Введение ^
В нашей конфигурации «Центр управления кассами» ежедневно разные инструменты загрузки проливают большие объемы данных. Это и кассовые операции, и данные о сменах с отчетами кассира, и эквайринг, и технические данные. На текущий момент самый большой по объему загружаемый тип документов принимает в себя около 6 миллионов экземпляров ежедневно. А при этом ещё в базе работает множество пользователей. Так что вопрос оптимального механизма загрузок стоял остро и мы понимали, что нужны инструменты, позволяющие обрабатывать такой поток информации.
До этого данные грузились более «по старинке». Обычные обработки загрузки, которые были неудобными, медленными. Требовали много лишних действий. Причем как от пользователей, которые должны были контролировать весь процесс загрузки данных, так и от администраторов и разработчиков, которые эти инструменты поддерживали и дорабатывали.
Часть загрузок была однопоточной, что само по себе медленно. Другая часть пыталась использовать фоновые задания, но из-за различных нюансов делала это неэффективно. Утечки памяти, потери фоновых. В каждом инструменте был свой подход со своими «особенностями» и поддерживать это было достаточно трудоёмко.
Пришла пора всё переделать. В наших реалиях инструменты загрузки должны быть:
-
Автоматизированными. Не должно быть спец. отделов, задача которых - нажимать кнопочки в нужном порядке и следить, чтобы ничего нигде не ругалось.
-
Стабильными. Минимум «падений», никаких потерь.
-
Удобными. Чем «юзабельнее» инструменты, тем легче с ними работать.
-
Быстрыми. Насколько вообще это возможно при таких условиях.
-
Оптимальными. Нужен баланс между скоростью доставки данных и комфортной работой пользователей в базе.
-
Логируемые. Что, когда и почему не загрузилось? Ответы нужно найти вчера.
-
Настраиваемыми. Ситуации бывают разные и иногда нужно запустить инструмент с особыми параметрами выполнения.
-
Масштабируемыми. Никто ведь не хочет, чтобы разработка каждый раз превращалась в длительный проект.
Идеальный механизм не создать, но задача нас как разработчиков — к нему стремиться. И на данный момент наши инструменты успешно трудятся уже несколько лет и в достаточной мере соответствуют каждому из описанных пунктов. А далее в статье мы расскажем, что и как у нас получилось.
«В начале была архитектура» ^
«Центр управления кассами» (или сокращённо ЦУК) — это конфигурация собственной разработки компании с внедрёнными подсистемами БСП (на данный момент 3.0.1.293).
Архитектуру мы прорабатывали сами, основываясь на предыдущих разработках и необходимостью интеграции с другими действующими продуктами в компании.
Функционально в базе каждый пользователь должен работать только с данными своей «Организации». Ему не нужно и не положено видеть чужие.
Однако, есть особые люди, которые должны видеть все данные, собирать сводные отчеты и вообще работать в базе без подобных ограничений.
Что мы сделали — разделили загружаемые документы на «области данных».
В конфигурации есть общий реквизит «РазделительУчета», у которого включен режим разделения данных. Значение этого реквизита зависит от выбранной организации в документе. В результате данные каждой организации пишутся в отдельной «области данных». Также у общего реквизита стоит режим разделения данных «Независимо и совместно». Это даёт возможность запускать сеансы как конкретной области данных, ограничиваясь одним значением РазделителяУчета, так и работать в «общем» сеансе, не используя никаких ограничений.

А что это даёт нашим загрузкам? Позволяет добиться как можно большего распараллеливания, о чем подробнее будет сказано далее.
«Из чего всё состоит?» ^
Что вообще у нас происходит? Есть источник данных — специальная система, которая в момент обращения наполняет свои таблицы свежей порцией записей. В ней находятся колонки «примитивных» типов: строки, числа, даты.
