






Введение
Казалось бы, уже столько всего написано про SonarQube, но все равно есть чем поделиться. В дополнение к докладу "Разветвленная разработка на хранилищах и файлах поставки" на Infostart Event 2022 вашему вниманию предлагается опыт нашего департамента по работе с SQ и организации самого процесса контроля качества кода.
Процесс разработки
Наши разработчики имеют индивидуальные хранилища по каждой задаче и работают исключительно с конфигуратором. Хранилища находятся на поддержке от поставки релизных конфигураций. Любое помещение в хранилище разработчика приводит к разбору версии на исходники, помещению в git и запуску проверки SQ. Разработчик самостоятельно контролирует отсутствие замечаний от сонара и передает задачу на дальнейшее code review только после того как все исправлено. Проверяющий обращает внимание лишь на логику функционирования доработки. Рутинная работа остается сонару, а если быть точным BSL Language Server (ведь именно он выполняет проверки, отдавая результат для формирования наверх SQ).
Кроме исправлений по результатам проверки качества кода и code-review разработчик запускает тесты (Vanessa-Automation) на своем хранилище, подтверждая, что уже существующий функционал "не пострадал". При необходимости тесты могут дорабатываться под новые реалии.
Проверки перед помещением в хранилище
Поскольку в нашей схеме проверка кода возникает только после помещения его в хранилище, то здесь возникает нежелательная задержка. Сначала хранилище разберется на исходники, затем попадет в git, потом подождем когда завершится работа sonar scanner - пройдет много времени. Минимум 10-20 минут на всё. Далее разработчик должен посмотреть результаты и исправить ошибки, после чего этот цикл повторится. Если бы в конфигуратор можно было подключить sonar lint или проверки как в EDT, то дело пошло бы быстрее.
Этап "разработка - проверка" мы ускорили при помощи локального BSL Language Server и обертки над ним в виде Phoenix BSL. Эта штука работает с конфигуратором и позволяет по нажатию кнопки вызвать проверку для любого куска кода. Все это практически мгновенно.
Разработчик локально ставит java, устанавливает феникс с нашими готовыми настройками (bsl-language-server.json) как на сонаре и работает как прежде, но регулярно проверяя код локально. Как результат - мы получаем ускорение проверок на порядки.
