Я руковожу отделом разработки в компании «Билайн». Поделюсь с вами опытом применения практик DevOps на крупном проекте. Мой доклад будет носить обзорный характер, хардкора практически не будет, но, тем не менее, мне есть, что рассказать.
О предмете доклада
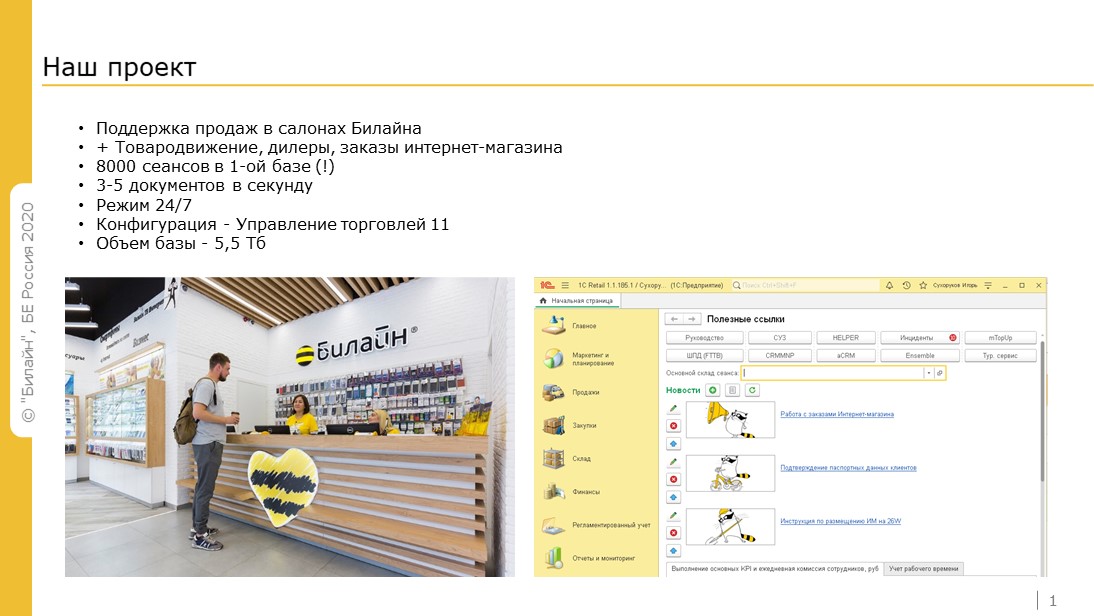
Перед тем, как поделиться нашими практиками, расскажу о нашем проекте.
-
Мы обеспечиваем продажи в салонах «Билайна» по всей России: от Москвы до Дальнего Востока. Также за нами процессы товародвижения, дилерские отгрузки, обработка заказов интернет-магазина.
-
Особенности нашей базы: единая, ключевой момент – 8 тыс. пользователей работают одновременно. Я уверен, что по этому показателю мы в топе.
-
Каждую секунду проводятся от 3 до 6 документов, в новогодние праздники может быть и больше.
-
Пользователи работают в режиме 24/7, потому что компания распределена по разным часовым поясам: Москва, Сибирь, Дальний Восток.
-
Конфигурация – сильно допиленная УТ 11 версии.
-
Объем базы – 5,5 Тб. Обычная реакция на такие характеристики : «Как вы там вообще держитесь?» или, если речь идет о найме, «Я хочу у вас работать!».
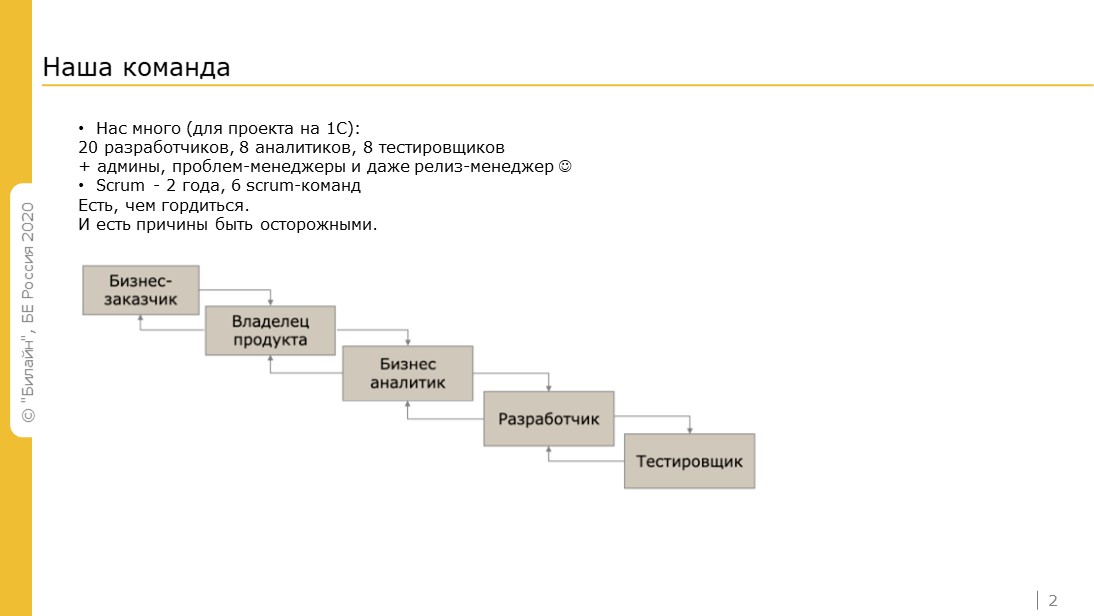
У нас большая для проекта 1С команда – 20 разработчиков, 8 аналитиков и 8 тестировщиков. Также в команде есть админы, problem-менеджеры и даже выделенный релиз-менеджер. По Scrum мы работаем порядка двух лет.
Расшифрую, какой у нас Scrum, потому что бытует мнение, что Scrum у каждой команды свой, свои отличия есть и у нас.
-
Задачи мы бьем на клиентские истории, если понимаем, что целиком ее выпустить не можем.
