.txt Словарь метаданных УНФ - СМ составленный по uuid в первой части статьи. 4 800 строк
- 1_dictionary_platform.xml Словарь перевода платформы. Не самый свежий, но может быть полезен. 8 500 строк
- 2_DictSB_1.5_23.03.2016.txt Словарь перевода УНФ 1.5 на английский (SmallBusiness). 294 000 строк
- 3_SSL_slovar.txt Словарь перевода английской БСП. 144 000 строк
- 4_SSL_auto.xlsx Cловарь перевода кода БСП 3. 25 000 строк
Language tool содержит встроенный словарь платформы, поэтому файл 1_dictionary_platform.xml не используем.
Далее воспользуемся следующим подходом: с помощью плагина Language Tool выгрузим все переводимые строки из УНФ 1.6 и последовательно переведём их по имеющимся словарям. Поскольку в дальнейшем мы планируем объединять CM и УНФ, хочется чтобы перевод УНФ максимально совпадал с переводом CM. Поэтому наибольший приоритет будут иметь словари 0_dict_uid.txt и 2_DictSB_1.5_23.03.2016.txt.
Предварительно отфильтруем словари 2_DictSB_1.5_23.03.2016.txt и 3_SSL_slovar.txt. Поскольку эти файлы помимо перевода идентификаторов (имён) содержат и перевод интерфейсных строк, выполним очистку от ненужных данных с помощью приведённых скриптов:
- оставляем строки с кириллицей (удаляем тривиальные строки типа ActionsPanel ActionsPanel)
grep -P '^.*?[а-яА-Я].*?\t' 'Dict.txt' > 'Dict filtered.txt' - удаляем строки с пустым переводом (после табуляции)
grep -P '\t.*?[a-zA-Z].*?\r' 'Dict filtered.txt' > 'DictSB filtered 2.txt' - удаляем строки с пробелами (т.е. интерфейсные строки)
grep -v ' ' '2. DictSB filtered 2.txt' | sed 's/\.//g' > 'DictSB NoDotsAndSpaces.txt'
