Облако и антиоблако

Начну с «минутки токсичности», расскажу, почему тот 1С:Fresh, который нам предлагает 1С, – это “антиоблако”.
В современном мире мы разделяем обычно разделяем: отдельные БД, отдельные схемы, отдельные сервисы. Даже если общая БД - разделяем БД по приложениям\по шардам\по схемам\по пространствам и т.п.
Короче, всё облачное подразумевает то, что мы что-то делим – по принципу «Разделяй и властвуй».

А в 1С, наоборот, в какой-то момент времени пришли к так называемой концепции Multi-tenant, притом в самом жутком её варианте - с одной БД для всех клиентов. На поверку это означает, что мы базы объединяем. У нас была куча маленьких клиентов, у которых Highload нет, мы их объединили в одну базу и сделали Highload там, где его не было.
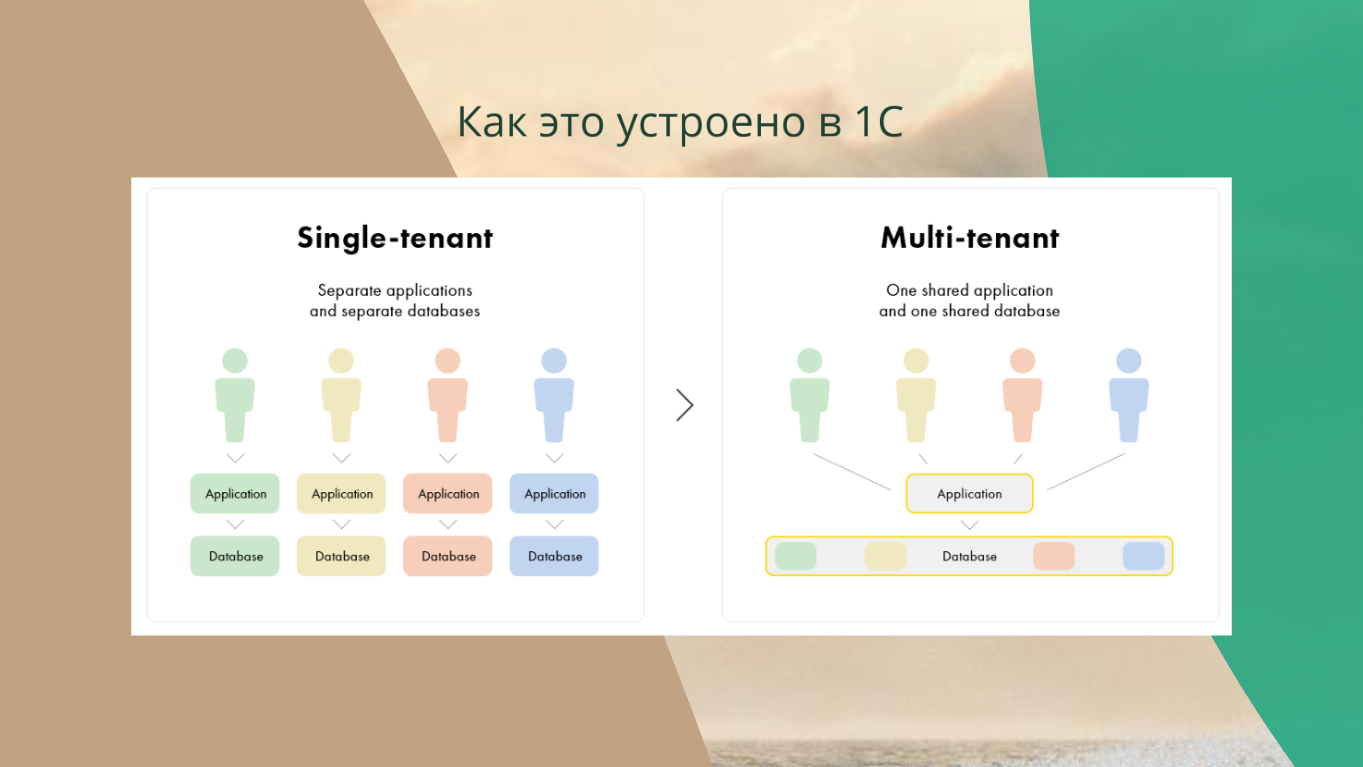
С точки зрения обслуживания казалась, что концепция Multi-tenant правильная – нам не нужно обслуживать 300 баз, а достаточно обслуживать одну базу с общей конфигурацией.
Но на поверку это значит, что у вас было 30 таблиц по миллиону записей и стала одна таблица на 30 миллионов. С точки зрения СУБД это плохо.
Хотя проблем с масштабируемостью у 1С нет, потому что сервер 1С – это фактически Stateless-приложение – некая считалка, которая ничего не хранит (я знаю что хранит, но все данные в БД). Сервер 1С можно сравнить с банальным сервером на Node.js, который выполняет на сервере код JavaScript и возвращает результат. Сервер 1С работает так же – получает на вход код 1С, берет данные из базы и возвращает результат. Поэтому 1С легко масштабировать – нод в кластер 1С вы можете добавить сколько угодно, они будут работать. Это всё без проблем масштабируется.
Сервер СУБД у нас обычно узкое место. И объединять в одну большую базу всех людей, у которых могли бы быть маленькие базы – это зло.
Практика показывает в мире, что добро — это когда мы все скриптуем. В современном мире не проблема выполнить одно административное действие с трехстами, четырехстами базами. Это делается быстро, просто и успешно. Это решают DevOps или SRE – у которых уже вагон инструментария, с этим все наработать научились.
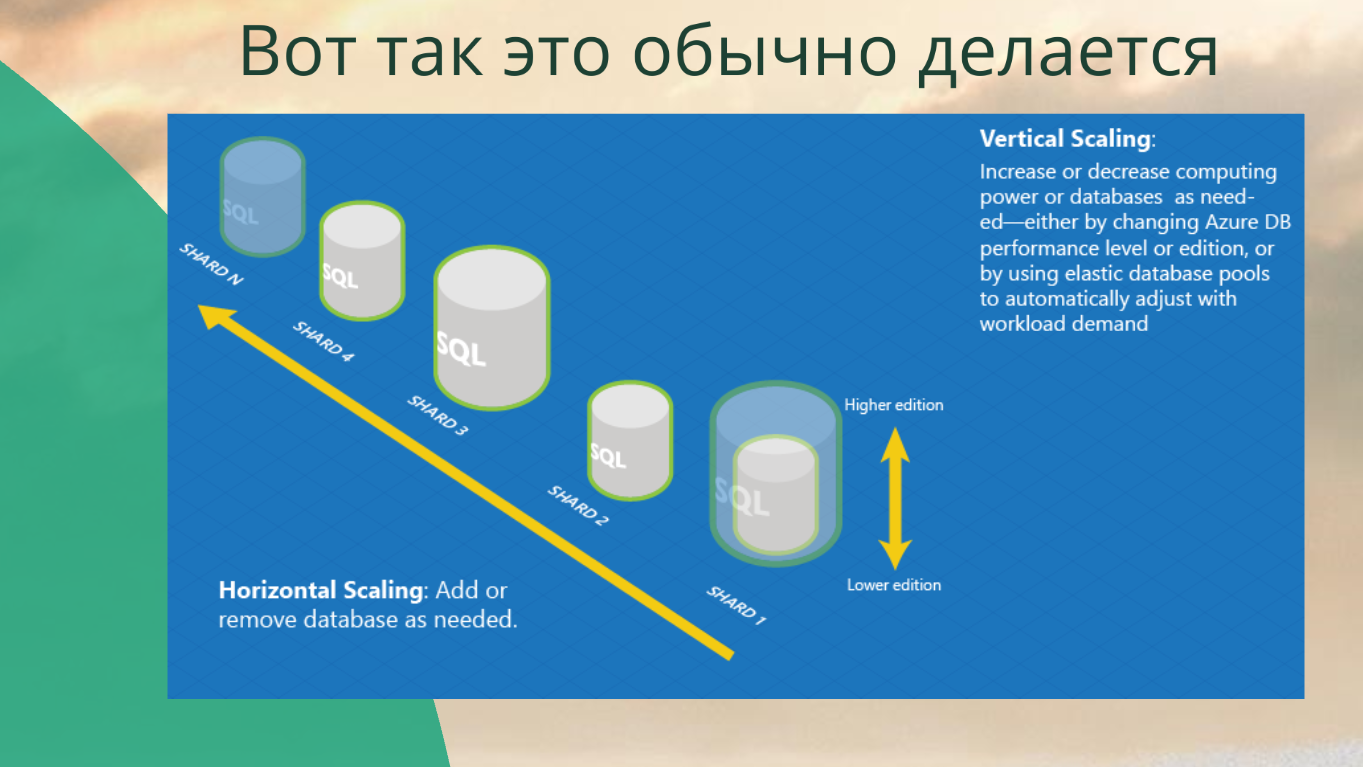
В современном мире облачные СУБД масштабируются на уровне новых БД без проблем.
На слайде – картинка с Azure. Azure научил свой SQL-сервер как вертикальному скейлингу, так и горизонтальному. Они и шарды умеют добавлять, и скейлить каждую ноду.
Вертикальный скейлинг у нас всегда ограничен, поэтому, когда мы говорим про клауд, ключевая история – это горизонтальное масштабирование. Про него мы будем говорить чаще всего.
PostgreSQL и Yandex Cloud

Ладно, минутка теории (или хейта) закончилась. Перейдем к практике. Расскажу про PostgreSQL в клауде.
Важно: Когда я буду говорить про клауд, я буду в основном говорить про Yandex.Cloud. Не потому, что я хейтер AWS или чего-то другого. Просто Яндекс наиболее полно отвечал картине с точки зрения РФ. Может быть, это уже не так, но не буду сейчас это обсуждать, не хочу никого рекламировать.

AWS тоже безумно люблю, для пет-проектов использую, он прикольный.
Но как думаете, почему я не буду рассказывать про AWS в контексте 1С? Потому что у нас есть 152-ФЗ. Практически всегда мы в 1С храним либо финансовую информацию храним, либо персональные данные. Практически у всех персональные данные есть, поэтому в AWS нам путь заказан, как бы мы не хотели.
У AWS есть еще одна проблема – он вам всегда предложит блочное хранилище. А блочное хранилище для транзакционных СУБД – это плохо. Дальше поговорим, почему.
Первичная настройка

