
Меня зовут Сергей Голованов, я программирую с 11 лет – очень давно, сколько себя помню.
Начинал программировать с калькулятора МК-52 – если кто такой знает, у того уже должно было олдскулы свести.
Лет в 15 обзавелся компьютером ZX Spectrum. Довольно быстро перешел там от игр к бейсику, а потом к ассемблеру. Собственно, оттуда все завертелось.
Диплом, как, наверное, большинство моих одногодок, я писал на Delphi.
В начале двухтысячных немного программировал под Linux на C++. Такое, конечно, нельзя людям показывать. Но оно работало.
Несколько лет назад прошел курсы по C#. И пару лет назад еще прошел курсы по Java на Stepik – это мне помогает писать диагностики для SonarQube.
И все это время – уже больше двадцати лет - с 99 года, как я начал работать, меня кормила 1С. Я на ней начинал с 7.5, потом с 7.7, потом сразу перешел на 8.3.
Получается, что с 1С у меня около 20 лет опыта, и около 10 лет опыта администрирования, потому что когда я начинал работать, нужно было уметь все – и картриджи заправлять, и vpn-туннели настраивать, и веб-серверы, и почтовые серверы.
И вот теперь на синтезе этого опыта мне достаточно комфортно ехать в DevOps – про это сегодня как раз и будет доклад.
Технический плейстоцен
В 2018-м году я пришел в компанию БКС – это один из крупнейших брокеров в России. Компании 26 лет.
Системе бэкофиса компании, написанной на 1С, конечно, не 26 лет, но где-то, наверное, близко к этому. То есть когда всё это писалось, мы еще не знали, что мы – инженеры бизнес-приложений. Не знали, что нам нужна спираль DevOps и постоянное улучшение. Никто про это ничего не знал, никто даже и думать не думал про какое-то автотестирование. Писалось по тогдашним меркам, круто, в конфигурации есть достаточно крутые модули, интересно сделаны. Но по современным практикам то, как оно написано – это плейстоцен.

Прикрутить ко всему этому практики CI/CD – это как к динозавру приделать пулемет и научить им пользоваться. И еще чтобы он стрелял только того, кого надо. Выглядела эта задача просто нерешаемо.
-
На тот момент в нашем бэкофисе было около 1,2 миллиона строк.
-
Очень специфический highload, потому что обычно под хайлоадом понимается работа тысячи пользователей, которые пытаются что-то одновременно писать в базу, у них там всякие блокировки, и вот это все. У нас такого практически нет. Но у нас есть несколько видов биржевых документов, которых в день в базу льется порядка 5-7-10 миллионов. Это нужно все обсчитывать, проводить каким-то образом, считать, сколько мы там денег с кого должны снять. Специфика есть своя.
-
У базы специфический старт – ее нельзя так просто взять и запустить. У нее есть определенное окружение, его нужно тоже настраивать. Это делают QA-специалисты – они запускают все эти тесты.
-
Специфическая работа с метаданными – человек, который у нас отвечает за весь проект, он знает буквально каждую табличку, каждый индекс – какого размера он должен быть, где как лежать, как часто обновляется статистика. Поэтому убедить его, что в базу нужно добавлять какую-то еще табличку– придется аргументированно объяснять, что нужно что-то завести. Из-за этого у нас небольшая конфигурация, это нам помогло очень.
-
Тридцать два глобальных модуля. Когда писалось – наверное, это было модно. Но из-за этого у нас «из коробки» не работает ни одна Ванесса. То есть, если взять Ванессу из интернета, попытаться запустить на наших базах, она пересекается по названиям функций глобального контекста и не работает. Говорит, что функция с таким именем уже есть, и все, до свидания.
-
Плюс еще у нас есть регулятор – Центробанк. С ним очень все строго – очень серьезные санкции, если мы что-то вдруг сделаем не так.
-
И поэтому засилье инфобеза, они могут сказать: «Нет». И все, и нет. Например, у нас запрещен запуск чего бы то ни было из временного каталога пользователя на наших компьютерах. Соответственно, если кто знает, как работает Ванесса – она формирует батничек, складывает его во временный каталог пользователя, потом оттуда его запускает. У нас это не работает.
