Меня зовут Игорь Левин, я – разработчик 1С в компании Спортмастер.
1С занимаюсь уже 18 лет. В Спортмастере работаю с 2020 года. Занимаюсь проектом ShipDocs v2.0 – это самописная конфигурация, которая предназначена для генерации и согласования нагрузочных документов для получения товаров, произведенных нашими друзьями-китайцами.
Типы автотестов

В рамках нашего ИТ-департамента есть центр компетенции QA, который выделяет 5 типов автотестов:
-
юнит-тесты;
-
интеграционные тесты;
-
Screen-тесты;
-
end-to-end-тесты;
-
Health-тесты.
Расскажу немного теории об этом.

Юнит-тестирование – это процесс программирования, позволяющий проверить на корректность работы процедуры и функции. Все внешние вызовы имитируются – т.е. тестирование проходит в закрытом контуре. Такое тестирование обычно проводит разработчик.

Интеграционное тестирование – это тестирование взаимодействия и связей каких-то частей одной системы или взаимодействия и связей нескольких систем. Подразделяется на подтипы:
-
компонентные тесты;
-
API-тесты;
-
и тесты внешних связей.

Screen-тестирование – это автоматизированное визуальное тестирование элементов пользовательского интерфейса.

Сквозное или end-to-end-тестирование – это тестирование системы в целом с эмуляцией реальной пользовательской среды. Обычно тестированию подвергается целые бизнес-функции – у нас этим занимается тестировщик в ручном режиме.

Еще есть health-тесты – это тестирование рабочей среды после накатки релиза, чтобы понять, что своим релизом мы не сломали систему.

Для автоматизации мы выбрали два типа из этих пяти – это юнит-тесты и интеграционные тесты. И это не случайно, потому что мы работаем от боли – было больно, и мы решили это поправить.
В данном случае интеграционные тесты у нас двух типов, они предназначены для решения двух проблем:
-
чтобы проверить свой код без участия второй стороны;
-
чтобы проверить перед релизом, что смежники пронесли свои структуры, и релиз можно накатывать – ничего не сломается.
А юнит-тесты мы пишем не на все подряд, а только на какие-то механизмы, которые долго, тяжело, больно тестировать.
Выбор варианта реализации

Далее возник вопрос: если мы хотим использовать автотесты, что нам выбрать – взять что-то уже имеющееся на рынке или реализовать собственный путь?

Плюсы решений, которые есть на рынке:
-
Их не нужно разрабатывать, они уже готовы.
-
В них изначально заложена обширная функциональность.
Но как всегда есть и минусы.
-
Во-первых, нужно разбираться с той функциональностью, которая есть, настраивать ее под себя. И тут есть шанс, что ты не сможешь 100% под себя настроить.
-
Есть риски, что решение перестанут поддерживать, и тогда нужно будет с этим что-то делать.
-
Не всегда вся заложенная функциональность нужна целиком. Чтобы полечить свои боли, скорее всего, нужно будет около 10%, но остальное все равно придется изучать, хотя тебе это пока не нужно.

С другой стороны свой путь.
-
Разрабатываешь сам под себя только то, что нужно.
-
Всегда можешь подкрутить.
-
Поддержка не прекратится, пока он тебе не надоест.
Но из минусов – нужна разработка.

Ну и сюрприз-сюрприз, у нас был выбран свой путь. Причем он был выбран еще до моего появления в компании Спортмастер.
В решении были реализованы некоторые подходы, имеющиеся на рынке, которые оказались неудачными. Поэтому когда я пришел, встала задача – нужно заняться реализацией автотестов.

Встала задача – стали обсуждать, что использовать:
-
Использовать ли какую-то подсистему в рамках основной конфигурации.
-
Использовать внешние обработки (в предыдущей компании, в которой работал, использовались внешние обработки).
-
Или использовать расширение.

Минусы отдельной подсистемы в рамках основной конфигурации:
-
По ошибке код автотестов можно пронести на рабочую среду – поскольку хранится все равно все вместе, ошибся и пронес.
-
Еще большим минусом является то, что нужны лишние обвязки для тестируемых процедур и функций.
-
Плюс, если что-то нужно протестировать, приходится обязательно помечать вызываемый метод ключевым словом «Экспорт». А зачем, если это не требуется?

Внешние обработки. У них тоже минусы:
-
те же самые обвязки, тот же самый лишний Экспорт;
-
и дополнительная проблема – это их хранение. Для хранения истории разработки можно и Git подключить, но зачем, если можно этого не делать?

На слайде – кусочек кода из типовой конфигурации, где показано, как выглядят эти лишние обвязки для автотестов.

Идеальным мы сочли расширение.

У расширения есть следующие плюсы.
-
Код расширения хранится отдельно от кода конфигурации – пронести его по ошибке в продуктовую среду уже не получится.
-
Расширения поддерживают механизм хранилища. Это хороший стабильный механизм, которым можно пользоваться для групповой разработки. Кроме того, он также хранит историю.
-
Ну и одним из самых важных пунктов является то, что в расширении есть аннотации «Вместо» и «После».
-
«Вместо» мы используем для интеграционных тестов;
-
«После» – для юнит-тестов;
-
Аннотации позволяют реализовать всю логику тестирования, не используя никаких ключевых слов «Экспорт».
-
Общая архитектура разработки

На слайде – схема, показывающая, как мы разрабатываем в нашем подразделении.
-
Разработчик на своей базе пишет код, тестирует его, там же может запустить автотесты.
-
Когда разработчик завершил отладку, он кладет основной код в разработческое хранилище. А код автотестов – в хранилище расширения тестирования.
-
Дальше по задачам, которые уже закончены, тестировщик вручную переносит код частями в тестовую базу для ручного тестирования.
-
А для запуска автотестов есть отдельная конфигурация (на схеме она не показана) – раз в день она автоматически обновляется и на ней прогоняются автотесты.
-
Плюс у нас прикручен SonarQube, который проверяет, как мы пишем код.
Это – тестовый конур.