-
Цель выпуска задачи – понимание того, что мы хотим ее проанализировать или провести демонстрацию у заказчика.
-
У каждой команды есть владелец продукта, который помогает сформировать очередь задач.
-
Разработчики заняты тем, что только пишут код. Если бывают технические небольшие задачи, они могут делать и их.
-
После реализации начинается самое интересное. Мы проводим приемочное тестирование или демонстрацию, куда наравне с бизнес-заказчиком и владельцем продукта приглашаем группу поддержки – поддержка во время просмотра может высказать свои замечания и предложения. Можно сказать, что это одна из практик DevOps – тесная взаимосвязь с поддержкой.
-
После того, как высказаны замечания группы поддержки, мы должны их исправить до выпуска в релиз. Такая практика обеспечивает непрерывность и равномерность процесса выпуска задач.
Снова эта всеми любимая картинка. Зачем нам DevOps?
Каждый спринт мы выпускаем порядка 30 задач и столько же багов, от этого никуда не деться. В самом начале пути основной мотивацией для нас стало сокращение количества багов и времени на их правки.
Дополнительная особенность – обкатка новых версий платформы. Об этом чуть позже.

Моя личная мотивация – я, как начальник отдела разработки, хочу высыпаться. На фото не я, но будили меня в два часа ночи регулярно, всех я вспоминаю добрыми словами. Отчасти именно это побудило меня внедрять у нас в отделе DevOps.

Так как «Билайн» – компания огромная, у нас были и есть определенные ограничения: организационные и технические.
Организационные ограничения выражаются в том, что у нас несколько сотен процедур по выпуску ИТ-систем. Ограничения установлены из-за того, что «Билайн» – публичная компания, торгуется на бирже SOX.
Примеры ограничений, с которыми мы вынуждены мириться:
-
разработчик не имеет права доступа к продуктивной базе;
-
еще одно ограничение – разработчик не может быть тестировщиком. Это отклонение от чистого Scrum, но ничего не поделаешь, бюрократия имеет место быть.
Теперь про технические ограничения. Основное техническое ограничение связано с тем, что мы не используем EDT. Не потому, что он тормозит. Нюанс в том, что нам очень важны последние версии платформы, мы их постоянно обкатываем. Сейчас у нас в обкатке 18 версия платформы, в порядке бета-тестирования.
К сожалению, EDT 18 версию не догнал, поэтому мы вынуждены использовать конфигуратор. Верим, что EDT скоро догонит платформу, тогда мы его и поюзаем.
Непрерывная интеграция
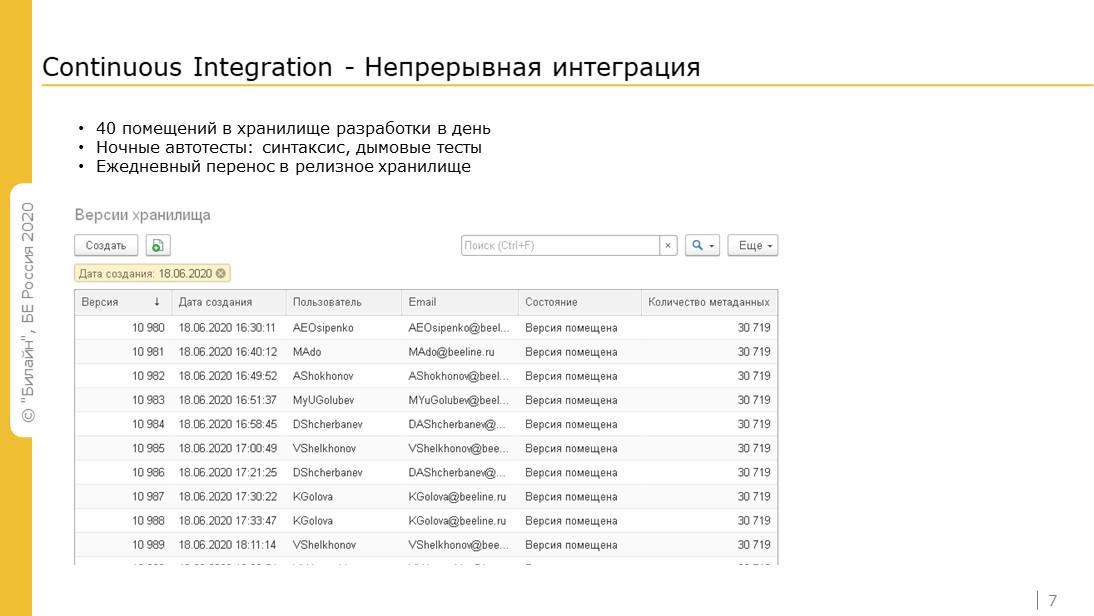
Автосборки проекта у нас нет, но постоянная интеграция есть.
-
Ежедневно 20 разработчиков делают 40-50 помещений в хранилище,
-
Каждую ночь отрабатывают автотесты – проверяется синтаксис и запускаются дымовые тесты.
-
По результатам автотестов тестировщики судят о качестве кода в хранилище и фиксируют баги. Причем все это делается оперативно и правится быстро. Непрерывность точно есть.
На скриншоте вы видите список изменений хранилища за час, которые показывает GitConverter – я про него сейчас подробнее расскажу.
