Я Михаил Калимулин, разработчик 1С, преподаватель. С конца 2017-го года я публиковал несколько статей на Инфостарте по поводу блокчейна и применимости его в 1С. Ну а теперь хочу предложить вашему вниманию данный доклад.

Безопасность – это поистине необъятная тема. И для того, чтобы понять, какое место занимает здесь блокчейн, давайте разделим все, что связано с безопасностью, на две большие категории по признаку того, что мы хотим добиться и с какой стороны подходим к решению проблем безопасности.
-
Мы можем хотеть сделать явное тайным – ограничить доступ к информации. Для этого используются пароли, права доступа, ограничения доступа и т.д. Блокчейн сюда не входит.
-
Есть другой подход к безопасности – «тайное» сделать «явным». Этот вариант менее очевидный, но не менее значимый. И мы сейчас поговорим именно об этом.
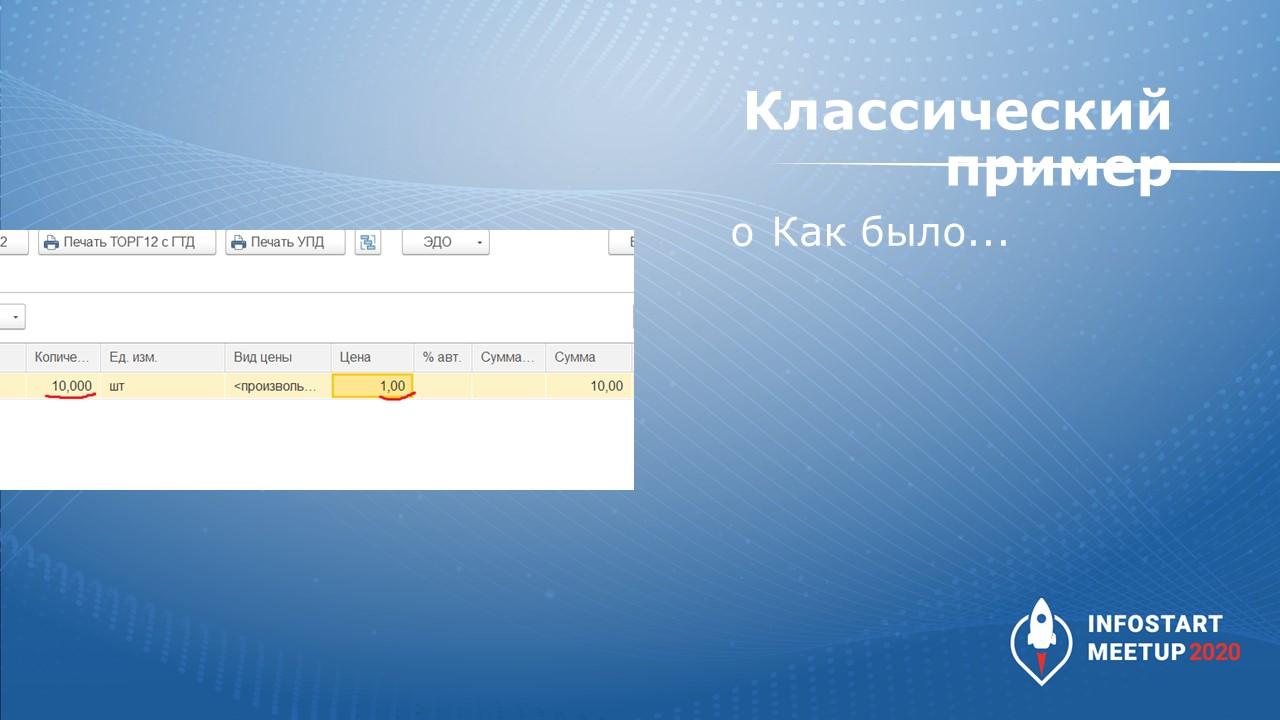
Есть классический пример – есть некий приходный документ, в котором у нас изначально было поступление 10 штук чего-либо по цене 1 рубль.
Этот документ изменяется вот так: пришла одна штука по цене 10 рублей. Сумма документа не поменялась.

Как нетрудно догадаться, гипотетический злоумышленник теперь может 9 штук спокойно отнести себе домой.
