Определение DevOps

Я выбрал из Википедии несколько цитат с определением того, что такое DevOps.
-
Первое и самое важное – это взаимозависимость процессов создания продукта и эксплуатации ПО. Очень важно, чтобы при разработке продукта учитывалось, как в дальнейшем этот продукт будет эксплуатироваться, как он будет раскатываться, как будут накатываться фиксы, как будут собираться тикеты, обратная связь и т.д. Это нужно сразу продумывать, а не работать в отдельных изолированных командах – отдельно команда продукта, отдельно команда эксплуатации.
-
Мне очень нравится цитата «Культура создания ПО в команде». В DevOps очень важно пропагандировать, создавать культуру – ведь, с одной стороны, мы все айтишники, инженеры, но с другой стороны, мы художники. Мы творим, создаем новое. Мы не просто ремесленники. Слово «Культура» очень важно. Мы увеличиваем свои знания, обмениваемся знаниями, проводим какие-то культурные мероприятия, такие как митапы и конференции Инфостарта.
-
Также очень важно, чтобы у нас во всех процессах работы с продуктом использовались единые стандарты, инструменты, единое окружение. Например, чтобы команда эксплуатации использовала те же инструменты, которыми пользуются разработчики – чтобы в обеих командах при развертывании баз 1С использовался rac, ras, еще какие-то инструменты. Чтобы соблюдались единые инструменты разработки – конфигуратор или EDT, и т.д.
-
И немаловажный момент для DevOps – системы автоматизации сборки и выпуска (CI/CD/Jenkins/GitLab/Azure и т.д.) должны быть доступны соответствующим лицам с правильными ролями. И могли использоваться на разных этапах DevOps.
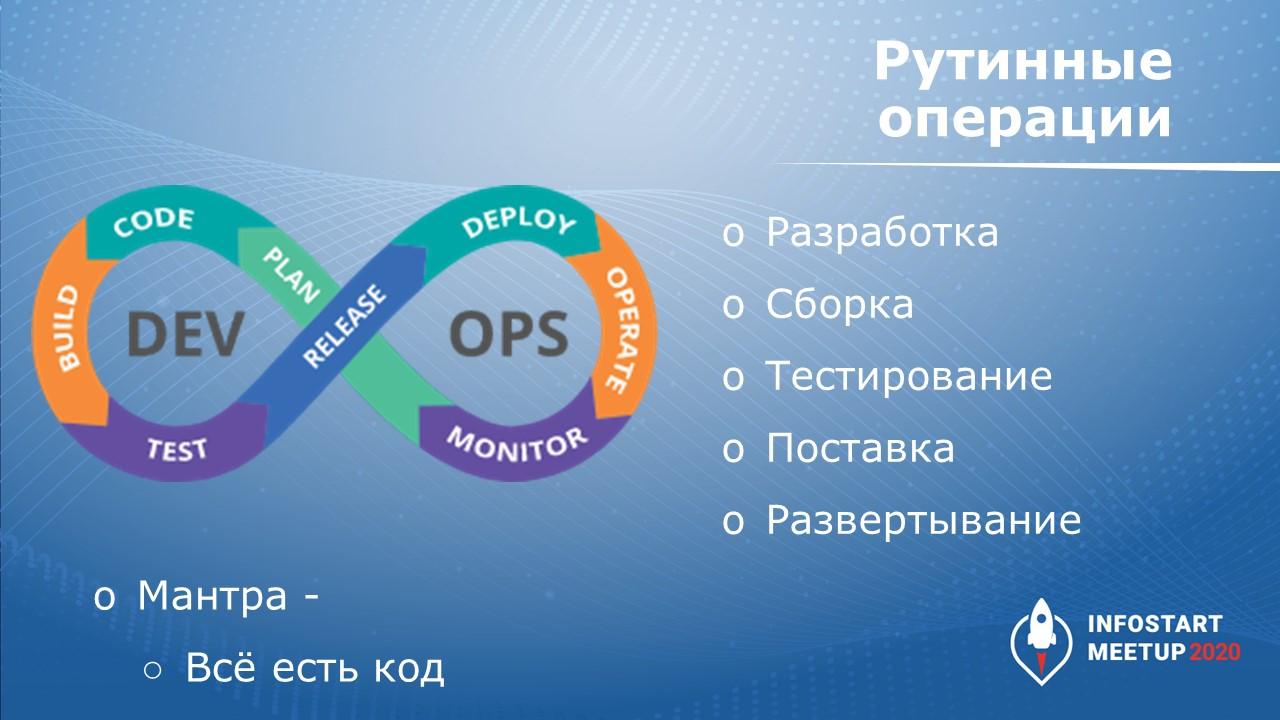
На картинке знаменитый знак бесконечности DevOps – планирование, кодирование, сборка, тестирование, потом выпуск релиза, операционная деятельность и мониторинг.