Как происходит обращение из 1С? В самом низу окна конфигуратора есть объект метаданных, который, хоть и нечасто используется 1Сники, но очень подходит для нашей задачи. ВнешнийИсточникДанных. Каждая таблица внешней системы добавляется в ЦУК, прописываются её колонки и методы, а дальше платформа позволяет работать с ними в коде и запросах.

Задача наших инструментов загрузки — регламентно выбирать эти записи, стыковать с данными ЦУКа и создавать документы. При этом в момент стыковки проводить как можно больше проверок корректности заполнения и выявлять ошибки на всех этапах.
Что же делать с ошибками? ^
Ошибки могут случаться совершенно разные:
-
ошибки стыковки: не определено нужное подразделение, найдено несколько контрагентов и т.д.
-
ошибки проверок: документ в закрытом периоде, не заполнен обязательный реквизит, указана неверная аналитика и т.п.
-
непредвиденные ошибки: не удалось провести документ, упало фоновое задание и любые другие технические ошибки, которые, хоть и возникают крайне редко, но также должны фиксироваться.
Чем больше данных, тем больше возможно ошибок. И все они без потерь должны быть в результате доставлены в ЦУК не блокируя работу ни самих загрузок, ни пользователей. Было решено сделать просто — хранить все непрогруженные данные в своих регистрах. Из которых механизм загрузки должен уметь создавать документы по той же логике, что и при загрузке из основного источника.

Теперь по каждому виду загрузки к внешнему источнику добавляется ещё и регистр «ошибочных записей». Измерения у него — ключевые колонки из источника, а ресурсы — все остальные. Так же обязательно добавляется строковый ресурс «ОписаниеОшибок», в котором будут заполняться все выявленные ошибки по текущей записи.
Нужна ли нам история ошибок? Обязательно! До тех пор, пока «сырая» запись не превратится в документ, мы должны хранить её в регистре и вести историю изменений как самих данных, так и описаний ошибок. Поэтому делаем регистры периодическими. Это нам поможет в дальнейшем разобраться в ситуации.
Инструменты работы с ошибками ^
Как помним, ошибки бывают разные. Есть те, которые случились из-за неудачного стечения обстоятельств. Они попадут в регистр и будут прогружены позднее автоматически. Есть те, которые также были временными. Например, приехал документ с аналитикой, которая ещё не закодирована в базе. Такое иногда случается. Но ничего страшного, ведь, как только в ЦУК появятся нужные элементы, следующий цикл прогрузки ошибочных записей сделает своё дело.
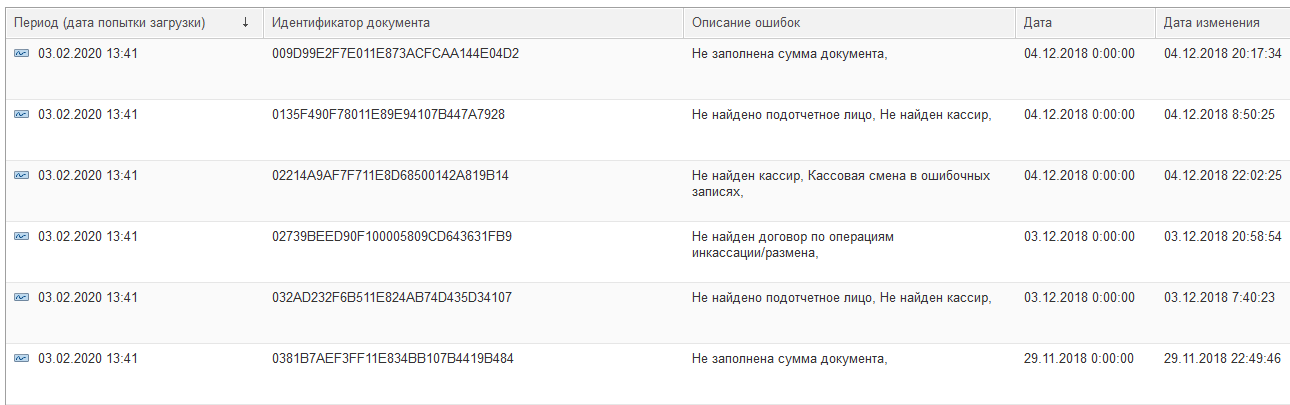
Но случаются и более сложные ситуации. Например, почему-то к нам приехали данные, которых вообще не должно было быть. Как же нам потом анализировать и обрабатывать накопленные ошибки? Нужен отчет!
