Чтобы более качественно понимать, как работает механизм соединений, решил написать поиск простых чисел через запрос, используя классический алгоритм Решето Эратосфена с элементами оптимизации. Позже уже увидел в этой публикации подобные решения, однако они сегодня менее производительны (для 106 не дождался вычислений). В новой версии платформы 8.3.20 в языке запросов появились новые функции возведения в степень/вычисление квадратного корня и округления до целого без лишних конструкций. Поэтому решение получается более простым и быстрым. Кроме того добавлено больше элементов оптимизации. Также приведена сравнительная характеристика по скорости вычисления для разных СУБД.
Публикация состоит из трех разделов:
- Краткое описание алгоритма
- Решение
- Скорость вычисления и сравнение производительности вычислений с двумя основными СУБД, файловым вариантом, чистым MSSQL и императивным кодом на 1С.
Простым числом называется такое число, которое больше единицы и без остатка делится только на единицу и самого себя. Наиболее простой вариант нахождения простых чисел - это брать последовательно каждое число и проверять его делимость на все предыдущие. Быстро приходим к выводу, что проверять все числа избыточно. Как минимум, нужно идти до половины (понятно, что при делении числа N на число Целое(N / 2) + k целового не получится), а если быть точнее, то делить будем только до квадратного из искомого числа. По одной из теорем наименьший положительный и отличный от единицы делитель составного числа a не превосходит его квадратный корень.
Запрос построен из двух частей:
- Генерация чисел, которые будем проверять на простоту
- Вычисление, является ли число простым
В качестве параметра запроса передаем верхнюю границы последовательности.
Генерация чисел осуществляется классическим способом через декартово произведение. Но написано немного хитро, чтобы быстро работало при любых значениях параметра. Если не отсеивать ненужные объединения при мелком значении параметра, то будет затрачиваться много времени на генерацию последовательности (чтобы всегда десять миллионов чисел не генерировалось). Поэтому использую полное соединение по Истина. Если не указывать соединения, то результат выборки будет только тогда, когда у всех выбираемых таблиц есть хотя бы одно значение. При полном соединении по Истина всегда выберутся данные хотя бы с одной таблицы, если там что-то есть.
Добавляем +2 внутри первого запроса, где получаются числа, чтобы генерация началась с двойки, так как 1 - это не простое число.
Далее отсекаем все числа, оканчивающиеся на четные цифры и кратные 5. Такие числа точно не будут являться простыми, нет смысла их рассматривать.
Не уверен, что здесь нужен индекс. Кажется, что он тут не срабатывает. Однако на скорость работы его наличия не влияет по тестам, так что оставил.
Генерируется максимум до 107 чисел.
Запрос 1. Генерация нужной числовой последовательности
ВЫБРАТЬ
Числа.Число КАК Число
ПОМЕСТИТЬ Числа
ИЗ
(ВЫБРАТЬ
Числа.Число КАК Число,
Числа.Число - 10 * ЦЕЛ(Числа.Число / 10) КАК ПоследняяЦифра
ИЗ
(ВЫБРАТЬ РАЗЛИЧНЫЕ
ЕСТЬNULL(T.tt * 1000000, 0) + ЕСТЬNULL(U.uu * 100000, 0) + ЕСТЬNULL(V.vv * 10000, 0) + ЕСТЬNULL(W.ww * 1000, 0) + ЕСТЬNULL(X.xx * 100, 0) + ЕСТЬNULL(Y.yy * 10, 0) + Z.zz + 2 КАК Число
ИЗ
(ВЫБРАТЬ 0 КАК zz ОБЪЕДИНИТЬ ВЫБРАТЬ 1 ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ОБЪЕДИНИТЬ ВЫБРАТЬ 4 ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ОБЪЕДИНИТЬ ВЫБРАТЬ 6 ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ОБЪЕДИНИТЬ ВЫБРАТЬ 8 ОБЪЕДИНИТЬ ВЫБРАТЬ 9)