Нужно обратить внимание, что такая манипуляция очень комфортна для злоумышленника, потому что практически неотличимо от обычной ошибки оператора – с кем не бывает, а кладовщик всегда может сказать, что испугался и не хотел показывать, что у него что-то не так на складе.
Надо понимать, что практически 100% баз 1С никак не защищены от подобного рода атаки. Тем не менее, решение этой проблемы существует.

Но, чтобы решить эту проблему, нам придется пройти непростым путем – между Сциллой и Харибдой.
-
Сциллой здесь будет то, что я называю «очарование технологиями», это полагаться исключительно на технику, игнорируя «человеческий фактор», думать, что мы сейчас в нашей базе прикрутим какие-то алгоритмы, и все будет хорошо. Такое достаточно сильно распространено, вспомните, насколько популярен совершенно бесполезный контроль отрицательных остатков. Нет, мы не сможем добиться никаких результатов, полагаясь только на алгоритмы. Чтобы понять, где была правда – 1*10 или 10*1 – нам нужен будет человек, нужны будут его глаза, руки, иногда голова. Надо взять первичный документ и на него посмотреть. По-другому не получится никак.
-
А Харибдой здесь будет – полагаться только на контроль человека, игнорируя технические вызовы и возможности.
Дело в том, что надо понимать, что у нас будет проверяться не один документ – нам нужно будет каждый раз проверять все. Если мы вернемся к нашему гипотетическому случаю со злоумышленником, то, если у нас налажен контроль (один человек ввел, другой – проконтролировал, вроде бы все хорошо), нашему злоумышленнику нужно будет всего лишь внести изменения сразу после того, как контроль пройдет. Таким образом, получается, что недостаточно проверять каждый из документов, а нужно каждый раз проверять все документы от начала и до конца, независимо от их общего количества в базе. А это, на первый взгляд, сделать невозможно. Однако есть технические решения, которые позволяют организовать визуальный контроль огромного массива информации.
Это техническое решение называется хэш-функции.
Хэш-функции, SHA-256

Хэш-функции – вещь простая. Мы берем что-то большое и сжимаем его. Мы можем взять гигабайт данных, а на выходе получить 32 байта. Например, одна из самых распространенных на данный момент хэш-функций SHA-256 – она нам как раз 32 байта выдаст.
Надо понимать, что сами по себе хэш-функции – вещь достаточно изощренная. Вы просто подумайте – вам нужно из гигабайта получить 32 байта. Можно, конечно, просто взять и в случайном порядке повыдергивать лишние, а вставить случайные 32 байта. Но это будет плохая хэш-функция. Хорошая хэш-функция работает так, что, если у вас есть один гигабайт данных и другой гигабайт данных, которые отличается друг от друга всего на один бит, хэш-функция вернет совершенно другое значение. Она не просто так выдергивает случайные 32 байта.
Второй момент, который нужно понимать – это то, что, когда мы большое превращаем в маленькое, разумеется, у нас когда-то произойдет коллизия – один набор данных выдаст точно такую же хэш-функцию, как и другой набор данных. Такое действительно может произойти, если рассуждать чисто математически. Но если рассуждать чисто практически, этого не произойдет.
Вероятность того, что мы получим у хэш-функции похожий набор, равняется 1 к 2 в степени 255 – ровно столько возможных значений в 32 байтах. Это 5*1076. А количество атомов во всей наблюдаемой вселенной по разным оценкам 4*1079, 4*1080 или 4*1081.
Это сравнимые числа. Представьте себе количество атомов – не в комнате, не в солнечной системе и даже не в галактике, а почти во всей вселенной, которую мы видим.

Итак, что мы можем сделать? Мы можем применить хэш-функцию к нашей базе данных, получить результат, результат запомнить, потом через какое-то время прийти, применить хэш-функции еще раз к нашему набору данных, еще раз посмотреть на результат и понять, что ничего не менялось.
Обратите внимание на алгоритм получения хэш-функции. Я специально здесь привел экранчик – не для того, чтобы разбираться, что там написано, а чтобы оценить, как это выглядит. Самый популярный алгоритм SHA-256, который используется в широко известном биткоине – вот он весь. Он на один экран помещается, он предельно прост. Здесь один цикл и внутри него два цикла, где производятся элементарные действия.