Размер словарей после фильтрации: 2_DictSB_1.5_23.03.2016.txt 157 000 строк, 3_SSL_slovar.txt 63 000 строк
2. Объединение словарей
Выгружаем из EDT все имена и идентификаторы УНФ 1.6 требующие перевода в файл common_en.txt.
Для этого нажимаем правой кнопкой на проекте в окне навигатора, выбираем Translation - Generate translation strings
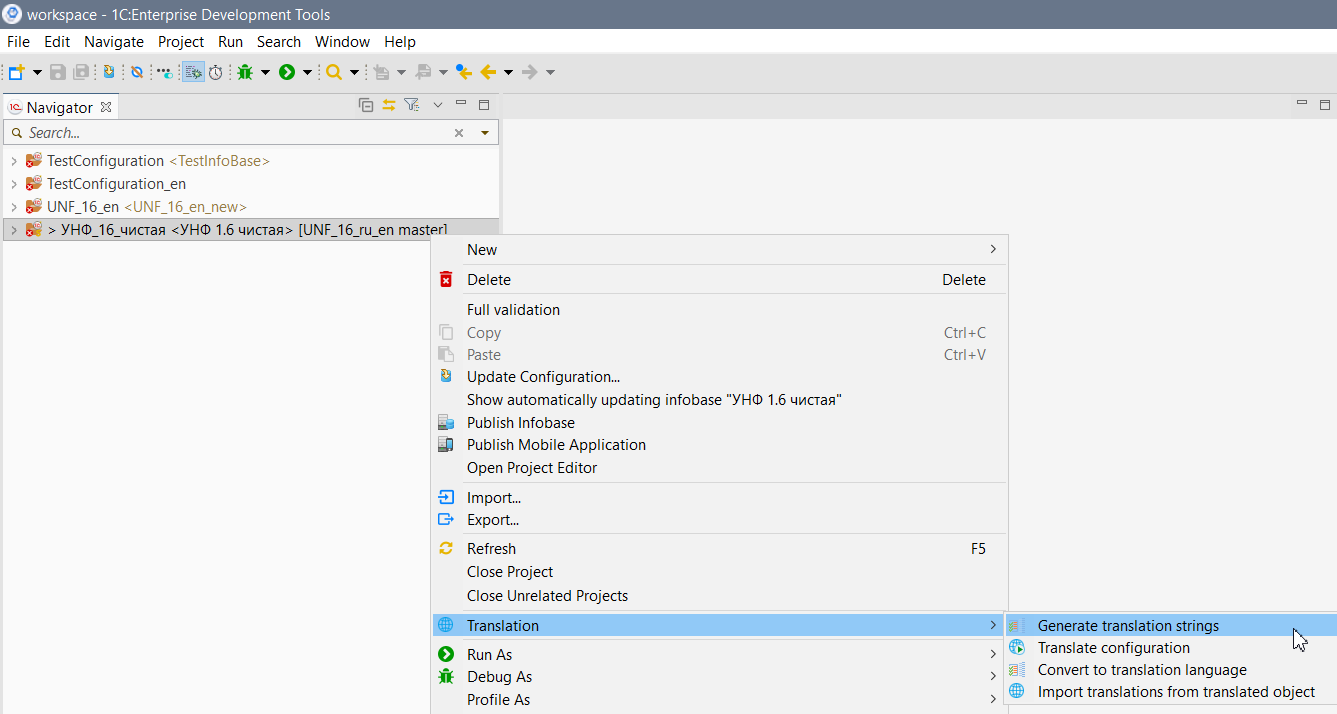
В открывшемся окне выбираем строки которые мы хотим выгрузить - только строки модели. Адрес сохранения перевода - общий словарь проекта. Отстуствующие переводы не заполнять.
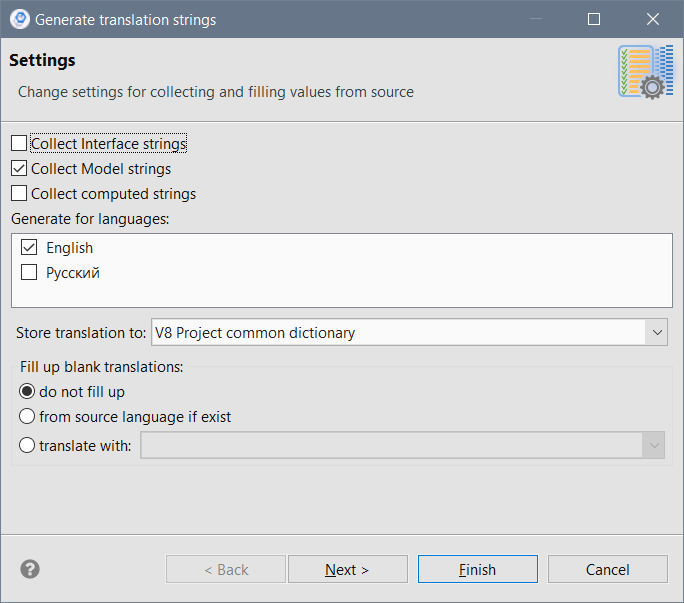
После окончания выгрузки в папке src появится файл common_en.dict, представляющий собой пустой словарь примерно такого содержания (фрагмент):
Ключи=
Ключи\ поиска\ по\ которым\ необходимо\ искать\ данные,\ поиск\ работает\ по\ логическому\ "И"\.\n*\ Ключ\ -\ Строка\ -\ имя\ реквизита\ настройки\.=
Ключи\:=
Ключи\:\ Номенклатура\ (Ссылка),\ ИдентификаторыХарактеристик\ (Массив\ (Строка))=
КлючиВариантов=
КлючиВариантовОтчета=
КлючиВсехНастроек=
КлючиВыделенныхСтрок=
КлючиДляУдаления=
КлючиДоступа=
КлючиДоступа\.Список\ \=\ &=
КлючиДоступа\.Ссылка\ В\n\t\t\t\t(ВЫБРАТЬ\n\t\t\t\t\tШапка?\.Ссылка\n\t\t\t\tИЗ\n\t\t\t\t\tСправочник\.КлючиДоступа\ КАК\ Шапка?\n\t\t\t\tГДЕ\n\t\t\t\t\tШапка?\.Значение?\ В\ (&ВедущиеКлючиДоступа))=
Фильтруем полученный словарь следующим образом: убираем знак "=", удаляем строки, не содержащие кириллицу, удаляем строки с точками и пробелами. Строковыми литералами мы потом займёмся отдельно, сейчас наша задача - составить словарь для перевода идентификаторов.
