Хочу вам рассказать про подход к организации хранилищ 1С – про некоторые технические ухищрения, которые я использую, чтобы оперировать множеством хранилищ 1С без боли, унижений и ручных операций.
Это будет только часть из того, что можно было бы сделать – некий вброс. Сюда, конечно же, еще по-хорошему можно будет прикрутить какое-нибудь веб-API, которое будет эти хранилища автоматически разворачивать/сворачивать, какой-нибудь Ansible и т.д. – сделать совсем полный цикл. Но я хочу рассказать именно про серединку этого механизма – про само управление хранилищами.
Проблемы беспорядочного появления хранилищ

Начнем с проблематики – как вообще появляются хранилища?
-
Допустим, у вас есть несколько команд 1С-разработки, каждая из которых делает несколько систем. И вот они приходят к админам, которые рулят сервером, и говорят: «Нам нужна сетевая шара под хранилище». В ответ админы им расшаривают папку 1C_storage на каком-то сервере – скорее всего, на том же, где стоит разработческий сервер 1С.
-
В папке 1C_storage разработчики создают свои каталоги для хранилищ – в этих каталогах могут быть еще какие-то каталоги и т.д.
-
И дальше разработчики управляют своими хранилищами сами.
-
Но файловый доступ – неконтролируемый. Чаще всего, эта шара доступна на запись всем. Если кто-нибудь попытается там создать копию какого-нибудь хранилища, он может нечаянно стереть при этом что-нибудь нужное в чужих папках – файловый доступ вообще неконтролируемый.
-
Более того, админы, после того как расшарили эту папку, скорее всего, ее никак не бэкапят. Хорошо, если они бэкапят всю виртуалку целиком как snapshot. Но чаще всего, они просто расшарили папку, а дальше – делайте с ней, что хотите. Бэкапов хранилищ чаще всего не существует.
-
Когда хранилищ для одной системы несколько, возникает путаница. Не всегда понятно, куда мы подключаемся – к основному, к релизному или к тестовому хранилищу?
Т.е. файловый доступ – это для тех, кто больше ничего не умеет. Если у вас двое разработчиков, и вы используете одно хранилище – это еще не страшно. Но когда хранилищ много, и работает несколько команд, файловый доступ – это уже головная боль.
Сервер хранилищ

Возникает эволюция – сервер хранилищ, который нам поставляет фирма «1С».
-
Это уже не файловый доступ, здесь уже нельзя просто так взять и стереть папку с хранилищем.
-
Но у сервера хранилищ есть и минусы – когда мы создаем хранилище в строке конфигуратора, мы все так же можем написать для него произвольный путь. Т.е. мы все так же можем создавать эти папки на сервере где угодно – это никак не контролируется. В дальнейшем, если, допустим, закончилось место под размещение хранилищ, и нужно что-то удалить, невозможно понять, где чье хранилище. Какое из них нужное, а какое – не нужное. Что можно удалять, а что – нельзя? Приходится ко всем бегать и опрашивать.
-
И ещё один минус – это то, что сервер хранилищ привязан к конкретной версии платформы. Нельзя подключить к серверу хранилище, созданное в более новой версии конфигуратора. Нужно и для сервера устанавливать новую версию, а это может повлечь дополнительные неприятности – я о них подробнее расскажу далее.
Хранилища-ветки

Еще есть такая практика как хранилища-ветки.
-
Это достаточно распространенная практика, когда мы в основном хранилище параллельно работаем над множеством фич, но в релиз (или в продакшн завтра-послезавтра) выпускаем не все.
-
Для этой цели мы заводим классическое релизное (или, как мы его называли в «Связном», «подливочное») хранилище, куда уже руками вливаются только те фичи, которые нужно выпустить в релиз завтра. Все остальные фичи, которые еще находятся в процессе написания, продолжают существовать дальше в основном хранилище.
-
Фирма «1С» рекомендует похожую практику – создавать отдельное хранилище под задачу. Такое создание хранилищ автоматизировано в СППР – там потом, когда работа над задачей закончена, такое хранилище может быть автоматически удалено.
-
Получается, что автоматически создавать хранилища-ветки могут только те, у кого есть СППР, и кому СППР нужен. Однако СППР любят далеко не все, и не все им пользуются. А штатно платформа 1С нам никак не позволяет делать хранилища-ветки.
Недостатки конфигуратора

Что лично меня не устраивает в работе с хранилищами?
-
Например, конфигуратор при малейшем чихе напрочь забывает путь к хранилищу и имя пользователя. Если ты сменил версию платформы или пытаешься создать под фиче-ветку какую-то новую базу, конфигуратор путь к хранилищу забывает напрочь и не пытается тебе помочь, подсказать, что ты недавно пользовался таким хранилищем. Список последних подключений к хранилищу конфигуратор нигде не ведет. Поэтому часто эти пути приходится перепрописывать.
-
В Снегопате есть плагин, который запоминает этот путь в настройках – но Снегопат, к сожалению, есть не у всех.
-
Если ты переключился на какое-то другое хранилище-ветку, настройка старого хранилища-ветки потеряна – нужно лезть в какой-то файлик или в вики-страничку, где у тебя это сохранено, и восстанавливать вручную. То есть тебе нужно вести какой-то отдельный список любимых хранилищ, с которыми ты работаешь. Это меня жутко раздражает. Всем разработчикам платформы, которые отвечают за диалог настроек хранилища, книжка «Психбольница в руках пациентов» в помощь. Сделайте уже для людей и по-людски, ну, пожалуйста.

Рассмотрим некоторые жизненные ситуации, которые показывают проблемы, возникающие при таком подходе. Между тимлидом и разработчиком может возникнуть такой диалог:
-
Где у нас лежит хранилище для базы 1С:Документооборот?
-
По адресу \\server\1C_storage\doc
-
Нет, это разработческое, а где лежит стабильное, откуда мы релизную версию собираем?
-
Здесь \\server\1C_storage\zup_1
-
А почему папка хранилища для Документооборота называется zup_1?
-
Ну там когда-то был ЗУП, его стерли, и в эту папку записали релизное хранилище от Документооборота.
Такое бывает, я сталкивался, когда хранилище одной системы называлось именем от другой системы, потому что имена папок не контролируются – их создают сами разработчики.

Или, например, диалог:
-
Например, почему у нас стабильная бухгалтерия называется new2?
-
Потому что папку new уже кто-то занял.
-
Почему она лежит внутри папки разработческого хранилища?
-
Потому что так удобнее, чтобы путь наглядней был.
Системное решение проблем с именами хранилищ
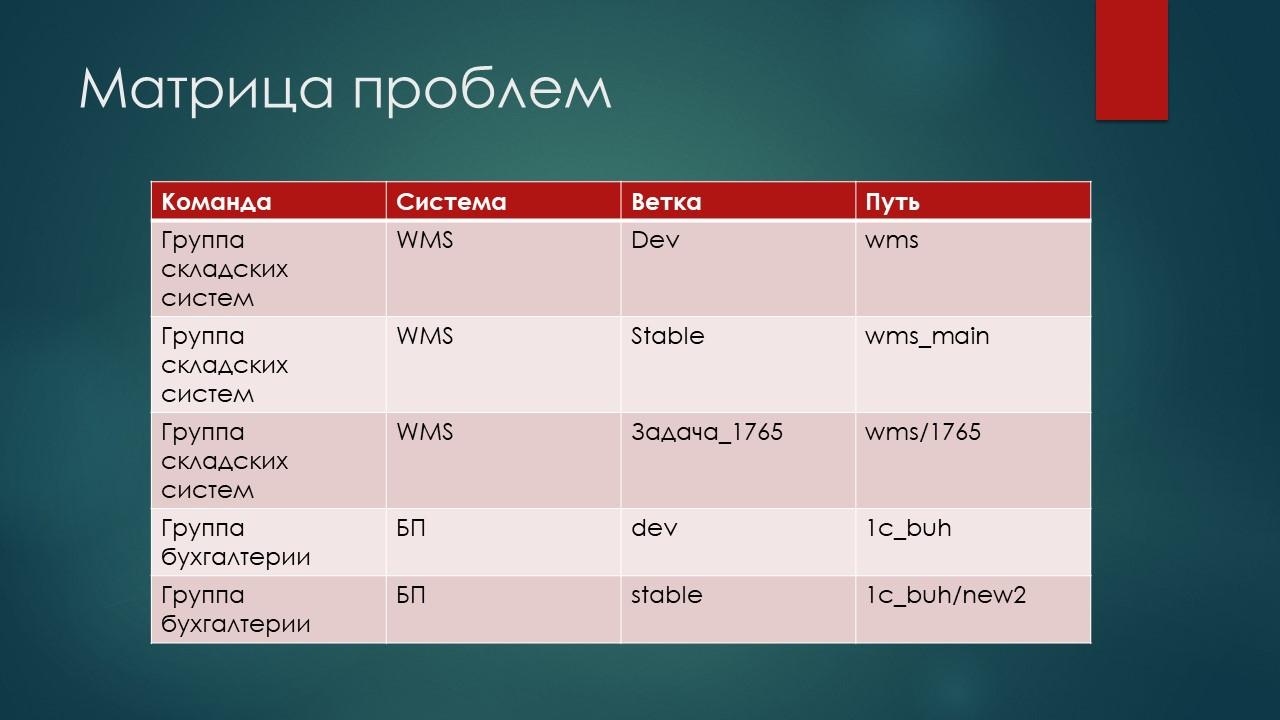
Как систематизировать подход к именованию хранилищ? Можно выделить матрицу, где перечислить все проблемы, которые нужно решить. Например:
-
существует несколько команд;
-
каждая из команд ведет разработку над перечнем систем;
-
для каждой системы может существовать несколько веток;
-
каждая ветка характеризуется каким-то путем к хранилищу;
-
и все эти компоненты именуются как попало.
Нужно составить такую матрицу – понять, где у нас что находится, и попытаться применить к этому системный подход.

