

Здравствуйте.
Мне необходимо осветить реализацию на основе инструкции от издателя 1С, по причине обновлённого подхода к реализации решения отказоустойчивого кластера для баз данных под системой управления PostgreSQL.
Обновлённый подход выражается в применении операционной системы выше на одну версию, чем в указанной инструкции, по этой причине, один из сервисов (etcd) ставится иначе, и настраивается слегка по другому. В основном большинство частей инструкции являются копией изложенного опыта, но с поправками и обращением внимания на нюансы, в самостоятельной форме которые приходилось преодолевать, очень рассчитываю на то, что мой опыт кому-то сможет помочь.
Собирал кластер первый раз, некоторые терминологические выводы основываются на гипотезах, признателен буду в случае обратной связи о том, верна ли гипотеза, а если нет, то какая истина ?
Имеется:
- 5 виртуальных машин на "Centos-8"
- 3 машины идут под базы данных, можно и две, но в целях пресечения так называемого явления "split-brain"(где обе машины начнут считать себя мастером) вводим третью машину и на каждую из них будет установлена служба "Patroni".
- 2 машины уходят под сервера приложений "1С", на каждую из них мы установим помимо сервера приложения "1С", "HAproxy", как предполагается для сбора статистики от службы "patroni" и однозначности обращения со стороны сервера приложения "1С" к одному, а один ко многим.
- На всех 5 машинах будут установлены сервисы "etcd" посредством которого, узлы будут введены в один общий кластер, как описано в инструкции от специалистов "1С", "etcd" будет использоваться службой "Patroni" в целях хранения своей конфигурации, но как на практике не совсем понятная суть изложенного, так как каждый конфигурационный файл "patroni.yml", будет создан на каждом узле хранения баз данных в ручную, с почти идентичным настройками.
- Таблица игроков
NS имя сервера БД-1 pg1.local *.1 четвёртый октет адреса NS имя сервера БД-2 pg2.local *.2 NS имя сервера БД-3 pg3.local *.3 NS имя сервера 1C 1c.local *.4 NS имя сервера 1C-R 1cr.local *.5 - Предварительно на серверах "pg-1", "pg-2", "pg-3" установлены системы управления баз данных "PostgreSQL" но не запущенные и без первичной инициализации баз данных, так же служба "PostgreSQL" снята с автозапуска, "patroni" самостоятельно будет управлять а так же конфигурировать "PostgreSQL".
- На серверах "1c" и "1cr", предварительно необходимо установить платформу приложений "1С".
Установка "etcd" на "Centos-8"(все операции на всех узлах, выполняются под суперпользователем root):
- Качаем релиз в виде архива, распаковываем, перемещаем распакованную библиотеку в окружение не системных коллекций
~$ export RELEASE="3.3.11" ~$ wget https://github.com/etcd-io/etcd/releases/download/v${RELEASE} ~$ tar xvf etcd-v${RELEASE}-linux-amd64.tar.gz ~$ cd etcd-v${RELEASE}-linux-amd64 ~$ mv etcd etcdctl /usr/local/bin - Проверяем версию:
~$ etcd --version etcd Version: 3.3.11 Git SHA: 2cf9e51d2 Go Version: go1.10.7 Go OS/Arch: linux/amd64 - Создаём окружение для работы сервиса "etcd":
~$ mkdir -p /var/lib/etcd/ ~$ mkdir /etc/etcd ~$ groupadd --system etcd ~$ useradd -s /sbin/nologin --system -g etcd etcd ~$ chown -R etcd:etcd /var/lib/etcd/ - Создаём для "etcd" как службы, служебный файл:
~$ nano /etc/systemd/system/etcd.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify WorkingDirectory=/var/lib/etcd/ EnvironmentFile=-/etc/etcd/etcd.conf User=etcd # set GOMAXPROCS to number of processors ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /usr/local/bin/etcd --name=\"${ETCD_NAME}\" --data-dir=\"${ETCD_DATA_DIR}\" --listen-client-urls=\"${ETCD_LISTEN_CLIENT_URLS}\"" Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target - Создаём конфигурацию начального/мастер узла кластера:
