











Здравствуйте, мои маленькие любители программирования. Сегодня мы поговорим об ….
Так начиналось большинство наших статей, которые мы писали, меняя наши внутренние процессы или анонсируя внедрение новых ИТ решений своей команде в Сименсе. То время безвозвратно ушло и теперь я работаю, в не менее известной компании «Самолет» в качестве системного архитектора.
В порядке знакомства
Зовут меня Валентин Козлов. Я начинал свою карьеру простым разработчиком 1С и дошел до руководителя отдела ИТ в компании являющейся частью глобального концерна. За годы работы мы смогли создать уникальную команду ИТ, способную решать задачи любой сложности, со средним сроком работы разработчиков 6 лет, и нам было совершенно не важно на каких технологиях мы решим ту или иную задачку. Поэтому я могу с полной уверенностью сказать, что в ИТ главное люди - а не технологии. По моему мнению, сработанная команда из 3-5 инженеров, которым «непофиг», может полностью изменить компанию изнутри и вывести её на первые места в отрасли. Для того, чтобы это произошло, этими людьми должны управлять люди, способные понимать все нюансы работы в ИТ и самое главное, что мотивирует и демотивирует инженеров. Именно поэтому сейчас есть огромный спрос на ИТ-лидеров, способных своими руками «делать страшное», а эра классических ИТ менеджеров потихоньку уходит в закат (да простят меня классические ИТ менеджеры 😊).
Большая проблема многих инженеров — это то, что они считают, что им достаточно просто хорошо работать. К сожалению, мир гораздо сложнее и нужно не только хорошо работать, но еще нужно уметь хорошо продавать результаты своего труда. Именно поэтому сегодня я хочу начать серию статей, рассказывающих о том, что нашей команде удалось сделать интересного, вместе с этим поделиться с Вами готовыми и не очень решениями, чтобы вы не делали всё с нуля.
Постановка проблемы и формулировка задачи
Я не буду вам рассказывать, как важно иметь инженерам различные инструменты для оптимизации своей работы, а о важности мониторинга, уже написано сотни книг и снято множество видео. Поэтому сегодня я хочу поделиться с вами, реальными результатами того, что нам удалось реализовать на поприще мониторинга включая мониторинг 1С.
Итак - предположим, у вас как в свое время и у нас есть проблема
- В условиях непрерывной разработки неизбежна ситуация, когда системы и продукты начинают “тормозить”
- Отдать технический долг быстро почти невозможно, для начала много времени будет затрачено на поиск неоптимальных мест
Отсюда и возникла задача:
- Измерить производительность наших ключевых операций для всех наших сервисов-продуктов, которых у нас больше 30 и количество их постоянно растет
На момент написания статьи у нас было 4 основных стека: 1C, Python, GoLang и C#, поэтому нам нужна была стандартная методология замера производительности операций, вместе с этим было важно предоставить “сервис для команд” который будет помогать им каждый спринт видеть какой технический долг отдать надо сегодня и какую ключевой операцию починить
Особенности решения (ADR)
В качестве рекомендуемой методики мы, недолго думая выбрали APDEX. И не потому, что она простая - есть и более качественные методики. Самыми главными критериями были:
- Не потерять фокус - потому что главная цель сделать сервис, а не внедрить методику. Методику можно в перспективе и дополнить для какого-то продукта, в нашем случае важней было сделать инструмент помощник для руководителей продуктов и их тимлидов
- В большинстве продуктов и фреймворках огромное количество готовых библиотек для реализации сбора телеметрии по ключевым операциям в целях расчета APDEX - в 1С так вообще это типовая функциональность, которую сам вендор рекомендует использовать. Ее даже кодить в общем случае нет необходимости.
И для тех, кто совсем не в курсе “за методику” APDEX дам вам небольшое определение из ссылки выше:
Apdex (Application Performance Index) - это открытый стандарт для измерения производительности программных приложений в вычислениях. Его цель - преобразовать измерения в информацию об удовлетворенности пользователей, указав единообразный способ анализа и составления отчетов о том, в какой степени измеренная производительность соответствует ожиданиям пользователей. Он был разработан альянсом компаний.