Дальше – чистая практика. Расскажу, как настроить PostgreSQL в Yandex Cloud.
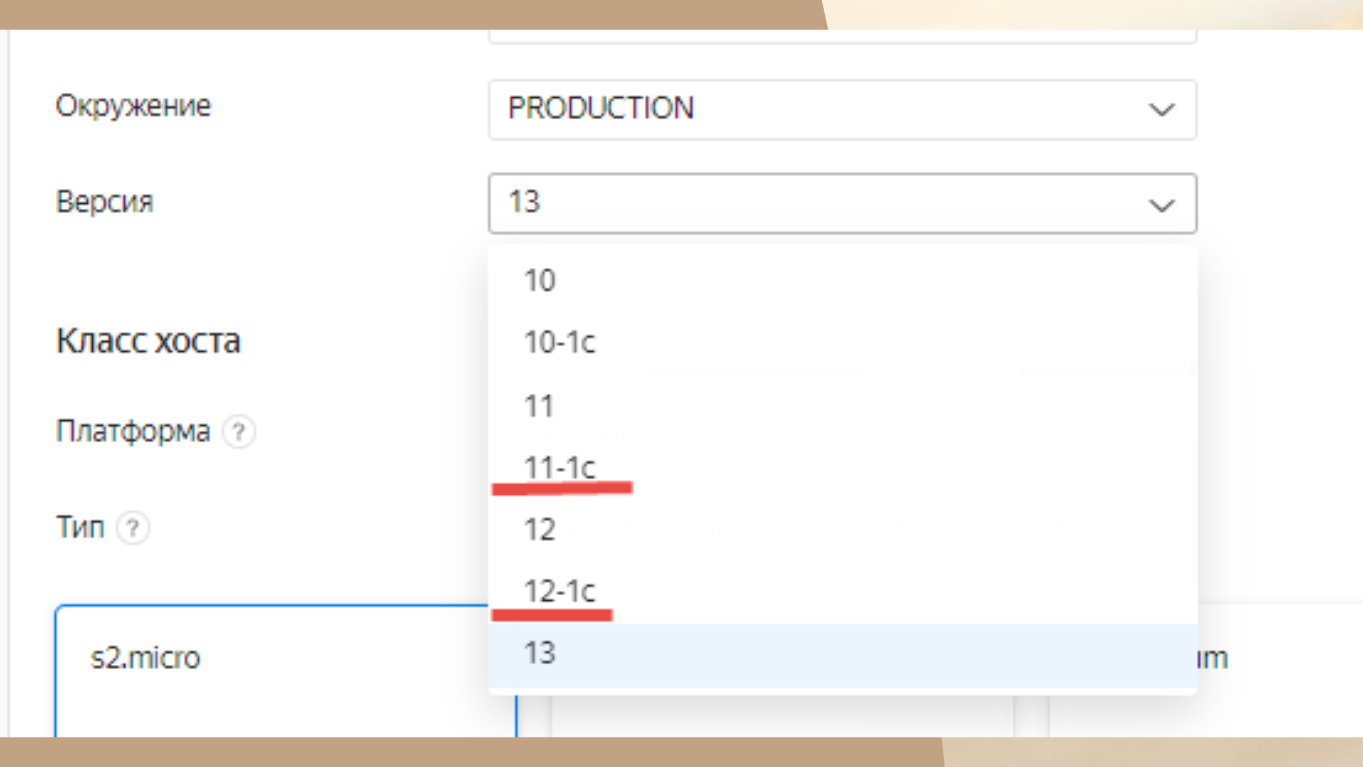
Когда вы создаете инстанс PostgreSQL в Yandex Cloud, первое, что он вас просит – это указать версию.
Обратите внимание, здесь есть 10-1с, 11-1c, 12-1c – это наши специальные 1С-ные сборки.
Выбираем нужную – и все, больше ничего делать не надо.
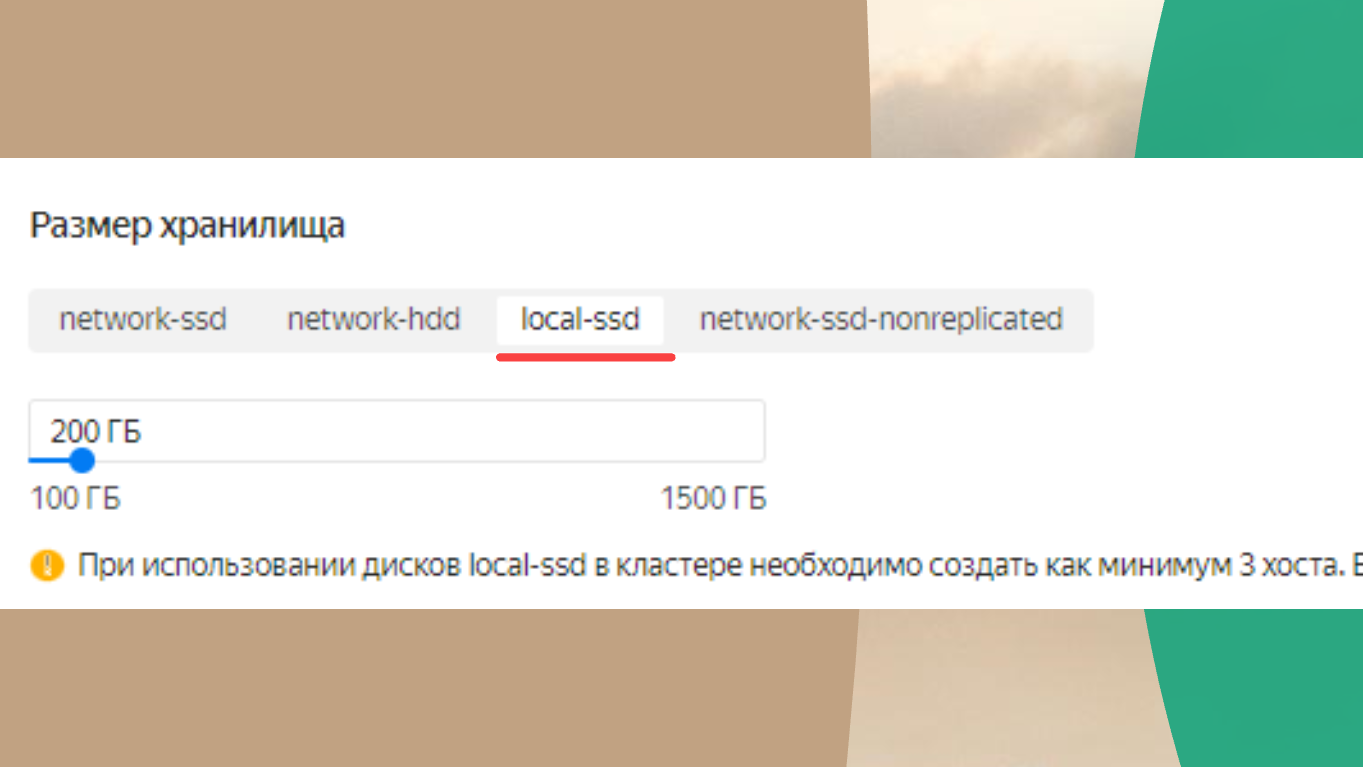
Главный лайфхак – в качестве размещения обязательно нужно указать local-ssd.
Дело в том, что сетевые блочные хранилища дают для 1С существенные задержки (latency), которые будут увеличиваться для транзакционных и OLTP-систем.
Даже если у вас система дает много IOPS, это не значит, что она будет работать быстро. Чтобы система могла работать быстро, у вас в основном должны быть мелкие транзакции. Поэтому вам ни IOPS, ни Bandwidth ничего не поможет – вам нужен low latency. Самый low latency – это когда у вас ssd стоит локально в сервере.
Яндекс – молодцы в этом отношении. Видимо, кто-то умный догадался, что это нужно, и они это сделали. Но, конечно, у этого есть определенные нюансы, о которых расскажу далее.
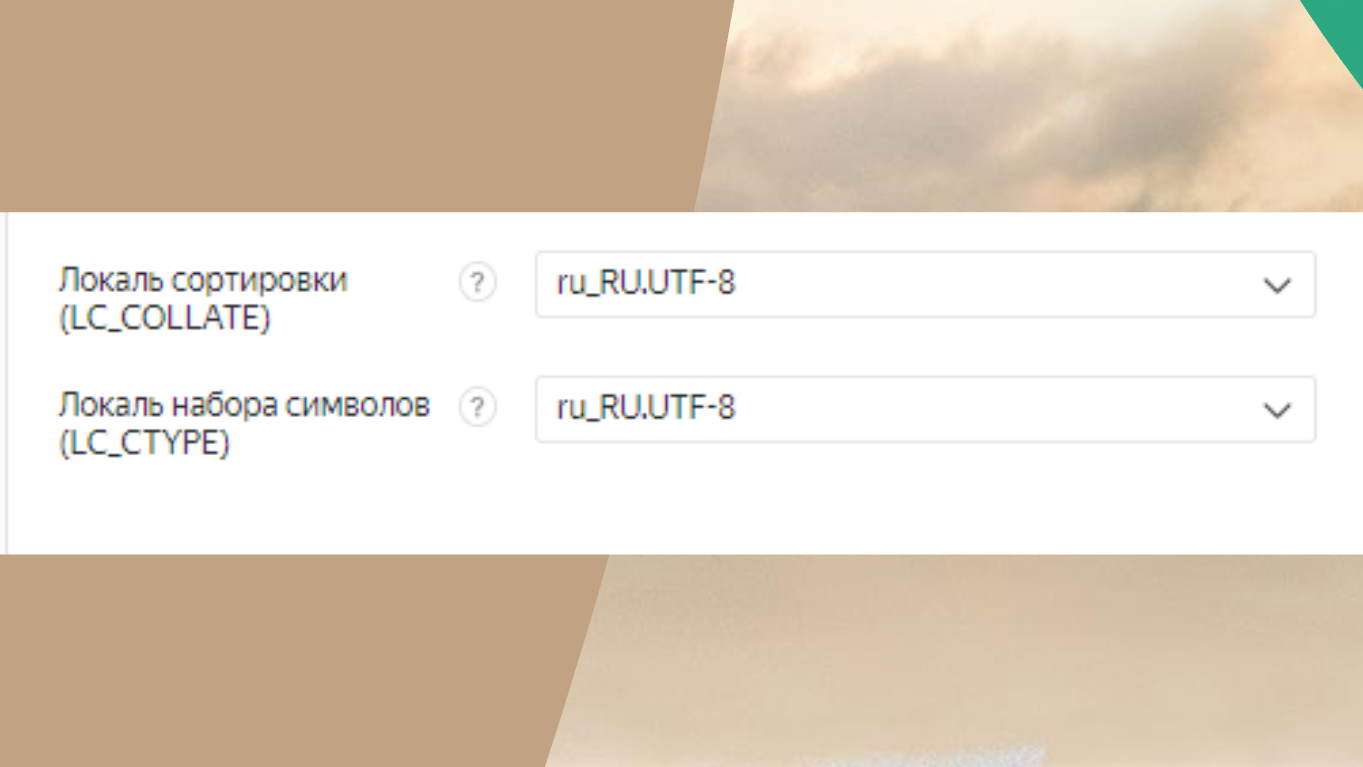
Про энкодинг – понятно, для инстанса нужно выбрать русскую локаль.
Вот это – плата за local ssd.
Все, наверное, видели статью про сгоревший ЦОД во Франции. ЦОДы тоже горят – даже крутые, даже Tier 3. Те, у кого был менеджмент сервис, выжили - данные сохранили. У кого были просто виртуалки - данные потеряли.
В реальном клауде, когда за сохранность ваших данных отвечает Яндекс, он вам должен обеспечить полную сохранность. Даже если на ЦОД упала атомная бомба (по состоянию на 2021-й год эта фраза означала “крайне маловероятный сценарий”), ваша инфраструктура должна выжить.
