











Оглавление.
-
Процессор
-
Память
-
Диски
Процессор
.Настраиваем энергопотребление на максимальную производительность.
Когда я поставил серверную Ubuntu, я и подумать не мог, что мой процессор будет работать в режиме максимальной экономии. Но это так. Для просмотра текущего состояния выполняем команду.
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
У меня вышло powersave. На самом деле у вас может быть ondemand. Тут вся фишка в том какие режимы может поддерживать ваш процессор. На моей тестовой системе процессор держит только powersave(энергосбережение) и performance(макс производительность).
Отключаем демон, который управляет частотой процессора.
systemctl disable ondemand
Перезагружаем систему и проверяем. Должно быть performance.
Проверяем текущие частоты каждого ядра
grep MHz /proc/cpuinfo
У меня так

cpu MHz : 1608.222
cpu MHz : 900.019
cpu MHz : 800.078
.Прочие настройки процессора
В файле /etc/sysctl.conf прописываем
kernel.sched_migration_cost_ns = 5000000 увеличиваем время выполнения операций на 1 ядре, чтобы долгие запросы не мигрировали с одного ядра в другое.
kernel.sched_autogroup_enabled=0 подробнее тут
В терминале выполняем
lscpu
Если напротив строки NUMA node цифра 1, ничего не делаем, если больше, тогда отключаем NUMA
vm.zone_reclaim_mode = 0
kernel.numa_balancing=0
Память
.HugePages
По умолчанию размер страниц памяти установлен 4 КБ. Можем установить в 2 МБ и 1 ГБ(1 ГБ не везде, подробнее будет ниже). На хабре есть статья тестирования производительности в зависимости от настроек HugePages. Меня привлек следующий раздел статьи

Если я правильно понял, то когда размер базы превышает выделенный Postgre shared_buffers и количество пользователей до 30, то размер страниц в 2 МБ самое то. Например достаточно близкая к реалиям 1с ситуация: сервер с 16 ГБ оперативной памятью, shared_buffers= 4ГБ, размер базы 7 ГБ, пользователей 10.
Проверяем текущие настройки
grep Huge /proc/meminfo
Увидим примерно следующее

получаем

2 момента, если у вас несколько экземпляров на одном хосте, то данную процедуру необходимо выполнить для каждого из них и результаты сложить. Второй момент, количество страниц зависит от настроек памяти в postgresql.conf. Если вы, что-то изменили, необходимо заново промониторить необходимое количество больших страниц.
Устанавливаем настройки в файле /etc/sysctl.conf
vm.nr_hugepages=(количество страниц)
После перезагрузки заново проверим выделение памяти. У меня так:

Чем больше эксплуатируем систему, тем меньше свободных и зарезервированных страниц будет.
Размер страниц 1 ГБ
Если у вас на сервере под 256 ГБ оперативной памяти можно установить данный размер
Проверяем поддерживает ли ваш процессор данную опцию
if grep pdpe1gb /proc/cpuinfo >/dev/null 2>&1; then echo "1GB supported."; fi
Если поддерживает, редактируем файл /etc/default/grub. В строке GRUB_CMDLINE_LINUX добавляем
default_hugepagesz=1GB hugepagesz=1G
выполняем
grub-mkconfig -o /boot/grub/grub.cfg
Перезагружаем систему и выполняем пункты описанные ранее для выделения нужного количества больших страниц нашей БД.
Резервируем HugaPages за PostgreSQL
Это на тот случай, если вы установите в систему еще какое-то приложение, которое может забрать большие страницы для себя.
Выполняем
id postgres
Из того, что увидим, нас интересует gid=1001(postgres)
В файле /etc/sysctl.conf прописываем
vm.hugetlb_shm_group = 1001
Теперь большие страницы памяти будут выделяться только для PostgreSQL.
.Файл подкачки
Уменьшаем агрессивность использования swap.
Устанавливаем настройку в файле /etc/sysctl.conf
vm.swappiness=1
По умолчанию в Ubuntu Server =60, совсем в 0 убирать не стоит, если памяти не хватит, операционка может убить процесс postgre для ее высвобождения.
.Прочие параметры памяти в файле /etc/sysctl.conf
vm.dirty_background_bytes =25% от скорости записи диска в байтах. Объем данных сбрасываемых из оперативки на диск фоновым процессом
vm.dirty_bytes =100-200% от скорости записи диска в байтах. Объем данных сбрасываемых из оперативки на диск выполняемым запросом.
Если у вас железный RAID с кэшем или SSD с кэшем, то vm.dirty_bytes=размер кэша
Что у нас в теории: по умолчанию в ubuntu эти механизмы настроены на 10 и 20% от оперативной памяти, но если у нас 64 ГБ оперативки, то разом на диск может приехать 6 ГБ данных. На практике же у нас в самой PostgreSQL есть настраиваемые параметры сброса данных из оперативной памяти на диск. Как настройки postgre и операционной системы между собой работают не знаю.
vm.overcommit_memory =2 подробнее тут
vm.min_free_kbytes =307200 увеличиваем свободную память до 300 МБ, которая не будет занята файловым кэшем. Если памяти много, то лучше 1ГБ, чтобы фрагментация памяти происходила раньше. По умолчанию 66 МБ.
Диски
.TRIM для ssd
После установки системы Ubuntu раз в неделю посылает команду TRIM ssd дискам, можно перенастроить под свои нужды.
Для начала проверим видит ли ваша система, что это именно ssd диск и команда TRIM туда посылается.
Вариант 1
hdparm -I /dev/sdc3 | grep TRIM
вместо sdc3 ваш раздел.
Вариант 2
lsblk --discard

Выделенное разделы на SSD, с нулем HDD.
Теперь проверим как часто в данный момент срабатывает отправка команды
systemctl list-timers fstrim.timer