~$ nano /etc/etcd/etcd.conf #[Member] ETCD_DATA_DIR="/var/lib/etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="1c" ETCD_HEARTBEAT_INTERVAL="1000" ETCD_ELECTION_TIMEOUT="5000" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="http://1c.local:2380" ETCD_ADVERTISE_CLIENT_URLS="http://1c.local:2379" ETCD_INITIAL_CLUSTER="1c=http://1c.local:2380" ETCD_INITIAL_CLUSTER_TOKEN="Ваш токен, любым генератором создаваемый" ETCD_INITIAL_CLUSTER_STATE="new" - Запускаем "etcd" службу и открываем порты:
~$ systemctl daemon-reload ~$ firewall-cmd -zone=public --permanent --add-port=2379-2380/tcp ~$ systemctl start etcd.service - Проверяем статус службы, в случае без ошибочного статуса, включаем службу "etcd" в автозапуск:
~$ systemctl status etcd.service `79; etcd.service - Etcd Server Loaded: loaded (/etc/systemd/system/etcd.service; disabled; vendor preset: Active: active (running) since Thu 2022-08-20 15:15:31 MSK; 3s Main PID: 5551 (etcd) Tasks: 18 (limit: 302041) Memory: 6.7M CGroup: /system.slice/etcd.service ^92;^72;4454 /usr/local/bin/etcd --name=agg-server-1 --data-dir=/var/lib/etcd авг 20 15:15:31 1c.local etcd[5551]: uid_сервера_1c.local received MsgVoteResp from uid_сервера_1c.local at term 2 авг 20 15:15:31 1c.local etcd[5551]: uid_сервера_1c.local became leader at term 2 авг 20 15:15:31 1c.local etcd[5551]: raft.node: uid_сервера_1c.local leader uid_сервера_1c.local at term 2 авг 20 15:15:31 1c.local etcd[5551]: setting up the initial cluster version to 3.3 авг 20 15:15:31 1c.local etcd[5551]: set the initial cluster version to 3.3 авг 20 15:15:31 1c.local etcd[5551]: enabled capabilities for version 3.3 авг 20 15:15:31 1c.local etcd[5551]: ready to serve client requests авг 20 15:15:31 1c.local etcd[5551]: published {Name:1c.local ClientURLs:[http://1c.local:2379]} to cluster uid_cluster авг 20 15:15:31 1c.local etcd[5551]: Started Etcd Server. авг 20 15:15:31 1c.local etcd[5551]: serving insecure client requests on [::]:2379, this is strongly discouraged! ~$ systemctl enable etcd.service - Проверяем состояние кластера:
~$ etcdctl cluster-health member uid_1c.local is healthy: got healthy result from http://1c.local:2379 cluster is healthy - Добавляем второй узел:
~$ etcdctl member add 1cr.local http://1cr.local:2380 Added member named 1cr.local with ID uid_1cr.local to cluster ETCD_NAME="1cr.local" ETCD_INITIAL_CLUSTER="1c=http://1c.local:2380,1cr=http://1cr.local:2380" ETCD_INITIAL_CLUSTER_STATE="existing" - Устанавливаем в аналогичном порядке "etcd" на втором узле, но изменяем конфигурацию под атрибуты данного узла:
#[Member] ETCD_DATA_DIR="/var/lib/etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="1cr" ETCD_HEARTBEAT_INTERVAL="1000" ETCD_ELECTION_TIMEOUT="5000" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="http://1cr.local:2380" ETCD_ADVERTISE_CLIENT_URLS="http://1cr.local:2379" ETCD_INITIAL_CLUSTER="1c=http://1c.local:2380,1cr=http://1cr.local:2380" ETCD_INITIAL_CLUSTER_TOKEN="Ваш_токен" ETCD_INITIAL_CLUSTER_STATE="existing" <- "Обратите внимание на флаг, он отличается так же" - Запускаем службу и проверяем состав кластера на состояние:
~$ etcdctl cluster-health member uid_1cr is healthy: got healthy result from http://1cr.local:2379 member uid_1c is healthy: got healthy result from http://1c.local:2379 cluster is healthy - Порядок дальнейшего добавления узлов в кластер опускаю, он идентичен на добавлением второго узла и после добавления Всех необходимых узлов, нужно привести конфигурацию на всех участниках к единому виду по следующим переменным:
ETCD_INITIAL_CLUSTER="1c=http://1c.local:2380,1cr=http://1cr.local:2380,pg1=http://pg1.local:2380,pg2=http://pg2.local:2380,pg3=http://pg3.local:2380" ETCD_INITIAL_CLUSTER_STATE="existing" - Далее нам необходимо создать пользователя кластера с высокими правами, для внутренней смежной коммуникацией между "patroni" и кластером "etcd":
~$ etcdctl user add root New password: User root created ~$ etcdctl user get root User: root Roles: root ~$ etcdctl auth enable Authentication Enabled ~$ etcdctl --username root user get root Password: User: root Roles: root
Установка и настройка сервиса "patroni" на "Centos-8":
- Устанавливаем "Python-3":
~$ yum install -y python3 ~$ python3 -m pip install --upgrade pip ~$ python3 --version Python 3.6.8 - Устанавливаем необходимые зависимости:
~$ yum install -y gcc python3-devel ~$ python3 -m pip install psycopg2-binary - Устанавливаем "patroni":
~$ python3 -m pip install patroni[etcd] ~$ patroni --version patroni 2.1.4 - Настраиваем первый узел "pg1.local", настроем окружение для службы "patroni":
~$ mkdir /etc/patroni ~$ chown postgres:postgres /etc/patroni ~$ chmod 700 /etc/patroni - Создаём файл настроек для службы "patroni", файл имеет мои собственные параметры для моего окружения, мною было принято решение оставить их для наглядности того, в каком блоке необходимо выполнять параметризацию "PostgreSQL" посредством "patroni", описание/понимание каждой строки как в этом так и в предыдущих примерах, оставляю на совесть испытуемого, большинство настроек имеет конфигурацию по умолчанию, то как они были указаны в инструкциях от 1с и других источников:
~$ nano /etc/patroni/patroni.yml name: pg1 namespace: /db/ scope: postgres restapi: listen: 0.0.0.0:8008 connect_address: pg1.local:8008 authentication: username: patroni password: patroni etcd: hosts: localhost:2379 username: root password: Ваш_пароль_кластера_etcd bootstrap: dcs: ttl: 30 loop_wait: 10 retry_timeout: 10 maximum_lag_on_failover: 1048576 master_start_timeout: 10 postgresql: use_pg_rewind: true use_slots: true parameters: wal_level: replica hot_standby: "on" wal_keep_segments: 8 max_wal_senders: 5 max_replication_slots: 5 checkpoint_timeout: 30 initdb: - auth-host: md5 - auth-local: peer - encoding: UTF8 - data-checksums - locale: ru_RU.UTF-8 pg_hba: - host replication replicator samenet md5 - host replication all 127.0.0.1/32 md5 - host replication all ::1/128 md5 users: usr1cv8: password: Сгенерированный_Вами_пароль options: - superuser postgresql: listen: 0.0.0.0:5432 connect_address: pg1.local:5432 config_dir: /var/lib/pgsql/14/data bin_dir: /usr/pgsql-14/bin/ data_dir: /var/lib/pgsql/14/data pgpass: /tmp/pgpass authentication: superuser: username: postgres password: Сгенерированный_Вами_пароль replication: username: replicator password: Сгенерированный_Вами_пароль rewind: username: rewind_user password: Сгенерированный_Вами_пароль parameters: max_connections: 181 dynamic_shared_memory_type: posix seq_page_cost: 0.1 random_page_cost: 0.1 cpu_operator_cost: 0.0025 logging_collector: on log_timezone: 'Europe/Moscow' datestyle: 'iso, dmy' timezone: 'Europe/Moscow' lc_messages: 'ru_RU.UTF-8' lc_monetary: 'ru_RU.UTF-8' lc_numeric: 'ru_RU.UTF-8' lc_time: 'ru_RU.UTF-8' default_text_search_config: 'pg_catalog.russian' temp_buffers: 128MB max_files_per_process: 10000 commit_delay: 1000 from_collapse_limit: 