Для каждого вида загрузки добавляется отчет. Он показывает пользователю, что за данные сейчас лежат в регистре и по какой причине. Отчет должен уметь отображать самые актуальные описания ошибок, а не только те, которые были зафиксированы в момент записи в регистр. Таким образом, ответственный пользователь может увидеть, что часть данных уже не считаются ошибками, а значит по ним можно не беспокоиться — при следующей прогрузке они превратятся в документы. А вот какие-то данные, например, почему-то приехали за закрытый период. А эти вообще с пустыми обязательными реквизитами. Нужно выяснить: что это и по какой причине появилось. Хорошо, что у нас для этого есть отчет, верно?
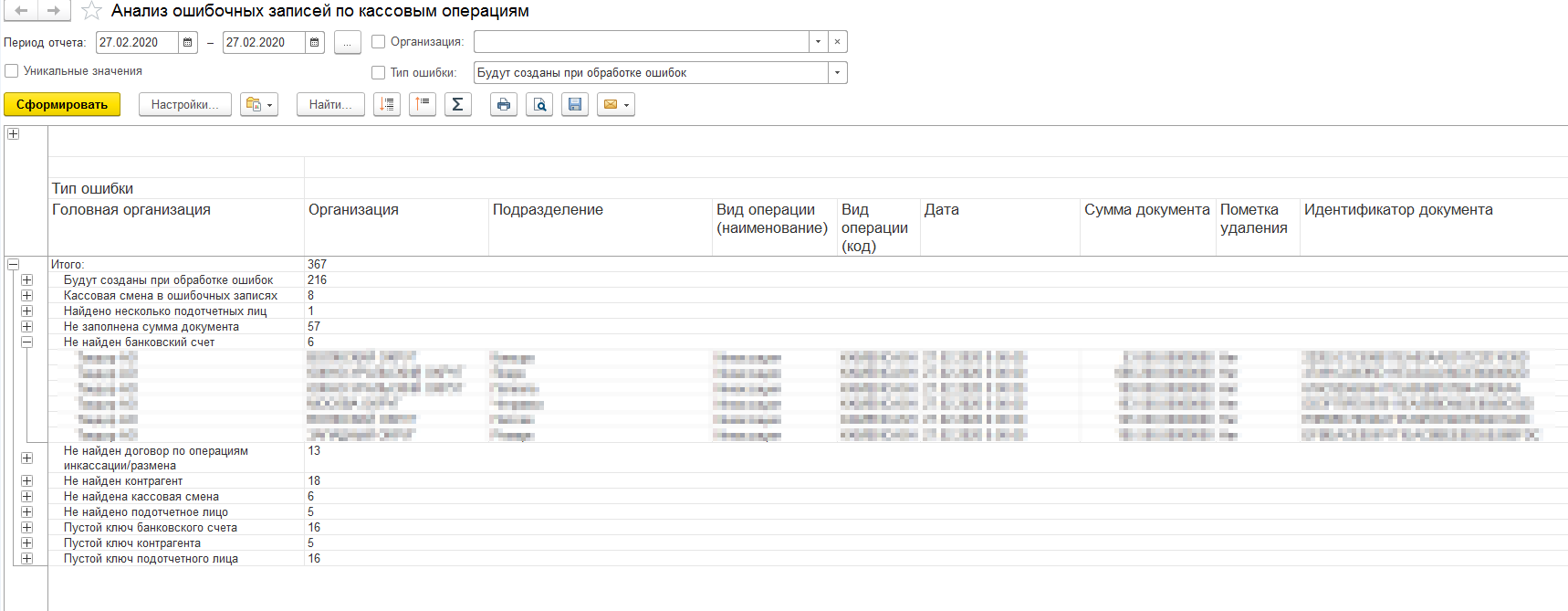
Так же наряду с отчётом есть возможность добавить инструмент по точечной загрузке ошибочных записей. Он позволяет особо ответственным пользователям, не дожидаясь регламентной загрузки, обработать конкретные записи из регистра. А также показывает отчет с разной информацией. Например, какие реквизиты каких документов будут в результате изменены или как текущая прогрузка повлияет на нумерацию кассовых документов.