Тут мы увидим время последнего выполнения и время следующего запуска команды. У меня система уже настроена на выполнения каждый час, в чистом дистрибутиве настроено выполнение раз в неделю.
Редактируем файл /lib/systemd/system/fstrim.timer
В строке OnCalendar= прописываем расписание выполнения команды
Например:
OnCalendar=hourly -каждый час в 00 минут
OnCalendar=* 4 *** -раз в день в 4 утра
OnCalendar=* 9-20 *** -каждый час с 9 утра до 8 вечера.
Применяем настройки
systemctl daemon-reload
Можно указать параметр discard при монтировании системы в файле /ets/fstab, но пишут, что скорость работы диска снизится.
.Параметры монтирования дисков
Меняем параметры в файле /etc/fstab c
ext4 defaults 0 0
на
ext4 defaults,noatime,nodiratime 0 0
если диск SSD и хотите TRIM при каждом изменении файловой системе, то:
ext4 defaults,noatime,nodiratime,discard 0 0
На самом деле параметров много, еще разбираюсь. Если в комментариях подскажут полезные для работы PostgreSQL буду благодарен.
.Перенос bitmap файл софтового RAID на другой диск
Далее цитата из интернета:
Linux-овый софтрейд поддерживает замечательную фичу: bitmap. Там отмечаются измененные блоки на диске, и если у вас почему-то отвалился один диск из массива, а потом вы его обратно добавили – полная перестройка массива не нужна. Чертовски полезно. Хранить можно на самом рейде – internal, а можно в отдельном файле – но тут есть ограничения (на тип ФС например). Я сделал internal bitmap. И зря. Internal bitmap тормозит безбожно т.к. постоянно дергается головка веников при записи.
Я монтировал RAID при установке системы и bitmap файл был смонитирован на этих же дисках.
Отключаем текущие настройки
mdadm --grow --bitmap=none /dev/md127
Где md127 это наш RAID
Устанавливаем новые настройки
mdadm -G /dev/md127 -b /var/md127_intent
Где md127 наш RAID, md127_intent где будет расположен наш bitmap файл. У меня раздел /var находится на ssd диске.
Заключение
После всех изменений pgbench с настройками "pgbench -c 8 -j 4 -T 600 -v"стал показывать прирост почти на 40% по сравнению с чистой Ubuntu. Размер тестовой базы 7 ГБ.
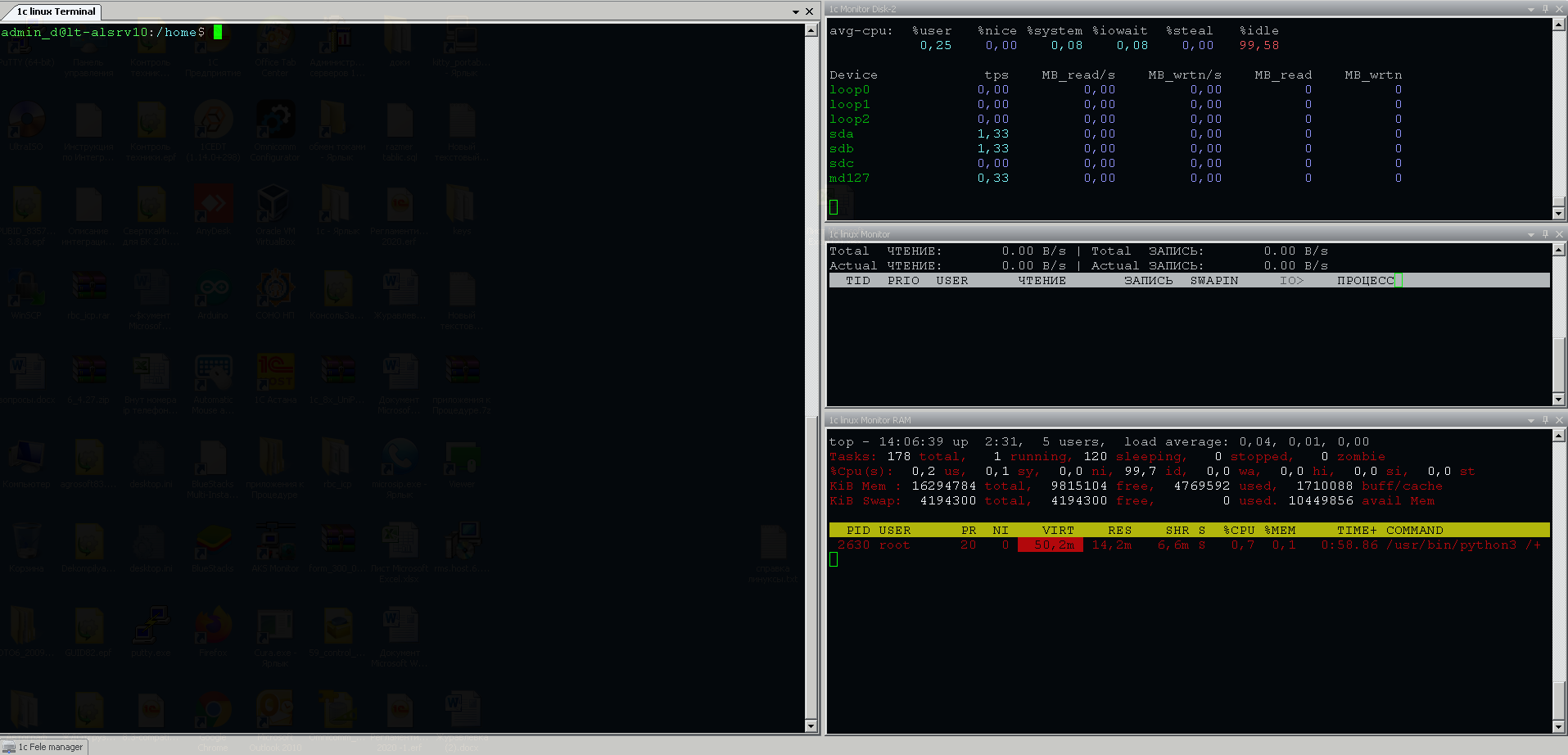
Если формат статей будет интересен, есть возможность рассказать варианте настройке SSH для работы с сервером. Текущий рабочий инструмент сейчас выглядит так. По центру рабочий терминал. Снизу всплывающая вкладка с файловым менеджером, справа три всплывающие вкладки для мониторинга системы. При необходимости их можно закрепить.


