Любая тема имеет маленькую предысторию, и у меня тоже есть такая.
Говорят, все программисты делятся на два типа: те, кто еще не используют систему контроля версий, и те, кто уже используют. Я всегда относился ко вторым – у нас в компании с самого начала были хранилища, в этом плане всегда было все строго.
Но в прошлом году я совершил фатальную для себя ошибку. В рамках подготовки к докладу в Казани я попал в «режим потока» – целую неделю собирал наши наработки в виде библиотеки, которую планировал выложить. А к концу недели, не знаю, в каком состоянии, случайно всё грохнул.
Это было крайне неприятно.
В тот момент я решил – такого больше не повторится. Хранилища – наше всё.
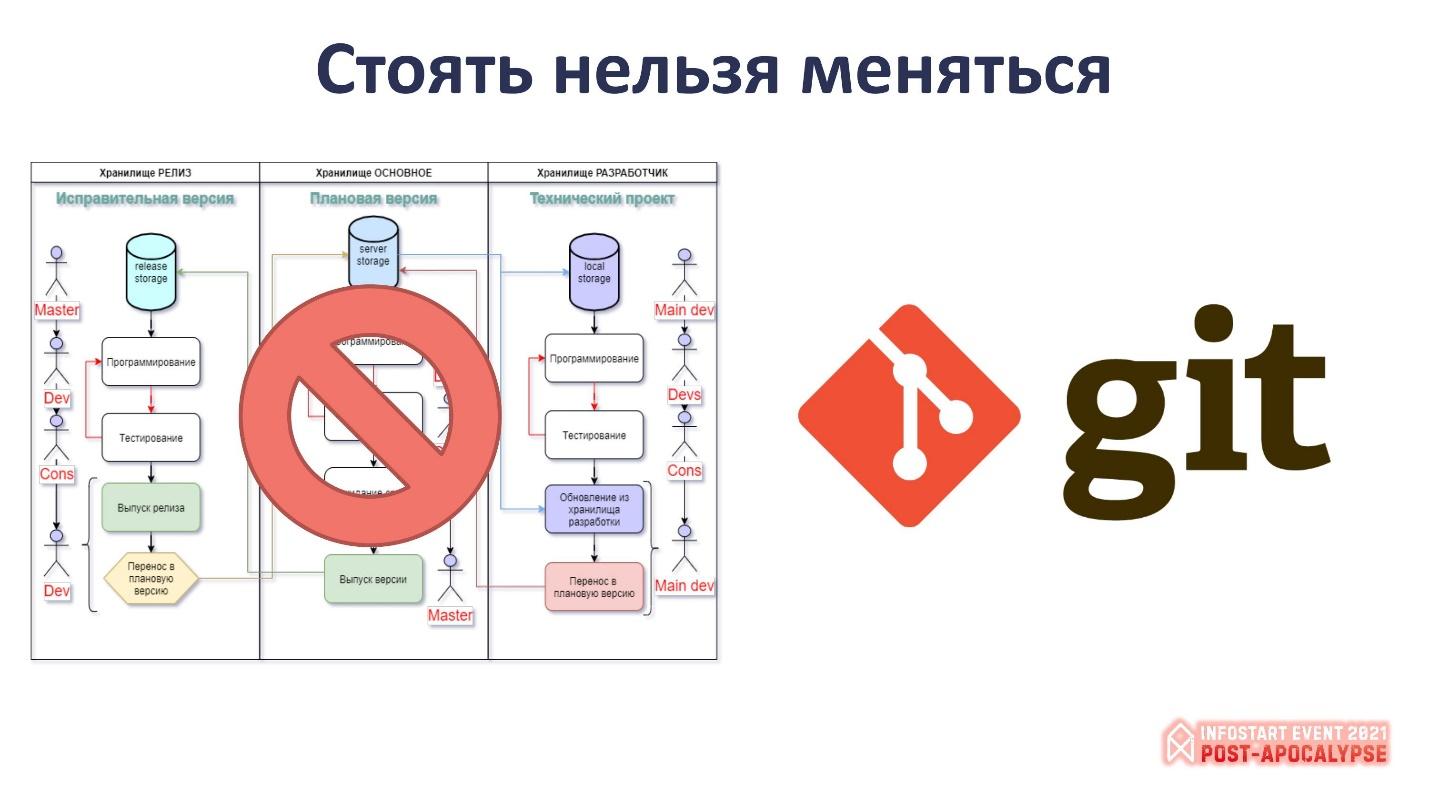
Слева на слайде – схема о том, как у нас раньше в компании была устроена групповая разработка.
Мы использовали несколько хранилищ:
-
основную ветку хранилища для разработки плановой версии;
-
хранилище для исправительных версий;
-
и технические проекты у каждого программиста.
Схема была непростая, поэтому для pet-проектов я ее не использовал – я делал все гораздо проще.
Но дело не в этом – тот доклад я благополучно закончил, а потом началась всем известная самоизоляция, и у меня, человека, которвый много кодил в компании, кодинга как такового не стало. Мне пришлось вспомнить, что я в первую очередь руководитель. Все ребята работают на удаленке, у всех есть задачи, а я сижу и ничего не могу делать. Бизнесы морозятся, деньги не приходят – всё очень вяло.
Есть такая шутка «Когда вы понимаете, что всё идет не так, самое лучшее, что вы можете сделать, – это пойти учиться». И я записался на курсы «DevOps в 1С» от Инфостарта. Курсы, кстати, очень классные, рекомендую. Спасибо всем ребятам, кто их вел. Информации действительно было много.
После этого мы в компании перешли на Git вместо хранилищ, у нас появились элементы Continuous Integration (CI), и даже что-то из Continuous Delivery (CD).