Code-review
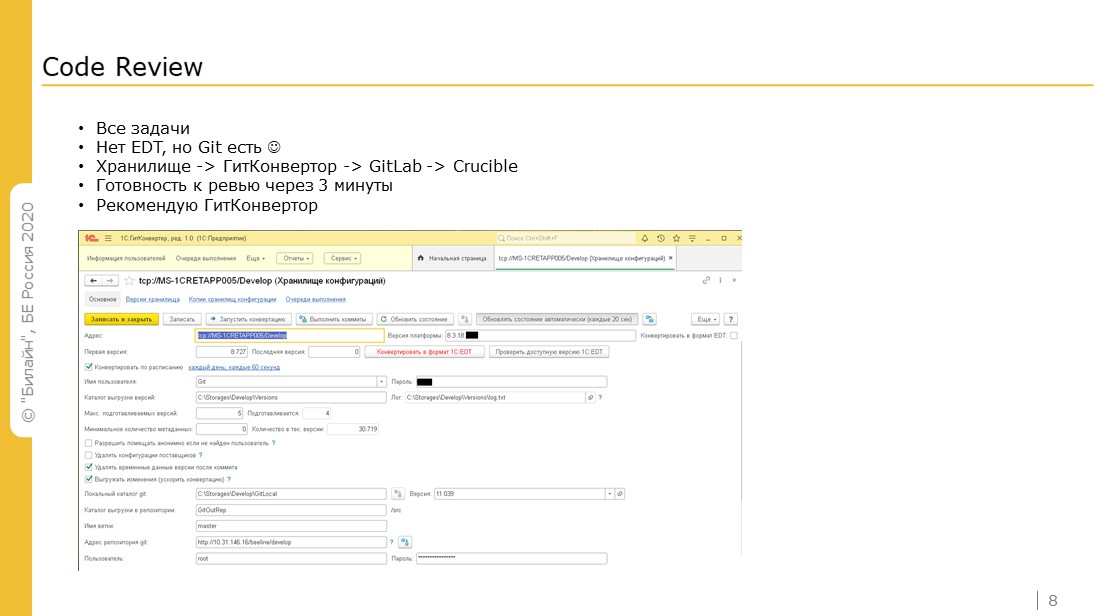
Возможно, code-review напрямую нельзя отнести к DevOps, но он помогает соблюсти непрерывность процесса, его равномерность, поддерживать качество готового продукта.
-
Code-review мы используем очень активно, применяем для всех задач.
-
И здесь возникает Git. Т.е. несмотря на то, что EDT нет, Git у нас есть.
-
Gitsync и Jenkins мы на текущий момент не используем. Мы используем цепочку: Хранилище 1С – > 1С:ГитКонвертер – > GitLab – > Crucible. Crucible – продукт для проведения ревью кода.
-
Причина неиспользования Jenkins и утилиты Gitsync в том, что мы хотели ускорить процесс. У нас большая, развесистая конфигурация. От момента помещения в хранилище до возможности начать ревью кода проходит порядка 15 минут. После использования 1С:ГитКонвертера нам удалось сократить это время до 3 минут. 1С:ГитКонвертер – это конфигурация от фирмы 1С, инструмент для синхронизации помещений в хранилище. Его можно скачать с сайта ИТС. Тот же Gitsync, только от фирмы «1С». Сам 1С:ГитКонвертер пришлось немного допилить, сейчас он нас полностью устраивает. В планах написать статью на эту тему на Инфостарте.
-
Процесс code-review мы административно ограничиваем 4 часами. Поэтому непрерывная сборка в итоге у нас есть – это помогает процессу.
На слайде показан скрин из 1С:ГитКонвертера – как он настраивается.
Непрерывная поставка
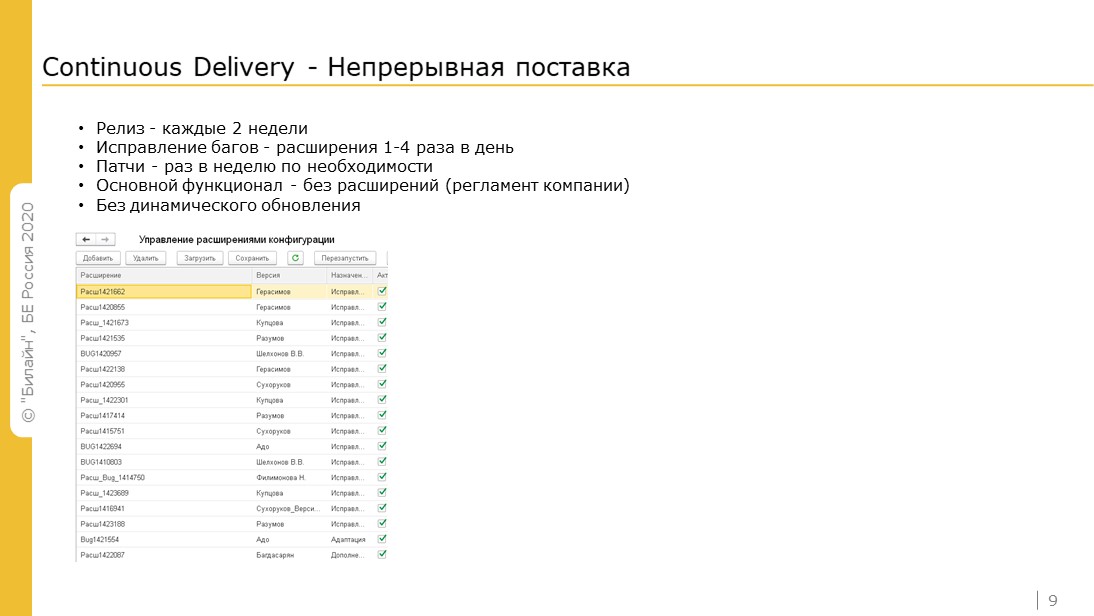
Как мы релизимся?
-
Релиз выходит раз в две недели: столько занимает у нас процесс сборки релиза, и это совпадает со временем спринта.
-
Все баги мы правим расширениями. Пять лет назад расширения только начинались, и это время мне страшно вспоминать.
-
Основную функциональность мы запускаем без расширений: отчасти из-за регламента, отчасти оттого, что постоянно приходится добавлять новые объекты.
-
Динамическое обновление мы не используем – базы падают. На продуктиве мы его никогда не использовали, но тестовые базы из-за динамического обновления падали регулярно.