Получаем словарь из 335 000 строк, после фильтрации 260 000
- Далее берём перевод из файлов словарей в следующей последовательности:
- 0_dict_uid.txt
- 2_DictSB_NoDotsAndSpaces.txt
- 4_SSL_auto.txt
- 3_SSL_sloar_NoDotsAndSpaces.txt
- Получаем объединённый словарь join_all.txt на 58 000 слов
Приведённый Bash-скрипт последовательно ищет переводы в каждом из перечисленных словарей, затем слова, для которых перевод не нашёлся, сохраняет в отдельный файл. Потом скрипт переводит этот файл по следующему словарю и так далее. В конце файлы переводов по каждому словарю объединяются в общий словарь Join_all.txt
sed -i 's/'='//' common_en.txt
grep -v '[\. ]' common_en.txt > common_en_clean.txt
grep -P '^.*?[а-яА-Я].*?$' 'common_en_clean.txt' > common_en_clean_ru.txt
join <(sort common_en_clean_ru.txt) <(sort -k1,1 0_dict_uid.txt) > join_uid.txt
join -v 1 <(sort common_en_clean_ru.txt) <(sort -k1,1 0_dict_uid.txt) > after_join_uid.txt
join <(sort -k1,1 after_join_uid.txt) <(sort -k1,1 2_DictSB_NoDotsAndSpaces.txt) > join_uid_dictSB.txt
join -v 1 <(sort -k1,1 after_join_uid.txt) <(sort -k1,1 2_DictSB_NoDotsAndSpaces.txt) > after_join_uid_dictSB.txt
join <(sort -k1,1 after_join_uid_dictSB.txt) <(sort -k1,1 4_SSL_auto.txt) > join_uid_dictSB_ssl_auto.txt
join -v 1 <(sort -k1,1 after_join_uid_dictSB.txt) <(sort -k1,1 4_SSL_auto.txt) > after_join_uid_dictSB_ssl_auto.txt
join <(sort -k1,1 after_join_uid_dictSB_ssl_auto.txt) <(sort -k1,1 3_SSL_sloar_NoDotsAndSpaces.txt) >
join_uid_dictSB_ssl_auto_ssl_slovar.txt
join -v 1 <(sort -k1,1 after_join_uid_dictSB_ssl_auto.txt) <(sort -k1,1 3_SSL_sloar_NoDotsAndSpaces.txt) >
after_join_uid_dictSB_ssl_auto_ssl_slovar.txt
cat join_uid.txt join_uid_dictSB.txt join_uid_dictSB_ssl_auto.txt join_uid_dictSB_ssl_auto_ssl_slovar.txt |
awk '!seen[$0]++' > join_all.txt
3. Нормализация данных
Выполним обработку полученного словаря: почистим дубли слов (ключей) и переводов (значений).
Удалим из словаря неоднозначные переводы:
Загрузка Import
Загрузка Load
Запись Record
Запись Write
Запретить Deny
Запретить Disable
Скрипт для поиска дублей по первой колонке:
awk 'n=x[$1]{print n"\n"$0;} {x[$1]=$0;}' join_all.txt > join_all_duplicate_keys.txt # получил словарь дублей
Таких строк всего 300, можно почистить вручную.