А это – рабочий контур. Тут разница с предыдущим слайдом в том, что:
-
Из разработческого хранилища мы помещаем в рабочее хранилище код, который необходимо накатить на рабочую базу, но пока не обновляем через F7.
-
Запускаются автотесты – проверяется доступность структур.
-
Если все хорошо, можно нажать F7 и обновить конфигурацию базы данных.

Вот наш прекрасный коллектив, которым мы ведем разработку.
Обработка по запуску автотестов и логика ее работы
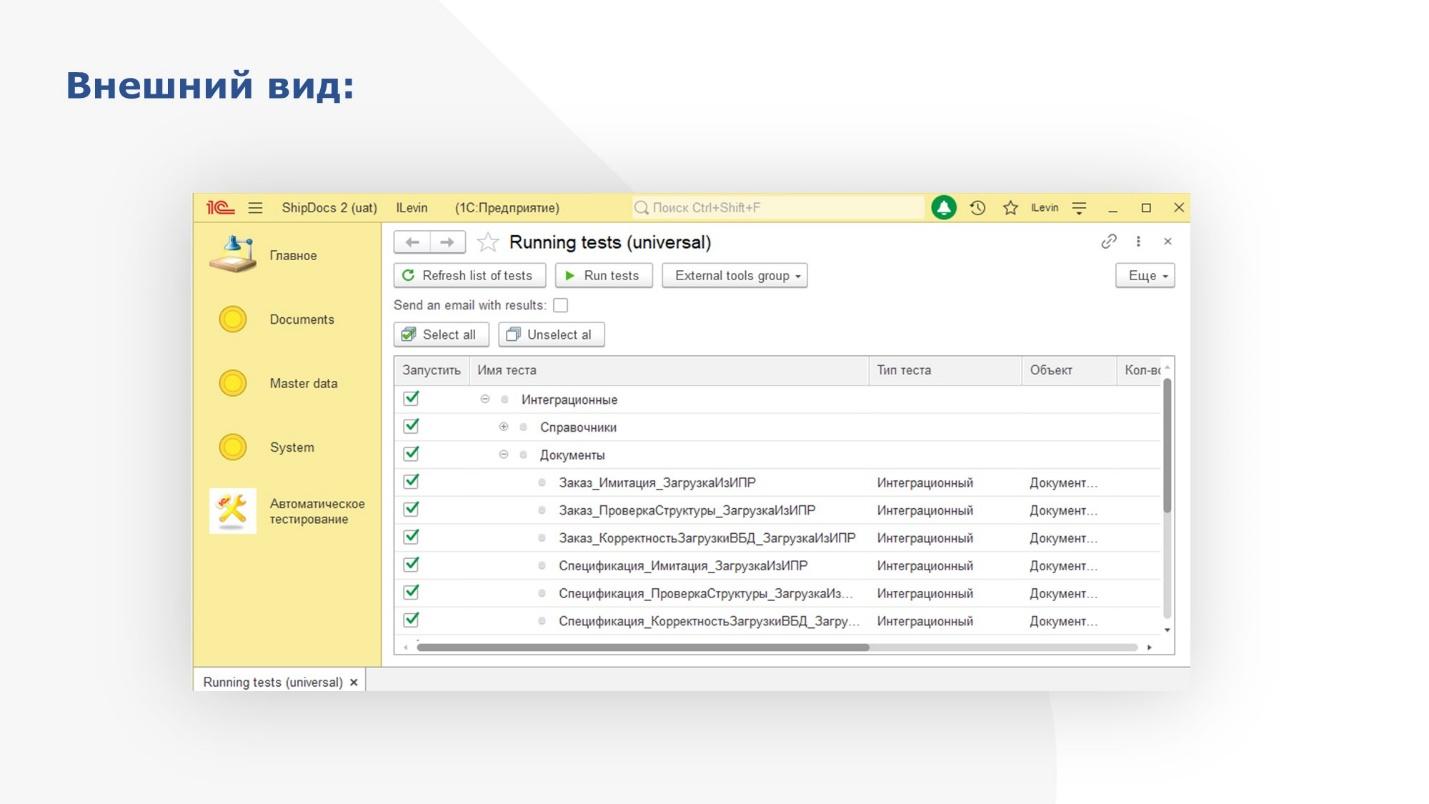
На слайде показана основная обработка по запуску автотестов. Тут из интересного, наверное, только дерево тестов.
-
Верхний уровень – это тип теста. Здесь – интеграционный.
-
Ниже уровнем идут типы объектов – справочники, документы, регистры.
-
И на последнем уровне находятся сами имена тестов.
Поскольку мы начинали с интеграции, нам показалось уместным хранить тесты именно пообъектно.
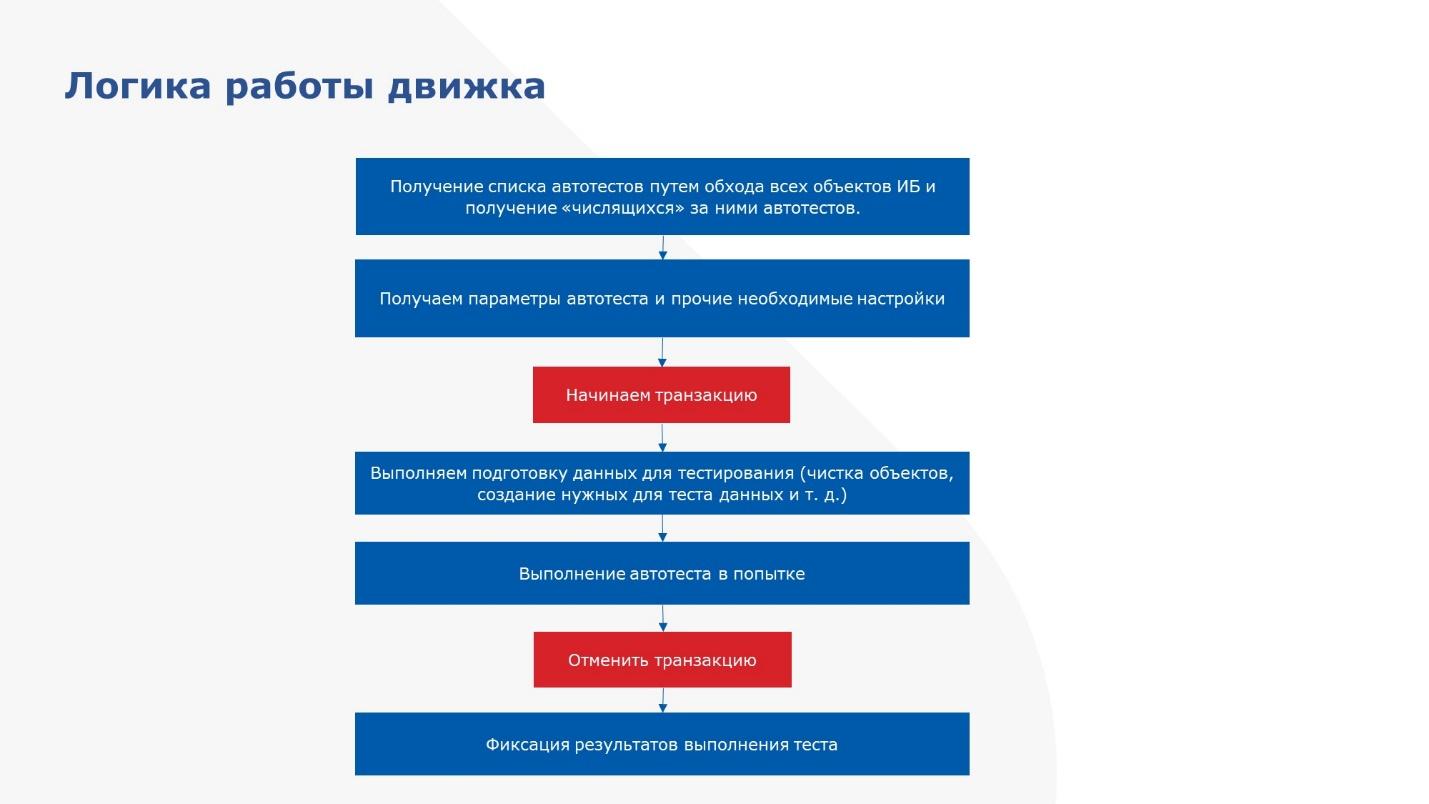
На слайде – схема работы обработки по запуску автотестов.
-
Сначала строим дерево автотестов.
-
Далее оббегаем его, чтобы перед запуском конкретного теста получить его входные параметры.
-
Начинаем транзакцию.
-
После того как начали транзакцию, готовим базу к тесту – добавляем какие-то данные, изменяем, удаляем, зависит от того, что нужно.
-
После этого выполняем тест и получаем результаты.
-
Далее – отменяем транзакцию, чтобы база вернулась в исходное состояние.
-
И передаем в обработку результаты выполнения.