Сценарное тестирование
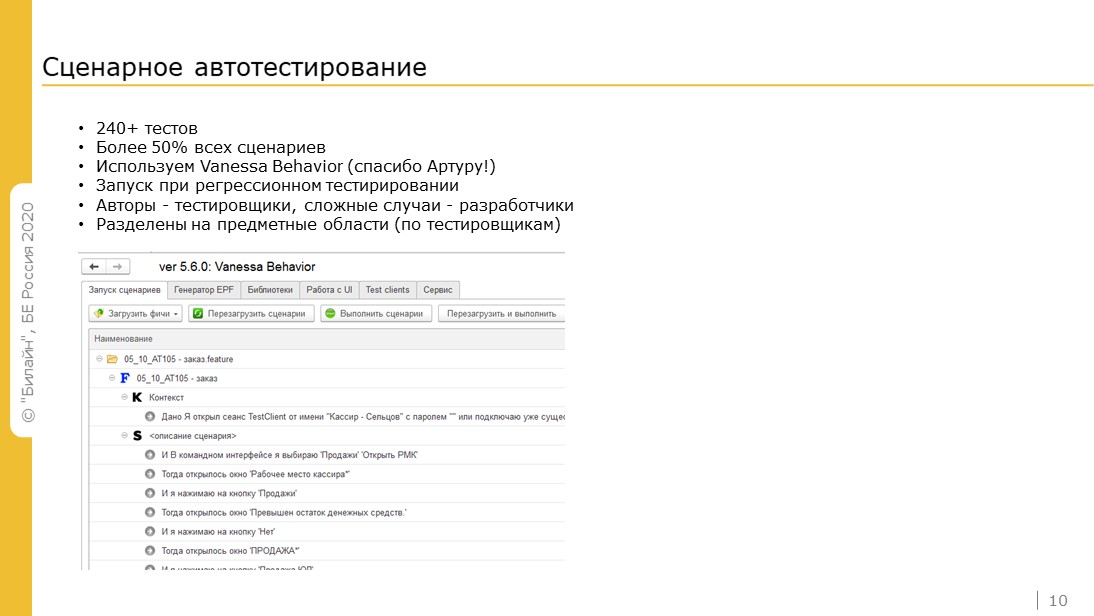
Практика написания автотестов в среде 1С мало распространена. И это одна из первых практик DevOps, с которой мы начали. Мы не знали, с чего начать. Было непонятно направление, куда двигаться в этой части, но два года назад Артур Аюханов нас обучил и помог выбрать инструменты для тестов.
-
Для целей сценарного тестирования используем Vanessa-Behaviour.
-
Сейчас у нас 240 тестов, ими обложено больше половины всех тест-кейсов. В пике доходили до 75%. Здесь основная особенность в том, что новые возможности появляются быстро, поэтому есть некое отставание.
-
Есть рекомендации о том, что к тестированию надо привлекать разработчиков. Но наша особенность в том, что у нас авторы тестов – это, по большей части, тестировщики. Есть человек-носитель знаний, который прошел обучение, он новым тестировщикам рассказывает, что, где и как. Разработчики привлекаются только в очень сложных случаях. Например, загрузка тестовых номеров для интеграционного теста.
-
И, так как кейсов у нас много и тестировщиков немало, у нас сценарное тестирование поделено на предметные области.

Что нам дало сценарное тестирование?
-
Оно нам дало ощутимую экономию: 55 человекочасов регулярно, каждые две недели. Раньше регресс длился полтора-два дня, постоянно были срывы выпусков. Сейчас регрессионное тестирование перед выпуском релиза длится полдня, иногда меньше.
-
Косвенный плюс: мы получили хранилище знаний, снизили возможный эффект bus-фактора, если все сотрудники одновременно уйдут с проекта. Каждый новый тестировщик может посмотреть свои и чужие кейсы. Иногда и разработчики смотрят.
-
И, самый приятный момент, я стал высыпаться.
Дымовые тесты
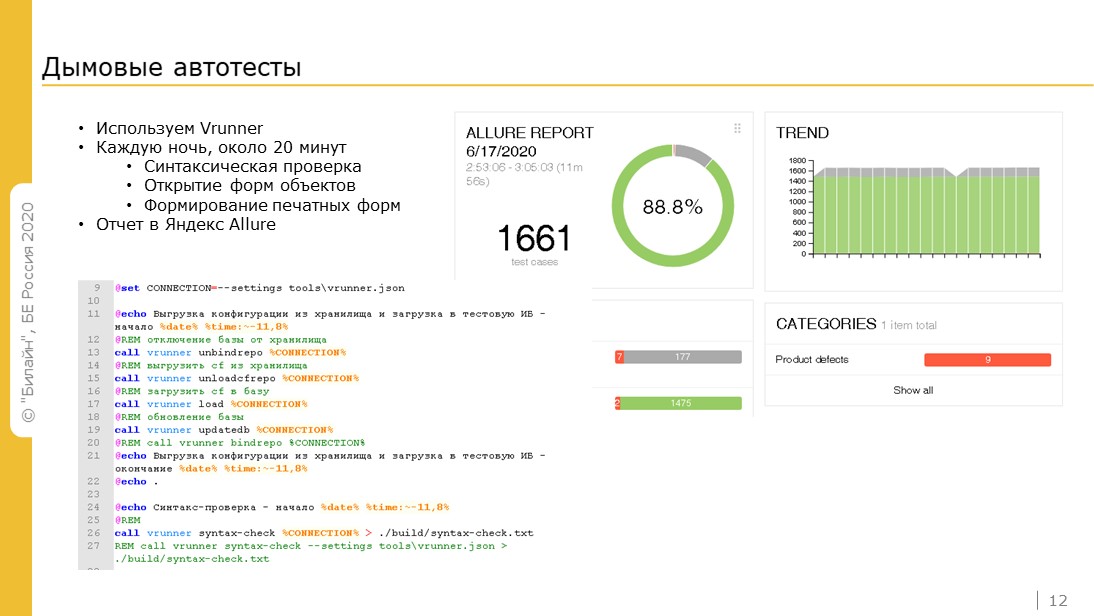
Для запуска дымовых тестов используем Vanessa Runner.
Дымовые автотесты помимо стандартной синтаксической проверки выполняют открытие основных форм объектов, формирование печатных форм, после чего у нас результаты визуализируются в Yandex Allure. На скрине можно увидеть, как выглядят результаты выполненных кейсов в отчете Allure.
