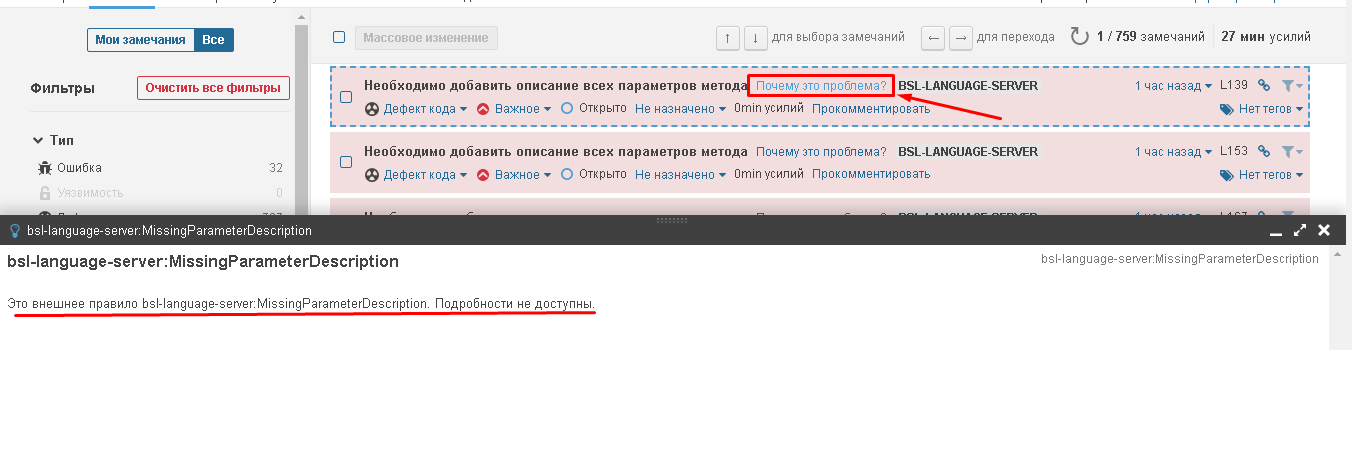
Сначала мы попробуем проанализировать «Библиотеку стандартных подсистем» и найти в ней пару интересных замечаний. Вообще последние версии БСП написаны очень качественно, ребята за этим хорошо следят, и что-то критичное действительно будет тяжело найти.
А в конце я покажу, как работать с исходниками конфигураций 1С в Git:
-
как подготовить нашу конфигурацию к Git;
-
как натравить на нее утилиту под названием gitsync, которая поможет регулярно получать изменения из хранилища конфигурации;
-
и как с помощью планировщика Windows настроить, чтобы это происходило регулярно – возможно, не на каждый коммит (как это следовало бы сделать, если бы у вас был полноценный сервер сборок), но, тем не менее, каждое утро вы сможете получать полезный результат.
Содержание
Что такое SonarQube?
Установка серверной части SonarQube
Установка Java
Как запустить SonarQube
Какие могут быть проблемы при запуске
Отсутствие Java на машине
Закрытие окна терминала с зависанием процесса Java
Занятые порты, на которых работает SonarQube
Недостаток свободного места
Проблемы использования встроенной базы данных
Подключение PostgreSQL
Sonar-Scanner
Установка плагинов
Базовые настройки сервера SonarQube
Из чего вообще состоит SonarQube
Анализ исходников БСП с помощью sonar-scanner
Ошибка с нехваткой свободного места
Что у нас есть на дашборде SonarQube
Какие настройки нужно сделать для выключения файлов на поддержке
Замечания по коду
Работа с Git
Результат исключения файлов на поддержке
Работа с Gitsync
Создание файла версий
Создание файла авторов
Автозапуск gitsync с помощью планировщика заданий Windows
Результат анализа замечаний с назначенными ответственными по данным авторов кода в хранилище
Вопросы
Что такое SonarQube?
SonarQube – это платформа для непрерывного статического анализа программного кода, где «из коробки» в бесплатной версии поддерживается 15 языков программирования. Наиболее известные – Java, C#, Swift, C++, JavaScript и PHP.
Платформа имеет довольно богатый API по расширению поддержки языков, и многие разработчики, которые не работают непосредственно в компании SonarSource, пишут свои плагины для других языков.
Язык 1С – не исключение, на платформе SonarQube есть два плагина по поддержке кода 1С. Мы сегодня познакомимся с бесплатным плагином, попробуем его поставить и что-нибудь проанализировать.
Сам SonarQube написан на Java, поэтому при его промышленной эксплуатации могут возникнуть вопросы, связанные с администрированием, нехваткой оперативной памяти или других ресурсов. Но для быстрого старта нам ничего этого знать не нужно. Мы за час разберем самые базовые моменты, и вы сможете быстро получить свой первый результат анализа.
Установка серверной части SonarQube
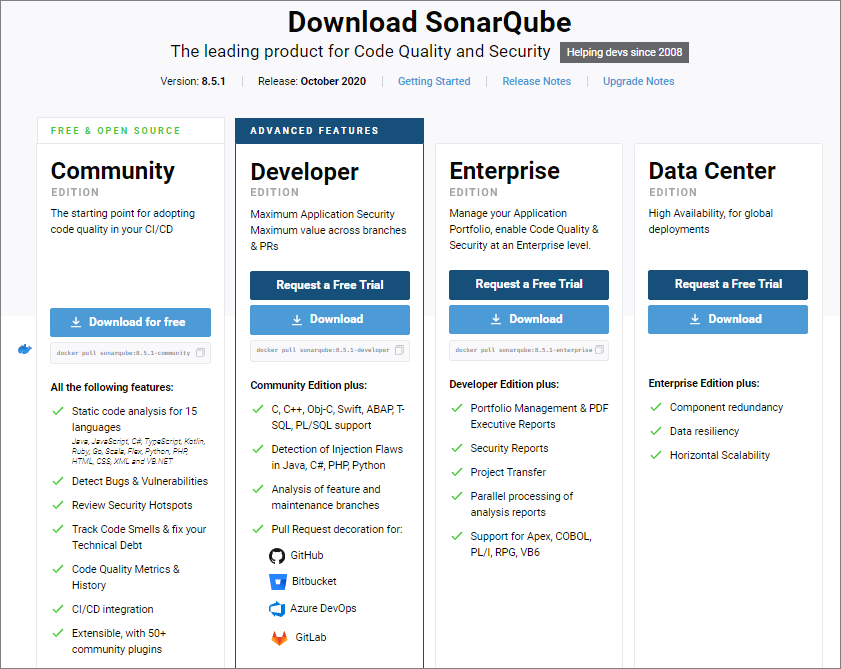
Скачать дистрибутив SonarQube можно на странице https://www.sonarqube.org/downloads/.
Здесь видно, что SonarQube поставляется в нескольких редакциях.
-
Есть бесплатная редакция Community Edition – ее достаточно для анализа небольшого количества проектов, если не требуется поддержка необычных языков, присутствующих только в платных редакциях SonarQube.
-
Если же вы планируете параллельно и одновременно анализировать много проектов, то можете столкнуться с ограничением количества фоновых задач на сервере. В этом случае вам потребуется апгрейд до Enterprise-редакции. Но до этого еще далеко, и для начала вам вполне хватит и Community Edition.
Поддержка нескольких веток в репозитории и декорирование пулл-реквестов заявлены только в Developer Edition, однако есть отдельный бесплатный плагин, реализующий эту функциональность в Community Edition. Но сегодня мы про него рассказывать не будем.

Каждая редакция поставляется с двумя версиями:
-
LTS (Long Term Support, версия с длинной поддержкой) – сейчас это версия 8.9.8;
-
и последняя, upstream-версия – сейчас это 9.2.
Выпуски upstream-версий выходят примерно каждые два месяца, а LTS выходит в среднем раз в год.
По умолчанию по кнопке «Download for free» вы скачаете последнюю версию (на момент написания данного материала – это 9.2). А чтобы скачать LTS-версию, вам нужно прокрутить окно чуть пониже.
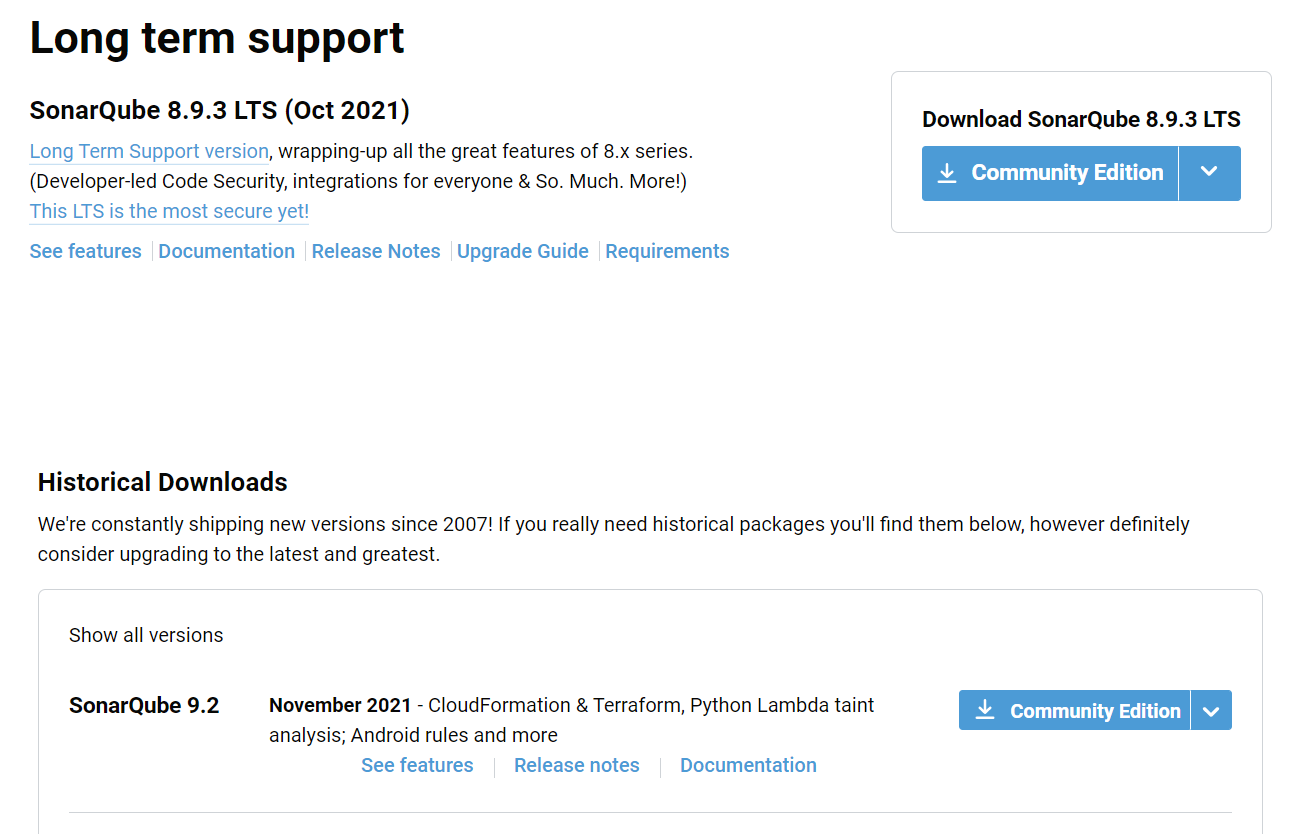
Еще ниже есть кнопка на скачивание всех версий – если вы захотите посмотреть, как развивался продукт или как менялся его внешний вид, можете последовательно все это поставить.

После нажатия кнопки «Download for free» вам скачается обыкновенный ZIP-архив.
Когда мы его разархивируем, у нас появится папка с названием приложения и версии (например, sonarqube-8.5.1.38104).
Если вы собираетесь использовать дальше текущую установку SonarQube на постоянной основе, рекомендую сразу переименовать каталог с указанием версии просто в «sonarqube», чтобы вам не приходилось переписывать скрипты при установке новой версии. И разместить эту папку в приличном месте, где-то рядом с прочими приложениями.
Установка Java
SonarQube – это приложение, которое написано на Java, и для его запуска вам нужна Java. Проверить, стоит она у вас или нет, можно в окне терминала по команде:
java --version
Если будет выведено сообщение, что Java не обнаружена – вам нужно поставить Java.
Если обнаружится, что установлена Java с версией меньше, чем 11, SonarQube тоже не заработает, потому что для него сейчас нужна минимум 11-я версия.
На момент написания статьи SonarQube сервер (ни версия 8.9 LTS, ни 9.2) не поддерживает Java 17, которая сейчас является последней версией с длительной поддержкой (LTS), сервер на нем физически не запустится. Поэтому для работы сервера вам нужна либо официально поддерживаемая Java 11 (тоже являющаяся LTS-версией), либо версии с 12 по 15 (которые сейчас уже не поддерживаются). Если я вас утомил этими цифрами – просто запомните, что вам нужна Java 11.
Откуда можно взять Java? Наверное, сейчас, когда каждый второй разработчик пробовал ставить себе EDT и проходил все эти приключения с установкой LibericaJDK, скорее всего какая-то java у вас стоит. Если вы пользовались последними версиями EDT, то у вас уже должна стоять 11-я Java.
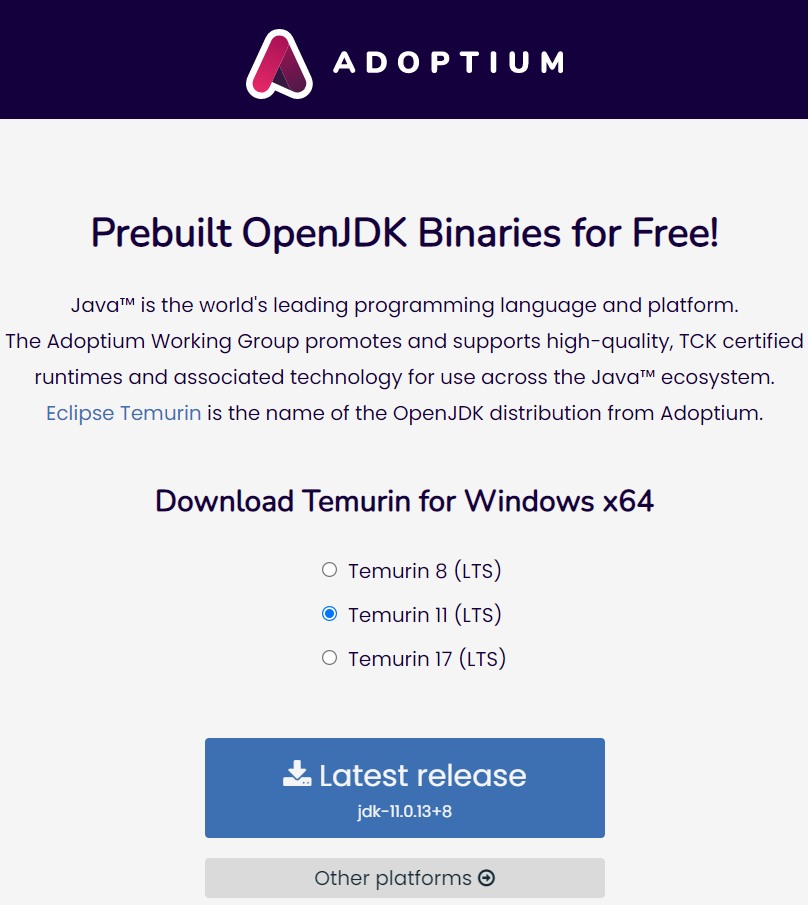
Я пользуюсь дистрибутивом под названием Eclipse Temurin от https://adoptium.net – здесь можно с помощью переключателей выбрать себе 11 Java и скачать последний релиз.
Если вы работаете из-под ОС Windows, по умолчанию запустится скачивание MSI – это установщик, который сразу пропишет все нужные вам переменные среды, и Java будет готова к работе. Возможно, вам нужно будет перезайти в систему, чтобы эти переменные обновились.
Также отсюда можно отдельно скачать ZIP-архив, распаковать, добавить путь к Java в переменные PATH и JAVA_HOME (инструкции, как это сделать, можно найти в интернете).
Если вы пользуетесь пакетным менеджером chocolatey, вы можете установить Java через команду choco – там в том числе доступны Temurin и LibericaJDK. Одной командой «choco install temurin11» вы поставите Java 11.
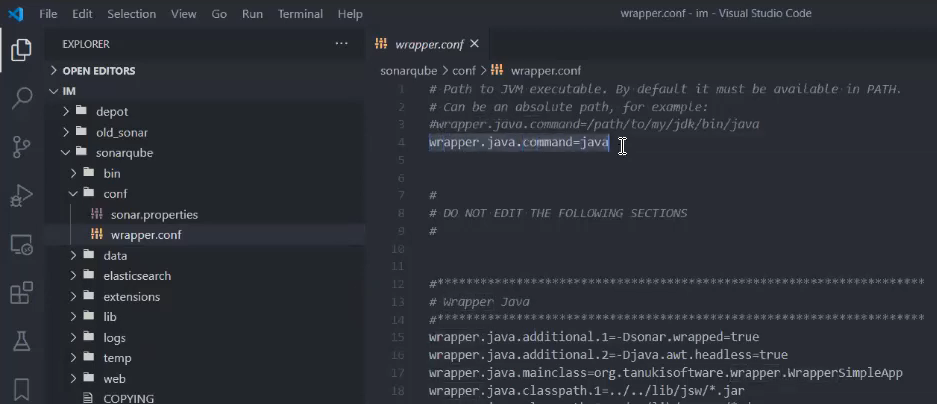
Еще может быть ситуация, когда у вас на машине стоит несколько версий Java – допустим, в качестве основной стоит Java 8, но кроме нее есть еще Java 11, Java 15 и т.д. Или у вас основная Java 11, но вы хотите, чтобы SonarQube у вас работал на Java 15, потому что она побыстрее и дает дополнительные преимущества.
В этом случае вы можете переопределить, какая Java будет использоваться для запуска – для этого нужно внести изменения в файл wrapper.conf, который находится в каталоге conf той папки, куда вы распаковали SonarQube.
Здесь самая первая настройка, которая не закомментирована (в начале строки нет #) – это как раз-таки путь к Java.
wrapper.java.command=java
По умолчанию эта настройка использует значение пути из переменной среды PATH, но вы можете указать полный путь, тогда у вас будет использоваться какая-то конкретная Java.
Как запустить SonarQube
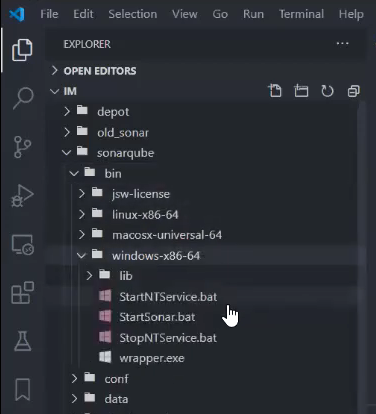
В папке bin есть разные варианты запуска для Linux, для Mac, для Windows. Нас сейчас интересует запуск для Windows. Здесь есть несколько батников:
-
для запуска из командной строки вам подойдет StartSonar.bat;
-
если вы хотите установить SonarQube как Windows-службу, вы можете выполнить StartNTService.bat с ключом install.
На этапе первичного запуска, пока вы еще разбираетесь в процессе, я рекомендую запускать этот батник не двойным кликом в проводнике, а используя командную строку, потому что, если вдруг в момент старта возникнет какая-то ошибка, окно с запущенным SonarQube закроется – вы не поймете, что конкретно произошло и как дальше расследовать проблему.

Запуск делается очень просто – вы в командной строке указываете батник StartSonar.bat, пытаетесь его запустить, пройдет немного времени и, если все хорошо, в конце появится строчка «SonarQube is up».
Какие могут быть проблемы при запуске
Разберем основные проблемы, которые могут помешать запуску SonarQube.
Отсутствие Java на машине
Самая частая проблема, которая может возникнуть – это отсутствие Java на машине. Как эту проблему диагностировать и решать – мы уже разобрались.
Закрытие окна терминала с зависанием процесса Java
Второй момент, который может вызвать проблему. Если вы запустили батник StartSonar.bat – не важно, двойным кликом по батнику в Проводнике или из Терминала – и после этого закроете Терминал «по крестику», то SonarQube не остановится, он останется у вас висеть в процессах, причем, будет три java-процесса, потому что SonarQube – это многокомпонентное приложение. Чтобы его остановить, вам придется «убивать» все эти три процесса из Диспетчера задач. Неудобно.
Стандартный сценарий остановки SonarQube – это в Терминале, где мы ранее увидели «SonarQube is up», нажать комбинацию клавиш Ctrl+C – и на Windows, и на Linux работает одинаково.
Эта комбинация клавиш перехватывается java-приложением, которое запускает SonarQube, и последовательно останавливает все компоненты, которые успели запуститься. После этого вы сможете без проблем запустить SonarQube снова.
Занятые порты, на которых работает SonarQube

Следующая популярная проблема – это занятые порты, на которых работает SonarQube. Самое частое, что может быть – это занятый 9000 или 9001 порт. Для демонстрации этой проблемы я сейчас на локальном порту 9000 запущу в docker-контейнер с Ubuntu командой.
docker run --rm -p 127.0.0.1:9000:9000 -it ubuntu
И попробую снова запустить SonarQube.
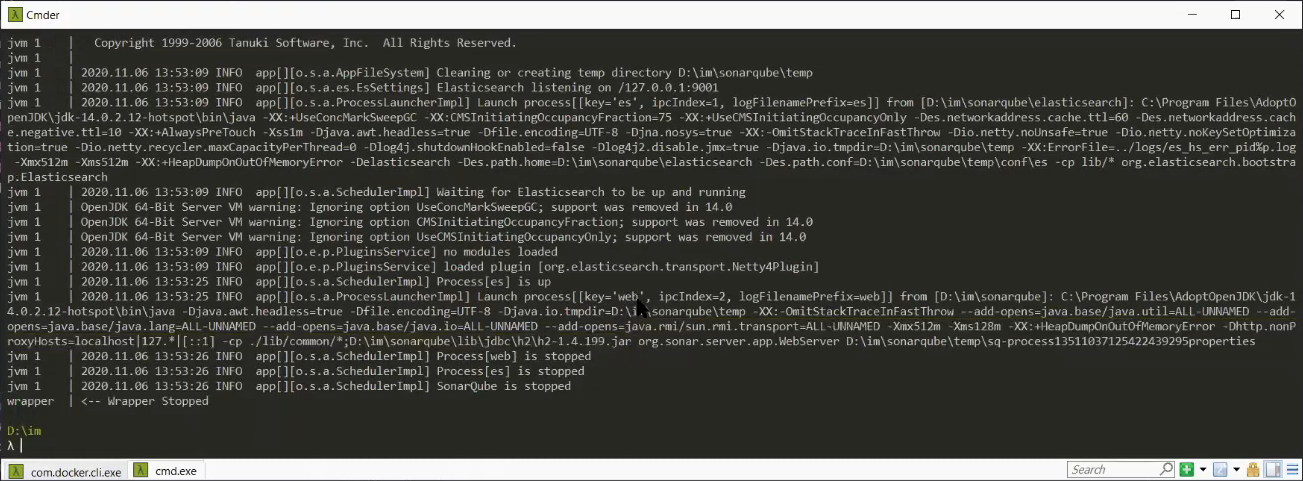
Сначала он какое-то время подумает, потом запустит Elasticsearch – компонент, который используется для полнотекстового поиска, быстрого поиска замечаний, информации по коду и т.д.. А потом, когда будет пытаться запустить процесс web – веб-сервер для сайта, который должен вам отвечать по 9000 порту – вы неожиданно увидите сообщения:
Process[web] is stopped
Process[es] is stopped
SonarQube is stopped
Не понятно, что делать дальше, и куда копать. Но есть одна подсказка – какой процесс первым остановился, тот по факту и упал.
Ищем в папке sonarqube папку logs и смотрим, что написано в файле web.log.
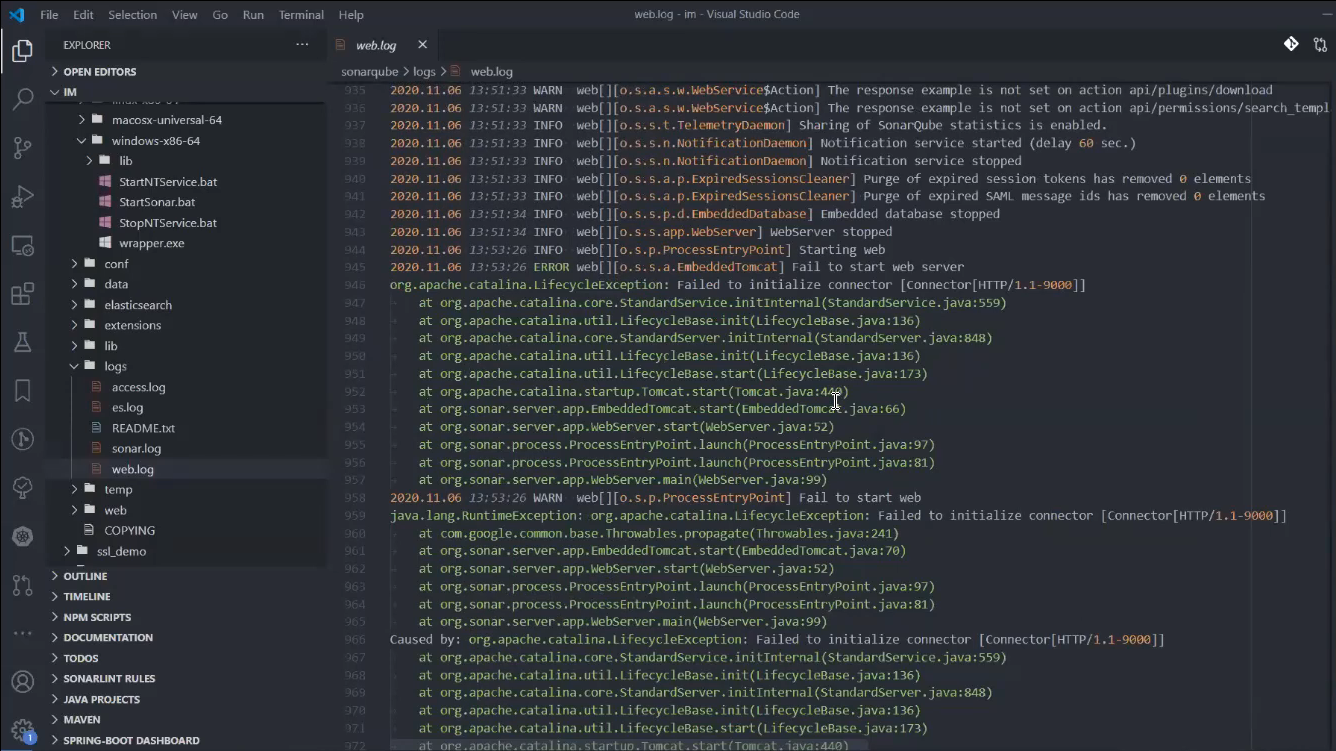
В самом низу этого файла вы должны увидеть вполне корректное исключение Java, по которому можно косвенно догадаться, что он попытался что-то поднять на 9000 порту, и у него это не получилось.