В предыдущей табличке были показаны проблемы только для двух команд. А представьте, что у вас:
-
4-5 команд;
-
у каждой команды – 15-20 систем;
-
для каждой системы есть несколько хранилищ-веток, тестовых хранилищ, устаревших хранилищ, которыми никто не пользуется.
-
А если у вас не файловый доступ, а сервер хранилищ, то добавьте в эту табличку еще и измерение «версия платформы»
Вот такое количество разнообразных адресов вы можете получить.

Давайте попробуем подойти к этому системно. Что у нас есть?
-
У нас есть команды со своими правилами игры. В каждой команде – свои правила разработки: кто-то хочет работать так, кто-то эдак. Т.е. нужно изолировать подходы работы с хранилищами по командам. Это первое.
-
У каждой команды – несколько систем в разработке, поэтому, помимо настроек под команду, еще должны быть настройки в разрезе систем.
-
У каждой системы несколько хранилищ. Есть хранилища-ветки – разработочные, стабильные и фича-ветки, которые создаются под какую-то конкретную задачу.
-
Дополнительно мы должны запретить произвольное создание хранилищ разработчикам – хранилище должен создавать тимлид команды. Он должен понимать, какие у него хранилища есть, какие актуальные, а какие – не актуальные.
-
Поскольку конфигуратор легко забывает и сбрасывает все введенные настройки (место для гнева), правила именования хранилищ должны быть легкими – чтобы любой разработчик, столкнувшийся с тем, что конфигуратор в очередной раз все забыл, должен просто по памяти с клавиатуры легко вбить адрес. Должно быть понятно, как этот адрес формируется, его не нужно вспоминать, его должно быть легко вычислить в своей голове, а не искать по корпоративной базе знаний.
-
Разные «хранилища-ветки» у нас могут быть под разными версиями платформы. Например, у нас в проде используется 17-я версия платформы, а мы хотим мигрировать на 19-ю. Это значит, что изменения из разработческого хранилища 19-й версии, где мы сняли режим совместимости и там подпиливаем, мы подливаем в релизное хранилище, где все еще 17-й релиз, и оттуда делаем сборку. И когда мы уже в проде переключимся на 19-ю версию, нам придется опять поменять там адрес подключения. Или наоборот, мы попытались перейти, поняли, что платформа сырая, и всем разработчикам нужно обратно откатить адрес хранилища с 19-й версии на 17-ю. Нужно побежать и всем рассказать, что теперь мы все возвращаемся на старый адрес: «Все срочно поменяйте адрес, не комитьте не туда».
Решение

Предлагается следующий подход – если конфигуратор забыл адрес, его должно быть удобно печатать заново.
Когда я поспрашивал людей, оказалось, что такой подход применяется уже не только у меня. Но, может быть, пока этот подход используют не все, поэтому его имеет смысл озвучить более широко.
Итак, есть некий HTTP-сервер хранилища, URL доступа к которому складывается из адреса сервера, дальше некий неймспейс (пространство имен) – название группы (команды), потом – название системы и ветки:
-
например, сразу после имени сервера будет идти префикс, соответствующий команде разработки складских систем (или команде автоматизации бухгалтерии и зарплаты);
-
после имени команды идет наименование системы – некий токен системы, которую мы пилим в этом хранилище;
-
и дальше опционально может быть какая-то ветка – test, dev, задача 18574 и т. д.
Такую схему именования разработчик легко может вспомнить, если знает, в какой команде он работает, и как называется его система.

Например, у нас есть:
-
сервер storages;
-
команда разработки склада, которая придумала себе префикс warehouse (wh) – ее разработчики все свои системы будут хранить внутри подраздела wh;
-
внутри этого подраздела хранится система wms;
-
у системы wms есть ветка test.
А команда разработки финансового контура, может взять себе префикс fin, запомнить его, и в принципе уже адрес становится уже более или менее понятным – разработчик в состоянии его просто с нуля воспроизвести в конфигураторе.
Кейсы

Рассмотрим следующий кейс.
-
Даже если у нас используется HTTP-сервер хранилищ, конфигуратор никак не запрещает нам создавать произвольные хранилища. Он никак не контролирует то, что написано в хвосте адреса – не проверяет путь на сервер и каталог, в котором на сервере будет лежать хранилище.
-
Он берет этот URL-адрес от разработчика как есть и создает по этому пути хранилище, которое станет каталогом на сервере. Все опечатки, все любые выдуманные имена – все это он принимает.
-
Поэтому здесь, если вдруг этот адрес не известен тимлиду, мы должны вмешаться и обрубить создание хранилища.

Еще существует такой кейс, как пустые комментарии.
-
Разработчики – хоть ты их ругаешь, бьешь или лишаешь еды – они все равно не комментируют закладки в хранилище: «Зачем комментировать? Я всего лишь там два слова поправил. Там было простое изменение. Когда задача большая, я комментирую, а тут я просто кнопку передвинул с места на место». Все же знают такие отмазки?
-
А потом непонятно, в какой момент привнесена ошибка. И, главное, зачем вообще делалось это изменение, в рамках какой задачи? Что было причиной и мотивацией? От какого посыла это изменение делалось?
-
Кроме того, поскольку теперь многие сразу транслируют хранилище в GIT, и для того, чтобы привязка коммита в GIT к задаче в Jira состоялась, должен быть в закладке указан номер – в рамках какой задачи это было сделано. Если это номер задачи указан, то GIT и Jira смогут состыковаться, и можно будет из задачи перейти к коду, а их кода к задаче. Это очень удобно. Но для этого нужно, чтобы разработчик указал-таки эту задачу. А проконтролировать, что он там укажет нельзя. Нельзя ввести некий паттерн на то, что пишет разработчик в качестве комментарии к коммиту. Поэтому этот вопрос тоже нужно как-то автоматизировать.