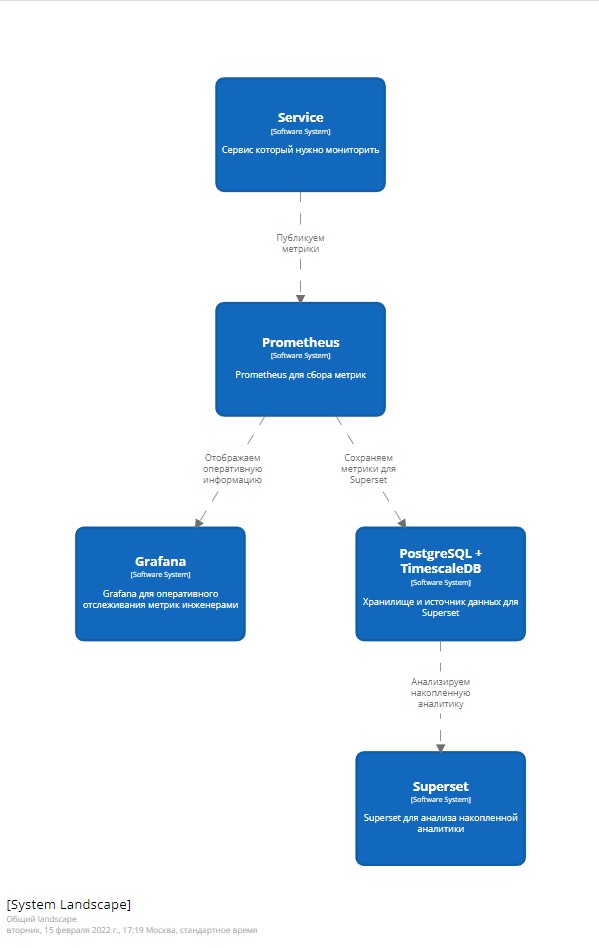
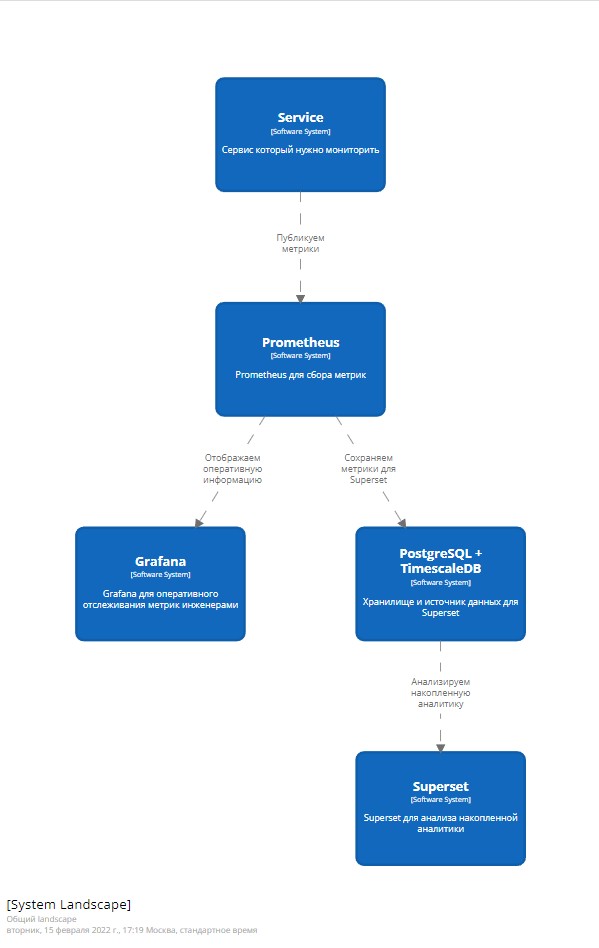
Дальше нам нужно было определить, как собирать метрики, где их хранить и чем их анализировать. По итогу мы выбрали
- Prometheus для сбора метрик - “Коллектор”
- Grafana для оперативного отслеживания метрик инженерами - “Отображатель и оповещатель”
- Superset для анализа накопленной аналитики - “Анализатор”
- В качестве хранилища и источника данных для Superset был выбран PostgreSQL с расширением TimescaleDB - “Хранилище накопленных метрик”
Мы получили следующую схему:
Скрытые причины выбора - о них стоит сказать отдельно
|
Инфраструктурный сервис |
Особенность сервиса |
Потенциальный выигрыш в перспективе |
|
Prometheus |
Сервис провоцирует разработчика думать о метриках самому - то есть идея сервиса в том, что “Только разработчик продукта знает какие точки и метрики ему мониторить”, в отличие от Zabbix агента - где метриками управляют админы, которые ничего не знают про продукт |
Обучающий эффект - когда команда продукта еще на этапе проектирования будет расставлять точки мониторинга - и это будет часть официального беклога команды |
|
Grafana |
Сервис провоцирует команду иметь свой, теплый ламповый дашбоард мониторинга с возможностью переиспользовать уже готовые элементы и не зависеть ни от кого |
Накопление готовых элементов в формате JSON/YAML с последующим переиспользованием между командами продуктов - вне зависимости от языка программирования |
|
Superset |
Сервис провоцирует инженеров погружаться в концепцию SelfService-Bi - а не ждать пока выдадут доступ на платные сервисы типа PowerBI/1C-Аналитика/Tableu/etc |
Обучающий эффект - умение построить себе самому диаграммы для принятия решений, а не заказывать их у DataSciense инженеров |
|
TimescaleDB |
Сервис провоцирует инженеров изучать специализированные хранилища данных - в частности хранение временных рядов |
Обучающий эффект - позволяет изучать экосистему PostgreSQL, без необходимости внедрять спец средства типа Yandex ClickHouse - то есть инженер развивается как DBA изучая теорию СУБД. |
