

Алгоритм позволяет кодировать двоичные данные по любому алфавиту, который можно представить в виде строки в поле ввода формы 1С:Предприятие.
На разработку этого решения меня натолкнула публикация: //infostart.ru/public/1153292/ В ней автор решал локальную задачу кодирования и раскодирования последовательности байтов в строку base-58. Исследовав вопрос кодирования, я решил провести эксперимент, какая же максимальная длина целого числа может быть представлена в 1С:Предприятии, чтобы не заниматься перемещением/умножением байтов. Точный ответ на этот вопрос я не получил, потому что умножение действительно длинных целых чисел происходит медленно, но стало ясно, что ограничение, если оно и есть, довольно велико, и для кодирования коротких последовательностей байтов, например ключей, вполне подходит.
Причём, когда-то эта тема уже исследовалась: https://forum.mista.ru/topic.php?id=608985 и там после 2^200 происходил "сбой" в арифметике. В релизе платформы для windows 8.3.16.1296 и 64х и 32х битном можно получать большие степени числа 2, другие релизы и на других платформах я не проверял.
Особенности реализации
Итак, платформа позволяет обрабатывать Большие целые числа. Попробуйте написать простую обработку, в обработке:
Сообщить(pow(2,1024*1024));
Так почему бы не воспользоваться.
Кодирование информации в строку по указанному алфавиту, с такими возможностями гораздо проще, умножай на размер алфавита каждый входящий символ при раскодировании и всё. А при кодировании каждый входящий байт на 256. Возможен любой алфавит. Нет необходимости перебирать байты и их двигать, умножать и т.п. когда 1С:Предприятие 8 позволяет оперировать со сколь угодно большими целыми числами. По крайней мере 2 в степени 1048576 позволяет получить, а это же 1048576 битное число, 128 килобайт данных можно передать таким числом.
Таким образом представляется возможным кодировать короткие сообщения напрямую умножая байты и получая остатки от деления на длину целевого алфавита.
Однако время на работу с длинными числами может быть весьма велико. Так, для кодирования в base-58 произвольной последовательности байт длиной 32768, требуется 4,5 секунды. Правда при этом вставка текста с Hex строкой длиной 65536 символов в поле ввода обработки происходит порядка 30 секунд.
Реализация алгоритма
В представленном коде имеются следующие функции:
КодироватьHex - кодирует строку Hex в строку по переданному алфавиту. Первый параметр - Hex строка, Второй - строка с символами алфавита. Нужна для удобства работы с обработкой и ввода байт в виде hex строки. Вызывает обработку Кодировать. Возвращает строку символов в кодировке алфавита.
Кодировать - кодирует двоичные данные по переданному алфавиту.
РаскодироватьHex - раскодирует строку символов по переданному алфавиту. Первый параметр - кодированная строка, второй - строка с символами алфавита. Вызывает функцию Раскодировать с теми же параметрами, но преобразует возвращаемые двоичные данные в hex строку, для удобства восприятия в обработке.
Функция ЛогарифмПоОснованию считает логарифм по произвольному основанию и позволяет примерно посчитать соотношение длины входных и выходных данных. При расшифровке входящей строки, нужно оценить каких размеров буфер двоичных данных создавать. Это можно сделать представив, что двоичные данные это тоже алфавит, состоящий из 256 "символов", а значит один и тот же объём информации в нём можно закодировать с использованием меньшего (или большего, если реализовать двухсимвольный например алфавит) числа "символов", чем во входящей строке. Соотношение между требуемым количеством символов можно записать как a^x=b, где a - число символов алфавита входной строки, b - число символов "выходной строки" - последовательности байтов. А x - коэффициент, в степень которого нужно возвести a чтобы получить b. Его можно вычислить как логарифм b по основанию а. Но средствами языка 1С можно получить только десятичный и натуральный логарифм. Поэтому получение логарифма по требуемому нам основанию реализовано этой функцией.