Утром разработчики правят найденные ошибки.
Что нам дают дымовые автотесты? С их помощью мы можем:
-
отлавливать глупые ошибки на стадии появления;
-
снижать риски отмены релиза и дедлайна
Из плохого:
-
Мы не можем запускать дымовые тесты на каждое помещение в хранилище, так как у нас более 40 помещений в хранилище. Проверка длится 11-20 минут, мы стали бы отставать. Но ночного запуска нам хватает с головой.
-
Также из негатива – процесс по дымовым автотестам не работает совсем, если нет ответственного лица, которое постоянно дергает разработчиков. Да, приходит рассылка о том, что все плохо, но разработчики могут и забить. Поэтому есть главный над тестировщиками, который требует от разработчиков правки.
Непрерывное развертывание
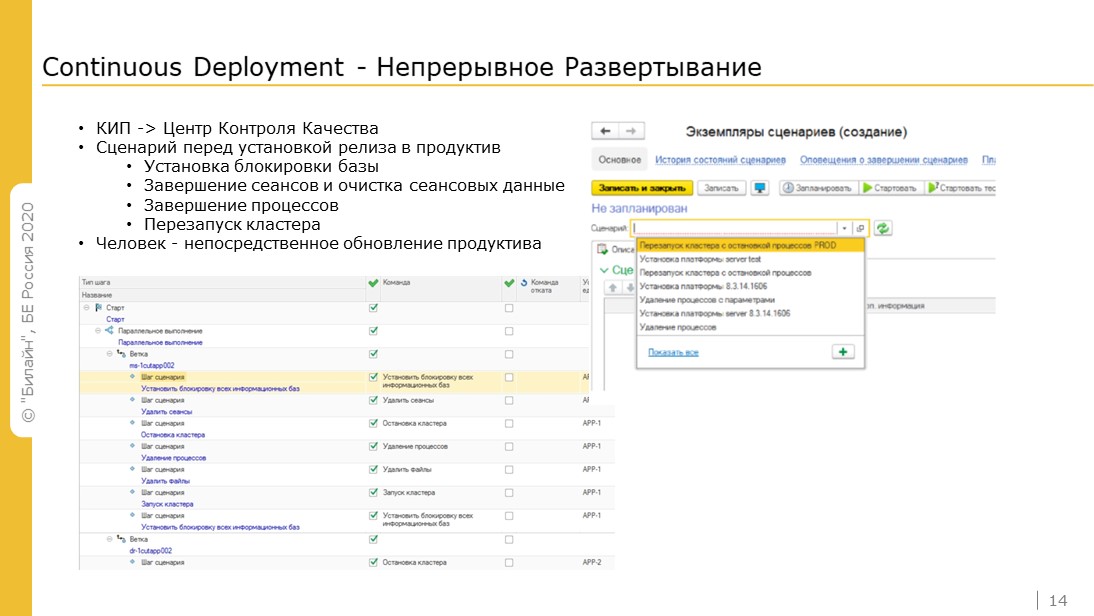
Для непрерывного развертывания мы используем Центр контроля качества (ЦКК) из состава корпоративного инструментального пакета (сейчас они вынесли эту функциональность также в Центр администрирования). Ранее мы разворачивали конфигурацию на продуктив путем написания разрозненных скриптов нашими админами, но теперь же мы заменили их на сценарии в ЦКК.
-
Текущий сценарий выполняет операции перед установкой релиза в продуктив: блокировка базы, завершение сеансов, очистка сеансовых данных, завершение процессов, перезапуск кластеров.
-
Есть определенные нюансы, связанные с объемом базы. Не все эти манипуляции очевидны. Понятно, что для обновления небольших баз какие-то шаги можно пропустить или забыть, но мы это выполняем.
-
Непосредственное обновление продуктива – пока ручная операция. Администратор выполняет команду Обновить, связано это с бюрократическими моментами.
-
Времени на обновление мало, так как режим работы нашей компании 24/7. Применяемый подход непрерывного развертывания дал нам возможность существенно сократить время обновления. Плюс ко всему, перед выпуском релиза мы всегда производим тестовое обновление: запускаем процесс обновления продуктива на его копии, замеряем время, фиксируем ошибки. Тем самым стремимся избежать ошибок при обновлении настоящего продуктива.
На скринах примеры сценариев из ЦКК.
Сбор информации о падениях
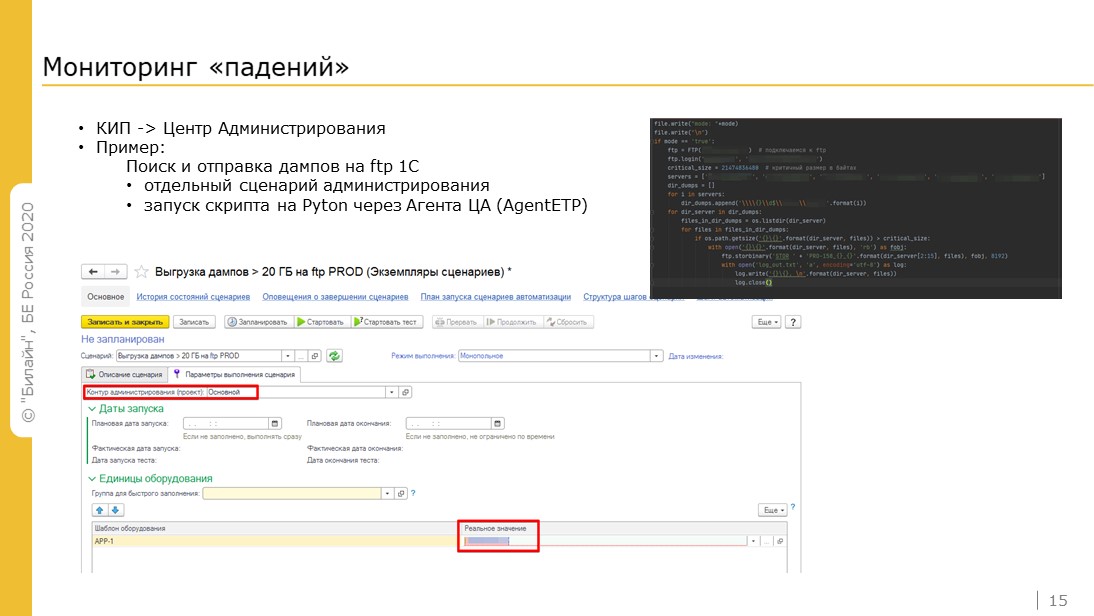
При мониторинге падений мы тесно взаимодействуем с фирмой «1С», собираем, обкатываем новые версии платформы, собираем и передаем данные для анализа. У нас с ними взаимовыгодное сотрудничество.