И вроде бы всё хорошо, но «серебряной пули» не случилось – я как руководитель не понял, в чем мы выиграли. Я чувствовал, что проблема есть, но в чём она, не мог для себя понять. И в какой-то момент стало приходить осознание, что проблема не в инструментах, а в головах.
Поэтому перед тем, как начать говорить о теме Continuous Integration, давайте просто поговорим про коллективную разработку.
Почему конфликты в Git обсуждают всем миром, а сравнение/объединение в 1С – это нормально?
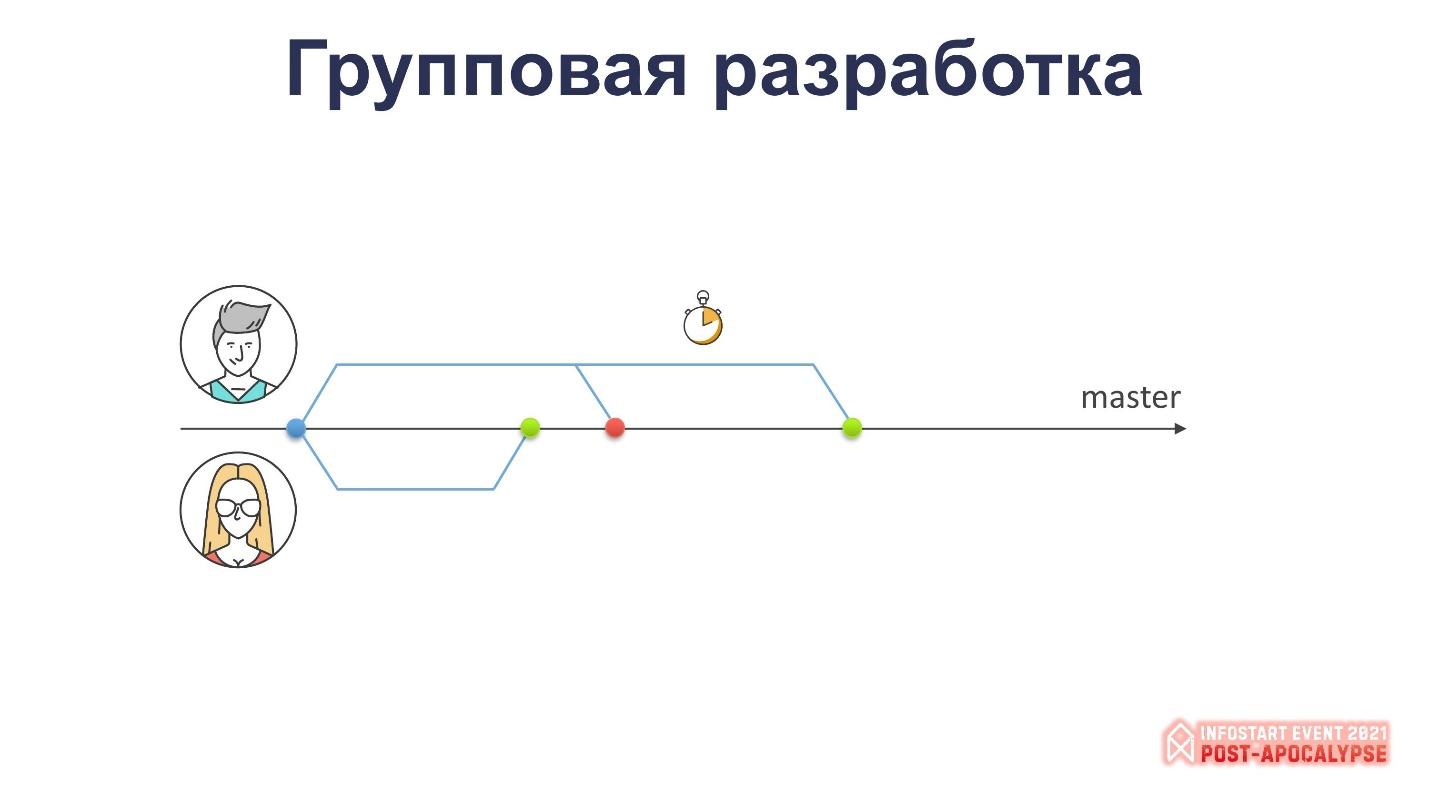
Итак – групповая разработка. Это когда есть два программиста, которые работают над некой веткой основного хранилища. Здесь написано, что эта ветка называется master, но это не важно.
Они берут задачи и начинают работать.
Первый программист заканчивает работу раньше – он заливает свои изменения, у него никаких проблем.
Второй программист закончил работу немного позднее, и у него, естественно, вышла проблема, о которой вы и так прекрасно знаете – для заливки своих изменений ему нужно сделать сравнение-объединение.
Получается, что вместо того, чтобы делать что-то дальше, мы теряем время на то, чтобы это слить. И это – простой пример. В жизни всё гораздо сложнее, не мне вам рассказывать.