Текст кода алгоритма кодирования и раскодирования по произвольному алгоритму:
Функция КодироватьHex(пСтрокаHex, пАлфавит) Экспорт
Возврат Кодировать(ПолучитьДвоичныеДанныеИзHexСтроки(пСтрокаHex), пАлфавит);
КонецФункции
Функция Кодировать(пДвДанные, пАлфавит) Экспорт
лБольшоеЧисло = 0;
лБуферДвДанных = ПолучитьБуферДвоичныхДанныхИзДвоичныхДанных(пДвДанные);
лЧислоБайт = лБуферДвДанных.Размер;
лРазмерАлфавита = СтрДлина(пАлфавит); // Алфавит односимвольный
// Получаем большое число
лСтрока1 = "";
Для Каждого лТекБайт Из лБуферДвДанных Цикл
лБольшоеЧисло = лБольшоеЧисло*256 + лТекБайт;
Если лБольшоеЧисло=0 И лТекБайт=0 Тогда
лСтрока1 = лСтрока1 + Сред(пАлфавит,1,1); // пишем ноль вначале, если лидирующие байты - нулевые
КонецЕсли;
КонецЦикла;
лСтрока2 = "";
// Разделяем на символы
лОстаток = лБольшоеЧисло%лРазмерАлфавита;
лБольшоеЧисло = Цел(лБольшоеЧисло/лРазмерАлфавита);
Пока лОстаток <> 0 или лБольшоеЧисло > 0 Цикл
лСтрока2 = Сред(пАлфавит,лОстаток+1,1) + лСтрока2;
лОстаток = лБольшоеЧисло%лРазмерАлфавита;
лБольшоеЧисло = Цел(лБольшоеЧисло/лРазмерАлфавита);
КонецЦикла;
Возврат лСтрока1+лСтрока2;
КонецФункции
Функция РаскодироватьHex(пСтрока, пАлфавит) Экспорт
Возврат ПолучитьHexСтрокуИзДвоичныхДанных(Раскодировать(пСтрока, пАлфавит));
конецФункции
Функция Раскодировать(пСтрока, пАлфавит) Экспорт
лБольшоеЧисло = 0;
лРазмерАлфавита = СтрДлина(пАлфавит); // Алфавит односимвольный
лДлинаСтроки = СтрДлина(пСтрока);
лНулевойСимвол = Сред(пАлфавит,1,1); // определяем количество лидирующих "нулей"
лКолвоНулевых = 0;
Пока Сред(пСтрока,лКолвоНулевых+1,1) = лНулевойСимвол Цикл
лКолвоНулевых = лКолвоНулевых + 1;
КонецЦикла;
// Лидирующие нули добавляют значащие символы в любой системе счисления 1 к 1, а не как a^x = b
лДлинаБуфера = Окр((лДлинаСтроки-лКолвоНулевых)/ЛогарифмПоОснованию(лРазмерАлфавита,256))+лКолвоНулевых+1; // Создаём буфер с учётом лидирующих "нулей" и небольшим запасом
лБуферДвДанных = Новый БуферДвоичныхДанных(лДлинаБуфера);
// Получаем большое число
лСтрока = "";
нн=0;
Для н=1 по лДлинаСтроки Цикл
лТекЧисло = СтрНайти(пАлфавит,Сред(пСтрока,н,1))-1;
лБольшоеЧисло = лБольшоеЧисло*лРазмерАлфавита + лТекЧисло;
Если лБольшоеЧисло=0 И лТекЧисло=0 Тогда
нн=н;
// лБуферДвДанных.Установить(нн,0); // пишем нулевые байты вначале, если лидирующие символы - нулевые
// писать нулевые байты смысла нет, они и так там нулевые. просто запоминаем сколько нулевых вначале и всё.