Вручную почистил разные переводы каждого слова из файла join_all_duplicate_keys.txt, сохранил в файл join_all_duplicate_keys_removed.txt
Далее из файла join_all.txt удаляем все строки совпадающие по первой колонке с очищенным списком дублей join_all_duplicate_keys_removed.txt, затем добавляем этот очищенный список в низ словаря. Получаем словарь с уникальными ключами join_all_uniq_keys.txt
cat <(awk 'FNR==NR {f2[$1];next} !($1 in f2)' duplicate_keys_removed.txt join_all.txt) join_all_duplicate_keys_removed.txt
> join_all_uniq_keys.txt
В полученном словаре удалим дубли переводов такого типа:
Другое Other
Прочие Other
Извещение Notification
Уведомление Notification
Заявление Statement
Ведомость Statement
Скрипт для поиска строк словаря с дублями переводов:
awk 'NR==FNR{s[$2]++;next} (s[$2]>1)' join_all_uniq_keys.txt join_all_uniq_keys.txt | sort -k2 >
join_all_uniq_keys_duplicate_values.txt
В файле join_all_uniq_keys_duplicate_values.txt имеем 3700 строк с дублями.
Language Tool при наличии нескольких одинаковых переводов берёт только один из них. Т.е. в примере выше Заявление переведётся, а Ведомость останется без перевода. При этом плагин чувствителен к регистру, и если Ведомость перевести как STATEMENT, то переведутся оба слова и Заявление и Ведомость.
Потенциально проблемы могут вызывать одинаковые переводы в рамках общего контекста (будем называть их опасные дубли). Например две переменных в одном модуле, которые до перевода назывались по-разному, а после перевода - одинаково. Или два элемента на одной форме, или два реквизита одного справочника, и т.д. Такие слова надо перевести действительно по-разному, т.к. платформа не чувствительна к регистру: Statement и STATEMENT это один и тот же идентификатор.
Чтобы найти такие ситуации, проведём следующий анализ: проверим, какие слова из словаря дублей встречаются в одном и том же файле конфигурации (нпример в .bsl или .mdo файле).
Для выполнения этой проверки нам понадобится собрать словарь, в котором для каждого переводимого слова будет указан путь до объекта метаданных (до файла конфигурации) в котором это слово встречается. Выгрузим из конфигурации переводимые строки как было описано выше, но теперь поместим их не в общий словарь, а в контекстное хранилище переводов проекта. Режим заполнения переводов выберем - По исходному языку.
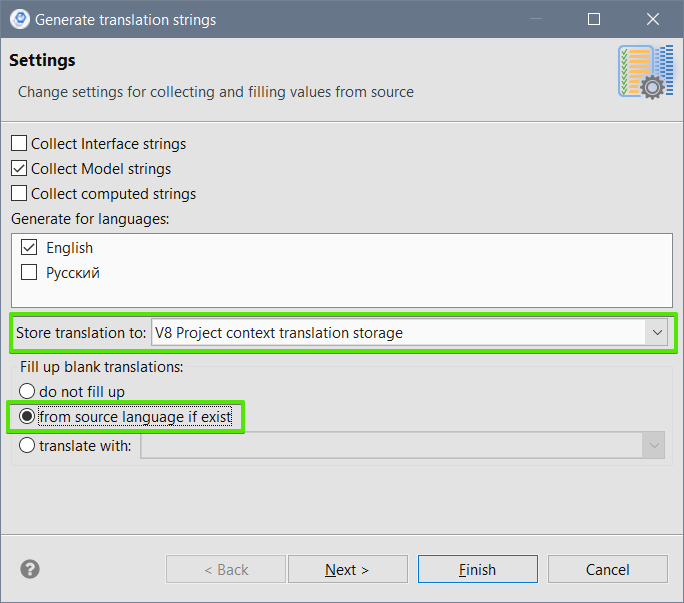
После этого в каждой папке в каталоге проекта появятся файлики *.trans, содержащие переводимые строки конкретной формы, модуля, шаблона и т.д. Соберём содержимое всех этих файлов вместе с путями до каждой строки в файл all_trans_w_path.txt с помощью скрипта:
grep -Pr '--include=*.'trans '=' > '...\Translation\all_trans_w_path.txt'