В качестве пилота был выбран один из наших сервисов написанных на Python. Для сбора метрик использовалась стандартная SDK “Prometheus Python Client”. Мои коллеги, успешно реализовали пилот и быстро получили свой дашбоард и быстро поправили неоптимальности…
То есть - в данном случае, исследовать особенности “прометея и не пришлось”
1С конфигурация про Open Telemetry не знает ничего
После пилота дошла очередь и до 1С. С ней все оказалось сложнее так как «проклятые буржуи» не сделали SDK для 1С, поэтому пришлось «колхозить» свой вариант реализации 😊. Для этого пришлось изучить формат выгрузки метрик и разобраться с их типами. Согласно документации Prometheus данные по APDEX должны «ехать» с типом метрик «histogram».
Вообще здесь важно обратить ваше внимание на несколько особенностей сервиса Prometheus которые заложены в нем архитектурно
- Первая особенность Prometheus: Модель API максимально абстрагирована, чтобы позволить загружать и рассчитывать любые метрики приложений
Интересно то, что скорость выполнения запросов из 1С должна быть очень высокой, так как метрики должны поставляться:
1 раз в минуту. Да - мы хотим видеть Continuous APDEX !!!
То есть команда может глядеть на свой APDEX раз в день, а сервис должен получать их раз в минуту — это важное требование. Потому что почистить и сжать метрики мы сможем всегда - а вот переделывать загрузку, когда нам понадобится изменить частоту отправки совершенно не хочется, плюс это стало дополнительным тестом на производительность самого “Прометея”.
- Вторая особенность Prometheus: Служба “Прометея” желает подключаться к API приложения и делать оттуда PULL метрик
А у нас при интеграции есть одно из наших любимых правил
«сосать плохо»
То есть мы считаем, что в общем случае НЕэффективно, когда кто-то ходит к нам в системы и сосет наши данные делая неконтролируемую нагрузку на них, поэтому в качестве поставщика метрик мы выбрали Prometheus Pushgateway. А 1С конфигурация как приложение делает PUSH своих метрик-замеров ключевых операций.
