
О докладчике

Меня зовут Алексей Шиянов, я программист в компании «БКС-технологии».
-
По образованию я физик – в 2009 году закончил факультет физики Южного федерального университета. Тогда же я начал изучать программирование на C++. Немного программировал на Delphi и даже написал примитивный калькулятор.
-
В 2010 году после окончания университета мне стало интересно заниматься более живым, приближенным к действительности программированием, поэтому я начал изучать 1С.
-
В 2011 году начал работать программистом 1С.
-
В 2013 году передо мной встала задача, за которую никто не хотел браться: нужно было написать сложный многоуровневый отчет. Этот отчет из-за технических ограничений системы мог быть написан только на СКД – я решил, что расшибусь, но отчет этот напишу Так и вышло – я написал этот отчет за две или три недели. Сначала он был достаточно корявый и неуклюжий, но я его причесал, и он используется до сих пор. Это меня сподвигло на дальнейшее изучение возможностей СКД. Я изучил, что СКД может формировать не только табличные документы, но деревья и таблицы значений. С тех пор я использую СКД в нестандартных задачах. Все, что вы увидите в этой презентации, взято из моего опыта.
-
В 2018 году я переехал из Ростова-на-Дону в Новосибирск, в более прохладный климат.
-
А в 2020 году решил впервые поучаствовать в конференции Инфостарта.
Я работаю в компании БКС. Наша компания на рынке 25 лет, мы – брокер № 1 в России. У нас 5 тысяч сотрудников, из них 90 человек – сотрудники 1С. Мы сопровождаем и разрабатываем множество конфигураций 1С.
В докладе:
-
Я расскажу, как решать с помощью СКД те задачи, которые традиционно решаются через запросы и циклы – не так быстро и эффективно, как хотелось бы.
-
Выясним, с какими подводными камнями можно столкнуться на нашем пути.
-
Расширим кругозор, а некоторые, может быть, расширят и свое сознание.
На чем будем экспериментировать
Для экспериментов в ходе доклада мы будем использовать тестовую базу с конфигурацией, написанной с нуля под легким влиянием УТ – я позаимствовал оттуда некоторые названия объектов, чтобы слушатели не запутались в необычных объектах метаданных.
Конфигурация очень проста: кроме примеров из моего доклада там будет еще несколько примеров аналогичного типа по использованию СКД.
Файл конфигурации вы можете скачать в приложении к статье.
СКД – не только для отчетов
Большинство программистов привыкли считать, что СКД предназначена исключительно для отчетов. Это могут быть отчеты, которые просто выводят список значений реквизитов по какому-то элементу справочника в табличный документ. Либо отчеты очень сложные – со множеством группировок, деревьев, диаграмм, кросс-таблиц.
Но СКД – это гораздо больше. С помощью СКД можно формировать не только таблицы, но и деревья значений с самой произвольной структурой. Причем в дереве значений может быть несколько корневых веток, из которых расходятся более мелкие.
Это очень удобно, я покажу, как мы используем это дерево для формирования движений документов.
Схема СКД
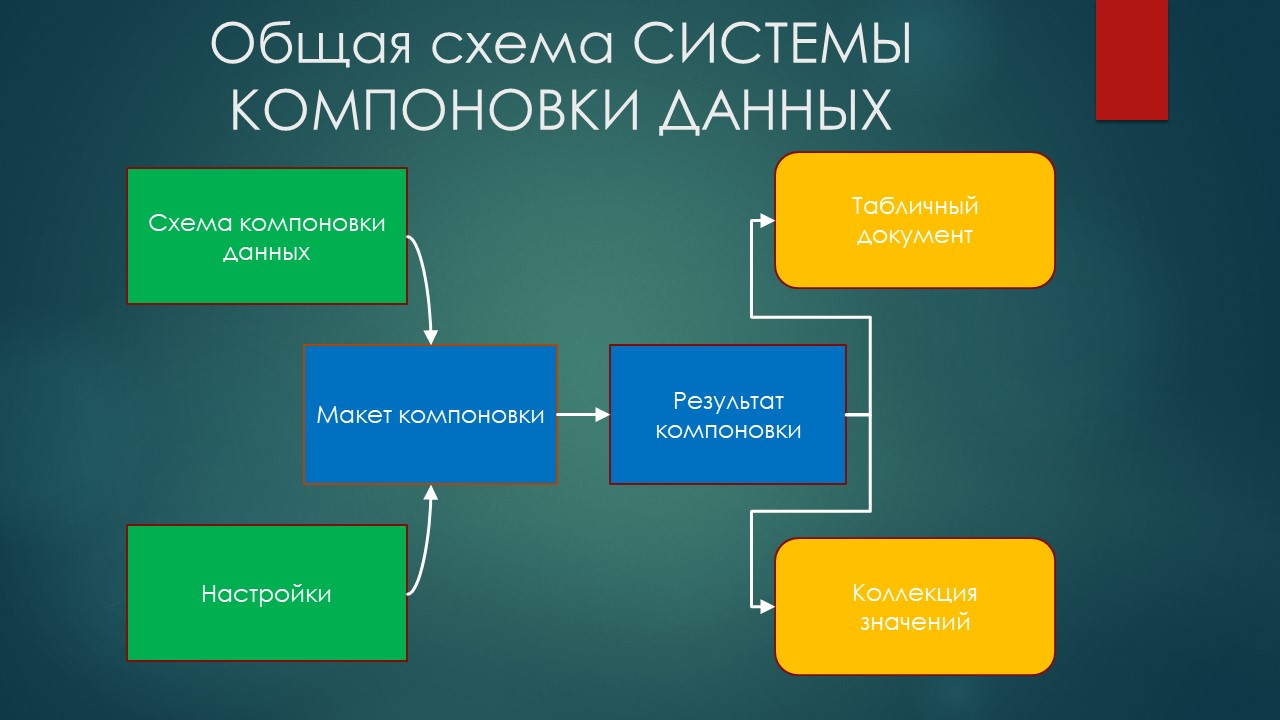
Как работает система компоновки данных:
-
В качестве входных параметров используются:
-
схема компоновки данных – это, фактически, декларативное описание источников данных, которые могут быть представлены как запросы, объекты или объединения;
-
настройки – список полей, которые мы будем выводить, с отборами, сортировками, условным оформлением и так далее.
-
-
Из входных параметров формируется макет компоновки, который, обращаясь к базе, вынимает из нее данные и образует результат компоновки.
-
Результат компоновки – некий полуфабрикат, который может быть выведен:
-
либо в коллекцию значений;
-
либо в табличный документ.
-
Нас будет интересовать тот случай, когда результат компоновки выводится в коллекцию значений.

Посмотрим, как это можно сделать программно.
-
Мы получаем схему компоновки данных – будем считать, что она зашита в объект метаданных.
-
Получаем из нее настройки по умолчанию.
-
Создаем объект «КомпоновщикМакетаКомпоновкиДанных».
-
Из компоновщика макета на основе схемы компоновки данных получаем макет – это некий полуфабрикат, который представляет собой конечное задание на выборку данных из базы и внешних источников.
-
Создаем объекты «ПроцессорКомпоновкиДанных» и «ПроцессорВыводаРезультатаКомпоновкиДанныхВКоллекциюЗначений».
-
Создаем таблицу значений, которая будет результирующей таблицей, в которой мы увидим наши данные.
-
Установим таблицу в процессор вывода и выведем в нее данные.
Таблица значений сформирована. Итого мы видим 10 строчек кода, с помощью которых мы будем в дальнейшем формировать движение документа.
Практика нестандартного применения СКД

Итак, поехали.
Допустим, у нас есть документ «Реализация товаров и услуг».