Как проверить, чем занят 9000 порт?
Для этого вы можете использовать команду netstat с флагом -ano, который добавит дополнительную информацию по процессам и PID (команда netstat доступна и в Windows, и в Linux).
Чтобы отфильтровать в выводе команды только строки, имеющие отношение к порту 9000, попробуем через вертикальную черту передать тот самый порт 9000:
-
в случае Windows – на утилиту findstr, которая будет искать в выводе какую-то информацию;
-
в случае Linux – на grep.
Я выполняю команду:
netstat -ano | findstr 9000
Вывод команды показывает, что порт 9000 сейчас используется – он прослушивается (находится в статусе LISTENING) и занят процессом с PID 17888.
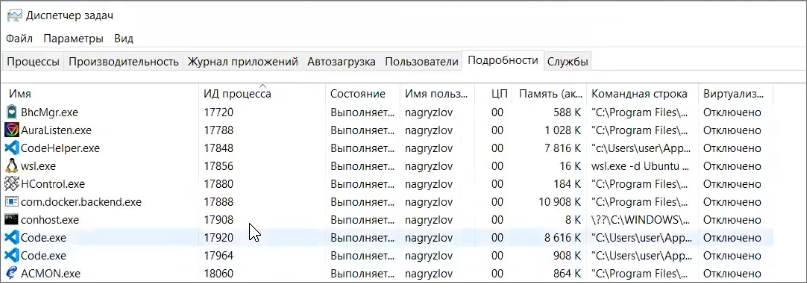
Дальше – открываем диспетчер задач, переходим на закладку «Подробности», упорядочиваем по колонке «ИД процесса» и ищем этот процесс.
Судя по всему, порт 9000 у меня занят docker-ом. В вашем случае это может быть что-то другое. Часто можно столкнуться с проблемой запуска Apache на 80-м порту, потому что его занимает Skype.
С помощью команды netstat вы можете узнать ИД процесса, который занимает выбранный вами порт, и понять, что конкретно нужно тормознуть. В случае docker – на каком порту остановить контейнер.

Освобожу порт 9000, который мешает серверу web – остановлю контейнер ubuntu.

Теперь запущу такой же контейнер на порту 9001, чтобы показать другую ошибку.
Снова запускаю SonarQube.
Теперь первым остановившимся процессом у нас стал Elasticsearch, значит, нам в каталоге logs нужно искать файлик es.log.

Также прокручиваем его вниз и видим ошибку failed to bind 9001 (не смог занять порт 9001, чтобы начать его слушать). То есть проблема та же самая.

Смотрим, кто у вас занял порт 9001. В моем случае это опять процесс 17888 – docker, а значит нужно опять остановить какой-то контейнер.

Я его останавливаю, и после этого SonarQube уже должен запуститься без ошибок.
Недостаток свободного места
Четвертая частая проблема, которая может быть при запуске SonarQube – это недостаток свободного места. В новых версиях SonarQube вы это обнаружите не сразу, а чуть позже. В ранних версиях SonarQube у вас рухнет StartSonar.bat сразу же при запуске.
На текущей машине стоит версия, которая на старте не рухнет, так что ошибку с недостатком свободного места я покажу вам чуть позже.
Проблемы использования встроенной базы данных
Дожидаемся, пока у нас стартанут все компоненты:
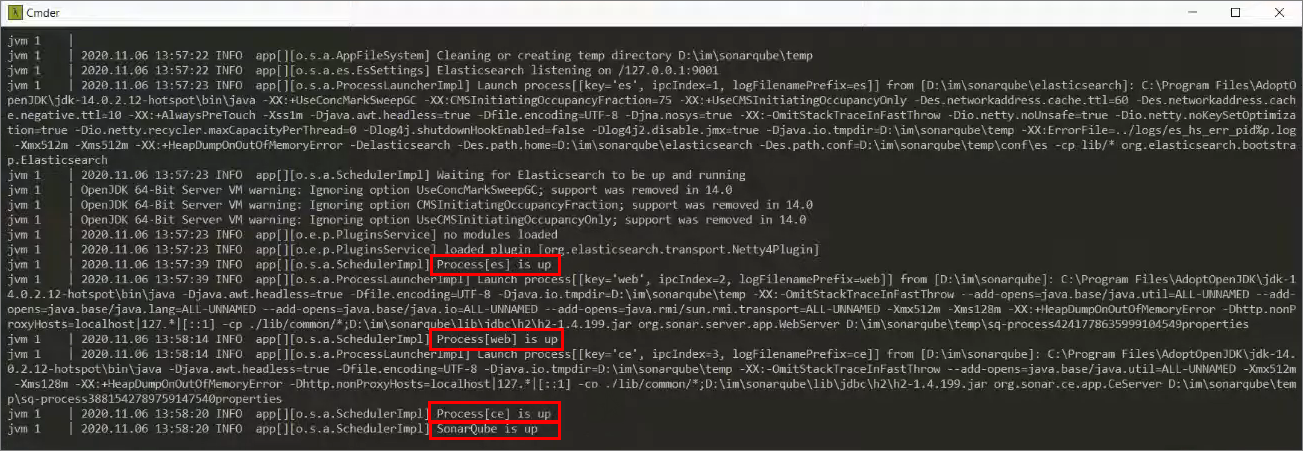
-
у нас запустился es – на этот раз без ошибок;
-
запустился web – без ошибок;
-
запустился третий компонент ce – compute engine, который обрабатывает фоновые задания в SonarQube;
-
и дальше мы видим заветную строчку «SonarQube is up».
Переходим в браузер, открываем адрес localhost:9000 и сразу видим веб-интерфейс SonarQube на английском языке.
Для входа в систему вводим данные авторизации (логин admin и пароль admin) и нажимаем на кнопку Log In.
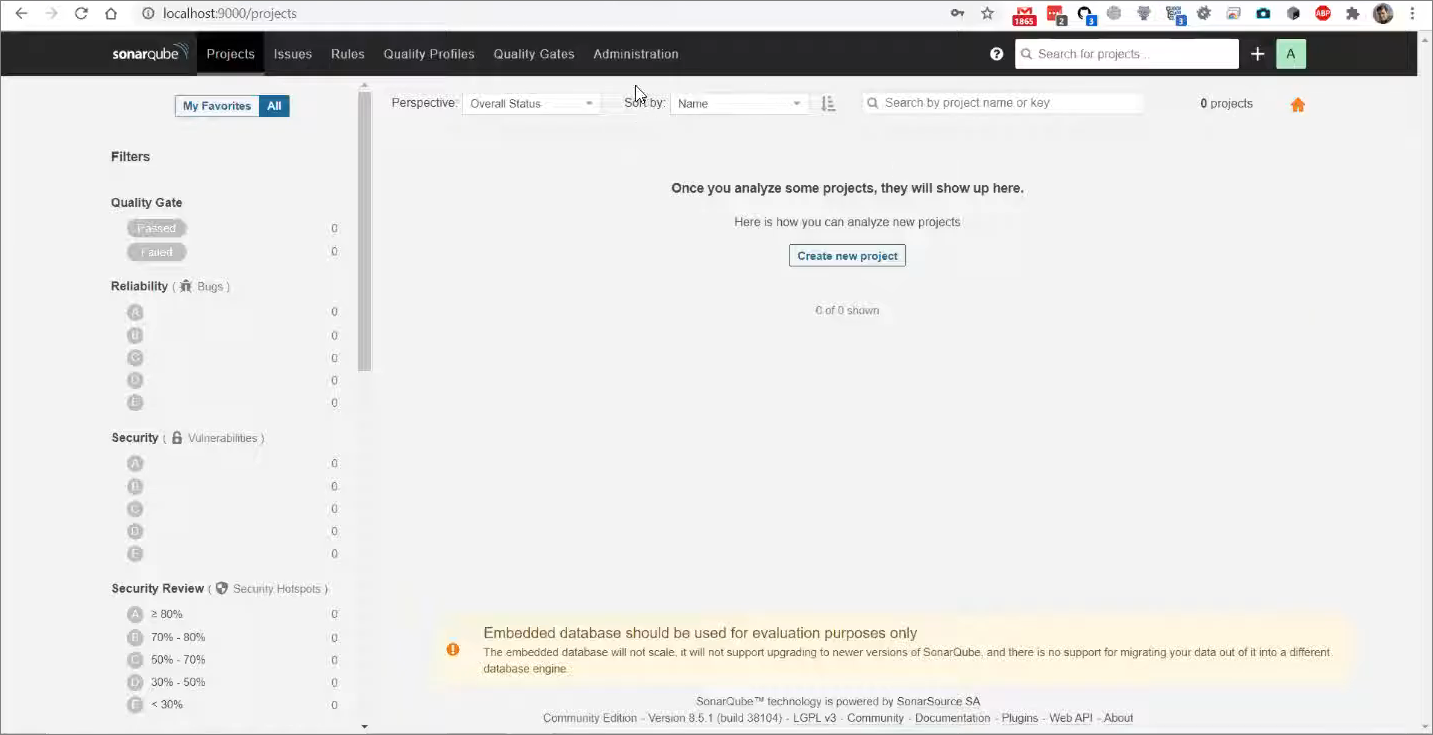
Готово! Можем переходить в настройки администрирования, создавать новые проекты и т.д. Я бы мог дальше продолжить свой рассказ, если бы не одна большая страшная надпись внизу – в вольном переводе здесь написано, что встроенная база данных должна использоваться только для целей демонстрации или тестирования.
Если вы собираетесь текущим инстансом SonarQube пользоваться больше, чем один день – вы хотите регулярно анализировать свою конфигурацию, показать его своим коллегам, перенести на централизованный сервер внутри вашей компании – то текущая установка ни в коем случае не полная, и вам обязательно нужно подключить СУБД.
Дело в том, что, во-первых, встроенная база данных не очень производительная – на малых объемах она справляется достаточно хорошо, но, когда мы начинаем грузить сюда ERP с его 10 миллионами строк кода и сотнями тысяч замечаний, она начинает немного «проседать». Если вы грузите туда больше одного проекта, она начинает «проседать» все больше и больше.
А вторая проблема – самая страшная – встроенная база данных не поддерживает обновление версии SonarQube и какую-либо миграцию на другую СУБД.
Если вы начали активно использовать SonarQube и не переехали на СУБД, то вы на этой внутренней базе данных останетесь навечно (и потонете в легаси). Это прямо совсем не круто.
Подключение PostgreSQL
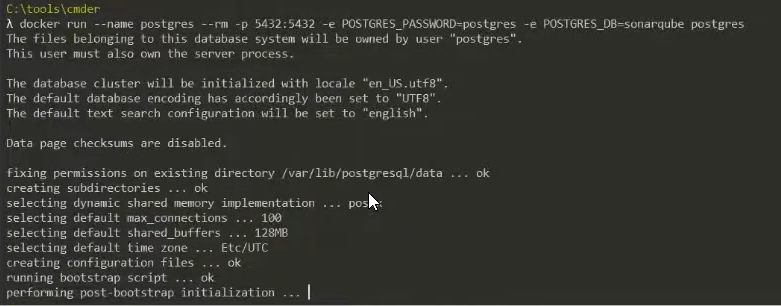
В качестве решения вы можете поднять PostgreSQL, например.
Я сейчас не буду поднимать инстанс PostgreSQL через инсталлятор, создавать базу через pgadmin и т.д. Я очень быстро – одной командой в Docker – запущу PostgreSQL под пользователем postgres с паролем postgres и автоматически создам базу с названием sonarqube:
docker run --name postgres --rm -p 5432:5432 -e POSTGRES_PASSWORD=postgres -e POSTGRES_DB=sonarqube postgres
Если вы захотите запустить эту команду у себя, то обратите внимание, во-первых, на флаг удаления контейнера после его установки (--rm), а во-вторых, на отсутствие каких-либо примонтированных каталогов для сохранения данных. Так что будьте осторожны – если вы хотите все-таки использовать postgres в docker, все-таки почитайте документацию, как его поднимать, либо используйте postgres из инсталлятора. И желательно на Linux, т.к. PostgreSQL на нем работает лучше, чем на Windows.
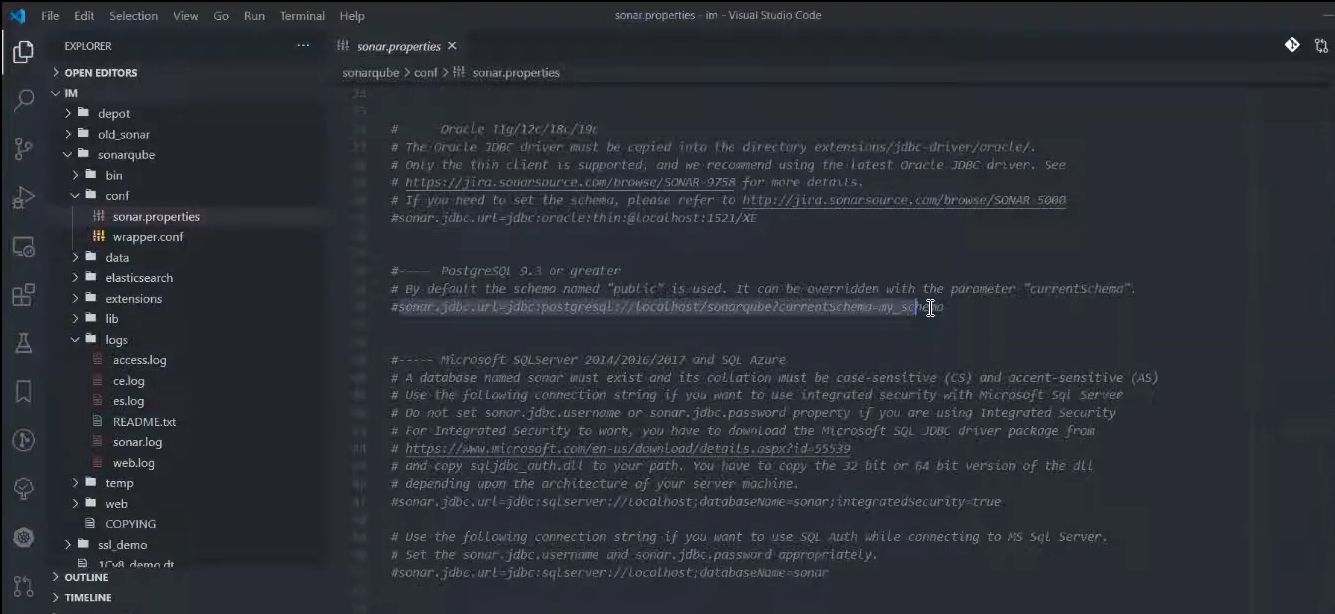
Как нам натравить SonarQube на использование PostgreSQL?
Останавливаем текущий инстанс через Ctrl+C.
И открываем файл sonar.properties из каталога conf папки, куда установлен SonarQube.
Здесь есть очень-очень много настроек – они все детально задокументированы.
Но нас здесь сейчас интересует настройка подключения к базе данных – sonar.jdbc.url.
Обратите внимание, в файле есть примеры подключения к различным базам данных – это Oracle, PostgreSQL и MS SQL (MySQL больше не поддерживается).
Для PostgreSQL есть пример строки подключения – мы его чуть-чуть поменяем.
И моя рекомендация – не нужно редактировать значение в файле свойств прямо в этой строке путем ее раскомментирования и редактирования, а перенесите все настройки в самый низ – вам нужно будет потом переносить настройки между версиями – вы просто из одного места их копируете и переносите в новое место.
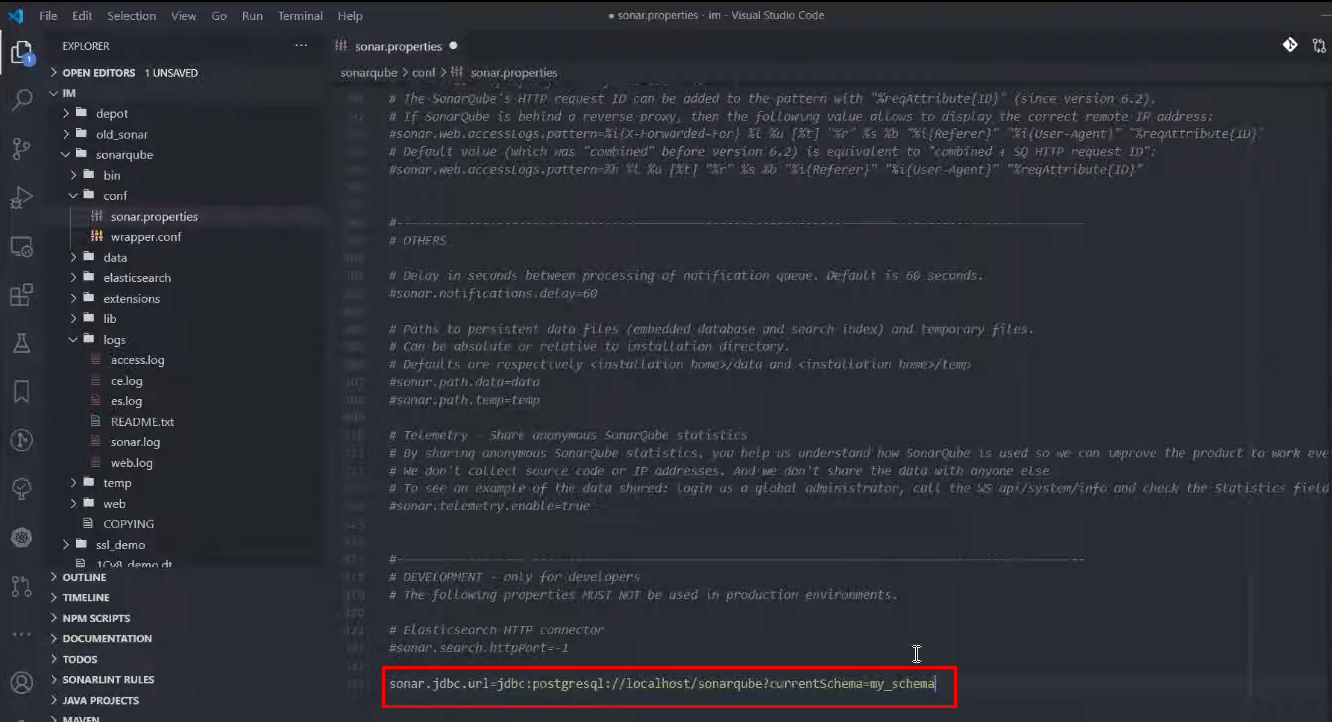
По умолчанию строка подключения к PostgreSQL выглядит так:
sonar.jdbc.url=jdbc:postgresql://localhost/sonarqube?currentSchema=my_schema
Это значит, что:
-
мы используем провайдер postgresql;
-
сервер у нас крутится на localhost;
-
СУБД, которая будет использоваться, называется sonarqube;
-
currentSchema – схема баз данных.
Поскольку у нас используется схема баз данных по умолчанию («public»), параметр currentSchema нужно удалить.
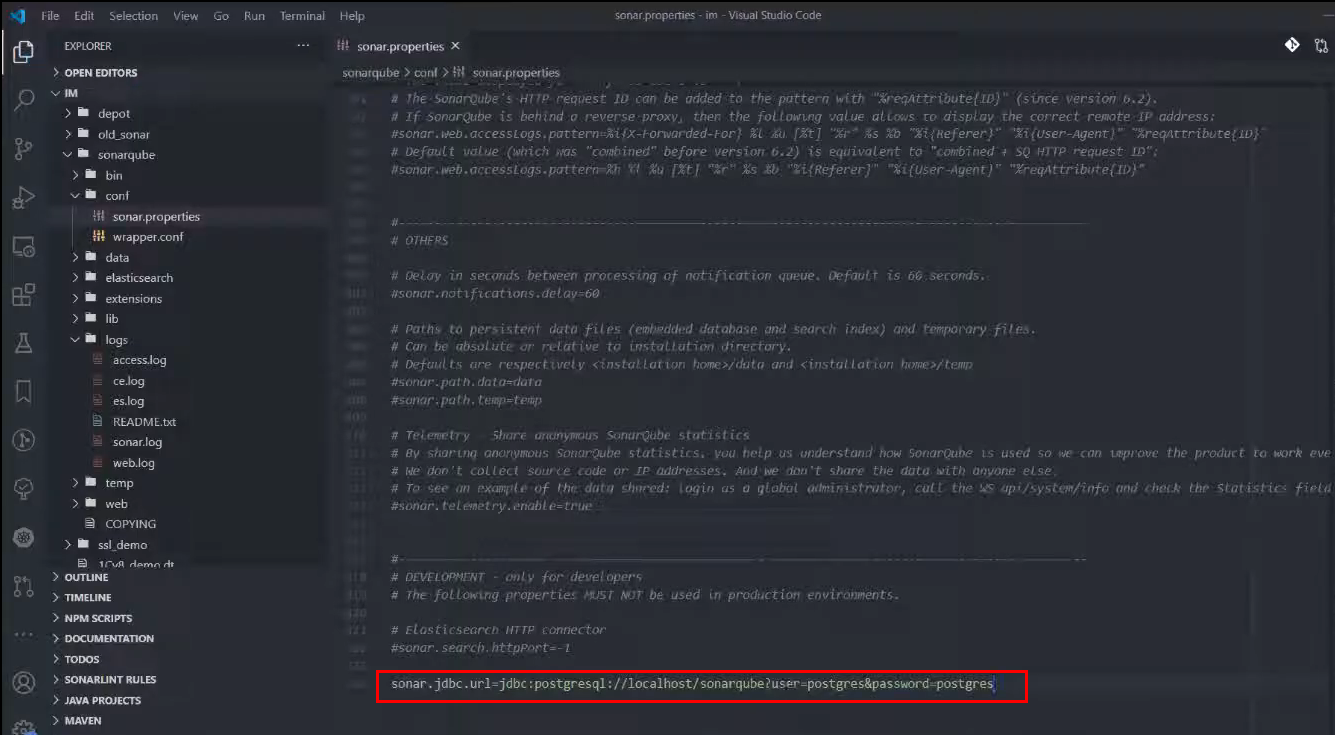
Вместо этого допишем данные авторизации:
sonar.jdbc.url=jdbc:postgresql://localhost/sonarqube?user=postgres&password=postgres
Естественно, в реальной инсталляции правильнее завести отдельного пользователя, раздать права и т.д., чтобы все было по-правильному.
Сохраняем файл sonar.properties.

Если это у вас чистый инстанс, который вы ни разу не запускали, вы можете просто снова запустить батник запуска SonarQube, и все будет хорошо.
Но если у вас этот инстанс уже использовался, вы уже делали там какие-то настройки, запускали анализ, я рекомендую вам в папке data удалить папку es6 – это данные полнотекстового поиска, который построил Elasticsearch внутри SonarQube. В случае наслоения данных разных БД (в том числе, внутренней и postgres), могут вылезать непонятные артефакты – вы можете увидеть проекты, которых на самом деле нет, или замечания, которые уже удалились.
Поэтому просто удаляете папку es6, перезапускаете сервер, при запуске он вам эту папку создаст заново и постарается подключиться к СУБД PostrgreSQL.

Как видите, сервер у нас поднялся, а страшная надпись пропала, значит, наш сервис уже более-менее готов к использованию.
Sonar-Scanner
SonarQube – многокомпонентное приложение, в нем есть:
-
отдельный компонент, который отвечает за серверную часть и складывает результат в базу данных;
-
отдельный компонент, который отображает вам результаты в веб-интерфейсе;
-
и отдельный компонент, который отвечает за анализ исходников.
С серверной частью SonarQube мы уже разобрались, веб-интерфейс SonarQube увидели, теперь посмотрим, как происходит анализ на стороне клиента.
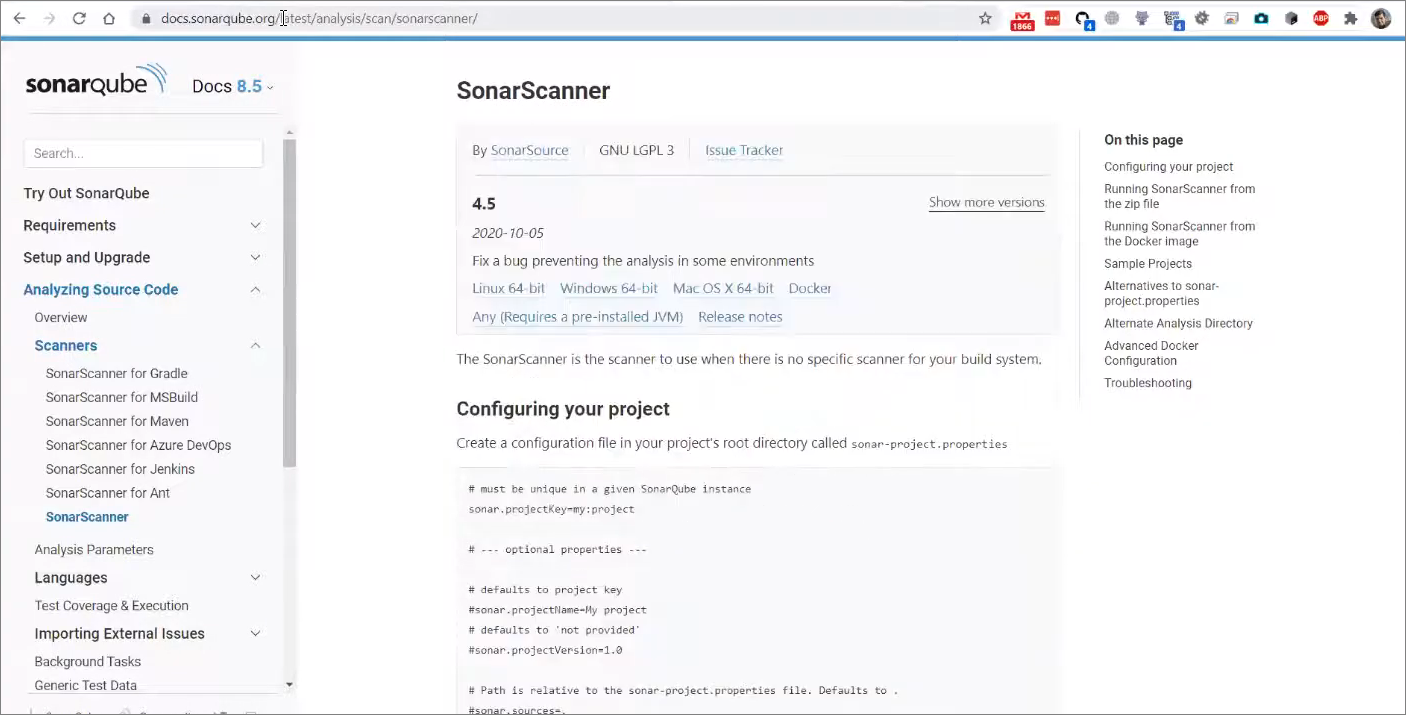
Компонент, который отвечает за анализ исходников, называется sonar-scanner, его можно скачать с сайта https://docs.sonarqube.org/latest/analysis/scan/sonarscanner/.
Рекомендую вам обратить внимание на сайт docs.sonarqube.org – здесь очень много информации о том, как настроить SonarQube, как использовать sonar-scanner, какие есть параметры для анализа – иногда даже какие-то неочевидные вещи. В том числе здесь есть информация о том, как запускать Java-проекты, как запускать C#-проекты, как интегрировать это все с Jenkins, если вы его используете и т.д. Надеюсь, вам это будет полезно.
Обратите внимание, здесь в разделе загрузок есть несколько вариантов установки. Казалось бы, можно взять установщик на Windows 64-бита и радоваться жизни. Но ссылка Windows 64-bit отличается от ссылки Any (Requires a pre-installed JVM) тем, что в дистрибутивах, которые заточены под конкретную операционную систему, внутри запакована какая-то Java, причем, не самой первой свежести. Причем, насколько я помню, даже не с последними security-патчами.
Поэтому, если вы торопитесь, вы можете установить дистрибутив Windows 64-bit, но, поскольку Java у вас на машине уже стоит, лучше сразу скачать any-установку.