Оба этих инструмента должны работать по той же самой логике, что и сама загрузка данных. Но и не дублировать эту же логику и там и сям. Никому ведь не хочется потом поддерживать повторяющиеся куски кода и запросов... Но это и не обязательно. Ведь мы можем вызывать сам инструмент загрузки данных и пользоваться его методами и алгоритмами. Так мы и сделали, и в результате сам отчет содержит в себе полупустую СКД, которая автоматически дополняется как самими данными, так и доступными пользователю колонками. Мы всё равно будем выполнять методы самой обработки.
Обработки загрузки данных ^
Ну вот мы подобрались ближе к основным механизмам загрузки данных.
У каждого вида есть своя обработка. Каждую обработку можно запустить:
- Интерактивно (администратором или ответственным пользователем)
- Регламентно (по заданному расписанию)
- Программно (из других инструментов)
- Извне (внешним соединением)
Загружать данные можно из:
-
Внешнего источника (основной режим запуска)
-
Ошибочных записей (выборка из нашего регистра)
-
Файл или каталог с файлами
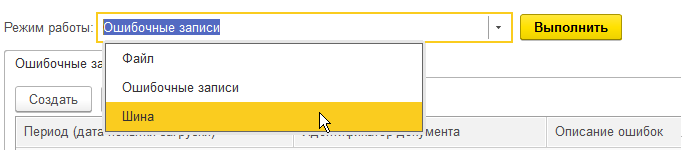
Каждая обработка содержит в себе:
-
Настройки выборки и хранения данных
-
Логика стыковки
-
Проверка корректности
-
Заполнение документа
-
Прочие технические настройки
Обработки содержат в себе всё то, что уникально для конкретного вида загрузки данных. И каждая обработка также не является самостоятельной единицей. Ведь, есть единый механизм, который и выполняет большую часть логики.
Общий механизм ^
И вот наконец-то мы добрались до основного механизма. Вся логика описана в одном общем модуле, который получает на входе обработку загрузки и параметры выполнения.
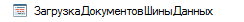
Общий модуль:
-
Содержит в себе основную логику выполнения
-
Получает на вход уточняющие параметры и обработку загрузки
-
Выполняет все необходимые действия, согласно параметрам выполнения
-
Вызывает события из обработки загрузки
-
Пишет лог выполнения в регистр на каждом этапе
Логирование ^
Это тоже важный пункт. Нужно иметь возможность посмотреть кто, когда и как выполнял. Поэтому в нашей подсистеме есть общий для всех загрузок регистр сведений. В нём хранится информация о каждом этапе, выводимые сообщения, некоторые параметры запуска и так далее. В том числе, хранится файл с данными из внешнего источника данных, который можно посмотреть в виде таблицы прямо в Предприятии. А можно сохранить данные в файлик для дальнейшего разбора и опять же загрузки через наш механизм.

Схема взаимодействия инструментов ^
Итак, сейчас у нас для каждой загрузки есть:
-
Таблица в внешнем источнике данных
-
Обработка загрузки
-
Регистр ошибочных записей
-
Отчет по ошибочным записям
-
Возможно наличие выборочной загрузки ошибок
Также имеются общие для всех загрузок объекты:
-
Общий модуль механизма
-
Регистр сведений логирования
Вот так в результате выглядит их взаимодействие:

-
Пользователь работает с отчетом по ошибкам и выборочной загрузкой ошибок.