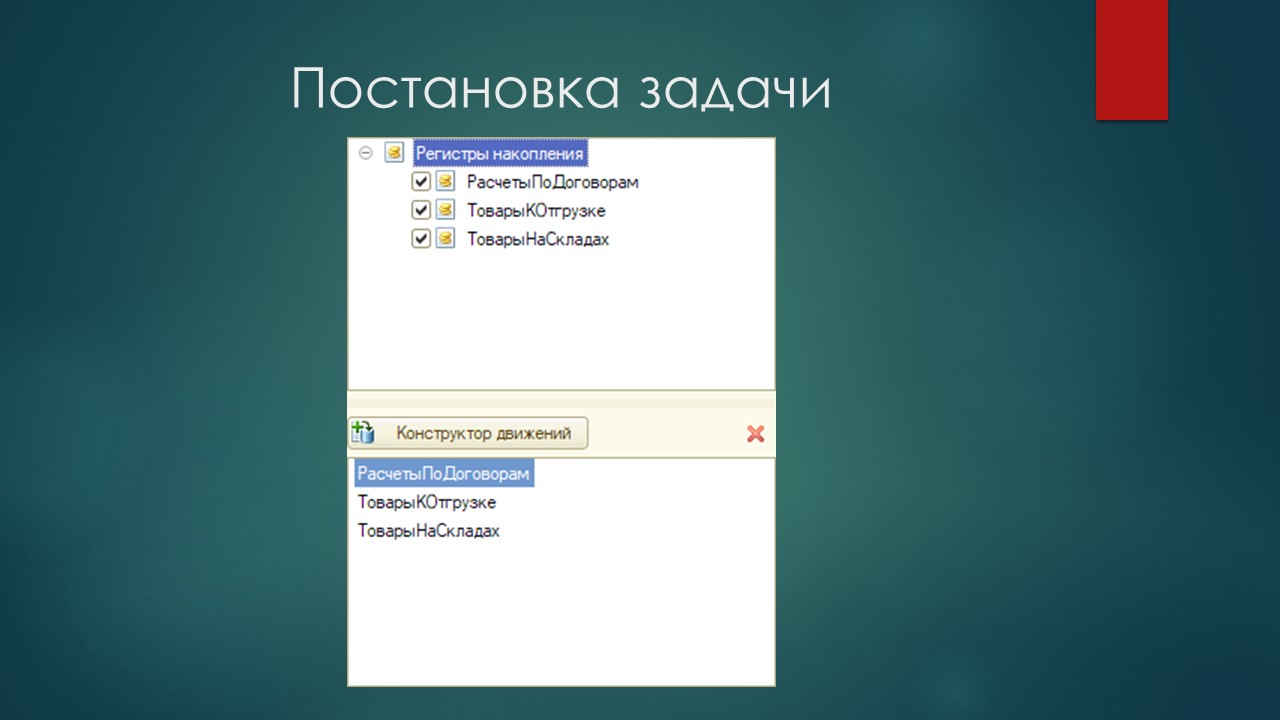
Документ делает движения по трем регистрам накоплений:
-
РасчетыПоДоговорам,
-
ТоварыКОтгрузке,
-
ТоварыНаСкладах.
Эти регистры накоплений имеют определенный набор измерений и ресурсов и, может быть, реквизитов. В моем случае реквизитов не было, но работа с ними ничем серьезно не отличается.
Наборы данных и их соединение
Чтобы сформировать движения с помощью схемы компоновки данных, мы создадим в нашей схеме компоновки данных два набора данных.
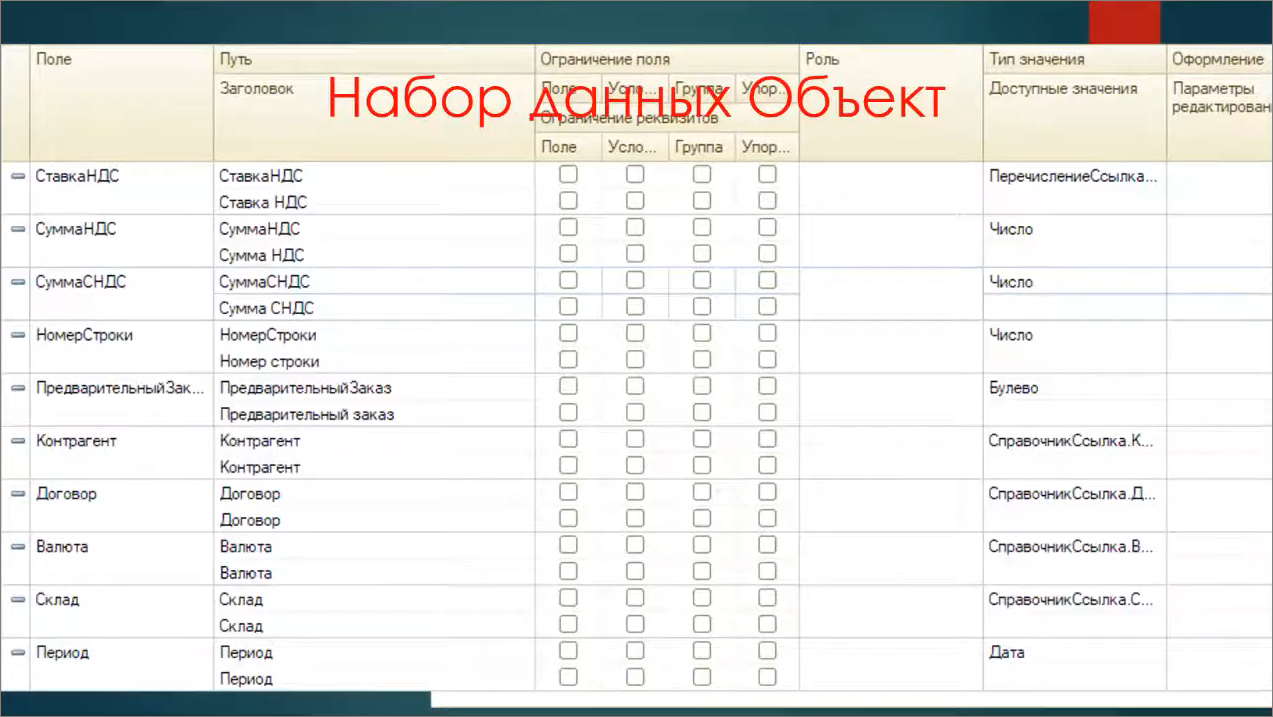
Первый – это набор данных-объект, представляющий собой зеркальное отражение табличной части документа, дополненный реквизитами шапки документа и дозаполненный ими.
-
Некоторые данные, идущие до «НомерСтроки», представляют собой реквизиты табличной части.
-
«ПредварительныйЗаказ» и все, что ниже – реквизиты шапки документа.
У всех реквизитов мы прописываем типы, аналогичные тем типам, что даны у нас в документе.
На этом набор данных-объект мы сформировали.
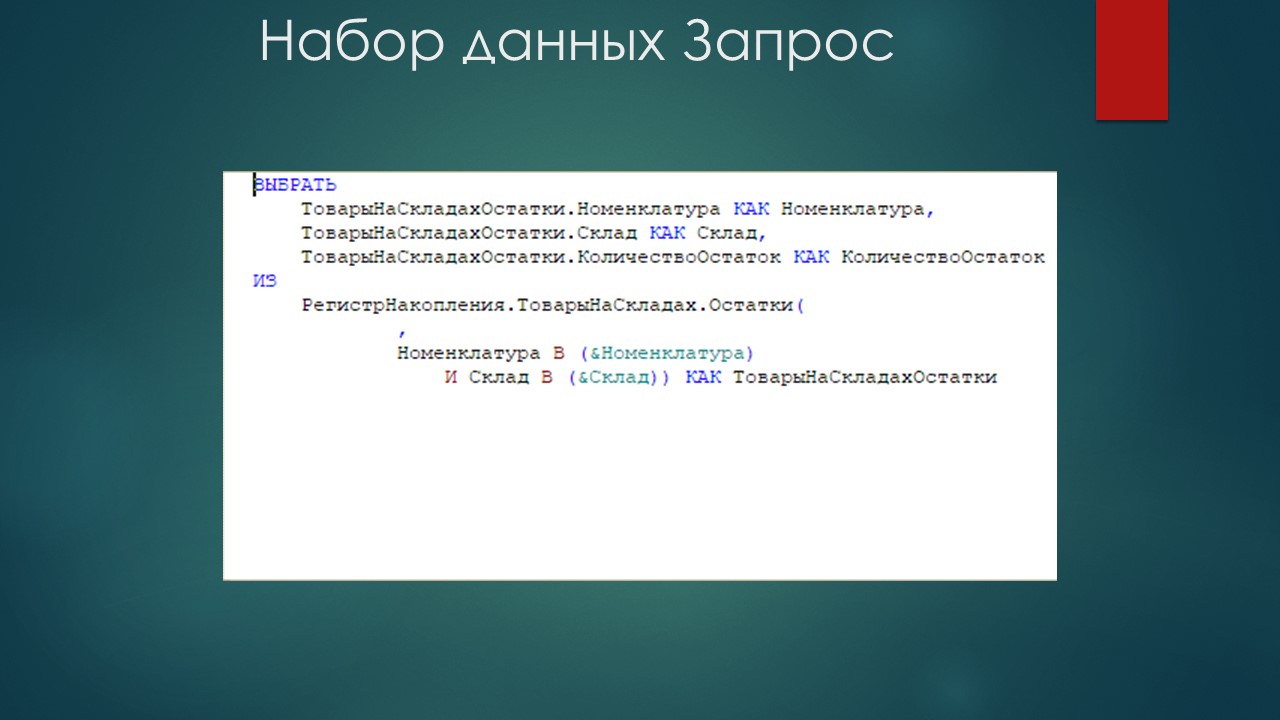
Второй набор данных – запрос, он представляет собой запрос к таблице остатков регистра накопления «ТоварыНаСкладах».