Из чего состоит расширение? Его основные части – это:
-
обработка по запуску;
-
кучка обработок с автотестами;
-
общие модули для служебных процедур и функций;
-
плюс модули тех объектов, которые мы тестируем – в основном это модули менеджеров (там также могут быть любые модули).
Пример теста для модуля менеджера в расширении

На слайде показан пример копии модуля менеджера для любого типичного справочника или документа, который мы тестируем в расширении.
Типичная копия модуля менеджера в расширении для тестирования имеет четыре процедуры и функции:
-
Первая процедура – для получения списка автотестов при построении дерева.
-
Вторая функция получает входные параметры автотеста.
-
Третья функция связана с основной задачей нашего интеграционного тестирования – нам важно тестировать загрузку-выгрузку данных из Oracle. А там типичной является процедура для получения данных из Oracle. Третья функция производит ее перехват.
-
А последняя, служебная функция проверяет, что создание или изменение данных прошло корректно. Эта функция предназначена для того, чтобы сравнить те данные, которые мы записали в базу, с теми, которые мы предполагаем, что должны быть записаны.
Интеграционные тесты

Подробнее о самих тестах.

Интеграционные тесты.
-
Как я и говорил, основная интеграция у нас – это загрузка и выгрузка в Oracle.
-
Мы выставляем soap, rest и дергаем кого-то за soap, rest – для этих вариантов интеграции пока автотестов нет, но мы об этом подумываем.
Тестирование загрузки данных из Oracle