КонецЕсли;
КонецЦикла;
// Разделяем на байты
н = 0;
лОстаток = лБольшоеЧисло%256;
лБольшоеЧисло = Цел(лБольшоеЧисло/256);
Пока лОстаток <> 0 или лБольшоеЧисло > 1 Цикл
лБуферДвДанных.Установить(лДлинаБуфера-н-1,лОстаток);
лОстаток = лБольшоеЧисло%256;
лБольшоеЧисло = Цел(лБольшоеЧисло/256);
н = н + 1;
КонецЦикла;
лРеальнаяДлинаБуфера = нн+н;
лДвДанные = ПолучитьДвоичныеДанныеИзБуфераДвоичныхДанных(лБуферДвДанных.Прочитать(лДлинаБуфера-лРеальнаяДлинаБуфера,лРеальнаяДлинаБуфера));
Возврат лДвДанные;
КонецФункции
Функция ЛогарифмПоОснованию(Основание, Показатель)
Возврат Log10(Показатель)/Log10(Основание);
КонецФункции
Примеры алфавитов:
| Base-85 ZeroMQ Version (Z85) | 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ.-:+=^!/*?&<>()[]{}@%$# |
| Base-64 Bash | 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ@_ |
| Base-64 Xxencoding | +-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| Base-64 Unix | ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789/+ |
| Base-64 GEDCOM | ./0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| Base-64 Bcrypt | ./ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789 |
| Base-58 ripple | rpshnaf39wBUDNEGHJKLM4PQRST7VWXYZ2bcdeCg65jkm8oFqi1tuvAxyz |
| Base-58 bitcoin | 123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz |
| Base-58 flickr | 123456789abcdefghijkmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXYZ |
| Base-36 | 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| Base-32 | 0123456789ABCDEFGHIJKLMNOPQRSTUV |
| Vigesimal | 0123456789ABCDEFGHJK |
| Hexadecimal | 0123456789ABCDEF |
| Duodecimal | 0123456789AB |
| Decimal | 0123456789 |
| Octal | 012345678 |
| Ternary | 012 |
| Binary | 01 |
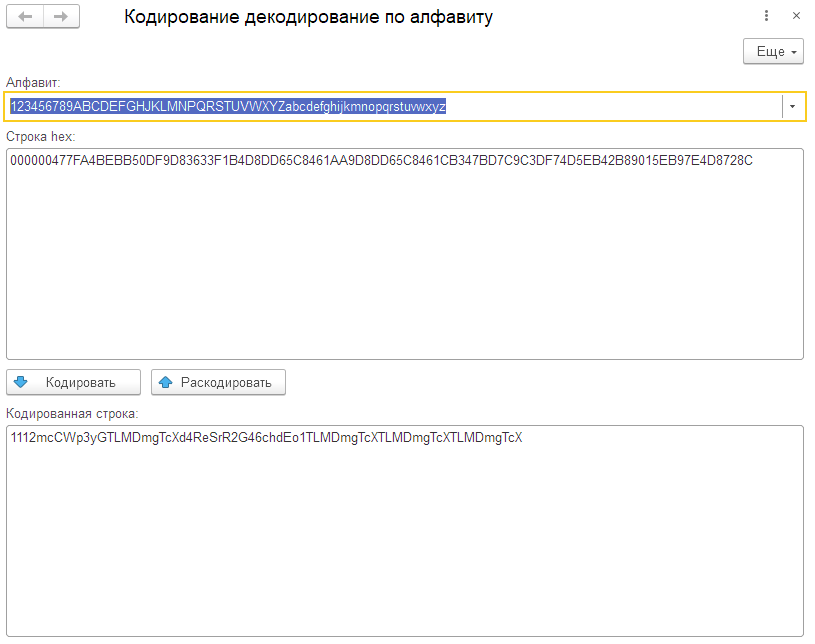
В Обработке реализован представленный код. В форме обработки в поле ввода алфавита есть возможность выбрать из списка различные общепринятые варианты, приведённые в этой таблице.
Примеры:
Base58
Алфавит: 123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz
Входящая строка: AABBCCDDEEFF
Кодированная строка: 2U2BSHrY6
Те же самые байты на входе, но по Base85:
5&-d%hf0
Используемая информация и сервисы:
https://www.appdevtools.com/base58-encoder-decoder
http://lenschulwitz.com/base58
https://www.browserling.com/tools/base58-decode
Проверено на следующих конфигурациях и релизах:
- Управление нашей фирмой, редакция 1.6, релизы 1.1.1.6
Вступайте в нашу телеграмм-группу Инфостарт



{kind=link}