И последний кейс – это смена платформы. Если у нас в проде 16-я версия, а мы хотим обновить на 19, мы берем наше хранилище и переключаем его на 19-ю.
Например, у нас сервер хранилища, который обрабатывал 16-ю платформу, стоял на порту 8316 (8.3.16). Мы рядом запустили еще одну службу хранилищ, но поскольку две службы не могут одновременно слушать один тот же порт, мы их разделили по портам – назвали порт 8319 (8.3.19), чтобы можно было по-разному к ним подключаться. И ведем в этом сервере разработку 19-й версии.
Но потом решили, что платформа сырая, и лучше не обновляться. Что должен сделать тимлид?
-
Во-первых, он должен обновить вот этот файлик в вики, где описаны все хранилища, чтобы все опять знали, какое хранилище актуальное.
-
Он должен пробежаться по всем программистам и сказать им: «Переключите адрес, туда больше не кладите, кладите по новому адресу».
-
И чтобы пресечь все-таки случайные закладки («Почему в релиз не попало?» – «Блин, я не в то хранилище задачу поместил»), чтобы этого не было, в старом хранилище еще надо пойти и все объекты захватить, чтобы никто туда не начал закладки делать.
Это – проблематика.
Описание идеи и демонстрация реализации
Как все это починить? Чуть позже я продемонстрирую, как это все сделано, и покажу, где взять исходники. Но пока про саму идею и принцип.
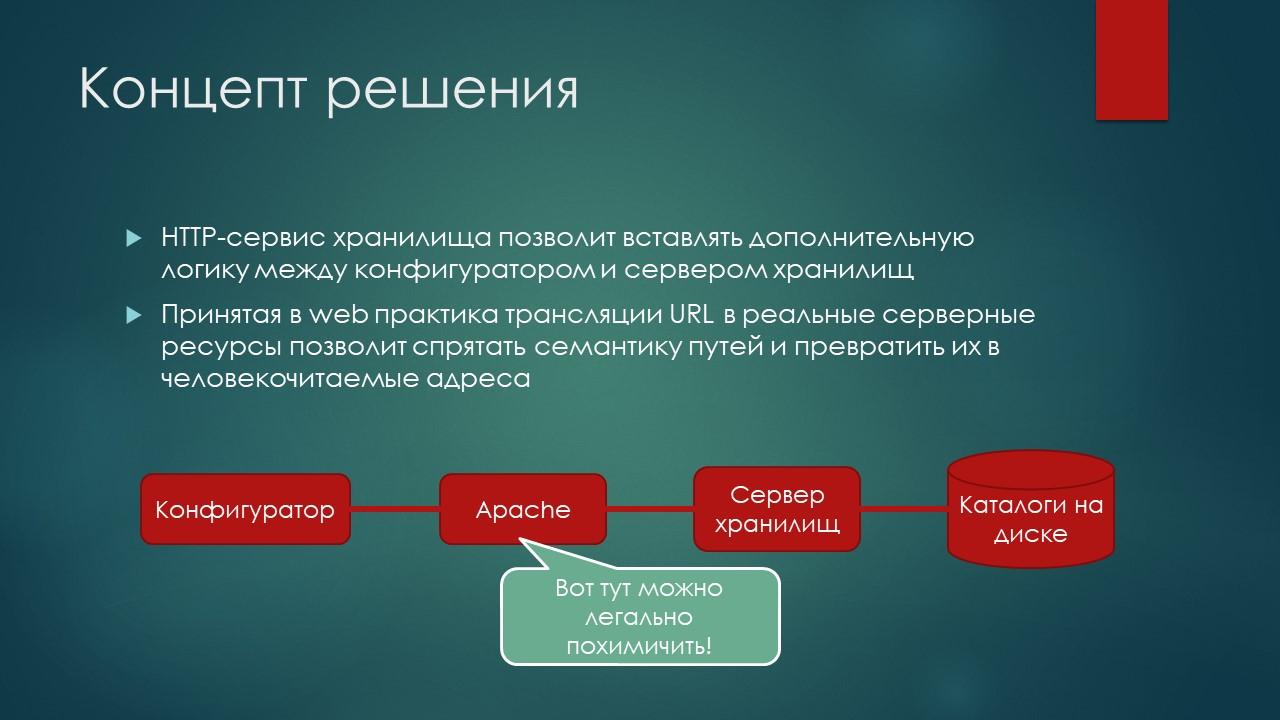
Допустим, у нас хранилище обрабатывается сервером хранилищ, которое работает по протоколу TCP. С помощью расширения веб-сервера мы можем сделать на его основе HTTP-хранилище. Это тоже штатная история фирмы «1С», когда мы ставим перед хранилищем сервер Apache, и хранилище становится HTTP-шным, и конфигуратор работает уже с Apache.
Так вот, в Apache богатые возможности для конфигурирования. И на стороне Apache можно немного «похимичить» и превратить URL-адреса, в которые заходит конфигуратор в правильные разрешенные нужные нам адреса на реальном сервере хранилищ, используя такую механику как URL-rewriting (переписывание адресов). То есть спрятать все эти страшные пути к файлу *.1ccr, которые непонятно, как писать, в красивую легко запоминаемую семантику путей. Создать человекочитаемые и человекозапоминаемые адреса.
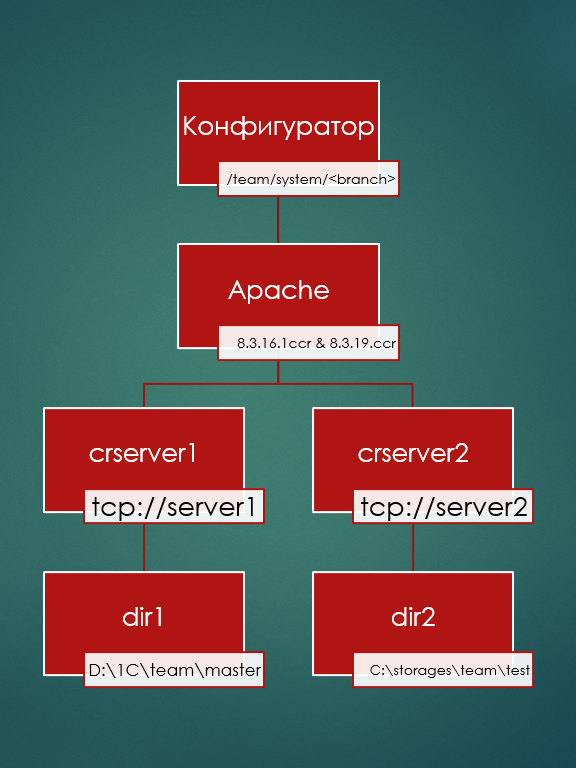
Более того, мы на одном и том же веб-сервере Apache можем разнести обращение к серверам разных хранилищ – находящихся на разных машинах, относящимся к разным версиям платформы и т. д. То есть у нас есть некий один Apache и много серверов хранилищ.
Причем, поскольку они работают по HTTP, они могут находиться не на этом же сервере, а на каком-то другом. То есть реальных серверов хранилищ, которые физически хранят данные на дисках, может быть много, но через конфигуратор мы будем обращаться к ним через один сервер. Таким образом мы можем точно так же прозрачно раскидывать хранилища по машинам, а разработчики про это даже знать не будут.
Вариант реализации для контроля доступа, управления версиями платформы, бизнес-логики при коммите в хранилище

Начинаем решать проблему.
Первое, что нам нужно сделать – это убрать неконтролируемый доступ к папкам, которые защищены сервером хранилищ. Нам нужно сделать так, чтобы конфигуратор не мог создать хранилище или подключиться к хранилищу по произвольному адресу, а мог создавать те или иные хранилища и подключаться к ним только по разрешенным адресам.
Как это работает:
-
Чтобы все работало, в Apache должен прийти запрос на адрес с файлом *.1ccr, в котором записана строка подключения к реальному серверу хранилищ. Мы должны будем запрятать настоящий ресурс 1С (*.1ccr) от внешнего доступа.
-
Берем Apache и добавляем в него rewrite rules, который переписывает входящий адрес в какой-то другой – и вот этот адрес /team/system (команда/система) мы внутри Apache меняем и переписываем его в /*.1ccr/team/system.
-
Таким образом, Apache сгенерирует уже реальный запрос, который работает с сервером хранилищ, а в конфигураторе у нас будет красивое правильное запоминаемое имя team/system. Согласитесь, что вариант слева на слайде проще запомнить, чем вариант справа.

Далее – как нам нужно запрятать от разработчика версию платформы, на которой крутится его хранилище?
Стандартно, когда у нас используется более новая версия, а потом мы решили откатиться к более старой, разработчику нужно переписать у себя в конфигураторе строку подключения.
Но если мы воспользуемся методикой, о которой сейчас пойдет речь, разработчик просто запускает новую версию платформы, подключается к той же базе с тем же путем, и его хранилище точно так же подключится и взлетит на новой версии – даже не придется ничего менять в строке подключения.
Поскольку мы переписываем имена «на лету» на стороне Apache, каждый внешний адрес мы можем связать с разными серверами хранилищ – сегодня с одним, а завтра с другим.
В конфигураторе там будет все тот же team/system, а вот эту branch-ветку можем прозрачно переключить на сервер хранилищ с другой версией платформы.
То есть на стороне Apache запрос на один и тот же входящий адрес мы можем кидать либо туда, либо туда. А в конфигураторе все будет то же самое.