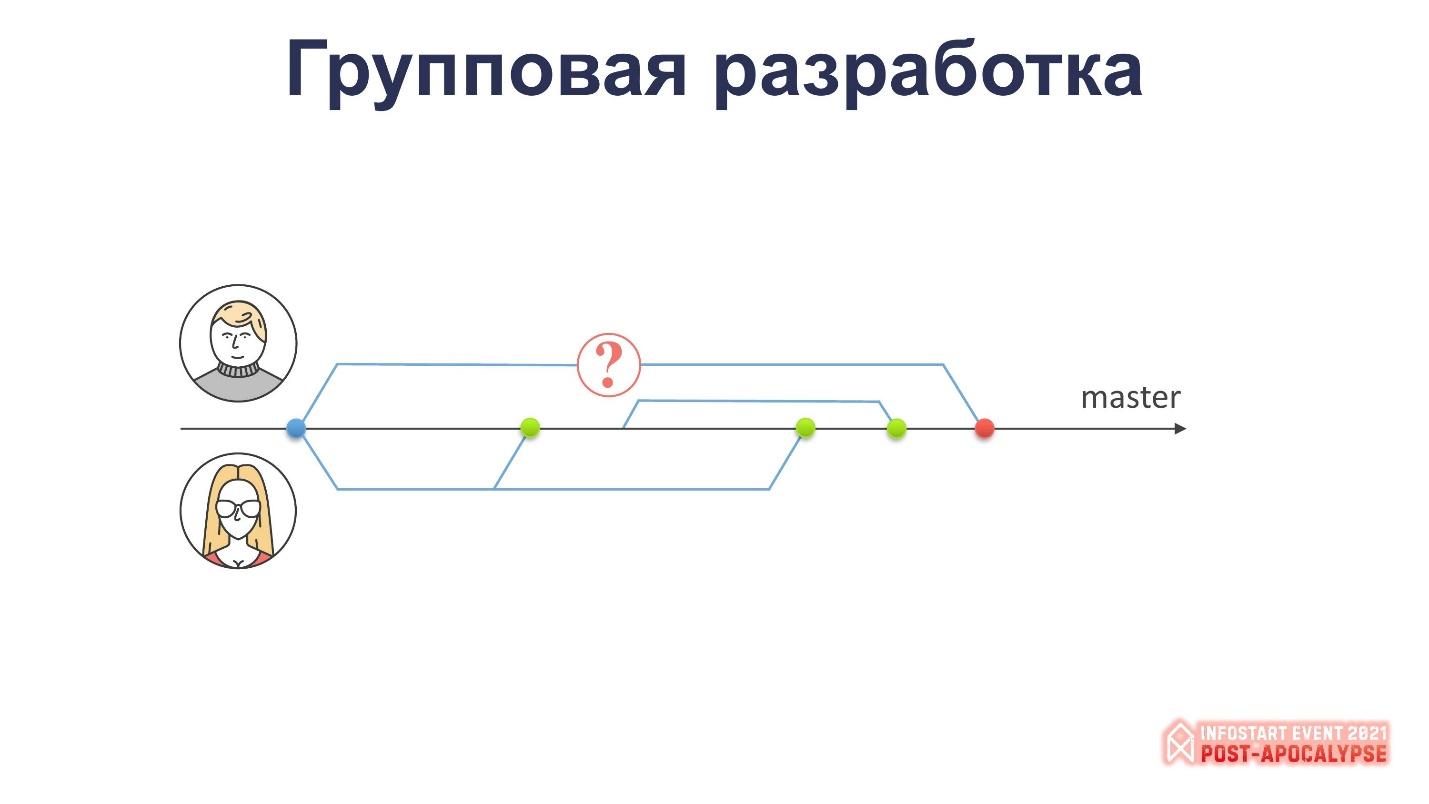
Давайте возьмём ещё одну популярную практику, когда к программисту добавляется молодой падаван, и появляется такая тема как пул-реквест. Через механизм пул-реквестов часто проводится код-ревью – интересный способ потешить своё самолюбие на фоне молодых специалистов.
Начинается все так же, как в предыдущем примере – оба разработчика берут свои задачи и начинают над ними работать. Наш опытный специалист заливает первую задачу и начинает работать над второй. В это время молодой специалист ему говорит: «Я закончил, посмотрите мой код». На что опытный программист отвечает: «Да-да, конечно, я посмотрю, только закончу свою работу и обязательно всё посмотрю».
Молодой программист у нас энергичный, талантливый – он берет новую задачу, начинает её делать, сливает её. А ему в это время: «Парень, я твою задачу посмотрел – давай, заливай!»
Как вы думаете, какие чувства будут у молодого разработчика по поводу этого? Он там когда-то в прошлом году закончил эту задачу, с тех пор в основной ветке уже многое поменялось, а ему говорят «вперёд, заливай». Это, в принципе, нормально?
Программист без интернета – это уже CI
Здесь стоит рассказать о том, какую боль изначально хотели решить люди, которые придумали концепцию Continuous Integration. В чем вообще заключается боль совместной разработки.
Концепция Continuous Integration родилась достаточно давно – Гради Буч сформулировал практически 30 лет назад (в 1991 году) в рамках практики экстремального программирования.
Переводится Continuous Integration как «непрерывная интеграция». Но давайте немного разберемся, почему она непрерывная и насколько глубоко производится интеграция.
-
Под интеграцией в этом термине подразумевается то, что каждый должен стремиться работать с актуальной версией, т.е. чаще заливать в основную ветку, меньше вызывать конфликтов. И, в общем, интеграция – это про то, как дотащить ваш код до master’а, ну или до основного хранилища – как ни называйте.
-
А Continuous она потому, что нужно интегрировать ваш код как можно быстрее – буквально каждые несколько часов.
Конечно, тут еще возникает вопрос ответственности, и на сцену выходят такие инструменты как Jenkins и автотестирование. Но я не хотел бы сейчас забегать вперед, потому что Continuous Integration вы можете организовать и без дополнительных инструментов проверки и тестирования. Как только вы отключите интернет и сядете кодить, у вас сразу начнется Continuous Integration – вы взяли задачу, сделали ее и залили в master; опять взяли, опять сделали и залили. И так далее – чем не CI?
И здесь всё хорошо, пока в коде разработчиков не появляются какие-то конфликты, и мы не начинаем терять время на их разруливание и заливание изменений в программу.
Если мы заливаем реже – конфликты больше, мы решаем их дольше – мы опять заливаем реже. Это как снежный ком – чем дольше задачу будешь решать, тем больше проблем будет с заливкой.