КАК Z
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ Y.yy КАК yy ИЗ
(ВЫБРАТЬ 0 КАК yy ОБЪЕДИНИТЬ ВЫБРАТЬ 1 ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ОБЪЕДИНИТЬ ВЫБРАТЬ 4 ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ОБЪЕДИНИТЬ ВЫБРАТЬ 6 ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ОБЪЕДИНИТЬ ВЫБРАТЬ 8 ОБЪЕДИНИТЬ ВЫБРАТЬ 9) КАК Y
ГДЕ &РазмерПоследовательности > 10)
КАК Y ПО (ИСТИНА)
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ X.xx КАК xx ИЗ
(ВЫБРАТЬ 0 КАК xx ОБЪЕДИНИТЬ ВЫБРАТЬ 1 ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ОБЪЕДИНИТЬ ВЫБРАТЬ 4 ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ОБЪЕДИНИТЬ ВЫБРАТЬ 6 ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ОБЪЕДИНИТЬ ВЫБРАТЬ 8 ОБЪЕДИНИТЬ ВЫБРАТЬ 9) КАК X
ГДЕ &РазмерПоследовательности > 100)
КАК X ПО (ИСТИНА)
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ W.ww КАК ww ИЗ
(ВЫБРАТЬ 0 КАК ww ОБЪЕДИНИТЬ ВЫБРАТЬ 1 ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ОБЪЕДИНИТЬ ВЫБРАТЬ 4 ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ОБЪЕДИНИТЬ ВЫБРАТЬ 6 ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ОБЪЕДИНИТЬ ВЫБРАТЬ 8 ОБЪЕДИНИТЬ ВЫБРАТЬ 9) КАК W
ГДЕ &РазмерПоследовательности > 1000)
КАК W ПО (ИСТИНА)
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ V.vv КАК vv ИЗ
(ВЫБРАТЬ 0 КАК vv ОБЪЕДИНИТЬ ВЫБРАТЬ 1 ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ОБЪЕДИНИТЬ ВЫБРАТЬ 4 ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ОБЪЕДИНИТЬ ВЫБРАТЬ 6 ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ОБЪЕДИНИТЬ ВЫБРАТЬ 8 ОБЪЕДИНИТЬ ВЫБРАТЬ 9) КАК V
ГДЕ &РазмерПоследовательности > 10000)
КАК V ПО (ИСТИНА)
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ U.uu КАК uu ИЗ
(ВЫБРАТЬ 0 КАК uu ОБЪЕДИНИТЬ ВЫБРАТЬ 1 ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ОБЪЕДИНИТЬ ВЫБРАТЬ 4 ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ОБЪЕДИНИТЬ ВЫБРАТЬ 6 ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ОБЪЕДИНИТЬ ВЫБРАТЬ 8 ОБЪЕДИНИТЬ ВЫБРАТЬ 9) КАК U
ГДЕ &РазмерПоследовательности > 100000)
КАК U ПО (ИСТИНА)
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ T.tt КАК tt ИЗ
(ВЫБРАТЬ 0 КАК tt ОБЪЕДИНИТЬ ВЫБРАТЬ 1 ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ОБЪЕДИНИТЬ ВЫБРАТЬ 4 ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ОБЪЕДИНИТЬ ВЫБРАТЬ 6 ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ОБЪЕДИНИТЬ ВЫБРАТЬ 8 ОБЪЕДИНИТЬ ВЫБРАТЬ 9) КАК T
ГДЕ &РазмерПоследовательности > 1000000)
КАК T ПО (ИСТИНА)
) КАК Числа
ГДЕ
Числа.Число <= &РазмерПоследовательности) КАК Числа
ГДЕ
(Числа.ПоследняяЦифра = 1
ИЛИ Числа.ПоследняяЦифра = 3
ИЛИ Числа.ПоследняяЦифра = 7
ИЛИ Числа.ПоследняяЦифра = 9)
ИНДЕКСИРОВАТЬ ПО
Числа.Число
;
Далее соединяем эту числовую последовательность саму с собой по условию <= от квадратного корня числа. В итоге каждому числу первой таблицы будет сопоставлено каждое число второй таблицы до квадратного корня.
При этом не будем рассматривать числа, кратные 2, 3, 5 или 7. Такая проверка в условии соединения будет выполняться быстрее, чем дальнейшее рассмотрение таких чисел. Выигрыш в скорости почти в 2 раза.
Выражение N - M * ЦЕЛ(N / M) равносильно выражению N % M (это остаток от деления).
В условии ИМЕЮЩИЕ помещаем выражение, которое возвращает остаток от деления числа, которое мы выбираем, на числа второй таблицы. Если все числа поделились с остатком, то МИНИМУМ вернет число большее нуля.
В объединениях добавляем нерассмотренные простые числа, которые выпали на уровне условия соединения.