Вот такая вот картина у нас была. И мы, смотря на это, пошли в вере, что сможем прикрутить ко всему этому новые технологии.
Как приходит DevOps в компанию?
Есть ребята, которые приходят в компанию и приносят Agile: «Вот сейчас мы вам сделаем хорошо».
DevOps примерно так же приходит, но он приходит еще и с инструментами.
Какие инструменты мы привнесли людям?
Мы ничего не забрали. Я сейчас буду показывать классическую схему доклада: вот так было, потом мы внедрили инструменты, и нам стало хорошо. Все, что было, по-прежнему есть, мы ничего не отбирали у людей. Если кто-то не хочет пользоваться новыми технологиями, он пока еще может работать по-старому.
Но мы добавили новые инструменты.

Понятно, что первый инструмент – это Git.
Это основа: «без Гита и жизнь не та». Это – вход в тестирование.
Как только появляется Git, уже можно что-то с этим делать.
Как мы с ним работаем?
Сидит человек, как обычно – разрабатывает в конфигураторе, заканчивает мысль, нажимает Ctrl+S (сохранить), и потом он жмет «Конфигурация» – «Выгрузить конфигурацию в файлы».
Это – ручная работа, которая добавилась. Другого варианта мы пока не нашли.
Я знаю, здесь на Инфостарте выступал человек, который рассказывал, что у них там есть какой-то сайтик для их внутренних людей, которым можно отправить заявочку, они там из SQL разбирают базу, выковыривают конфигурацию. У нас пока этого нет. У нас просто человек жмет «Конфигурация» – «Выгрузить в файлы».
Из-за того, чтобы как раз метаданных не очень много, даже полная выгрузка конфигурации – это порядка там 20-25-30 секунд, а инкрементная – она буквально меньше секунды.
И вот человек нажал и пока он тянет мышку к Git-клиенту, у него уже все выгрузилось.
В качестве Git-клиента у нас используется SourceTree. Все инструкции написаны для SourceTree.
Но есть уже отдельные граждане, которым стало тесно в гуевом клиенте, они уже идут в консоль, начинают в консоли разбираться и просто в Git Bash писать команды, что очень радостно лично для меня как линуксоида.

Следующий инструмент, который мы привнесли – это SonarQube.
Если Git – это некая платформа, на которой все построено, как основа, как базис какой-то, то SonarQube – это как вишенка на торте, самая вершина того, что мы привнесли.
SonarQube реально меняет качество кода. Если вы до сих пор не внедрили SonarQube, очень рекомендую его поставить, хотя бы где-нибудь в сторонке.
Чем он хорош?
Понятно, что про него тоже много уже рассказывали, много показывали, как он работает. Расскажу, что я увидел для себя, с чем я столкнулся.
Если прийти к людям, которые по 20 лет в профессии и сказать им: «Мужики, вы пишете код не очень», то можно получить достаточно серьезную реакцию в ответ. Особенно, если у людей ни было практики code review, если они не умеют отделять себя от своего кода. Когда кто-то ругает их код, они начинают воспринимать это лично, и могут даже драться полезть.
Что делает SonarQube? Мы ставим SonarQube, и теперь он вместо нас рассказывает людям: «Чуваки, ваш код не очень». И весь негатив, который есть у людей, разбивается о то, что бездушной железяке бесполезно говорить, чем ты недоволен.
Конечно, особо прошаренные граждане сразу прибежали и сказали: «Это не железяка, это ты его настроил! Это из-за тебя меня теперь заставляют пробелы после запятых писать, отключай давай!»
Как мы это обошли? Мы кинули клич в нашем корпоративном чате, собралась инициативная группа около 15 человек, и вместе коллегиально мы решили, какие правила нужно оставить, какие нам не актуальны, какие нужно выключить.
И теперь, если человек в своем праведном возмущении хочет не ставить пробелы после запятых, ему придется с каждым из 15 человек все это пройти, рассказать, почему это не надо. Я не видел, чтобы кто-то смог это до конца пройти этот путь.
И когда люди проходят все стадии: отрицание, гнев, торг, депрессия – в конце концов они начинают писать код по стандартам, и это реально меняет качество кода.