Весь мой доклад будут пронизывать некие идеи или мантры.
На слайде DevOps присутствует первая мантра «Все есть код» – она означает, что все действия, которые мы выполняем при разработке, при эксплуатации продуктов, нужно фиксировать. Это не должны быть действия, которые мы каждый раз интерактивно “закнопываем”. Все рутинные операции, которые выполняет разработчик или эксплуататор, должны выполняться в автоматическом режиме.
Например, разработчик нажимает кнопку или запускает одну простую команду, и у него выполняется сборка его проекта или собирается/обновляется информационная база. Или эксплуататор нажимает кнопку и происходит автоматическое развертывание релиза на продуктовую базу – выгоняются пользователи и т.д.
В своем выступлении я затрону шесть из восьми этапов DevOps. На «знаке бесконечности» они расположены слева и в середине – это:
-
подготовка окружения;
-
разработка;
-
сборка;
-
тестирование;
-
поставка;
-
развертывание.
На этих этапах можно использовать одни и те же инструменты.
Про оставшиеся два этапа – Operate и Monitor я рассказывать не буду, потому что для них используются немного другие инструменты.
Инструменты для автоматизации рутинных операций

Какие инструменты мы можем использовать на всех этих этапах.
-
Наш любимый и родной конфигуратор – я очень надеюсь, что мы будем все активнее использовать Снегопат, про который на митапе рассказал Александр Орефков,
-
По поводу EDT я тут поставил вопросительный и восклицательный знак. Я раньше много играл в шахматы, там для каждого хода можно поставить оценку. Вопросительно-восклицательный знак значит, что ход странный, но очень интересный. И вот EDT я поставил такую оценку, потому что EDT вроде как есть, живет, но у него есть какие-то проблемы – он работает не на всех компьютерах, не на всех конфигурациях, проблемы с установкой, со справкой и т.д. Т.е. пока еще остается вопрос с его использованием. Классный инструмент, но пока едет очень медленно, к сожалению.
-
Очень важно использовать Git в любых вариантах. Неважно, где вы разрабатываете – в конфигураторе или в EDT. Мантра «Без Git – никуда».
-
И можно использовать различные Open Source-инструменты.

Про доступные Open Source-инструменты я рассказывал на конференции Инфостарта в 2017 году.
На слайде показано облако инструментов – оно, конечно, немного уже устарело, влияние каких-то инструментов из облака уже уменьшилось, для каких-то увеличилось. EDT и SonarQube сейчас можно увеличить побольше, но набор, в принципе, для меня сейчас остался тем же.
Подготовка окружения
Настройка Git

Теперь можно перейти к внедрению.
Перед тем, как начать, важно подготовить окружение для разработки – чтобы хорошо плыть, хорошо ехать и т.д.
Мантра «Лучше день потерять, а потом за 5 минут долететь».
Поскольку мы работаем с Git, начать нужно с настроек инструмента – без правильной настройки Git с 1С-проектами не заработает или будут проблемы при его использовании. Настраивать можно самостоятельно, опираясь на материалы из статей – есть много вариантов.
Но самый простой способ – это взять некий командный файл, который настроит Git автоматически.
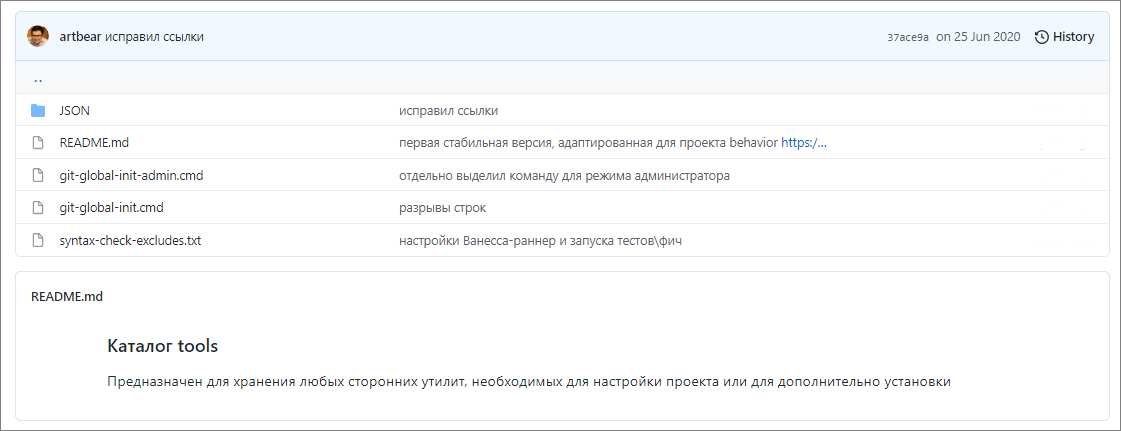
В репозитории Vanessa Bootstrap в каталоге tools я подготовил два специальных командных файла по настройке Git – git-global-init.cmd и git-global-init-admin.cmd:
-
первую команду можно запускать в обычном режиме, она делает локальную настройку для пользователя.