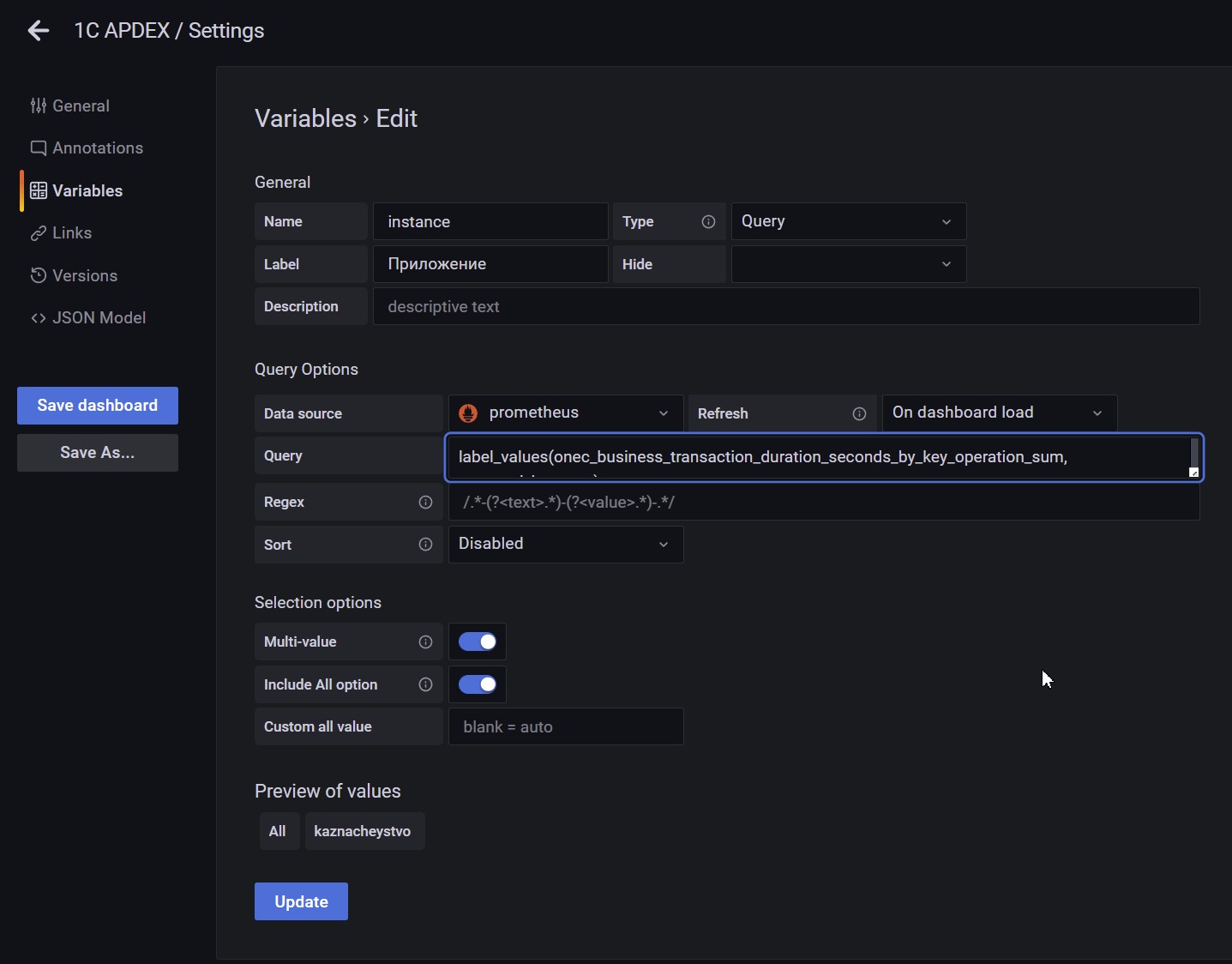
Адаптер 1С-Prometheus
Как же в итоге сделан - адаптер на стороне 1С. Внимание - сейчас будет минутка программиста.