Запрос 2. Генерация последовательности простых чисел
ВЫБРАТЬ
КОЛИЧЕСТВО(ПростыеЧисла.ПростоеЧисло) КАК КоличествоПростыхЧисел
ИЗ
(ВЫБРАТЬ
Числа1.Число КАК ПростоеЧисло
ИЗ
Числа КАК Числа1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Числа КАК Числа2
ПО (Числа2.Число <= SQRT(Числа1.Число))
И (Числа1.Число - 2 * ЦЕЛ(Числа1.Число / 2) <> 0)
И (Числа1.Число - 3 * ЦЕЛ(Числа1.Число / 3) <> 0)
И (Числа1.Число - 5 * ЦЕЛ(Числа1.Число / 5) <> 0)
И (Числа1.Число - 7 * ЦЕЛ(Числа1.Число / 7) <> 0)
СГРУППИРОВАТЬ ПО
Числа1.Число
ИМЕЮЩИЕ
МИНИМУМ(Числа1.Число - Числа2.Число * ЦЕЛ(Числа1.Число / Числа2.Число)) > 0
ОБЪЕДИНИТЬ ВЫБРАТЬ 2 ГДЕ &РазмерПоследовательности >= 2
ОБЪЕДИНИТЬ ВЫБРАТЬ 3 ГДЕ &РазмерПоследовательности >= 3
ОБЪЕДИНИТЬ ВЫБРАТЬ 5 ГДЕ &РазмерПоследовательности >= 5
ОБЪЕДИНИТЬ ВЫБРАТЬ 7 ГДЕ &РазмерПоследовательности >= 7
) КАК ПростыеЧисла
Также решил написать запрос на чистом SQL (используя T-SQL в MSSQL). Чтобы сравнить производительность запроса, написанного через 1С-овскую обертку и напрямую. Разница в производительность оказалось огромной. Для того, чтобы результат сравнения был релевантный, то сделал также вариант запроса без использования оператора "%". Так как оператор остатка от деления почему-то не завезли в язык запросов 1С.
Здесь, в T-SQL, созданный вручную индекс во временной таблице работает. Скорость выполнения с индексом выше почти в 1,5 раза.
Запрос на T-SQL (без оператора "%" остатка от деления)
DECLARE @limit INT;
SET @limit = 1000000;
IF OBJECT_ID('tempdb..#numbers') IS NOT NULL
DROP TABLE #numbers;
SELECT
numbers.number
INTO #numbers
FROM(SELECT
numbers.number,
numbers.number - 10 * FLOOR(numbers.number / 10) last_digit
FROM(
SELECT DISTINCT
ISNULL(T.t * 1000000, 0) + ISNULL(U.u * 100000, 0) + ISNULL(V.v * 10000, 0) + ISNULL(W.w * 1000, 0) + ISNULL(X.x * 100, 0) + ISNULL(Y.y * 10, 0) + Z.z + 2 AS number
FROM
(SELECT 0 z UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9) Z
FULL OUTER JOIN (SELECT Y.y FROM
(SELECT 0 y UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
Y WHERE @limit > 10) Y ON 1=1
FULL OUTER JOIN (SELECT X.x FROM
(SELECT 0 x UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
X WHERE @limit > 100) X ON 1=1
FULL OUTER JOIN (SELECT W.w FROM (
SELECT 0 w UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
W WHERE @limit > 1000) W ON 1=1
FULL OUTER JOIN (SELECT V.v FROM
(SELECT 0 v UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
V WHERE @limit > 10000) V ON 1=1
FULL OUTER JOIN (SELECT U.u FROM
(SELECT 0 u UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
U WHERE @limit > 100000) U ON 1=1
FULL OUTER JOIN (SELECT T.t FROM
(SELECT 0 t UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
T WHERE @limit > 1000000) T ON 1=1
) AS numbers
WHERE numbers.number <= @limit
) AS numbers
WHERE (numbers.last_digit = 1
OR numbers.last_digit = 3
OR numbers.last_digit = 7
OR numbers.last_digit = 9)
;
CREATE INDEX id_number ON #numbers(number)
;
SELECT
COUNT(prime_numbers.prime_number) AS count_primeNumbers
FROM(
SELECT
numbers1.number AS prime_number
FROM
#numbers AS numbers1
JOIN #numbers AS numbers2
ON numbers2.number <= SQRT(numbers1.number)
AND (numbers1.number - 2 * FLOOR(numbers1.number / 2) <> 0)
AND (numbers1.number - 3 * FLOOR(numbers1.number / 3) <> 0)
AND (numbers1.number - 5 * FLOOR(numbers1.number / 5) <> 0)