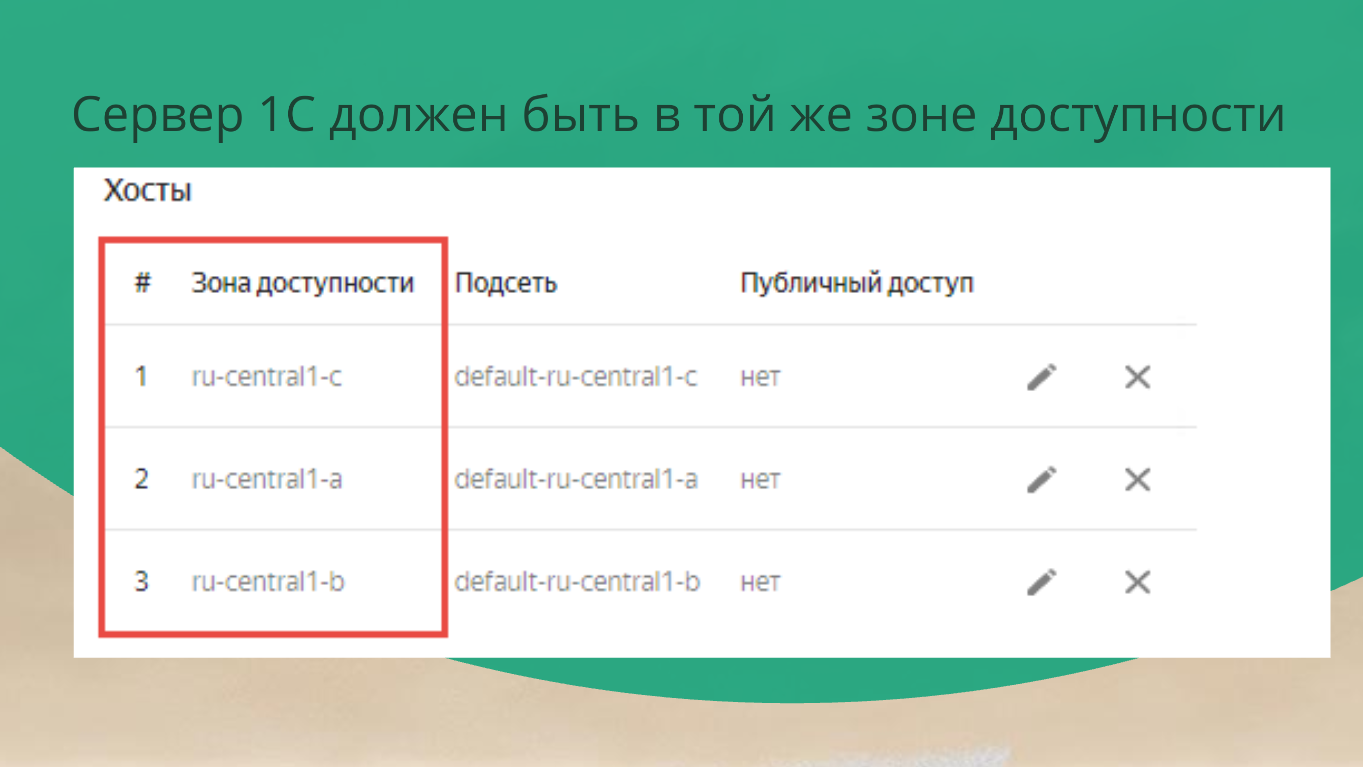
В этом кейсе они берут три зоны доступности, де-факто – это три ЦОДа в разных регионах РФ и в каждой зоне доступности создают по ноде. Между ними настраивают stream replication.
Здесь вы ничего не делаете – просто нажимаете кнопочку далее, и все.
Просто так отсюда ноду удалить вы не можете, потому что скажет: «Нет, у тебя local ssd, ты все данные потеряешь, я не могу тебе этого позволить. Я это решаю за тебя, и я создам три ноды». Соответственно, за эти три ноды нужно будет заплатить.
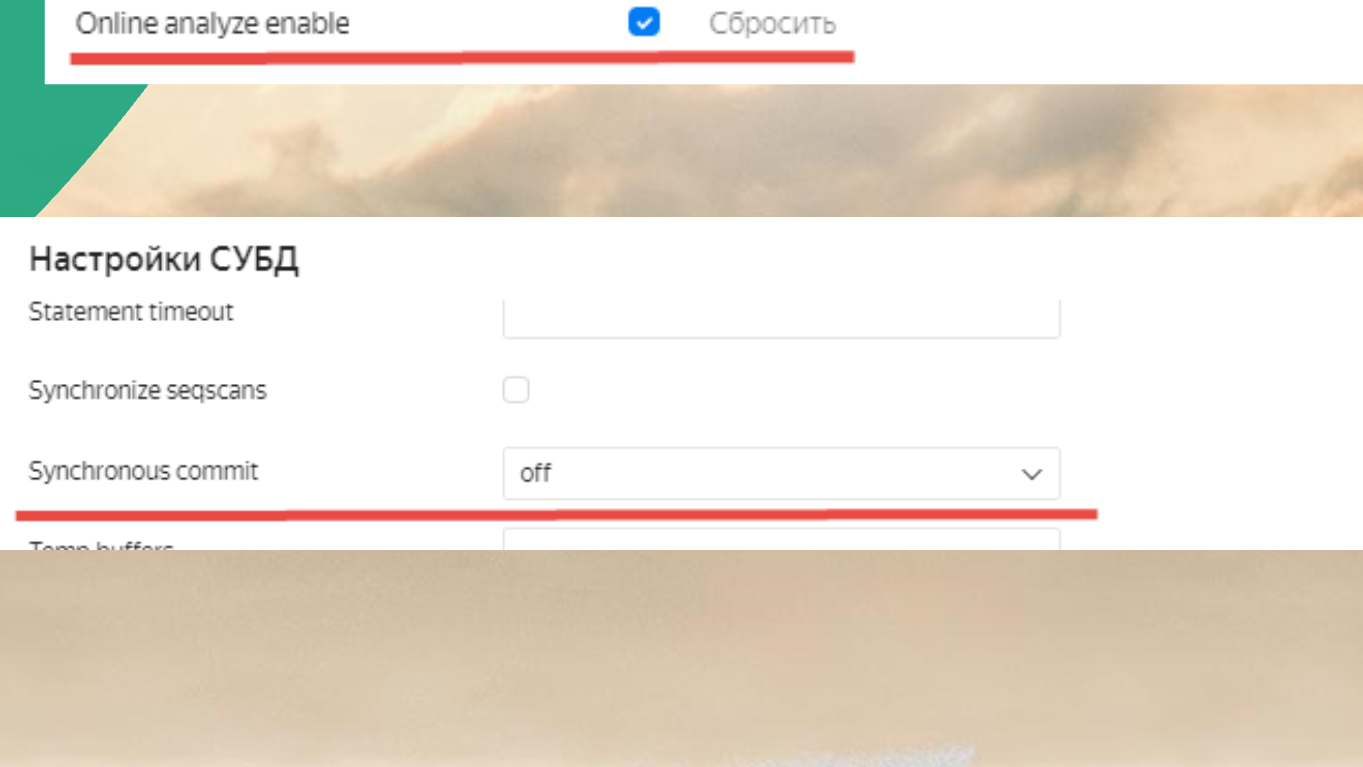
Поскольку между нодами настроен stream replication, обязательно нужна настройка Synchronous commit = off, иначе все будет тупить.
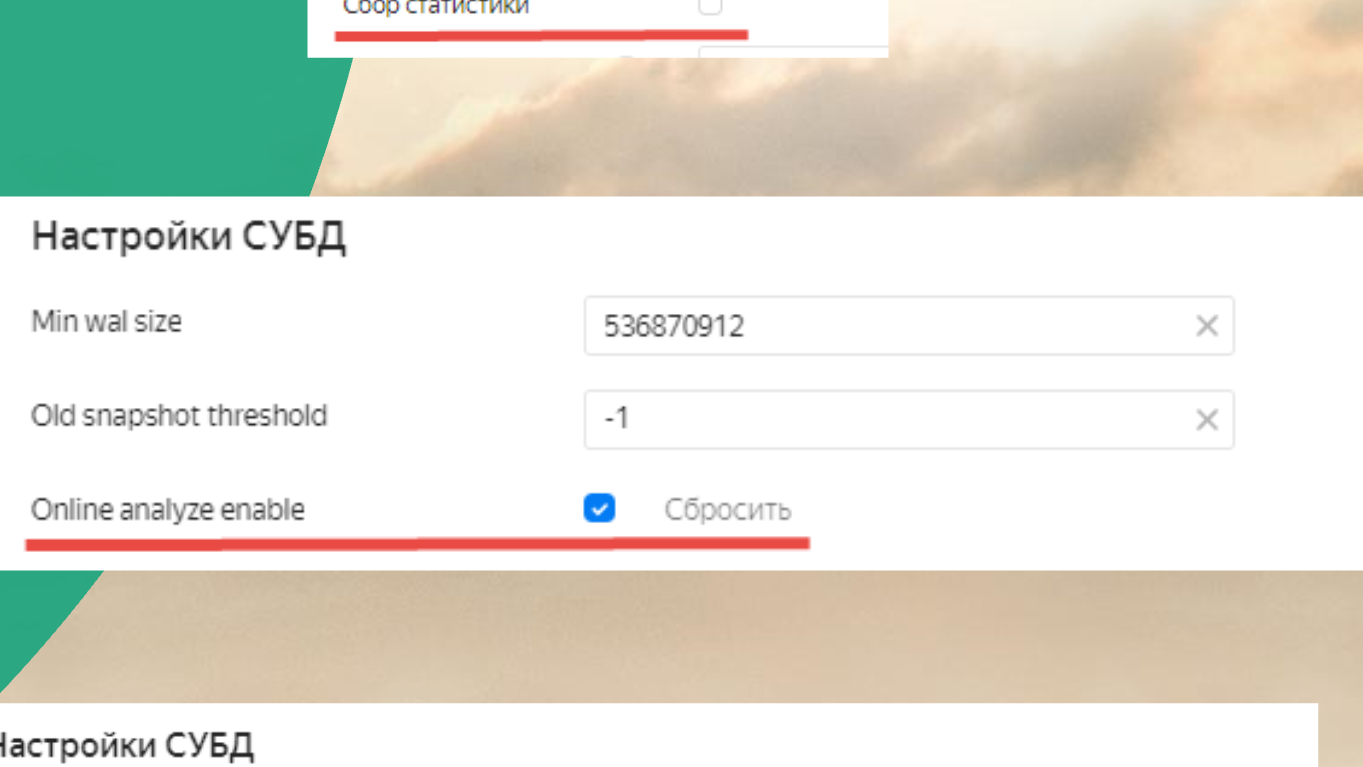
Еще нужно включить Online analyze enable, иначе тоже будет тупить.
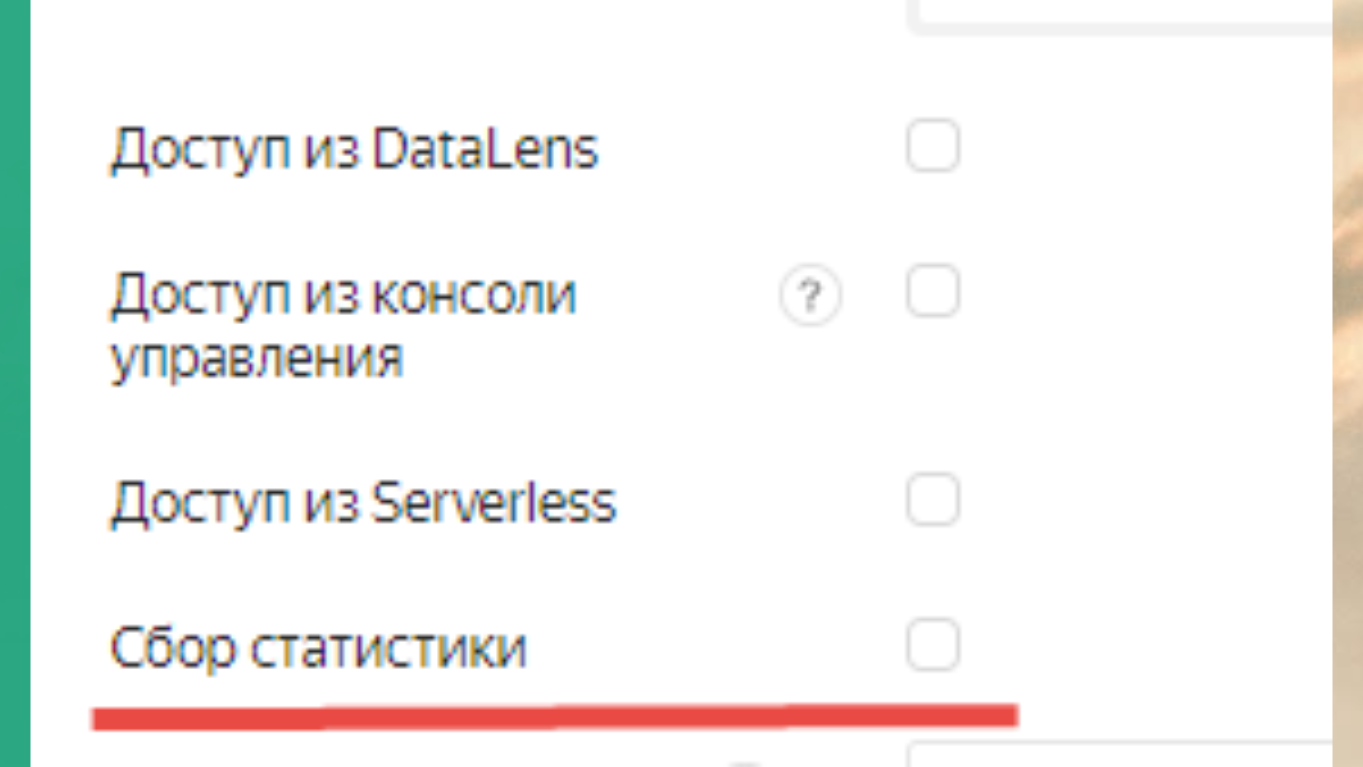
Еще надо отключить сбор статистики. По умолчанию Яндекс его включает, но с ним все работает плохо, поэтому его не надо включать.
Другие настройки, которые нужны для 1С вы все плюс-минус знаете, я про них детально рассказывать не буду.
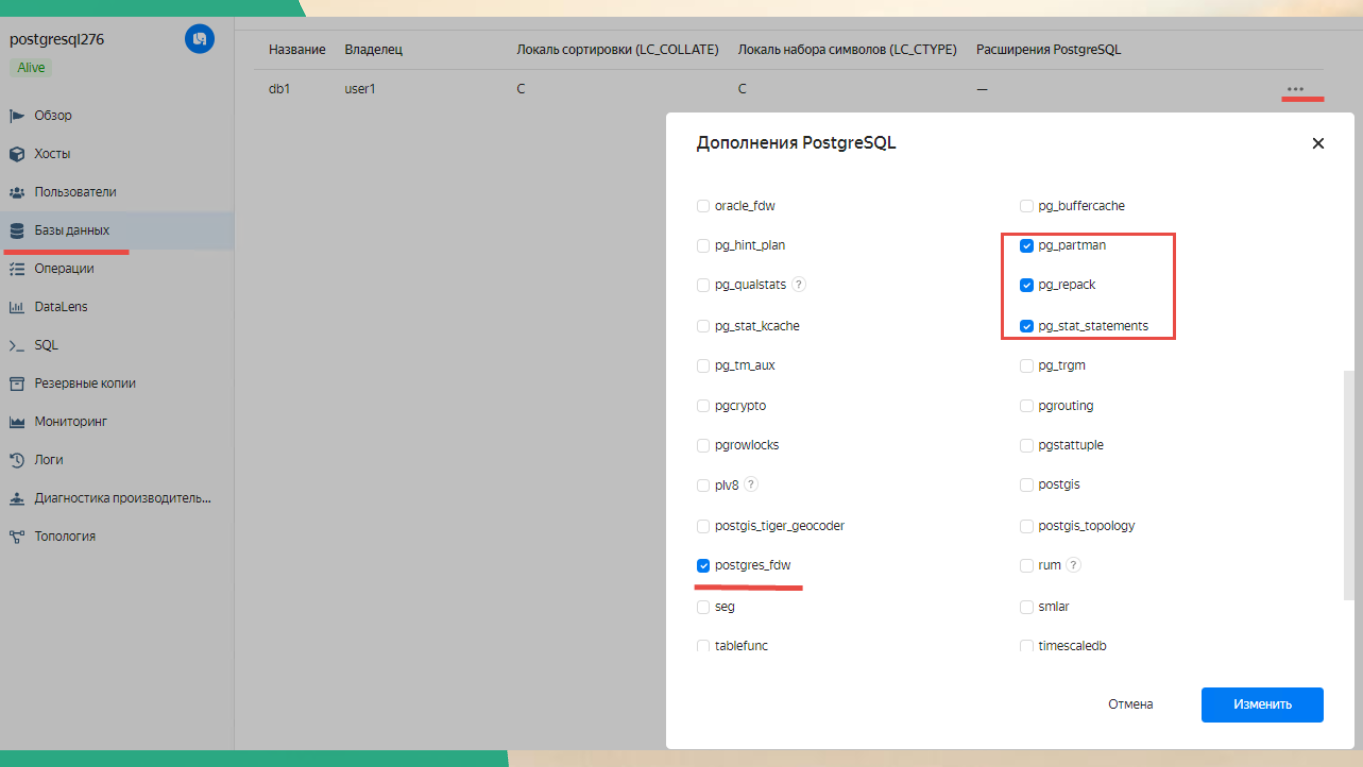
Я здесь еще показал, какие расширения для базы стоит установить. Но это расширения больше – для тех экспериментов, про которые я буду рассказывать дальше.
Это:
-
postgres_fdw – для FDW нам с вами нужно;
-
pg_stat_statements – для того, чтобы статистику запросов по таблицам получить.
В жизни вам тоже очень пригодится pg_repack, если у вас будет кончаться место, и вы захотите сделать VACUUM FULL.
Но VACUUM FULL в PostgreSQL не нужно делать, наверное, никогда. В большинстве случаев достаточно сделать обычный репак.