Как я говорил, при тестировании загрузки мы закрываем две основных задачи:
-
Первая это тестирование собственного кода на разработческом контуре без привлечения второй стороны.
-
И второе – это тестирование перед релизом. Тестируется соблюдение или несоблюдение контраста, а также доступность тех структур, которые мы хотели бы видеть.
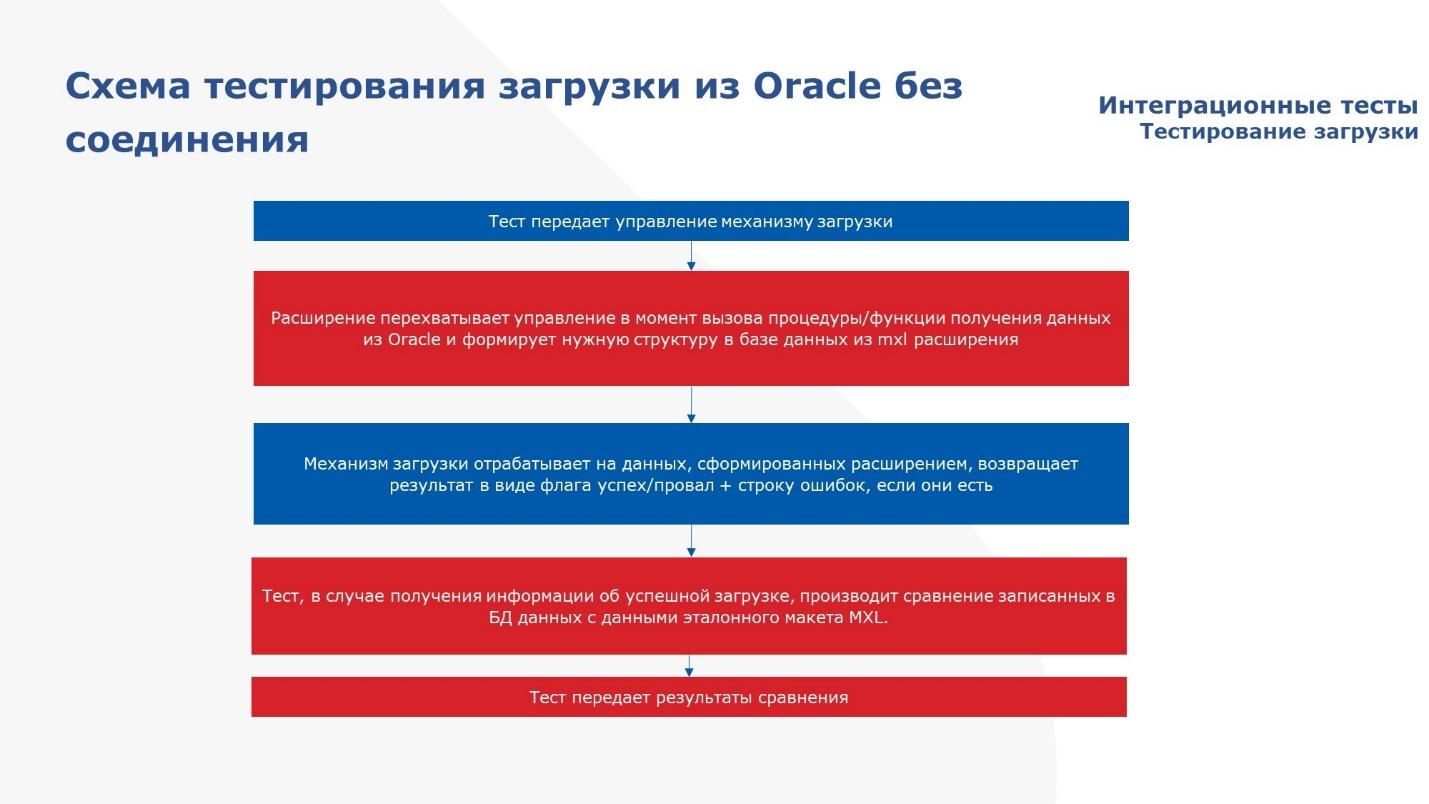
Вот схема теста. Выглядит следующим образом.
-
Наш тест передает управление механизму загрузки.
-
И в момент, когда загрузка пытается обратиться к Oracle, идет перехват расширением и подмена той структуры, которую должен был нам отдать Oracle, на данные, которые поднимаются из макета mxl.
-
Загрузка отрабатывает на данных, поднятых из макета и возвращает в автотест информацию об успешной или неуспешной записи в базу данных.
-
Если запись в базу произошла неудачно, тест падает, дальше не идет.
-
Если же все было корректно, тест продолжается и дальше мы сверяем ту информацию, которую записали в базу (получаем ее при помощи автосгенерированного в 1С запроса), с некими эталонными данными, которые у нас тоже в макете хранятся.
-
И потом по эстафете возвращаем результат – сначала в тест, а потом и в обработку по запуску.

В коде это выглядит вот так.

Вызываем загрузку.
В момент загрузки идет обращение к Oracle – оно перехватывается расширением, где мы подменяем данные Oracle собственными данными и возвращаемся в основную обработку.

Идет запись в базу данных тех объектов, которые загружаем, и возвращаем в автотест результат – успешно или неуспешно.
Если не успешно, записываем, какие ошибки возникли.
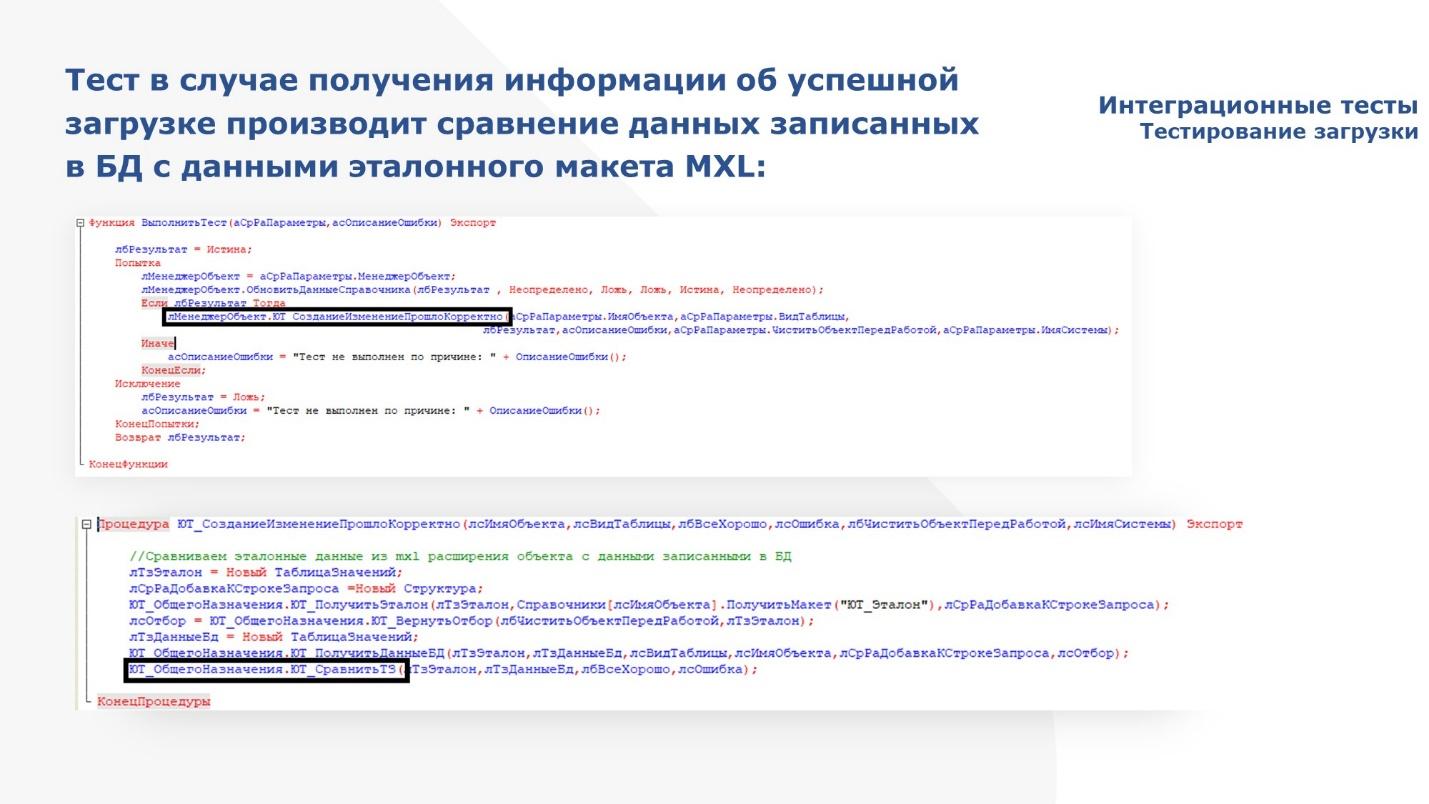
Если успешно, то далее сверяем с эталонными данными.