Физический смысл этого запроса – мы должны получить количество данных на выбранных складах в разрезе выбранных номенклатур, потому что в дальнейшем мы должны не допустить, чтобы документ списал со склада большее количество товаров, чем на нем есть. Если в документе списывается больше – ситуация считается ошибочной, и с этим нужно что-то делать.
Обратите внимание, что я здесь не указал дату среза, это поле я заполню позже. Это – маленькая военная хитрость, я к этому параметру вернусь позже.
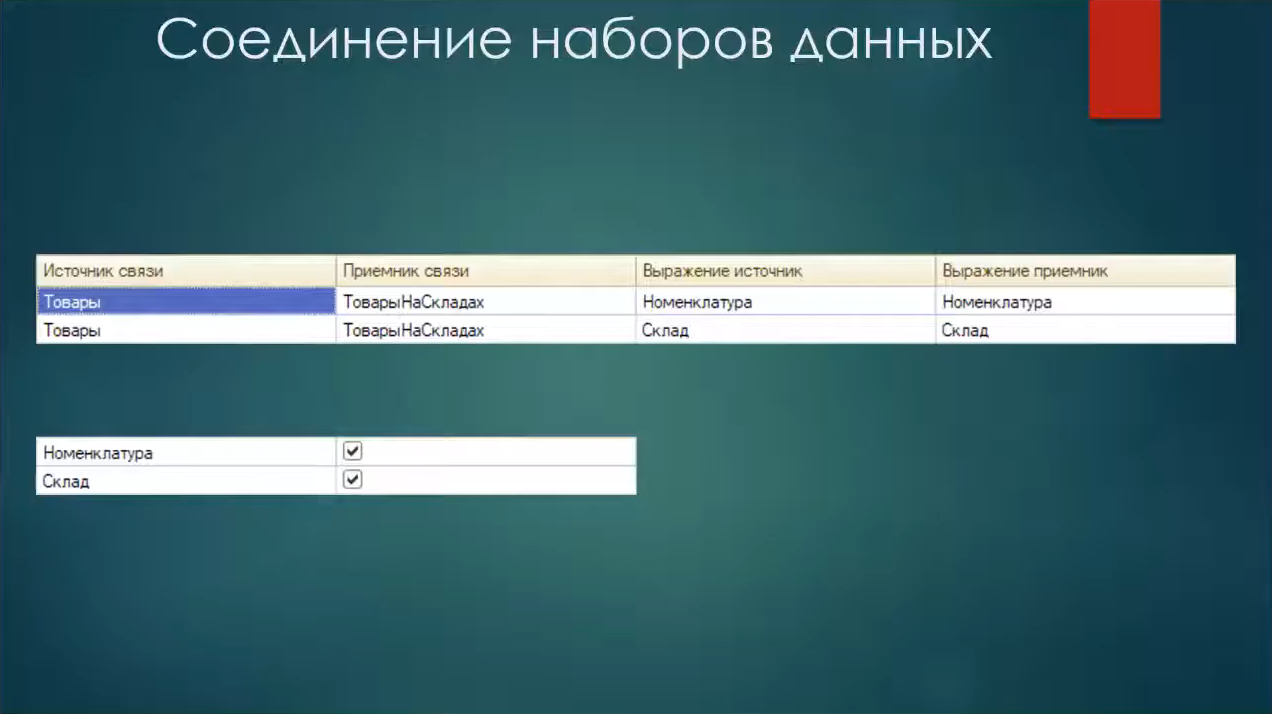
Состыкуем два наших набора данных: это «Товары» – набор данных-объект и «ТоварыНаСкладах» – набор данных-запрос.
Их мы стыкуем по полям «Номенклатура» и «Склад».
Эти связи являются параметрическими – параметры я сделал одноименными для простоты.
Эти параметры являются списками значений. Почему? Особенность СКД в том, что если есть левое соединение двух наборов данных, оно может быть выполнено при определенных условиях столько раз, сколько встречается различных вариантов полей в первичном наборе данных. Если мы ставим «Номенклатуру» и «Склад» как параметры с типом «Список значений», то запрос выполнится только один раз, а в эти параметры будут переданы все возможные сочетания значений номенклатур и складов.

Вот как это выглядит – в исходной таблице «Товары» три строки, из них два варианта номенклатуры и два варианта склада.
Соответственно, в запрос второго набора данных будет передан следующий список параметров «Номенклатура» и «Склад».
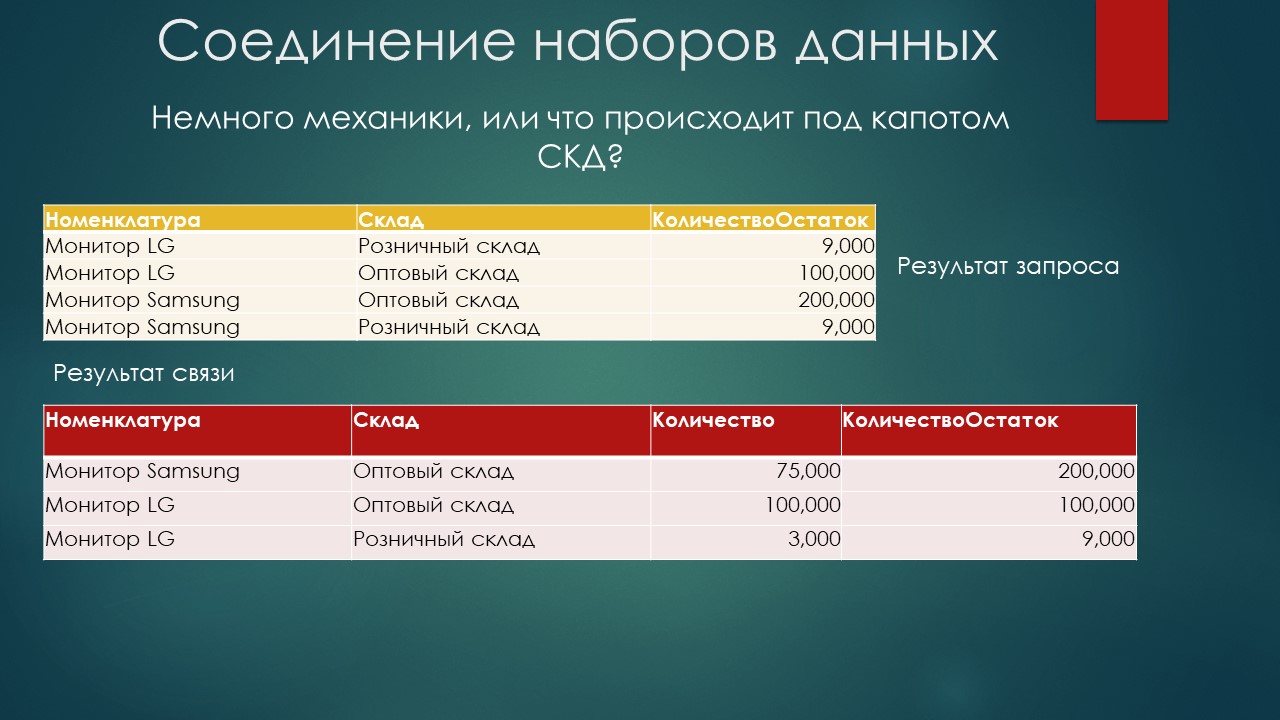
По остаткам мониторов LG и Samsung на розничном и оптовом складах мы получим следующий результат запроса.
Пристыковываем этот результат запроса к нашему исходному и получаем дополненную таблицу. Так как остатки мониторов Samsung по розничному складу нам неинтересны, они выпали из этой результирующей таблицы и, в принципе, нам больше ничего не надо.
Вот так отрабатывает в ходе выполнения схемы компоновки данных наша связь.