-
а вторую команду нужно запускать в режиме администратора.
Командный файл git-global-init.cmd
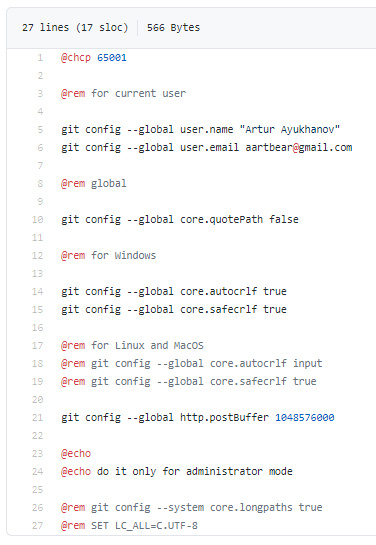
Что происходит при запуске git-global-init.cmd?
Командами
git config --global user.name "Your Name"
git config --global user.email your@email
мы указываем настройки имени и почты пользователя – это те настройки, под которыми мы будем вносить изменения в Git.
Команда
git config --global core.quotePath false
важна для корректного показа русских имен файлов.
Настройки переносов строк
git config --global core.autocrlf true
git config --global core.safecrlf true
нужны, если вы работаете на Windows – чтобы возврат каретки, перенос строки правильно учитывались. Например, команда у вас работает на Windows, а тесты, CI/CD выполняются на Linux. Чтобы нормально работало в гетерогенных средах, нужно выполнить эти две команды.
Также, если мы работаем через HTTP, желательно выставить максимальный размер буфера:
git config --global http.postBuffer 1048576000
Подытожу - берем командный файл и запускаем, он нам автоматически устанавливает все перечисленные настройки Git, и еще несколько не указанных настроек.
Командный файл git-global-init-admin.cmd
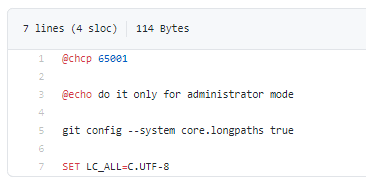
В командный файл git-global-init-admin.cmd, который нужно запускать в режиме администратора, отдельно вынесено две команды.
Команда
git config --system core.longpaths true
нужна для поддержки длинных путей файлов, потому что у нас 1С любит длинные пути, когда выгружает исходники. Плюс некоторые тестовые файлы могут иметь длинные пути.
И интересная команда, которая устанавливает переменную окружения:
SET LC_ALL=C.UTF-8
ее нужно установить, чтобы Git при выполнении верно показывал русские имена, русские сообщения в логах и т.п.
Командный файл git-global-init-admin.cmd нужно выполнить в режиме администратора.
Эту настройку нужно выполнить один раз – на каждой машине, где будет организована работа с Git.
Подготовка структуры проекта

Теперь переходим к подготовке конкретного проекта разработки.
Лучше использовать единую структуру для всех проектов 1С. И для этого давно был придуман инструмент Vanessa-bootstrap.
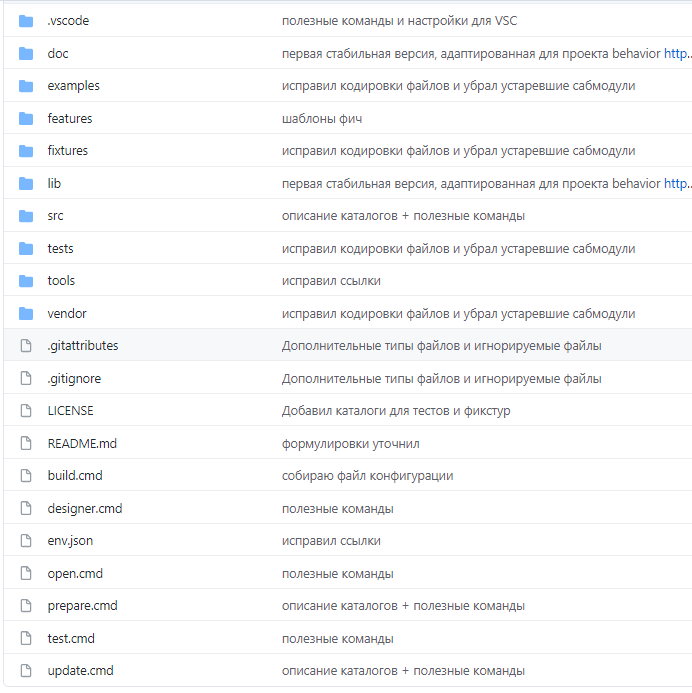
Репозиторий Vanessa-Bootstrap содержит рекомендуемую структуру каталогов. Например, здесь есть каталоги:
-
src, где хранятся исходники;
-
doc для документации;
-
examples для каких-то примеров, на которые ссылается документация;
-
features – для сценариев тестирования;
-
tests для тестов;
-
fixtures – где хранятся тестовые данные;
-
tools, чтобы хранить какие-то утилиты, ссылки, настройки;
-
vendor, чтобы хранить конкретные инструменты.