Ну и результат возвращаем в обработку по запуску.

Далее схема проверки структуры. Тут чуть по-другому.
-
Тест создает соединение с Oracle и передает его в механизм загрузки.
-
Механизм загрузки обращается к Oracle и получает оттуда набор данных – точнее структуру.
-
Дальше мы эту структуру сверяем с той структурой, которую считаем эталонной.
-
Результат возвращаем в обработку по запуску.

В коде это выглядит следующим образом – создаем соединение, вызываем обработку загрузки.

Получение данных из Oracle в обработке загрузки перехватывается расширением, но так как в условии проверки соединения используется метод «ПродолжитьВызов», для полученных данных отрабатывает стандартная загрузка из Oracle.

Дальше идет сверка структур.

Проверяется:
-
количество колонок, которые мы хотели загрузить;
-
имена колонок;
-
типы;
-
длина;
-
точность.
Все, что нужно.

По итогам мы возвращаем результат – успешно тест отработал или не успешно.
Тестирование выгрузки данных в Oracle

Дальше по мере развития нашей базы, загрузив все, что возможно, и обработав это, мы стали генерировать что-то свое.
Поэтому потребовалось тестировать выгрузку. Тут ровно те же задачи.
-
Это тестирование собственного кода без привлечения второй стороны.
-
И тестирование перед релизом – понять, что нам доступ предоставили к тем таблицам, к тем структурам, в которые мы хотим что-то положить. И есть ли они вообще.