Код становится чистый, читабельный, красивый, одинаковый – разные люди начинают одинаково писать.
Это по-настоящему меняет ту кодовую базу, которая есть.

Следующий инструмент – Vanessa ADD.
Понятно, что нужна какая-то обработка, которой тестировать. Для автоматизированного тестирования у нас в БКС есть своя обработка, которая называется «Автоматизация тестирования».
Но основная ее проблема в том, что она за пределами БКС превращается в тыкву.
Из-за безопасности мы не можем свой код вынести куда-то наружу, и, даже если ты – суперспециалист по этой обработине, ты уволился, пошел в другую компанию, и все, эти знания никуда не нужны.
Стандарт де-факто в отрасли – это Ванесса. Мы сначала пытались завязаться на Vanessa Automation, но нам приходится ее пересобирать.
Я уже рассказывал, что у нас есть проблема, у нас не работает Ванесса. Как мы это обошли?
Я забираю исходники Ванессы из интернета, я запускаю свой скриптик на bash, который использует sed и awk. Так как я с линуксом 20 лет, то мне это было легко написать. Он проходит по исходникам и меняет имена функций, так как мне надо, чтобы они не пересекались с глобальным контекстом. Потом я запускаю сборку и кладу получившуюся Ванессу в репозитарий, все начинают ей пользоваться.
Так вот, сборка Vanessa Automation с некоторых пор стала возможна только в 8.3.17, у нас платформа 8.3.10. А ставить новые версии – это опять инфобез, это опять все эти квесты.
Поэтому мы перешли на Vanessa ADD – отличная вещь, работает. Позволяет подключать свои плагины – просто восхитительная вещь. Короче, мы остановились на Vanessa ADD, работаем с ней.
Выбор скриптового языка
Но все эти три инструмента как будто разбросанные: один одно делает, другой – другое. Нужно что-то, что их скуёт в одну цепь, как-то объединит в единое целое, в тот самый CI.
Нужен скриптовый язык.
Изначально свою первую автоматизацию я писал на bash-скрипте, с sed и awk, но как только я на внутреннем митапе попытался показать это людям "вот смотрите, вот так можно теперь автоматизировать ваш труд", реакция была очень однозначной. Они сказали: «Это вообще что? Неужели это язык? Что это такое?» То есть продать это людям невозможно. 1С-нику изучить bash – невозможно. Есть фанатики, но основная масса – они не хотят этим заниматься.
У нас работал человек, который написал обвязку над 1С на Ruby – фактически аналог v8runner. Тоже там все круто сделал, но опять же, это не продать. Что-то изменить или поменять невозможно. Ruby вообще никто не знает. Даже Python больше знают, хотя даже питону научить сотню программистов 1с – это что-то нереальное.
И вот встал вопрос у нас – чем это все обмазать.

И вот здесь как солнце сквозь тучи, и как ответ на все наши вопросы воссиял OneScript.
OneScript позволяет обойти любую специфику, любые проблемы, которые придумывает наш инфобез или администраторы.
Все это можно обойти с помощью OneScript. Он отвечает на все вопросы, всё, как мы любим.
Чем в основной массе отличается 1С-ник от программиста на другом языке? Ты придешь к программисту на другом языке, говоришь: «Чувак, здесь такая проблема», он говорит: «Пойду я в интернет, поищу, какие там есть библиотечки на эту тему. Может, что-то готовое есть».
А как только мы 1С-нику говорим, что есть проблема, он уже глаза закатил и придумывает: «Сейчас мы тут сделаем справочник, а тут – регистр, тут вот такие индексы. Я же эксперт, я знаю, как лучше хранить».
Мы всегда все пишем с нуля – так же и этот наш CI.
У нас есть специфика, свои нюансы. И все эти нюансы с помощью OneScript можно закрыть. Написать на нем что угодно.
OneScript – это потрясающая вещь, которая позволила сделать весь наш CI таким, какой нам нужен.
Что было? Боль и страдания
Вообще все доклады – они такие, там при рассказе «что было» – боль и страдания.