Если вы хотите посмотреть вживую, как это работает, регистрируйтесь в Yandex.Cloud, он при регистрации учетки вам там 4000 рублей сразу отсыпет на эксперименты.
Для совсем ленивых – репозиторий на гитхабе, в котором все это есть, чтобы вы могли хотя бы тестовый environment себе создать.
Здесь готовые скрипты в формате Windows *.cmd, Linux *.sh, и еще конфиги Terraform.
Лучше, конечно, попробовать последний.
Terraform нужен, если у вас есть инфраструктура в клауде. В любом – в Яндексе, в Амазоне, в публичном или приватном (в public клауде вы что-то юзаете, в private – что-то для себя создаете). Так вот, управляйте ей, пожалуйста, через какое-нибудь нормальное решение – Ansible или Terraform. Потому что да, скриптовать можно, но этому нужно хорошо научиться.
Terraform — это когда вы все, что у вас в инфраструктуре есть, описываете конфигами в файлике и закидываете их в GitHub (или в GitLab – в зависимости от того, что у вас корпоративно принято).
Потом просто пишете: terraform plan – он проверяет, есть ли у вас эти ресурсы, может ли он их выделить, не конфликтует ли что-нибудь.
Потом пишете: terraform apply – и у вас появилась та инфраструктура, которую вы описали.
Абсолютно прекрасная штука. У вас всегда есть конфиги, история и актуальное состояние вашей инфраструктуры.
Короче, пользуйтесь, привыкайте. Так надо. Рано или поздно вы все равно это будете делать.
Рост объема данных

Минутка практики закончилась. Немного грусти.
Если у нас растет объем данных в облачном PostgreSQL, мы будем вынуждены съехать с менеджера сервисов Yandex MDB на Computer Node.
Если PostgreSQL у вас management service, за вас делают все – за вас базу бэкапят, реплицируют, гарантируют доступность, настраивают память. Чтобы ее масштабировать, вы просто говорите, что вам нужно увеличить память/оперативку и так далее. И дальше все происходит для вас прозрачно.
Но если вы делаете виртуалочку, вас ждут все эти приключения с postgresql.conf. Кто не боится - тот не боится. Кому страшновато - тому это не понравится.
При этом нужно учитывать, что у Яндекса лимит на одну ноду 3 терабайта (данные на 2021-й год). Если вы в одну ноду уже не уложились, вам, скорее всего, придется заниматься этим самим. Если не самим, то, наверное, уже лучше бы к Postgres Pro обратиться – там и сжатие таблиц есть и бэкапы нормальные…
Короче, с прекрасного MDB, который я показал, придется съезжать.
Но, на самом деле, до 3 терабайт может уложиться достаточно большой спектр приложения. А во-вторых, я еще буду детально говорить, как эти вопросы можно решить по-другому – чуть более красиво.
Копии баз данных и Дата акселератор
С первичной настройкой в клауде вроде разобрались. Теперь давайте подумаем, как можно масштабировать чтение, особенно если мы в клауде.