Как работает сбор информации, если были падения? В Центре администрирования есть сценарий, написанный на Python. Мы подхватываем нужную информацию – дампы – и отправляем их на FTP. Если на смену Python придет 1С:Исполнитель, мы будем использовать его.
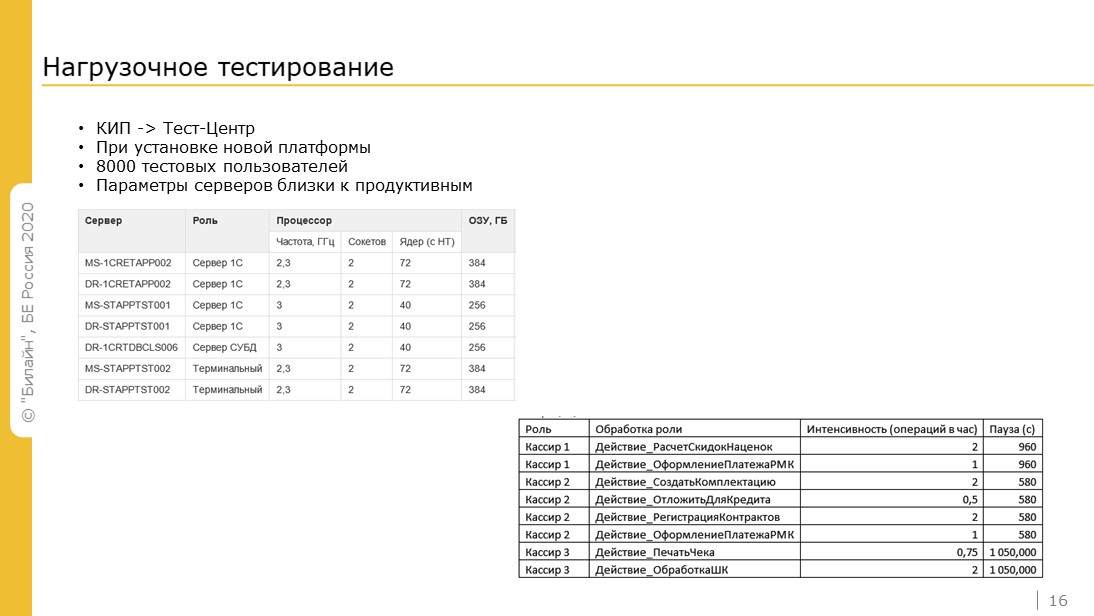
Для нагрузочного тестирования используем Тест-центр:
-
Проверяем работу нашей конфигурации на новых версиях платформы.
-
Так как в базе одномоментно может находиться 8 тысяч пользователей, то Тест-центр настроен на такое же количество пользователей, которые эмулируют частые операции с базой.
-
При этом параметры тестовых серверов близки к продуктивным. Здесь все серьезно, это не захудалый тестовый компьютер, где мы это все прогоняем. Из тестовых операций: пробитие чеков, оформление платежей, расчет скидок и т.д.
-
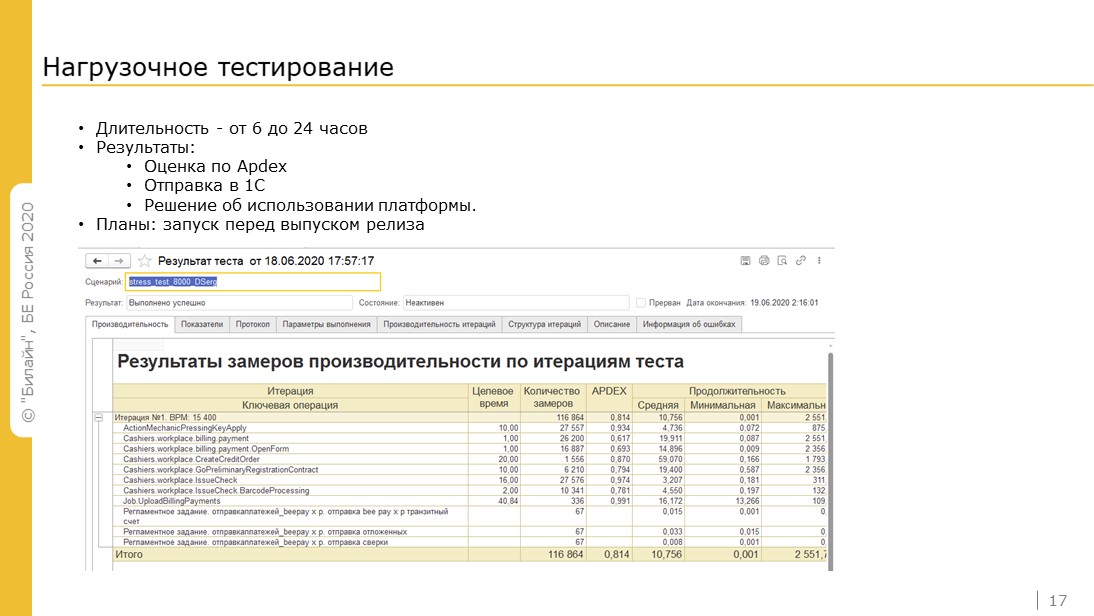
Длительность нагрузочного тестирования от 6 до 24 часов.