Приведу хороший личный пример: у меня в компании есть программист, отличный специалист, я его очень уважаю, но у него есть любимая привычка взять какую-нибудь задачу, уйти на неделю в состояние астрала и выкатить маленький коммит размером с пол-конфигурации. А тут ты со своим маленьким изменением в роли пришёл и где-то на два часа завис, чтобы просто понять, что он вообще там натворил. Ничего не могу с этим поделать. Борюсь, как могу, но это моя боль как руководителя в данном вопросе.
У нас в 1С со сравнением-объединением вроде нет никаких проблем – все красиво в окошечке решается, но чтобы этого окошка дождаться, нужно время-время-время…
Те, кто работают с крупными конфигурациями, точно лучше меня скажут, сколько нужно времени, чтобы подождать, пока просто окно появится. А задачка-то ваша, может быть, маленькая.
Решение – декомпозиция задач
Теперь надо поговорить о том, как эту проблему будем решать.
Моё предложение – это декомпозиция задач.
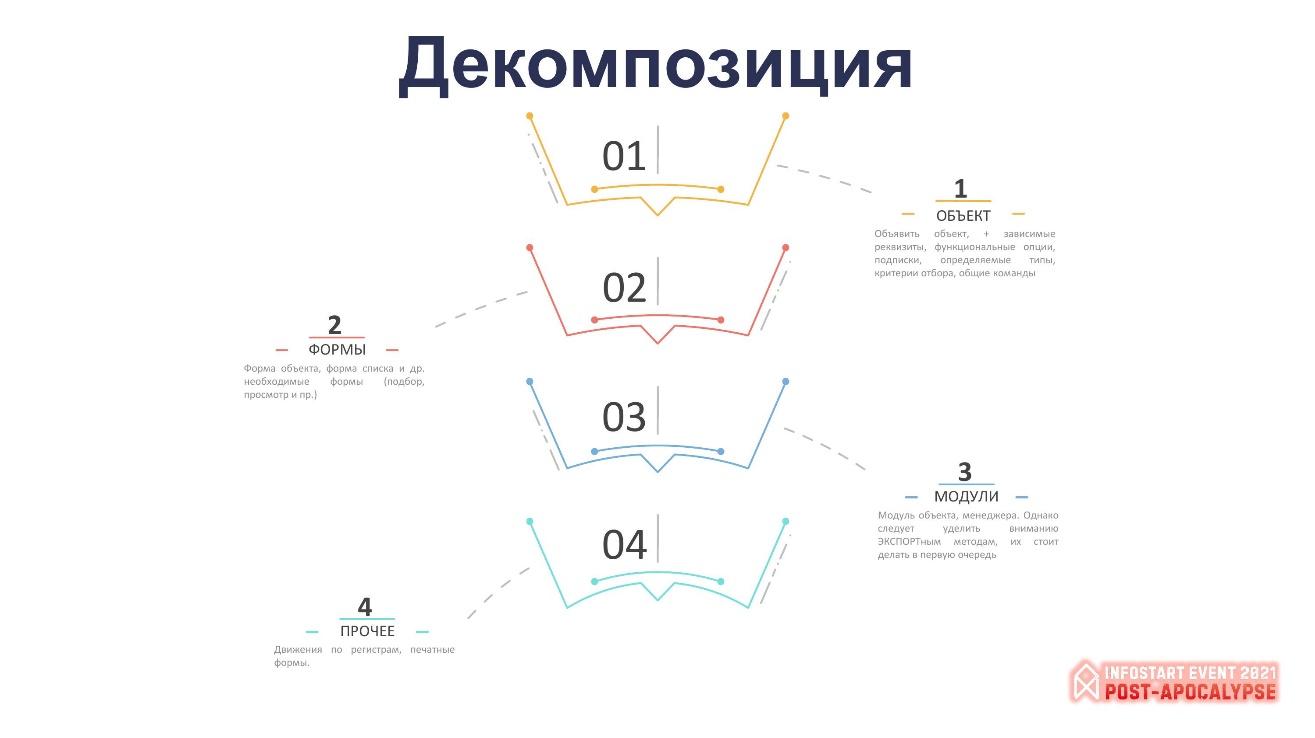
Разбивать задачи – тема популярная, но давайте поговорим на конкретном примере, как это сделать в 1С. Возьмем конкретную задачу – реализовать документ «Реализация» или «Счет на оплату». Задачка в целом на один-два дня – даже если у вас есть особые требования к юзабилити интерфейса, за пару дней вы должны справиться. Простейший пример.
Если помните, что документ состоит из:
-
объекта и его набора реквизитов;
-
из форм;
-
из модулей объекта и менеджера, где описана бизнес-логика работы с документом;
-
из движений по регистрам и из каких-то печатных форм, которые мы получаем на выходе.
Здесь как раз стоит упомянуть про Git.
-
Всё, что вы меняете в коде – это текст с расширением *.bsl, и это легко мержится средствами самого Git, тут вообще нет никаких проблем.
-
Но всё, что касается изменения конфигурации, перестроения дерева – это всё изменение xml-файлов. И, к сожалению, это проблема общая – Git никак не мержит xml. Это проблема не только в 1С, это проблема всех, у кого есть xml-ки. Да, для этого есть какие-то инструменты, но круче 1С-овского сравнения-объединения, на самом деле, ничего для нас нет.
Поскольку мы решили разбить задачку на несколько частей, я бы рекомендовал строить декомпозицию, исходя из тех ограничений, которые у нас есть в рамках работы с Git. Сразу оговорюсь, что эта методика подходит только для случаев «быстрой разработки», когда один этап не затягивается на недели – максимум, вам нужно постараться закончить свою задачу в рамках дня.