8 join_collapse_limit: 8 autovacuum_max_workers: 4 vacuum_cost_limit: 200 autovacuum_naptime: 10s autovacuum_vacuum_scale_factor: 0.01 autovacuum_analyze_scale_factor: 0.005 max_locks_per_transaction: 512 escape_string_warning: off standard_conforming_strings: off shared_preload_libraries: 'online_analyze, plantuner' online_analyze.threshold: 50 online_analyze.scale_factor: 0.1 online_analyze.enable: on online_analyze.verbose: off online_analyze.min_interval: 10000 online_analyze.table_type: 'temporary' plantuner.fix_empty_table: on shared_buffers: 8GB effective_cache_size: 16GB maintenance_work_mem: 1GB checkpoint_completion_target: 0.9 wal_buffers: 16MB default_statistics_target: 500 effective_io_concurrency: 200 work_mem: 13981kB min_wal_size: 2GB max_wal_size: 8GB max_worker_processes: 12 max_parallel_workers_per_gather: 6 max_parallel_workers: 12 max_parallel_maintenance_workers: 4 tags: nofailover: false noloadbalance: false clonefrom: false nosync: false - Создаём сервис для запуска службы "patroni":
~$ nano /etc/systemd/system/patroni.service [Unit] Description=Runners to orchestrate a high-availability PostgreSQL After=syslog.target network.target [Service] Type=simple User=postgres Group=postgres ExecStart=/usr/local/bin/patroni /etc/patroni/patroni.yml ExecReload=/bin/kill -s HUP $MAINPID KillMode=process TimeoutSec=10 Restart=no [Install] WantedBy=multi-user.target - Запускаем службу "patroni" и открываем порты:
~$ systemctl daemon-reload ~$ firewall-cmd -zone=public --permanent --add-port=8008/tcp ~$ firewall-cmd -zone=public --permanent --add-port=5432/tcp ~$ systemctl start patroni.service - Проверяем статус службы "patroni":
~$ systemctl status patroni.service ? patroni.service - Runners to orchestrate a high-availability PostgreSQL Loaded: loaded (/etc/systemd/system/patroni.service; disabled; vendor preset: disabled) Active: active (running) since Wed 2022-08-20 16:01:12 UTC; 2s ago Main PID: 1029 (patroni) CGroup: /system.slice/patroni.service 1715 /opt/pgpro/1c-14/bin/postgres -D /var/lib/pgpro/1c-14/data --config-file=/var/lib/pgpro/1c-14/data/postgresql.conf --listen_addresses=0.0.0.0 --port=5432 --cluster_name=postgres --wal_level=replica --hot_standby=on --max_connections=180 --max_wal_senders=5 --max_prepared_transactions=0 --max_locks_per_transaction=64 --track_commit_timestamp=off --max_replication_slots=5 --max_worker_processes=8 --wal_log_hints=on авг 20 16:01:13 pg1.local patroni[1029]: Data page checksums are enabled. авн 20 16:01:13 pg1.local patroni[1029]: fixing permissions on existing directory /var/lib/pgpro/1c-14/data ... ok авг 20 16:01:13 pg1.local patroni[1029]: creating configuration files ... ok авг 20 16:01:13 pg1.local patroni[1029]: running bootstrap script ... ok авг 20 16:01:13 pg1.local patroni[1029]: performing post-bootstrap initialization ... ok - Проверьте каталог по пути "/var/lib/pgpro/1c-14/data", он должен быть полным.
Так же проверьте, слушает ли "PostgreSQL" порт 5432?:~$ ss -ltn | grep 5432 LISTEN 0 128 0.0.0.0:5432 0.0.0.0:* - Добавляем "patroni" в автозапуск:
~$ systemctl enable patroni.service - Для проверки состояния кластера службы "patroni", выполняем следующую команду:
~$ patronictl -c /etc/patroni/patroni.yml list +--------+-----------------+---------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | + Cluster: postgres (*******************) -----+----+-----------+ | pg1 | pg1.local | Leader | running | 1 | | +--------+-----------------+---------+---------+----+-----------+ - Добавление нового узла.