Вычисляемые поля

Перейдем к вычисляемым поляя – они необходимы, чтобы трансформировать исходные поля в те, которые будут использованы для заполнения ресурсов в регистре сведений.
Мы добавим поле «Сумма», которое будет тождественно равно полю «СуммаСНДС» исходного набора данных «Товары».
Еще одно поле – «ОписаниеОшибки», это триггерное текстовое поле, оно будет заполняться только в том случае, когда по какой-то номенклатуре количество в документе превысит количество остатка. Здесь приведена формула, по которой это поле будет заполняться – в случае выполнения условия это сообщение в дальнейшем будет выводиться пользователю.
Ресурсы и параметры
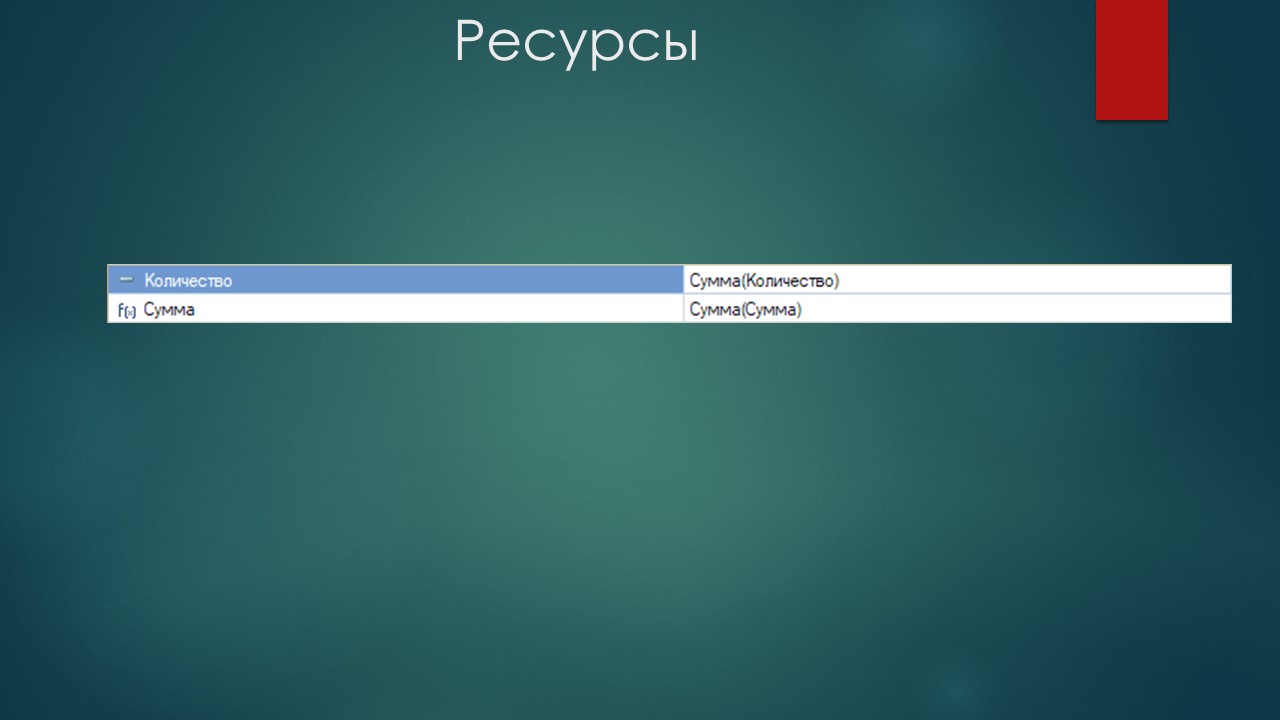
Поля «Количество» и «Сумма» добавим в ресурсы с применением агрегирующей функции Сумма().
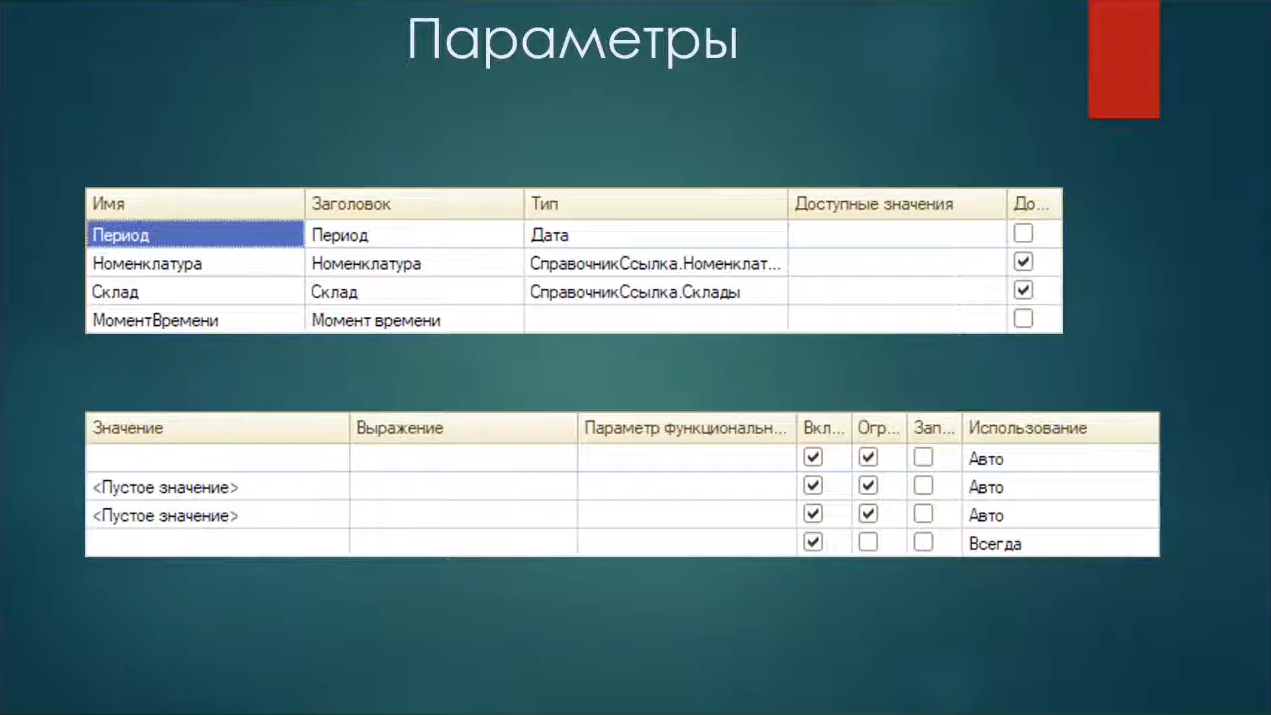
Перейдем на закладку «Параметры»:
-
Добавим параметр «МоментВремени».
-
Остальные три параметра: «Период», «Номенклатура» и «Склад» у нас уже есть, но мы отключим для них использование и заполнение извне (поставим флажок «Ограничение доступности»).
Для параметра «МоментаВремени» не будем указывать тип, но оставим для него использование «Всегда» и уберем флажок «Ограничение доступности».