-
Боевая база у нас порядка восьми терабайт. Даже когда она свернутая, обрезанная, сжатая, подготовленная к разворачиванию для тестов – она занимает примерно 500 гигов. То есть люди берут этот бэкап, разворачивают, генерируют там миллионы документов или еще что-то. После этого они понимают, что нужно все откатить и запустить заново. Откатить даже к снепшоту – это часто дольше, чем развернуть заново. Поэтому базs у нас постоянно разворачива.тся – и тут, и вот тут, и на этом сервере. Все разворачивают базы, и тепловая смерть вселенной наступает огромными темпами.
-
Донастройка и запуск развернутой базы – я уже говорил, что там есть свои сложности.
-
Есть тестирование, которое QA как специалисты настраивают и запускают на ночь, чтобы спокойно уйти домой, а потом утром прийти и увидеть результаты. И вот они запустили все, радостно уходят домой, а утром приходят и видят, что там суперпрограммист забыл проверить синтаксис, и оно упало через пять минут после запуска. И так 17 дней подряд. Конечно, такому программисту потом выносится общественное порицание, но от этого легче не становится.
-
Переиспользования и перезапуска тестов не было, тесты писались под задачу. Соответственно, задача внедрена – тесты похоронены и не перезапускаются, протухают. Получается, что работа впустую.
-
Ручной перенос изменений в хранилище – т.е. человек разрабатывает задачу в каком-то тестовом хранилище, затем это нужно перенести в боевое, и вот он руками это все переносит. Все он перенес или не все, затер он или не затер чужой код - все это только на совести того, кто переносит. И еще почему-то тоже очень любят в процессы встраивать такую вещь, что нужно где-то написать на какой-то служебной записке список изменений, которые по задаче вносятся. И вот ты сидишь, переписываешь тут функции, которые ты изменил. С точки зрения сегодняшнего момента – это дикость, но это много где есть.
Преодолевание

Как мы всю эту боль обошли?
-
Мы сделали запуск на пустых базах. С этим связана достаточно серьезная трансформация мозгов. Потому что когда у тебя есть боевая база или какая-то копия, ты туда можешь зайти и спросить у пользователя, с каким клиентом проблема. Порыться в реальных данных, что-то найти или подковырять. А когда у тебя пустая база, тебе нужно тестировать только логику. И написание фич для того, чтобы тестировать логику, не привязываясь к каким-то конкретным клиентам, данным – это достаточно серьезная трансформация у людей в головах. До сих пор она идет.
-
Автоматическая донастройка и запуск. Вся эта настройка окружения, которая нам требуется для базы, описана на OneScript.
-
Тестируем логику, чтобы на CI и на компах пользователей работало одинаково. Например, у нас на компах пользователей нельзя снять защиту от опасных действий. Если запускать Ванессу, где дополнительно подключается еще 20 плагинов, нужно для каждого нажать: «Да, я согласен». Но это не автоматизация, это что-то непонятное. Как это обошли? Создали маленький dt-шничек, где есть несколько ролей, и пользователь со снятой защитой от опасных действий. Этот dt-шник грузится в базу, потом в нее уже загружается конфигурация, от этого пользователя запускается база, фичами создаются уже другие пользователи, и начинается дальнейшее тестирование.
-
У Ванессы библиотека сниппетов из коробки. Если раньше у нас тесты лежали в xml, и найти в них что-то было нереально, то теперь тут спокойно все работает.
-
Автотестирование. Весь прогон CI проходит порядка двадцати-тридцати минут – вместе со статическим анализом и выгрузкой на аллюр.
-
И автомерж. Мы делаем merge-request, а в нем автоматически выводится весь список изменений. Ты не можешь там ошибиться – он тебе показывает все изменения, которые есть на самом деле – вот в таких функциях, в таких строках.
-
И если нет конфликтов, то автоматически нажатием одной кнопки все эти изменения заливаются.
-
Если есть конфликты – я запускаю небольшой скриптик, который формирует временную базу и загружает туда нашу сломанную конфигурацию из нашей ветки (с конфликтами). Перед этим я конфликтные файлы, заменяю нашими версиями, а рядышком складываю уже собранный cf-ничек с конфигурацией из ветки, которую мы мержим. В результате получается, что у нас открывается уже готовый конфигуратор, и все, что остается человеку – это сравнить-объединить с этим вот cf-ником.