Скачанный архив мы распакуем также в каталог рядом с sonarqube, и для красоты переименуем его в просто sonar-scanner.
Структура каталога sonar-scanner примерно такая же, как у самого sonarqube:
-
в каталоге bin лежат файлы, которые непосредственно будут запускаться;
-
в каталоге conf лежат общие настройки sonar-scanner.
В файле sonar-scanner.properties вы можете прописать значения по умолчанию для всех анализов.
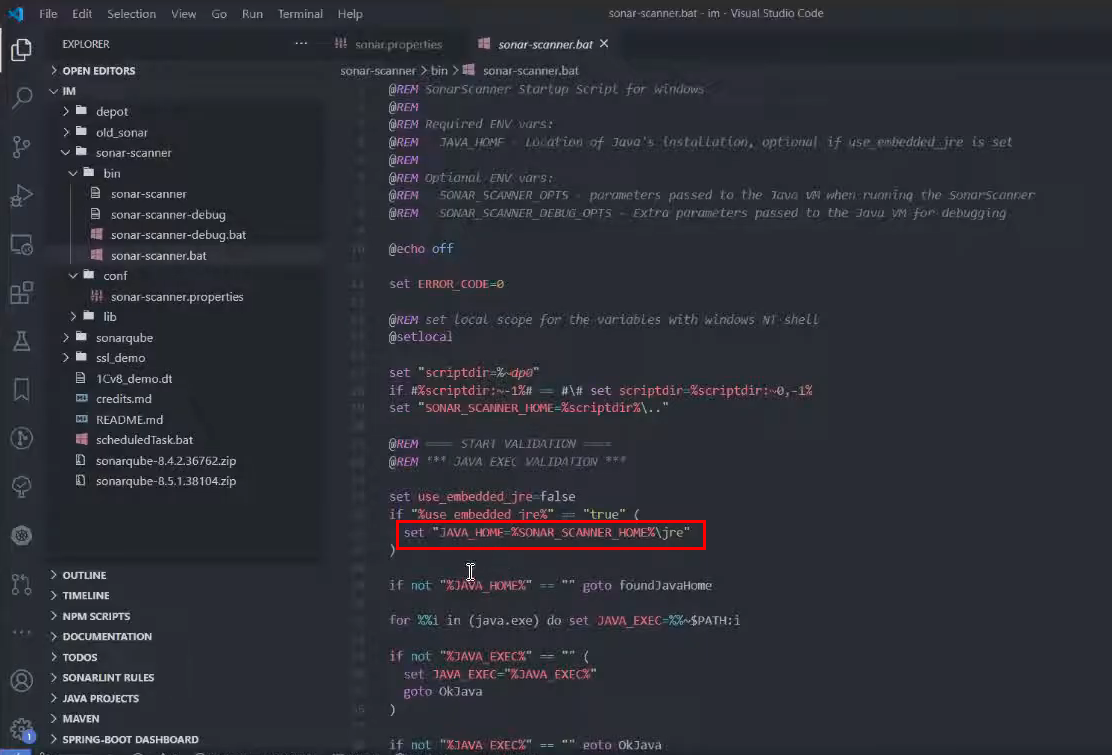
И в самом запускающем bat-нике (sonar-scanner.bat) можно, например, переопределить местонахождение Java (по умолчанию он ищет Java в переменной среды JAVA_HOME либо в переменной среды PATH, но вы можете это здесь поменять).
Чтобы у вас sonar-scanner запускался из командной строки без прямого пути, вы можете открыть свойства компьютера, дополнительные параметры системы, переменные среды, найти переменную среды PATH и добавить сюда каталог bin из папки sonar-scanner (например, под Windows 10):
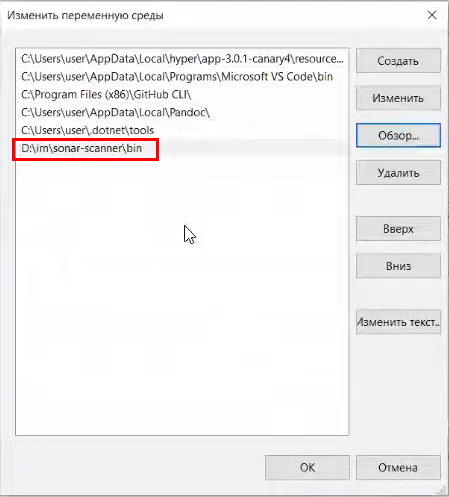
После этого, когда вы сохраните значение переменной PATH и переоткроете командную строку (перезапустите cmd), у вас sonar-scanner будет доступен уже без прямого указания – просто по имени sonar-scanner.
Установка плагинов
Вернемся к веб-интерфейсу SonarQube. Что мы можем сделать, чтобы упростить себе работу?
В первую очередь, мы можем поставить плагин локализации.
Для этого нужно перейти в раздел Administration по гиперссылке Marketplace.
Здесь есть несколько плагинов – большинство из них бесплатные, но внимательно проверяйте, на каких условиях они поставляются. Иногда написано, что лицензия коммерческая, и вам нужно принять какие-то условия – поэтому ставьте плагины осторожно.
Первый же плагин в это списке – это плагин для поддержки 1С – 1C (BSL) Community Plugin. Это бесплатный плагин, который доступен для установки прямо из маркетплейса. Нажимаем кнопку Install.
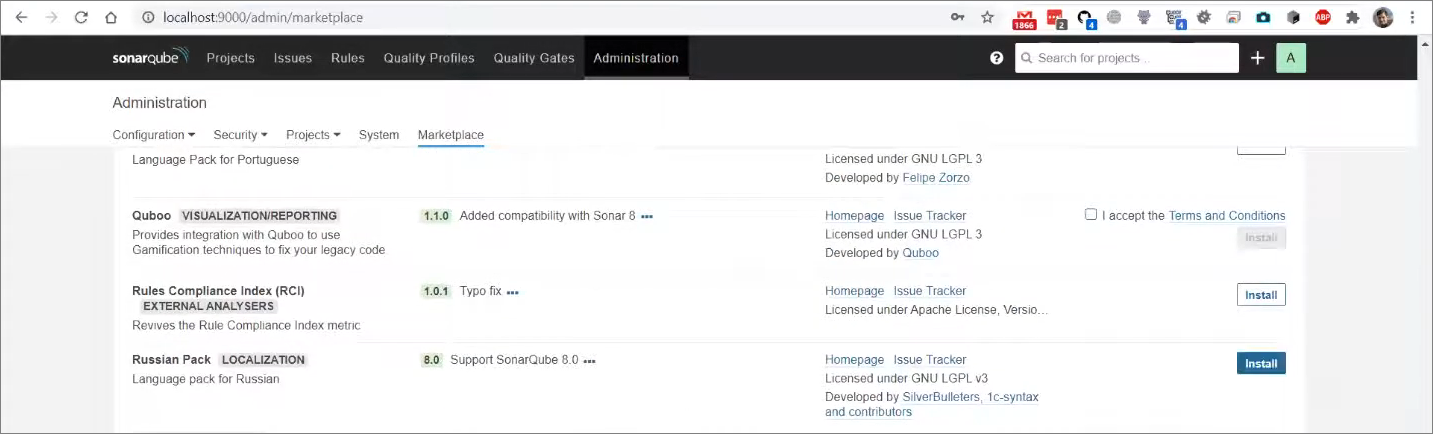
И второе, что нас здесь интересует – это плагин Russian Pack. Тоже нажимаем кнопку Install.
Текущий перевод, который доступен в маркетплейсе, заточен под версию 8.0, но мы постепенно переводим все больше и больше.
Надеюсь, мы все-таки догоним версию 8.5, и все переводы будут актуальны. В этой версии вы можете встречать какие-то места, которые переведены не до конца. Но в целом, большая часть интерфейса будет на русском.
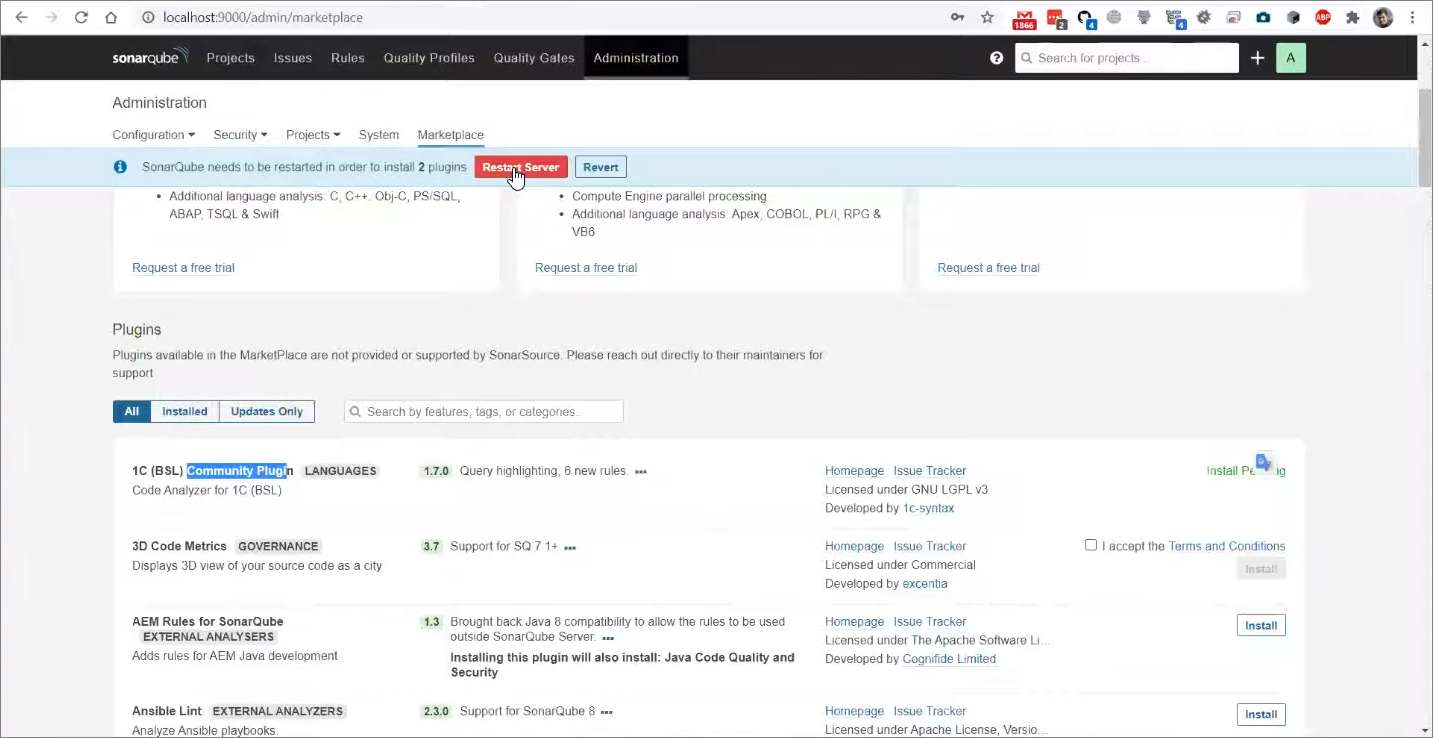
Плагины установились и просят перезагрузить SonarQube.
Обратите внимание, куда все это скачивается.

Никакой магии нет. В каталоге sonarqube есть папка extensions, здесь есть папка downloads, куда складываются текущие плагины, которые вы скачали, но которые еще не применились к установке и не поставились на сервер.
И папка plugins, в которой лежат сторонние, не зашитые в ядро SonarQube плагины, которые вы поставили отдельно.
После перезагрузки jar-файлы из папки downloads переместятся в папку plugins, и все должно заработать автоматически.
Есть два момента:
-
Во-первых, в папке plugins не должно быть нескольких jar-файлов плагинов с одним и тем же ключом. Ключ обычно зашит в середине наименования – в случае 1С-ного плагина это communitybsl. Если ваш сервер увидит несколько jar-файлов на один и тот же ключ плагина, он не запустится. Он тоже напишет ошибку в web.log о том, что обнаружено дублирование плагинов, вам нужно будет этот конфликт как-то разрешить.
-
Второй момент – если у вас сервер запущен, и вы просто положили плагин в папку plugins, сервер об этом ничего не знает, его нужно будет перезагрузить для того, чтобы он подхватил новые изменения, загрузил их в память и стал использовать для дальнейшей работы.
Правильный путь установки плагинов, которые не доступны из маркетплейса – это положить их в папку downloads, а потом при старте сервера они переедут в папку plugins, причем, заменят старые версии, если там какие-то уже стояли.
Нажимаем кнопку «Restart Server», которая перезагрузит SonarQube. Также возможность перезагрузки доступна из вкладки «System» – там справа вверху будет кнопка «Перезагрузка сервера», которая сделает то же самое.
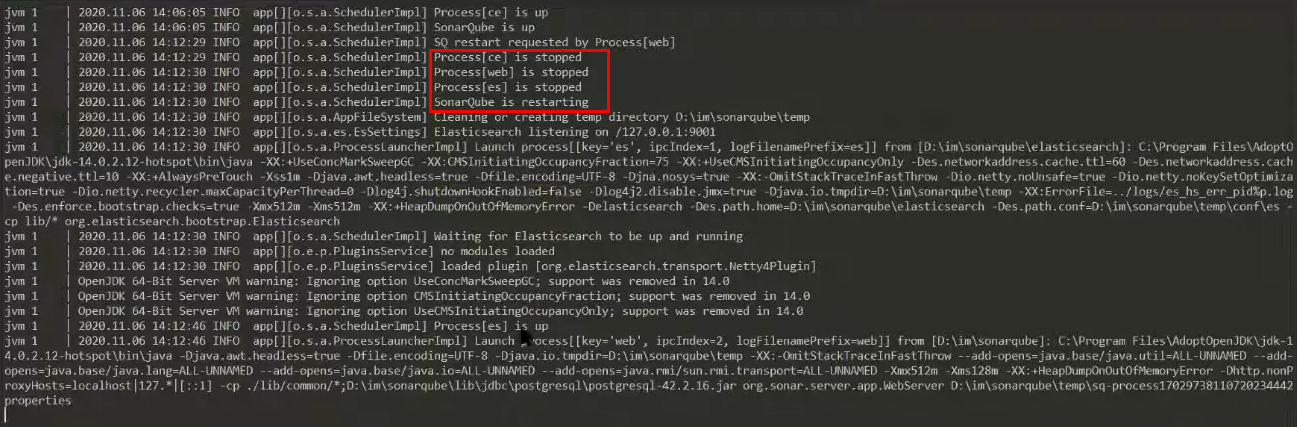
В логах мы можем увидеть, что SonarQube пошел на рестарт и сейчас заново начнет переподнимать все свои процессы. На этот раз уже побыстрее, потому что мы базу данных проинициализировали, и индекс Elasticsearch у нас построен. Все должно быть хорошо.
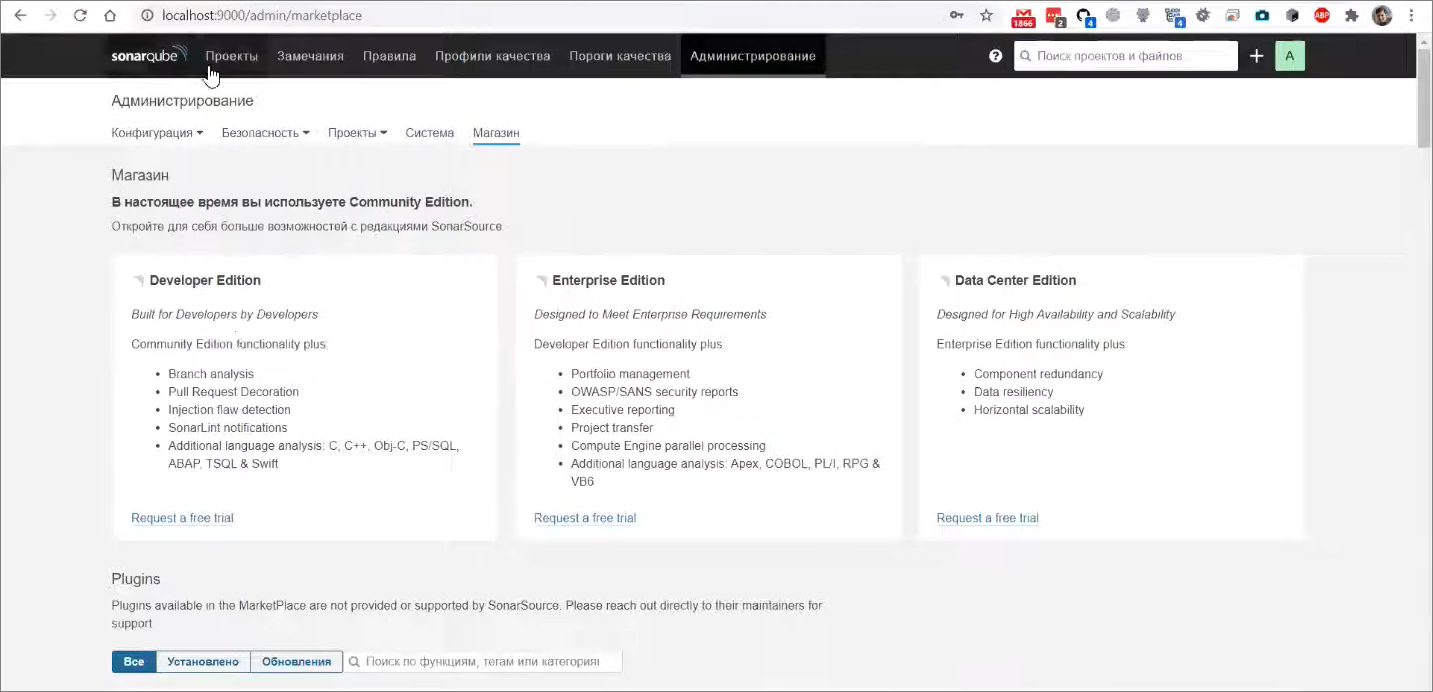
Как мы видим, после перезагрузки нас уже приветствует русский интерфейс.
В целом, если зайти в настройки и посмотреть, что тут есть – сами настройки не переведены, потому что API для этого в самом SonarQube нет, но когда мы будем исследовать данные по какому-то проекту, там уже многие вещи будут написаны на русском языке – все метрики, вся информация по проекту и т.д.
Базовые настройки сервера SonarQube
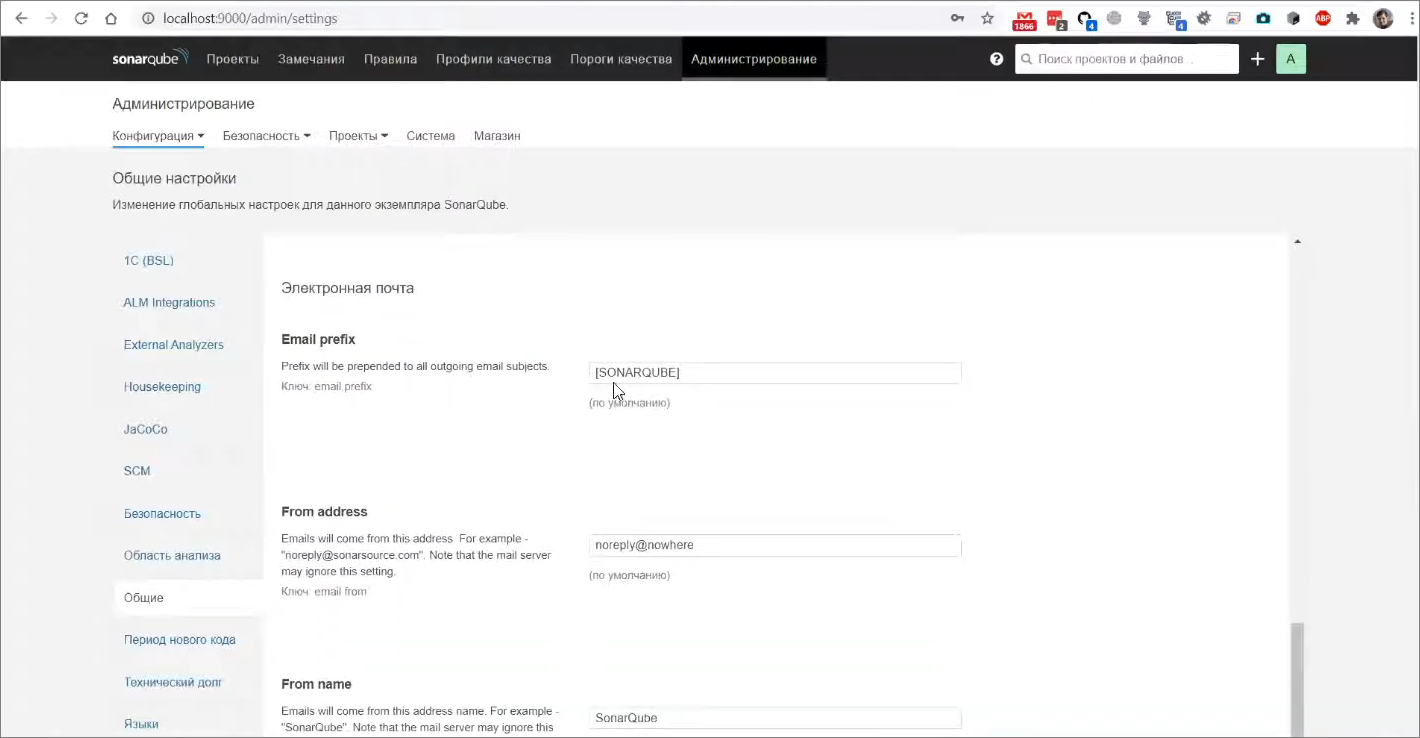
Какие есть базовые настройки на уровне сервера?
Конечно же, вас будет интересовать настройка почты, потому что вам, скорее всего, захочется настроить рассылку о замечаниях. Настройка почты находится в разделе «Общее» – «Электронная почта». Здесь вы можете указать – откуда, куда, параметры подключения, SMTP-host и т.д.

Также, если вы все-таки планируете этот сервер показывать кому-то еще, если он у вас будет работать долго, вам нужно включить явное требование авторизации, которое находится в разделе «Безопасность» – это параметр
«Force user autentification». Эта штука закроет ваш инстанс SonarQube от просмотра проектов без предварительного логина, в том числе неавторизованный пользователь не сможет выполнять анализ.
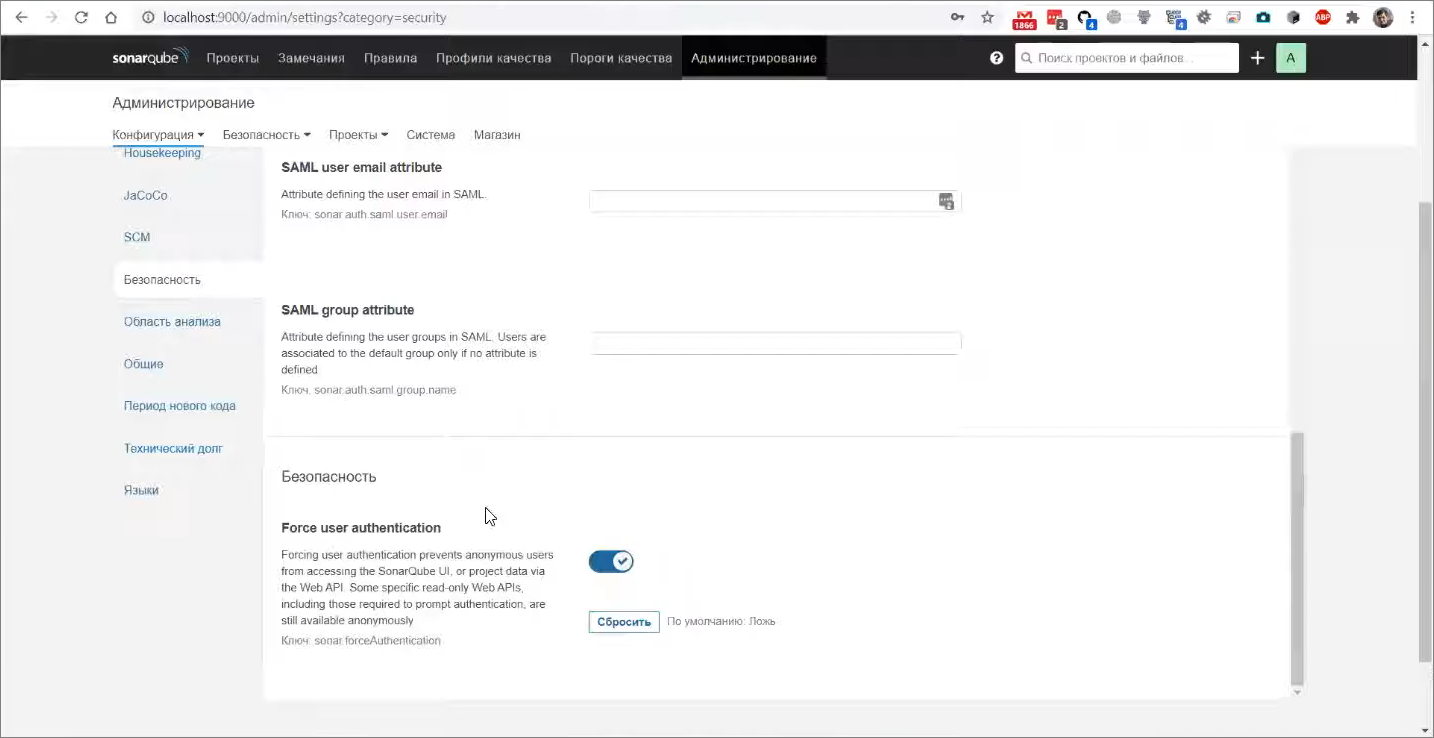
Я тоже сейчас эту опцию включу, потому что хочу показать вам работу с авторизацией.
Из чего вообще состоит SonarQube
Сверху есть панель с разделами – это, по сути, самые главные компоненты, которые есть в сервере.
На закладке «Проекты» будут отображаться проекты – мы совсем скоро проанализируем здесь свой первый проект.