Полученный файл представляет собой словарь в формате ПутьКФайлу:ПутьКПереводимойСтроке.ТипСтроки=ПереводимаяСтрока:
Catalogs/Банки/Forms/ФормаЭлемента/Module_en.trans:Изменить.Результат.Name=Результат Documents/ЧекККМКоррекции/mdo_en.trans:Attribute.Кассир.Name=Кассир Documents/СчетФактура/ManagerModule_en.trans:ИнициализироватьДанныеДокумента.String.ЭтоПродажа.Key=ЭтоПродажа AccumulationRegisters/БонусныеБаллы/RecordSetModule_en.trans:ПриЗаписи.Запрос.Lines.БонуснаяКарта.Content=БонуснаяКарта AccumulationRegisters/БонусныеБаллы/RecordSetModule_en.trans:ПриЗаписи.Запрос.Lines.Expr.НомерСтроки.Alias=НомерСтроки
Теперь "переведём" этот файл по нашему словарю дублей и проверим, где образовались одинаковые переводы внутри общего контекста.
Скрипт, с помощью которого был получен словарь опасных дублей (см. комментарии в коде):
# 1 Выбираем переводы только для нужных типов строк
# получили строки формата 'ПутьКФайлу:ПутьКПереводимойСтроке=ПереводимаяСтрока'
# 2 убираем ПутьКПереводимойСтроке (всё что между : и =)
# 3 убираем строки с рпобелами
# 4 к полученному списку добавляем перечень имён объектов метаданных из файла Configuration.mdo
# 5 оставляем строки с кириллицей
# 6 сортируем и оставляем только уникальные слова
cat \
<(grep -Pv '\.Lines=|\.Content=|\.Description=|\.TaskDescription=|\.Comment=|^Comment=|\.Condition=' all_trans_w_path.txt |\
sed -E 's/:.*?=/=/' |\
grep -v ' ') \
<(grep -Po '\..*?\<\/' Configuration.mdo | \
sed 's/[\<\/]//g' |
sed 's/\./Configuration\.mdo=/') |\
grep -P '=.*?[а-яА-Я]+' |\
sort | uniq | sed 's/=/ /' \
> trans_w_path_filtered.txt
# 6 сворачиваем предыдущий список, оставляя только уникальные сочетания путь+слово,
# 7 присоединяем переводы из файла join_all_uniq_keys_duplicate_values.txt:
awk 'NR==FNR {file1[$1]=$0; next} $2 in file1 {print $1 " " file1[$2]}' join_all_uniq_keys_duplicate_values.txt
<(awk '!a[$0]++' trans_w_path_filtered.txt) > used_duplicates_grouped.txt
# 8 оставляем строки, по которым есть одинаковые сочетания "путь - перевод"
# (для каждого пути остальись только уникальные ключи после предыдущей операции):
awk 'n=x[$1$3]{print n"\n"$0;} {x[$1$3]=$0;}' used_duplicates_grouped.txt > used_duplicates_grouped_filtered.txt
# получили список вида "путь слово перевод"
# 9 убрали путь, оставили уникальные сочетания "слово перевод":
awk '!a[tolower($2$3)]++{print $2 " " $3}' used_duplicates_grouped_filtered.txt | sort -k 2 >
used_duplicates_grouped_filtered_uniq.txt
Полученный файл used_duplicates_grouped_filtered_uniq.txt является словарём из 900 опасных дублей, которым нужно вручную дать отличающиеся переводы. Результат работы я сохранил в файл used_duplicates_grouped_filtered_uniq_removed.txt
(На самом деле не все эти дубли являются опасными и список можно ещё сократить, но это требует более сложного анализа.)