-
Вот так у нас все работает. То есть только конфликты исправляются. Если что-то мержится автоматически, оно мержится автоматически.
Основной инсайт: нетехнический плейстоцен

Все технические вещи решается с помощью OneScript. А с нетехническими сложнее.
Сотрудники начинают рассказывать:
-
«Я – программист и не хочу писать Gherkin»
-
«Ваш Git мне там опять все испортил»
-
«Там что-то все красное, непонятно»
-
«Зачем мне нужно чужие тесты править?»
-
«Отключите Sonar» – это вот вообще популярно было.
Но, к сожалению, рассказывать про эту борьбу нет времени - на доклад выделяют всего полчаса, а не неделю :)
Я столкнулся с тем, что ты делаешь человеку хорошо, а он говорит: «Нет, мне раньше было лучше. Мне не надо ничего, я не хочу ничего учить». Вот это сопротивление изменениям – это основная вещь, которая очень сильно демотивировала. Я не «директор по счастью», и не умею работать с такими людьми, мне было тяжело.
И когда я уже был готов все бросить, потому что людям ничего не надо, внезапно появились неофиты. Эти люди попробовали и сказали: «Ух ты, а нам действительно удобно, а нам действительно классно. Нам так проще и быстрее. Мы так не боимся рефакторить – у нас есть тесты, где логика не зависит от реализации. Мы можем спокойно полностью все переписать, потом тесты прогнать. У нас все работает, мы спокойно внедряемся и вообще не переживаем, что что-то сломаем».
После этого началась трансформация мозгов у людей, получилась так называемая «заразная автоматизация».
«Сахарок» и «дрожжи»

Из-за того, что у нас тесты на пустых базах, перед тестом нужно данные создать. А написать фичи, которые создают данные каждого вида – это очень простая, но очень нудная задача. И вот человек сидит, перекладывает реквизиты документа в значения таблицы Gherkin – это очень нудно, они тоже ругались: «Очень тяжело создавать эти данные, зачем это всё придумали?»
И внезапно нашелся человек, который посмотрел на это и сказал: «Зачем я буду на каждый вид метаданных писать свою отдельную фичу, я лучше напишу сахарок». И он написал сахарок – это четыре шага.
-
Первый – создает любой справочник
-
Второй – создает любой документ
-
Третий – пишет движения в любой регистр сведений
-
И четвертый – пишет движения для регистра накопления
Мы сейчас эту возможность уже подготовили, скорее всего, будем делать мерж-реквест в Ванессу как плагин – можно будет создавать любые данные (сейчас на следующем слайде покажу).
Что это дало?
-
Создание тестовых данных стало единообразным.
-
У нас теперь создание любого справочника и любого документа – это известный заранее синтаксис.
-
Поэтому у нас теперь QA могут сами писать фичи. Потому что программист написал что-то, и он свое тестирует. А QA же любят как-нибудь завертеть – мы тут сначала создадим данные, а потом удалим, а потом снова создадим, а потом еще раз удалим – как это обработается? За счет того, что синтаксис понятен, QA могут сами писать фичи.
-
А после этого нашелся другой человек, который к сахарку написал дрожжи. Он написал обработку, которая генерирует фичи. То есть буквально ты выбираешь какой-нибудь конкретный документ (или справочник) в базе, эта штука обходит метаданные, и сама формирует уже готовую фичу. Мы эту фичу запускаем, она, опять же, опирается на синтаксис «сахара» – все счастливы.