-
У нас задача сделать документ, значит, первым делом мы должны максимально быстро накидать сам объект, его реквизиты и его табличные части. Никаких форм, никаких внешних интерфейсов. Вместе с документом мы закидываем какую-нибудь функциональную опцию, например, «ТестовыйРежим», на который повесим этот документ, чтобы в случае чего его можно было спокойно отключить. И заливаем это в конфигурацию. Поскольку изменений очень мало, слиться с такими изменениями большой проблемы не составляет. Если, конечно, у вас не будет конфликта на уровне configuration.xml, когда вы добавляете какой-то объект в конфигурацию одновременно с другим специалистом. Но на то вы и команда, чтобы такие моменты разрулить: «Давайте сейчас я объект добавлю, а потом вы дальше двинетесь. Мне нужно 5 минут».
-
После того как мы залили объект и поменяли configuration.xml, следующим этапом я предлаю посмотреть в сторону форм. Здесь вы уже можете зависнуть подольше, потому что требования к формам существенные, тем более, что в современном мире к usability предъявляются повышенные требования. Но у форм, хоть они и хранятся в репозитории в виде xml-файлов, на самом деле нет проблемы мержинга, потому что заливаются они легко, и вряд ли в это время кто-то сильно полезет в ваш объект.
-
На третьем этапе мы можем совершенно спокойно писать все свои модули с экспортными методами, дописывать их, менять. Текст любого модуля прекрасно мержится средствами Git’а – даже не нужно вспоминать, что у вас есть конфигуратор. Грубо говоря, если другой специалист параллельно со мной делает новый документ, я его изменения смогу подтягивать прямо к себе, мне для этого не нужно пересобирать конфигурацию. Когда у меня будет 15 минут перерыв, я смогу слить свои изменения, забрать его изменения и пересобрать конфу заново.
-
Ещё один момент: мы не работаем с EDT по одной простой причине: пока там отсутствует механизм поддержки. Мы, к сожалению, в рамках принятой нами технологии разработки не можем отказаться от этого механизма – у нас очень много библиотек, как собственных, так и сторонних, которые мы держим в поддержке, и, к сожалению, EDT нам пока не даёт к нему прикоснуться.
-
Ну и на конец мы оставляем доработку движений по регистрам и реализацию печатных форм. Здесь на самом деле всё просто. Можно много спорить, но большинству пользователей глубоко фиолетово, какие регистры при проведении двигаются, и что просходит под капотом вашего документа. Главное, какой отчёт они в конце получат.
Если немного забегать вперёд и смотреть не только в сторону CI, но и на CD (Continuous Delivery, когда мы тоже максимально быстро доставляем до заказчика), этот механизм позволяет вам уже на втором этапе показывать заказчику прототипы каких-то объектов.
Но, естественно, вы должны соблюдать при этом правила безопасности. Поэтому:
-
накиньте функциональную опцию, чтобы механизм можно было отключить;
-
старайтесь не делать резких движений по изменению существующей логики;
-
а иногда просто не поленитесь немного продублировать код, если понимаете, что ваш новый объект сильно меняет какую-то логику конфигурации.
Почему я акцентирую внимание на необходимости декомпозировать задачи, почему считаю это проблемой?
Я как управленец отвечаю не только за тот код, который мы делаем, но и за то, как думают аналитики. Если они ставят задачу, не декомпозируя её на части, не предполагая её выкатывать клиенту по частям, не предполагая обкатывать какие-то теории и тестовые экземпляры – все бесполезно. Вам выкатят большое ТЗ, и даже если вы будете так работать, весь профит, который вы получите, замкнется внутри вашей команды. Но для заказчика профита не будет. Я же, решая сегодняшние задачи разработки, стараюсь смотреть вперёд.
Пруфы в студию

Эта тема не новая – Google проводит ежегодные исследования State of DevOps. Здесь показан их слайд из доклада 2019-го года (рекомендую почитать вариант, переведенный на русский язык от Николая Воробьева-Сарматова).
Google нашёл связь между тем, как часто вы заливаете изменения и тем, насколько качественный у вас получается результат.
Они вывели несколько показателей продуктивности программного обеспечения – их всего четыре:
-
частота развертывания;
-
срок реализации изменений;
-
время восстановления сервиса;
-
доля неудачных изменений.
Если закрыть один глаз и засунуть голову в песок, то я, в принципе, могу считать, что моя компания находится в элите – у нас вообще все круто, потому что:
-
отдельно взятый программист у меня в компании готов всё развернуть по нескольку раз в день;
-
срок реализации изменений у него всегда меньше одного дня;
-
время восстановления сервиса – он взял быстренько в расширение киданул маленькую зашлёпку, и всё работает;
-
а доля неудачных изменений? Какие неудачные изменения, он за секунду всё поправил.
Т.е. высокая степень эффективности доставки ПО коррелирует с исполнителем и его желанием работать сверхурочно.
Но мы же понимаем, что по мере роста компании всё может сильно усложниться.
Чем больше программистов у нас будет, и чем больше задач у них будет в работе, тем будет хуже. И мы вдруг заметим, что свалились уже до одного релиза раз в месяц, а то и раз в несколько месяцев. А срок реализации изменений может растянуться на несколько месяцев, потому что задача у нас в бэк-логе может валяться чёрт знает сколько времени, и мы вообще не хотим ничего трогать, ну и так далее.
Перестаньте рекомендовать Gitflow
Здесь я хочу рассказать об еще одном мнении на организацию разработки: в 2015 году компания Thoughtworks в своем Technology Radar «накинули на вентилятор» сообществу и поставили любимую многими методику Gitflow в состояние hold – выразили сомнение в том, что она помогает организовывать DevOps в компании.