И тут я наткнулся на очень интересный репозиторий на GitHub, и понял, что эту технологию с Apache можно еще больше развить и пойти еще глубже.
Нужно просто добавить в этот коктейль немного NGINX. Потом я пришел к мысли, что все настройки вообще можно сделать не на стороне Apache, а на стороне NGINX. Но эта мысль пришла ко мне чуть позже, и я уже не стал развивать ее в виде кода. Хотя это тоже возможно.
Если мы в этот коктейль добавим еще немного NGINX, мы сможем описать произвольную бизнес-логику, которая перехватывает то, что мы кидаем из конфигуратора на сервер, и как-то с этим работать.
Дело в том, что NGINX имеет внутри себя реально очень быстрый интерпретатор языка LUA. Это – язык, который я совершенно не знаю, но слава Google и Stack Overflow – в принципе, можно легко и быстро найти какие-то основные решения, а самое главное, что уже ребята из сообщества 1С-ников напилили несколько удобных решений по работе с хранилищем.
Так вот, мы можем туда вообще добавлять любую скриптовую логику.
Например, возвращать ошибку, если программист забыл написать комментарий. Если мы коммитим закладку из конфигуратора с пустым текстом, закладка не проходит, и в конфигураторе выдается ошибка «не могу положить изменения в хранилище».
Инструменты

В сообществе есть два готовых скрипта:
-
Первый – это веб-хук от Алексея Соснового https://github.com/asosnoviy/commitHook. Алексей – это тот самый «человек в шапке», который красуется на рекламном баннере конференции Инфостарта 2021 года. Идею использовать LUA с NGINX для хранилища придумал именно он – только не про пустые коммиты, а о том, как сделать событийную синхронизацию хранилища с GIT по коммиту, а не по таймеру каждые 5-15 минут. Он сделал скрипт для NGINX на LUA, который при поступлении коммита из конфигуратора вызывает сторонний веб-сервер. То есть когда коммит пришел, этот скрипт на LUA дергает веб-хук, в котором реализована какая-то произвольная логика на OneScript, JavaScript или чем-то другом. Туда даже HTTP-сервер 1С, наверное, можно повесить. Т.е. когда кто-то что-то кладет в хранилище, с помощью этого скрипта мы можем дернуть какой-то сторонний сервис и просигнализировать туда, что положили закладку в хранилище.
-
Второй плагин или скрипт для NGINX, который мне очень понравился – это фильтр коммитов от Дмитрия Овчаренко https://github.com/ovcharenko-di/crserver-filter. Вот он как раз позволяет проверить текст на соответствие правилам – указан ли там номер задачи, указан если там вообще текст, является ли этот текст длинным, а не просто номером задачи без пояснений (слишком краткое обозначение тоже неудобно). С помощью этого скрипта можно проверять текста коммита и управлять этой логикой перед коммитом. А за NGINX стоит Apache, и дальше – все как я говорил: rewrite rules, который переписывает адрес к хранилищу и все такое. Т.е. помимо того, что мы получили легкозапоминаемые имена и прозрачность от версии и от физического сервера, где лежит каталог с хранилищем, мы еще и получаем некую бизнес-логику перед коммитом.