Здесь приходит сразу на ум наша история с копиями баз данных и дата акселератором – то, что в платформе КОРП появилось не так давно (по состоянию на 2021 год).
Копии баз данных

Самое главное – не путайте копии баз данных с Дата акселератором - это разные вещи.
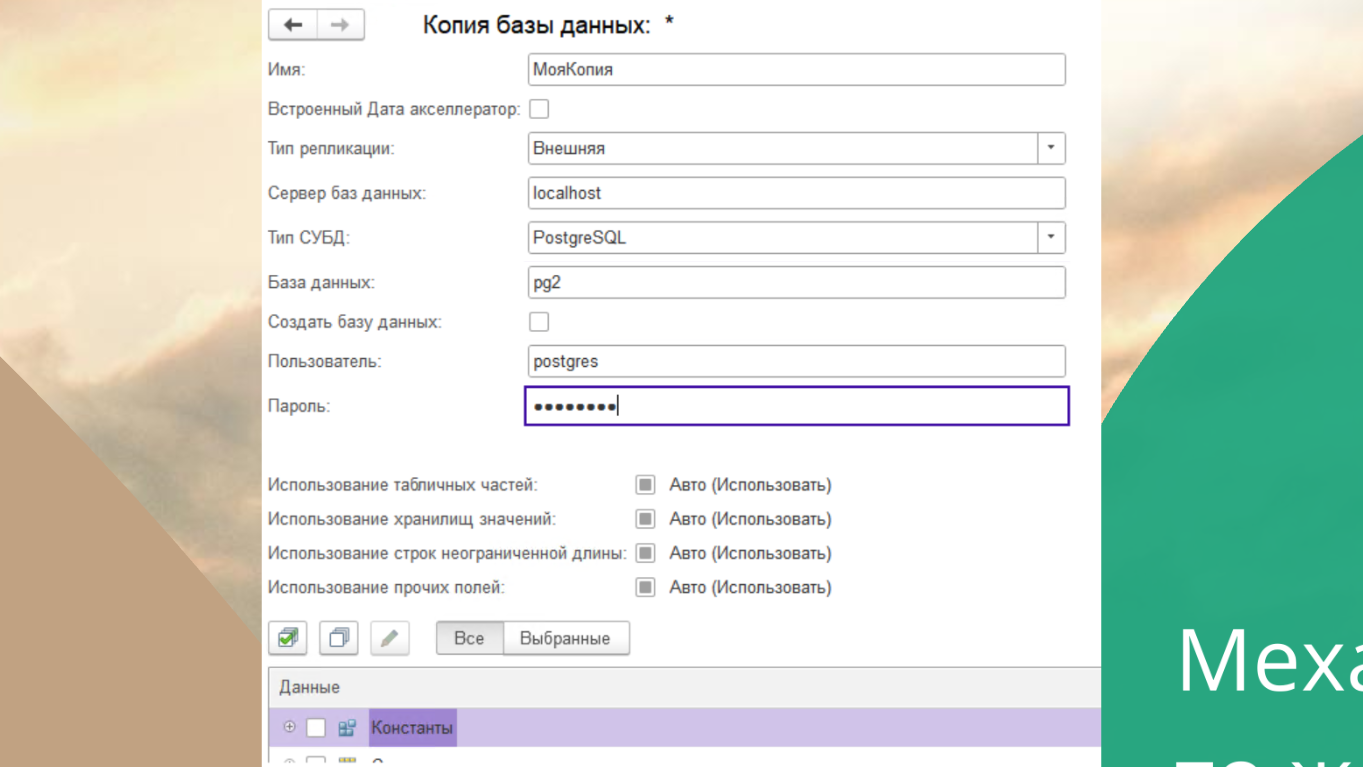
Вот так примерно выглядит настройка: там ничего страшного, просто указываете настройки для копии.
И вот здесь ключевая история – не рекомендую использовать тип репликации «Внутренняя», всегда используйте внешнюю репликацию.
Дело в том, что внутренний механизм копий баз данных реализует rmngr. Это – самый страшный в 1С процесс, на который надо молиться, не дышать, чтобы он, главное, rphost-ы запускал и тормозил вовремя. Управлял сеансовыми данными и делал это нормально. Пожалуйста, не надо трогать несчастный rmngr с какими-нибудь новыми экспериментальными фичами. Переливать данные из базы в базу умеет много разных утилит, но они все для нас не так критичны с точки зрения стабильности системы.
Если мы включаем внутренний механизм копий баз данных:
-
во-первых, появляются неожиданные странные поведения;
-
во-вторых, система может завалиться по абсолютно сторонним причинам.
Поэтому лучше ставить внешнюю репликацию – тогда у вас работает возможность выводить копию базы данных вовне.
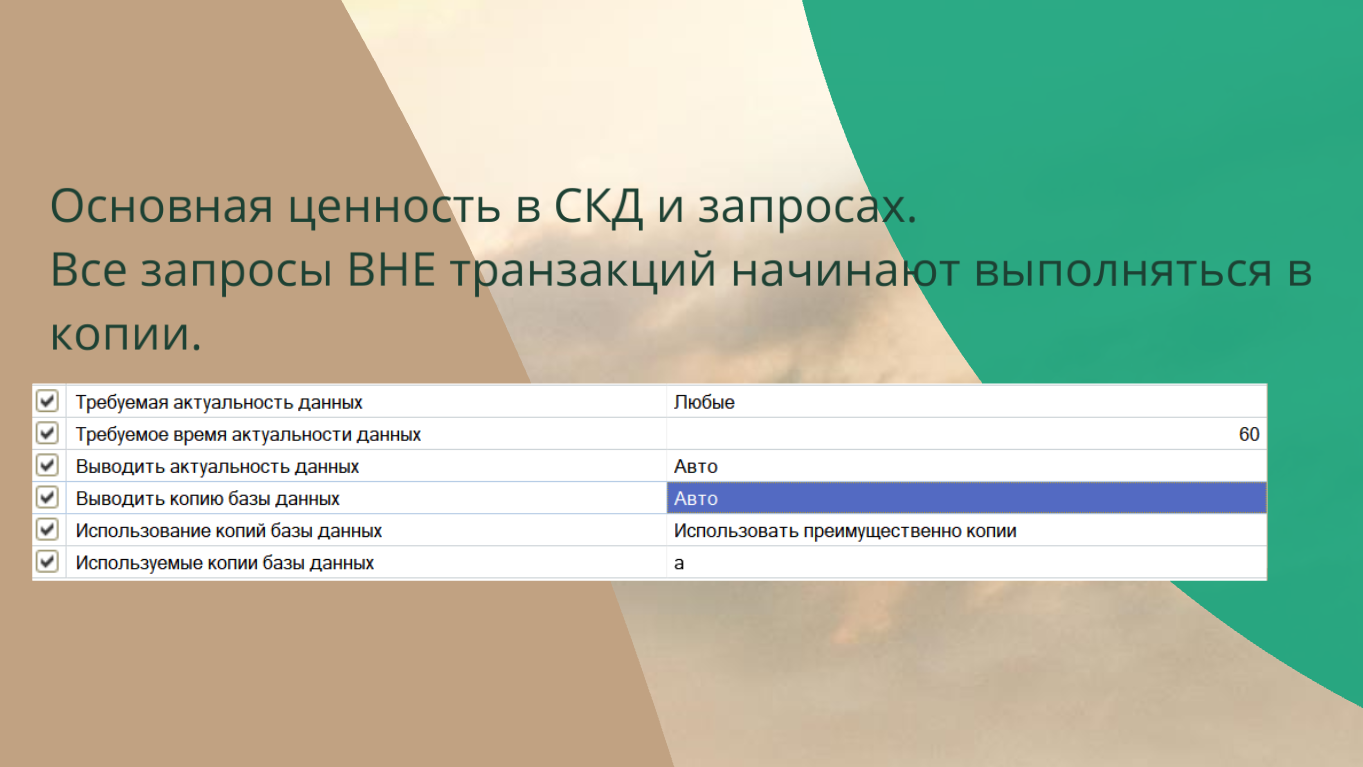
На самом деле ценность версии КОРП в том, что вы можете в любом месте вашей системы указать – бери данные из копии, не лезь в основную базу, не трогай ее! У нас транзакционная система с одним бедным несчастным сервером. На него надо “не дышать”.
Наверняка, вы тоже создавали для себя отдельную 1С-ную базу “для отчетов” (в своё время было модным трендом). Большинство из нас так делали – когда вас в одну базу пишем, из другой читаем. Потому что, не дай Бог, тут что-то крупное записали, у нас все встало.
Теперь вместо нее – механизм копий баз данных. Наконец-то мы можем это делать чуть более по-человечески.
Механизм копий БД – это универсальный инструмент, он вам позволяет создать базу для отчетов нормальными средствами репликации.
Но, как всегда, не все так просто.
Когда я это увидел, я подумал – наконец-то теперь мне пригодятся реплики, которые мне Яндекс создал через stream replication. И обломался.
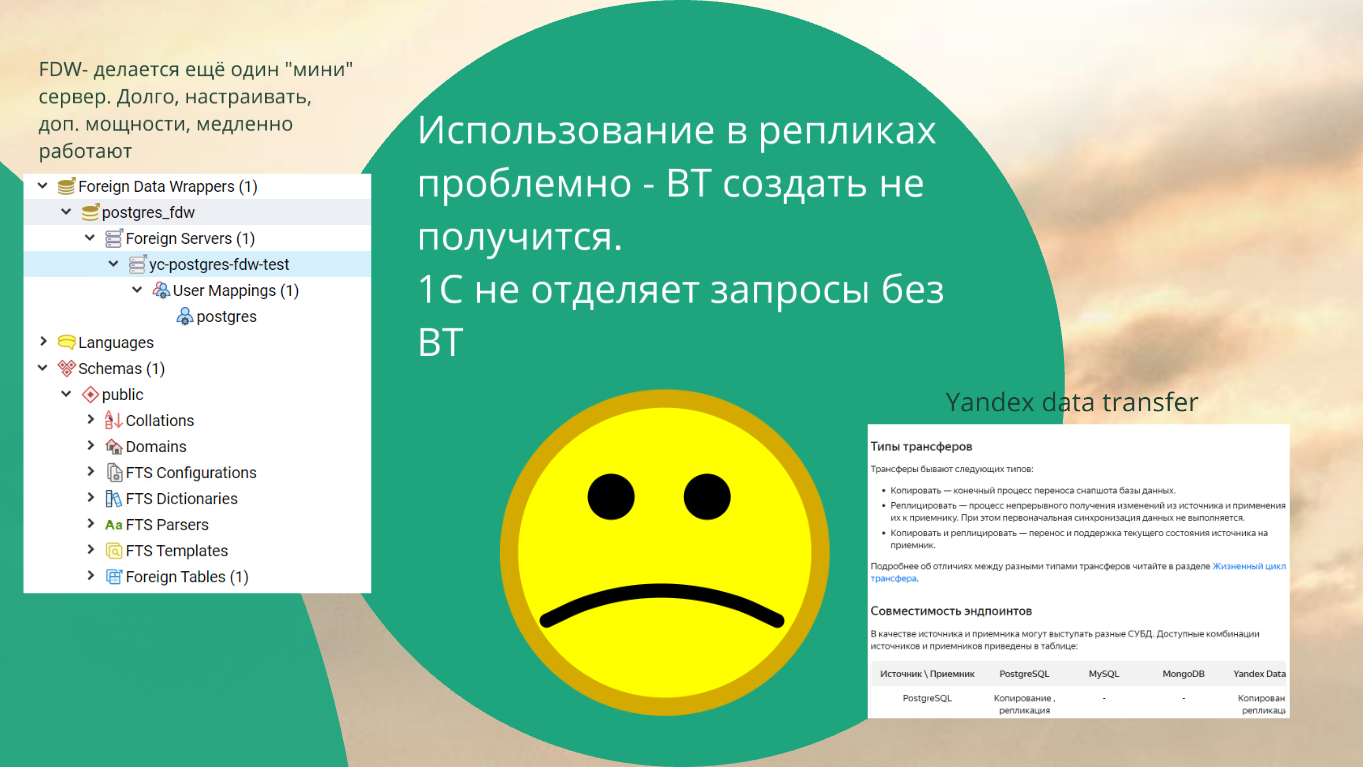
Оказалось, что использовать реплики Яндекса как копию баз данных я не могу, потому что 1С создает временные таблицы, а с точки зрения stream replication PostgreSQL реплика существует в режиме read-only, поэтому создать в ней объект нельзя. Поэтому использовать временные таблицы в реплике не получится.
Причем 1С очень топорно с этим работает – она просто в этом случае выкидывает ошибку: «Запрос не выполнен», не пытаясь переадресовать запрос к временной таблице туда, где её можно создать.

Это в принципе решается. Спасибо Антону Дорошкевичу, он помог найти решение.
Мы можем рядом с репликой поднять еще одну маленькую базочку, где смапить таблички через FDW.
С помощью FDW мы можем из другой базы подключить табличку к нашей базе так, чтобы она работала как родная.
Но там много нюансов – foreign table, соединение с обычными таблицами, соединение двух foreign table, опять же overhead самого FDW.
Все это приводит к тому, что запросы через FDW начинают тормозить. Иногда необоснованно, иногда очень трудно разобраться с их планами запроса – понять почему это стало тупить. Поэтому мы от этой истории отказались.