На закладке «Замечания» будут отображаться замечания для имеющихся у вас проектов – их тоже можно будет посмотреть с различными фильтрами, мы это тоже сегодня проделаем.

На закладке «Правила» можно посмотреть, какие правила доступны для использования – например, вы можете отобрать по языку «1С (BSL)» и увидеть 123 доступных на текущий момент правила (151 на 2022-05-01).
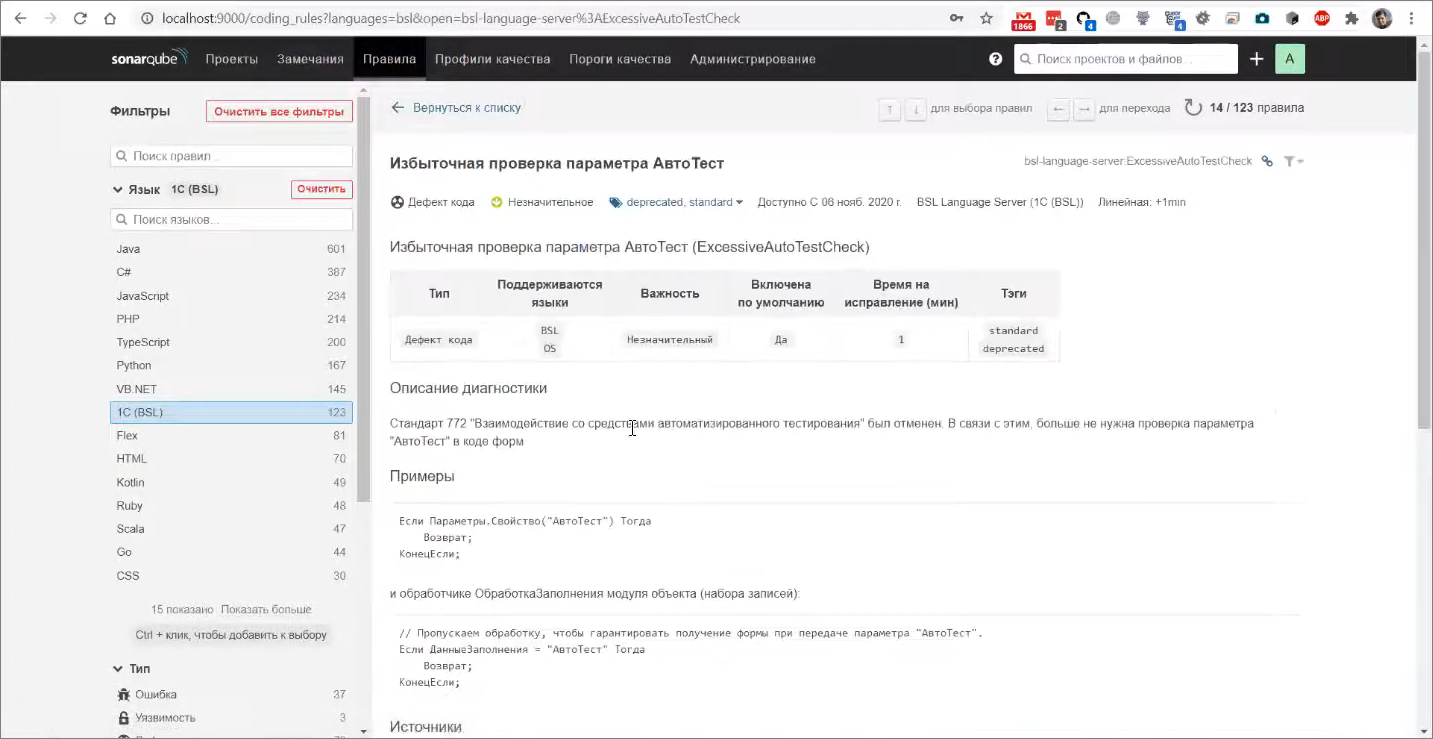
Здесь можно посмотреть описание каждого правила:
-
к какому типу оно относится – ошибка, уязвимость, либо дефект кода;
-
какая у него важность;
-
какие у него теги;
-
когда это правило появилось;
-
и, наверное, самое полезное – это сколько технического долга приносит каждое срабатывание такого правила.
Если в вашем коде будет обнаружено использование параметра АвтоТест, то размер технического долга на вашем проекте увеличится на одну минуту.
Примерно так технический долг и считается:
-
мы берем все замечания, которые сработали на ваш проект;
-
умножаем их на значение времени на исправление;
-
получаем какую-то большую цифру в часах. Делим ее на 8 (потому что у нас стандартный 8-часовой рабочий день) и получаем количество долга в днях.
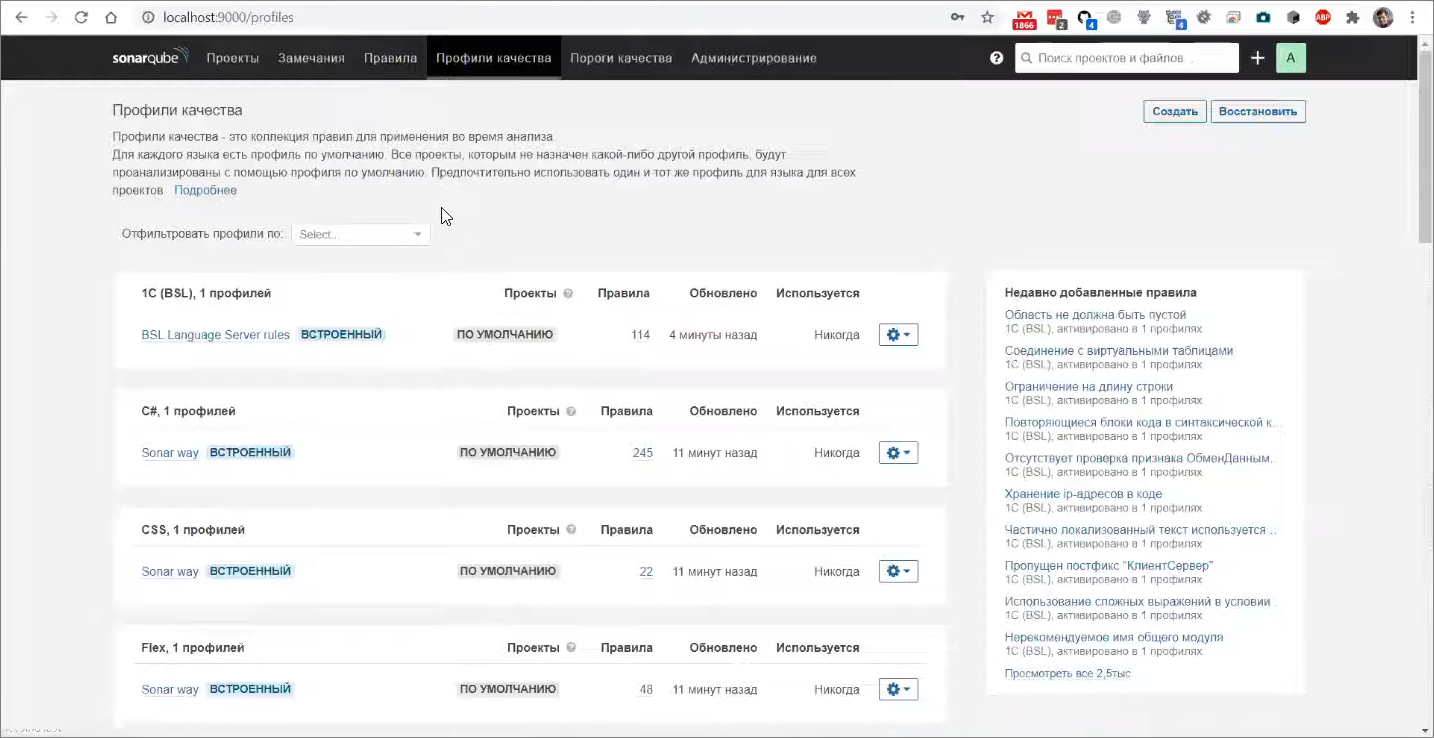
Все правила, которые есть в каждом из плагинов, группируются в так называемые профили качества. Это совокупность активированных правил и каких-то их настроек.

Например, у нас есть встроенный профиль качества «BSL Language Server rules» – это движок анализа, который предоставляет все эти данные. Нажмём гиперссылку активных правил, чтобы вывести их список.
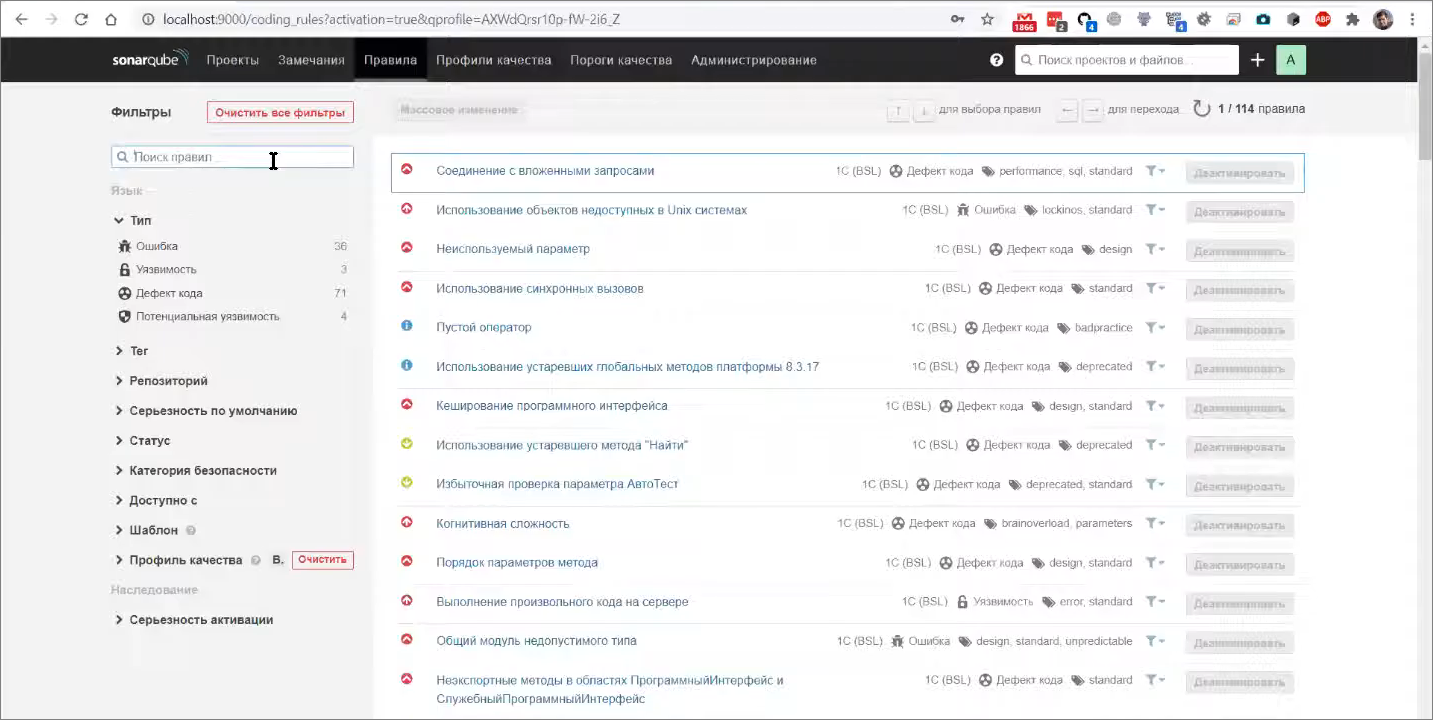
Здесь представлены все правила, которые используются в данном профиле качества – их можно фильтровать по типам и искать в списке по строке.

Откроем правило «Ограничение на длину строки», которое по умолчанию имеет настройку в 120 символов.
Создавая собственные профили качества, вы можете эти настройки переопределять, включать или выключать какие-то правила, тюнить настройки анализа под себя (в конце мастер-класса я это покажу).
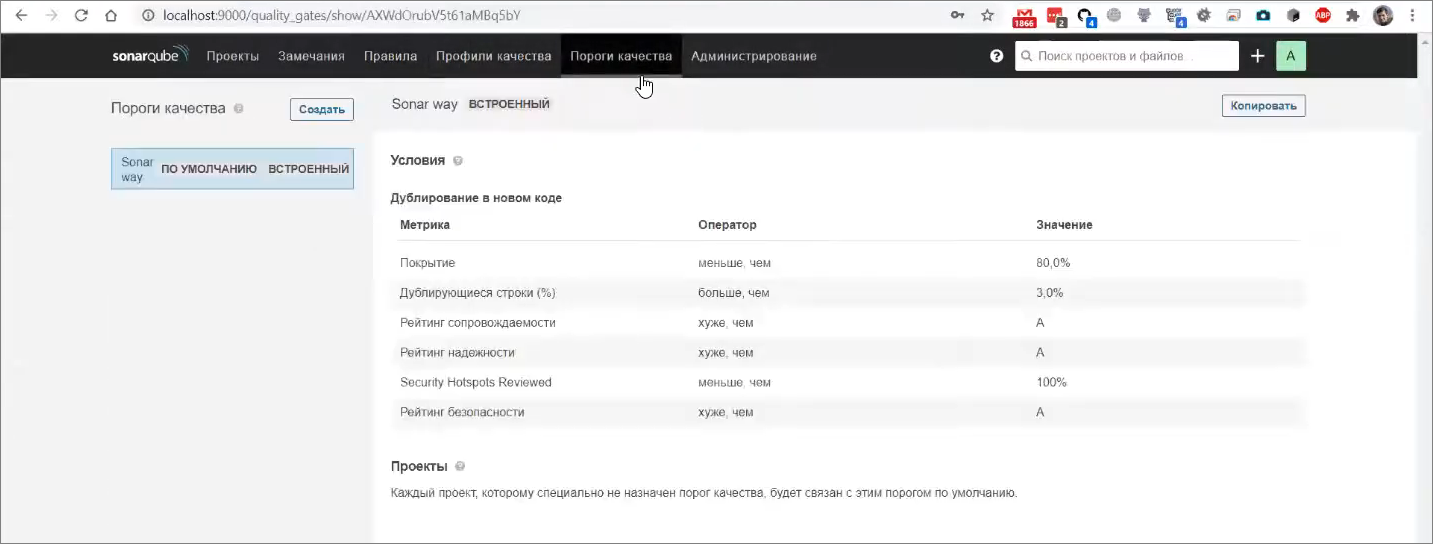
И последний важный компонент – это так называемый «порог качества». В SonarQube вообще есть идея о том, что вам нужно не допускать ухудшения состояния вашего программного продукта путем контроля некоторых очень важных метрик. Например, у вашего проекта «не должно быть новых ошибок и уязвимостей» или «соотношение технического долга, который вы добавили в новой версии, не должно превышать какого-то определенного порога».
Все эти «хуже, чем», «меньше, чем», «больше, чем» и т.д. вы можете настроить в пороге качества, который изначально уже имеет какие-то показатели.
Обратите внимание, что он ожидает 80% покрытие, о чем нам в 1С можно только мечтать. Но все это дело тоже можно поменять и подтюнить под ваше конкретное использование.
Анализ исходников БСП с помощью sonar-scanner