В расширении перехватываем запись стандартного регистра "ЗамерВремени” из БСП и формируем данные в нужном нам формате в регистре “APDEXMetrics”:

По итогу получаем данные по каждой ключевой операции с количеством раз выполнения нарастающим итогом в разрезе бакетов. Бакеты — это временные интервалы выполнения ключевой операции. Для оптимизации скорости сбора данных было денормализовано общее количество для ключевой операции и в отдельно записали общее фактическое время всех измерений (Время выполнение операций):
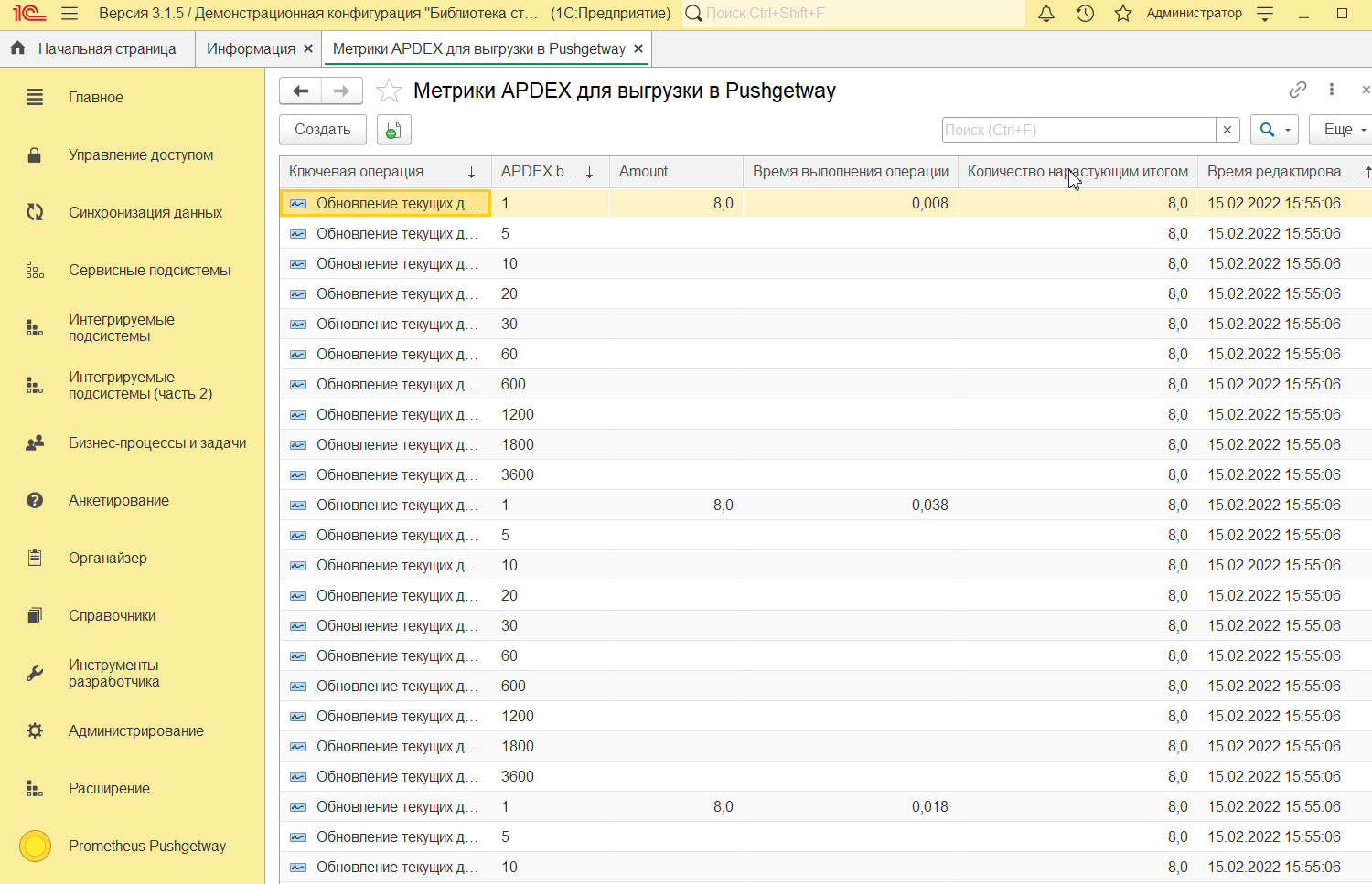
Для отправки метрик выбираем данные из регистра APDEXMetrics:
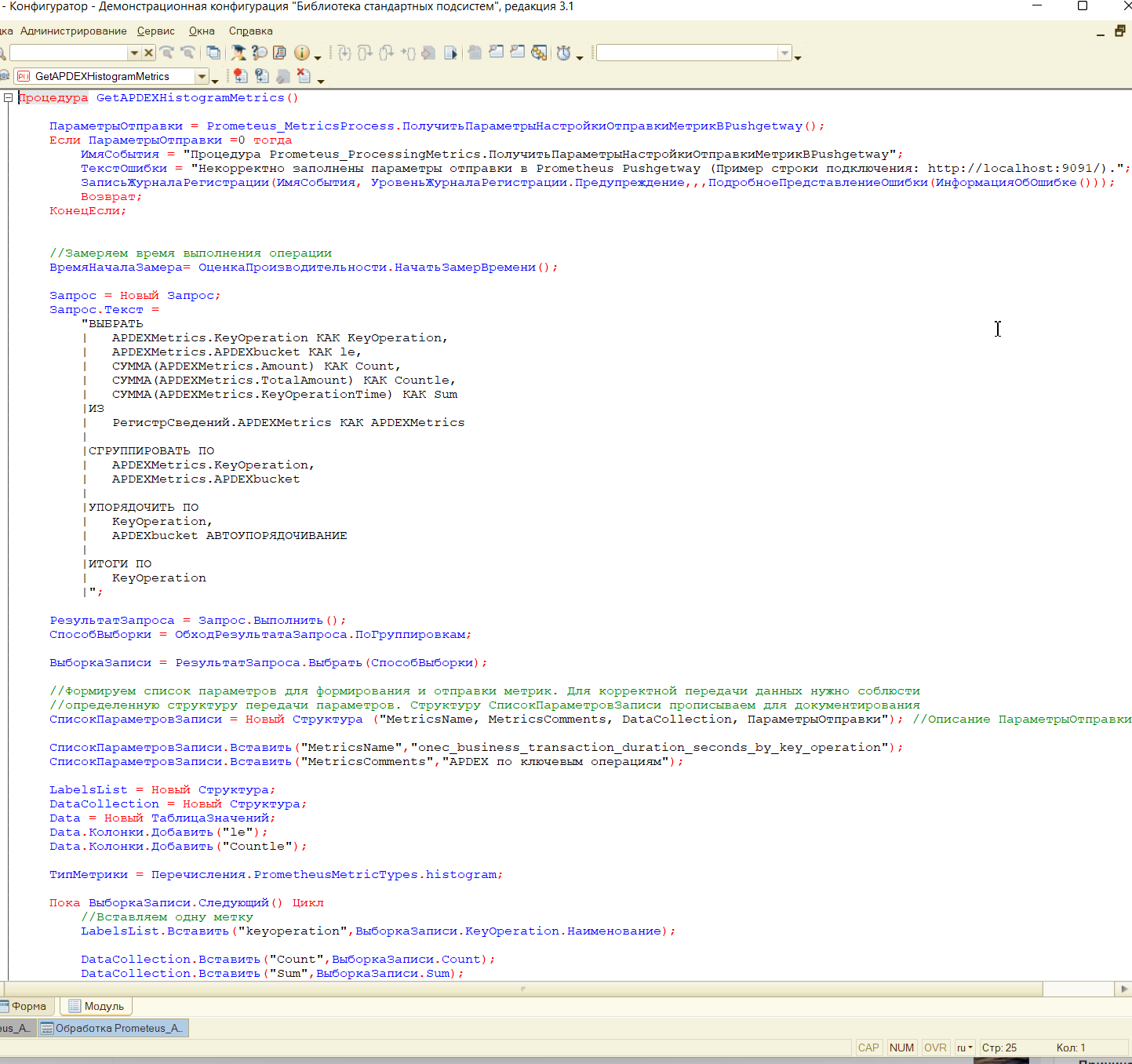