-
Пользовательские инструменты обращаются в соответствующую обработку загрузки
-
Регламентное задание по расписанию выполняет стандартные загрузки
-
Администратор также может запускать непосредственно обработку загрузки. Например, иногда внепланово нужно пролить данные из другой таблицы внешнего источника с особыми отборами. Тогда администратор настраивает нужным образом обработку и выполняет её.
-
Обработка загрузки сама ничего не делает — она передаёт себя в общий модуль.
-
Общий модуль выполняет выборку данных, запись ошибок в регистр, логирование каждого этапа, а потом возвращает необходимую информацию обратно вверх по цепочке.
Как это работает? ^
Как же происходит загрузка данных?

Общий модуль выполняет этапы:
-
Выборка данных источника
-
Стыковка с данными нашей базы
-
Определение и запись ошибок
-
Многопоточная прогрузка данных фоновыми заданиями
-
Сбор всех данных и анализ результата
Сначала происходит выборка загружаемых данных. Это либо строки из таблицы внешнего источника, либо записи регистра ошибок, либо файл данных из лога.
Далее используется специальный запрос, внутри которого происходит стыковка всей информации с базой ЦУК. Также в рамках этого запроса и происходят проверки на ошибки. По содержашим ошибки записям ставится флаг «ЕстьОшибки» и заполняется «ОписаниеОшибок».
Когда все стыковки и подготовки данных завершаются, то отделяются ошибочные записи от корректных. Ошибки пишутся в регистр, а вот корректные данные отправляются в дальнейшее превращение в документы.
Распараллеливание ^
Самый долгий процесс — запись данных в базу. Этот этап нужно было максимально ускорить. И тут нам на помощь пришёл наш общий реквизит «РазделительУчета», о котором говорилось в самом начале.
Как происходит распараллеливание:
-
Все данные разбиваются на порции по разделителям учета.
-
На каждую порцию запускается своё фоновое задание с включенным разделением данных (ФоновоеЗадание.РазделениеДанных)
-
В каждом фоновом задании происходит обработка порции данных, запись возникающих ошибок, подсчёт статистики и прочие технические действия.
-
Родительский сеанс в это время опрашивает свои ФЗ, собирает и обрабатывает по ним результаты выполнения. Если вдруг какое-то задание не выполнилось (упало, отменено), то вся порция данных этого задания помещается в регистр ошибочных записей с соответствующей ошибкой. Это позволяет нам быть уверенными, что все данные из источника попадут в нашу базу.
Эта стандартная картина может усложняться. Например, в пики больших объемов, каждое дочернее фоновое задание может порождать ещё потоки. В результате, на один РазделительУчета могут трудиться уже не одно, а несколько фоновых заданий по проведению документов. Например, таким образом, чтобы количество записей в каждом потоке было усреднено. В таком случае берётся общее число записей в каждом основном потоке, определяется среднее число на каждый дополнительный поток и распределяются равномерно загружаемые строки.
В результате грамотного распараллеливания скорость загрузки данных заметно увеличивается. В зависимости от типа документов, некоторые загрузки добавляют в базу больше 50 тысяч документов за 2 минуты. Некоторые, 1.5 миллиона документов за час. Такие показатели вполне удовлетворяют потоку компании.
А что под капотом? ^
Теперь, когда ясна архитектура и само взаимодействие между объектами, можно рассказать об устройстве внутри них.