Теперь с помощью уже использованного выше приёма внесём в словарь join_all_uniq_keys.txt изменения из файла used_duplicates_grouped_filtered_uniq_removed.txt:
cat <(awk 'FNR==NR {f2[$1];next} !($1 in f2)' used_duplicates_grouped_filtered_uniq_removed.txt join_all_uniq_keys.txt)
used_duplicates_grouped_filtered_uniq_removed.txt > join_all_uniq_keys_uniq_values.txt
Оставшиеся в файле дубли считаем безопасными, т.е. после перевода конфигурации они не приводят к конфликтам внутри общего контекста. Для корректной работы плагина их достаточно разделить хотя бы по регистру.
Получим список дублей:
awk 'NR==FNR{s[$2]++;next} (s[$2]>1)' join_all_uniq_keys_uniq_values.txt join_all_uniq_keys_uniq_values.txt | sort -k2 >
case_duplicates.txt
Как и ожидалось, у нас осталось 2700 дублей.
Для разделения дублей по регистру используем следующий подход:
- Составные лексемы из двух и более слов на примере ПолноеИмяРеквизита AttributeFullName
- Для дубля приводим к верхнему регистру первое слово: ATTRIBUTEFullName
- При наличии второго дубля приводим к верхнему регистру второе словао: AttributeFULLName
- Для всех последующих дублей приводим к верхнему регистру начальные буквы: ATtributeFullName, ATTributeFullName и т.д.
- Одиночные слова на примере Active
- Для каждого последующего дубля приводим к верхнему регистру ещё одну начальную букву: Active, ACtive, ACTive и т.д.
Скрипт, выполняющий данное преоброазование:
cat \
<(awk 'seen[$2]++ == 0' case_duplicates.txt) \
<(awk 'seen[$2]++ == 1' case_duplicates.txt \
| sed -r 's/( [A-Z]+)([A-Z][a-z].*$)/\L\1\E\2/' \
| sed -r 's/( [A-Z][a-z]+?)([A-Z].*)/\U\1\E\2/' \
| sed -r 's/( [A-Z][a-z])([a-z0-9]*$)/\U\1\E\2/') \
<(awk 'seen[$2]++ == 2' case_duplicates.txt |\
sed -r 's/( [A-Z][a-z]+?)([A-Z][a-z]+)(.*)/\1\U\2\E\3/' |\
sed -r 's/( [A-Z][a-z]{2})([a-z]*$)/\U\1\E\2/') \
<(awk 'seen[$2]++ == 3' case_duplicates.txt | sed -r 's/( [A-Z][a-z]{3})(.*$)/\U\1\E\2/') \
<(awk 'seen[$2]++ == 4' case_duplicates.txt | sed -r 's/( [A-Z][a-z]{4})(.*$)/\U\1\E\2/') \
<(awk 'seen[$2]++ == 5' case_duplicates.txt | sed -r 's/( [A-Z][a-z]{5})(.*$)/\U\1\E\2/') | \
sort -k2 > case_duplicates_removed_auto.txt
Это позволило автоматически обработать 2600 строк списка дублей, результат помещён в файл case_duplicates_removed_auto.txt
Оставшиеся 100 строк я обработал вручную и сохранил в файл case_duplicates_removed_manual.txt
Внесём изменения из этих двух файлов в наш словарь join_all_uniq_keys_uniq_values.txt:
cat <(awk 'FNR==NR {f2[$1];next} !($1 in f2)' case_duplicates_removed_auto.txt join_all_uniq_keys_uniq_values.txt)\
case_duplicates_removed_auto.txt > join_all_uniq_keys_uniq_values_case_sensitive.txt
cat <(awk 'FNR==NR {f2[$1];next} !($1 in f2)' case_duplicates_removed_manual.txt\
join_all_uniq_keys_uniq_values_case_sensitive.txt) case_duplicates_removed_manual.txt\
> join_all_uniq_keys_uniq_values_case_sensitive_final.txt
На этом закончено составление словаря идентификаторов.