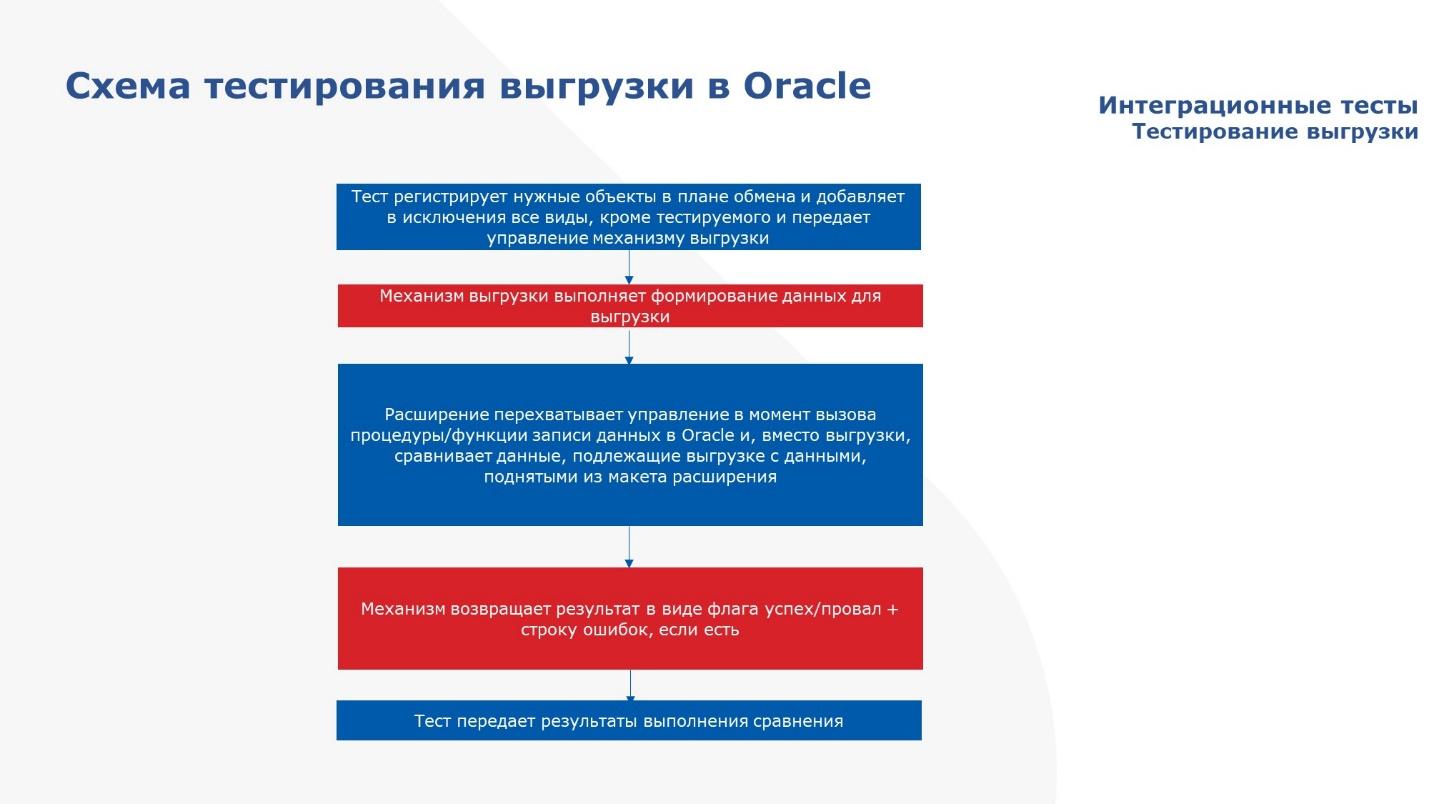
Тут очередная схема по работе теста.
-
То, что необходимо выгрузить, мы собираем при помощи планов обмена. Тест регистрирует нужные объекты в плане обмена стандартными средствами 1С, а ненужные оттуда вычищает (в исключение ставит) и передает управление механизму выгрузки.
-
Механизм выгрузки генерирует пакеты, чтобы положить их далее в Oracle.
-
Но перед тем, как он положит, идет перехват расширением и происходит сверка того, что хотели положить, с тем, что мы ожидали, что будет положено.
-
И результаты мы возвращаем.
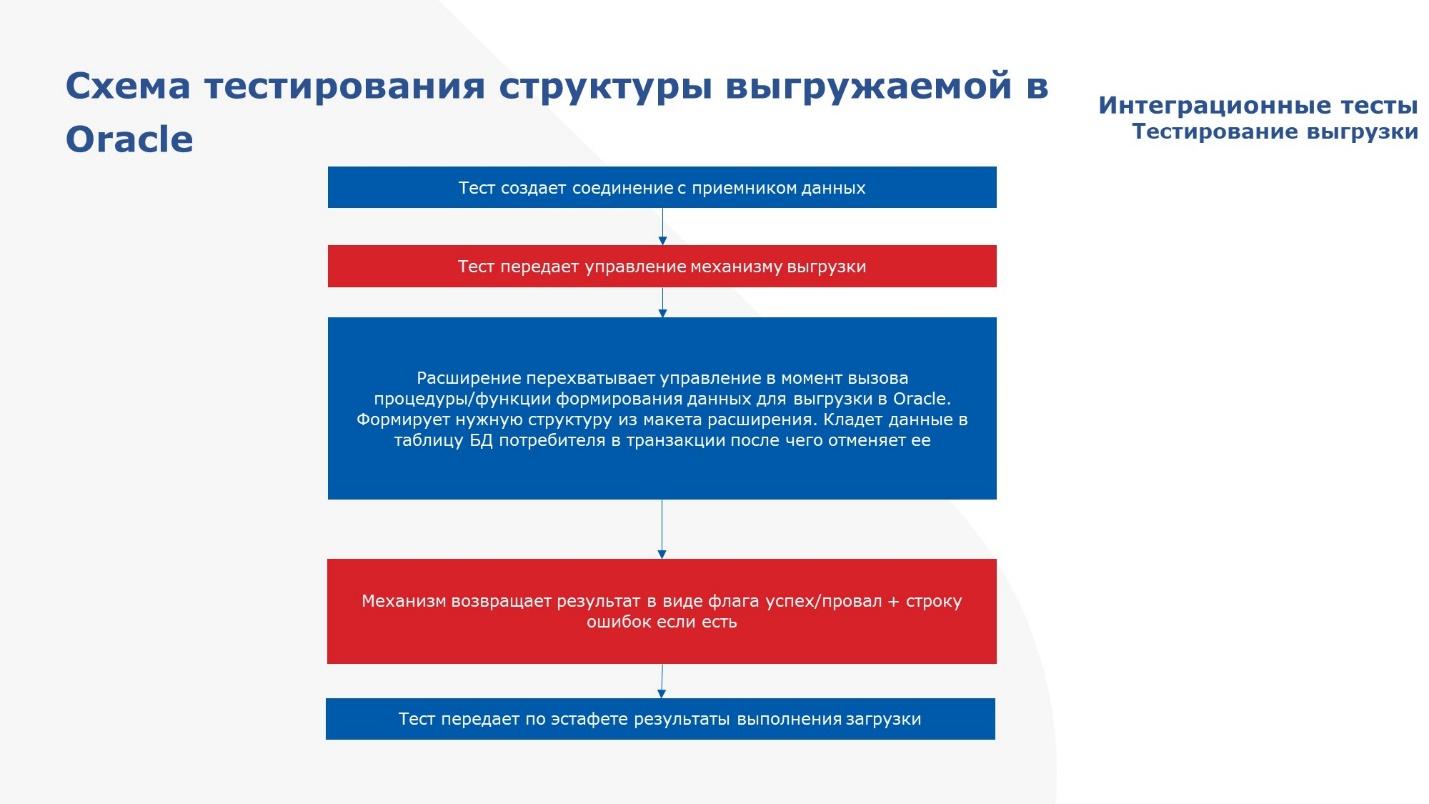
И второй тест на структуру.
-
Тут опять мы создаем соединение,
-
Передаем управление обработке по выгрузке – она так же формирует пакеты.
-
Расширение перехватывает оракловую транзакцию, формирует нужную структуру и кладет в таблицу базы данных только одну строчку – это нужно, чтобы никакие данные не остались по окончании проверки доступности структуры.
-
По окончании фиксируем результаты и отменяем транзакцию.
-
И далее передаем результат выполнения загрузки по эстафете.
Юнит-тесты. Тест на формирование документа «Упаковочный лист»
Дальше мы стали разрабатывать более сложные механизмы, которые было проблематично тестировать руками – это долго и нудно.
Поэтому решили написать юнит-тесты.