Также репозиторий содержит полезные файлы:
-
например, файл .gitignore, который позволяет пропустить различные служебные файлы;

-
или файл .gitattributes, который указывает Git-у, как правильно работать с конкретными файлами – какие файлы должны быть бинарными, в каких файлах нужны правильные переносы (например, чтобы правильно работать с файлами 1С, нужно в качестве разрыва строк указывать crlf).
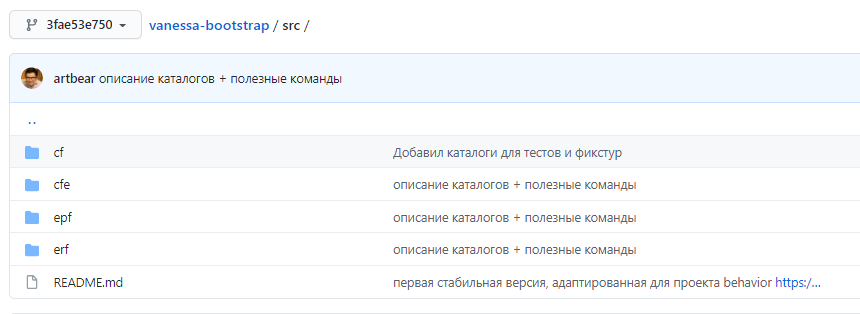
Внутренние каталоги тоже имеют рекомендуемую структуру. Например, внутри каталога src есть:
-
папка cf, в которой мы храним исходники конфигурации текущего проекта;
-
папка cfe для расширений – для каждого расширения вводится отдельный подкаталог;
-
папка epf для внешних обработок;
-
папка erf для внешних отчетов.
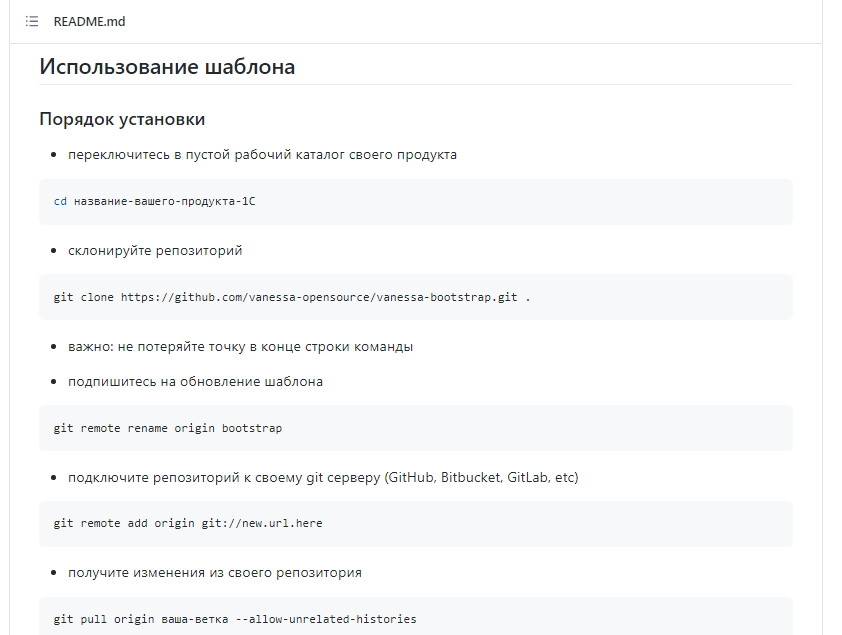
В файле README.md описаны команды, которые нужно выполнить, чтобы использовать этот проект:
-
создаем для вашего продукта пустой каталог, переходим в него:
cd название-вашего-продукта-1С -
клонируем сюда репозиторий Vanessa bootstrap:
git clone https://github.com/vanessa-opensource/vanessa-bootstrap.git . -
потом переименовываем origin репозитория, чтобы можно было подключать свой origin:
git remote rename origin bootstrap -
добавляем свой origin – подключаемся удаленному репозиторию, где хранятся изменения вашего продукта:
git remote add origin git://new.url.here -
и заливаем изменения из своего репозитория:
git pull origin ваша-ветка --allow-unrelated-histories -
если у вас уже использовалась какая-то своя структура каталога (например, свои файлы gitattributes, gitignore) – исправьте конфликты;
-
все, можно начинать работать.
Давайте я создам каталог и выполню в нем команду:
git clone https://github.com/vanessa-opensource/vanessa-bootstrap.git .