На данном этапе, настройка похожа как и в случае конфигурирования кластера "etcd", то есть, выполняем те же этапы установки и создаём тот же файл конфигурации "patroni.yml" с некоторыми поправками:~$ nano /etc/patroni/patroni.yml name: pg2 namespace: /db/ scope: postgres restapi: listen: 0.0.0.0:8008 connect_address: pg2.local:8008 authentication: username: patroni password: patroni etcd: hosts: localhost:2379 username: root password: Ваш_такой_же_пароль_что_и_в_первой_конфигурации bootstrap: dcs: ttl: 30 loop_wait: 10 retry_timeout: 10 maximum_lag_on_failover: 1048576 master_start_timeout: 10 postgresql: use_pg_rewind: true use_slots: true parameters: wal_level: replica hot_standby: "on" wal_keep_segments: 8 max_wal_senders: 5 max_replication_slots: 5 checkpoint_timeout: 30 initdb: - auth-host: md5 - auth-local: peer - encoding: UTF8 - data-checksums - locale: ru_RU.UTF-8 pg_hba: - host replication replicator samenet md5 - host replication all 127.0.0.1/32 md5 - host replication all ::1/128 md5 users: usr1cv8: password: Ваш_такой_же_пароль_что_и_в_первой_конфигурации options: - superuser postgresql: listen: 0.0.0.0:5432 connect_address: pg2.local:5432 config_dir: /var/lib/pgsql/14/data bin_dir: /usr/pgsql-14/bin/ data_dir: /var/lib/pgsql/14/data pgpass: /tmp/pgpass authentication: superuser: username: postgres password: Ваш_такой_же_пароль_что_и_в_первой_конфигурации replication: username: replicator password: Ваш_такой_же_пароль_что_и_в_первой_конфигурации rewind: username: rewind_user password: Ваш_такой_же_пароль_что_и_в_первой_конфигурации parameters: max_connections: 181 dynamic_shared_memory_type: posix seq_page_cost: 0.1 random_page_cost: 0.1 cpu_operator_cost: 0.0025 logging_collector: on log_timezone: 'Europe/Moscow' datestyle: 'iso, dmy' timezone: 'Europe/Moscow' lc_messages: 'ru_RU.UTF-8' lc_monetary: 'ru_RU.UTF-8' lc_numeric: 'ru_RU.UTF-8' lc_time: 'ru_RU.UTF-8' default_text_search_config: 'pg_catalog.russian' temp_buffers: 128MB max_files_per_process: 10000 commit_delay: 1000 from_collapse_limit: 8 join_collapse_limit: 8 autovacuum_max_workers: 4 vacuum_cost_limit: 200 autovacuum_naptime: 10s autovacuum_vacuum_scale_factor: 0.01 autovacuum_analyze_scale_factor: 0.005 max_locks_per_transaction: 512 escape_string_warning: off standard_conforming_strings: off shared_preload_libraries: 'online_analyze, plantuner' online_analyze.threshold: 50 online_analyze.scale_factor: 0.1 online_analyze.enable: on online_analyze.verbose: off online_analyze.min_interval: 10000 online_analyze.table_type: 'temporary' plantuner.fix_empty_table: on shared_buffers: 8GB effective_cache_size: 16GB maintenance_work_mem: 1GB checkpoint_completion_target: 0.9 wal_buffers: 16MB default_statistics_target: 500 effective_io_concurrency: 200 work_mem: 13981kB min_wal_size: 2GB max_wal_size: 8GB max_worker_processes: 12 max_parallel_workers_per_gather: 6 max_parallel_workers: 12 max_parallel_maintenance_workers: 4 tags: nofailover: false noloadbalance: false clonefrom: false nosync: false - В результате, после настройки и запуска всех узлов, должно быть три узла в кластере "patroni":
~$ patronictl -c /etc/patroni/patroni.yml list +--------+-----------------+---------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | + Cluster: postgres (*******************) -----+----+-----------+ | pg1 | pg1.local | Leader | running | 1 | | | pg2 | pg2.local | Replica | running | 1 | 0 | | pg3 | pg3.local | Replica | running | 1 | 0 | +--------+-----------------+---------+---------+----+-----------+