Один из таких тестов — это как раз тест на формирование документа «Упаковочный лист» (packing).
В этом документе есть три таблицы, которые взаимосвязаны и в прямом и обратном направлении: весогабариты группируются, разгруппируются, плюс там номера коробов тоже меняются в прямом и обратном направлении.
Внутри запрос километровый с десятками всяких таблиц – тестировать его изменения достаточно сложно.

Что мы сделали? Тоже опять элементарно.
-
Тест вызывает процедуру по формированию таблиц документа – четыре таблицы: три на табличной части и одну на шапку.
-
Далее поднимает собственные эталонные и попарно их сверяет.
-
Если ничего не сбилось – все группировки на месте, округления нигде не перепутали, строк не стало меньше, больше – значит все отлично.
-
Сверили, результат передали.
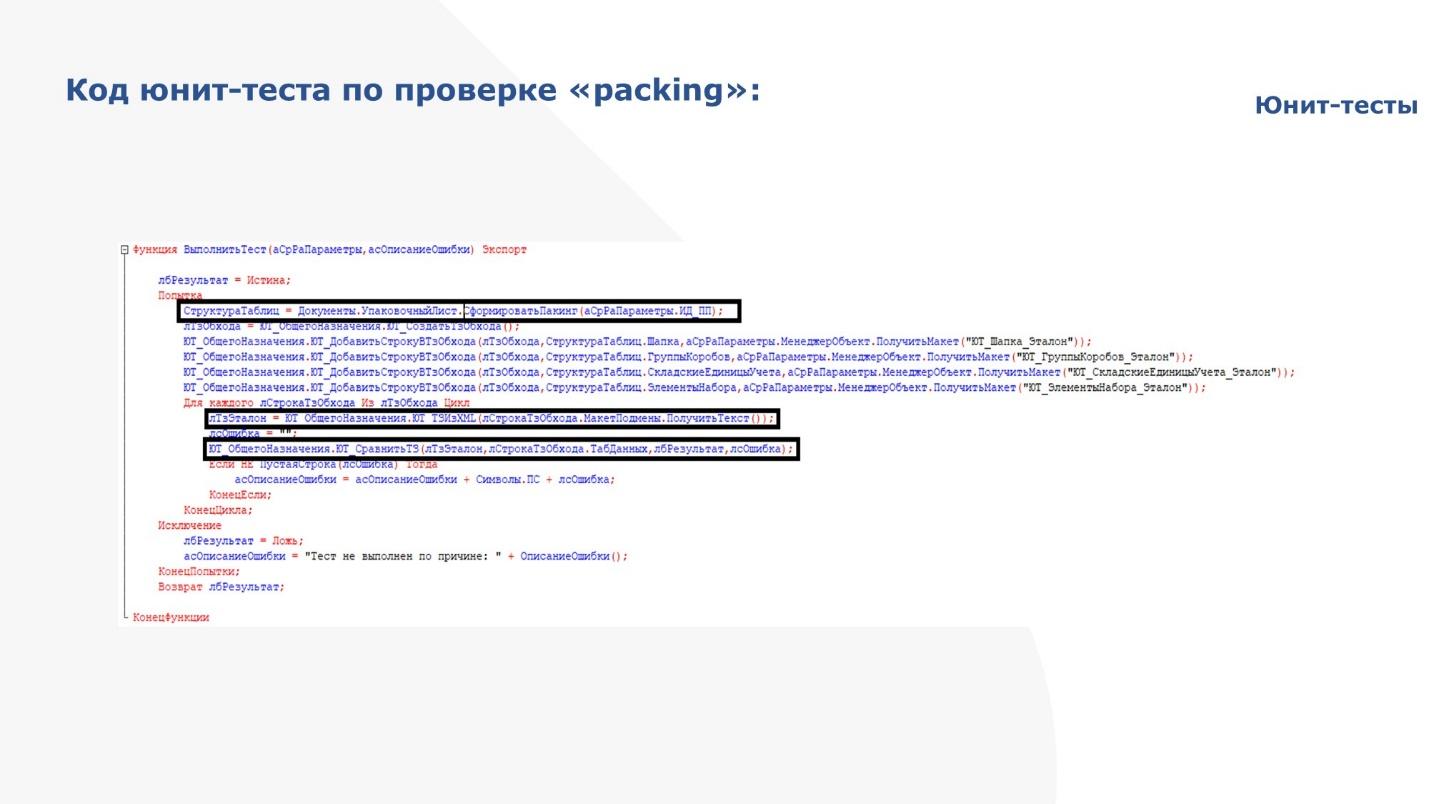
На слайде – весь код этого теста.
Первая выделенная строчка – это вызов стандартной процедуры по формированию документа.
Дальше поднимаем свои макеты и попарно сверяем
Результат возвращаем в основную обработку.
Запуск тестирования. Вручную и скриптом

На слайде показано, как выглядит список тестов в нашей обработке, после того как они все отработают.
Зелененьким помечены тесты, в которых все же хорошо, красненьким – не очень хорошо.
И выводится статистика – сколько времени работал тест, сколько тестов было запущено.

Чтобы автотесты запускались, мы попросили админов сделать для нас на PowerShell скрипт, который:
-
Обновляет базовую конфигурацию из хранилища конфигурации.
-
Далее обновляет расширение из хранилища расширения
-
Потом накатывает это все на конфигурацию базы данных.
-
После чего под определенным пользователем запускается 1С:Предприятие и под этим пользователем запускается обработка по запуску автотестов.
-
Обработка отрабатывает и делает рассылку о том, насколько все хорошо или нехорошо – сколько тестов отработало, сколько не отработало.
Планы