Очень важно учесть точку в конце, чтобы изменения склонировались в текущий каталог – теперь здесь есть все файлы, про которые я говорил.
Потом выполняю команду по переименованию ветки origin:
git remote rename origin bootstrap
Команду по подключению своего удаленного репозитория и заливке изменений из него я выполнять не буду – буду считать, что я разрабатываю с нуля, когда удаленного репозитория со своим проектом еще нет.
В принципе, все – весь набор файлов есть. Но здесь пока пусто.
Теперь нужно перейти к следующему этапу.
Первичная настройка для выполнения команд

Мы создали проект, создали для него структуру и теперь нужно выполнить первичную настройку, указать:
-
с какой версией платформы мы работаем;
-
с какой служебной базой мы работаем – это может быть файловая база или клиент-серверная база, которая развернута на какой-то машине и т.д.
Эти настройки будут использоваться для выполнения команд через инструмент Vanessa-runner.
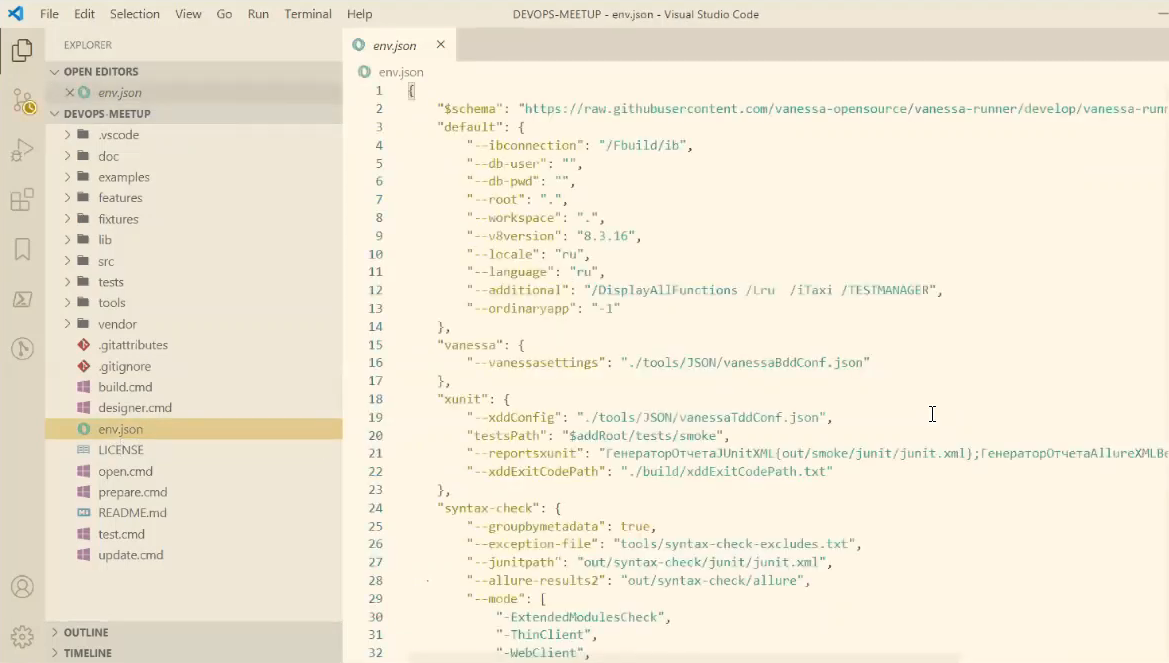
Для внесения изменений в файлы настроек используем Visual Studio Code – открываем его для конкретного каталога проекта.
Важно помнить, что нужно работать именно с каталогом проекта на вашем компьютере. Не открывайте отдельные файлы, подкаталоги.
В Git есть такое понятие – рабочий каталог проекта. С ним мы и работаем всегда. Сразу открываем сам основной рабочий каталог.
Начинаем с настроек файла env.json. Он является главным файлом настроек для Vanessa-runner. Все команды, которые мы в дальнейшем будем на разных этапах выполнять, используют этот файл, будут обращаться к нему.
Начинать нужно с секции default – в ней нужно настроить основные настройки.
-
Первое – в параметре --v8version (2 дефиса) обязательно указываем платформу, с которой работаем. Это важно, потому что, если вы работаете с клиент-серверной базой, и укажете не ту платформу, будет ошибка выполнения. Если вы работаете с файловой базой и не укажете версию, у вас может открыться самая новая платформа, а вам, возможно, это не нужно – у вас продуктив работает на платформе 8.3.16. Поэтому обязательно заполняем.
-
Также, если нужно, указываем настройки локализации – параметры locale и language (по умолчанию русский).
-
И указываем строку соединения к базе – параметр --ibconnection. Если мы используем служебную файловую базу данных, тогда строка соединения должна начинаться на строку /F, которая означает, что база файловая.