Здесь уже, наверное, пора перейти от слов к делу.
Как получить профит?
На GitHub есть репозиторий Димы Овчаренко, который я немного доработал – добавил туда свой Apache и еще немного логики (сделал его чуть более модульным).
Эти изменения Дима у себя еще не успел принять, поэтому все это пока лежит у меня в ветке https://github.com/EvilBeaver/crserver-filter/tree/feature/modular, но потом будет лежать у Димы.
Как это все у себя организовать?
Начнем с Apache, а потом перейдем к уже к NGINX и фильтру коммитов.
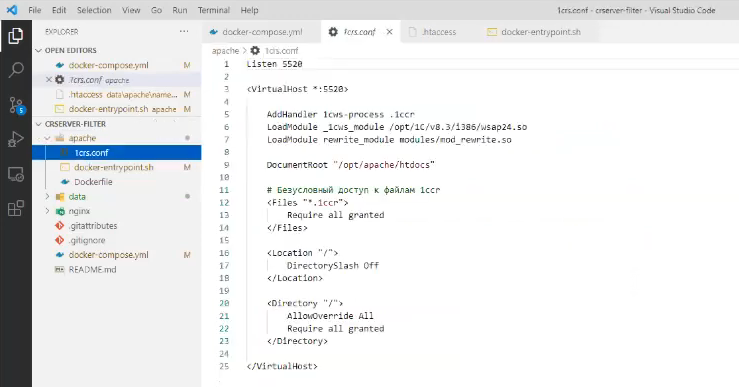
Для Apache мы почти штатно делаем установку HTTP-сервера хранилищ 1С – всё по инструкции с ИТС «Установка сервера хранилища».
Единственное, что основной конфиг-файл Apache 1crs.conf мы чуть-чуть переписываем следующим образом – добавляем туда:
LoadModule rewrite_module modules/mod_rewrite.so
И переопределяем правила доступа к корневой директории:
<Location "/">
DirectorySlash Off
</Location>
<Directory "/">
AllowOverride All
Require all granted
</Directory>
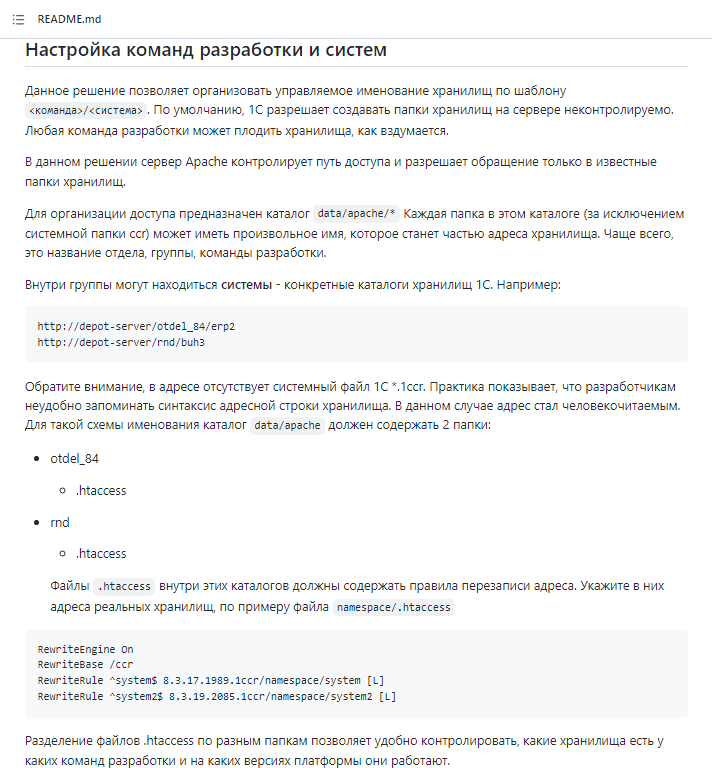
Как работает Apache? По умолчанию, когда мы обращаемся на сервер, Apache пытается отдать файл из физической файловой системы сервера – транслирует путь к странице как файловый путь.
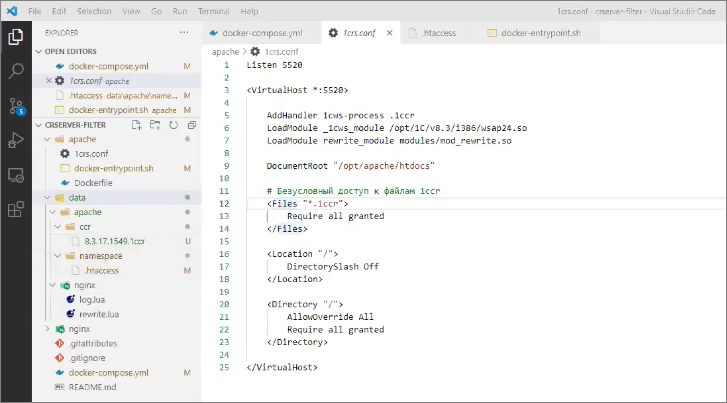
Представьте, что каталог data/apache – это корневой каталог на сервере Apache, на который замаплен корневой URL адреса сервера. Т.е. когда мы обращаемся в Apache по адресу http://server/, мы попадем в папку data/apache.
В этой папке у нас лежит каталог ccr с системным файликом 8.3.17.1549.1ccr и некая папка namespace с настройкой .htaccess – сейчас покажу, что это такое.
Допустим, нам нужно, чтобы в конфигураторе мы обращались к хранилищу по адресу:
http://server/namespace/system
Этот путь содержит:
-
некое пространство имен namespace, куда мы поместим хранилища конкретной команды разработки;
-
и некое имя (токен системы) system.
Т.е. папка namespace содержит настройки под конкретную команду разработки, а если у нас будет какая-то вторая команда (например, по разработке складских систем), мы создадим здесь еще одну папку, назовем ее wh.
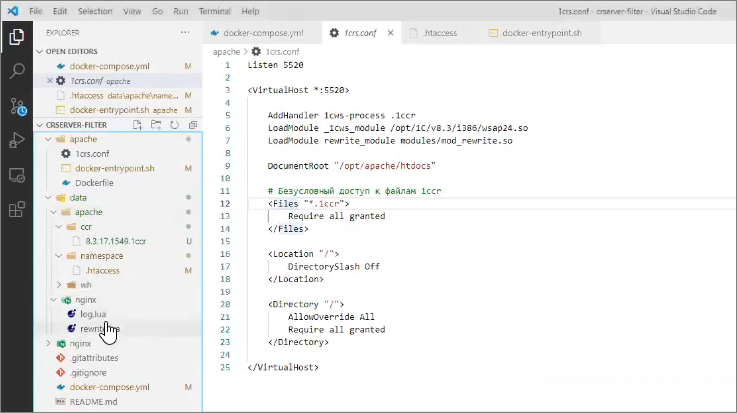
В папке wh я помещу настройки другой команды, у которой какие-то свои системы и свои версии платформы.
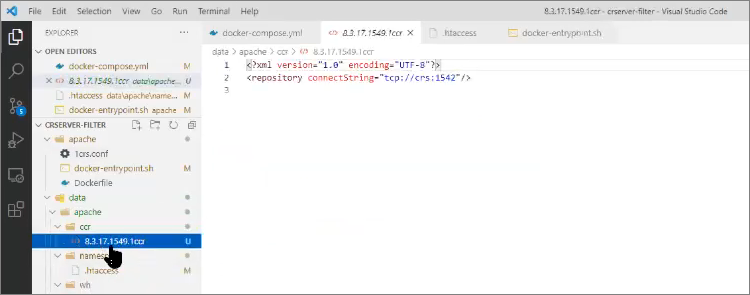
Что у нас лежит в файле 8.3.17.1549.1ccr?
Файл *.1ccr определяет путь к реальному хранилищу 1С, где лежит уже реальный сервер хранилищ 1С. Здесь может перечислено несколько путей – я рекомендую их делать по версиям платформы, потому что параметр connectionstring привязан к платформе.
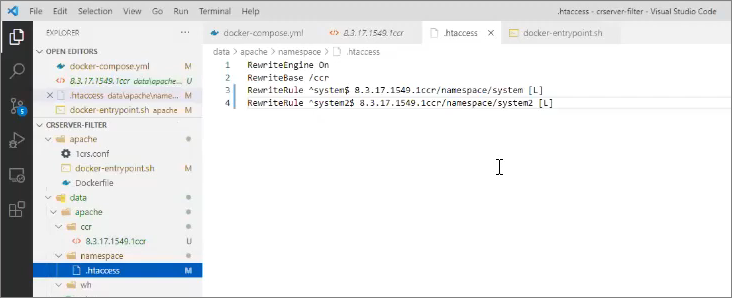
А внутри папки с настройками команды лежит файл .htaccess, который определяет правила переписывания адресов для Apache.
Файл .htaccess – шаблонный, его можно просто копировать/вставлять. Единственное, что мы здесь должны сделать – это переписать настройки для систем system и system2, установить сюда имена своих систем и перепрописать для них пути доступа к 1ccr-файлам, согласно версиям платформы, которые у нас лежат в каталоге ccr. Все, больше нам делать ничего не нужно.
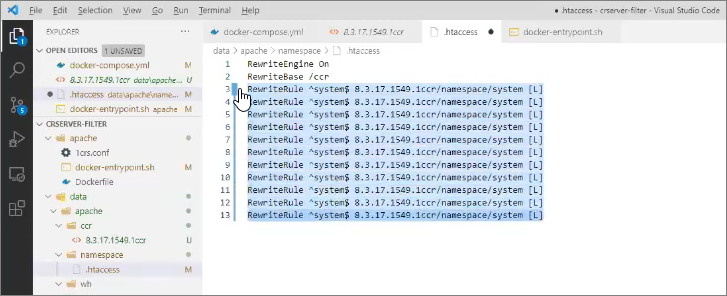
Здесь тимлид команды разработки может размножить строки для правил переадресации под свои системы, тем самым определяя, какие имена вообще доступны извне.
Теперь из конфигуратора куда попало обратиться не удастся – можно будет обратиться только к разрешенным именам.
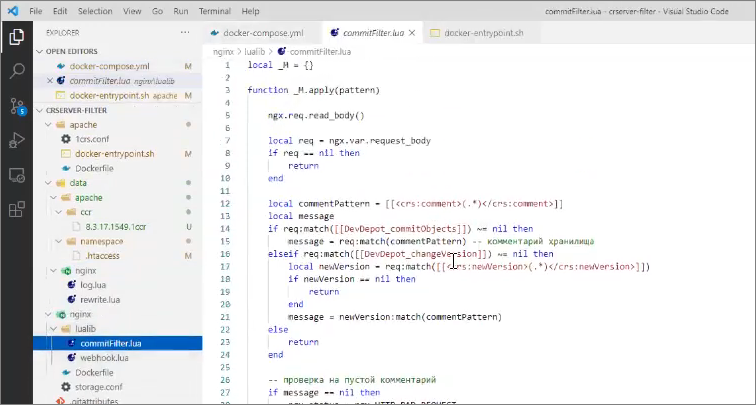
Что еще здесь важно знать?
Важно знать, что у нас перед Apache стоит NGINX, в котором у нас, помимо всяких конфигурационных файлов, лежат два библиотечных плагина на LUA:
-
тот самый webhook.lua от Алексея Соснового;
-
и commitFilter.lua от Димы Овчаренко.
Библиотечные плагины в NGINX – это как общий модуль, мы их не меняем. Это просто библиотечные функции, которые находятся в этом docker-образе, и мы их не трогаем. Но если интересна бизнес-логика, в них можно залезть и посмотреть, как они работают.
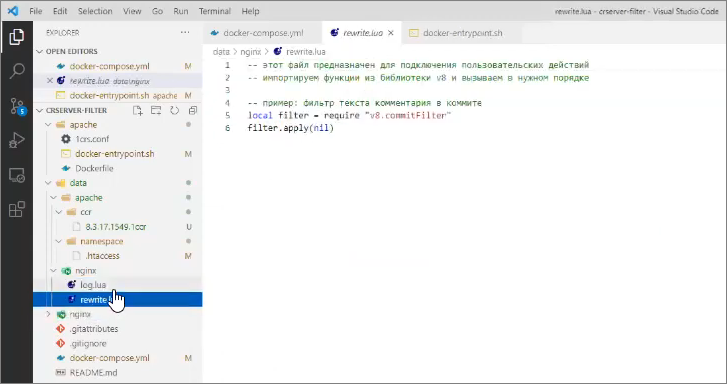
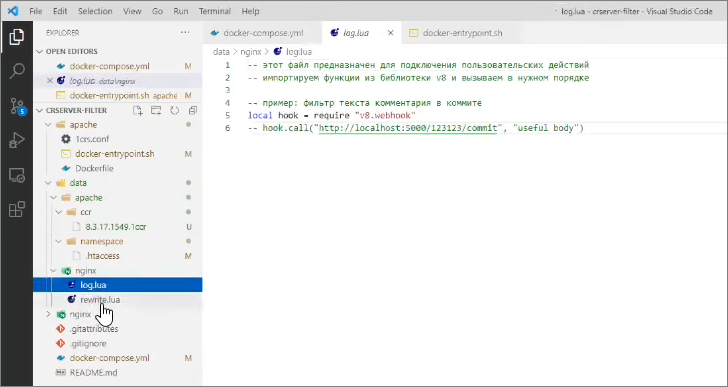
А то, что на нашей пользовательской стороне – то, чем мы должны порулить, реализуя бизнес-логику своей команды, это два файла: rewrite.lua и log.lua
Их название связано с этапами обработки запросов nginx (чуть позже я покажу, где это настраивается):
-
rewrite.lua выполняется в самом начале, еще до совершения HTTP-вызова,
-
log.lua выполняется в самом конце
В rewrite.lua мы можем подключить библиотеку v8.commitFilter – тот самый библиотечный общий модуль, который я сейчас показывал.
И дальше – вызвать этот фильтр, передав ему некое регулярное выражение на текст задачи.
-
Если текст коммита соответствует регулярному выражению, запрос пройдет.
-
Если текст коммита не соответствуют регулярному выражению, запрос конфигуратора не пройдет, и попытка закоммитить закладку с текстом, который не проходит регулярное выражение, отвалится.
Например, вызов filter.apply(nil) задействует фильтр пустых коммитов.
Этап логирования выполняется в самом конце обработки запроса – здесь удобно прописать веб-хук.
Когда уже все в хранилище успешно хорошо поместилось, ошибок не было, здесь мы можем сделать какой-то веб-хук на какой-то адрес, который запустит, например, gitsync или еще что-нибудь сделает – например, можно подписаться на коммит в хранилище.
Вы можете добавить сюда еще каких-то своих библиотечных плагинов – на что у вас фантазии хватит.
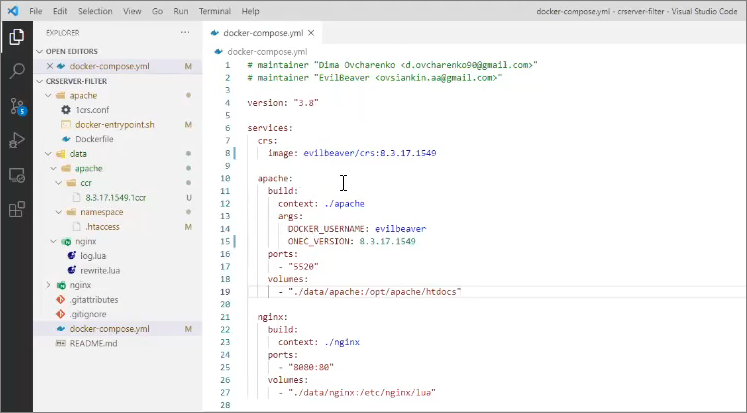
Чтобы все это завести вместе, я собрал файл docker-compose.
Здесь у нас есть три сервера:
-
crs – это сервер хранилищ. Это необязательно должен быть докеризированный сервер хранилищ – это может быть любой сервер хранилищ. В данном случае, поскольку в докере просто по одной строчке поднял – все работает. Отдельная благодарность ребятам из «Первого БИТа» за докер-репозиторий BITSemenovskaya, который содержит огромное количество готовых образов по докеру для 1С. Я просто взял у них готовый репозиторий с сервером хранилищ, поэтому мне не пришлось ставить самому себе 1С-ный сервер хранилищ, поднимать его, настраивать у себя локально Apache – я просто взял докеризированный сервер хранилищ. Он может быть любой. В данном случае для понимания всей этой технологии конкретный сервер хранилищ как раз не нужен – он может быть любой.
-
А вот настройки apache здесь требует понимания. Рассмотрим их.
-
Сервер Apache мы билдим из папки apache, чтобы прокинуть ему конфиг ./apache/1crs.conf (файл docker-entrypoint.sh и все остальное в папке ./apache нам не так важно).
-
Далее мы открываем для Apache порт 5520 – на этот порт будет ходить nginx.
-
И в качестве папки opt/apache/htdocs для этого образа мы примонтируем папку ./data/apache. Поскольку папка примаплена к моей реальной файловой системе, я могу, не пересобирая докер-образ, прямо при работе докер-контейнера здесь «на лету» что-то менять – подкидывать сюда версии хранилищ, создавать подпапки с настройками команд и т.д. Поэтому настройки Apache прокинуты внутрь него через папку на моей локальной файловой системе.
-
-
С nginx то же самое. Я здесь могу на самом деле написать любой порт, в том числе и 80, но у меня почему-то установлен порт 8080. И точно так же у меня тут примаплена папка с настройками ./data/nginx, где я прописываю мои реальные фильтры – регулярные выражения для коммита, будет ли вообще этот фильтр применяться и т. д.
Все, что нам осталось сделать – запустить все это дело командой docker-compose up.