Мы пришли в итоге вот в эту историю. У Яндекса есть прикольный сервис, называется Yandex Data Transfer. Это – некая логическая репликация, которую Яндекс сделал между разными базами (кажется некоторые навороты вокруг debezium CDC).
Через эту репликацию можно сделать копию:
-
из вашей локальной PostgreSQL в облачную PostgreSQL;
-
из облачной PostgreSQL в локальную PostgreSQL;
-
из PostgreSQL в MySQL;
-
из MySQL в PostgreSQL.
В документации есть целая табличка – что куда можно реплицировать. Работает это в принципе стабильно, т.к. похоже просто интерфейс к хорошо обкатаным и популярным средствам.
Самое главное, что это не трогает 1С - мы на нее “не дышим”..
Вот так копию создаете, в 1С указываете «Тип репликации: Внешняя», и у вас появляется замечательная база для отчетов.
Теперь, конечно, хардкор – Дата акселератор. Это – штука, которую нам 1С рекомендовала как in-memory СУБД.
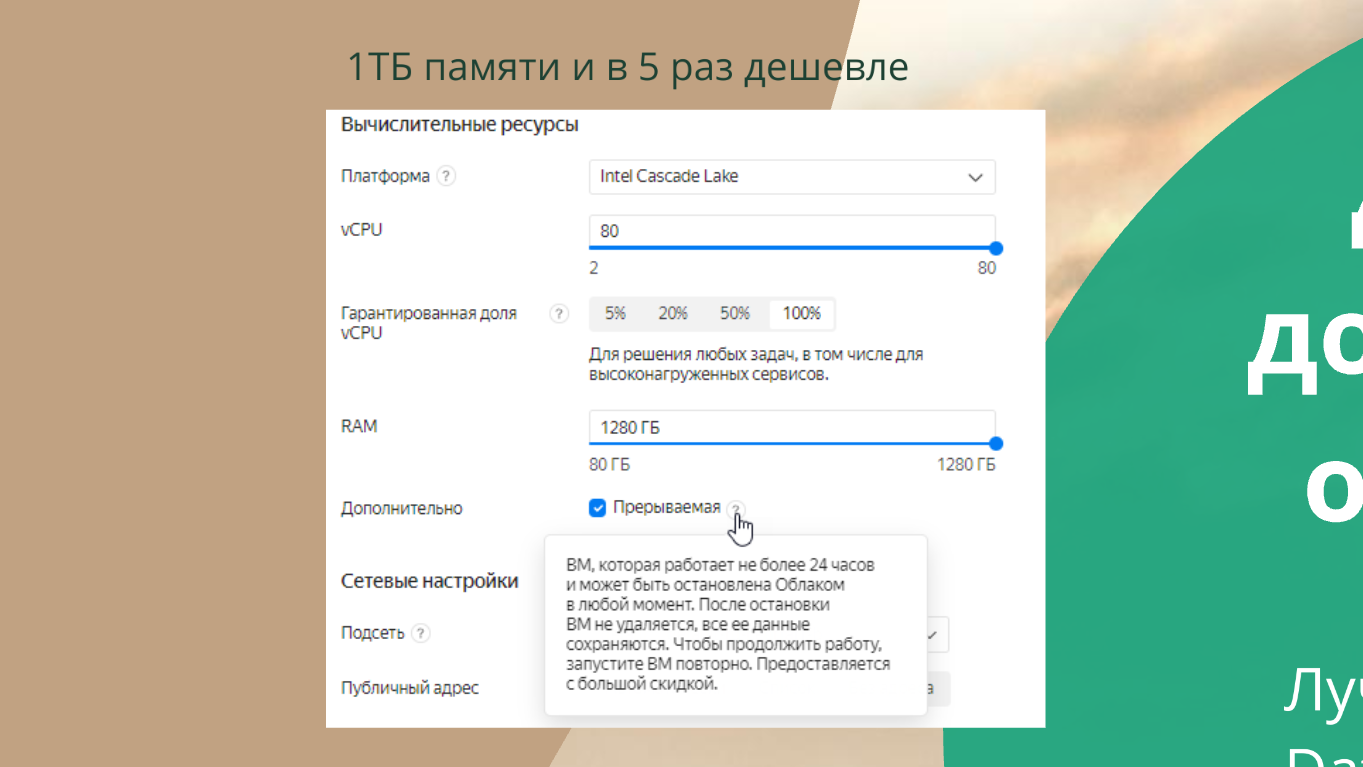
В облаке разворачивать Дата акселератор немного проще: не нужно покупать сервер с терабайтом оперативки – его можно взять в аренду в облаке.
Если вы хотите попробовать Дата акселератор в облаке и сэкономить в пять раз, поставьте галочку «Прерываемая». Так у вас получится прерываемая машинка, которая через 24 часа может быть выключена, но при этом она не потеряет своих данных и настроек. За то, что Яндекс ее может иногда выключать, он делает ее в 5-10 раз дешевле.
Это некие дешевые мощности для экспериментов – обычно такие штуки любят дата-саентисты. Но это прикольно подходит и для Дата акселератора.
И терабайт оперативы тут тоже выделить можно. Но, конечно, это все очень недешевое удовольствие в итоге получается.
Сразу скажу, что у такого размещения Дата акселератора много ограничений, много глюков. Может быть, я не умею его готовить, но если вы уже в клауде, проще использовать Data Platform от Яндекса.
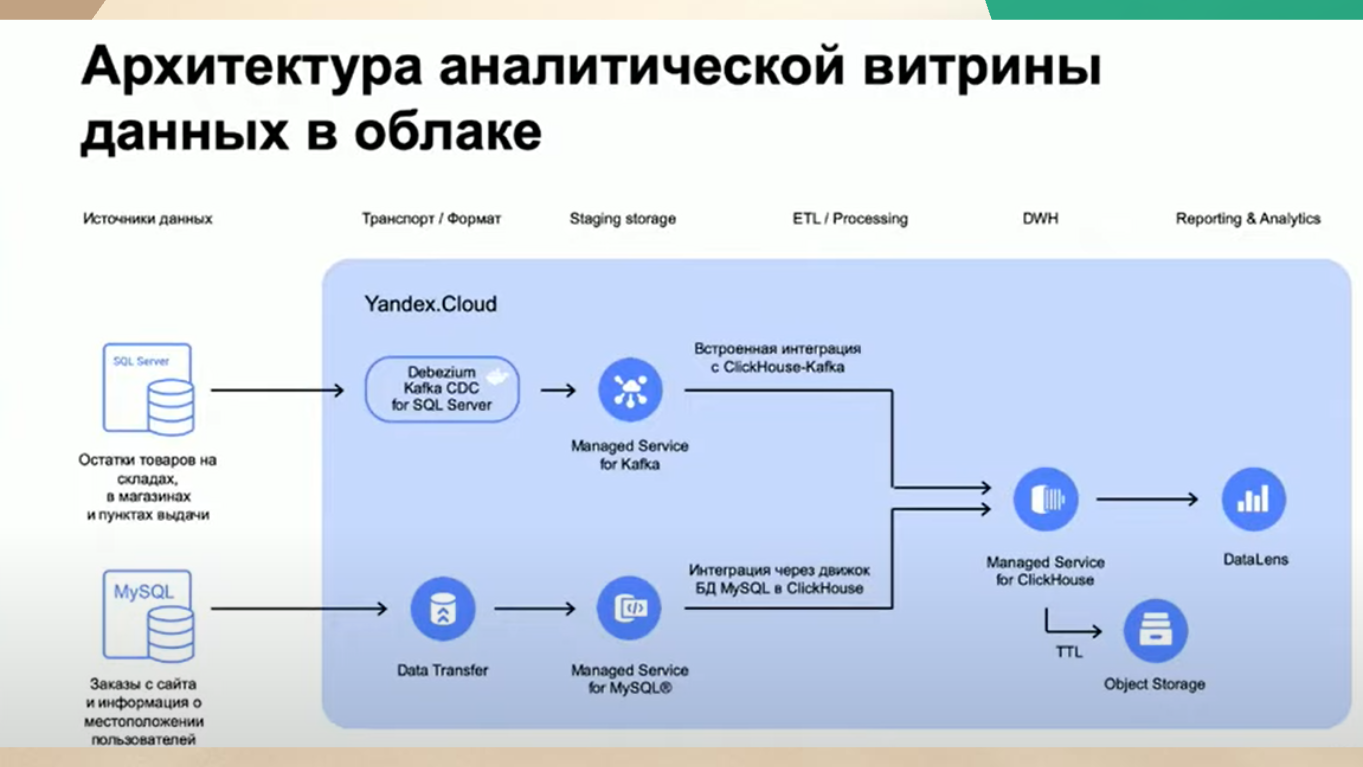
Витрину данных нам предлагают строить так:
-
Слева, где SQL Server – 1С с OData.
-
От него данные передаются через Managed Service for Kafka
-
В два клика настраивается интеграция напрямую с ClickHouse, который выполняет роль витрины.
Классическая задачка с первого занятия школы дата инженеров: Data Source – стриминг – витрина.
Этот урок, к сожалению, придется пройти даже 1С-никам:
-
В качестве Data Source у вас 1С.
-
В качестве стриминга – Kafka.
-
Витрина – это ClickHouse.
-
При этом ClickHouse еще может и в Object Storage свои старые данные хранить.
ClickHouse в Яндексе очень хорошо дружит с DataLens – в нем вы можете рисовать дашборды. Вы можете посадить какую-нибудь девочку, которая закончила курсы аналитиков на Skillbox за пару месяцев. И она вам кучу красивых дашбордов нарисует. У вас там бизнес будет просто плакать: «Вау, как круто».
Эти же самые таблички вы можете использовать под Дата акселератор – для этого вам не нужно их адаптировать:
-
Возьмете здесь Data Transfer.
-
Поставите Data Transfer в Kafka.
-
И сделаете из ClickHouse консьюмер для Kafka.
Это работает.
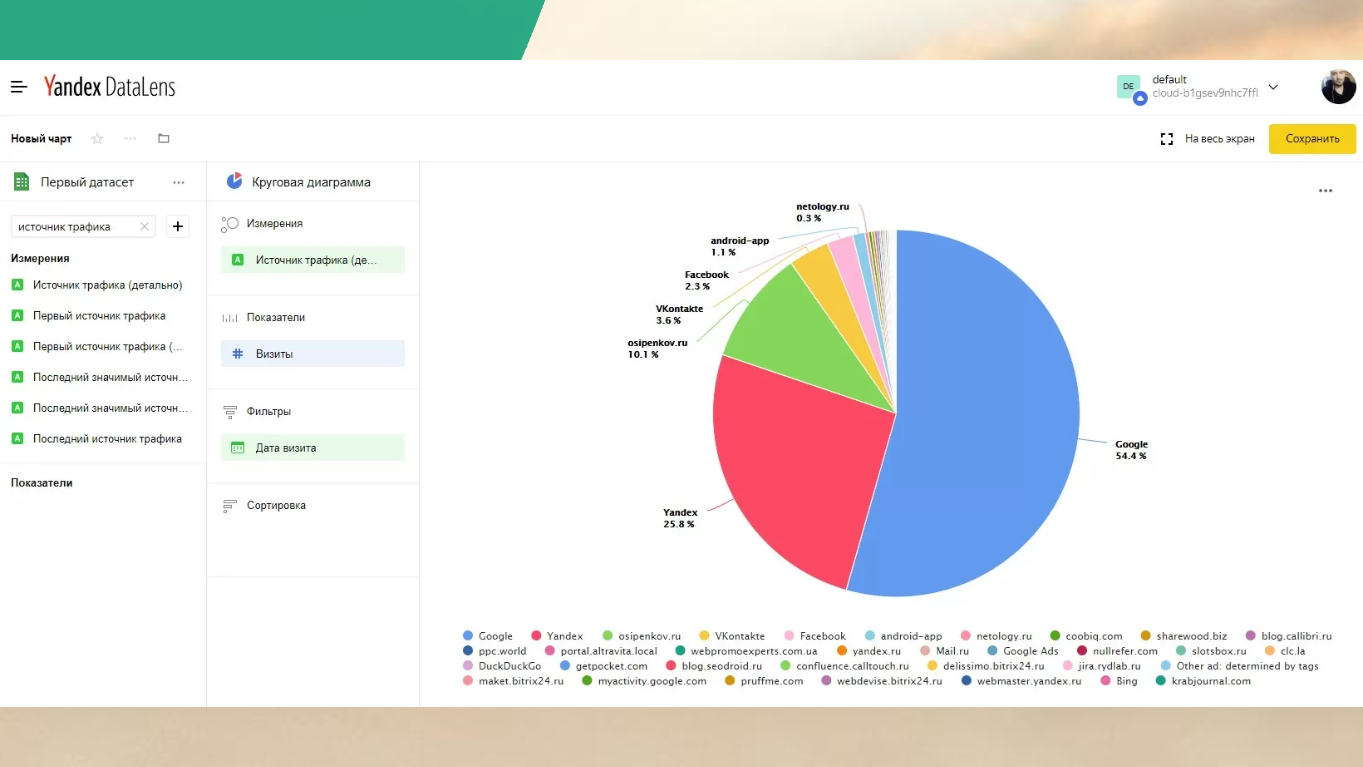
Вот так выглядит в итоге DataLens – по мне так это очень красиво, понятно и приятно.
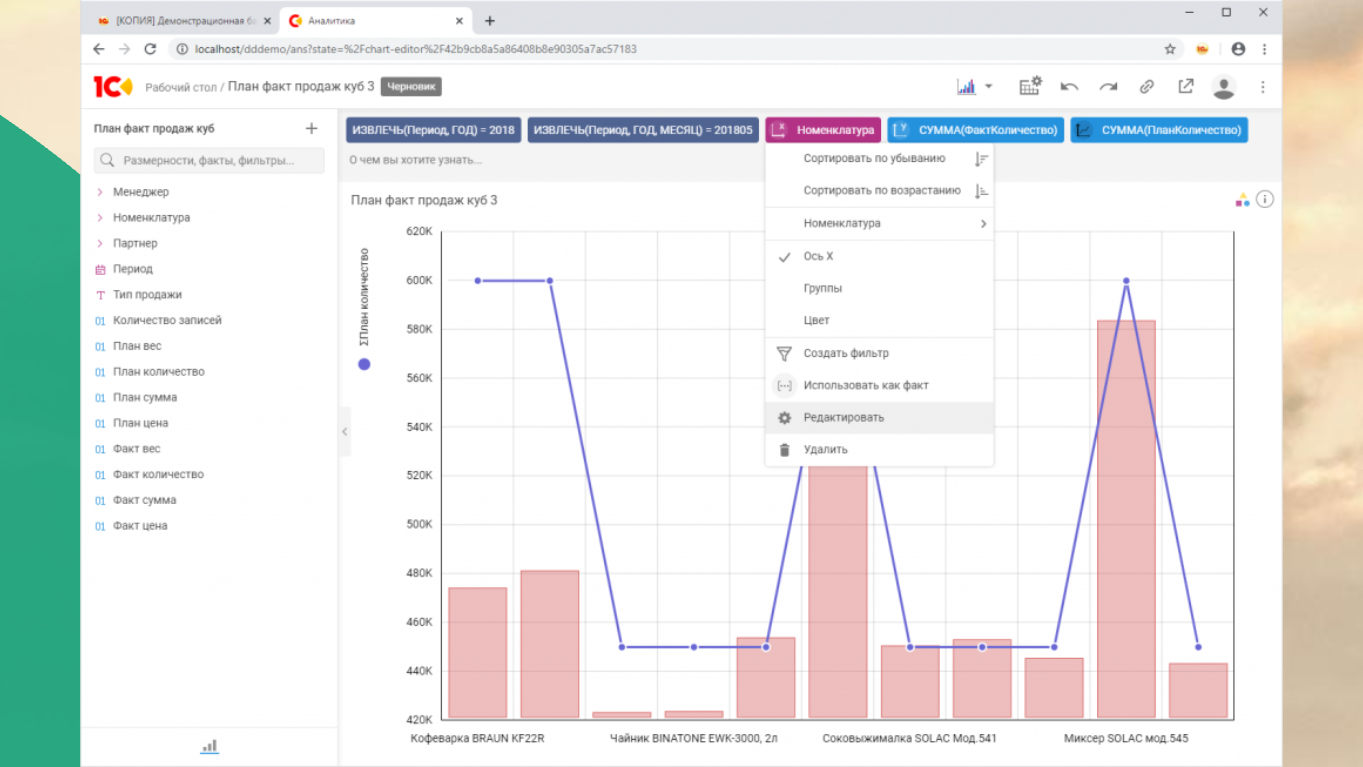
Вот так, для сравнения с DataLens, выглядит 1С:Аналитика. Дело вкуса. Я не силен в дизайне, просто показал две картинки.
Шардинг и партиционирование