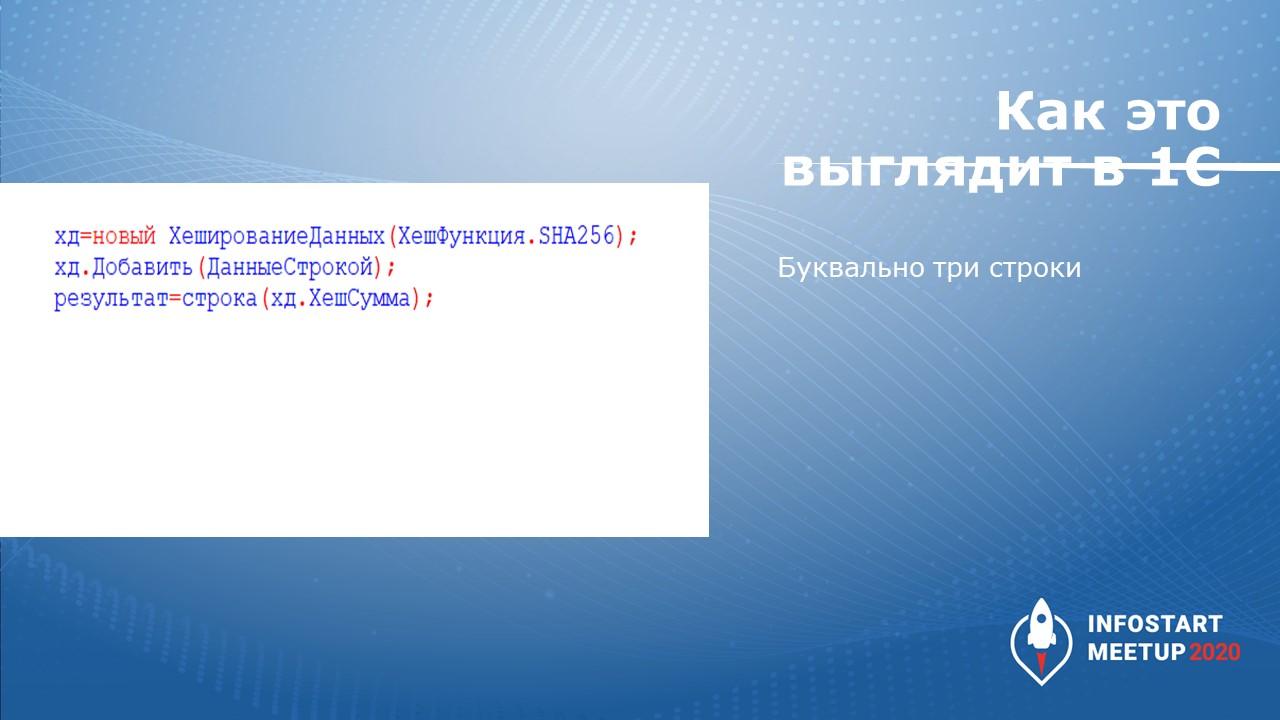
В 1С это выглядит еще проще. Тут буквально три строки.
Итак, мы можем воспользоваться хэш-функцией, чтобы сжать наши данные в 32 байтах. А 32 байта – это не очень большой объем, его можно визуально контролировать. Можно тренировать память и запоминать. Можно на бумажку выписать и сравнить. Занимает меньше минуты, я сам это делал.
Так мы можем контролировать огромный набор данных.
Алгоритм работы журнала по принципу "цепочки блоков"
Если мы применим хэш-функцию ко всей базе данных, а потом на следующий день опять применим хэш-функцию ко всей базе данных, разумеется, мы увидим, что она поменялась, потому что приличные базы данных меняются постоянно. Нам эта информация ни о чем не говорит, поэтому мы с вами будем применять эту хэш-функцию не вообще ко всей базе данных, а к ее отдельным документам.
Вернемся к нашему примеру с приходными документами. Представим себе, мы решили организовать такой контроль:
-
Когда мы начинаем работать, у нас пока нет ни одного приходного документа.