Переходим к анализу нашей конфигурации.
У нас здесь БСП версии 3.1.323 – это последняя БСП, которая опубликована на сегодня (прим. ред.: ноябрь 2020 г.). Она у нас с заблокированной возможностью изменения.
Тренироваться мы будем на этой базе. Нам даже не обязательно ее запускать, главное получить исходники.
SonarQube анализирует только исходники конфигурации – он ничего не знает про CF-файлы, про EPF-файлы и прочее, что связано с 1С-спецификой. Поэтому для анализа нам нужно выгрузить конфигурацию в файлы.
Я создам новый каталог SSL, внутри которого создам подкаталог src, в котором создам каталог cf.
Я это делаю для двух целей:
-
Во-первых, потом мы это превратим в Git-репозиторий, а в Git-репозитории помимо исходников конфигурации обычно лежат еще всякие конфигурационные файлы, тесты, документация и т.д. Если исходники будут лежать прямо в корне – это будет нехорошо.
-
Во-вторых, когда мы натравим на исходники gitsync, у него есть особенность – он чистит каталог с исходниками, поэтому, если вы будете выгружать в корень репозитория, у вас удалится все.
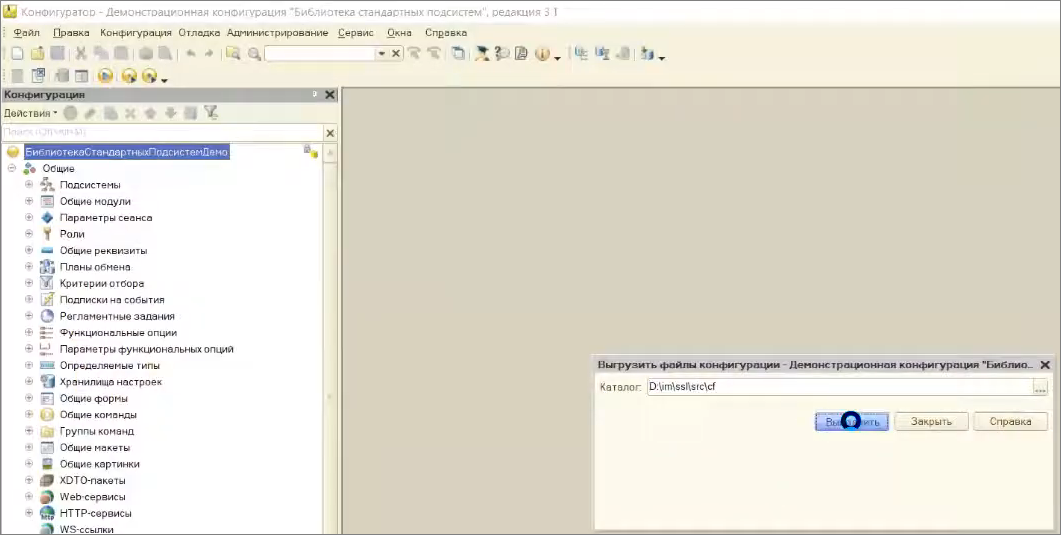
Выгружаем конфигурацию в созданную нами папку.
Пока идёт выгрузка, откроем еще один терминал, перейдём в созданный каталог и в этом каталоге мы сейчас запустим sonar-scanner, который мы уже добавили в переменную среды PATH (либо придется прописать полный путь).
И здесь мы укажем ему несколько важных настроек.
Самая важная настройка, которая есть в анализе – это ключ проекта. Без передачи ключа проекта у вас ничего не заработает. Ключ проекта можно задавать:
- либо через переменные окружения,
- либо передавая их в командной строке,
- либо сформировав специальный файлик, до которого мы чуть попозже дойдем.
Мы зададим ключ проекта в командной строке:
sonar-scanner -Dsonar.projectKey=ssl
Для передачи параметра мы ставим -D, для указания ключа проекта используется параметр sonar.projectKey и через знак равенства указываем, что sonar.projectKey=ssl.
Запускаем.
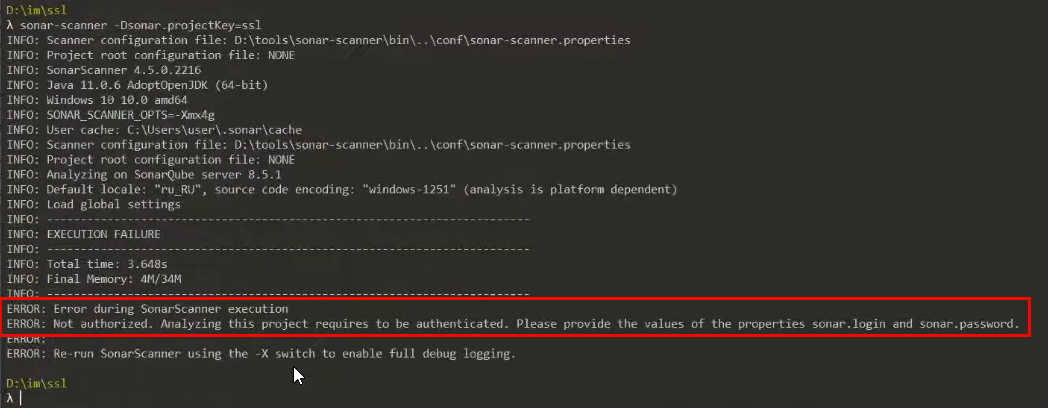
У нас будет выведен лог, в котором будет в том числе информация о том, какая версия Java используется для анализа, с какими параметрами анализ запустился, какие дополнительные конфигурационные файлы используются.
И дальше мы ловим первую ошибку – SonarQube нам говорит о том, что мы не авторизованы. Это как раз та защита от внешних вредителей, которые могут попортить наш сервер – нам нужно передать настройку sonar.login и sonar.password. На самом деле, это старые настройки, сейчас достаточно передать только sonar.login, в который нужно передать аутентификационный токен.
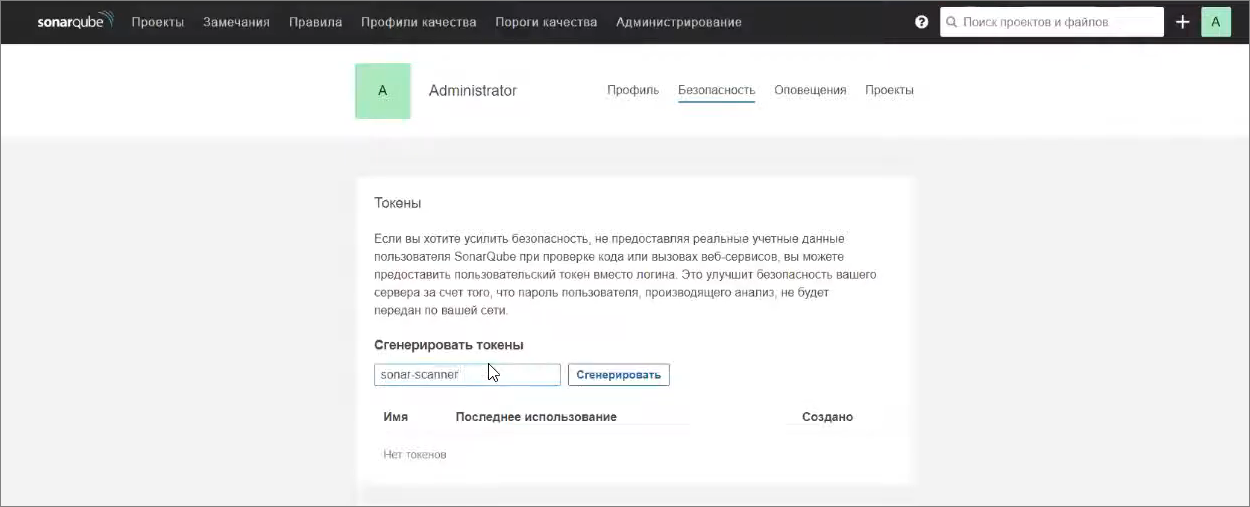
Токен берется из вашего аккаунта – вы можете зайти в ваш аккаунт, перейти на вкладку «Безопасность» и сгенерировать новый токен.
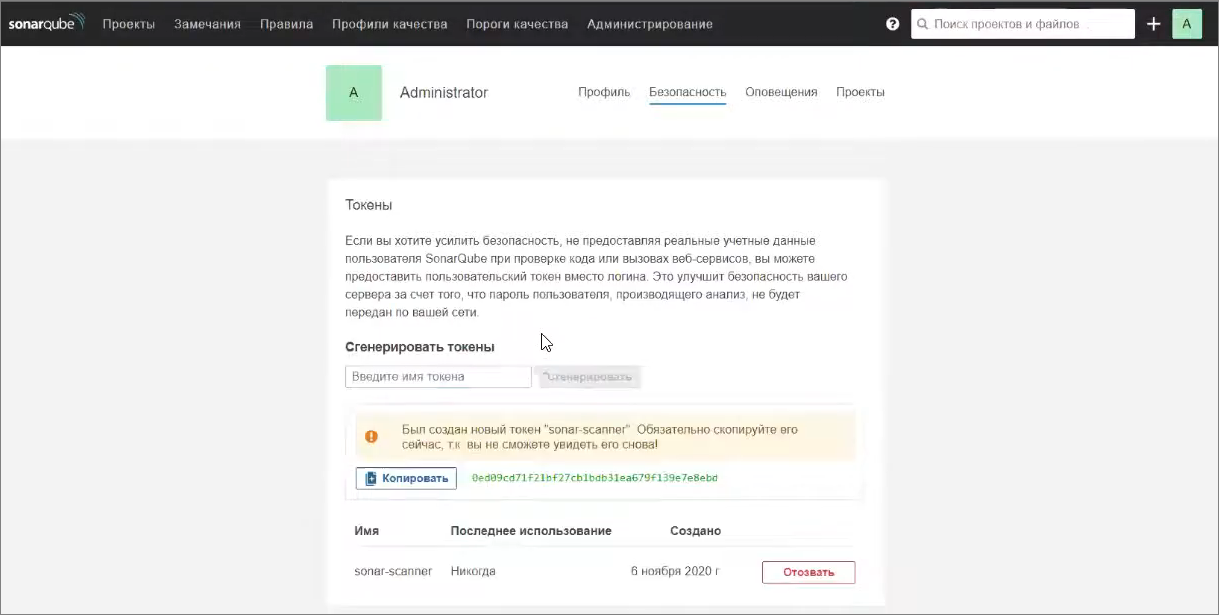
Токен – это последовательность символов, которая будет вам показана только один раз. Если вы обновите страницу, токен уже пропадет – он больше не отображается, просто написано, когда он был создан, как он называется и когда он последний раз использовался.
Этот самый токен вы можете передать как значение sonar.login – это такой комбинированный логин и пароль.
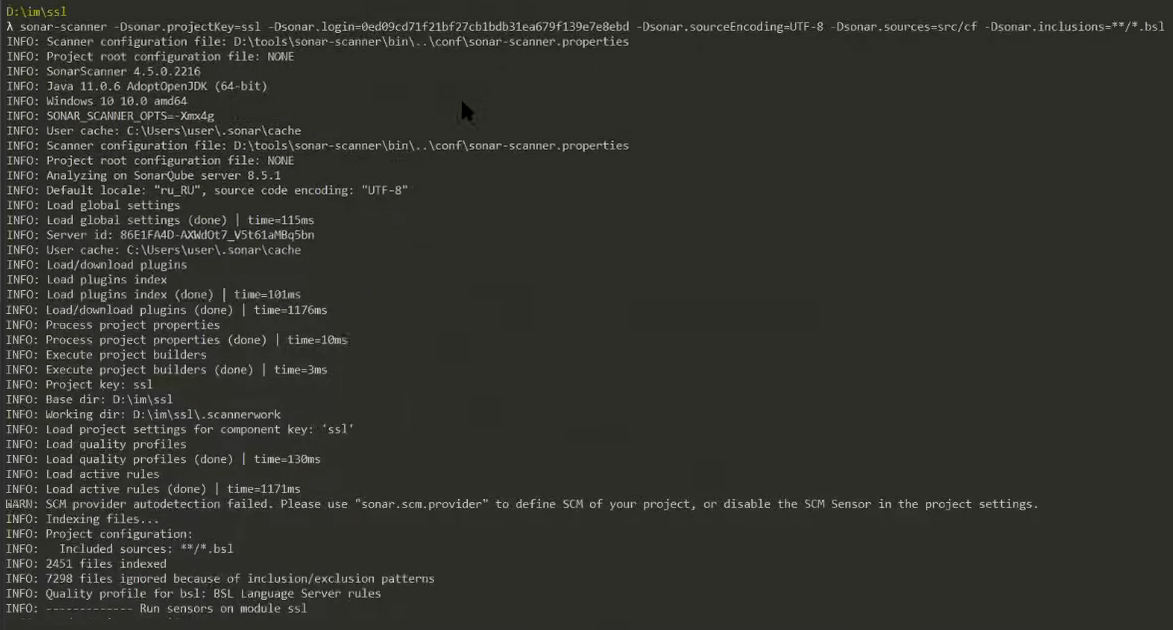
sonar-scanner -Dsonar.projectKey=ssl -Dsonar.login=[токен] -Dsonar.sourceEncoding=UTF-8 -Dsonar.sources=src/cf -Dsonar.inclusions=**/*.bsl
И также я передам несколько дополнительных настроек, которые нужно задавать под Windows, а именно:
-
sonar.sourceEncoding=UTF-8 - кодировка исходных файлов. Вы можете увидеть сообщение от Sonar о том, что он начал читать файлики в 1251. Это происходит потому, что Java под Windows по умолчанию работает в системной кодировке, которая, к сожалению, ANSII, а не UTF-8. Но мы это дело можем исправить, передав параметр sonar.sourceEncoding.
-
sonar.sources=src/cf - чтобы SonarQube было меньше сканировать, мы поможем ему, указав путь к исходникам через sonar.sources – это поможет вам сократить количество файлов, которые изначально захватываются для анализа. Например, если вы анализируете JavaScript, вам не нужно анализировать node_modules, потому что там сотни тысяч файлов, которые будут очень долго анализироваться, а вам это не нужно, поэтому вы можете натравить анализ на конкретный каталог.
-
sonar.inclusions=**/*.bsl - маска для поиска файлов. Здесь «**» означают, что нам нужно искать во всех каталогах любой вложенности. «*.bsl» говорит о том, что нам нужно искать bsl-файлы с любым именем;
-
Если вы захотите исключить какие-то файлы из анализа – например, часто исключаются регламентированные отчеты либо отчетность целиком – вы можете исключить их, передав дополнительное свойство sonar.exclusions.
Запускаем.
Анализ у нас уже начался, и мы видим, что:
-
наши исходники уже переключились в UTF-8;
-
мы не подхватили настройки системы контроля версий (у нас никакой системы контроля версий нет);
-
мы будем анализировать 2.5 тысячи файлов;
-
при этом 7000 файлов мы заигнорировали – это все файлы xml, html, zip, png и прочие файлы, которые лежат в исходниках конфигурации.
Я рекомендую в обязательном порядке отключать анализ xml, потому что на xml-файлы вы получите триллионы замечаний, которые вам не нужны, потому что вы xml-файлы все равно редактировать не будете. Я рекомендую ограничиваться только bsl и теми файлами, в которых вы реально пишете код – например, os для OneScript.
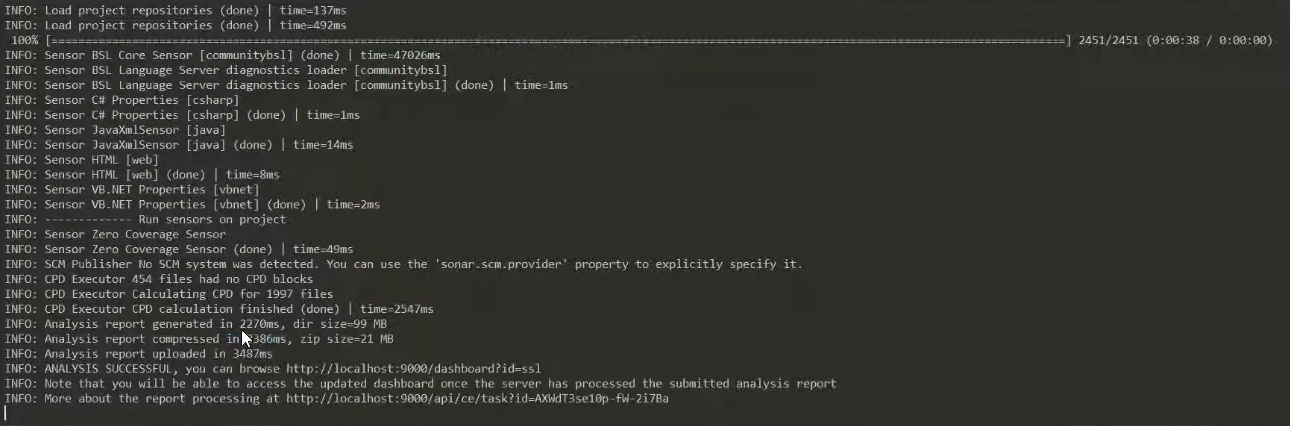
Наш анализ на клиентской стороне завершился – у нас появилась ссылка, по которой мы можем увидеть результаты проверки проекта, а также ссылка для опроса по API результатов текущего анализа.
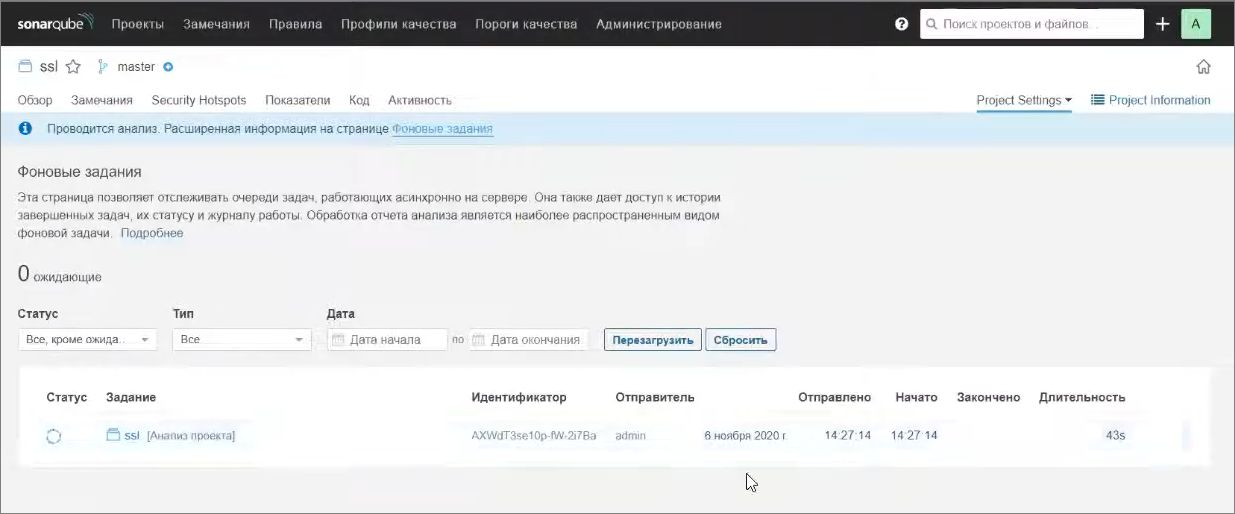
Что это значит? Когда мы проанализировали исходники, мы изначально ожидаем, что, когда мы открываем проект, здесь сразу будет информация об обнаруженных проблемах. Но это не так, потому что мы выполнили только клиентскую часть анализа. После того, как sonar-scanner на клиенте проанализировал наш исходный код, он отправляет его на сервер, где сервер уже разбирает эти результаты анализа, складывает их в СУБД и строит индексы полнотекстового поиска в Elasticsearch. У вас может быть сервер на одной машине, sonar-scanner на другой машине - они работают независимо. Причем, нагрузка обычно больше будет на ту машину, на которой находится sonar-scanner – эта утилита более требовательна к ЦПУ, активнее читает диск и т.д. А на сервере все может быть полегче.
Через какое-то время все это закончит анализироваться, и мы сможем посмотреть результаты.
Ошибка с нехваткой свободного места

Пока у нас анализируется, я сделаю хитрую настройку, которая позволит мне показать вам ошибку с недостатком свободного места. Эта настройка позволит мне создать файл размером 300Гб.

Сейчас я забил свободное место на диске практически под ноль.
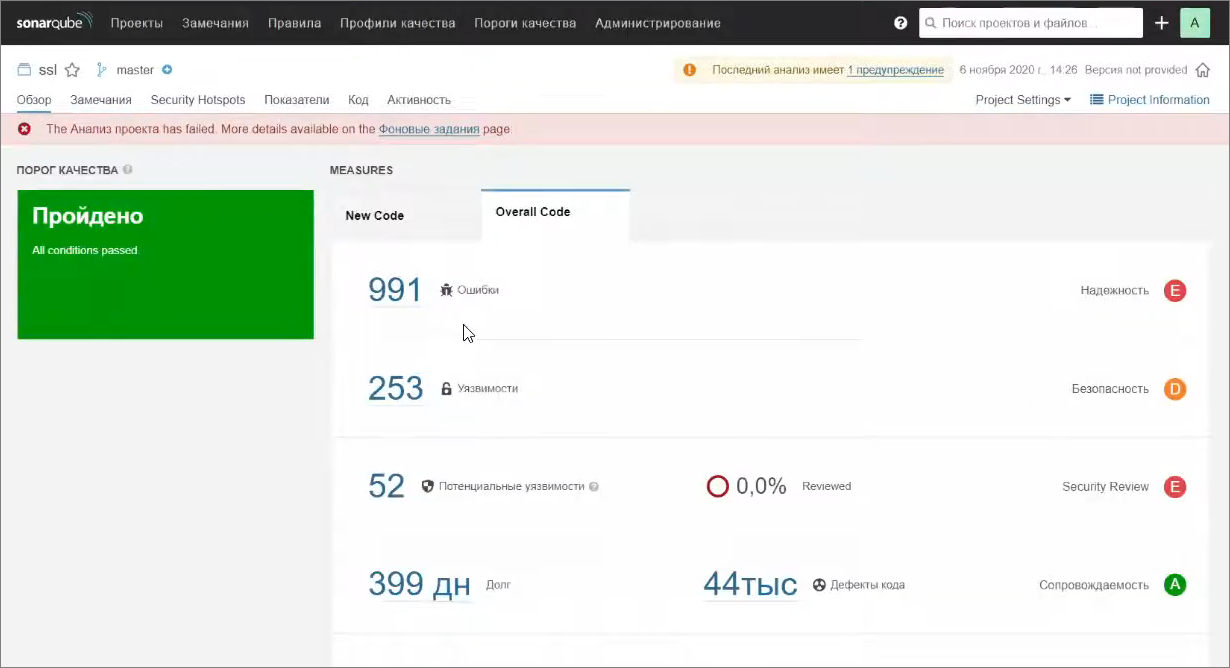
Что получилось – SonarQube у нас вроде бы работает, с ним все хорошо, анализ нашего проекта завершился, мы видим какое-то количество метрик, но у нас есть информация, что «Анализ проекта has failed» и дополнительная информация доступна на странице фоновых заданий.
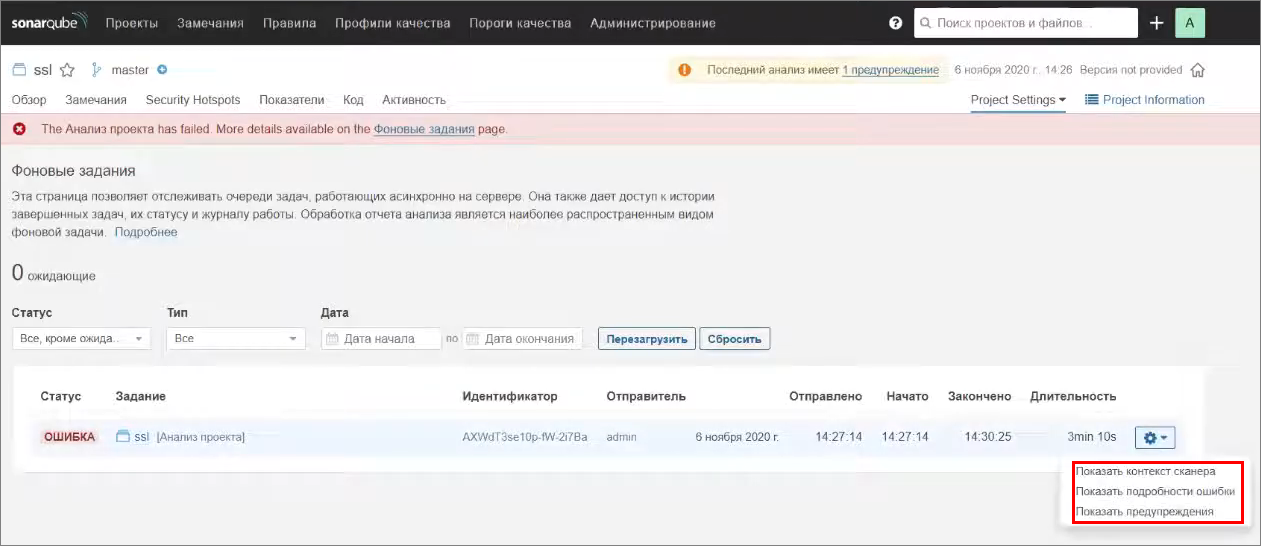
А здесь мы видим, что это фоновое задание обработки результатов нашего проекта завершилось с ошибкой.
Что же произошло? Если мы нажмем на «шестеренку», мы можем увидеть различную дополнительную текстовую информацию.
Контекст сканера говорит нам о том, какие плагины были установлены, какие настройки использовались для анализа, на какой сервер мы это отправляли – но все это мы и так знаем.
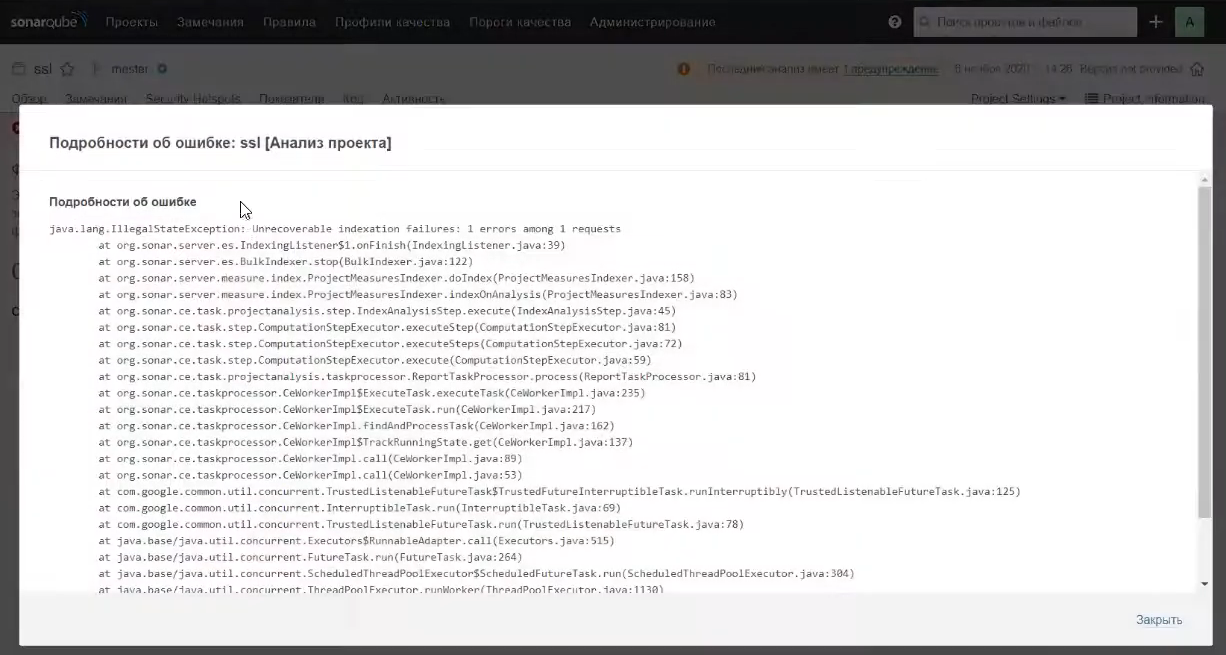
Самое интересное – это «Показать подробности ошибки». Здесь мы видим, что из компонента Elasticsearch нам пришло исключение, в котором написано Unrecoverable indexation: 1 errors among 1 request.
Поскольку мы видим, что исключение пришло из компоненты es, следовательно, стоит заглянуть в лог Elasticsearch.
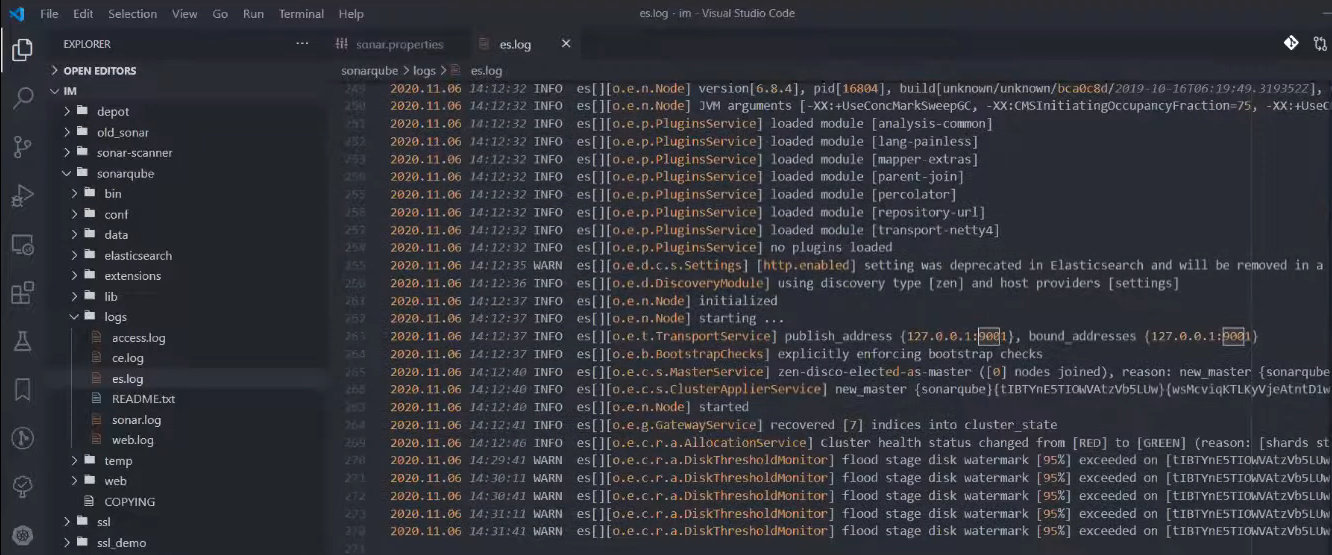
Открываем файл лога Elasticsearch, прокручиваем результаты вниз и видим, что у нас появились какие-то дополнительные непонятные ворнинги – явно что-то пошло не так. SonarQube говорит нам о том, что на нашем диске, на котором расположен Elasticsearch, занято более чем на 95%. Т.е. осталось мало свободного места.
В более старых версиях SonarQube это приводило к интересным моментам, когда Elasticsearch понимал, что на текущем узле осталось мало места, значит, нужно переехать на другой. Но в кластере по умолчанию есть только один узел, поэтому он переезжал сам на себя и в итоге уходил в бесконечный цикл – видел, что места нет и начинал переезд дальше.
Как это исправить? Никак, кроме как освободив свободное место. Если у вас осталось меньше 20 Гб (для моего диска), то у вас будут проблемы с использованием SonarQube, вам нужно будет либо его куда-то уносить на виртуальный диск с более безопасным распределением свободного места, либо просто чистить.
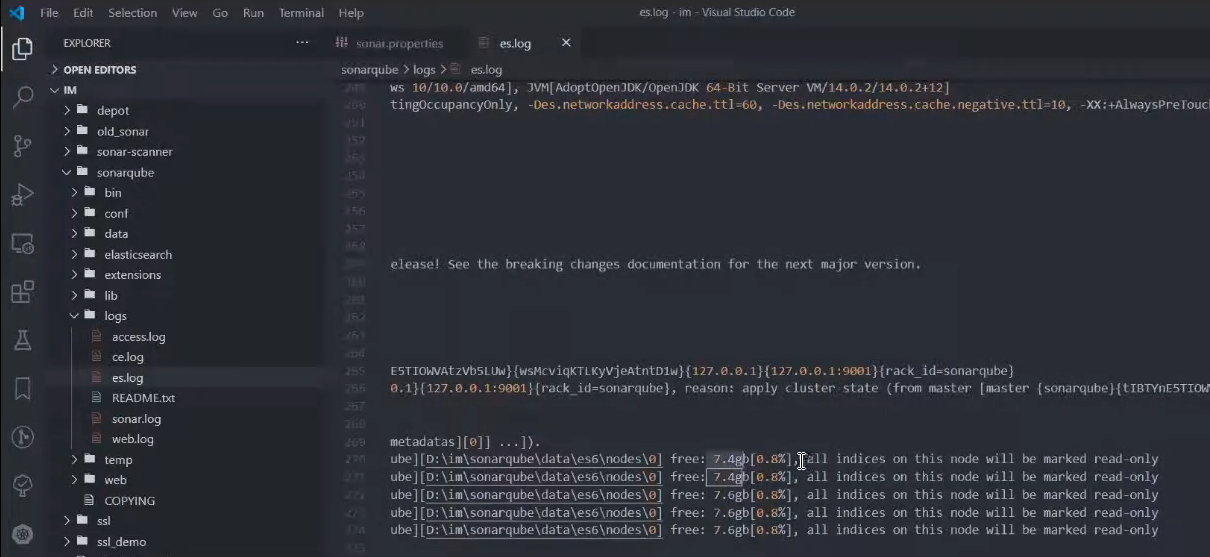
В частности, здесь написана информация о том, что все индексы Elasticsearch на этом узле помечены как readonly – вы не сможете что-либо менять в текущем инстансе Elasticsearch.
У вас будет падать весь анализ, который у вас происходит в системе.

После удаления файла на 300Гб наш анализ должен завершиться успешно – я его сейчас еще раз запущу, но частично мы уже сможем исследовать сам веб-интерфейс, потому что часть данных все-таки успела сохраниться.
Что у нас есть на дашборде SonarQube

На закладке Overall Code у нас есть информация о том, что происходит в целом по коду. Видно, что у нас есть 991 ошибка, 253 уязвимости (на самом деле, уязвимостей там нет, это очень спорные моменты, в основном ошибки типа False Positive).
И есть 44 тысячи дефектов кода – это либо нарушения стандартов разработки 1С, либо нарушения каких-то правил, заложенных BSL LS. Суммарно технического долга по дефектам кода набралось почти на 400 дней.