-
Параметры --db-user и --db-pwd – указываем логин и пароль.
-
И параметр --ordinaryapp отвечает за запуск определенного типа клиента – тонкий или толстый. Значение -1 означает, что будет запущен тонкий клиент.
Настройки в других секциях:
-
vanessa – предназначены для запуска BDD-тестов,
-
xunit – для запуска дымовых тестов
-
syntax-check – это расширенной синтаксической проверки.
Эти настройки будут использоваться далее на этапе CI/CD.
Получение исходников

Следующее – нужно каким-то образом получить исходники. Очередной раз здесь появляется мантра «Все есть код».
Каким образом можно получить исходники?
-
Можно получить исходники напрямую из хранилища с помощью инструмента gitsync – достаточно легко и просто.
-
Можно вручную выгрузить файлы из конфигуратора – вызвать из меню «Конфигурация» команду «Выгрузить файлы».
-
Можно получить исходники из файла конфигурации с помощью команды vrunner decompile – например, у вас есть готовый cf-ник из тестовой базы.
-
Или, если в организации уже есть Git-репозиторий с исходниками, а вы только подключились к разработке, то можете просто написать git clone.
Положим в корень каталога проекта файл конфигурации 1cv8.cf, попробуем получить его исходники и положить их в каталог src/cf. Если не помним, какие параметры указывать в команде, можно вызвать справку:
vrunner help decompile
Для распаковки конфигурации на исходники вызываем команду.
vrunner decompile --out src/cf --in ../1cv8.cf
После этой команды в каталоге src/cf появятся все необходимые файлы.
Подготовка окружения – создание служебной базы для тестирования из cf-файла

Следующее – нужно подготовить окружение.
Мы настроили Git, сформировали структуру в каталоге проекта, указали в файле настроек платформу, логин и пароль. Теперь нужно подготовить нашу служебную базу.
Командный файл prepare.cmd
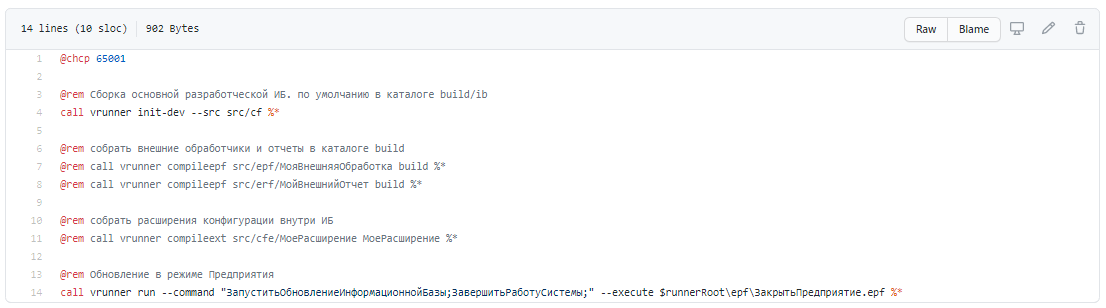
Чтобы создать служебную базу, из шаблона Vanessa-Bootstrap выполняем команду prepare.cmd. Она выполняет вызов vrunner с параметром init-dev и загружает нашу служебную базу из исходников, которые лежат в каталоге src/cf.
Что делает команда prepare? Она загружает исходники в базу в режиме конфигуратора, выполняет обновление базы, и потом выполняет обновление в режиме предприятия, чтобы запустились обработчики обновления (например, БСП-шные обработчики).
Обновление в режиме предприятия нужно делать обязательно, потому что очень часто команда разработки отдает команде эксплуатации многостраничные инструкции о том, что мы выпустили релиз, вам нужно зайти в программу – ввести в ней такие-то данные, запустить миграцию данных, запустить внешнюю обработку или алгоритм и т.д. Такие ручные действия неверны по многим факторам, расшифровывать не буду, можем обсудить в комментариях. Все эти данные нужно вводить полностью автоматически с помощью обработчиков обновления.
Все, мы настроили окружение, теперь можно перейти непосредственно к разработке.
Разработка
Представим, что нам нужно приступить к новой задаче. Что нужно сделать? Всегда нужно обновиться. Из хранилища, из Git и т.д. Для этого существует командный файл update.cmd.