Методику GitFlow придумал Винсент Дриссен – в 2010 году он опубликовал статью с ее описанием. А в 2020 году выложил к своей статье 10-летней давности маленькую аннотацию. Ее примерный текст:
«Модель Gitflow была задумана более 10 лет назад, и она стала своего рода стандартом, а для кого-то – догмой или даже панацеей. Если вам нужно поддерживать несколько версий ПО, Gitflow по-прежнему подходит для вашей команды. Но если вы используете непрерывную поставку, это не лучший выбор. Панацеи нет, всегда думайте своей головой. Проблема Gitflow – в дисциплине, потому, что ветки feature и release могут висеть примерно вечность».
Кто работал с Git’ом, прекрасно знают, насколько это удобный инструмент – ветка создается за доли секунды, убивается за доли секунды, мержинг и переключение очень быстрые, всё работает очень хорошо.
Но то, что ничего не стоит – обычно не ценится, и часто получается так, что за состоянием созданных веток никто не следит. А при Gitflow количество веток для вашего проекта будет множиться на количество программистов, и вы будете иметь несколько версий одного кода – несколько версий одной правды. Это будет только путать и усложнять процесс разработки.
Я не призываю вас отказаться от ветвления, но я хочу сказать, что время жизни различий в этих ветках должно быть коротким.
Критикуя – предлагай. Если Gitflow – не лучший выбор, то что можно использовать?
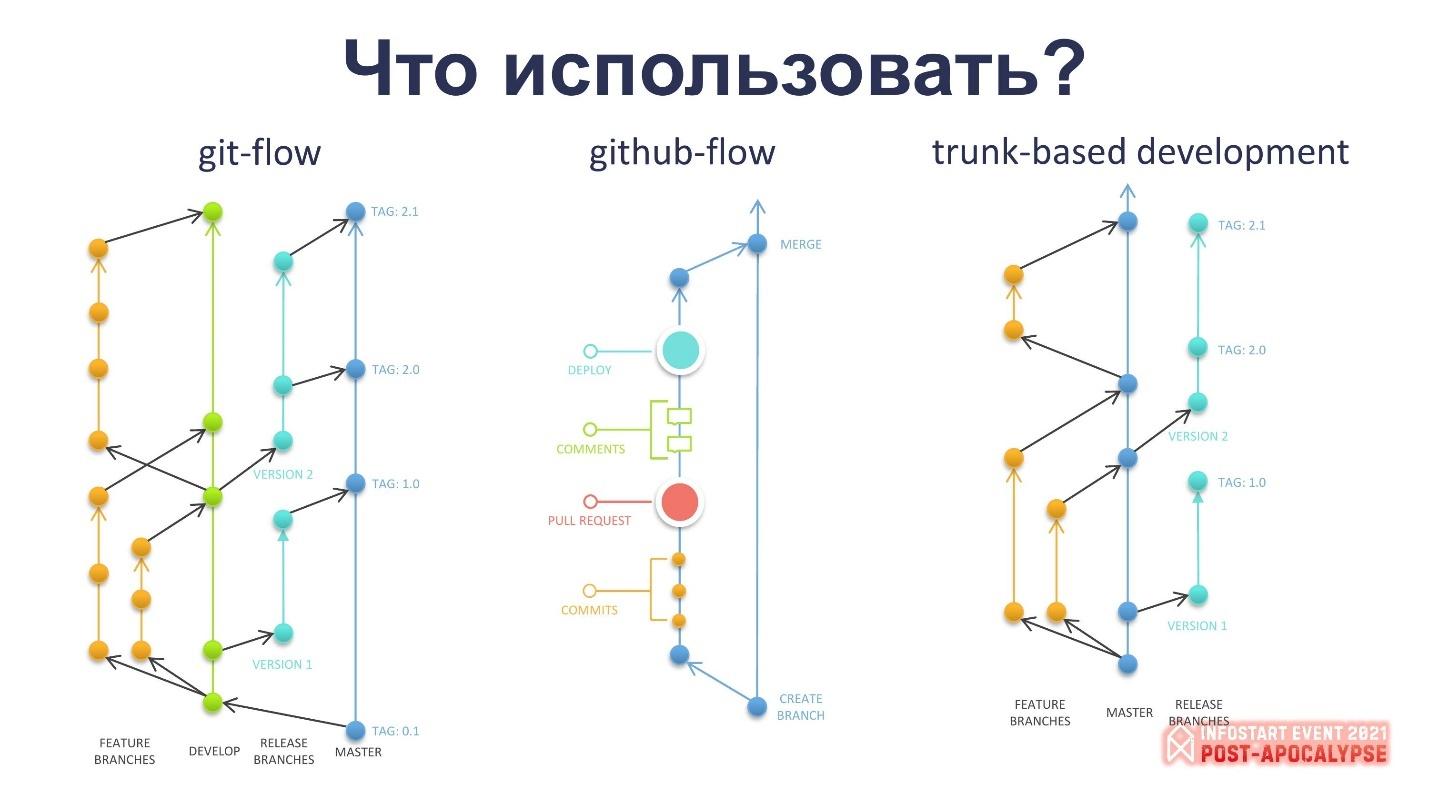
-
Слева на слайде показано, как выглядит всем известный Gitflow – в нем две постоянноживущие ветки (master и develop), дополнительные ветки release и hotfix и много веток feature под задачи.
-
В середине – вариант, предложенный Гитхабом, GitHub-Flow. Сразу оговорюсь, этот вариант не очень применим в реалиях 1С – мы пока редко автоматизируем в репозитории деплой с проверкой. Вариант GitHub-Flow интересен тем, что у вас есть ветка, в которую вы коммитите, потом вы делаете пул-реквест, обсуждаете его с вашими коллегами-разработчиками, и после проверки производится мерж в основную ветку. Вариант простой – ветка, по большому счёту, одна, от неё ответвляется каждая задача, и так далее.