Наши перспективы.
-
С одной стороны, мы сейчас хотим привлечь к составлению тестовых данных тестировщика – сделать для них в 1С:Предприятии отдельный слой, чтобы снять нагрузку с разработчиков и не пускать тестировщиков в конфигуратор.
-
С другой стороны, хотим написать автотесты на HTTP, SOAP и сервисы.
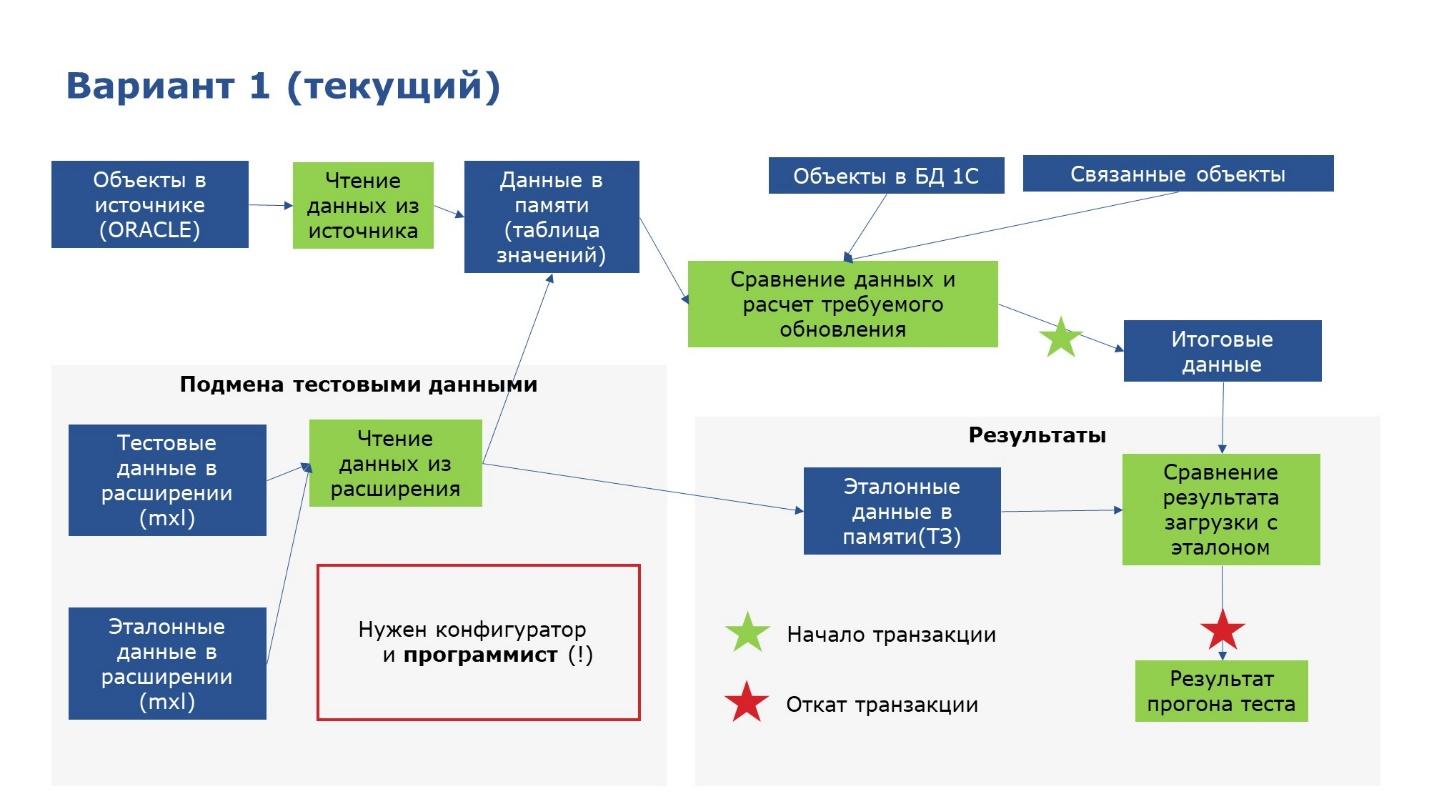
Поясню, как мы хотим подключить тестировщика к составлению тестовых данных
Сейчас система такая.
-
Разработчик в конфигураторе добавляет тестовые данные, эталонные данные.
-
Тестовые данные подменяют оракловые, а эталонные сверяются с данными базы данных.
Все прекрасно, все удобно, но хотелось бы, чтобы не только разработчик работал, но и тестировщик.

Поэтому хотим добавить еще один слой – добавить в расширение справочник, и заполнять его в 1С:Предприятии данными из конфигуратора.
Это позволит тестировщику добавлять туда свои наборы данных интерактивно, чтобы лучше протестировать.
Вопросы
Планируется ли опубликовать это решение в open source или это внутреннее решение Спортмастера?
Это пока внутреннее решение.
Почему вы не взяли что-то из существующих решений, а все-таки свое написали?
Доподлинно не знаю, потому что я присоединился не в самом начале, а чуть позже. Ребята пробовали, и что-то у них не пошло. Видимо неудобно было. Или, может быть, еще что-то.
Вы используете mock-тестирование (с помощью заглушек для внешних сервисов) только для интеграции с Oracle или для интеграции других сервисов тоже используете?
Пока только Oracle. Хотели еще веб-сервисы тестировать. Пока мы внедряем то, что нас больше всего беспокоит по мере развития базы.
Каким образом вы управляете тестовыми данными? Понятно, что тесты пишутся внутри расширений, а сами тестовые данные как готовятся?
В макетах – есть MXL, есть XML.
В расширении очень удобно, что тестовые данные хранятся вместе с кодом. Это огромный плюс расширения. Это не обработки, где обработка лежит в одном месте, фикстура – в другом месте, код, который запускает эти обработки – в третьем месте. В расширении все это скомпоновано.
Как вы управляетесь с расширениями? Там же в зависимости от вида расширения у них меняется порядок загрузки при компиляции.
У нас одно расширение, поэтому управлять особо нечем.
Вот вы отменяете транзакции. Получается, вы клиентские методы вообще никак не проверяете, только серверные?
Сейчас да.
Для серверных и интеграционных тестов, когда UI фактически вообще нет – отмену транзакций использовать удобно. Если только это не полный интеграционный тест, когда нужно зафиксировать транзакцию, чтобы другая система смогла получить какой-то ответ.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse
Вступайте в нашу телеграмм-группу Инфостарт