Подробный обзор продукта на Инфостарте: infostart.ru/1c/articles/1656631
Покрытие кода тестами
Узнать, насколько полно конфигурации покрыты тестами, можно при помощи замечательного инструмента Coverage41C. Идея в последовательном прогоне тестов в один поток и замерах производительности, которые конвертируются в соответствующие метрики. Покрытый тестами код можно увидеть прямо в исходниках в интерфейсе SQ.
Вот такие красивые картинки можно увидеть по результату.
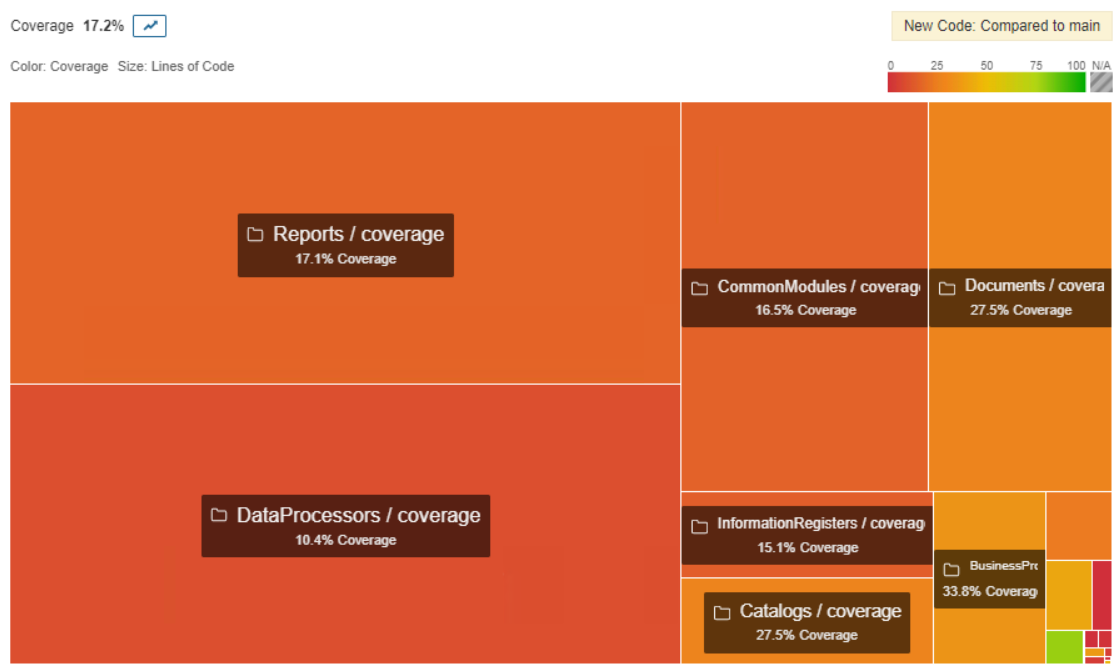

Последние строчки могут вводить в заблуждение - количество строк кода, которое осталось покрыть тестами (Lines to cover, 284К) существенно меньше чем количество кода в проекте (LOC - lines of code, 622К). Тут просто - не весь код можно покрыть тестами. На примере ниже полностью покрытая тестом процедура. Как видим, не весь код исполняется, поэтому такая существенная разница (девять против пятнадцати).

Поскольку тестов у нас много, запуск происходит в один поток, то время выполнения значительно. Поэтому расчет покрытия кода мы запускаем редко. Для хранения метрики мы используем отдельную неудаляемую ветку. А триггерами к запуску расчета является добавление в нашу коллекцию новых тестов.
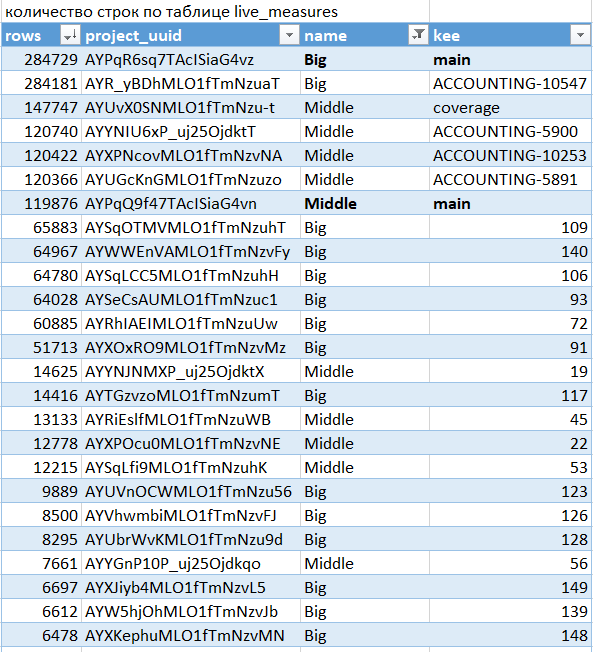
Объем базы на сервере SonarQube
Ветки и PR
В самом начале работы с SQ было понятно, что удобно можно работать только с ветками. Недостаточно проверять только одно релизное хранилище. В community версии из коробки этого нет, но, к счастью, есть свободно распространяемый плагин https://github.com/mc1arke/sonarqube-community-branch-plugin.
Плагин позволяет выполнять проверки для разных веток хранилища, настраивать разные политики сравнения. В результате разработчик может получать отчеты только на свою ветку, что также ускоряет проверку и постанализ.
Важно. Плагин дорабатывается и следует за обновлениями самого сонара. Но никогда не переходите на новую версию SQ, пока не протестируете работу плагина sonarqube-community-branch-plugin на ней. Плагин сторонний, его поддержка и разработка никак не коррелирует по времени с выпуском новых версий сонара. Можно попасть в ситуацию, когда плагин будет адаптирован лишь через месяц-другой. Все это время вы не сможете работать с ветками. В результате придется откатываться. Возможно, болезненно.