Командный файл update.cmd
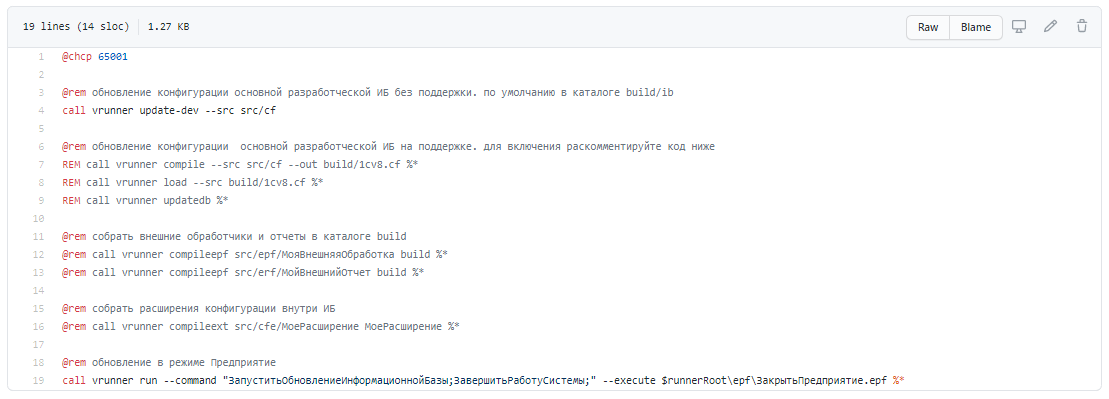
Командный файл update.cmd запускает команду:
vrunner update-dev --src src/cf
В процессе выполнения команды точно так же из исходников забираются изменения конфигурации и выполняется обновление в режиме 1С:Предприятие. Если вы работаете с хранилищем, то эту команду можно подправить, чтобы данные подгружались из хранилища, но я предпочитаю забирать обновления из исходников в Git.
Другие полезные командные файлы из Vanessa-bootstrap
Vanessa-bootstrap содержит дополнительные командные файлы для автоматизации простых рутинных действий, которые мы всегда выполняем – открыть конфигуратор, поработать в нем, закрыть. Открыть 1С и т.д.

Командный файл designer.cmd. Этот командный файл открывает конфигуратор нужной базы с подстановкой логина/пароля и т.д. Можно не открывать базу руками, а просто запускать этот файл.
Запускаем команду designer.cmd прямо в каталоге проекта, и запускается конфигуратор конкретно для этой базы, которая лежит в каталоге build\ib – это та самая база, путь к которой указан в настройках проекта.

Командный файл open.cmd. Также можно запустить командный файл open, который просто запустит нужную 1С в нужном режиме. Например, открываем тонкий клиент в режиме 1С:Предприятие. Если нужно, в режиме менеджера тестирования. Если нужно, можно вообще открыть сразу нужную обработку и т.д.
Это такие простые рутинные действия, которые можно автоматизировать без нажатия кучи кнопочек.
Я надеюсь, скоро добавятся команды Снегопата, чтобы вместо конфигуратора мы могли сразу запускать Снегопат.
Тестирование
Переходим к тестированию. Опять же, как это делается?
С помощью командного файла test.cmd можно быстро запускать тесты.
Командный файл test.cmd

Внутри, если посмотреть, командный файл test.cmd выглядит очень просто – используется команда:
vrunner vanessa %1
эта команда позволяет быстро прогнать фичи.
Можно дополнить этот командный файл модульным или дымовым тестированием, добавив команду:
vrunner xunit %1
но дымовое тестирование выполняется достаточно долго, поэтому сейчас делаем просто быстрое тестирование через BDD-тесты (инструмент Vanessa-ADD) или через модульные тесты (также инструмент Vanessa-ADD).
Магия для запуска тестирования в VS Code
Чтобы упростить работу с тестами, есть возможность применить определенную магию.
Давайте откроем в VS Code файл какой-нибудь фичи – например, в шаблоне Vanessa-Bootstrap в папке features есть файл «Шаблон фичи.feature».
И запустим из меню Terminal («Терминал») команду «Run task» («Запуск задачи») – у меня эта команда для ускорения работы назначена на горячую клавишу кнопку F7.
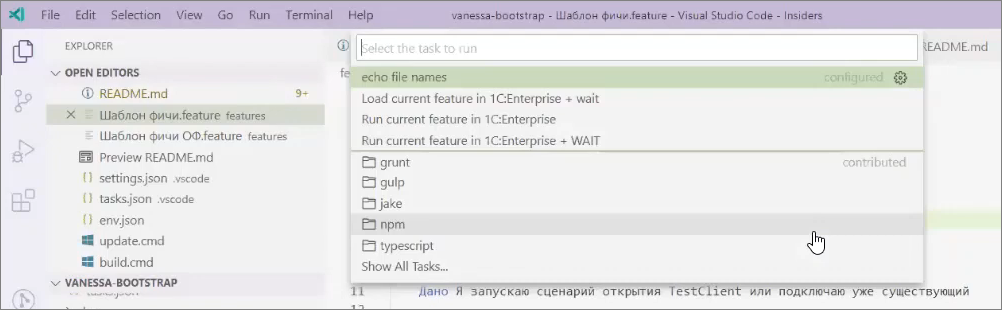
В шаблоне Vanessa-bootstrap я добавил три команды для работы с тестами, с фичами, с bdd. В чем между ними разница?