Запускаем. Сейчас он у меня должен запустить некий стек. Запустился.
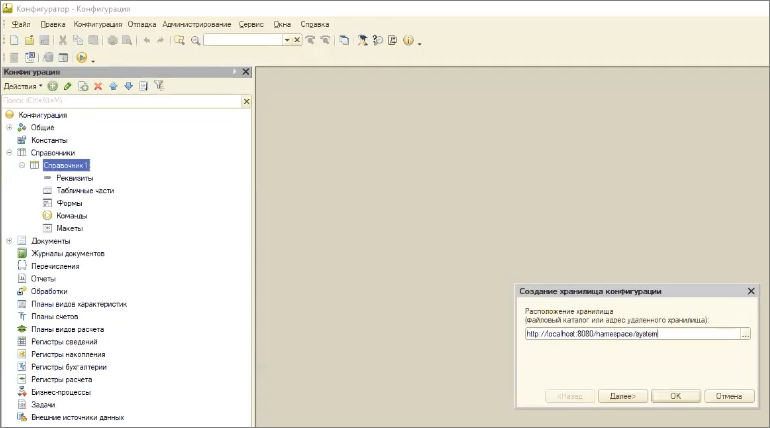
Теперь я запущу 1С версии 8.3.17.1549 – здесь у нас есть нехитрая система 1С с одним справочником «Справочник1».
Создаем хранилище конфигурации – в качестве его расположения указываем:
http://localhost:8080/namespace/system
Мы помним, что у нас в Apache есть папка команды namespace, внутри которой разрешена система с названием system (или system2). На сервере хранилищ они будут отображаться вот в такую папку.
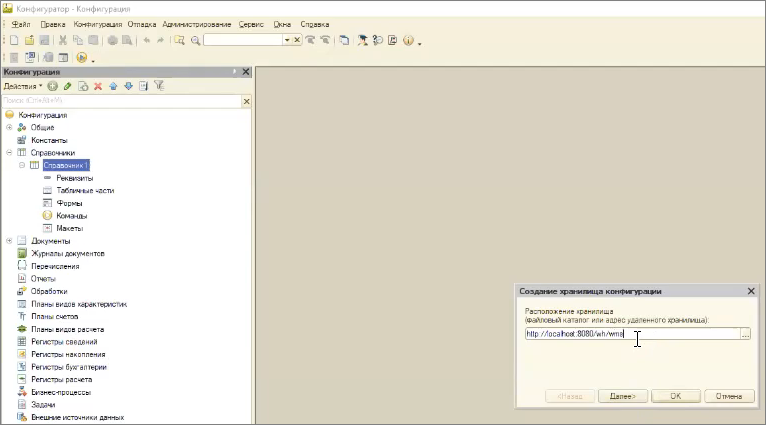
Допустим, если моя команда разработки склада называется wh и система wms – то такое хранилище я сейчас создать не смогу, потому что путь к папке wh на Apache запрещен.
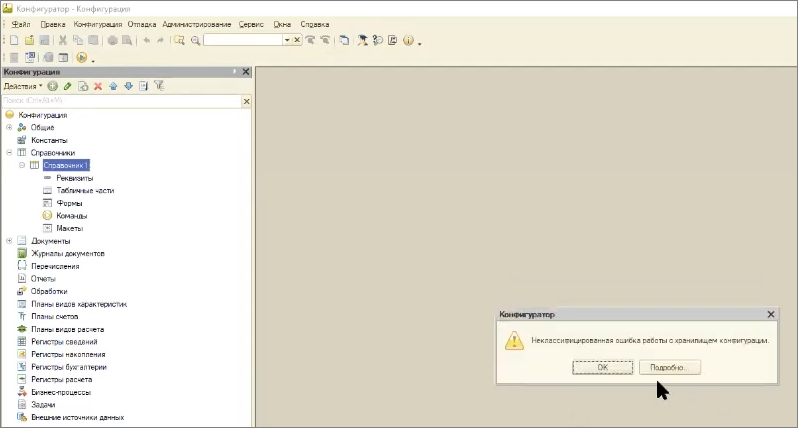
Демонстрируем – нельзя создать.
Перепишем на разрешенный адрес.
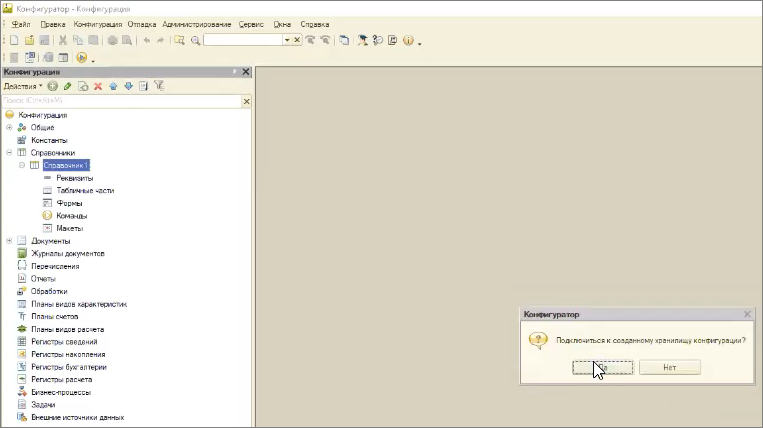
Работает! Это хранилище мы можем создавать и подключаться к нему.
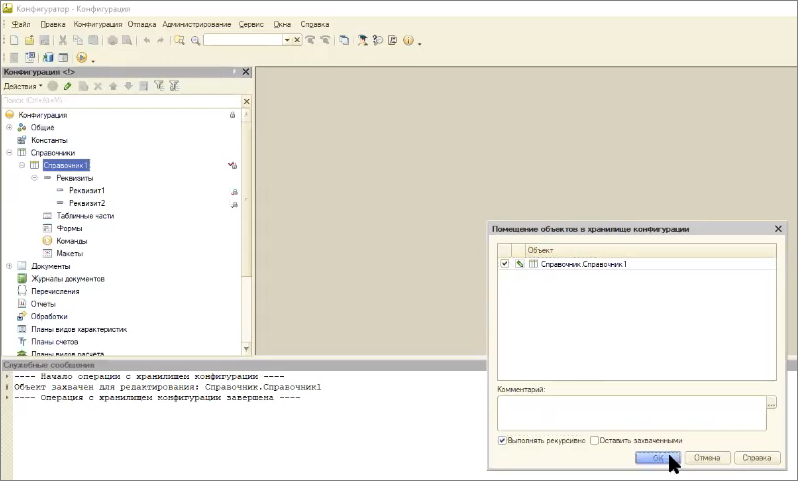
Дальше – добавим в наш справочник пару реквизитов.
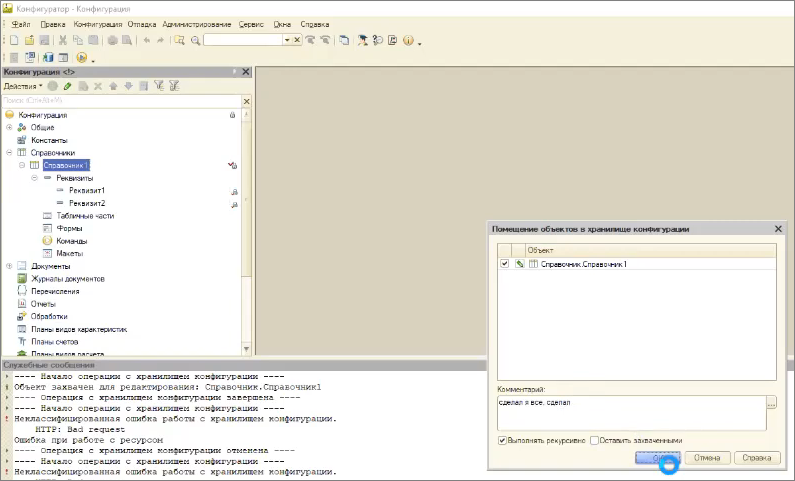
Захватываем его в хранилище, добавляем в него какие-нибудь реквизиты – Реквизит1 и Реквизит2. Сохраняем и пытаемся поместить с пустым комментарием.
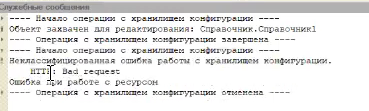
Задача не выполнена – вы видите HTTP: Bad request
Здесь наверное еще как-то поиграться и хакнуть то, как выглядит формат ошибки- исключения, которую сервер хранилищ бросает в 1С, чтобы 1С показала красивое окно ошибки, но так далеко я формат не ковырял.
Можно будет, в принципе, из NGINX вернуть некий xml, который конфигуратор 1С воспримет, как исключение, и покажет в виде красивого окна, но это надо будет немного еще покопаться с реверсингом.
Но даже вот такое – уже работает. То есть когда мы пытаемся заложить в хранилище что-то с пустым комментарием, нас не пускают – такая закладка не работает.
Теперь попытаемся положить с непустым комментарием.