Формируем метрику в нужном формате:

и отправляем данные в Pushgetway:

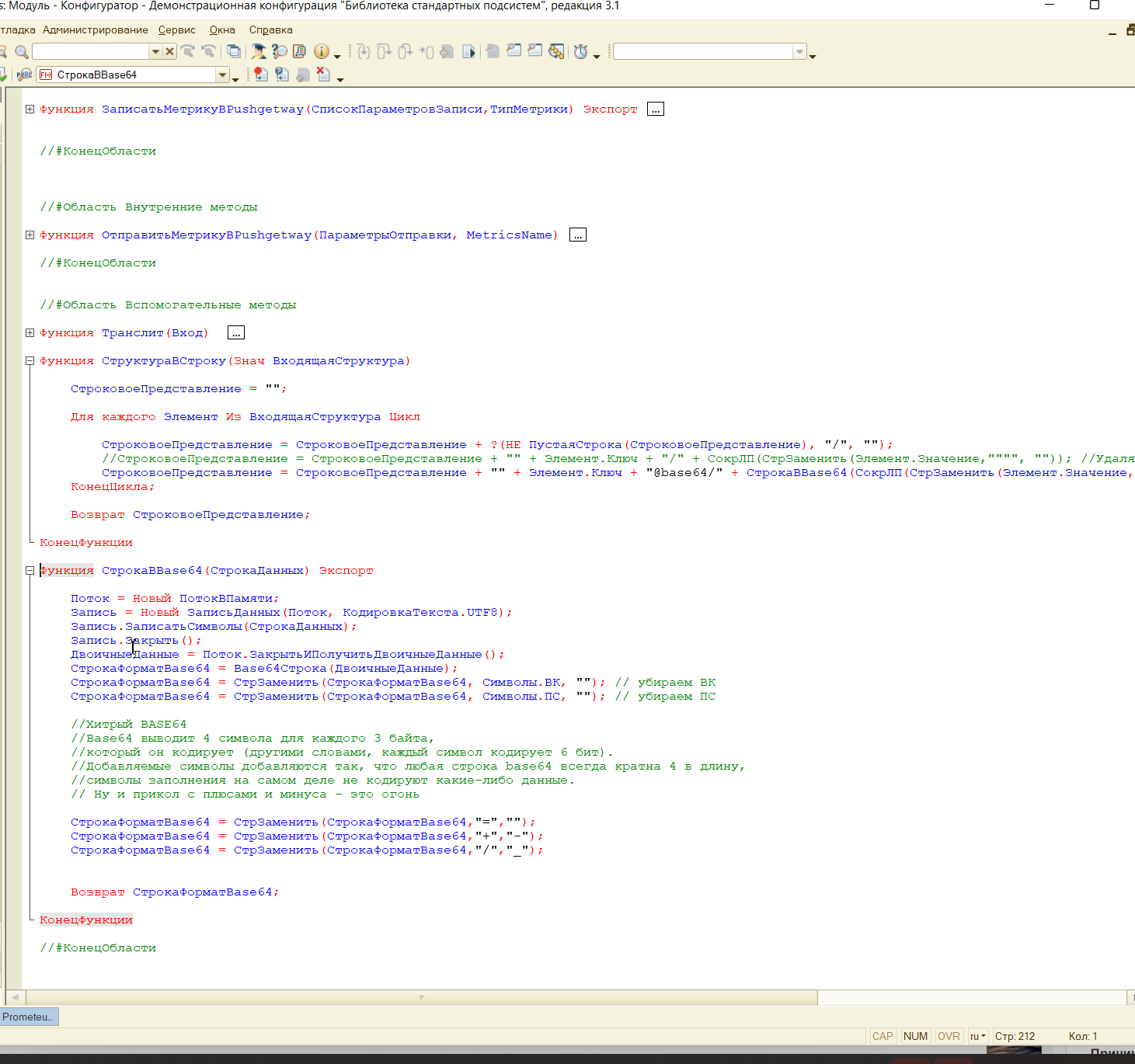
Ну и из Ынтересного. Обратите внимание, что все метки (Labels) формируются в кодировке base64. Это нужно, чтобы русские букавки выводились корректно:
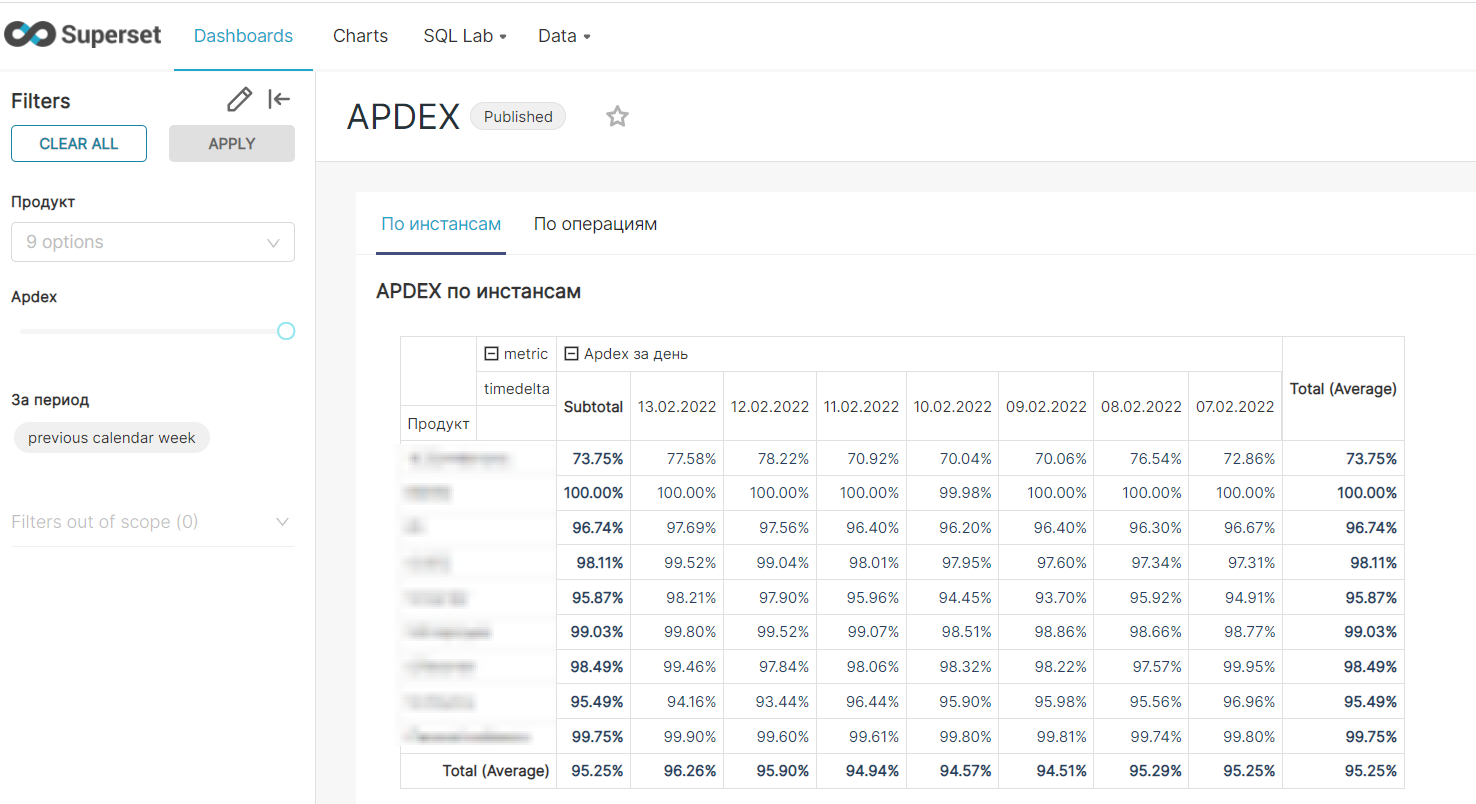
Красивые результаты, что видят наши команды
Когда метрики были доставлены до Prometheus, дошла очередь для формирования красивых бордов в Grafana:



Далее метрики из Prometheus были перенаправлены в PostgreSQL и выведены в общий борд Superset-а по APDEX:
Заключение