Установка балансировщика "HAproxy" на сервер "1c.local":
- Устанавливаем "HAproxy", так же перемещаем настройки по умолчанию в сторону:
~$ yum install -y haproxy ~$ mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.conf.def - Создаём конфигурационный файл:
~$ nano /etc/haproxy/haproxy.cfg global maxconn 100 defaults log global mode tcp retries 2 timeout client 30m timeout connect 4s timeout server 30m timeout check 5s listen stats mode http bind *:7000 stats enable stats uri / listen postgres bind *:5432 option httpchk http-check expect status 200 default-server inter 3s fastinter 1s fall 2 rise 2 on-marked-down shutdown-sessions server pg1 pg1.local:5432 maxconn 100 check port 8008 server pg2 pg2.local:5432 maxconn 100 check port 8008 server pg3 pg3.local:5432 maxconn 100 check port 8008 - Запускаем службу "HAproxy", и открываем порты:
~$ setsebool -P haproxy_connect_any=1 # в случае включенного SELinux ~$ systemctl start haproxy.service ~$ firewall-cmd -zone=public --permanent --add-port=7000/tcp - Если запуск прошёл успешно, добавляем службу "HAproxy" в автозапуск:
~$ systemctl enable haproxy.service
В целом на этом настройка закончена, по адресу "http://1c.local:7000" можно проверить состояние узлов кластера "Patroni".
При добавлении базы данных, обращение в менеджере кластера "1C", выполняется на "localhost", так как HAproxy вещает на "*:5432" возможность подключения к системе управления баз данных "PostgreSQL", но в моём случае было необходимо поправить конфигурацию файла "/var/lib/pgpro/1c-14/data/pg_hba.conf" в ручную, в целях предоставления возможности подключения с узла "1c.local" к "PostgreSQL", эти изменения мною проводились на всех узлах кластера Patroni и после выполнялась порядовая перезагрузка узлов кластера:
~$ patronictl -c /etc/patroni/patroni.yml reload postgres pg1
~$ patronictl -c /etc/patroni/patroni.yml restart postgres pg1
~$ patronictl -c /etc/patroni/patroni.yml reload postgres pg2
~$ patronictl -c /etc/patroni/patroni.yml restart postgres pg2
~$ patronictl -c /etc/patroni/patroni.yml reload postgres pg3
~$ patronictl -c /etc/patroni/patroni.yml restart postgres pg3
Дальше задумка следующая, запустить второй "1cr.local" сервер приложения 1С, который уже в кластере и котором я умолчал, выполнить установку/настройку службы "HAproxy", добавить этот сервер посредством менеджера кластера "1С" как второй рабочий, с последующей настройкой его как резервный и тестировать отказоустойчивость на уровне сервера приложения "1С".
Обновление:
По результатам настройки кластера приложений "1С" посредством консоли управления кластером "1С" было выявлено не адекватное и не предсказуемое поведения самого кластера при переключениях с ведущего сервера приложений на повторитель, порог ожидания 10 минут после введения резервного сервера в кластер.
Что было выявлено:
- Зависает на 10-15 секунд, после переключает на резервный в случае если сам узел ведущего в сети а сама служба "1С" на ведущем сервера остановлена, то есть срабатывает некое условие перенаправления. Работает подключение к базам при таких условиях на всех узлах интрасети.
- В случае если физически не доступен узел ведущего сервера "1С", то тип модели меняется на ошибку, что узел не доступен, при том что на том узле, где выполнялась настройка кластера посредством консоли, появляется так же ошибка но сообщает уже о не доступности баз данных, но через примерно 15-30 секунд, подключение работает, ссылаясь на сетевое имя узла "1c.local" с установлением сессии на "1cr.local", но в интрасети, на других узлах, подключение не работает.