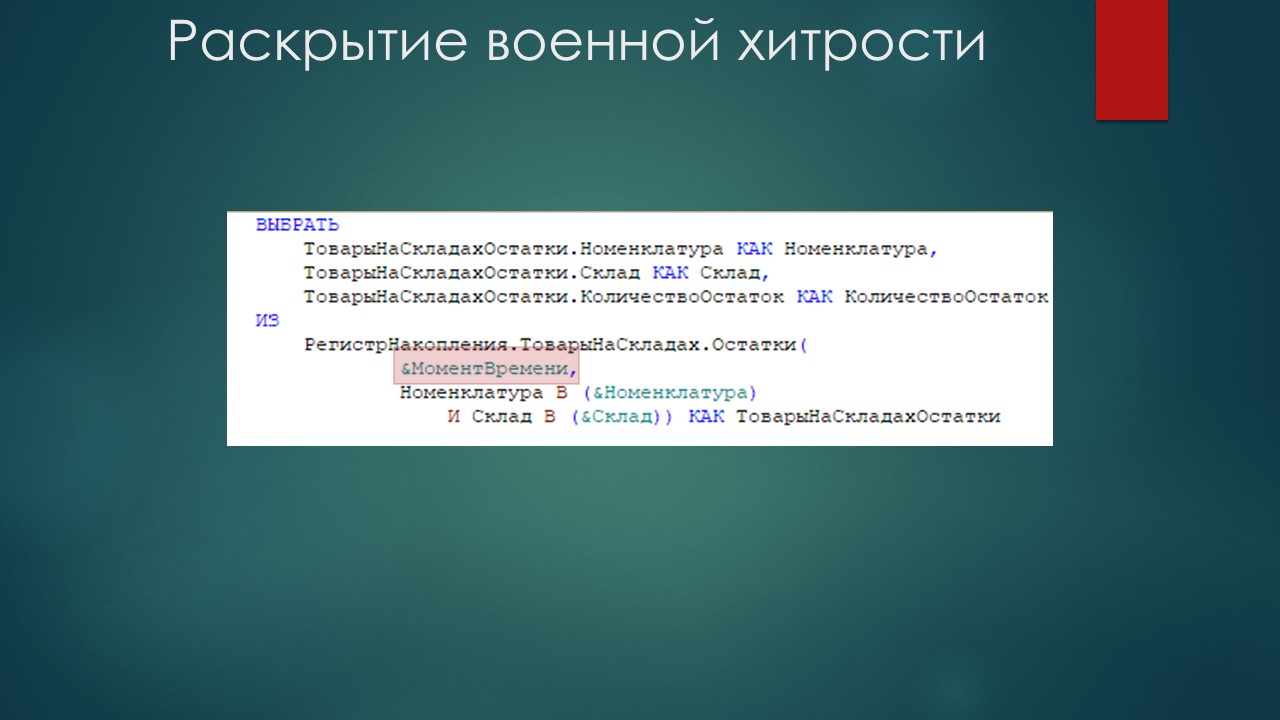
Раскрою военную хитрость, о которой уже упомянул. Мы заходим в исходный набор данных-запрос и добавляем параметр &МоментВремени.
Почему нельзя было делать это сразу? Дело в том, что схема компоновки данных умеет работать с нестандартными значениями типа Момент времени, Граница и так далее.
Но если мы сразу укажем здесь параметр «&Граница» или «&МоментВремени», они автоматически типизируются в дату, что приведет к неправильной работе алгоритма и багам.
А если мы сначала создадим параметр, а потом его передадим, «&МоментВремени» всегда будет передан как Момент времени, а «&Граница» как Граница. Эта схема проверена, поэтому я рекомендую такой способ обхода ограничений 1С.
Настройки
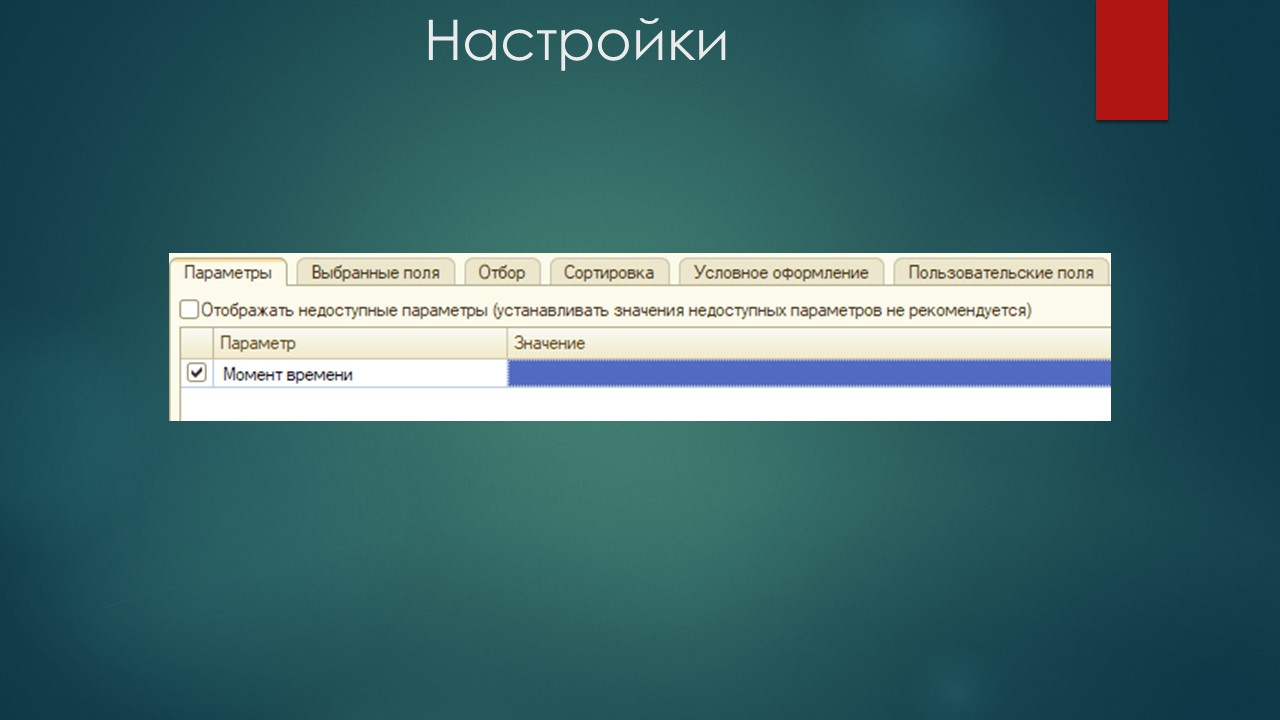
Дальше переходим на вкладку «Настройки», включаем использование параметра «Момент времени» и дальше будем думать, как нам группировать дерево значений.
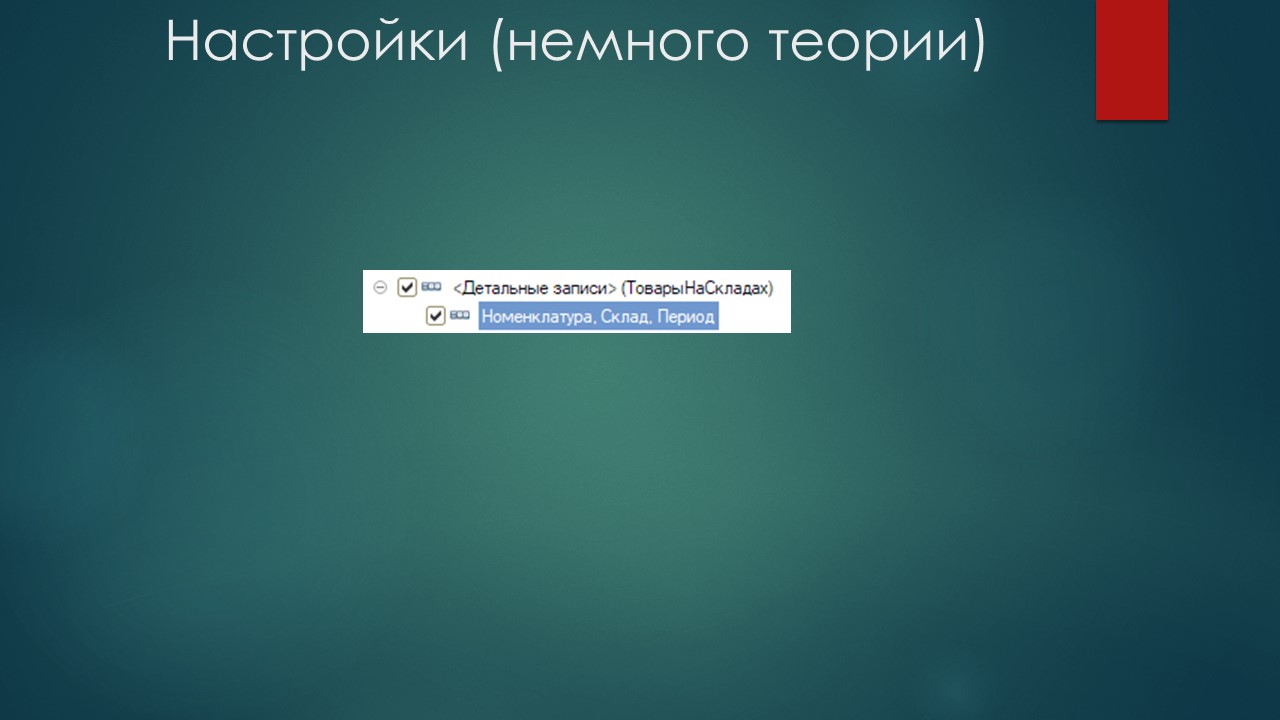
У нас будет три группировки для регистров, так как у нас документ «Реализация» делает движения по трем регистрам накопления. Каждая группировка для регистра накопления будет названа точно так же, как этот регистр.