Все доработки по 1С живут в моем репозитории 1C_PrometheusExporter там же есть подробная инструкция по адаптации расширения. Есть множество микро идей как его можно развить, например:
- Покрыть тестами
- Перевести на EDT
- Поработать с функцией ИсторияДанных для регистра сведений замеров, чтобы не использовать подписку на событий
- Прочее
Но сейчас, я как любой «нормальный» ИТ специалист люблю делать полезные вещи итеративно и радуюсь, когда результатами моего труда могут пользоваться другие, поэтому очень надеюсь, что данная статья будет полезна вам.
В любом случае - в следующей статье я расскажу вам, как мы «вывезли» в Superset логи журнала регистрации, какие проблемы у нас были и как мы их решили, ну и конечно выложу рабочие инструменты позволяющие повторить «наш подвиг» 😊.
А если вы хотите повторить такое же у себя на основе этой статьи - обратите внимание, что реализация подобного подхода позволит вам подружиться со всеми участниками вашего большого коллектива - с Python разработчиками, с ведущими программистами 1С и т.д.
P.S. Обратите внимание, пока мой аккаунт "отбрендирован" как корпоративный - это временное решение, так как мы хотим уже начать делиться с сообществом, а наши корпоративные закупщики пока согласуют деньги ;-) на корпоративный аккаунт.
Вступайте в нашу телеграмм-группу Инфостарт



{kind=link}