Помещается – прекрасно работает.
Дальше – разработчики могут быть хитрыми, и могут в истории версий редактировать комментарии к предыдущим версиям хранилища. Соответственно, нужно запретить им обнуление комментариев к предыдущим версиям.
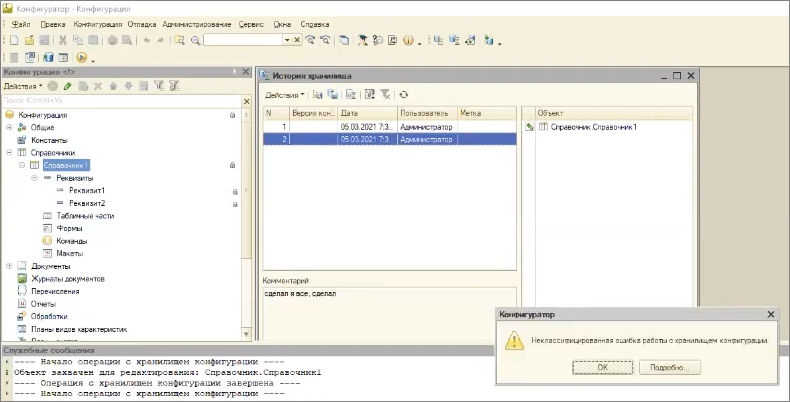
Обратите внимание, если я стираю комментарий, возникает ошибка, запрос не доходит до сервера хранилищ.
Здесь можно реализовать еще один плагин, который проверяет существующее значение комментария и вообще запретит операцию его изменения.
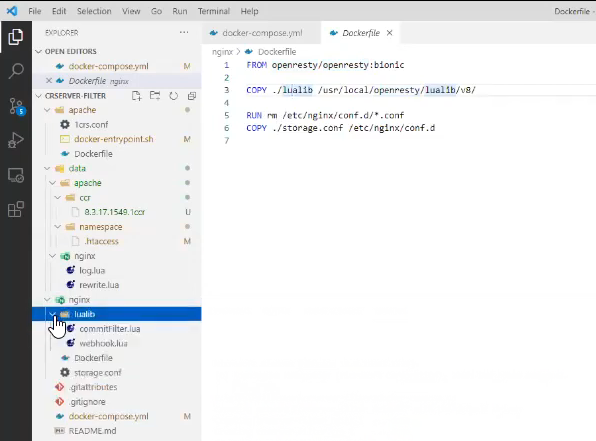
Давайте теперь посмотрим, как выглядит конфиг-файл для nginx.
В dockerfile для nginx у нас используется openresty – веб-платформа для nginx, которая как раз включает в себя интерпретатор LUA.
Из папки ./lualib мы копируем в каталог /usr/openresty/lualib/v8/ наши библиотеки.
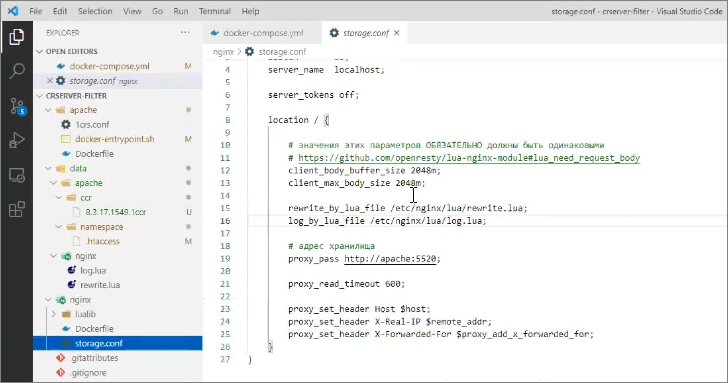
И сам location – адрес, который обрабатывается nginx, выглядит следующим образом: у него подключены вот два этапа:
-
rewrite_by_lua_file – который соответствует файлу rewrite.lua
-
log_by_lua_file – который соответствует файлу log.lua
Таких этапов, на самом деле, больше, но в данном случае мы подключаем только два.
И дальше – стандартный проброс портов. Мы говорим, что все, что пришло, нужно пробрасывать в Apache на порт 5520. Потому что, если вы помните, мы в настройках docker-compose разворачивали Apache на порту 5520.
Здесь на 11-й строке есть еще один лайфхак-оптимизация – если кому интересно, ссылочка https://github.com/openresty/lua-nginx-module#lua_need_request_body рассказывает, почему написаны 12-я и 13-я строчки, и как их писать по-правильному. У нас сейчас это немного костыль.
В принципе, правила RewriteRule можно написать сразу на стороне nginx – делать перезапись путей на стороне location.
Но мне показалось, что это выглядит чуть более сложно, потому что конфиг-файл nginx выглядит чуть более громоздко для 1С-ника, и разбираться в нем сложнее. А файл .htaccess тимлид-1С-ник вполне себе способен поддерживать – добавлять или удалять отсюда какие-то строчки.