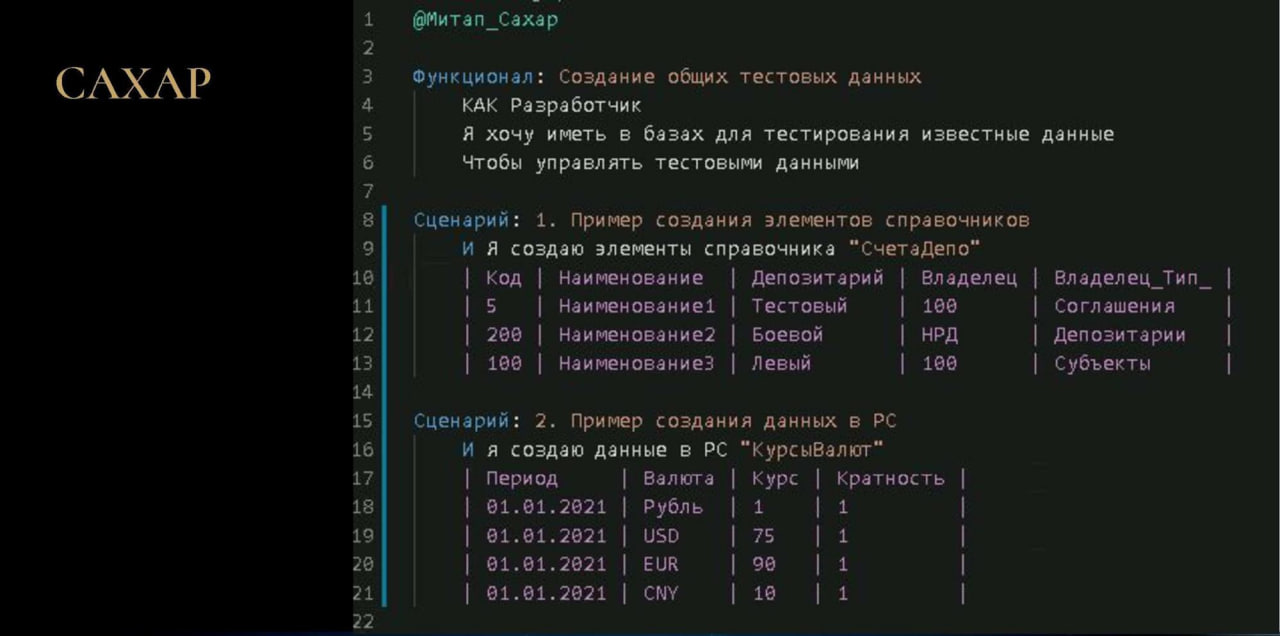
Вот так выглядит «сахар»:
-
у нас есть фича «Я создаю элементы справочника»,
-
параметром я ей передаю наименование справочника – в данном случае «СчетаДепо».
Соответственно, в конфигурации у нас есть все реквизиты этого справочника, мы просто идём по колонкам, ищем такой реквизит и заполняем его.
Если нам нужно заполнить не значением примитивного типа, а какой-то ссылкой, тогда мы ищем по наименованию. Если не нашли, то ищем по коду. Если не нашли, то падаем.
Очень простая вещь. И вот эта вещь, которая реально заставляет человека меняться.
Он сидел раньше и делал нудную тяжелую работу, ему было плохо – его заставляли тесты писать «Как же так? Что происходит?»
А рядом сидит человек, который написал вот такую интересную вещь. И все его хвалят, он на митапе выступил, все смотрят, думают, как у него все интересно.
И начинается «брожение умов», люди начинают автоматизировать свой труд.
И за счет того, что все реализовано на OneScript, это очень легко – ни один 1С-ник не может сказать: «Я не знаю, как этим пользоваться». Тут все на 1С – ты все знаешь и умеешь. Не умеешь? Бери и смотри.
Я очень радовался, когда пришли мерж-реквесты на мои скрипты автопрогона. Это значит, что уже есть люди, которые пишут свои скрипты – для обновления базы из текущей ветки, или наоборот, для сборки поставки. Это все работает.
Фича для тестирования логики для обычных форм
Из-за того, что у нас обычные формы, мы не можем использовать менеджер тестирования, клиент тестирования. Мы тестируем логику.
Грубо говоря, мы проверяем, что у такого-то клиента остаток в отчете будет 4.
А при прогоне этой фичи может быть задействовано пять обработок, запускающихся в разном порядке – формирующие документы, удаляющие и это все.
На слайде показан пример такой фичи.