После того как наш первый продукт прошел успешное тестирование на нескольких ветках и было принято решение подключить все остальные хранилища (ветки) к сонару, у нас произошел неприятный инцидент. Подключив десяток веток, по которым были сделаны первые проверки, наша база упала с SQL ошибкой по превышению места. SQL Express с 10Гб на базу не выдержал нагрузки.
Пришлось разобраться в структуре хранения и понять, что именно занимает столько места. Было сделано несколько удивительных открытий. Оказалось, что ветки хранятся в базе целиком (даже дочерние), не смотря на практически полную идентичность. В итоге, если "цена добавления" одной ветки 100Мб, то три - это уже 300Мб. Такой порядок вещей привел нас в растерянность.
К счастью дальнейшие исследования показали, что хранение кода в Pull-request-ах такой проблемы расточительности лишены. В PR хранятся лишь отличия. Поэтому одна релизная ветка и несколько PR (несколько задач) - это 147Мб + 43Мб + 13Мб + 8МБ и т.д. (все зависит от сложности изменений). И это выход.
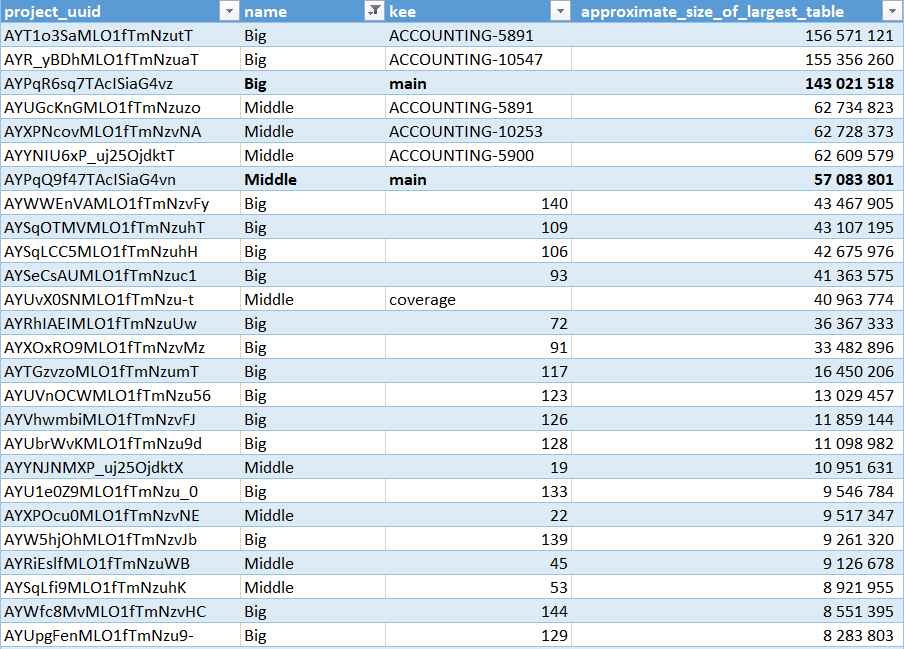
В итоге, наша рабочая схема - одна ветка (мастер), к которой есть много MR. Политика "нового кода" - сравнение с мастером (Project settings -> New code -> Define a specific setting for this project -> Reference branch).
Что же еще отъедает объемы и как все это хранится? Вот интересные запросы для исследования (postgresql).