-
Потом появляется первый документ, мы проводим контроль и вычисляем хэш-функцию от этого документа – сериализуем документ (разворачиваем его в строку тем или иным способом – любым, который нам понравится), и потом к этой строке применяем хэш-функцию. Получаем ее значение, которое я называю ключом, и записываем в какой-нибудь журнал ссылку на документ и значение ключа.
-
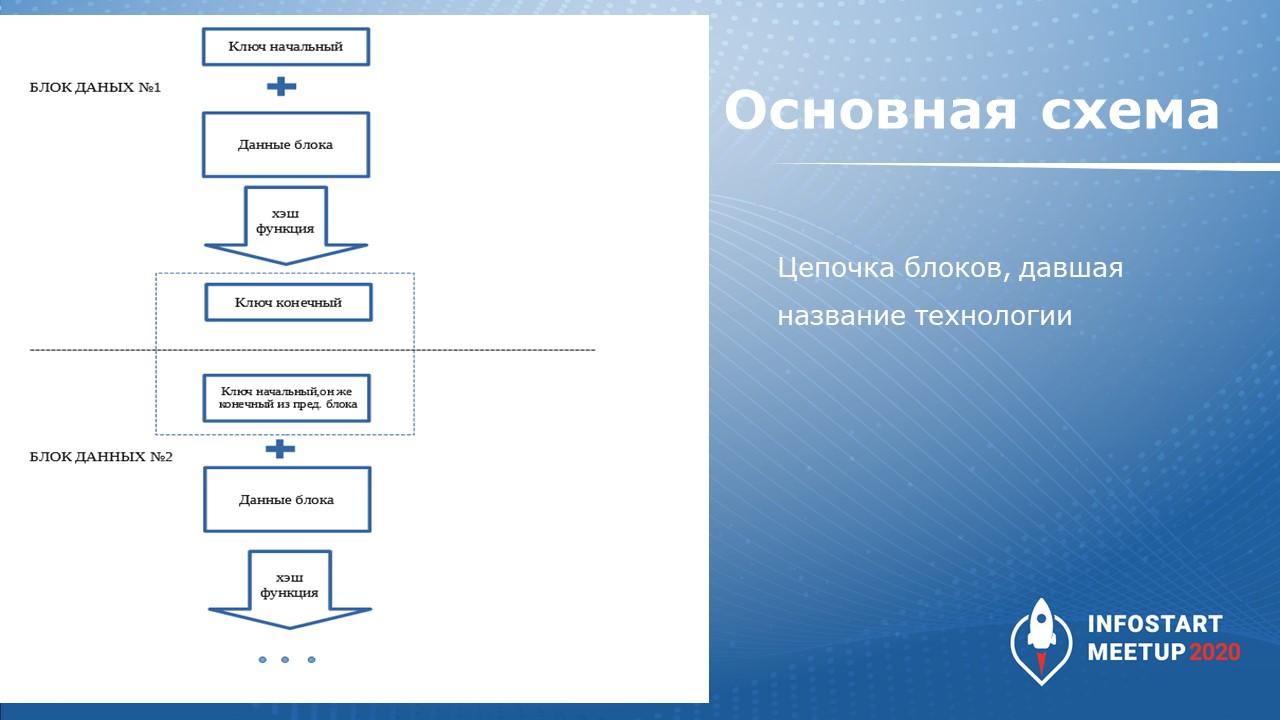
Приходим на следующий день, у нас появился следующий документ. Что мы делаем? Мы опять же сериализуем этот следующий документ, превращаем его в строку, но передаем в хэш-функцию уже не только этот документ, но и предыдущий ключ, который у нас был от предыдущего документа, и применяем хэш-функцию к соединению этих двух строк – получаем ключ уже от документа и предыдущего ключа. Вот здесь и происходит так называемая сцепка.
В результате мы получаем то, что называется цепочка блоков или блокчейн – то, что дало название этой технологии.
Что здесь хорошо? Мы можем теперь взять наш журнал, нам его глазами не нужно просматривать весь. Нам глазами достаточно посмотреть только один последний ключ – те самые 32 байта. Я открываю журнал, вижу последний ключ и сравниваю его с чем-нибудь (с бумажкой, например). Если ключи совпадают, мой журнал в целостности, мне не нужно проверять каждый из этих блоков глазами, если это можно проделать программно.

Алгоритм работы журнала достаточно простой.