-
По результатам тестирования мы формируем отчет, где по каждой операции своя оценка APDEX.
-
Все это отправляем в 1С и вместе с ними принимаем решение об использовании платформы.
-
Были попытки использовать нагрузочное тестирование перед выпуском релиза, но пока мешает длительность – регрессионное тестирование заканчивается ближе к выходным, и есть риски, что нагрузочное тестирование к моменту релиза может еще не закончиться.
Мониторинг производительности
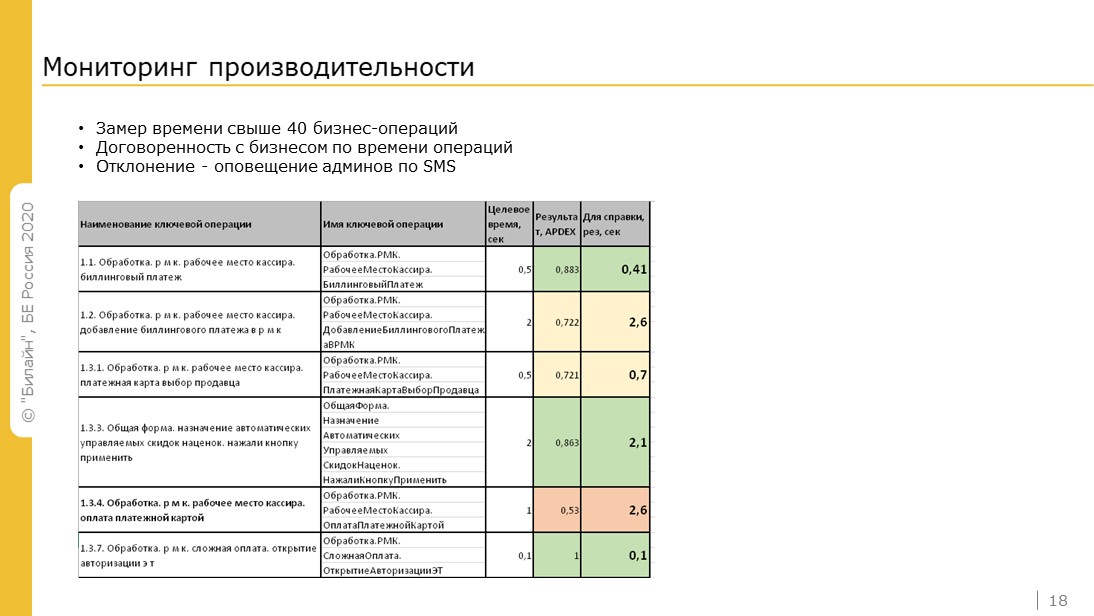
Чтобы избежать перебоев в работе нашей системы, мы постоянно ее мониторим.
-
Мониторим APDEX ключевых бизнес-показателей.
-
Есть договоренность с бизнесом по времени этих операций. Договоренность неформальная, но они этот список видят, создают инциденты, если что-то не так. Т.е. бизнес ориентируется на длительность операций, но для себя мы учитываем именно APDEX, что правильно. Также мы замеряем по ключевым операциям загрузку серверов, каналы связи и так далее.
-
При отклонении показателей наши админы получают извещение по смс
Визуализируем мониторинг
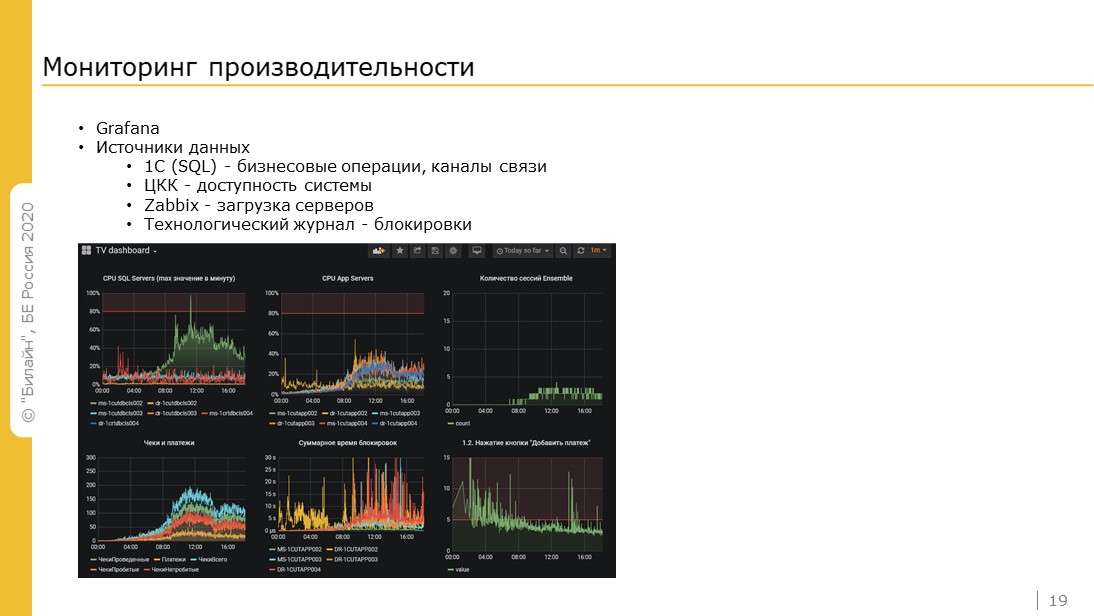
Визуализируем мониторинг через Grafana, источников данных несколько.
-
Для бизнесовых операций и каналов связи – это 1С.
-
Для доступности системы организуем некий пинг через Центр контроля качества.
-
По загрузке серверов и отчасти каналов связи используем Zabbix и технологический журнал.
-
Также технологический журнал смотрит блокировки, взаимоблокировки, дает возможность формировать полный контекст вызова для багов. У нас на продуктивном сервере отладка выключена, а технологический журнал дает полный стек вызовов, и разработчики понимают, что им править.