Также есть информация о том, сколько в нашем проекте процентов копипаста (дублирования кода). И сколько участков с копипастом.
На каждый показатель можно нажать и «провалиться».
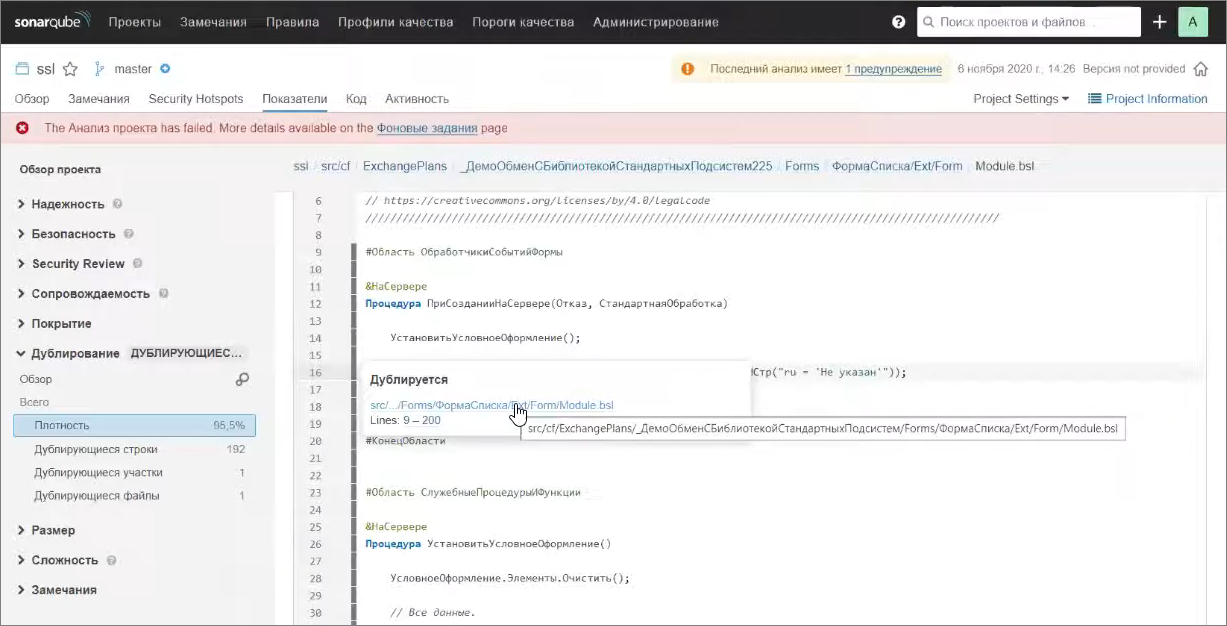
Я провалился на дублирующиеся участки, и можно увидеть, что, например, информация из плана обмена _ДемоОбменСБиблиотекойСтандартныхПодсистем с 9 по 200 строку дублируется с информацией из другого плана обмена.

Если мы перейдем туда, мы увидим тот же самый кусок кода, который будет указывать на соответствующее дублирование.
Как диагностируются дубликаты? К сожалению, сейчас это происходит «втупую» – исходный код разделяется на токены – неделимые лексемы (идентификаторы, операторы, знаки пунктуации и т.д.), все это «скармливается» особому компоненту системы (он нам не подконтролен), который эти токены загружает в какую-то «молотилку».
Там есть определенные пороги – по умолчанию он считает, что если есть 70 токенов в блоке минимум 10 строк, которые повторяются в другом участке кода, значит, это дублирование кода. Такой участок помечается как дубликат.
К сожалению, реальность 1С нас очень часто сталкивает с такими ситуациями – в процедурах «ПриСозданииНаСервере» часто происходит подключение дополнительных подсистем – версионирования, управления доступом, контактной информации. Все эти обработчики попадут в дубликаты – и да, это грустно.
Мы можем попробовать что-то с этим сделать на стороне плагина, но это, к сожалению, не так просто. А у пользователя сейчас на это повлиять возможности нет вообще, кроме как увеличить порог, на котором сработает копипаст (но его можно случайно выкрутить до такого состояния, что вам анализ в итоге ничего не покажет).
Грубо говоря, анализ дублирования сейчас производится по тексту. Нашел кусок текста, который совпадает, значит, это копипаст.
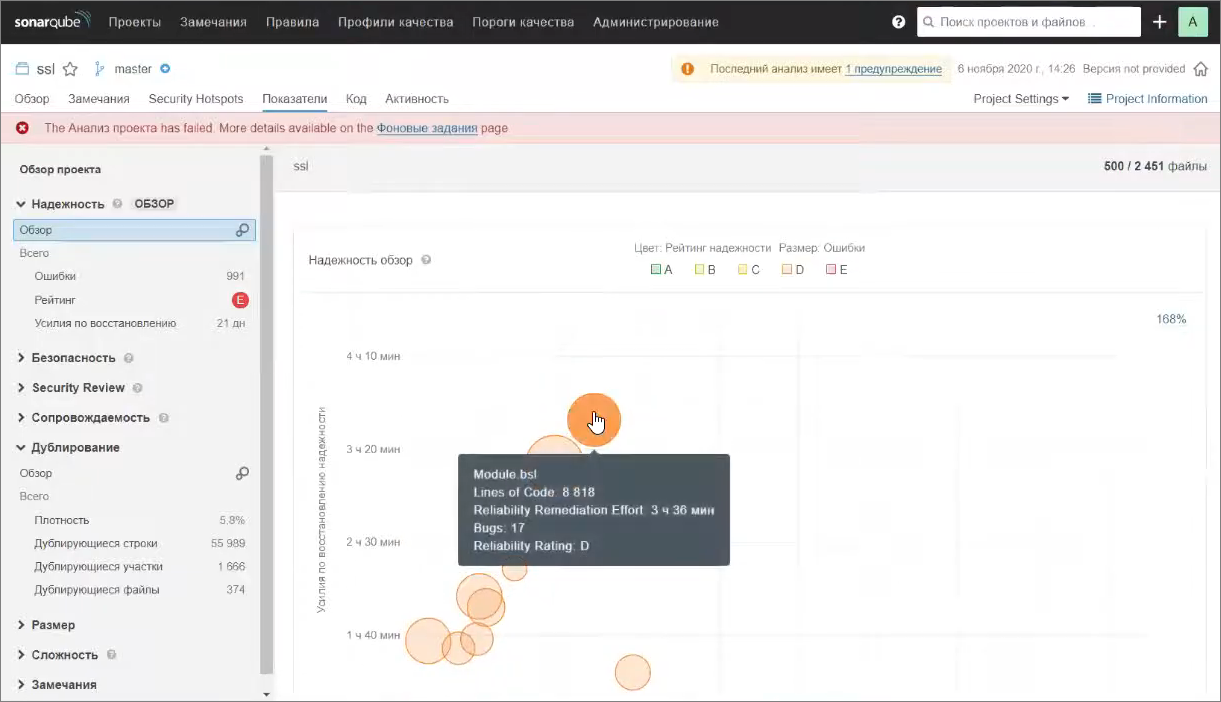
На закладке «Показатели» есть довольно много информации о нашем проекте. Конечно, покрытия у нас никакого нет, но можно посмотреть распределение ошибок по каким-то модулям – так называемая bubble-диаграмма.
Например, можно увидеть, что в каком-то модуле (на него можно кликнуть и перейти) 8 тысяч строк кода и 17 ошибок – это проблема.
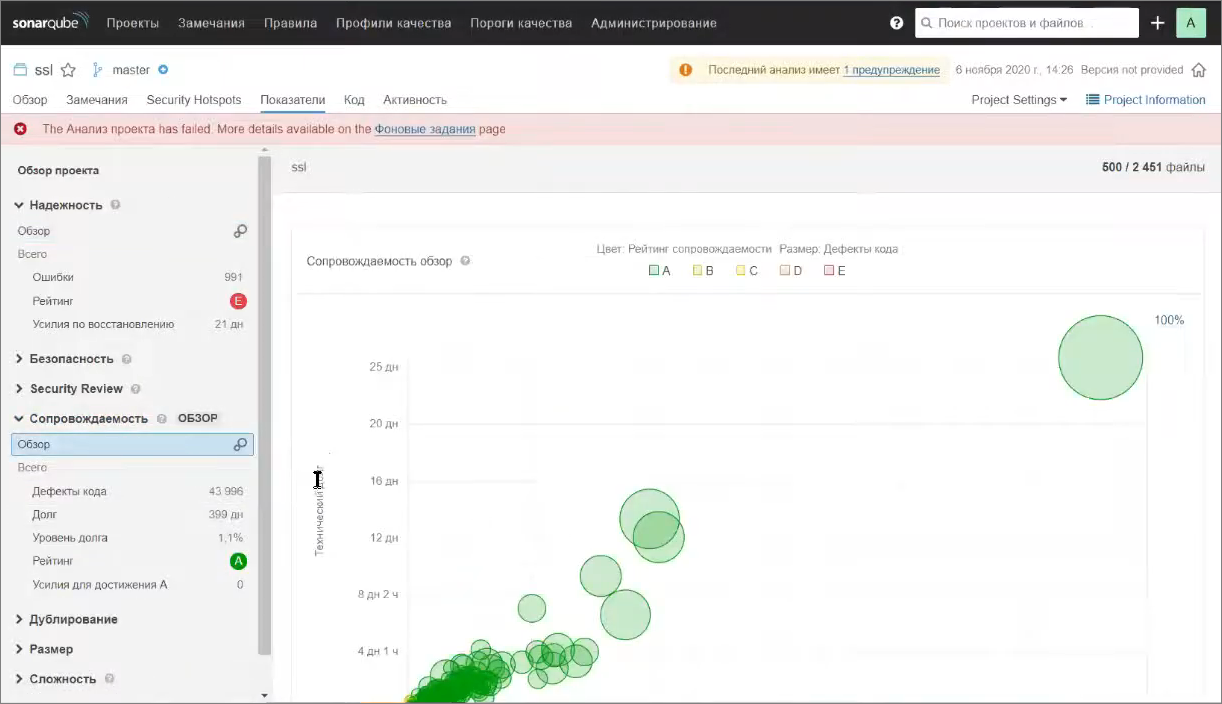
Такая же информация есть по нарушению стандартов кодирования – по дефектам кода.

Можно походить по папкам, пооткрывать какие-то файлы и увидеть эти нарушения.

Здесь есть дополнительная информация по размеру:
-
количество строк кода – у нас текущая версия БСП содержит 608 тысяч строк кода
-
количество строк всего – 966 тысяч строк;
-
количество функций;
-
количество файлов;
-
количество строк комментариев;
-
плотность (%) комментариев.
И есть два показателя – цикломатическая и когнитивная сложность:
-
цикломатическая сложность показывает, насколько сильно код ветвится и сколько нам потребуется тестов, чтобы его полностью протестировать – нужно написать 137 тысяч юнит тестов;
-
когнитивная сложность показывает сложность восприятия – я чуть позже покажу, как такие замечания выглядят в коде.
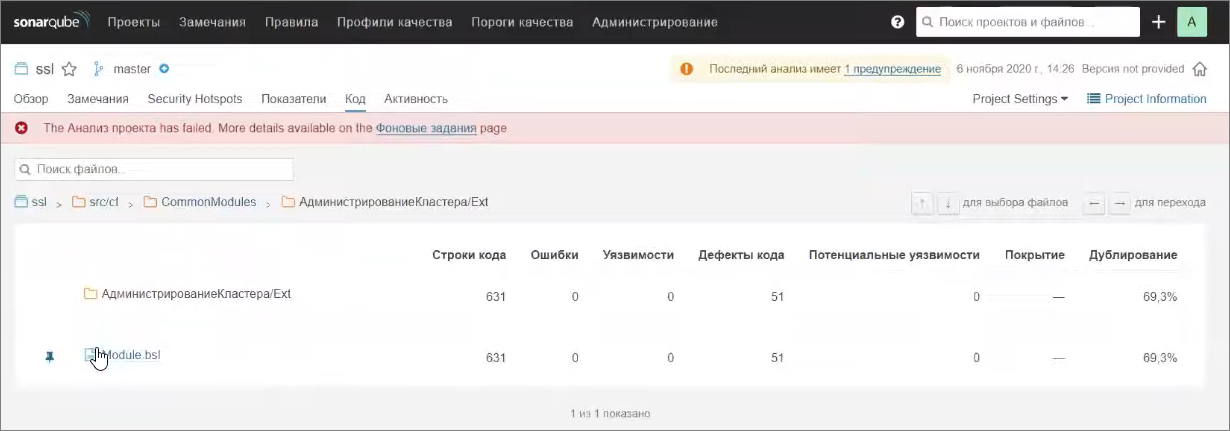
Давайте откроем какой-нибудь общий модуль – например, «АдминистрированиеКластера». Здесь 631 строка кода и в них – 51 дефект.
Код отображается с подсветкой ключевых слов, в последней версии плагина в том числе с подсветкой запросов.
Какие настройки нужно сделать для выключения файлов на поддержке
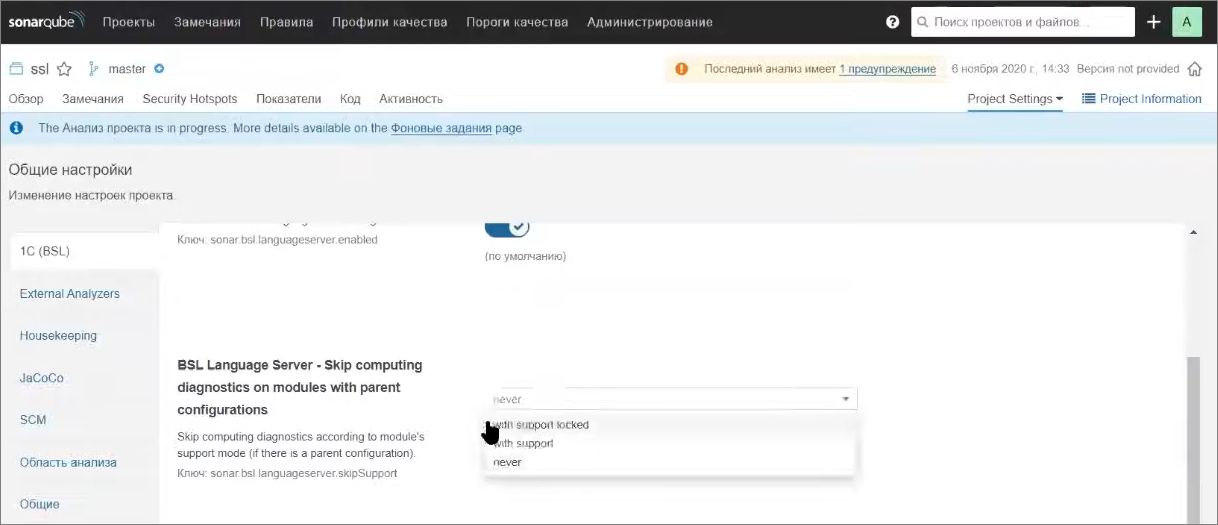
В настройках проекта (Project Settings) либо в настройках сервера в целом есть подраздел для 1С.
Здесь есть свойство «Skip computing diagnostics on modules with parent configurations», которое отвечает за то, какой статус замочков на файлах (либо это «желтый куб с замком», либо это просто «желтый куб») будет исключаться из анализа:
-
по умолчанию указано значение «never» – т.е. мы никакие файлы из анализа не исключаем;
-
а если вы в разработке придерживаетесь правила, что все объекты поставщика должны быть на замках, то вы можете поставить настройку «with support locked» («замок на желтом кубе») и тогда у вас файлы исключатся из анализа. Они будут выгружаться на сервер, по ним будут считаться метрики, но замечания по ним диагностироваться не будут;
-
если же у вас бОльшая часть объектов «снята с замков» (или вся конфигурация «снята с замков»), но вы эти модули не дорабатываете, вы можете переключить значение на «with support» (все файлы на поддержке будут считаться данными от поставщика и тоже будут исключаться).
Мы сейчас в настройках поддержки включим возможность изменения БСП, но остальную конфигурацию оставим «на замках», поэтому я ставлю значение «with support locked».

Итак, снимем замок для ряда БСП-шных общих модулей.
После этого нам нужно повторно выгрузить конфигурацию в файлы – поверх нашего текущего каталога. Вместе с файлами в каталог Ext выгрузится файл ParentConfiguration.bin, в котором находятся настройки поддержки.
Это – огромный скобочный файл, эта комбинация нулей и единичек как раз означает настройки поддержки. Анализатор читает эти настройки и на их основании как раз понимает, какие файлы нужно исключать из поддержки или нет.
Если вы используете анализ в исходниках Git, не кладите файл ParentConfiguration.bin в .gitignore. Если вам страшно, что он большой, положите его под git lfs. Но если он у вас будет заигнорирован, информацию о замках рассчитать не получится, и все файлы будут лететь в анализ.
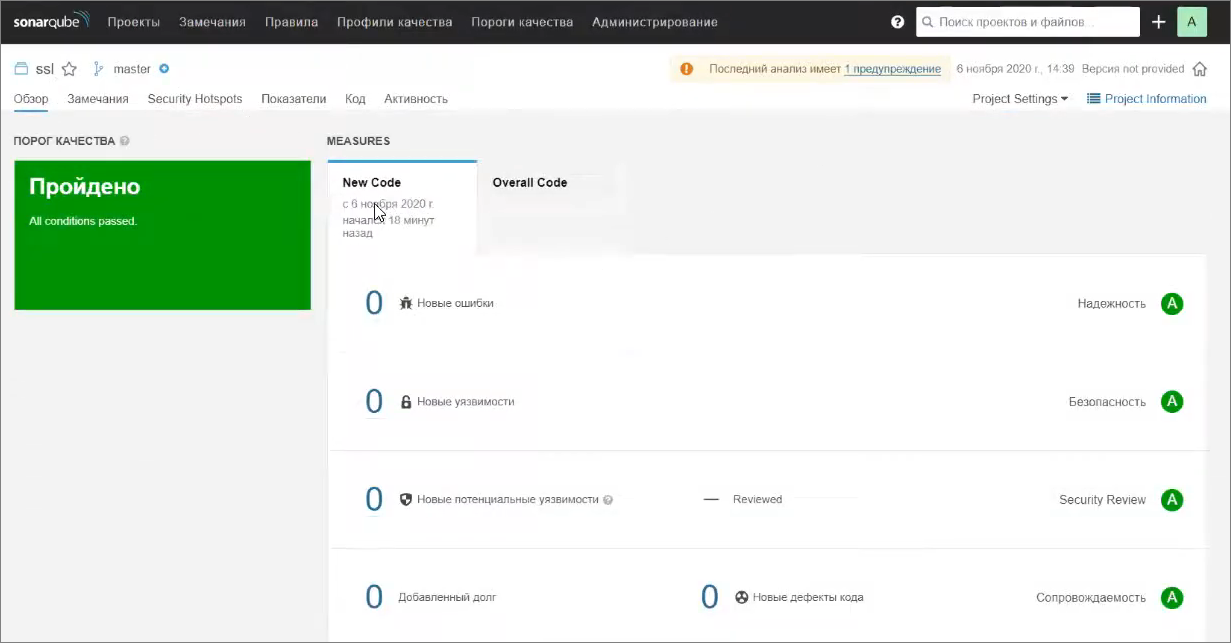
Итак, у нас завершился второй анализ. Мы можем увидеть вкладку New Code, которая нам говорит о том, что никакого нового кода и никаких привнесенных ошибок нет – это логично, потому что мы ничего не меняли.

Данные целиком по конфигурации все так же есть на Overall Code.
Замечания по коду
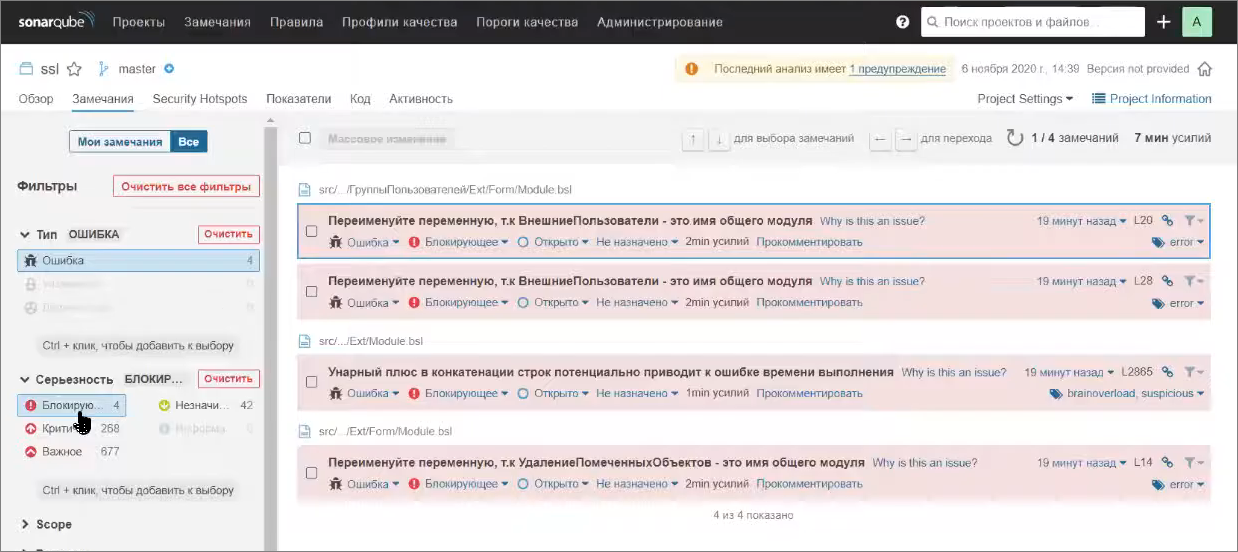
И мы, наконец-то, можем перейти на закладку «Замечания» и посмотреть, какие тут есть интересные штуки.
Во-первых, обратите внимание на фильтры – мы можем посмотреть только ошибки, например, со статусом «Блокирующие» – это наиболее важные ошибки, которые должны останавливать конфигурацию от наката на прод, потому что здесь явно что-то очень-очень плохо.
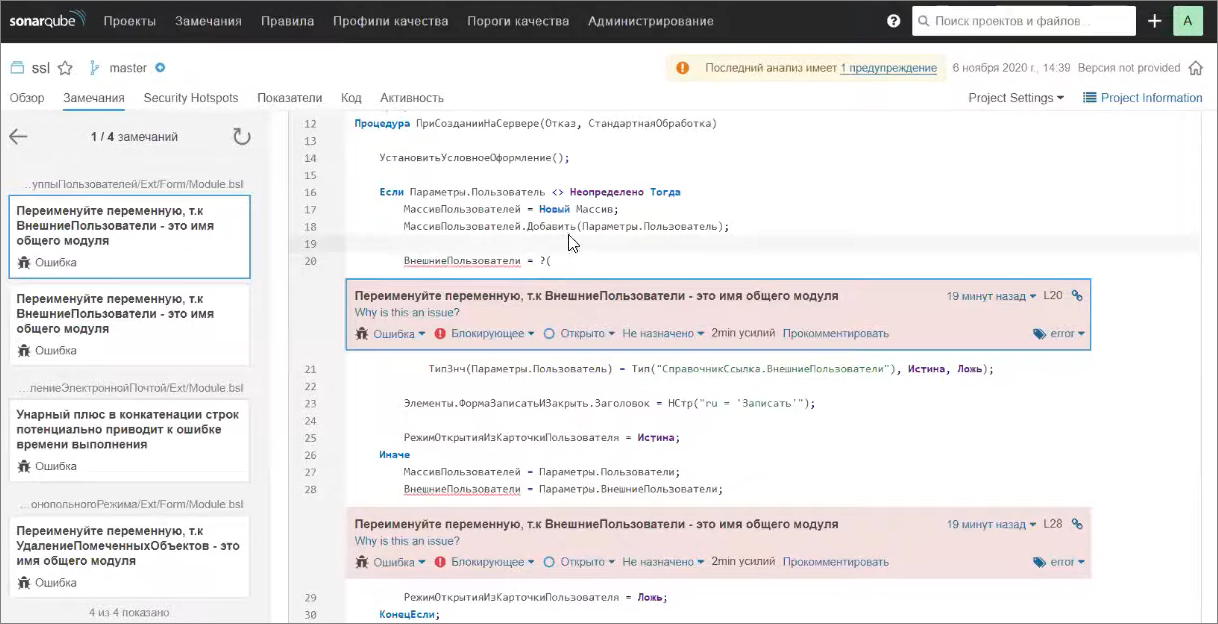
В частности, здесь будут показаны ошибки о том, что вы назвали переменную так же, как и имеющийся общий модуль.
Если в контексте, в котором вы работаете, этот общий модуль будет доступен (серверный общий модуль), у вас в рантайме вывалится ошибка присвоения значению недопустимого типа.
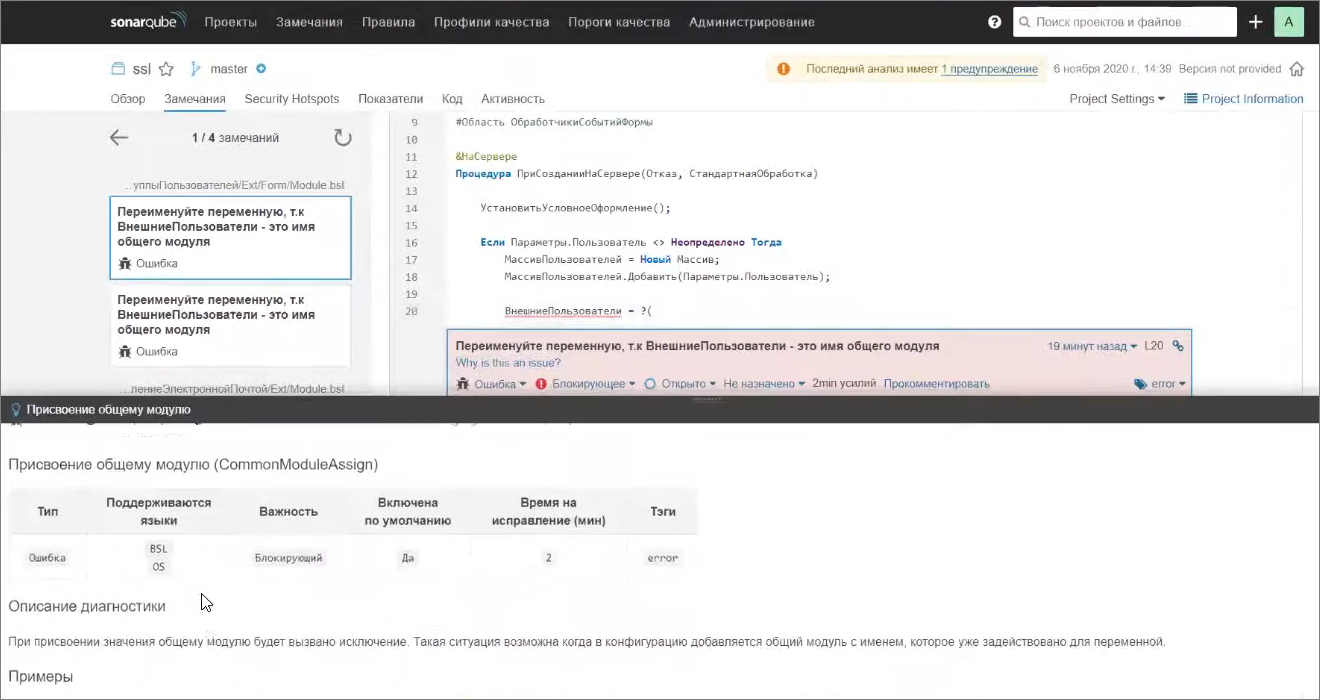
Вы можете нажать на гиперссылку «Why is this an issue?» и увидеть описание этой диагностики.
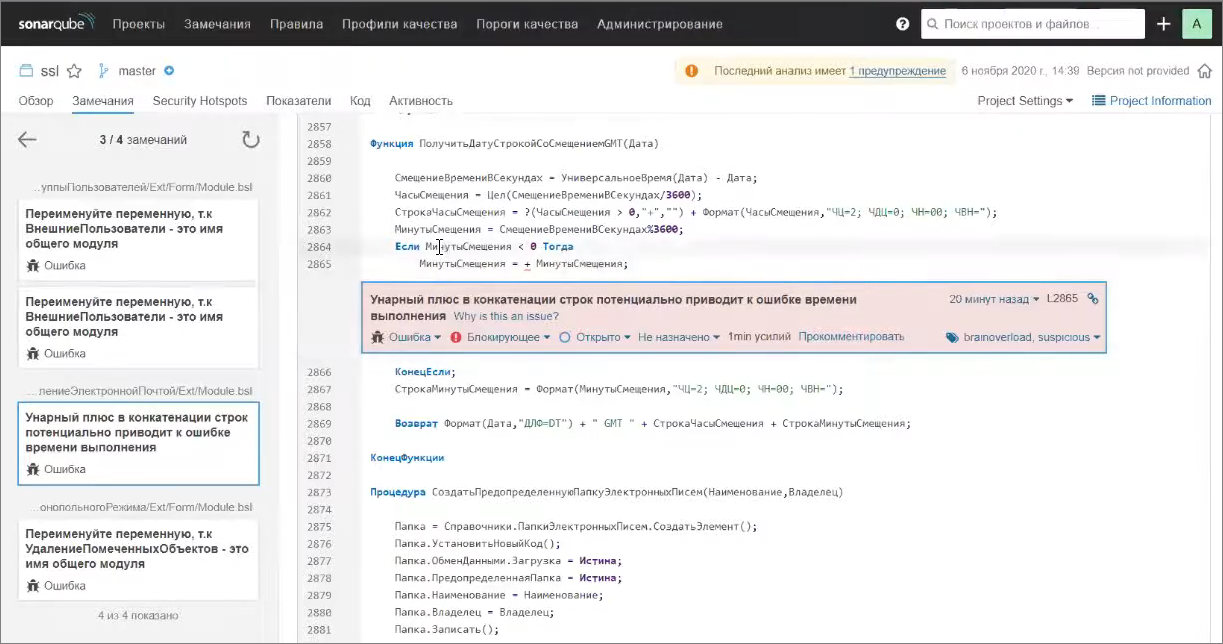
Еще есть интересная ошибка из разряда блокирующих. Тут это так называемый False Positive, потому что тут нет никакого унарного плюса в конкатенации строки, потому что очевидно, что минуты смещения – это будет число. Но просмотр этой ошибки наталкивает на мысль, что тут что-то не так. Если мы посмотрим на код, мы можем догадаться, что имел в виду автор. Если минуты смещения – это отрицательное число, то нужно инвертировать это значение, чтобы получить положительное. Но вместо минус МинутыСмещения, автор написал +МинутыСмещения.
То есть, код, грубо говоря, не делает совсем ничего.
И несмотря на то, что сама ошибка не совсем точно сработала и смысл в ней был не тот, это натолкнуло нас на другую ошибку – уже логическую, которую мы можем из SonarQube почерпнуть.
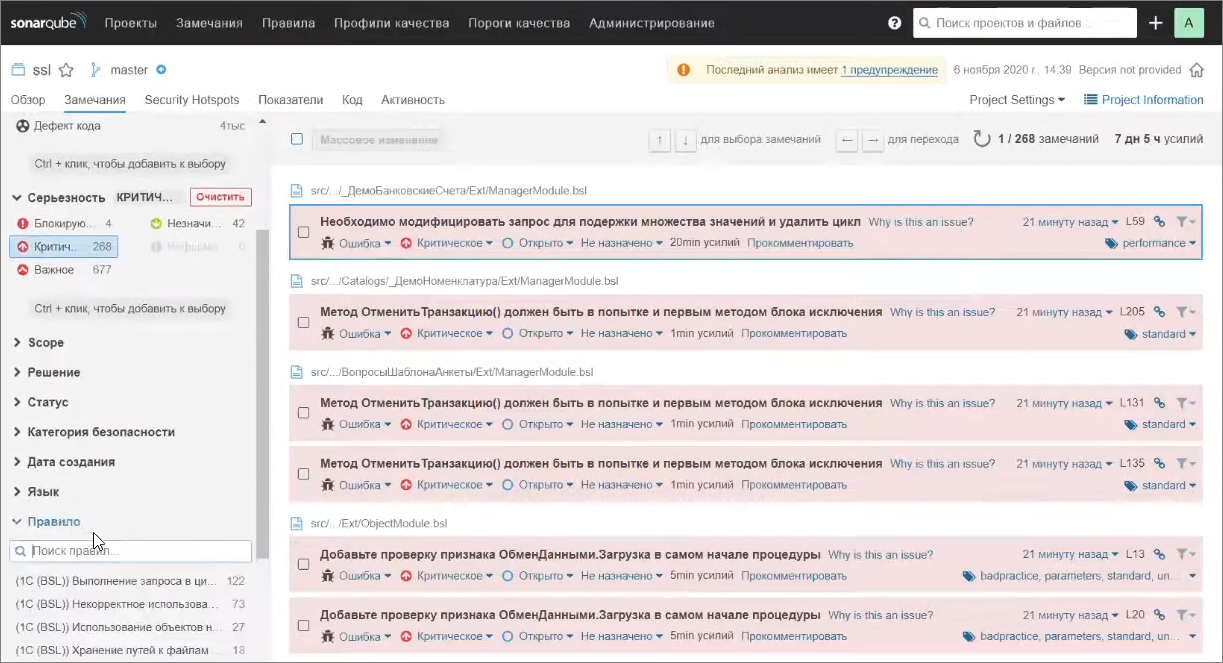
Что еще есть интересного?
В критических замечаниях меня больше всего радует запрос в цикле.
Здесь можно отфильтроваться по конкретному правилу и увидеть все, что мы любим.