-
Мы делаем проверку целостности журнала – у нас программа бежит по этим блокам, получает хэш-суммы от данных документа. Проходит по ссылкам, разворачивает, сериализует документ, получает данные документа в виде строки, добавляет предыдущий ключ, вычисляет хэш-функцию, сравнивает ее значение с записанным конечным ключом. Если значения совпадают – все хорошо. Пробегаемся по всем документам и получаем список того, что у нас есть в журнале. Нам остается простейшим запросом получить, чего в журнале нет – какие новые документы добавились. И дальше новые документы добавляем в конец журнала.
-
Следующий шаг – мы добавляем записи о новых (измененных, удаленных) блоках. Если я бежал по этим блокам и где-то увидел, что документ изменен, я с этим блоком ничего не делаю, с ним все нормально, я просто в конец журнала добавлю еще раз ссылку на этот же документ, но уже пересчитанные ключи, пересчитанные хэш-суммы. А в той записи укажу, что она была изменена, и укажу ссылку на ее потомка. Допустим, у меня была запись №1, потом через 10 записей ее поменяли. В 10-й записи лежит актуальная копия. В случае, есть документ меняли несколько раз, вот так по цепочке можно пройти. Смысл в том, что любое изменение всегда попадает в конец. Удаленные документы – это частный случай изменения. Там есть некоторые хитрости, но я не буду на этом останавливаться.
-
И визуализирую все, что у меня было – вот мои документы новые, вот мои документы измененные. Вот теперь садитесь, включайте свои глаза, свои руки, свои головы, берите первичные документы и проверяйте.
Если запустить такую систему, нашему гипотетическому злоумышленнику становится некуда влезть. Подменить 10 на 1 не получится никаким способом.
Возможные уязвимости решения

Можно придумать только две уязвимости.
-
Первая уязвимость чисто техническая, связанная с алгоритмами хэш-функций. Здесь речь о том, что алгоритм получения хэша очень простой, у него 64 шага. Если количество шагов уменьшить до 10, это тоже будет хэш-функция, она тоже будет приемлемо работать, но такую функцию уже сломали. Она действительно уже не работает, потому что есть способ поискать коллизии – автоматически запустить алгоритм, который будет находить такие наборы данных и выдавать тот же самый результат хэш-функции. SHA-256 взломали до 30-го шага, но в целом он до сих пор является надежным. С другой стороны, существование коллизий – это вопрос для математиков. Допустим, мы можем найти одну-две-три коллизии. Вопрос в том, то нам не первую попавшуюся надо. Если вспомнить, что мы делаем с документом – мы его сериализуем. Мы документ превращаем в строку по каким-то правилам (XML, JSON). Мы нашли коллизию, но эта коллизия в формат JSON или XML не попадает. А перебирать коллизии до тех пор, пока мы не наткнемся на что-то приемлемое – это может быть столь же неприемлемо, как просто перебирать. С этой стороны эта уязвимость весьма гипотетическая.
-
А второй момент – подмена алгоритма. Многие уверены, что надежная программа – это только та, которую ты сам написал. Во все остальное, что ты запускаешь, всегда можно что-то куда-то вставить. Тут мы возвращаемся к тому моменту, когда я вам говорю о простоте. Сам алгоритм хэш-функции прост, его можно воспроизвести самому. Можно пользоваться конструктором ХэшированиеДанных() – это три строчки в 1С, как я показывал. Там невозможно что-то вставить.