-
И есть ещё одна интересная методика от компании Google, которая намного интереснее в этом плане – она называется Trunk-based development. Если вы планируете переходить на Git или думаете о ветвлении, я рекомендую рассмотреть ее использование. Главное, на что надо обрать внимание в методике Trunk-based development – это то, что ветки (feature branches) должны закрываться очень быстро. Взяли задачку – сделали – залили, и так далее. Это повышенная ответственность, поэтому здесь нужно смотреть в сторону автотестирования и каких-то таких механизмов.
Кстати, забавный момент – по непроверенным источникам, Google не только использует эту методику, но ещё и любит моно-репозитории, т.е. у них в одном репозитории несколько программных продуктов.
Правда, я с трудом представляю, как можно вместить Chrome в один репозиторий с Android, но, если у них это получается, это шикарно. Когда вы готовы собрать из одного репозитория несколько продуктов, пересечение и дублирование кода у вас в разы уменьшится – хотя бы на этапе разработки. Хотя проектирование, конечно, усложнится, тут никто спорить не будет.
Простой тест, есть у вас CI или нет

На сайте continuousdelivery.com Jez Humble опубликовал три вопроса, помогающих определить, действительно ли команда практикует CI
Вот эти три вопроса:
-
Все ли инженеры помещают свой код в основную (а не в функциональные ветки) ежедневно?
-
Запускает ли каждый коммит выполнение модульных тестов?
-
Если сборка не работает, обычно она исправляется в течение 10 минут?
Ответьте на эти три вопроса честно, и вы поймёте, в каком примерно состоянии вы находитесь в рамках CI. Оставляю вам это на раздумье.
Итоги
Попробую подвести итоги:
-
Continuous Integration и вообще работа с непрерывной доставкой кода – это ни в коем случае не Jenkins, GitLab и другие инструменты. Это не значит, что инструменты плохие, просто они не решают проблему, пока вы не решите её в голове, методологически, пока вы не перестроитесь внутри компании.
-
В первую очередь, Continuous Integration – это практики, методики, подходы внутри компании. А дальше вы гвоздь хоть молотком, хоть микроскопом забивайте – результат будет хорош.
-
Continuous Integration нужен для того, чтобы избегать конфликты кода в разработке небольшой ценой каждый день, чтобы не решать их большой ценой в конце. На эту тему есть такая хорошая цитата от Линуса Торвальдса, автора Linux: «Если вы будете коммитить ваши изменения каждый небольшой кусочек времени каждый день, в конце вы обнаружите, что вам не надо решать проблему большого коммита».
-
И да, Continuous Integration – это не только про код, но ещё и про коммуникации внутри компании. Когда у вас код очень быстро доходит до основной ветки, вы внезапно начинаете больше между собой общаться, появляется меньше дублирования, меньше каких-то таких проблем.
У моих ребят-разработчиков при начале применения подходов CI часто возникал вопрос – как часто надо коммитить, как часто мержить. У меня на этот вопрос есть простой ответ:
-
коммитить надо тогда, когда ваш код хоть что-то делает;
-
а мержить – тогда, когда он ничего не ломает.
Почему для меня применение CI было так важно?
Помните начало? Когда мы решили (точнее, мы посовещались, и я решил), что у нас будут изменения, я хотел не просто заменить хранилище на Git и внедрить автотестирование, я хотел поменять принцип разработки в самой компании. Я много раз об этом говорил, но никогда не думал, что мы сможем это сделать.
Когда ты в компании, которую организовал, начинаешь такие кардинальные изменения, всегда есть шанс облажаться и не получить конечного результата.
Но я хочу, в первую очередь, сказать спасибо всем, кто делал доклады на темы Git’а, DevOps’а, CI – всем, кто выкладывал информацию.
Если ещё не начали применять CI – начинайте, не бойтесь. В интернете полно информации. А ребята из Инфостарта (это ни в коем случае не реклама) вам помогут, потому что крупные компании делятся с нами, и за это им огромное спасибо.
Полезные ссылки
-
Continuous Integration как практика, а не Jenkins. Андрей Александров
-
https://www.scaledagileframework.com/continuous-integration/
-
https://services.google.com/fh/files/misc/state-of-devops-2019.pdf
-
https://assets.thoughtworks.com/assets/technology-radar-vol-24-en.pdf
Текст доклада выложен в репозитории – https://github.com/vandalsvq/is21_ci_as_practice Там вы найдете еще больше полезной информации.
Вопросы
На последнем слайде у вас было три вопроса. Как вы ответили на них в своей компании?
При любом внедрении всегда хочется подвести итог – получилось сделать или нет?
На первый вопрос: «Все ли инженеры помещают свой код в основную (не функциональную) ветку ежедневно» я с уверенностью могу ответить «Да». Мы смогли добиться того, чтобы все наши программисты каждый день заканчивали кодом.
А аналитики?
Тут уже другая проблема. Я уже говорил, что если аналитики не разбивают задачу, не умеют ее декомпозировать, а выдают вам ТЗ на несколько десятков страниц, и к ним нужно идти и объяснять, что так нельзя.
И те четыре блока, о которых я говорил, – имеют отношение не только к разработчикам, это, в том числе, подход к пониманию и у самих аналитиков. К сожалению, мне у себя в компании пока не удается донести это до аналитиков, я пока это меняю сам – беру конкретную задачу с конкретным аналитиком, разбиваю ее по кусочкам и заставляю этот кусочек нести клиенту. Показываю, чтобы они привыкали. Но чисто методологически пока не получается все это описать.