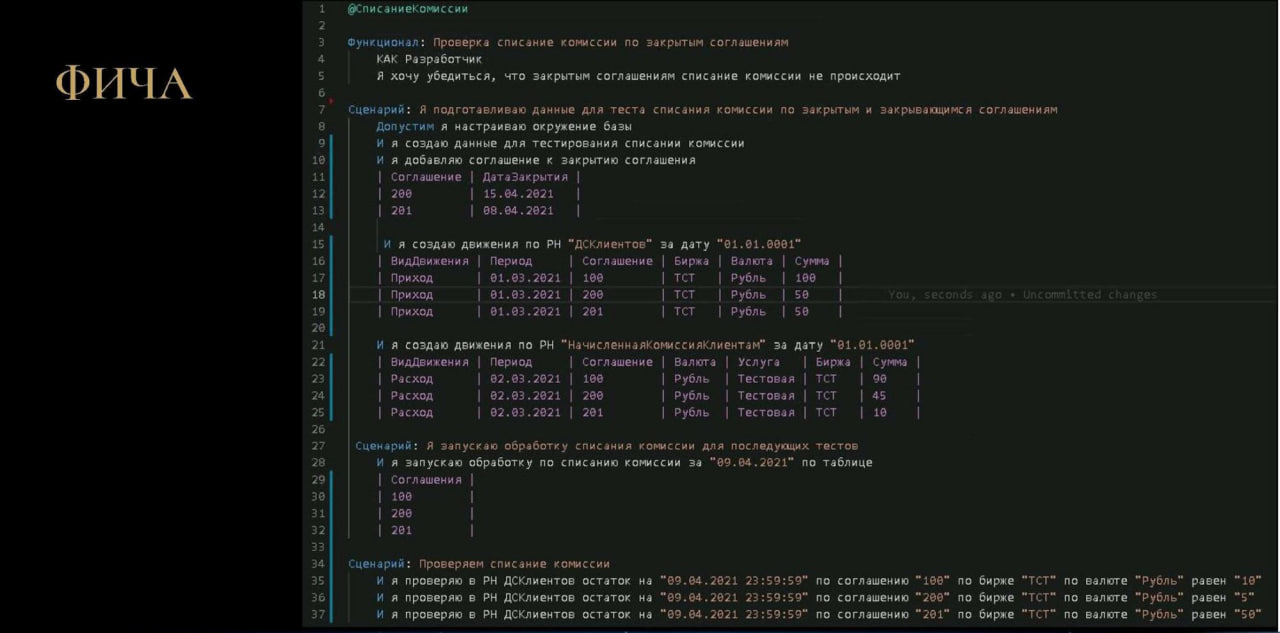
Эта фича проверяет логику.
Сначала мы задаем какие-то начальные данные – создаем людям остатки в денежных средствах:
-
по соглашению «100» вводим 100 рублей
-
по соглашению «200» вводим 50 рублей
-
по соглашению «201» вводим 50 рублей
Затем мы начисляем, что мы с них хотим снять:
-
у соглашения «100» мы хотим снять 90 рублей
-
у соглашения «200» хотим снять 45 рублей
-
у соглашения «201» – 10 рублей.
Итого, проверяем, сколько должно остаться:
Казалось бы, по соглашению «100» должно остаться 10, по соглашению «200» должно остаться 5, а по соглашению «201» должно остаться 40. Но у нас 8 апреля закрылось соглашение «201», а соглашение «200» закроется 15 апреля. Расчет комиссии мы запускаем за 9 апреля, то есть соглашение «201» уже закрылось. И тогда по соглашению «201» как было 50, так и осталось, потому что с закрытых соглашений нельзя списывать остатки, оно уже закрылось.
Таким образом мы проверяем высокоуровневые фичи.
И еще – из-за того, что нельзя пользоваться менеджером и клиентом тестирования, у нас встал вопрос, как запускать тесты под разными пользователями.
Пришлось городить на OneScript. Если в фиче первой строкой стоит комментарий, и там написано «Пользователь такой-то», то, поскольку в OneScript есть регулярки, это делается очень легко. Мы запускаем клиента от нужного указанного пользователя, и таким образом тестируем функциональность под разными пользователями.