Как посчитать размер ветки/PR:
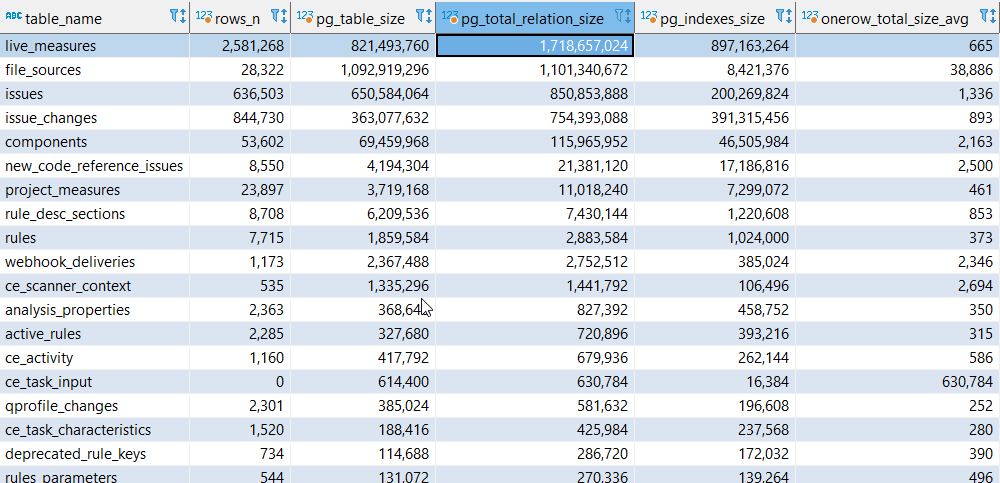
Что самое тяжелое в базе?
Количество живых метрик
Здесь на нашем примере видно, что уж лучше бы разработчики меньше создавали smell-кода и ошибок - это напрямую влияет на размер хранения.
Автоочистка
Для уменьшения объема хранения однозначно рекомендую использовать автоочистку неиспользуемых веток и PR. Например, из коробки стоит автоудаление в 30 дней, после чего ветка/PR будет удалена. В этом нет ничего страшного. Если запустить сканер еще раз, то ветка появиться вновь.
Важно. Очистка не запускается автоматически по истечении заданного интервала. Она отработает только после запуска любой проверки кода. Это значит, что если проверка у вас не каждый день, а, например, раз в неделю, то удаление произойдет на 30-36 день. Странное поведение, но вот так.
Интеграция с Gitlab
Поскольку код у нас уже в git, то почему бы туда же не складывать уведомления о результатах проверок?
Из коробки в SonarQube есть декорирование pull request. Очень мощная штука, которая позволяет внутрь PR/MR (merge request) при помощи комментариев сразу весь код разметить и подсветить все проблемы. Т.е. сразу все наглядно, и даже в SQ можно не переходить. Это удобно и довольно стабильно работает при условии, что замечаний к коду практически нет и коммитов тоже мало. А вот если разработка существенная или длительная, и/или ошибок десяток-другой, то gitlab начинает тормозить при выводе страницы MR. В итоге ожидание становится неприемлемым. При этом сам факт комментариев внутри очень интересен, и мы хотели оставить эту возможность. Дело в том, что мы используем MR еще и как точку входа для запуска тестов. Сюда же попадают ссылки о результатах тестирования.
В сети на тему комментариев из SQ нашелся лишь https://github.com/gabrie-allaigre/sonar-gitlab-plugin
Очень мощный настраиваемый плагин. Можно настроить комментарии к строкам кода, выключить их вовсе, настроить вывод различных метрик, причем поддерживаются собственные шаблоны. К большому сожалению, на нашем инстансе плагин так и не заработал. Пробовали разные комбинации версий плагина и сонара и все неудачно. Хотя из коробки с демо-сонаром даже на самом gitlab.com это работает. Увы, пришлось продолжить поиски.
В итоге мы пришли к третьему способу - путем интеграции через веб-хук. После того как сонар выполняет проверку, он отправляет данные в сторонний сервис, который формирует строку с результатами и делает post-запрос к api gitlab для публикации. Веб-хук и адрес сервиса настраивается через интерфейс SQ (Project settings - webhooks).
Для проброса любых параметров через себя у сонара есть специальные параметры sonar.analysis.*. Именно они используются для передачи данных об MR и последующем post-запросе.