Возможно эта особенность проблемы кроется в сети, так как локально работает "IDS\IPS" система. - На момент 15-30 секундного переключения с ведущего сервера на резервный, в этот момент в консоли кластера "1С", наблюдалось поведение оповещающие о том что резервный не является центральным сервером, показывая при этом в ошибке хэш кластера, соответствующая галочка была установлена.
- При настройке силами консоли управления кластера "1С", посредством изучения тем, форумов, на вопрос настройки кластера отказоустойчивости, было выявлено, что поведения повторителя должно быть с моделью поведения как у повторителя, то есть может быть ситуация при той концепции о которой написана инструкция, когда ведущий сервер делает запись в БД а повторитель повторяет эту запись в туже БД, что приведёт к коллизиям и проблемам.
Было предпринято решение на основании указанных пунктов (не исключается тот факт, что автору этой статьи не хватает опыта работы с настройкой отказоустойчивого кластера силами инструментов самой платформы) выполнить кластер используя "HAproxy" перед сервером "1С" ведущим и сервером "1С" резервным, под именем "srv1c.local", без ввода этого узла в кластер "etcd".
Этапы установки на новый узел, не отличаются от указанных мною этапах данной инструкции, по этому приведу сразу работающий пример конфигурации:
~$ nano /etc/haproxy/haproxy.cfg
global
maxconn 100
defaults
log global
mode tcp
retries 2
timeout client 3s
timeout connect 5s
timeout server 3s
timeout check 2s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen 1c
bind *:1540-1541
bind *:1560-1691
option tcp-check
balance first
server 1c 1c.local maxconn 3000 check port 1541
server 1rc 1rc.local maxconn 3000 check port 1541
Какие изменения коснулись конфигурации:
- Мы провели смену проверки на tcp "option tcp-check"
- bind поставили прослушивать диапазоны нужных нам портов
- Роль балансировки выставлена "first", политика этой роли в том, что на каждый сервер выдаётся свой предел соединений и осуществляется это по декларативному порядку, то есть по порядку следования, тот кто первый указан в списке, тот и будет первым, тот кто вторым, тот будет вторым после первого и т.д.
Определяется порог установленных сессий по количеству переменной "maxconn"
По поводу переключения с ведущего сервера на резервный: выполняется с ошибкой, то есть пользователь однозначно это переключение увидит из за ошибки, ошибка будет предлагать два выбора, завершить работу или перезапустить, хватает выбора перезапустить и выполняется уже подключение к резервному серверу. Ошибка сама говорит о том что уникальное соединение утеряно, вероятно на каждое соединение генерируется уникальная случайная последовательность символом и цифр, когда переключение происходит и сессия теряется, то резервный сервер не содержит этой информации, то есть у него локально нету этих данных, они находятся на основном сервере, но клиентская часть знает об этом, по этому сообщает что связь утеряна:
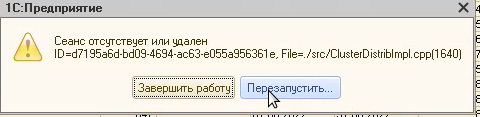
Схема:
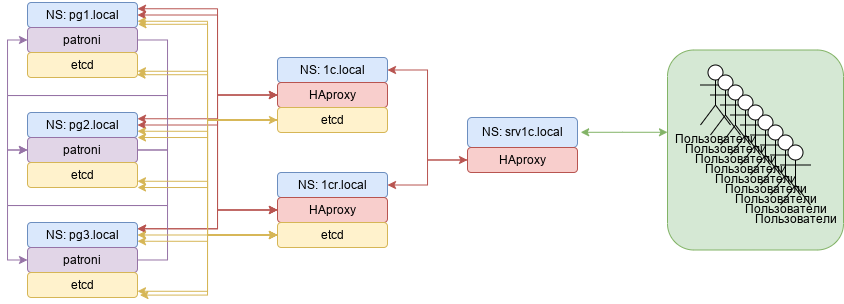
Аннотированный Список:
Вступайте в нашу телеграмм-группу Инфостарт