Конечно, группировки можно назвать как угодно: группировка 1, 2, 3 или по имени программиста, который разрабатывает, но это плохая практика, потому что сопровождать это будет тяжело. Поэтому каждую группировку я назвал одноименно с регистром.
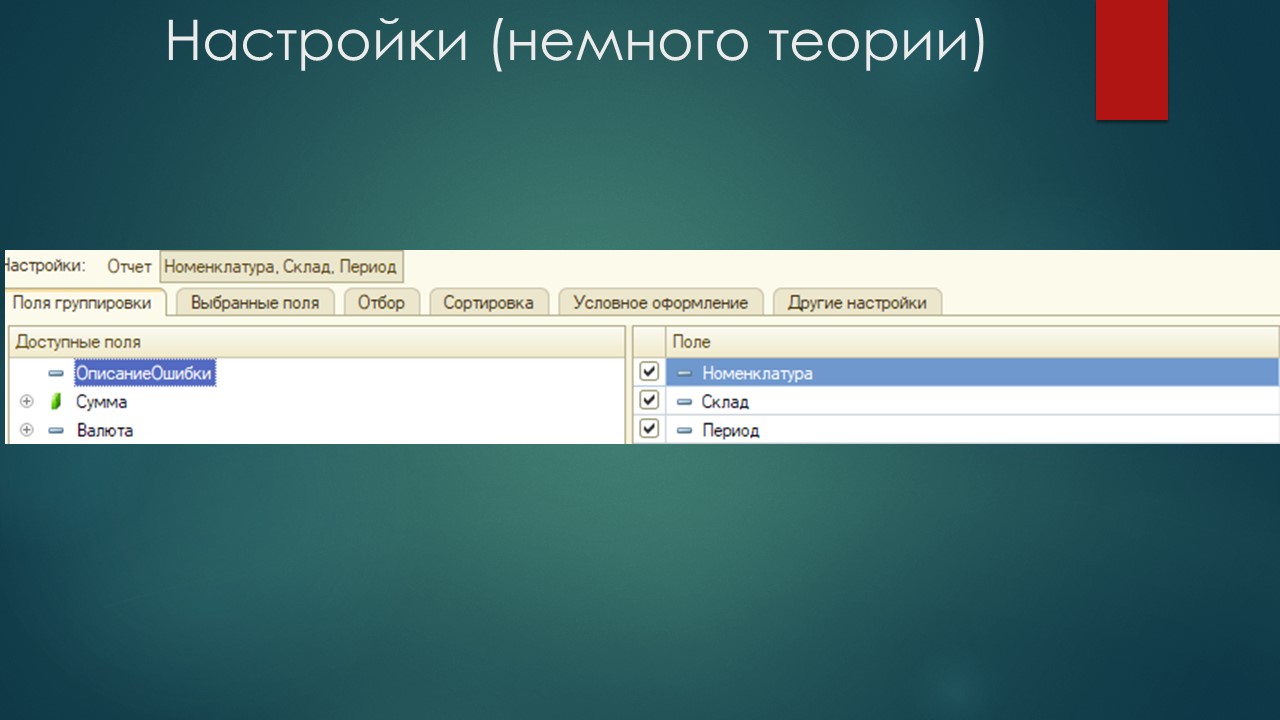
В поля группировки я обязательно включаю поле «Период» и два поля, которые у нас являются измерениями регистра накопления – «Номенклатура» и «Склад».
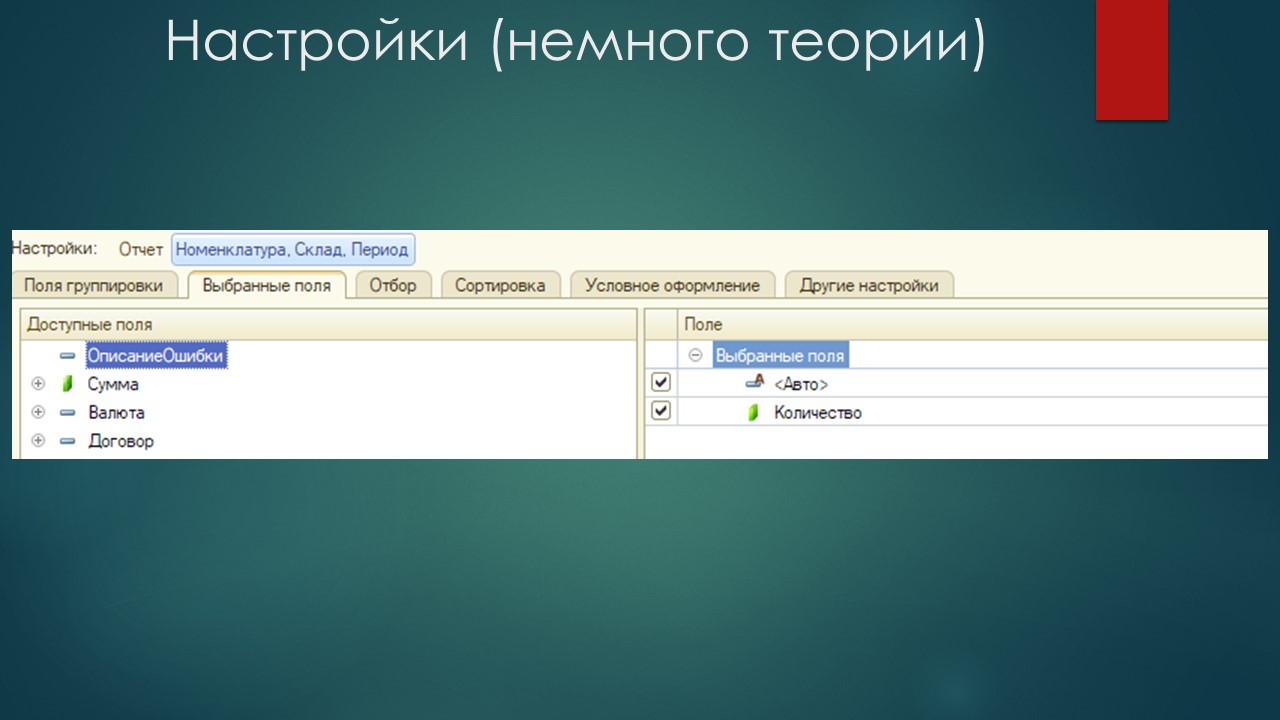
В выбранные поля я включил авто-поле и поле ресурса «Количество».
Если у наших регистров накопления есть еще и реквизиты, то мы их тоже должны сюда включить, перед этим добавив на вкладку «Ресурсы» схемы компоновки данных с результирующей функцией МАКСИМУМ().