Поэтому сам запуск проверок из gitlab выглядит так (.gitlab-ci.yml)
Роль стороннего сервиса выполняет Jenkins, хотя мог быть простейший веб-сервер со скриптом. Сам пайплайн:
Вот так это выглядит в gitlab после завершения проверки:
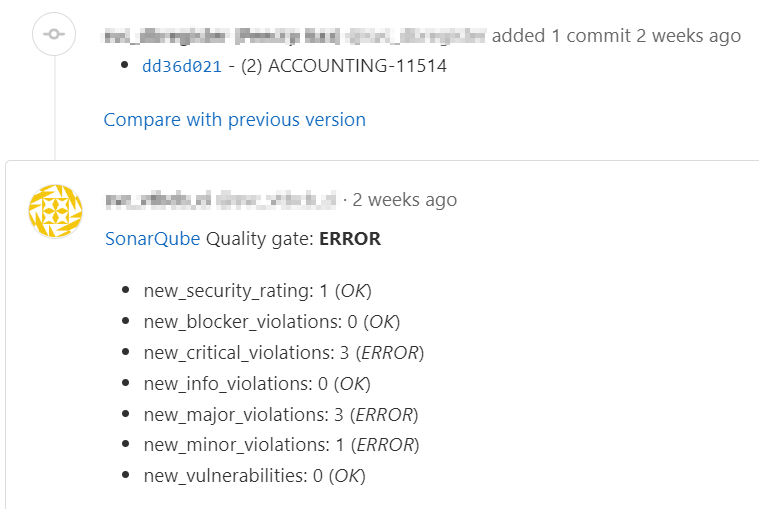
Из минусов подхода через веб-хук - это еще одна точка отказа в виде сервиса отправки.
Вместо заключения. А надо ли проверять качество кода
С точки зрения решения бизнеса контроль качества кода можно интерпретировать как лишние затраты, поэтому было важно минимизировать "потраченные часы" на это. Оптимизация в нашем случае - это бесшовность, скорость, удобство для всех участников процесса.
Про преимущества проверок. Как не жаль, но львиную долю потраченного времени составляет отладка. Неиспользованные переменные, смешивание алфавита, неработоспособные или бессмысленные условия - это лишь тот минимум причин, с которым встречался каждый при поиске проблем в коде.
А если добавить сюда более "интеллектуальные" вещи про парность транзакций, соединения с подзапросами - можно предотвратить и более серьезные проблемы производительности.
Следование стандартам разработки и контроль позволяет снизить время на отладку и поиск этих неприятностей. Объективно посчитать выигрыш от использования проверок, увы, не представляется возможным, потому что измерить отладку по невозникшей проблеме нельзя, ибо она была предотвращена.
Ну и отдельный блок ссылок про это:
- Книга «Чистый код» Роберт Мартин (купить/скачать). Если уж совсем никак, то конспект https://habr.com/ru/post/485118/
- Управление качеством кода //infostart.ru/1c/articles/1096770/#_wjjx02srzer9
- Вы не умеете работать с транзакциями https://habr.com/ru/post/419715/
- Качественный код в 1С. Теория, инструменты (1С:Автоматизированная проверка конфигураций, SonarQube) https://rarus.ru/publications/20210827-ot-ekspertov-kachestvennyj-kod-v-1c-avtomatizirovannaya-proverka-konfiguracij-sonarqube-492925/
Благодарности
Спасибо всем авторам и контрибьюторам перечисленных в статье проектов и продуктов! Вы делаете очень нужную работу! Без вашего вклада, энергии и энтузиазма наш мир так и оставался бы грустным и не оптимальным. Ждем ваших новшеств!
Ссылки
- BSL Language Server https://1c-syntax.github.io/bsl-language-server/
- Phoenix BSL: правим ошибки "не отходя от кассы" //infostart.ru/1c/articles/1656631/
- Автоматизация расчета покрытия кода тестами //infostart.ru/1c/articles/1445790/
- Плагин для вывода информации о проверках из SQ в Gitlab: https://github.com/gabrie-allaigre/sonar-gitlab-plugin
- Плагин для работы с ветками в SQ: https://github.com/mc1arke/sonarqube-community-branch-plugin
- Разветвленная разработка на хранилищах и файлах поставки https://event.infostart.ru/2022/agenda/1678739/
Вступайте в нашу телеграмм-группу Инфостарт