4. Строковые литералы
Когда мы отфильтровали переводимые строки УНФ, убрав строки с пробелами и точками, размер словаря сократился с 335 000 до 260 000 тысяч строк. Что это за 75 000 строк, которые мы выкинули?
Это например описания процедур и функций:
AccumulationRegisters/ПлатежныйКалендарь/RecordSetModule_en.trans:ПриЗаписи.Description=Процедура - обработчик события ПриЗаписи набора записей.
Комментарии объектов метаданных:
AccumulationRegisters/СдельныеНаряды/mdo_en.trans:Resource.НормоЧасы.Comment=Загрузка в часах
Или просто встретившиеся в коде строки, которые плагин не смог распознать (типизировать). Среди них есть как "пользовательские" строки, которые не интересуют нас в рамках работы по переводу кода, так и "системные", котрые обязательно нужно перевести иначе получим неработоспособную конфигурацию.
Характерный пример - программная модификация текста запроса через функцию СтрЗаменить(). Скажем, такой код из модуля ВариантыОтчетов:
Запрос = Новый Запрос;
ТекстЗапроса =
"ВЫБРАТЬ
| ВариантыОтчетов.Ссылка КАК Ссылка
|ИЗ
| Справочник.ВариантыОтчетов КАК ВариантыОтчетов
|ГДЕ
| НЕ ВариантыОтчетов.ПометкаУдаления
| И ВариантыОтчетов.ТипОтчета = &ТипОтчета
| И ЕСТЬNULL(ВариантыОтчетов.Отчет.ПометкаУдаления, ИСТИНА)";
ИмяТаблицы = "Справочник.ВариантыОтчетов";
Если Режим = "ОбщиеДанныеКонфигурации" Тогда
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, ".ВариантыОтчетов", ".ПредопределенныеВариантыОтчетов");
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "И ВариантыОтчетов.ТипОтчета = &ТипОтчета", "");
ИмяТаблицы = "Справочник.ПредопределенныеВариантыОтчетов";
КонецЕсли;
Запрос.Текст = ТекстЗапроса;
СсылкиУдаляемыхВариантов = Запрос.Выполнить().Выгрузить().ВыгрузитьКолонку("Ссылка");
Плагин переведёт весь код и текст запроса, но он не знает как интерпретировать строку "И ВариантыОтчетов.ТипОтчета = &ТипОтчета". Поэтому вся строка целиком пойдёт в словарь и для неё нужно задать отдельный перевод, не смотря на то что в словаре уже есть перевод по отдельности для "ВариантыОтчетов" и "ТипОтчета".
Чтобы не переводить одно и то же несколько раз, воспользуемся следующим приёмом: выделим из файла all_trans_w_path.txt интересующие нас строковые литералы, а затем заменим все слова на их перевод из подготовленного уже словаря идентификаторов.
Составление словаря строк:
grep -P '\.Lines=' all_trans_w_path.txt |\
sed -r 's/^.*?\.String\.(.*?)\.Lines=/\1~/' |\
# в контекстном словаре ключ сохраняется с символами пробела, табуляции и переноса строки в начале и конце строки,
# а в общем словаре они обрезаются; удаляем эти символы чтобы преобразовать формат от контекстного словаря к общему:
sed -r 's/^(\\\ |\\t|\\n)*// ; s/(\\\ |\\t|\\n)*~/~/' |\
awk -F'~' '!seen[$2]++' > tmp/trans_w_path_lines.txt
Перевод словаря строк по словарю идентификаторов:
sed -r 's/(^.*?) (.*)/s\/\\b(\[nt\]\?)\1\\b\/\\1\2\/g/' join_all_uniq_keys_uniq_values_case_sensitive_final.txt > common_en_script.txt
sed -rf common_en_script.txt <(cut -d~ -f2 trans_w_path_lines.txt) > trans_w_path_lines_values_trans.txt
paste -d' ' <(cut -d~ -f1 trans_w_path_lines.txt) trans_w_path_lines_values_trans.txt > trans_w_path_lines_translated.txt
Всё готово! Объединяем словарь идентификаторов и словарь строк, вносим небольшие правки и формируем итоговый файл словаря common_en.dict: заменяем разделитель (пробел) на знак '=', добавляем необходимую шапку файла и приводим окончания строк к формату Windows:
cat tmp/join_all_uniq_keys_uniq_values_case_sensitive_final.txt tmp/trans_w_path_lines_translated.txt |\
LC_COLLATE=C.UTF-8 sort -k1b,1 |\
sed -r 's/([^\\]) /\1=/' | sed '1i#Translations for: common' |\
perl -p -e 's/\n/\r\n/'\
> common_en.dict
4. Анализ полученного словаря
Общее количество строк в словаре идентификаторов УНФ 1.6 260 000 шт.