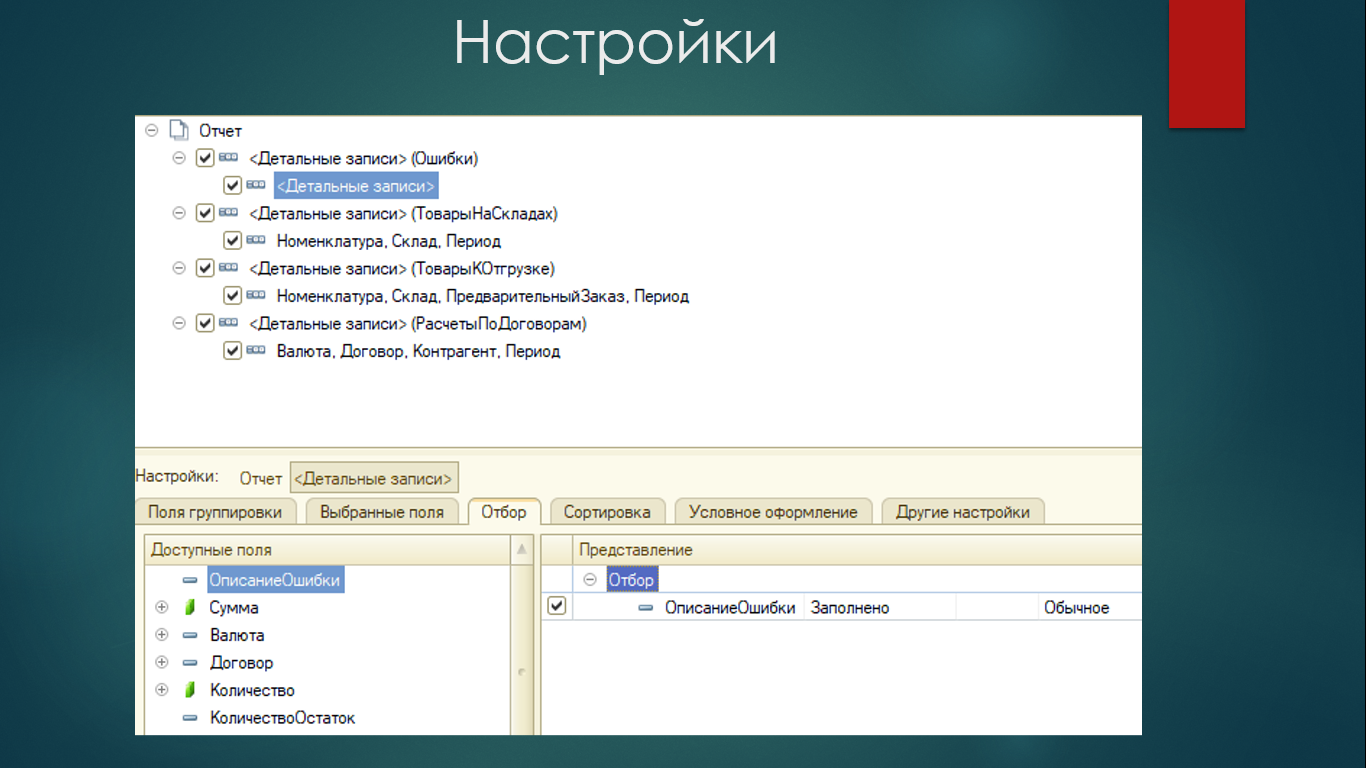
У нас будет три группировки для регистров – они будут идти под номерами 1,2,3.
А группировка с номером 0 будет называться «Ошибки». В нее мы добавим отбор по заполненному полю «ОписаниеОшибки» – если у нас в поле «ОписаниеОшибки» что-то вылезет, мы обязательно выведем это писание в первую группировку. Это поможет в дальнейшем при работе нашего алгоритма отловить эту ситуацию и не допустить проведения документа.
Краткое описание построения схемы компоновки данных завершено. Переходим к процедуре проведения.
Процедура проведения

Процедура проведения достаточно проста:
-
сначала мы очищаем все наши движения;
-
потом из макета получаем схему компоновки данных;
-
из схемы вытаскиваем настройки по умолчанию;
-
и передаем в настройки значение момента времени документа;
-
дальше создаем объект «КомпоновщикМакетаКомпоновкиДанных»;
-
получаем макет компоновки.
-
создаем процессор компоновки, инициализируем его.

И дальше делаем таблицу «Товары» – клон табличной части «Товары». Мы ее просто выгружаем и дальше дозаполняем колонками, соответствующими реквизитам в шапке документа:
-
«ПредварительныйЗаказ»;
-
«Контрагент»;
-
«Валюта»;
-
«Договор»;
-
«Период».
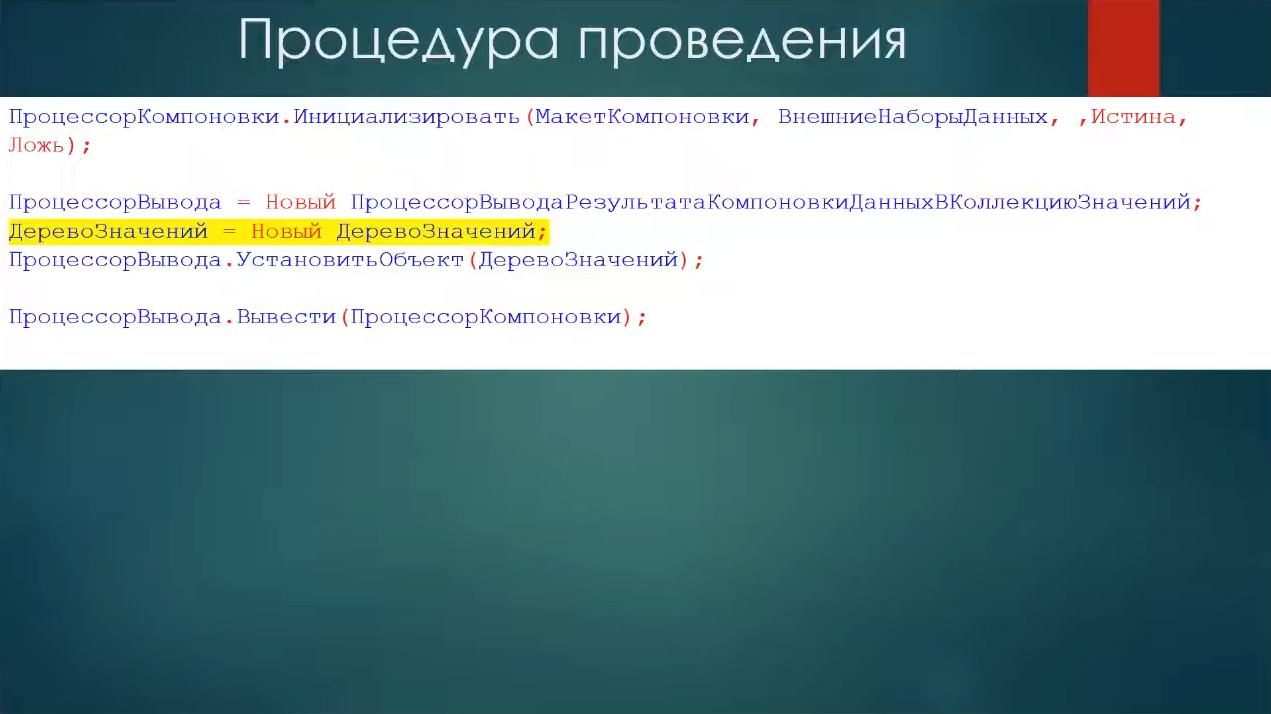
Дальше:
-
инициализируем процессор компоновки, передав ему в качестве параметра внешние наборы данных – под внешними наборами данных я подразумеваю структуру, в которую мы вложили таблицу значений;
-
создаем дерево значений;
-
создаем процессор вывода;
-
устанавливаем дерево значений в качестве результата процессора вывода;
-
и выводим.
Все, мы получили дерево, из которого будем создавать движение.
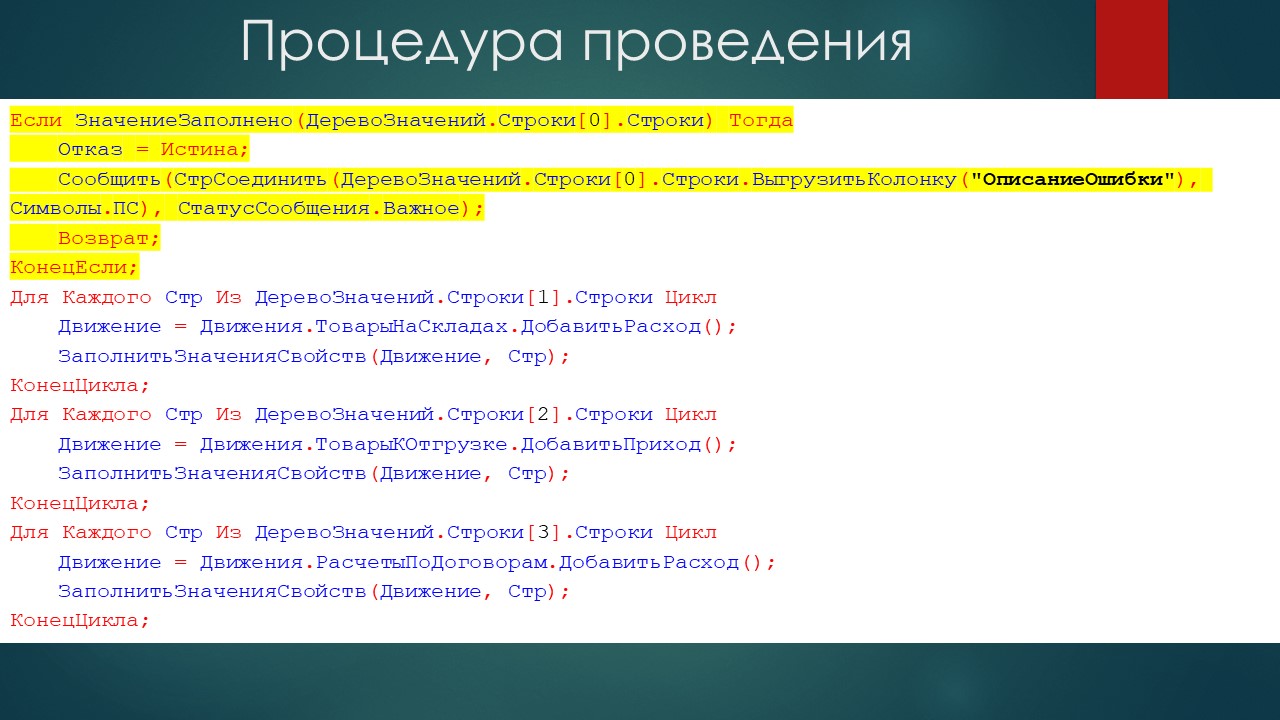
Как я уже сказал, нулевая группировка – группировка описания ошибки. Если в этой группировке есть хотя бы одна строка – ставим флаг отказа, сообщаем пользователю все возможные комбинации описания ошибок и прекращаем проведение. Пользователь получает информацию о том, что что-то не так.