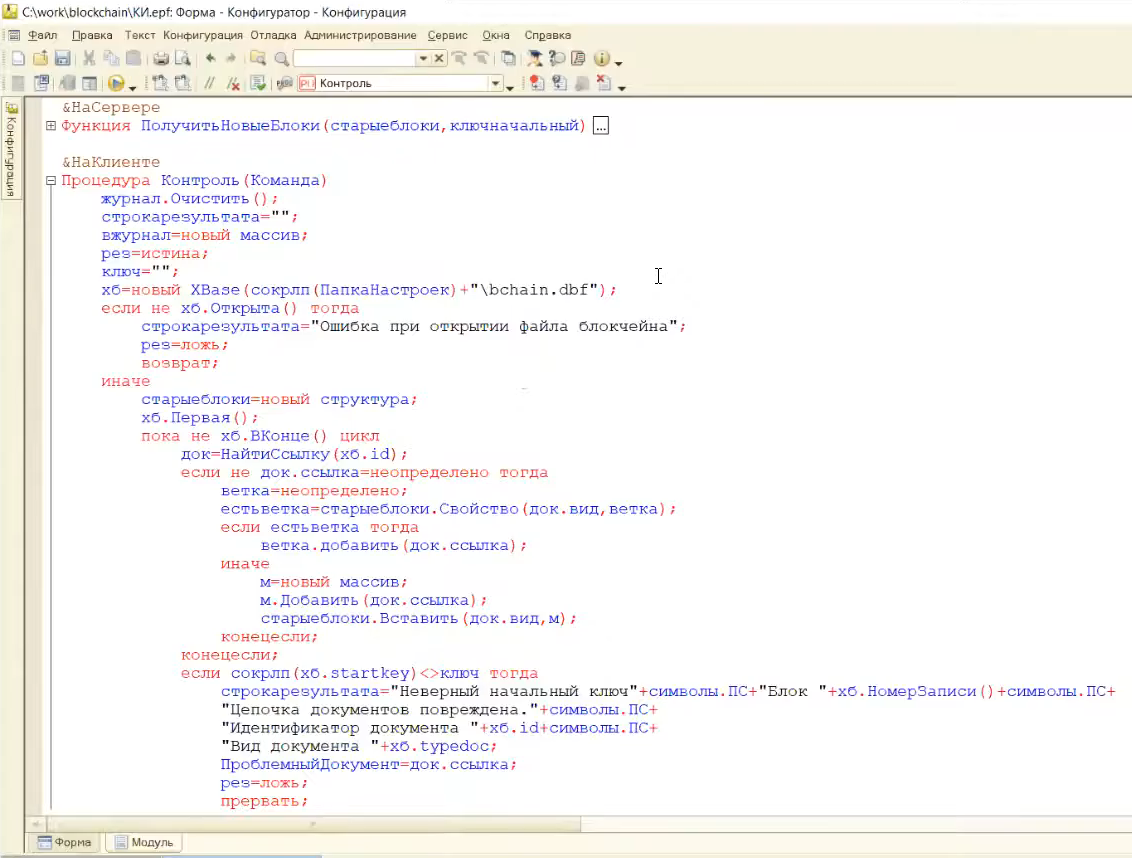
Вот так выглядит описанный мной на предыдущем шаге алгоритм в реальности.
В процедуре контроля всего лишь 150 строк кода – это не ERP, где куда-то что-то можно вставить и не найдешь никогда, это можно контролировать глазами.
Если вы, перед тем как запускать контроль журнала, хотите убедиться, что запускаете код, где никаких вставок быть не может – это можно проделать глазами.
Соответственно, аргумент о подмене алгоритма тоже легко парируется, а вы получаете технические методы контроля, основанные на хэш-функциях.
Вывод

К чему я хочу призвать коллег?
Давайте посмотрим на безопасность с другой стороны. Мы можем стараться сделать так, чтобы у людей не было возможности поменять 10 на 1, а можно подойти с другой стороны – можно сделать так, чтобы все изменения в базе было легко контролировать. Этот механизм математически работает абсолютно безупречно, и вы с его помощью можете создать систему контроля, которую никак не обойти и никак не испортить.
Вопросы
Есть ли готовая реализация вашего решения?
Да, в конце 2017-го года я опубликовал на Инфостарте первое решение – там просто конструктор, который выдает куски кода. Их можно использовать, чтобы сделать свою систему контроля. А после этого я еще совсем недавно опубликовал более законченное решение – есть некий журнал, в котором ты можешь сказать, что нужно контролировать вот этот набор документов. И по принципу, который я описал, будет происходить контроль. Я запускаю этот контроль, получаю на выходе последний ключ, который могу сохранить в виде секрета, а журнал мне выдает – у тебя вот эти документы новые, эти изменились, а вот этот документ вообще удален. Это достаточно простое решение.
Тут дело даже не в технике. Технически это доступно любому специалисту любого уровня. Надо понимать идею. Если ты идею понял, даже самый простой специалист ее реализует.