AND (numbers1.number - 7 * FLOOR(numbers1.number / 7) <> 0)
GROUP BY numbers1.number
HAVING MIN(numbers1.number - numbers2.number * FLOOR(numbers1.number / numbers2.number)) > 0
UNION SELECT 2 WHERE @limit >= 2
UNION SELECT 3 WHERE @limit >= 3
UNION SELECT 5 WHERE @limit >= 5
UNION SELECT 7 WHERE @limit >= 7
) AS prime_numbers
;
DROP TABLE #numbers
Запрос на T-SQL (более быстрый, с использованием "%")
IF OBJECT_ID('tempdb..#numbers') IS NOT NULL
DROP TABLE #numbers
;
SELECT numbers.number
INTO #numbers
FROM(SELECT DISTINCT
ISNULL(T.t * 1000000, 0) + ISNULL(U.u * 100000, 0) + ISNULL(V.v * 10000, 0) + ISNULL(W.w * 1000, 0) + ISNULL(X.x * 100, 0) + ISNULL(Y.y * 10, 0) + Z.z + 2 AS number
FROM
(SELECT 0 z UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9) Z
FULL OUTER JOIN (SELECT Y.y FROM
(SELECT 0 y UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
Y WHERE @limit > 10) Y ON 1=1
FULL OUTER JOIN (SELECT X.x FROM
(SELECT 0 x UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
X WHERE @limit > 100) X ON 1=1
FULL OUTER JOIN (SELECT W.w FROM (
SELECT 0 w UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
W WHERE @limit > 1000) W ON 1=1
FULL OUTER JOIN (SELECT V.v FROM
(SELECT 0 v UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
V WHERE @limit > 10000) V ON 1=1
FULL OUTER JOIN (SELECT U.u FROM
(SELECT 0 u UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
U WHERE @limit > 100000) U ON 1=1
FULL OUTER JOIN (SELECT T.t FROM
(SELECT 0 t UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9)
T WHERE @limit > 1000000) T ON 1=1
) AS numbers
WHERE numbers.number <= @limit
AND (numbers.number % 10 = 1
OR numbers.number % 10 = 3
OR numbers.number % 10 = 7
OR numbers.number % 10 = 9)
;
CREATE INDEX id_number ON #numbers(number)
;
SELECT
COUNT(prime_numbers.prime_number) AS count_prime_numbers
FROM(
SELECT
numbers1.number AS prime_number
FROM
#numbers AS numbers1
JOIN #numbers AS numbers2
ON numbers2.number <= SQRT(numbers1.number)
AND numbers1.number % 2 <> 0 AND numbers1.number % 3 <> 0 AND numbers1.number % 5 <> 0 AND numbers1.number % 7 <> 0
GROUP BY numbers1.number
HAVING MIN(numbers1.number % numbers2.number) > 0
UNION SELECT 2 WHERE @limit >= 2
UNION SELECT 3 WHERE @limit >= 3
UNION SELECT 5 WHERE @limit >= 5
UNION SELECT 7 WHERE @limit >= 7
) AS prime_numbers
;
DROP TABLE #numbers
Далее представлена скорость вычислений в секундах для разных размеров последовательности и разных СУБД (Postgres и MSSQL), включая файловый вариант. Код для варианта с использованием императивного языка был использован из этой публикации.
| N |
100 |
103 |
104 |
105 |
106 |
107 |
| 1С+Файловый режим |
0.006 |
0.02 |
0.22 |
5.07 |
125 |
3550 (59.2 мин) |
| 1С+Postgres |
0.532 |
0.52 |
0.63 |
2.72 |
50 |
1356 (22.6 мин) |
| 1С+MSSQL |
0.003 |
0.01 |
0.11 |
1.60 |
37 |
1009 (16.8 мин) |
| MSSQL без "%" |
0.037 |
0.04 |
0.08 |
0.66 |
13 |
347 (5.8 мин) |
| MSSQL с "%" |
0.009 |
0.02 |
0.07 |
0.54 |
12 |
309 (5 мин) |
| Императивный код 1С |
0.004 |
0.01 |
0.09 |
1.00 |
10 |
112 (2 мин) |
На графике наглядней видна разница в скорости вычислений для режимов работы с разными СУБД (здесь по горизонтали - размер последовательности, по вертикали - время выполнения в секундах).
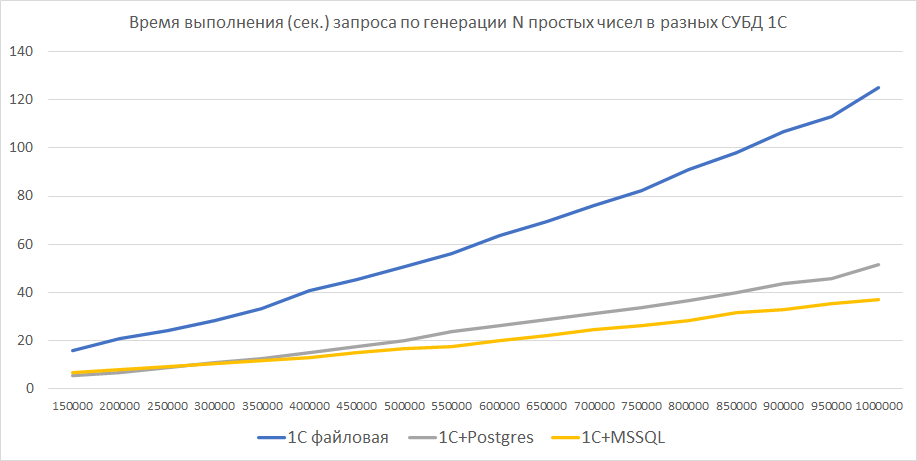
Отдельно приведу график сравнения выполнения аналогичного кода на чистом MSSQL и через 1С-овскую обертку.