Сборка релиза
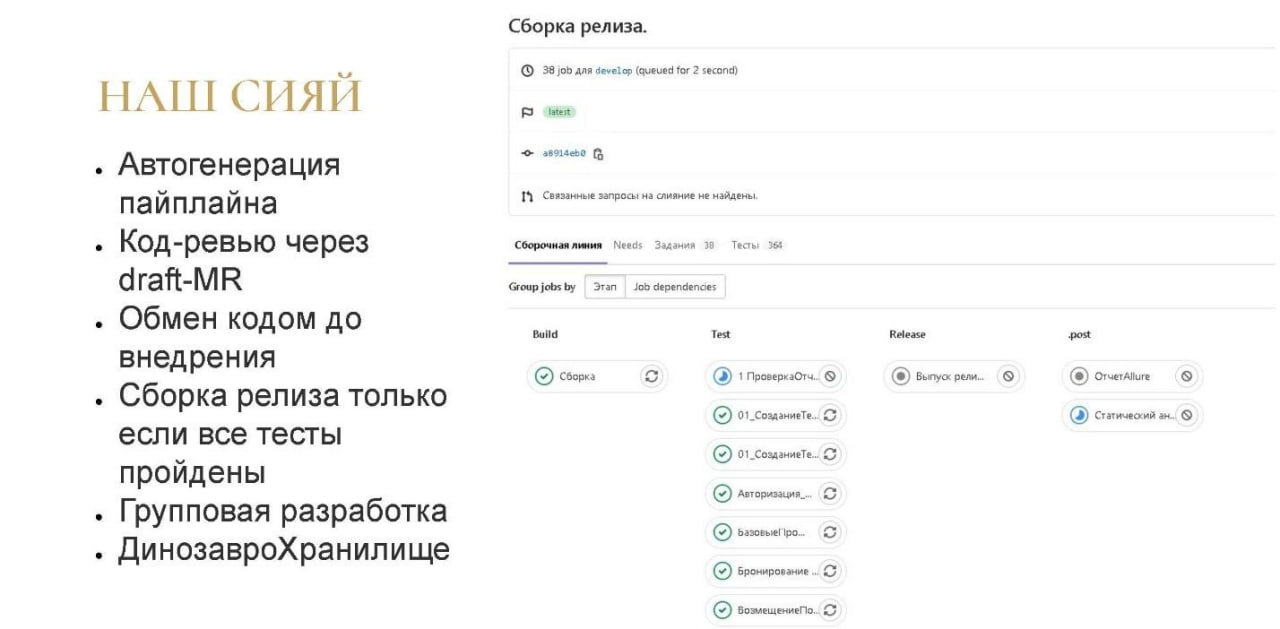
Собственно, вот так выглядит наш CI.
-
Предусмотрена автогенерация пайплайна. Поскольку очень сильно хотелось сделать так, чтобы каждая фича, каждый тест запускался отдельно – пришлось написать генерацию. Скрипт на OneScript обходит весь каталог библиотеки, собирает все фичи, которые нужно запустить и по шаблонам генерирует пайплайн (yaml-файлик для GitLab CI), в котором перечислены все джобы.
-
И таким образом получается, что:
-
у нас есть сборка;
-
потом в параллель запускаются все тесты, и за счет этого достаточно быстро все проходит;
-
затем по некоторым условиям запускается выпуск релиза – делается сборка поставки и запускается статический анализ кода, как раз чтобы людям показать, что в их коде не так (что нужно пробелы после запятых ставить).
-
-
Люди, которые этим начали пользоваться, очень быстро распробовали и делают code review через черновики мерж-реквестов. Там сразу видно все изменения. Очень удобно, тимлиды очень радостно этим пользуются.
-
Обмен кодом до внедрения – еще даже до того, как что-то внедрилось. Ты можешь из другой ветки себе забрать какое-то изменение, даже которое еще не внедрено, тебе потом будет даже легче объединяться.
-
Сборка релиза, только если все тесты пройдены.
-
И те, кто еще не перешел на новую методику, они еще работают в хранилище. Из хранилища мы GitSync'ом перегоняем все их изменения, и на каждый коммит в основную ветку запускаются тесты. Поэтому, если кто-то залился в хранилище, минуя все наши модные инструменты и что-то сломал, мы сразу видим, на каком коммите что сломалось, поднимаем панику, и они исправляют.
Вот так у нас все построено.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.
Технологический консалтинг и DevOps для 1С
Мы решаем проблемы производительности, инфраструктуры и автоматизации разработки на 1С
Вступайте в нашу телеграмм-группу Инфостарт