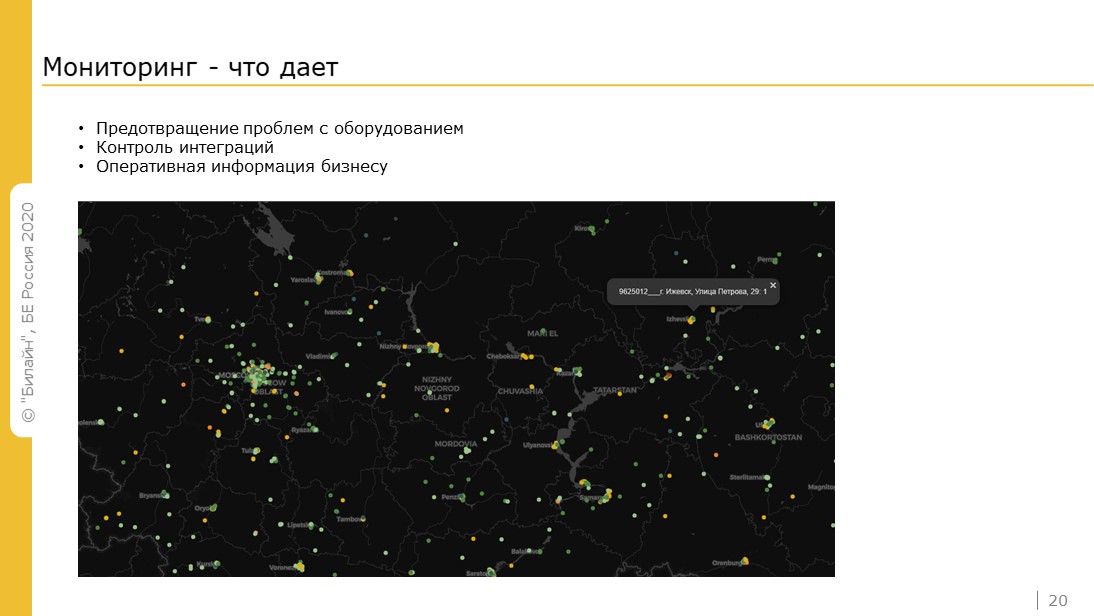
Здесь бизнесовая часть мониторинга. С его помощью мы:
-
предупреждаем проблемы оборудования;
-
видим проблемы со смежными системами, которых у нас целая куча;
-
и можем давать информацию бизнесу.
В период карантина постоянно запрашивали информацию, сколько у нас чеков пробивается в минуту, чтобы понимать рост продаж. Или почему не работает тот или иной офис.
На скрине – карта из Grafana, где мы можем видеть пропускную способность каналов связи для офисов в реальном времени, можем оперативно реагировать.
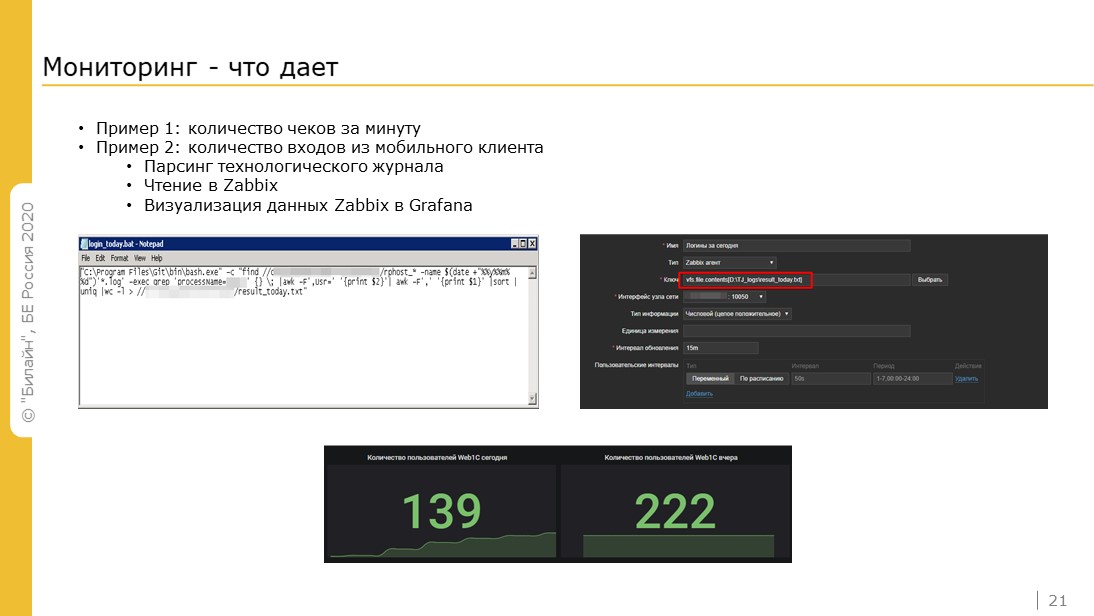
Из примеров мониторинга у нас есть мобильный клиент, мы измеряем количество входов с мобильного клиента. Для этого парсим технологический журнал, источником данных является Zabbix, a Grafana эти данные отображает. Таким образом отслеживаем, насколько успешно мы внедряем мобильный клиент в офисах.

Мой доклад носил обзорный характер. Надеюсь, слово «Осторожный» в названии доклада стало более понятно. Оно связано с тем, что:
-
Мы постоянно балансируем между стабильностью и скоростью работы.
-
У нас есть свои ограничения, которые мы принимаем или обходим.
-
У нас свое прочтение практик DevOps.
-
Идеала нет. Не бойтесь экспериментов, ищите свой путь, свое направление развития – надеюсь, мой доклад вам в этом поможет.
-
И, конечно, работайте в команде – без нее никуда.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "DevOps в 1С: Тестирование и контроль качества решений на 1С".
Технологический консалтинг и DevOps для 1С
Мы решаем проблемы производительности, инфраструктуры и автоматизации разработки на 1С

Вступайте в нашу телеграмм-группу Инфостарт