Используемые инструменты:
-
веб-хук от Алексея Соснового https://github.com/asosnoviy/commitHook
-
фильтр текста коммита от Дмитрия Овчаренко https://github.com/ovcharenko-di/crserver-filter
-
доработанная версия фильтра текста коммита, которая демонстрировалась в ходе доклада – https://github.com/EvilBeaver/crserver-filter/tree/feature/modular
Вопросы
У меня в StartManager-е прописаны все пути к хранилищам. Удобно, не забывается.
Вы имеете в виду альтернативный стартер 1С? Да, он очень крутой, я тоже в свое время хотел такой написать, но меня опередили, сделали этот. Поскольку в нем реализовано все, что я хотел сделать, я отказался от реализации своего старт-менеджера.
Эта проблема касается не хранилища, а подходов к разработке. Должен быть регламент разработки и правила именования.
Да, но эти правила приходится заставлять соблюдать. А так это за нас делают роботы. Это чуть меньше головной боли и автоматизация контроля. В принципе, регламент разработки говорит о том, что нужно писать код без ошибок, но почему-то мы все равно тестируем наши программы. Казалось бы, зачем тестировать, да еще и автотестировать, если в регламенте разработке можно просто указать "запрещается писать код с ошибками"? Если все по регламенту сделали – должно быть и так хорошо. Но ошибки почему-то есть. То же самое – здесь.
Как быть с IIS?
В топку. Сжечь и похоронить.
Apache не умеет держать две разные платформы – как он две версии хранилища поймет?
Внимание, он умеет держать две разные версии платформы. Если мы берем туда вот эту wsap24.dll от какой-нибудь современной версии платформы, он тянет все предыдущие – я проверял. Библиотека wsap24.dll не меняется и не зависит от платформы, поэтому один Apache реально может держать разные версии платформы. Я проверял – работает.
А почему вы не ставите по Apache на каждую версию платформы?
На стороне nginx мы можем раскидывать это на разные Apache. Но, в принципе, один Apache держит несколько версий платформы.
Какую ошибку получит разработчик, если он не заполнил комментарий к коммиту?
Я уже говорил, что не смог заставить конфигуратор показать вменяемый текст ошибки. Наверное, потому что текст ошибки конфигуратор забирает из тела ответа. Там идет xml – некий rpc между конфигуратором и сервером хранилищ, и вот эту xml-ку нужно, по сути, сымитировать и пробросить в конфигуратор. Тогда он, наверно, покажет какую-то красивую ошибку. Сходу это сделать не удалось.
Я пробовал прописывать body в теле ответа от nginx, но этот ответ не показывается – конфигуратор показывает только «Bad request». В принципе, возможно там в статусе ответа можно попытаться что-нибудь пробросить, но я не пробовал. Если совсем по красоте, то нужно вот здесь в теле ответа закинуть xml-ку, которую конфигуратор прожует. Но для этого нужно пореверсить трафик и понять, чем они обмениваются. Я этим не занимался, но, наверное, как развитие этой истории – это возможно.
Инструкцию по развертыванию описанной схемы где можно получить?
Там же в репозитории достаточно большая REDME.md
IIS умеет несколько версий, а Apache, увы, нужно дублировать.
Нет, не нужно, у меня не дублируется. Но я допускаю, что это возможно, поэтому несколько Apache можно раскидать на location nginx, но в целом, у меня и один работает.
Очень нужная вещь – у нас с ней народ привык комментарии писать. Но все равно ошибки могут быть.
Чтобы не было ошибок, ему можно еще и регулярку подкинуть, чтобы вначале стоял, допустим, номер задачи из Jira. Регулярка позволяет вам проматчить любой текст.
У нас Apache на большой нагрузке в 1С (более тысячи пользователей) падает.
В одном хранилище тысяча разработчиков? Я такого не видел никогда. Если у вас большая команда разработки на тысячу пользователей, посадите их на несколько разных Apache. Действительно, вы можете разгрузить этот Apache на несколько серверов.
В nginx можно переопределять сообщения для HTTP кодов.
Я тоже думаю, что их можно переопределять, но я просто не попробовал. Наверняка это можно сделать.
Можете рассказать, как настраивать несколько версий платформы на Apache?
Берем конфиг Apache – 1crs.conf, подключаем в него модуль расширения веб-сервера wsap24.dll от той платформы, которую хотим использовать. И теперь мы просто внаглую им пользуемся для разных версий платформы. Это не документировано, но это работает без какой-либо донастройки.
Мы просто берем модуль wsap24.dll, какой у нас есть, и потом в папке ccr прописываем пути к хранилищам разных версий. Здесь можно прописать путь к хранилищу другой версии – будет работать. Единственное, что это не документировано. И я действительно допускаю, что какие-то комбинации не станут работать. Но я не встречал. Если такое случится, на помощь приходит nginx – тогда мы в его файле настройки storage.conf уже выбираем не Apache, а Apache1, Apache2, Apache3 и т.д., разруливая такую коллизию на nginx.
Но вообще можно просто внаглую заюзать модуль wsap24.dll от какой-нибудь 1С 8.3.19 – и все версии 8.3.16, 8.3.17, 8.3.18 с ним так же прекрасно работают.
Apache – это хорошо, но он не всегда ладит с 1C:ERP, поэтому соединение приходится переключать на TCP.
У Димы Овчаренко тоже 1C:ERP, и он говорит, что на большой нагрузке 1С:ERP у него вся эта конструкция тянет – все прекрасно работает.
Но я допускаю, что на больших конфигурациях возможны проблемы. В TCP тоже, наверное, можно будет реверсить трафик, но это уже сильно сложнее – здесь уже конфигами nginx не обойдешься.
А если Apache не под Linux, а под Windows – работать будет?
Я думаю, что разницы нет. Apache необязательно должен работать под Linux, он и под Windows работает. Разные версии платформы все равно на нем можно запускать – по крайней мере с теми версиями платформы, на которых я проверял. Если вдруг все-таки на каких-то версиях wsap24.dll действительно поменялся и перестал работать с какой-то из версий, тогда мы это раскидываем на уровне nginx на разные Apache.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "DevOps в 1С: Инструменты автоматизации рутины в 1С-разработке".