Как это выглядит для пользователей, для аудиторов? Например, если в документе изменился какой-то реквизит, сможет ли аудитор увидеть, какой именно реквизит изменился? Или он в целом увидит, что документ изменился?
Тут нужно понимать, что вопросы безопасности должны решаться комплексно. Эта технология не отменяет бэкапы, да, мы делаем регулярные бэкапы базы. Эта система дает сигнал, что этот документ изменился, и дальше можно придумать такую систему, которая почти в автоматическом режиме поднимет бэкап, сравнит текущую базу с бэкапом, покажет, что эти реквизиты поменялись. Это тоже можно все в автоматическом режиме сделать. Можно просто не заморачиваться этим и построить систему контроля, которая основана на том, что изменился документ – значит, нужно поднимать первичку. Не обязательно говорить тому же аудитору, что конкретно поменялось. У тебя прошел сигнал, что с этим документом что-то не так, его надо снова проверять. Хотя я согласен, что, если там будет 1000 строк, ему не очень удобно снова все проходить. В этом случае, действительно, вы поднимаете из бэкапа конкретный документ. Тут ведь главное понимать, что вы ищете не иголку в стоге сена, а вы идете по ссылке на конкретный документ и сравниваете его реквизиты.
Есть же механизм версий – и в платформе, и в БСП. Насколько возможности блокчейна оправданны? Можно ли заменить один механизм на другой? Есть ли смысл?
По идее, эти механизмы должны друг друга дополнять. Механизм контроля версий – это всего лишь таблица с определенными данными, их можно запросто поменять. Если использовать только журнал регистрации, то любой школьник погуглит и найдет, как в нем запись удалить или поменять. Нужно понимать, что есть защита, которая подразумевает, что злоумышленник чем-то не будет владеть, чем владеет администратор системы. И есть абсолютная защита, в которой неважно, какой уровень доступа у злоумышленника. Он все равно ничего не сможет сделать. Что бы он ни сделал, это будет видно. Я призываю к тому, чтобы посмотреть на безопасность с разных сторон. Если у вас будет безопасность и там, и там, тогда это будет настоящая безопасность.
А почему версию можно поменять, а блокчейн нельзя пересчитать с какого-то момента?
Нельзя пересчитать, потому что у вас где-то на бумажке записан последний ключ. Пересчитать можно, действительно, у нас есть алгоритм, который пробегает по журналу и контролирует соответствие данных документов их хэш-суммам. Да, можно весь журнал заменить каким-то способом. Но у вас в кармане лежит бумажка. Вы замените весь журнал, у вас последний ключ в этом журнале будет другой. Здесь суть в том, что мы не полагаемся полностью на алгоритмы, у нас есть глаза и алгоритмы. И то, и другое в синтезе.
Как на каждый документ-объект базы сделать «бумажку» с последним блоком?
Не каждый документ, вам нужно записать только последний блок. У вас есть журнал – он постоянно растет, а вы раз в день проверяете, у вас всегда есть только один последний ключ, вам не нужно хранить значения блока на каждый документ. В этом и смысл блокчейна как цепочки. У вас это все зацепилось одно за другое. И в конце концов вы получили самый последний ключ – надо понимать, что он в себе содержит все предыдущее, потому что у вас ключ за ключ цеплялся и последний ключ связан со всеми остальными.
А что делать, когда идет работа задним числом?
Изменение документа и добавление нового документа – это почти одинаковые операции. Но в журнале мы сразу видим, что документ изменили. И когда мы пишем в журнал это изменение, мы этот блок, который был, оставляем как есть, а делаем отдельную запись на этот измененный блок, в котором записана следующая версия этого документа. И все эти изменения мы записываем в конец.
Все, что произошло с базой, всплывает в самом конце. И мы всегда видим добавленные документы, которых пока еще не было. И все измененные документы мы тоже увидим – их надо заново проверить, раз их поменяли. С ними что-то произошло – берем первичный документ и проверяем.
Там есть больше вопросов к специфике отражения изменений в 1С – например, мы же документ можем не трогать, мы же только движения можем поменять. Есть множество специфических тем, но я боюсь, мы просто не сможем их все обсудить сейчас. Я бы просто хотел обратить внимание коллег на то, что существует такой способ.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Безопасность в 1С".

Вступайте в нашу телеграмм-группу Инфостарт