Дальше чуть хардкорнее. Чтение мы уже масштабировали – по крайней мере, разобрались как. Теперь масштабируем запись. Здесь сложнее.
Партиционирование. Про него вкратце расскажу.
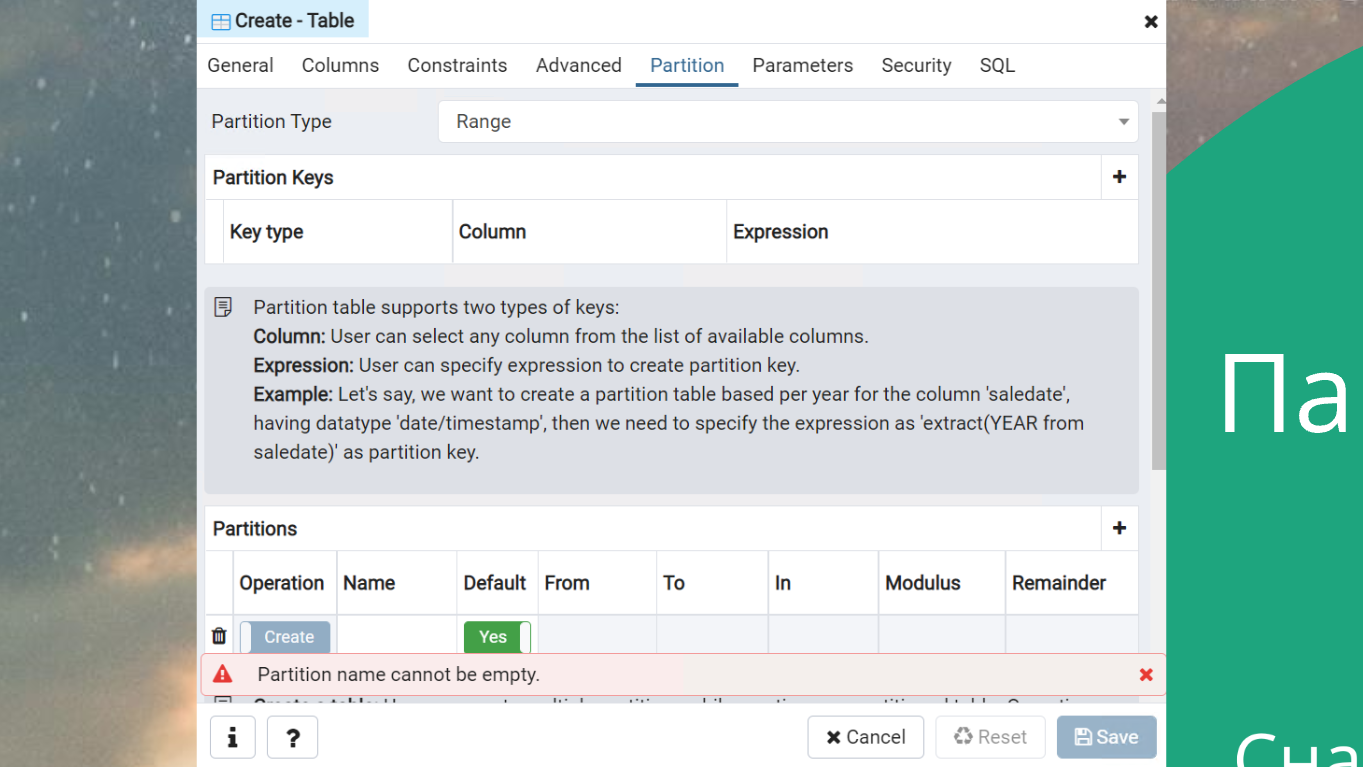
Вы можете сразу в pgAdmin создать табличку с Partitions. Просто поиграйтесь – это полезно. Партиционировать нужно. Партиционировать очень хорошо.
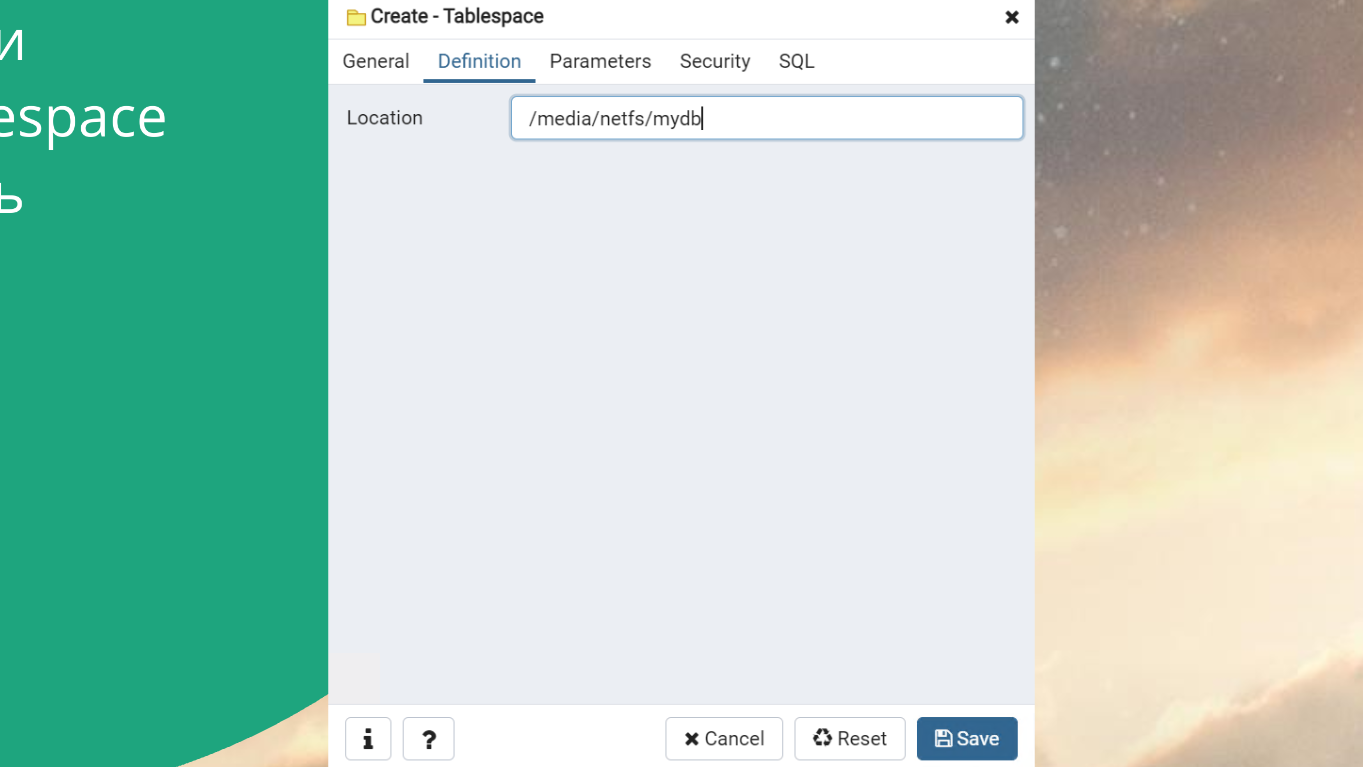
Если хотите работать с большой базой, обязательно научитесь делать Tablespace.
Подключаете сетевой диск и выкидываете туда все страшные таблицы:
-
истории версии объектов;
-
электронные письма;
-
файлы;
-
справочники какие-то страшные.
Все это не нужно хранить в нормальной обычной базе – это можно хранить на более дешевых носителях.
В клауде у вас всегда есть выбор вариантов для storage:
-
local-ssd;
-
network-ssd;
-
network-hdd.
Делите ваши таблички в базе по степени сервиса – это нормальная история. С Tablespace нужно научиться работать.
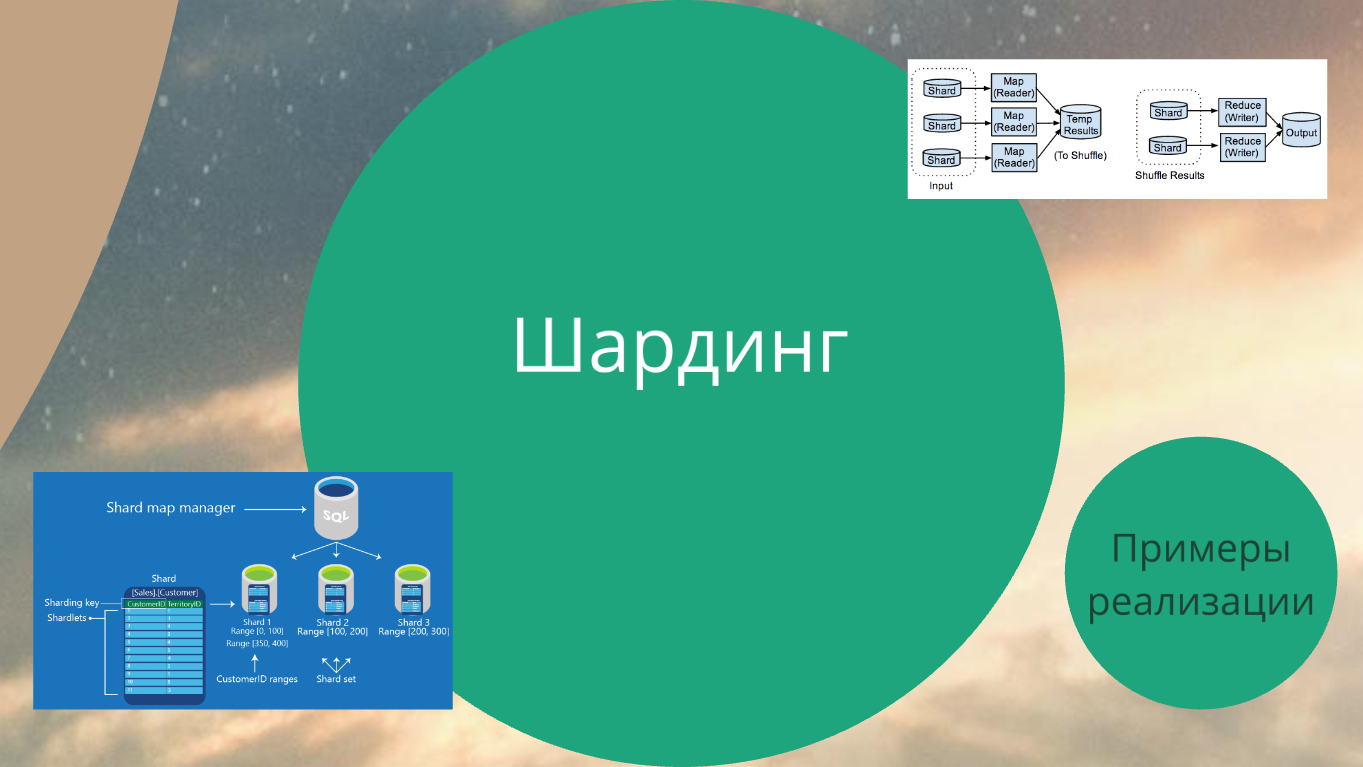
Шардинг. Это уже интересней.
Вкратце надо объяснить, что такое шардинг.
Слышали про Map-Reduce?
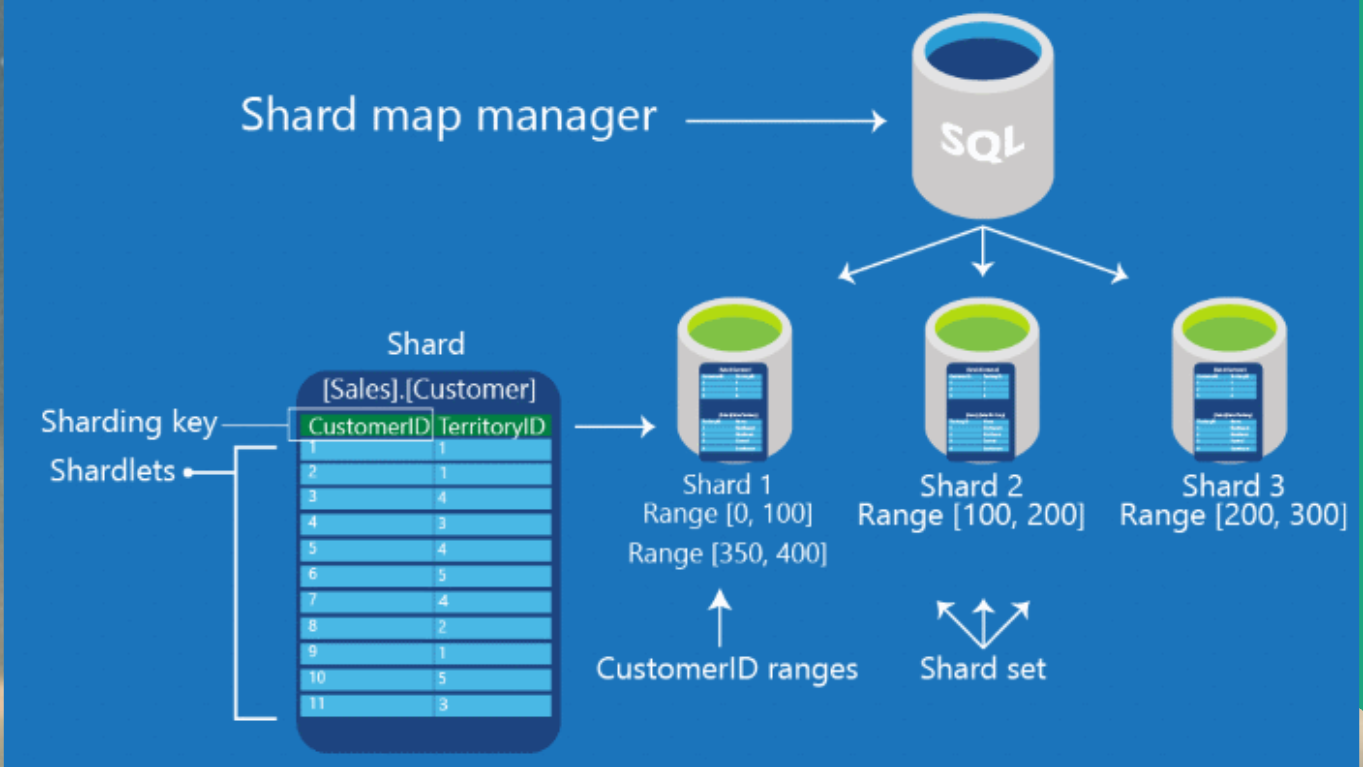
Это когда у вас очень большая табличка, где есть поле TerritoryID (допустим, это ваш регион). И запросы на какую-то информацию у вас чаще всего формируются в контексте регионов.
И только конкретные запросы могут отсылать информацию по всем регионам – например, когда нужно посчитать среднюю или суммарную зарплату по всем регионам. Но это будет редко.
Так вот функция Map организует хранение данных в разрезе конкретных полей:
-
Если табличка регион такой-то, иди вот на тот сервер.
-
А если регион такой-то, вот на тот сервер.
Reduce делается ровно обратно – когда нам нужно собрать данные по всем табличкам на всех серверах, собираем запросы и отдаем все в сумме.
Map-Reduce это основа любого хайлоада – где-то он работает «из коробки», но в RDBMS его организовать все еще достаточно трудно.
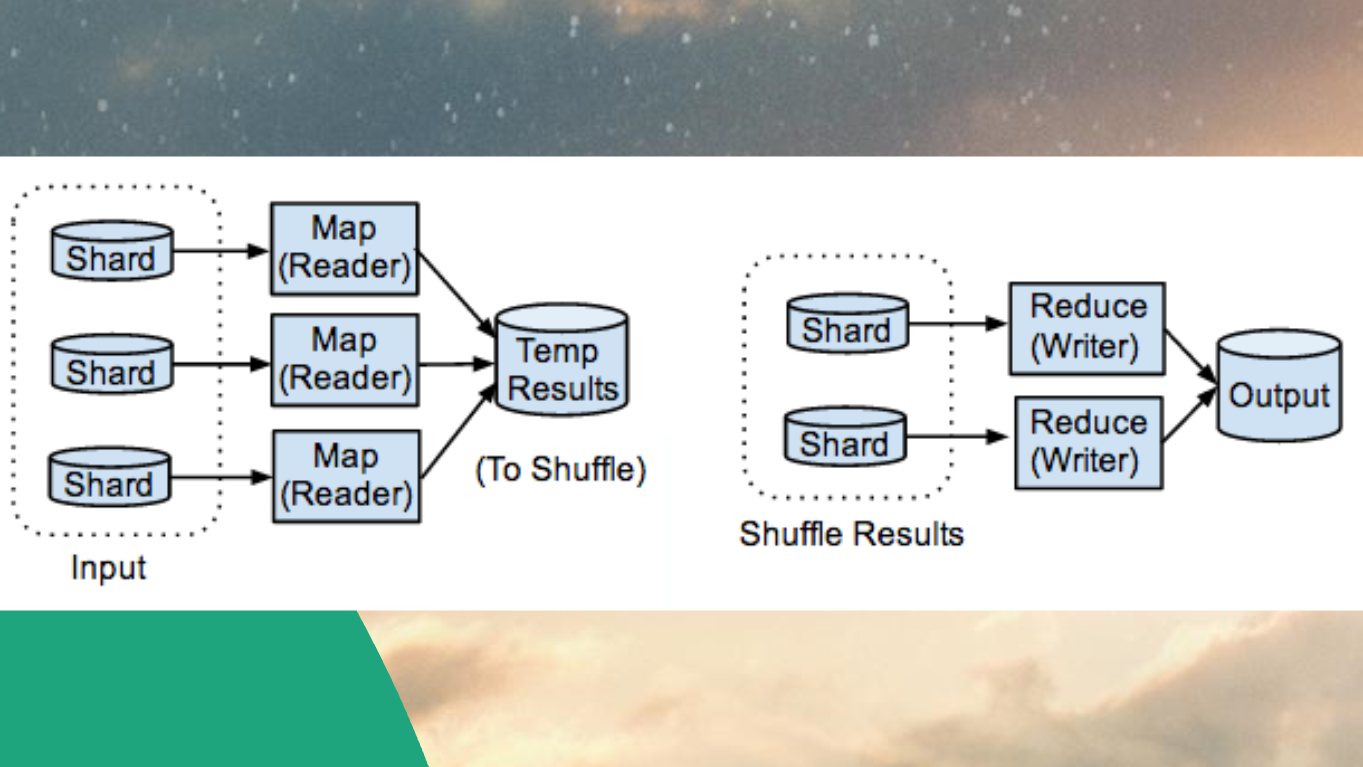
Шарды – это кусочки вашей базы данных, которые, на самом деле (в случае с RDBMS), являются отдельными базами данных. Мы просто имитируем Map-Reduce.