Например, «Для каждого… Запрос.Выполнить().Выгрузить()[0].Значение»
Да, в какие-то моменты это допустимо – есть алгоритмы, которые очень трудоемко написать по-другому либо вообще невозможно из-за ряда технических ограничений. Но в большинстве случаев, если вы видите такую ошибку, то вы знаете, что разработчику нужно что-то с этим сделать.
Я не анализировал детально код БСП, но по большей части просмотренных срабатываний мне показалось, что такое применение допустимо, потому что это либо маленькая выборка, либо действительно по-другому код написать очень сложно.
Можете пощелкать по замечаниям, увидеть, как у нас меняется позиционирование в файлике.

Еще из интересного – проверки, которые касаются транзакций:
-
парность транзакций – НачатьТранзакцию / ЗафиксироватьТранзакцию;
-
неправильность расположения кода перед Попыткой и после Попытки.
В данном конкретном случае то, что ЗафиксироватьТранзакцию находится не перед Исключением, не приведет к проблеме (это «всего лишь» нарушение стандарта по работе с транзакциями), но, тем не менее, любое неосторожное движение, и с этим кодом может быть что-то не так:
-
например, если мы пропустим «Продолжить», то можем случайно два раза зафиксировать транзакцию (это по поводу нарушения парности вызова);
-
также может быть еще проблема с тем, что у нас «НачатьТранзакцию» идет до начала Попытки, и какой-то код, который попадет в транзакцию, у нас «вывалится» прямо между этими двумя строками и не откатится, потому что у нас не используется «ОтменитьТранзакцию».
Я из своего опыта очень много проблем в этим выловил с прода, и SonarQube мне в этом плане очень помог.
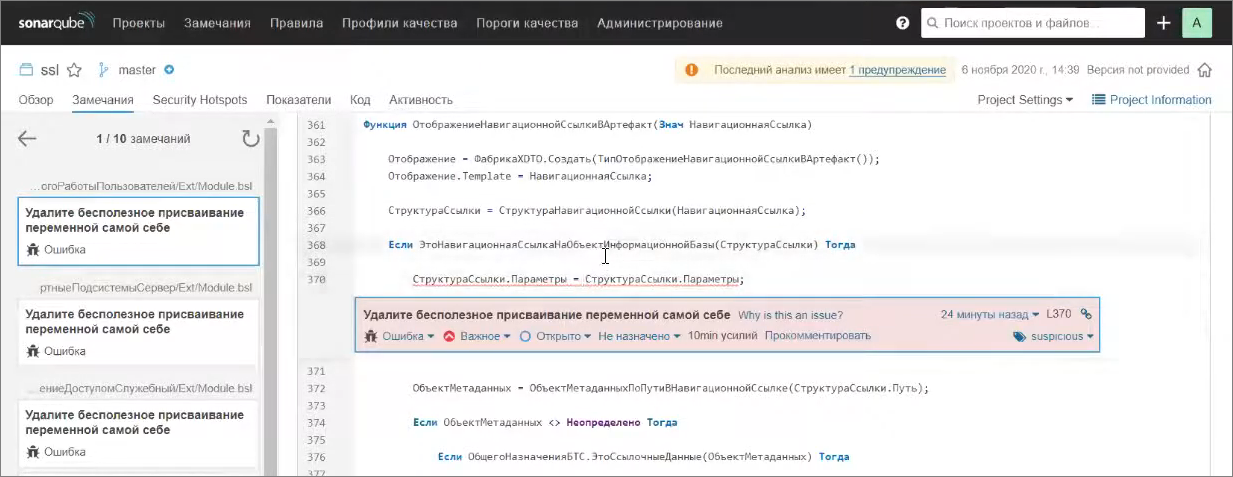
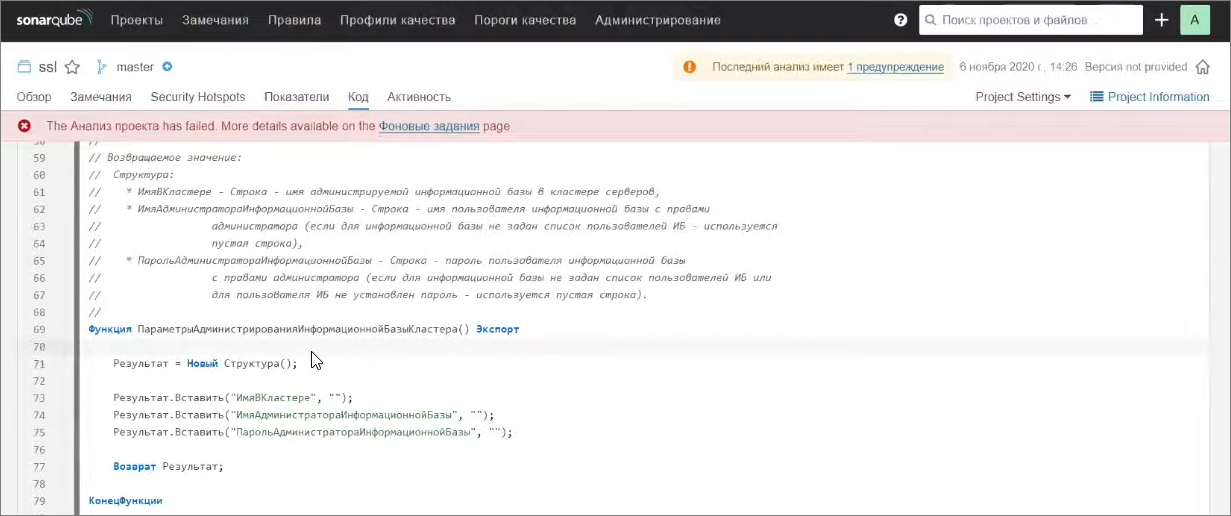
Еще можно посмотреть присвоение переменной самой себе – ошибка не особо страшная, но ее обнаружение позволяет устранить некоторые трудноуловимые баги.

Я обратил внимание, что в БСП много таких конструкций, когда идет присваивание переменной самой себе, после которого выводится комментарий с типом этого значения. Видимо, либо EDT, либо какие-то внутренние инструменты, которые используются в БСП, позволяют дополнительно типизировать таким образом – как в Снегопате типизирующие комментарии через двоеточие. Внутри БСП тоже что-то похожее используется – это очень наглядно таким образом отлавливается.
Работа с Git
Я вчера заранее уже закоммитил проект БСП в git с выключенной поставкой. Заранее – потому что первый коммит исходников в Git выполняется очень долго, я ждал минут 15, пока это закоммитится.
В репозитории есть файл .gitignore, в котором указан каталог .scannerwork.
Сам коммит не составляет никакой сложности:
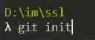
Открываете терминал, переходите в каталог и, чтобы проинициализировать репозиторий, выполняете команду:
git init
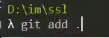
Потом, чтобы все добавить в индекс гита, пишете:
git add .
(внимание – точка обязательна!). Ждете какое-то количество времени.
И потом делаете коммит:
git commit -m ”Тут пишете комментарий”
Все дополнительные настройки Git мы оставим за рамками мастер-класса.
Итак, сейчас у нас в git уже есть некий проект ssl_demo.
Чтобы просто выгрузить все эти исходники в git и получить в SonarQube замечания, которые назначены на каких-то конкретных людей, нужно выполнить две вещи – во-первых, у каждого пользователя должна быть задана его почта.

К сожалению, почта заполняется только администратором сервера в настройках администрирования на вкладке «Безопасность» – «Пользователи».
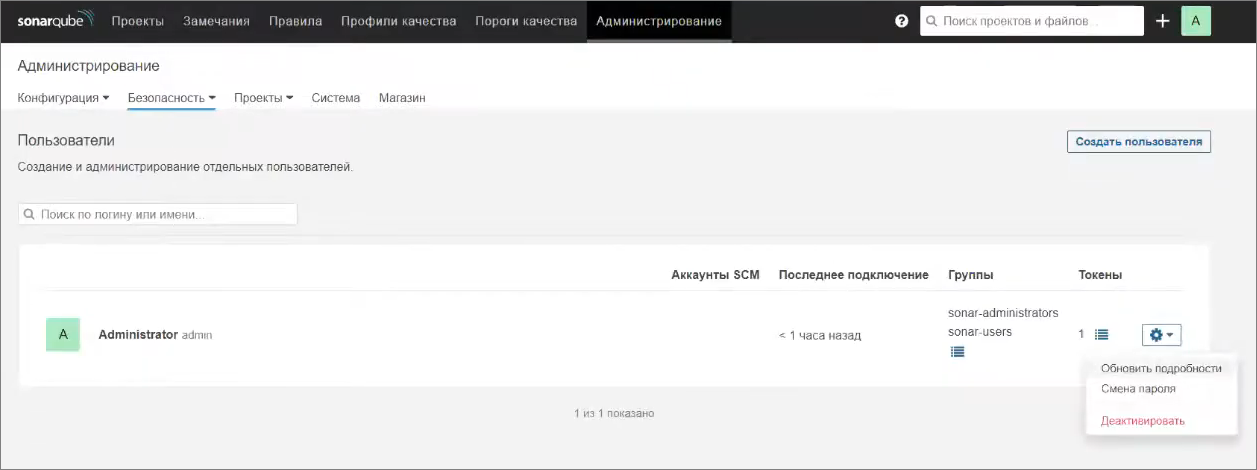
Находите нужного вам пользователя и нажимаете на «шестеренку» – «Обновить подробности».

Здесь указываете, какая у него электронная почта используется для анализа – почта, из-под которой этот пользователь коммитил.
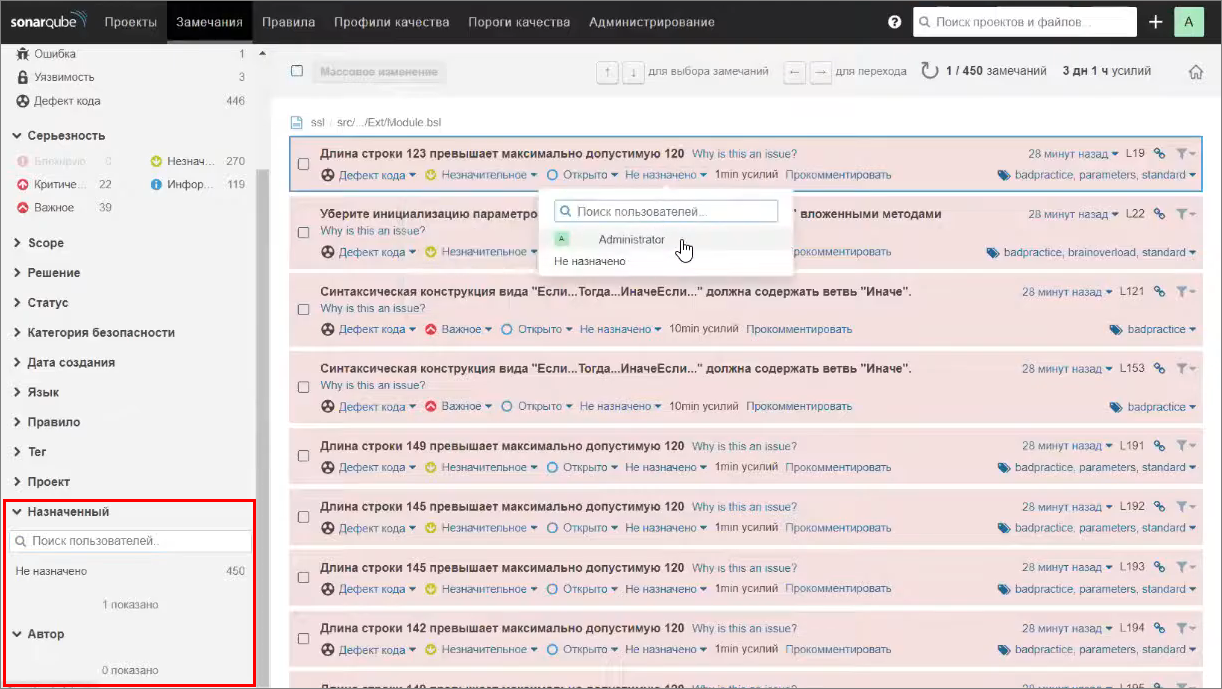
После этого строки кода, в которых были обнаружены замечания и в которых SonarQube по истории Git’а поймет, что эти строки менялись вами, автоматически «повесятся» на вас. Причем, они «повесятся» двумя разными способами – в замечаниях есть:
-
Автор (это информация о почте) – я пока запускал sonar-scanner из каталога без репозитория Git, поэтому у меня здесь пусто.
-
Назначенный – это грубо говоря, исполнитель, который будет менять какое-то конкретное замечание.
Вы любое замечание можете назначить на любого исполнителя.
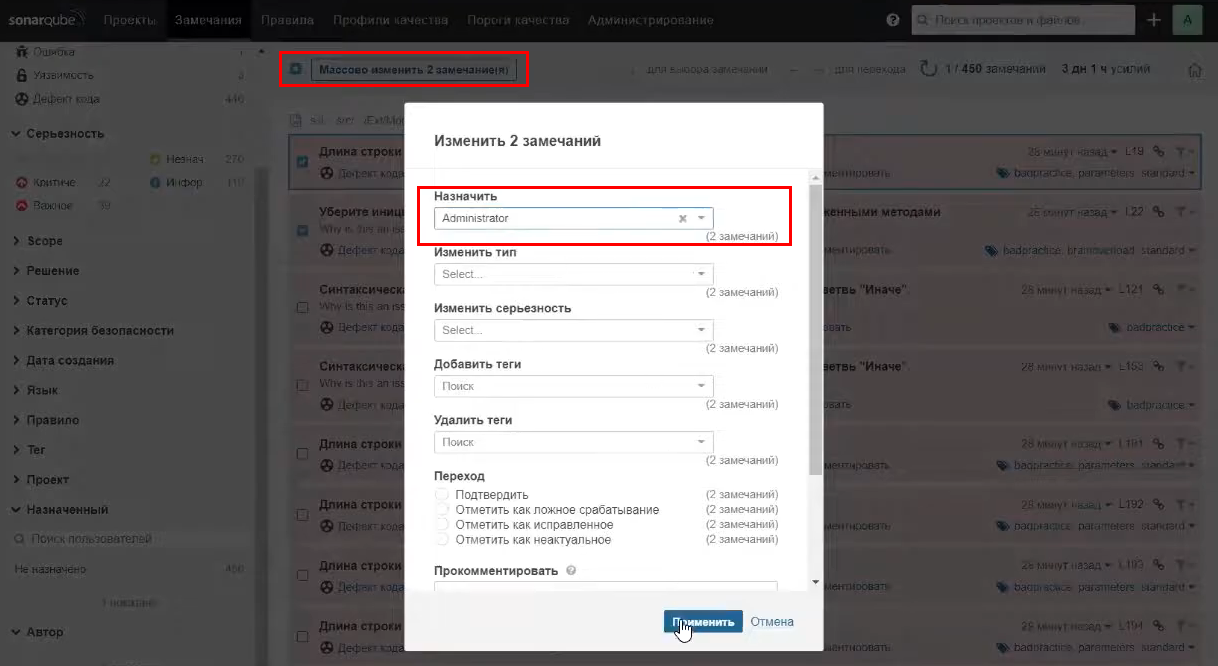
Вы можете массово «перевесить» все эти замечания на какого-то конкретного человека.
Либо назначенный будет подставляться автоматически по соответствию почты в Git и настройках пользователя.
Результат исключения файлов на поддержке
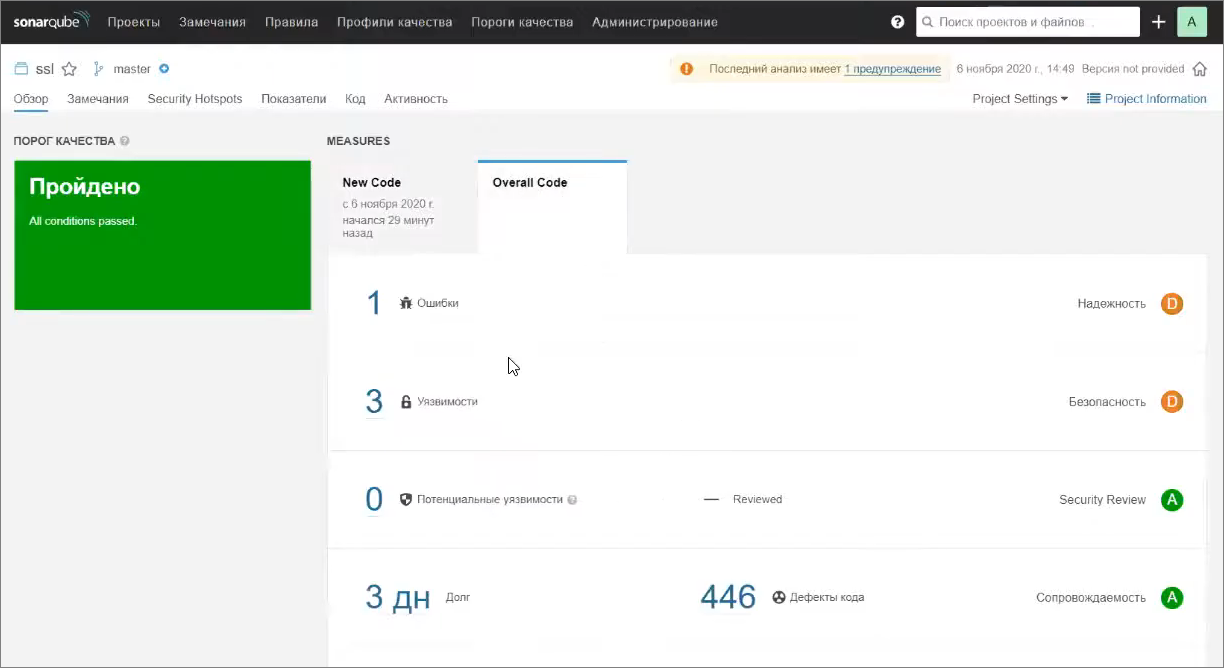
Хочу обратить внимание, что после запуска с исключением файлов на поддержке в нашей конфигурации стало заметно меньше «плохокода», потому что мы в настройках поддержки конфигурации включили возможность изменения и сняли «замочек» только с части модулей, а в настройках проекта указали «with support locked».
У нас теперь показывается только код по нашему изменённому модулю.
Работа с Gitsync
По Git – я этот проект удалю, потому что SonarQube не умеет переназначать замечания, если ему «приехала» информация о Git.

Но мы сейчас точно так же запустим sonar-scanner, и через какое-то время проект появится снова.
Пока идет анализ, чтобы я мог показать вам, что там, расскажу про gitsync.
Gitsync – это приложение, которое написано на OneScript.
OneScript – это виртуальная машина для выполнения кода 1С. Кто еще не знает, перейдите на сайт oscript.io. Здесь можно почитать, что это такое, почитать документацию, скачать.
Также установить OneScript можно с помощью OneScript Version Manager.