В нашем словаре идентификаторов 58 000 слов, что составляет 22% от общего количества.
Чтобы получить процент перевода кода и модели конфигурации, подсчитаем долю по количеству мест использований слов.
Общее количество использований переводимых строк в УНФ 1.6 512 000 шт.
Из них по нашему словарю переводится 295 000 мест использования.
Можно оценить, что доля перевода исходного кода конфигурации примерно равна 58%
Из конфигурации удалены наиболее объёмные по тексту объекты российской специфики - регламентированные отчёты, обработки ЭДО, классификаторы типа ВЕТИС и пр.
5. Полезные команды
- Вывод дублей по колонке 1 ($2 - по второй, можно по сочетанию колонок, например $1$3 - первая и третья)
awk 'n=x[$1]{print n"\n"$0;} {x[$1]=$0;}' file
На практике этот способ хорошо сработал при поиске дублей по первой колонке, но при поиске дублей по второй колонке часть строк вывода задваивалась. Поэтому я использовал...
- Альтернативный способ поиска дублей по колонке:
awk 'NR==FNR{s[$2]++;next} (s[$2]>1)' file file - Удаление строк с дублями по колонке (сочетанию колонок). Остаются только строки с уникальным значением ключа.
Вывод строк с уникальными значениями колонок номер 2 и 3. Остальные колонки отбрасываются:
awk '!a[$2$3]++{print $2 " " $3}' file
Вывод строк с уникальными значениями колонок номер 2 и 3. Выводится вся строка (все колонки):
awk '!a[$2$3]++' file - Соединение файлов по ключевой колонке (или сочетанию колонок):
awk 'NR==FNR {f1[$1]=$0; next} {print $1 " " f1[$2]}' file1 file2
В отличие от командыjoin, не требуется сортировка файлов. Это важно когда хочется сохранить порядок строк после мёрджа. - Вывод всех строк файла2, для которых нет соответствия в файле1 по заданному ключу:
awk 'FNR==NR {f2[$1];next} !($1 in f2)' file1 file2
6. Дальнейшие планы
С помощью предложенных в статье приёмов можно на основании имеющихся словарей собрать и нормализовать словарь для перевода конфигурации. В моём примере существующих ресурсов хватило на перевод 58% исходного кода. Чтобы увеличить процент и продвинуться в переводе дальше - необходимо создание новых словарей. Сейчас это в основном решается силами переводчиков, т.к. качество машинного перевода идентификаторов оставляет желать лучшего, и в конечном итоге словарь составляется/редактируется человеком. В следующей статье мы посмотрим, как можно улучшить качество машинного перевода, чтобы минимизировать участие человека.
7. Приложения
В архиве DemoBuild.zip вы можете найти демо-версии всех использованных словарей и скрипт выполняющий сборку итогового словаря по описанному в статье алгоритму. Нужно распаковать архив и запустить compile_common_en.sh - будет создан файл словаря common_en.dict
Вступайте в нашу телеграмм-группу Инфостарт