-
Команда «Load current feature in 1C:Enterprise + wait» загрузит текущую фичу в режиме менеджера тестирования и как-то ее отладить.
-
Вторая команда «Run current feature in 1C:Enterprise» позволяет сразу выполнить фичу – лог выполнения будет выведен в VS Code. 1С полностью прогонит тестирование этой фичи и завершит свою работу.
-
И последняя команда «Run current feature in 1C:Enterprise + WAIT», которой я чаще всего пользуюсь – мы запустим текущую фичу в конкретной базе, ее выполним и остановимся на ожидании. Никакие тест-клиенты, ничего не закроется – можно будет посмотреть результаты, посмотреть состояние тест-клиентов, состояние базы. При необходимости перезагрузить фичу, продолжить с любого места и т.д.
Пользоваться этими командами очень удобно, очень быстро. Если мы будем делать интерактивно, это достаточно долго – запустить 1С, открыть Vanessa Add (или Vanessa Automation), найти нужную фичу, дождаться, пока она загрузится, потом нажать кнопку выполнить, дождаться, пока все выполнится. Это все время и потери. Проще запустить и пойти делать свои дела.
Формирование файлов поставки
На этапе поставки выполняются похожие команды, все также с помощью инструментов командной строки.
Мы на этом этапе готовим некие артефакты – например, файл конфигурации, файл внешних обработок и т.д. Для этого существует команда build. Тут я представил несколько вариантов. Можно собрать файл конфигурации, а можно, если у вас есть внешние обработки, отчеты, расширения, собрать их.
Командный файл build.cmd
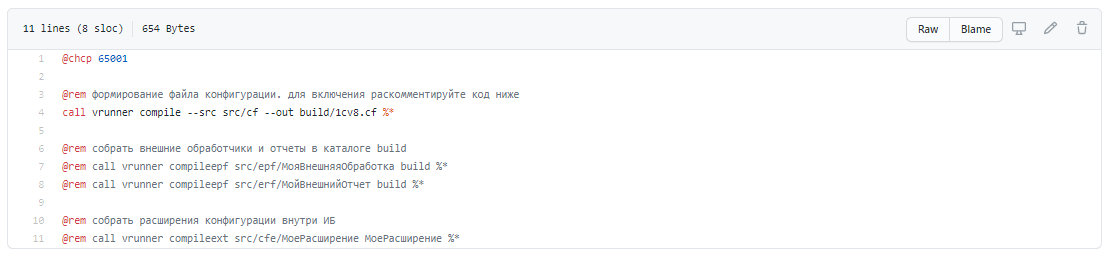
Здесь я представил несколько вариантов – по умолчанию используется команда vrunner compile для формирования файла конфигурации. Но если у вас в проекте есть внешние обработки, отчеты и расширения, можно также раскомментировать строки с командами compileepf и compileext – это все можно использовать.
После запуска build.cmd у нас в каталоге build из исходников в папке src/cf будет создан 1cv8.cf.
Развертывание
Дальше – при развертывании какие команды? Все тот же наш Vanessa-runner.
-
В первую очередь, команда
vrunner session
она позволяет управлять серверами 1С, отключать пользователей, запрещать им вход, разрешать и т.д. Очень полезно при развертывании. Как на продуктиве – тот самый деплой, так и на тестовых базах или на разработческих базах – все это можно использовать. -
Команда
vrunner load
просто загружает файл конфигурации. -
Команда
vrunner update
использует для загрузки файл поставки cfu, если у вас продуктив находится на поддержке. -
Команда
vrunner updatedb
делает обновление в режиме конфигуратора (замена кнопки F7 в Конфигураторе), -
И команда
vrunner run
это обновление в режиме предприятия. Очень важный элемент – миграция данных в режиме предприятия, про которую я уже упоминал.
Этап Operate (CI/CD)
И на этапе того самого Ops на CI/CD мы выполняем абсолютно те же самые команды.
Единственное, что там могут добавиться некие ключи – например:
-
пути к информационным базам, потому что это должна быть специальная тестовая база.
-
какие-то логины и пароли,
-
секретные токены/ключи и т.д., которые нельзя показывать, ими управляют ответственные лица.
Для всего этого используется Jenkins или GitLab – на всех этих серверах все это выглядит одинаково.
*************
Об этом, и не только, в подробностях и пошагово, будет рассказано и показано в курсе, который стартует 16 июля 2021 года: "DEVOPS для 1C". Курс был существенно обновлен и расширен с момента его последнего проведения.
Записаться на курс
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "DevOps в 1С: Тестирование и контроль качества решений на 1С".
Технологический консалтинг и DevOps для 1С
Мы решаем проблемы производительности, инфраструктуры и автоматизации разработки на 1С

Вступайте в нашу телеграмм-группу Инфостарт