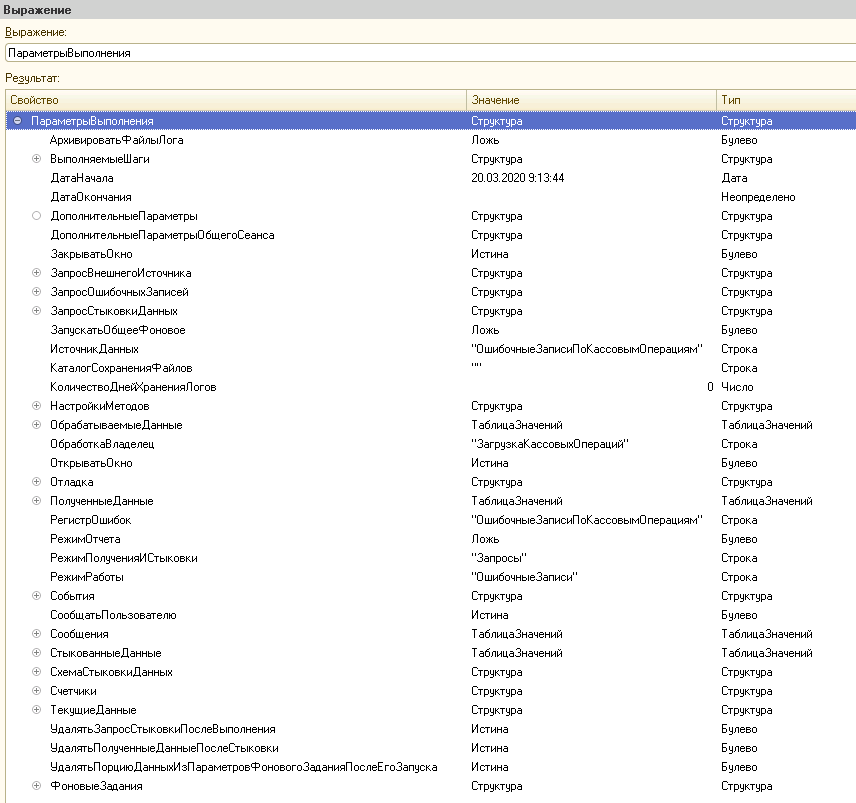
Центром является общий модуль. Он принимает в себя обработку с параметрами. Структура параметров — это, можно сказать, одна основная переменная, содержащая в себе большое количество свойств и подсвойств.
-
Основные (обязательные) настройки. Обработка загрузки, Регистр ошибок, таблица внешнего источника и так далее.
-
Накапливаемые данные о ходе выполнения. Сообщения пользователю, счетчики, статистики.
-
Настройки логики. Например, таймаут одного ожидания фоновых заданий или стоит ли дополнительно записывать файл данных в каталог.
-
Оперируемые данные. Это и выбранные записи и результат запроса стыковки. В общем, все те данные, которыми оперирует механизм в процессе выполнения. Они также хранятся в этой единой переменной. Это позволяет в любой момент получить к ним доступ и обработать так, как нужно разработчику в конкретной обработке загрузки.
-
Выполняемые шаги и события. Это «ПередПолучениемДанных», «ПередСтыковкойДанных», «ПередЗапускомФоновогоЗадания», «ПередДобавлениемСообщения». Как раз при помощи этого разработчик конкретной обработки загрузки может оперировать данными и в нужный момент времени либо обработать их по своему, либо полностью отказаться от выполнения текущего шага.
-
Дополнительные значения. Произвольные данные, к которым можно обращаться по мере необходимости.
Построенная система позволяет добавлять новую обработку загрузки данных, не прописывая бОльшую часть кода самому, а лишь донастраивая текущую под себя. Если же появляется необходимость какой-то новой фичи в инструменте загрузки, то мы можем добавить её сразу в общий модуль и она будет доступна во всех базируемых на нём инструментах.
Выводы ^
На выходе мы имеем большой универсальный механизм, который заметно ускоряет разработку и доработку обработок по загрузке данных. Контроллировать все этапы и анализировать статистику выполнения. Быть уверенными, что данные в любом случае будут доставлены в ИБ и нигде не затеряются. Да, нет идеальных систем и в нашей также есть что дорабатывать, однако, и на данном этапе она уже неплоха и мы рады были о ней рассказать.
Понравилась статья?
Покажите это автору своим "плюсом" и комментариями =)
Вступайте в нашу телеграмм-группу Инфостарт