Сам Gitsync ставится очень просто через пакетный менеджер opm, который входит в состав OneScript по команде (Важно: в cmd, запущенном с правами Администратора Windows, если вы устанавливали OneScript через msi-инсталлятор, а не через OVM):
opm install gitsync
Opm скачает, распакует и установит gitsync.
После первой установки gitsync вам обязательно нужно проинициализировать плагины – о том, какие у gitsync есть плагины, можно прочитать в документации, плюс часть плагинов я сейчас покажу.
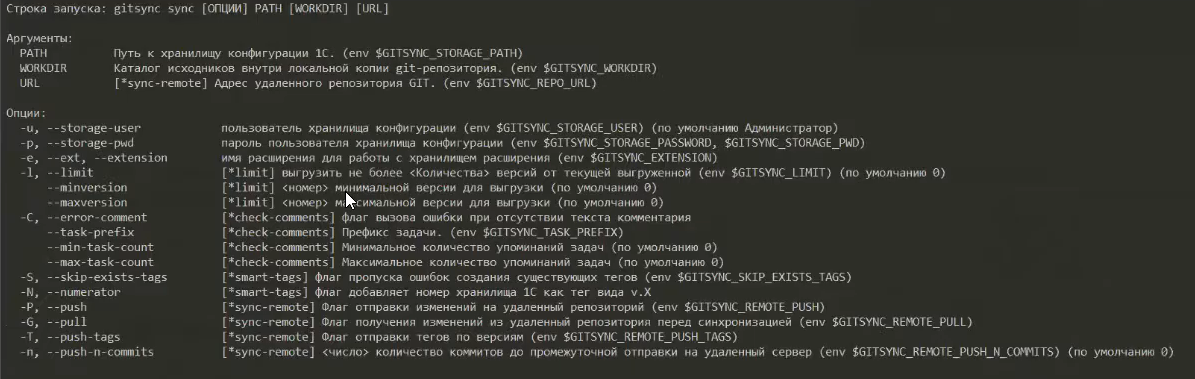
Чтобы выполнить саму синхронизацию, нам нужно будет использовать команду sync.
Чтобы посмотреть по ней справку и понять, как с ней работать, можно набрать
gitsync sync help
Как видите, здесь используется типичная командная строка для запуска с опциями, после которых нам нужно передать путь к хранилищу конфигурации.
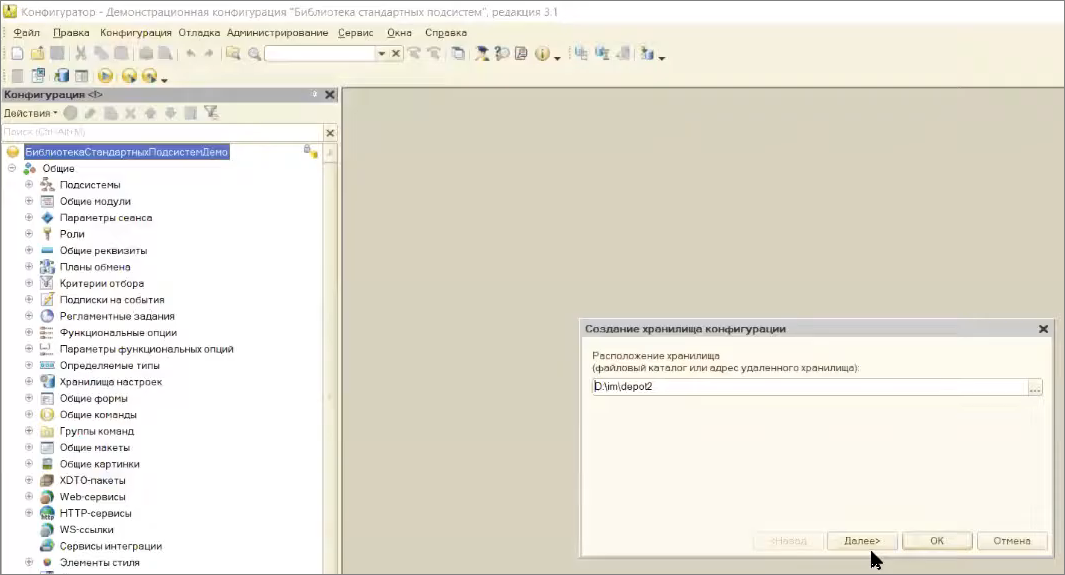
Давайте я создам новое хранилище, чтобы с версиями все было хорошо.
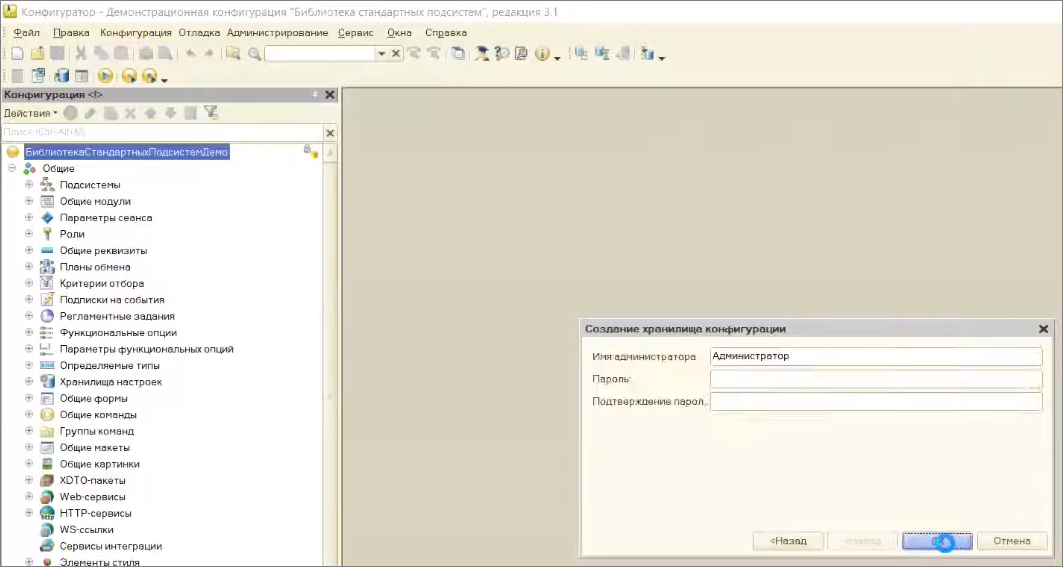
И под Администратором без пароля всю конфигурацию в хранилище выгрузим.
Также у Gitsync есть различные плагины, которые позволят нам немного кастомизировать синхронизацию.

Если выполнить
gitsync plugins ls -a
то мы можем увидеть список плагинов. По умолчанию, все плагины отключены, поэтому вам для дальнейшей работы их нужно будет настроить.
Плагин increment позволяет нам включить инкрементальную выгрузку. Активируем его командой:
gitsync plugins enable increment
Плагин check-authors заставляет Gitsync выдавать ошибку и не запускать разбор версии хранилища, если в настройке AUTHORS у нас не указан соответствующий email для автора версии. Включим его тоже:
gitsync plugins enable check-authors
Плагин check-comments – также останавливает разбор версии хранилища, если при помещении в хранилище не хватает комментариев.
gitsync plugins enable check-comments

Сама строка запуска будет выглядеть примерно так:
gitsync sync -u Администратор -C ..\depot2 src/cf
-
-u – это флаг для указания пользователя;
-
-C – это флаг от плагина check-comments, который нам скажет, что мы не можем выгрузиться, потому что нет комментариев к хранилищу – очень полезно при долгосрочном использовании;
-
дальше нам нужно указать путь к хранилищу;
-
и куда помещать.
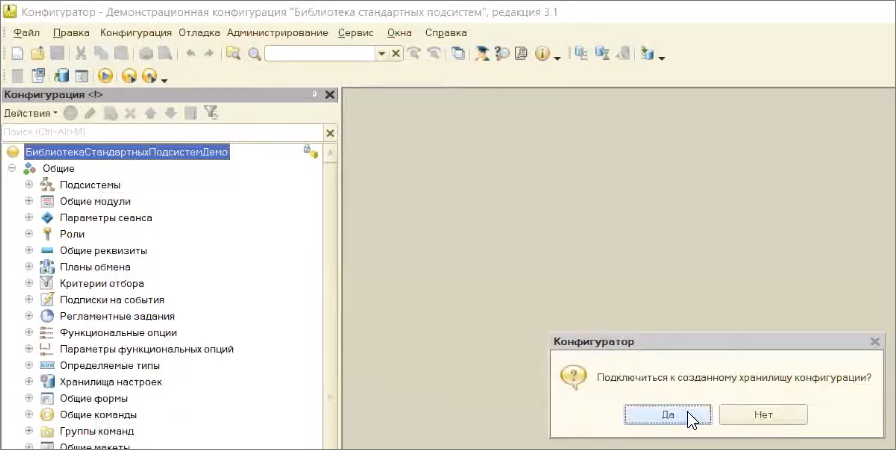
Хранилище мы создали, давайте подключимся к нему.
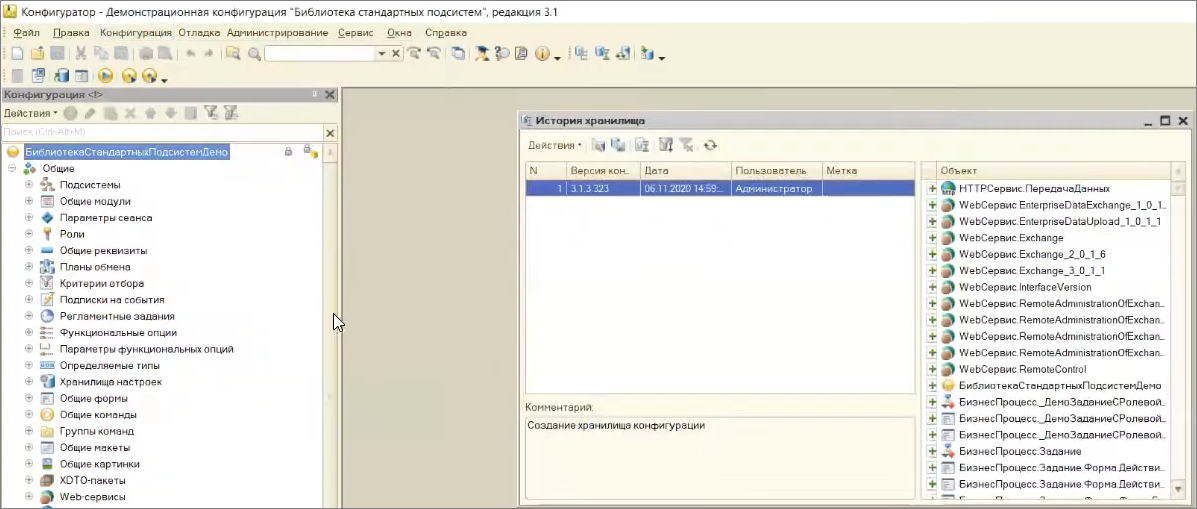
В истории хранилища мы видим наше помещение и создание хранилища конфигурации.
Создание файла версий

Если мы сейчас выполним команду, то мы получим ошибку о том, что не найден файл с версией Git.
Это говорит о том, что нам в каталоге src/cf нужно сначала создать файл VERSION с информацией о версии, с которой нужно разбирать хранилище.
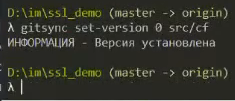
Мы будем разбирать хранилище с нулевой версии. Чтобы создать такой файл в каталоге src/cf автоматически, выполним команду:
gitsync set-version 0 src/cf
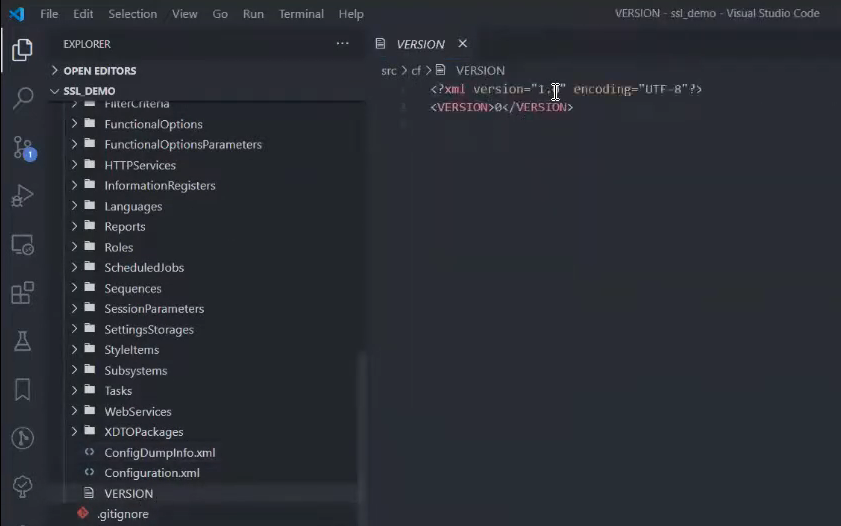
Итак, у нас в каталоге src/cf был создан файл VERSION. Это очень простой xml-файл, в котором буквально один тег – информация о версии, с которой gitsync нужно синхронизировать хранилище (в данном случае, с нуля).
Создание файла авторов

Запустим нашу синхронизацию еще раз.
Дальше мы получили ошибку о том, что у нас не хватает данных об авторах за счет того, что мы включили плагин check-authors.

Файл авторов тоже выглядит очень просто – он называется AUTHORS. В нем нам нужно сопоставить пользователей из хранилища с какими-то пользователями в Git – под кем мы будем коммитить, кто у нас будет попадать в git blame и на кого будут назначаться замечания.
Конечно же, я считаю, что Администратор – это компания 1С, потому что она нам принесла кучу непонятного вендорского кода.
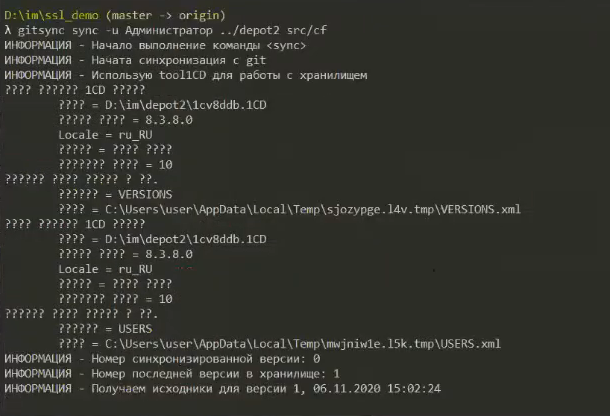
После этих настроек мы уже получили работающий скрипт, сейчас gitsync пойдет работать.
Автозапуск gitsync с помощью планировщика заданий Windows
Последнее, что мы сегодня сделаем – это настроим постоянный автозапуск gitsync.

Для этого вы можете использовать, например, планировщик заданий Windows.

И здесь создать простую задачу.
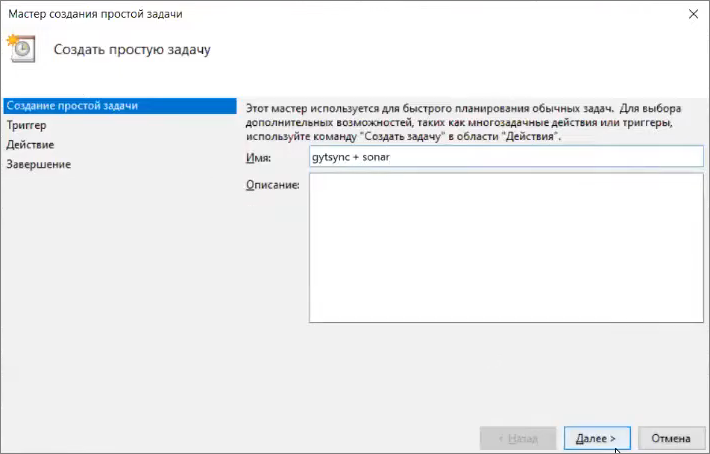
Назвать ее gitsync + sonar,

указать, что она выполняется ежедневно,

в какое-то время.
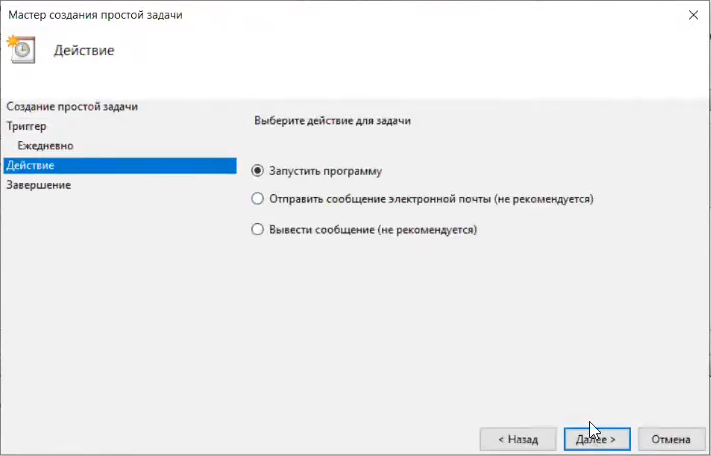
И вам нужно запустить программу.
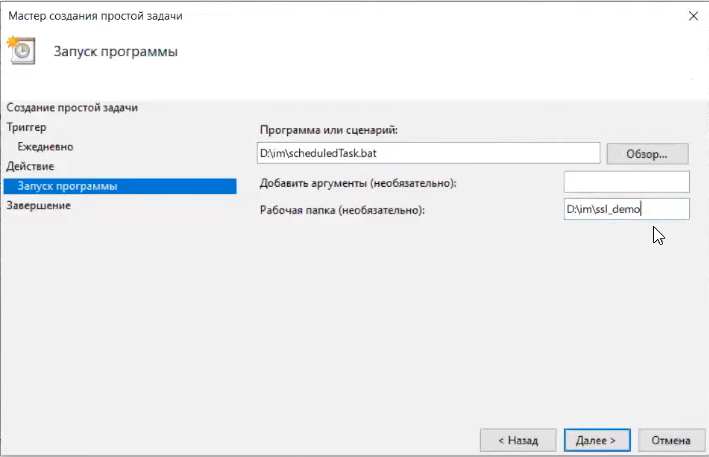
Запускать мы будем маленький bat-ник, я сейчас покажу его содержимое.
В качестве рабочей папки укажем ssl_demo, чтобы у нас все скрипты выполнялись относительно этого каталога.
И нажимаем Готово.
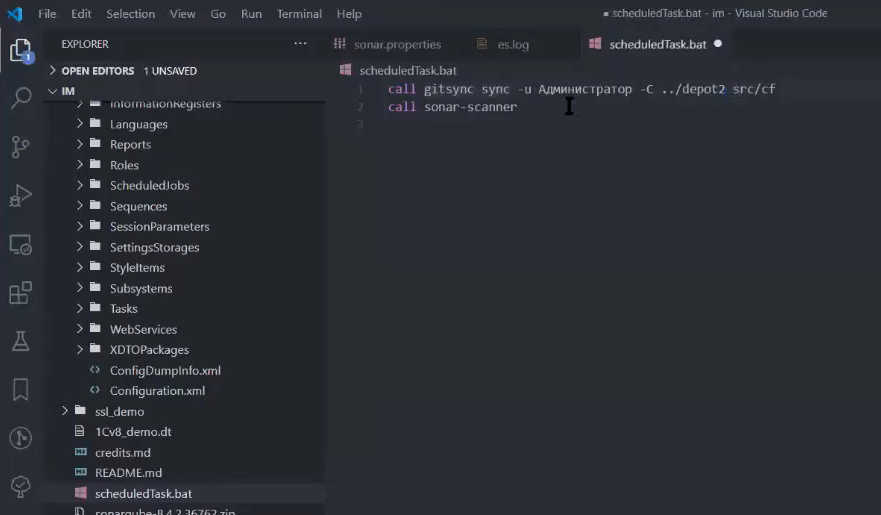
Вот так выглядит содержимое батника – мы вызываем gitsync с данными по синхронизации и вызываем sonar-scanner.
Для того, чтобы нам не передавать кучу параметров в sonar-scanner, мы можем в каталог нашего репозитория положить файлик sonar-project.properties.
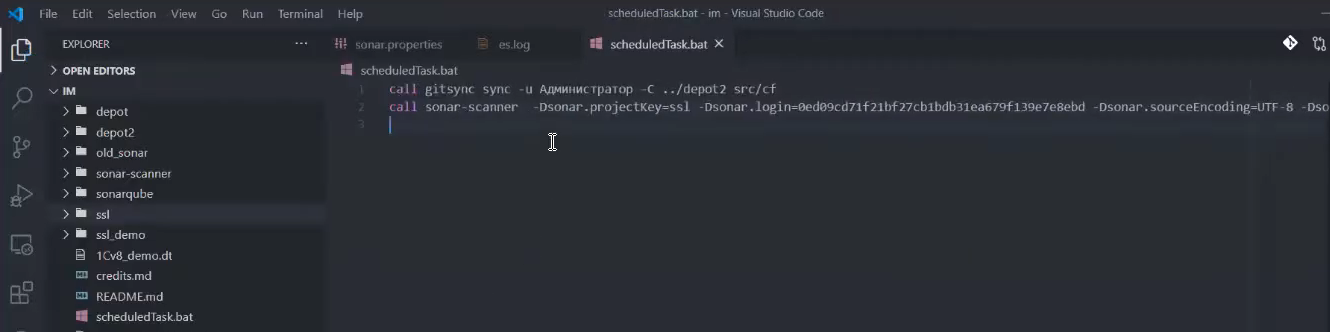
Но я для экономии времени просто перенесу все наши аргументы прямо сюда.
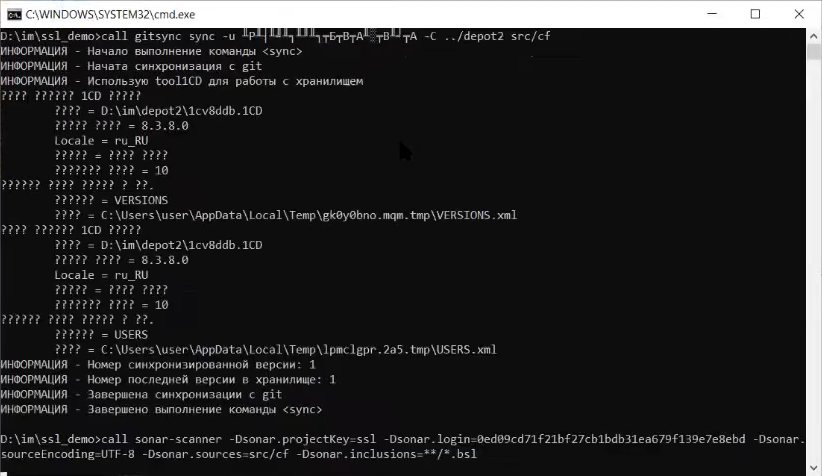
Запускаем наше задание – появится черное окно, в котором отработает gitsync, и дальше запустится sonar, который выгрузит наши исходники на сервер SonarQube.
Результат анализа замечаний с назначенными ответственными по данным авторов кода в хранилище
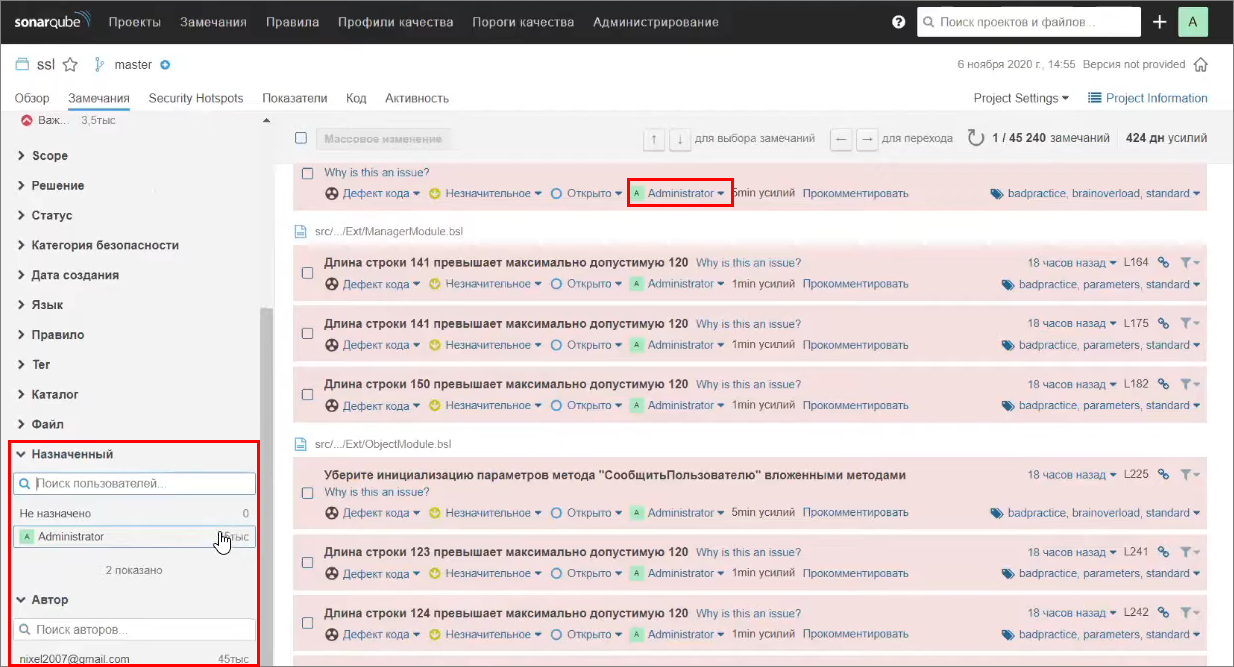
Давайте перейдем в веб-интерфейс. Наш проект уже повторно проанализировался, и можно обратить внимание, что все замечания автоматически назначились на Администратора, потому что у этого пользователя в профиле настроена почта 1c@localhost, которая совпадает с информацией о почте пользователя git из вывода git blame. Этот назначенный исполнитель тоже сюда «подцепился».
В планировщике Windows вы можете настроить расписание, чтобы этот батник у вас запускался каждый раз, когда вы логинитесь, либо каждый день, или даже каждый час.
И таким образом, мы буквально за один час получили мини-сборочную линию, которая разберет ваше хранилище, автоматически положит исходники в Git, запустит анализ кода с помощью sonar-scanner и выгрузит все это в sonar.
Вопросы:
За что отвечает компонента sonar-scanner? Какая её роль в общем анализе? Она выполняет основную работу, а остальное – это просто веб-интерфейс?
Практически так. Большую часть работы выполняет sonar-scanner. Сам анализ исходников выполняется sonar-scanner-ом на клиенте. Есть ряд задач, которые выполняет сервер при разборе этого анализа. Он считает часть общих метрик по количеству файлов, по количеству просто строк. В плагине могут быть какие-то серверные перехватчики, которые дополнительно еще что-то «докручивают», но плагин «1С (BSL) Community Plugin» рассчитан именно на то, что наибольшая часть работы выполняется на клиенте.
А как организовать анализ внешних обработок?
Внешние обработки нужно выгрузить в исходники в какой-нибудь соседний каталог – не в src/cf, а в src/epf. И они тоже будут анализироваться. Естественно, вам нужно будет поменять настройку sonar-project.properties – где лежат ваши исходники (можно просто на src натравить). Там пока не все хорошо. Например, обработка будет считаться частью вашей конфигурации. Работа с расширениями и вообще с внешними файлами очень нетривиальная и пока реализована не очень хорошо. Но сами исходники обработок анализироваться будут, формы будут разбираться, какие-то нехорошие вещи в модулях будут искаться. Я надеюсь, с течением времени сценарий поддержки обработок, внешних отчетов и расширений мы будем прорабатывать, и все будет лучше.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Путь к идеальному коду".
Вступайте в нашу телеграмм-группу Инфостарт