А дальше для каждой строки из каждой группировки, ответственной за формирование документа, я получаю данные для заполнения движения по регистру. И, перебрав все строки, я заполняю все движения документа.
У документа в свойстве «Запись движений при проведении» стоит значение «Записывать модифицированные», поэтому после того, как этот цикл отработает полностью, документ будет проведен и движения сформированы.
Вот так это происходит.
Сравниваем «классику» и СКД

Все, конечно, красиво, но сразу возникает вопрос: если все так круто с СКД, почему еще используют «классику»?

У «классики» есть свои плюсы.
-
В ряде случаев она проще в сопровождении и разработке. Если проведение совершенно примитивное (добавляются только строки в регистр сведений напрямую из табличной части) в СКД вообще нет никакой потребности.
-
Есть случаи, которые СКД не может реализовать при всем желании, а в классике такие случаи можно реализовать.
Но у «классики» есть проблемы:
-
Нет единообразия кода. Когда программист добавляет новый документ, он может написать проведение так, как он привык писать до этого, не глядя на то, как прописаны остальные документы. Смотреть на этот код то еще удовольствие. В СКД это легче обойти, потому что процедуры, которые отвечают за техническую работу с СКД, можно вынести в общий модуль – тогда программирование сводится к разработке схемы, и вероятность получить «лоскутное одеяло» из разных стилей кода уменьшится.
-
В «классике» нет возможности использовать агрегатные функции СКД, такие как СоединитьСтроки(), Массив(), ТаблицаЗначений() – функция, которая выбирает из запроса коллекции. В ряде случаев использовать агрегатные функции удобно, хотя таких случаев не так много.

У СКД много других плюсов:
-
Встроенные функции СоединитьСтроки(), Представление(), Формат(). С помощью функции Формат() можно преобразовать дату или число к нужному формату в самой схеме и получить их на выходе без последующей обработки в цикле. Функция Представление() в СКД позволяет создать свое представление, которое отличается от встроенного представления в запросе, которое используется для общесистемных целей. Это классно, потому что в ряде документов нужно заполнять комментарий, который с помощью Представления() в СКД может быть получен достаточно легко, без необходимости написания сложных условий.
-
СКД может брать напрямую данные из всяких экзотических источников. Об этом мало кто из программистов знает, но СКД умеет брать данные из области табличного документа с параметрами, из структуры напрямую, из массива однотипных структур.
-
СКД легко масштабируется без вмешательства разработчика. Оно будет быстро работать как для 15 строк, так и для 15 тысяч строк, если там нет диких конструкций типа обращения к внешней функции, которая работает в цикле.
-
При хорошем подходе разработка с помощью СКД приводит к разработке только самой схемы. Как я уже сказал, можно вынести все процедуры работы с СКД в общий модуль и забыть о них до лучших времен.
У СКД только два недостатка.
-
В СКД нельзя реализовать все, что можно реализовать в «классике».
-
И у многих программистов существует предубеждение, что СКД – только для отчетов. Писать с помощью СКД такие вещи требует специального навыка, что для многих непривычно.
Итог поединка

Итоги нашего поединка: СКД, по моему субъективному мнению, побеждает с перевесом в 1 балл.
Естественно, этот балл незначителен. Но каждый программист, который умеет пользоваться СКД, может извлечь из этого балла большие дивиденды.
Конечно, для запроса типа «Выбрать первую ссылку из справочника Контрагенты» нецелесообразно делать схему компоновки данных. Но в большинстве других случаев СКД может выиграть у «классики» с гораздо большим перевесом, особенно, когда нужно сделать слияние нескольких таблиц или получить данные из нестандартного источника.
Файл конфигурации вы можете скачать во вложении к публикации. В этой конфигурации вы можете посмотреть, что у меня еще реализовано с помощью компоновки данных.
Вопросы:
Зачем такие танцы с бубнами? Как и почему пришли к такой реализации? И в чем вообще преимущество реализации на СКД?
Я так понимаю, вопрос вызван простотой примера. Мне нужно было написать некую конфигурацию, которая не защищена авторским правом и свободна для распространения, поэтому я написал такой простой пример. Если у вас будет не одна табличная часть, а пять. Не три регистра, а, допустим, шесть. Из них половина – регистры сведений, а не только регистры накопления. Плюс регистры будут использовать частично одинаковые данные, частично – не одинаковые. Там это станет более понятным.
Вопрос по скорости проведения документов, которые так через СКД завернуты – выигрывает ли скорость относительно классики или проигрывает?
На малых объемах (100-150 строк в документе) примерно то же самое получается. Но если будет 15 тысяч строк, то СКД начинает уже выигрывать. СКД лучше масштабируется.
Как производить отладку и поиск ошибок в таких алгоритмах?
В самом СКД, как правило, ошибки не так сильно разнообразны, как в классике. Получать информацию о том, какая ошибка, можно глядя на сообщение, которое выводит отладчик при формировании схемы компоновки данных. Например, на моменте вывода выдается сообщение об ошибке «Не найдено поле для замены», которая означает, что мы забыли добавить поле во внешний набор данных. В общем, в силу опыта, я уже знаю, как интерпретировать ошибки, которые платформа показывает. Гораздо труднее, конечно, получать ошибки, которые не выводятся как ошибки, а просто приводят к какому-то искажению данных. Тут уже необходимо перехватывать запрос, который СКД создает. Это можно сделать на этапе отладку, поставив точку останова в том месте, где «КомпоновщикМакета.Выполнить()». Получается у нас новый макет компоновки. В макете компоновки находятся все наши запросы, которые СКД интерпретировала в соответствии с нашим заданием. Эти запросы можно вытащить в консоль запросов и дальше смотреть уже, как они отрабатывают. Ситуаций, когда искажения были не из-за запросов, у меня не возникали – здесь достаточно иметь опыт именно работы с данными. Грубо говоря, если у нас на входе таблица значений, а на входе нужно получить дерево значений, то научиться правильно строить дерево не сложно. Дальше уже ошибок никаких не будет.
Какую самую интересную задачу с точки зрения разработки и бизнеса ты решал на СКД?
Была история, когда нужно было переписать веб-сервис, который раньше был сделан на «классике». В коде веб-сервиса нужно было получать уникальный идентификатор объекта. Естественно, это делалось с помощью классики – сначала делался запрос, потом для результирующей таблицы значений добавлялось поле «Уникальный идентификатор», потом эта таблица сканировалась, и для каждого ссылочного поля этот уникальный идентификатор заполнялся. Фактически, получался запрос в цикле, из-за этого код веб-сервиса отрабатывал очень медленно. Мы переписали его на СКД, потому что там для СКД в вычисляемых полях можно использовать встроенную функцию XMLСтрока(Ссылка), которая, фактически, получает строковое значение идентификатора. И эта функция работает быстрее, чем Ссылка.УникальныйИдентификатор(). Производительность веб-сервиса возросла на 60%, никакие вторичные циклы больше не используются – мы на вход подали схему, а на выходе получили таблицу.
Приходилось ли когда-нибудь сделать откат в классику?
Такого не было, был переход на «полуклассику», когда в итоговом дереве одна колонка заменялась в цикле на другую. Там не было запроса в цикле, там просто была перестановка значений при переборе ветвей дерева – чтобы не тратить времени и не убивать то, что уже было сделано.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Новосибирск.

Вступайте в нашу телеграмм-группу Инфостарт