Второй вопрос: «Запускается ли каждый коммит выполнение модульных тестов?» Признаюсь – нет. С автотестированием у нас пока беда, потому что я просто не могу победить вот эти коммиты раз в неделю размером с полконфигурации. Я понимаю, что при этом можно делать тестирование. Вопрос только в том, что тестирование на разных ветках – разное. Где-то есть простые тесты, где-то – более сложные. Где-то – сценарные тесты. Но если у меня специалист в основную ветку выкатывает огромные изменения – тут сказывается моя управленческая проблема. Инструменты тестирования, которые я пробовал, действительно работают, помогают, но дальше меня это пока не ушло.
Ну и третий вопрос: «Если сборка не работает, обычно она исправляется в течение 10 минут». Тут у нас все хорошо по одной простой причине – у нас хорошо было и без Git, и без автотестов. Мы в принципе научились более-менее качественно работать. Но я не уверен, что на этот вопрос нужно отвечать положительно только потому, что у нас это исторически сложилось хорошо. Сказать, что сборка у нас исправляется в течение 10 минут, я все равно не могу. Поэтому на этот вопрос я отвечаю «Да, но нет».
Т.е., если судить по ответу на первый вопрос – у нас все получается. А по второму и третьему вопросу – пока с натягом. Но большой путь начинается с маленьких шагов. Поместите свой код в Git, и у вас появится магия – захочется это как-то развить дальше, получить пользу, чтобы все было не зря.
Постскриптум. Взгляд из декабря 2022 года
Если посмотреть календарь, 21-й год был «вчера», но я уверен, у всех ощущение, будто прошло порядком больше.
С одной стороны, слово не воробей, поэтому я не хотел бы, чтобы статья отличалась от сказанного тогда, с другой стороны, есть что дополнить. Поэтому по порядку.
****
Цитата:
И вроде бы всё хорошо, но «серебряной пули» не случилось – я как руководитель не понял, в чем мы выиграли.
Пояснение:
От перехода на Git вместо хранилища выиграли на самом деле очень много. Я помню, с каким кайфом я по утрам (во время отпуска), пока моя семья спала, выходил кодить на улицу летом, отправлял коммит и был уверен, что мои изменения попадут в тестовую сборку, оттуда в сборку для клиента.
А время, которое я тратил на передачу кода от себя в компанию, составляло несколько секунд (конечно же, без учета времени его написания).
Как стало удобно (и быстро) разбираться в истории изменений, откуда проблема, кто ее принес. А если это не проблема, то почему тот или иной код появился.
В общем, чтобы у читателя не было ощущения, будто «я не умею готовить кошек», скажу так. Кошка очень даже вкусная.
Но здесь речь идет не обо мне в моем обличии программиста, а речь обо мне, в лице руководителя. Поэтому ключевая фраза «я как руководитель»
И да, в отпуске я тоже работаю, так мне легче отдыхать. Эдакий договор с совестью
****
К чему весь этот «разгон» про Continuous Integration и азы групповой разработки?
Пояснение:
Большинство работает в команде, у кого есть хранилище, для них проблемы конфликтов не столь актуальны, особенно если они живут в одном хранилище все. Захватил объект и гарантировал себе неприкосновенность своего решения.
Но если выйти за пределы «классического рецепта» приготовления хранилища и начать смотреть по сторонам, то рано или поздно вы придете к какой-то системе распределенной разработки с ветвлением. А уж инструментарий дело второе.
И вот когда придете, начнете пытаться работать, выяснится, что вы и сосед работаете по-разному. А когда у вас разный подход, но один продукт, кто-то точно будет страдать. А возможно страдать будут оба, но по-разному.
Об этих «страданиях» и идеях, как их решить, я и пытался как-то кратко рассказать...
****
Немного про «декомпозицию».
Пояснение:
Чтобы не было ложного восприятия, я действительно сам стараюсь работать так, чтобы мое решение не мешало выкатывать релизы. Даже если я его не доделал, в develop я лить буду то, что не ломает ничего другого, скрыто от посторонних глаз и не вызывает опасений.
То есть я лично придерживаюсь описанного подхода, частенько использую временные роли, функциональные опции, пишу расширения до переноса в основной функционал, в общем я всячески стараюсь свой код максимально быстро дотащить до всех.
Однако, когда я пытался донести подобный подход до других, я сталкивался с недопониманием. Со стороны аналитиков, других программистов, заказчиков. И им приходилось объяснять, почему надо смотреть «полуфабрикат».
Возможно, я когда-нибудь более детально рассмотрю этот вопрос, но сложилось ощущение, что мало кому интересна эта тема. Если интересна, пишите, наберется аудитория – будет с кем обсуждать – будет причина написать.
****
Блок «пруфы в студию» по-хорошему надо было где-то в конец поставить, я уже не помню, почему вдруг он пошел выше того же обсуждения ветвления.
Поэтому если у читателя возник вопрос «куда тебя понесло», то пропускайте, дочитывайте до главы «Простой тест, есть у вас CI или нет» и где-то там эта глава будет более логичной.
****
Перечитывая доклад, я понял, что лично мне сейчас пока нечего существенно добавить. Ввиду некоторых событий, происходящих в компании и вне ее, вопрос разработки и дальнейшего совершенствования данного процесса несколько выпал из моего поля зрения.
Мы по-прежнему пользуемся теми инструментами, что внедрили. Я на себе обкатываю возможность применения конфигурации «Тестер» с целью сценарного тестирования, в планах есть его интегрировать в процесс.
Я по-прежнему очень интересуюсь этой темой, вот недавно покрутил 1С:Исполнитель и подумал, что некоторые наши инструменты можно переписать с его использованием. Просто сейчас я занят несколько другой трансформацией в компании, а этот функционал просто хорошо работает.
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.

Вступайте в нашу телеграмм-группу Инфостарт