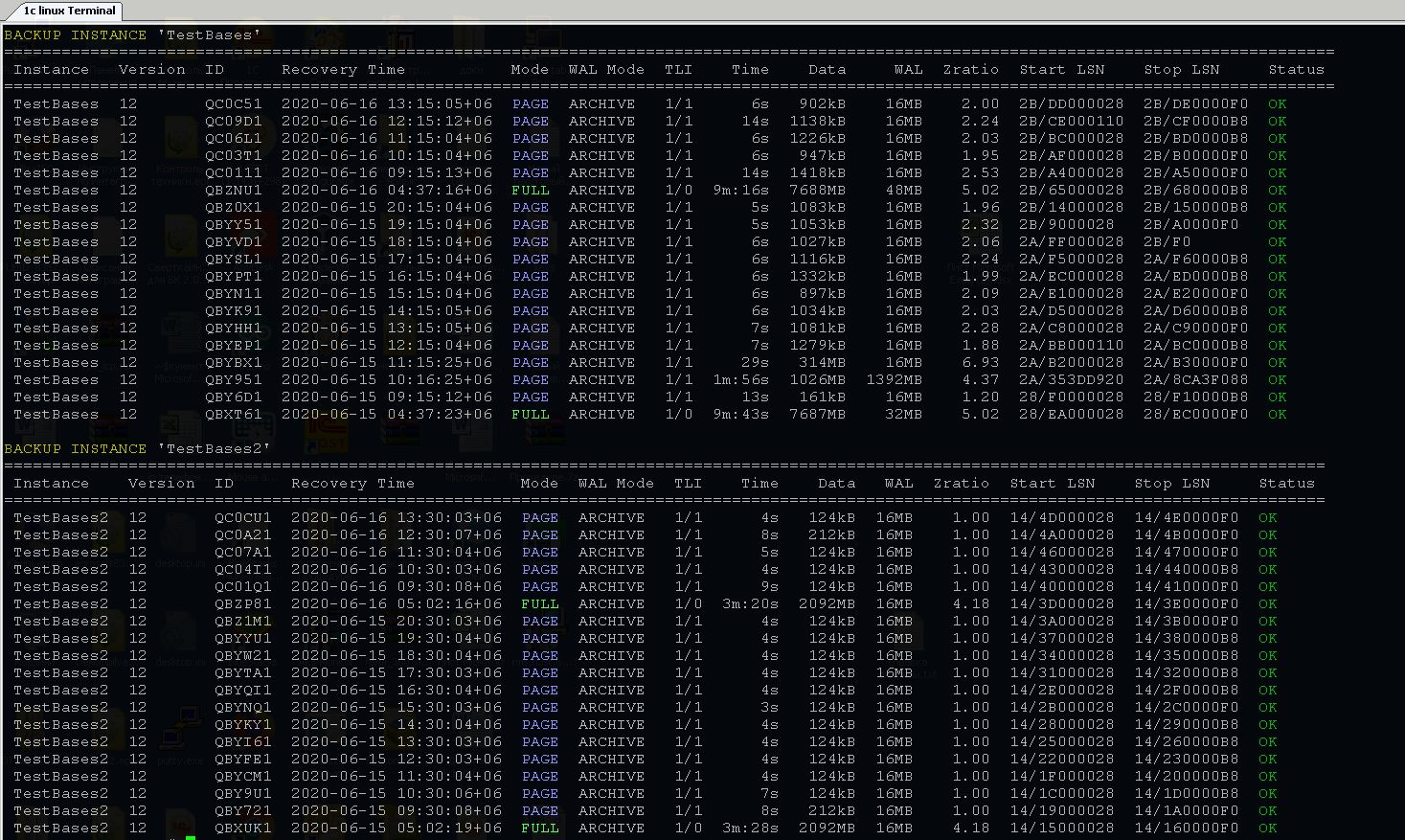
Архивирование делаю при помощи pg_probackup, с небольшой цветовой надстройкой, чтобы удобнее было мониторить бекапы.

Вступайте в нашу телеграмм-группу Инфостарт