Чтобы имитировать Map-Reduce на PostgreSQL, почитайте мануал от GitLab. Или посмотрите скрипт https://github.com/swarm64/fdw-cluster-example.
Там нет космоса. У вас, грубо говоря, просто создается обычное партиционирование таблички. Вы создаете партицию и говорите – это партиция на этом сервере. Вот эта – на этом, а эта – на другом.
В итоге вы получаете неограниченное масштабирование одной таблицы – то, что доктор прописал.
Cloud native

Вернемся поближе к нашей жизни.
Cloud Native Computing Foundation. Если вы хотите понять, что происходит в облаках, вам нужно читать https://www.cncf.io/.
Весь клауд – он там. Это очень крупные компании, которые собрались вместе и сказали – мы теперь Cloud Native Computing Foundation.
То, что есть там, заонбордится у вас практически в любом облаке. Прикольный сайт, почитайте, посмотрите.

Пару слов о логической репликации. В PostgreSQL с какой-то версии поддерживается уже не stream replication, которую почему-то имплементировал Яндекс, а нормальная, адекватная логическая репликация.
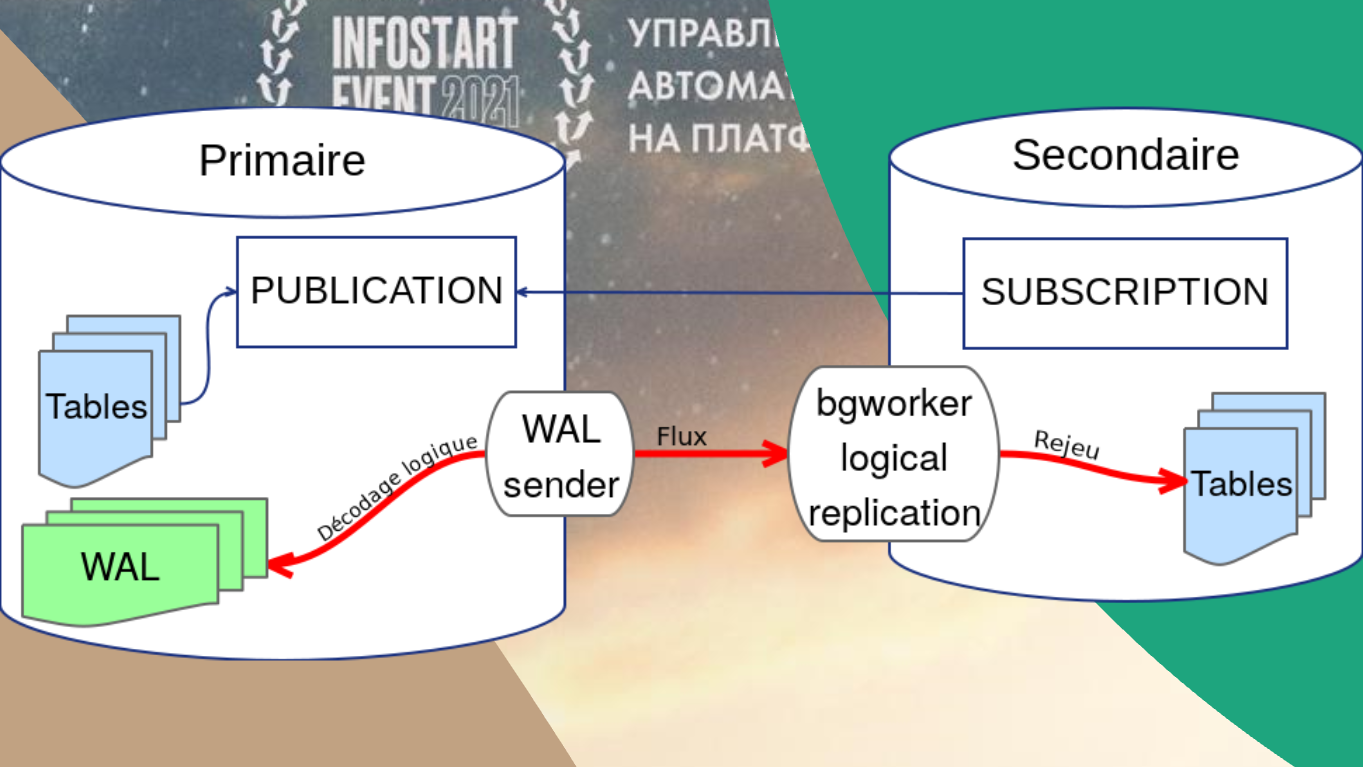
При логической репликации временные таблицы в базе будут создаваться. Более того, вы можете там еще и что-то записать.
То есть логическая репликация позволяет вам полноценно использовать копии баз данных.
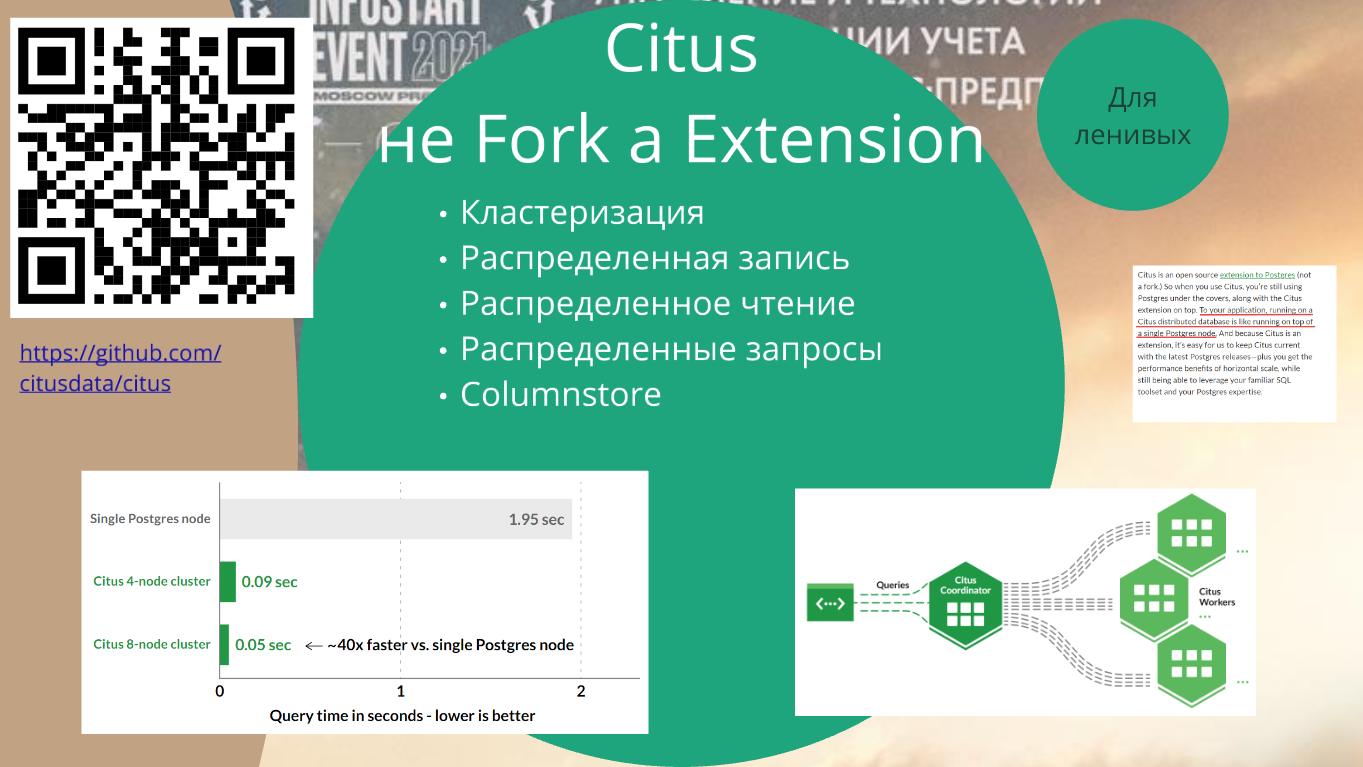
Citus. Гвоздь программы. Давайте я просто зачитаю эти волшебные слова:
-
Кластеризация,
-
Распределенная запись,
-
Распределенное чтение,
-
Распределенные запросы. Кстати говоря, распределенные запросы – это не то же самое, что распределенное чтение, это MapReduce.
-
И еще и Columnstore добавили.
Ознакомьтесь лучше с этой штукой по детальнее – вся информация опубликована по ссылке https://github.com/citusdata/citus.
Это – PostgreSQL, который позволяет масштабироваться. Если эта штука сможет работать с 1С, это решит все проблемы, которые мы обсуждаем на Highload-секции.
Если вы использовали в продакшн ElasticSearch, MongoDB, вы знаете, что там, чтобы масштабироваться, достаточно добавить шард, распределить по ним коллекцию и кинуть ключи. Горизонтальное масштабирование – наше все.
Citus умеет так же скейлить PostgreSQL. По крайней мере, по их словам. А их слова, конечно, впечатляют.
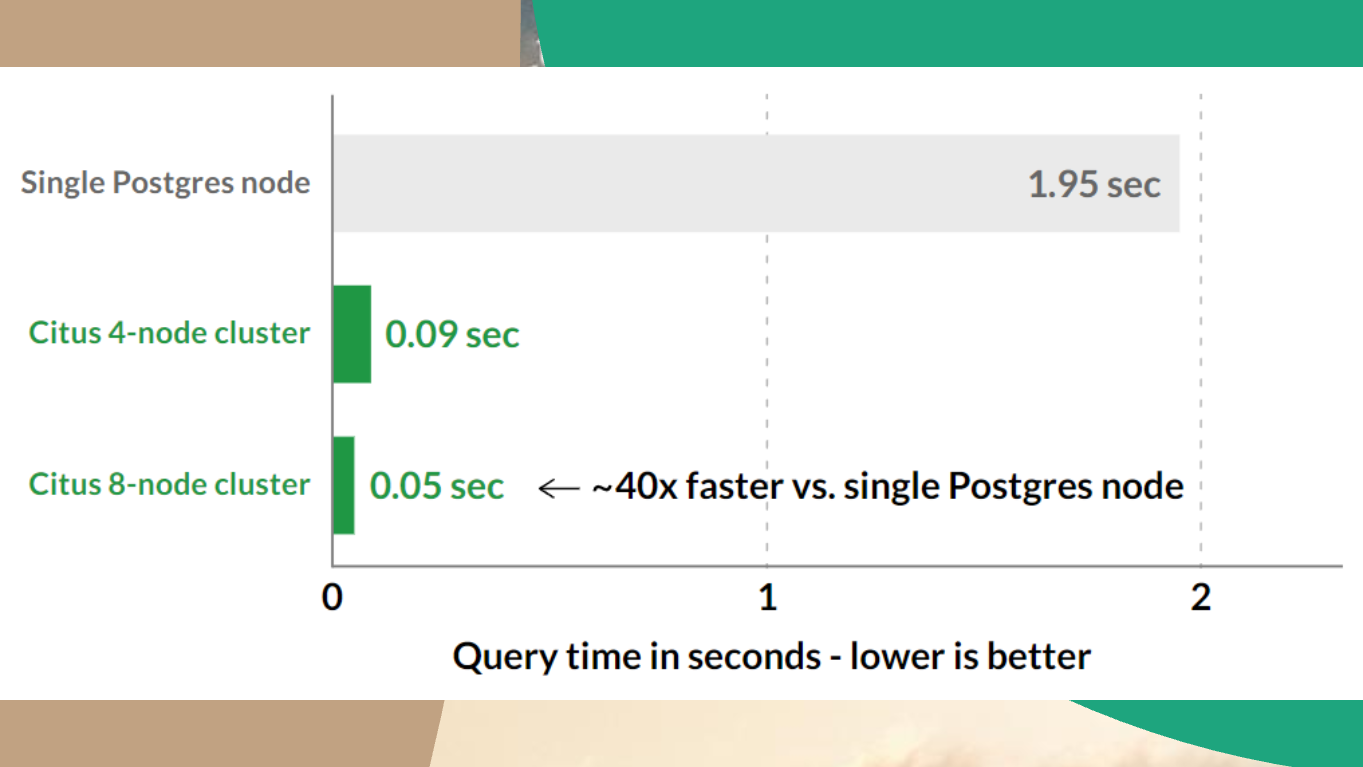
Кластер из 8 нод работает в 40 раз быстрее, оно само распараллелит запросы.
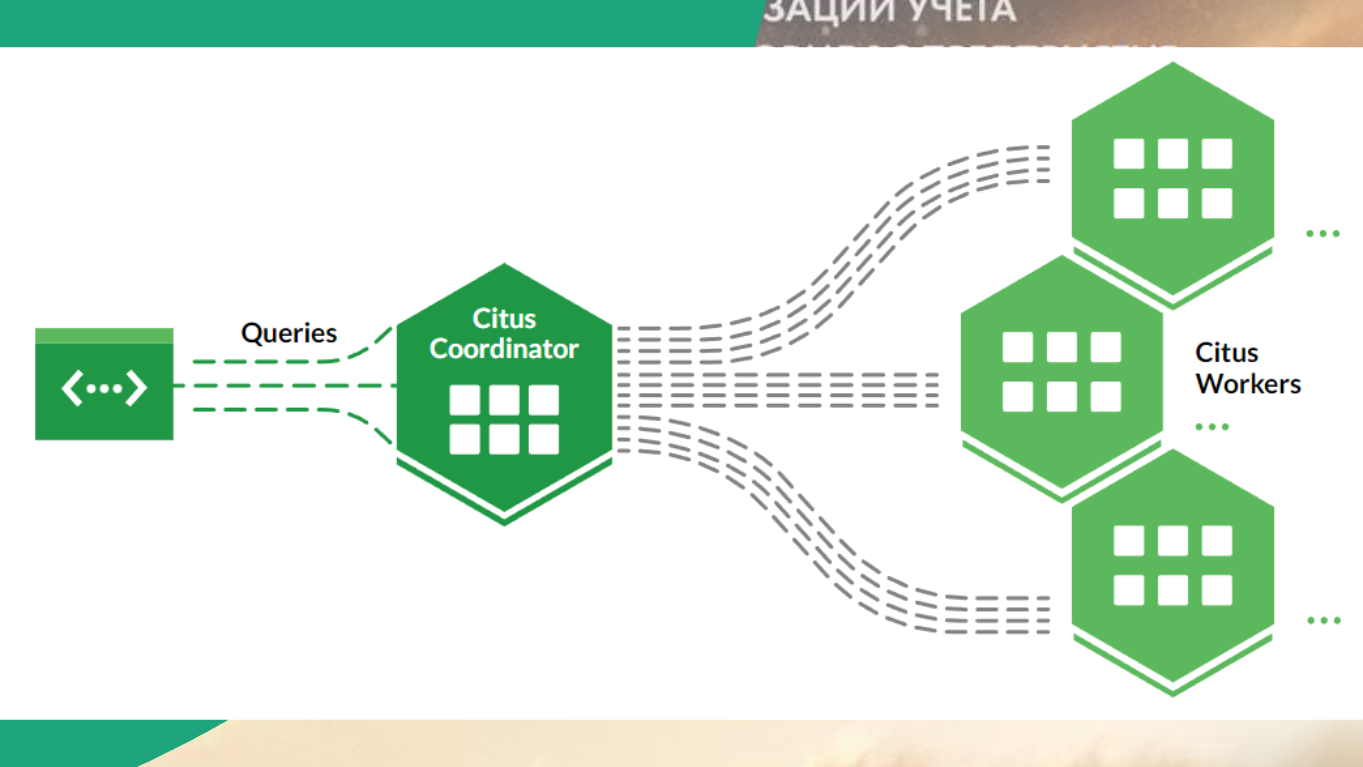
Все это реализует специальный координатор.

Самая фантастика – вот здесь. У тех, кого с английским не очень, переведу.
Это не форк PostgreSQL, это extension. Что значит? Это значит, что мы берем абстрактный PostgreSQL, любой, который нам нравится, добавляем туда несколько файликов, и у нас теперь не PostgreSQL, а Citus.
В чем проблема PostgreSQL, который использует 1С? В том, что он патченый, он не настоящий PostgreSQL.
Но по словам инженеров Citus, их расширение будет работать с любым PostgreSQL.
Более того, итоговое приложение не знает, что оно работает с Citus. Это – то, что нам для 1С важно. Оно думает, что оно работает просто с PostgreSQL. Оно с ним общается, как с обычным PostgreSQL, просто тот все параллелит.
Звучит фантастически.

Я хотел сделать что-то приятное для ленивых, но не сделаю. Знаю, что на Инфостарте есть люди, которые умеют собирать PostgreSQL из исходников. Если они есть, пожалуйста, отзовитесь и попытайтесь выполнить действия по инструкции:
-
Citus взять тут: https://www.citusdata.com/download/ (только версию подменить на 13)
-
Как патчить для 1С описано тут: https://its.1c.ru/db/metod8dev/content/5942/hdoc
У меня не получилось, я в Си не очень силен. И оно сильно завязано на определенную версию.
Я не сдался, я написал в сам Citus. Если им интересен российский рынок, надеюсь, что они прислушаются, и у нас с вами будет Citus (фраза по состоянию на 2021 год).

Greenplum. Кто хранит логи, телеметрию или еще что-нибудь массовое в реляционной БД – не надо это хранить в PostgreSQL точно. Это надо хранить в Greenplum.
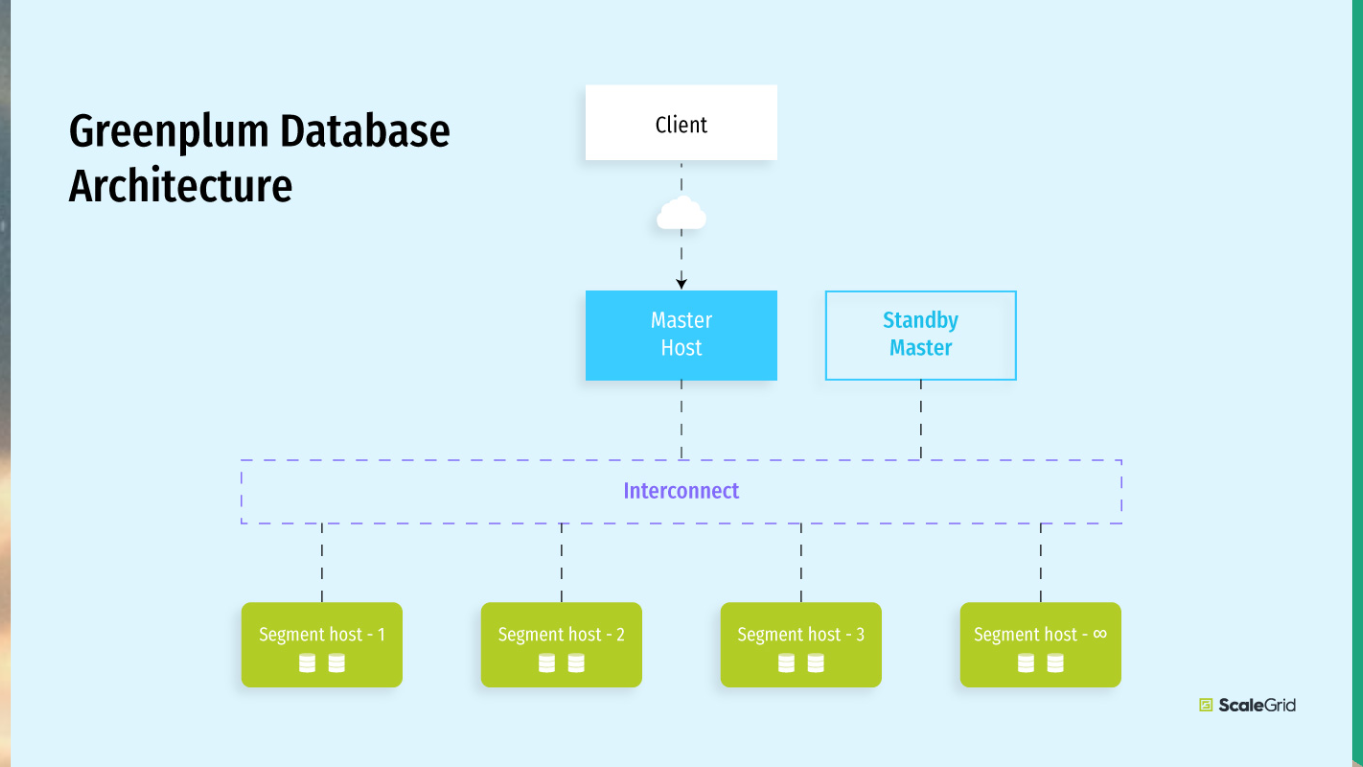
Greenplum сейчас стал практически стандартным для DWH (хранилище данных, где хранят архивные данные).
Greenplum очень хорошо распределяет таблицы по разным серверам, тоже отлично масштабируется.
Но он еще и хорошо джойнит таблицы, которые находятся на разных серверах. Прекрасно это делает. Любой объем данных, который у вас есть, Greenplum может, не стесняясь, засунуть в реляционные таблички. Это будет нормально работать.
Если у вас есть таблицы с большим объемом данных, Greenplum будет сильно похож на PostgreSQL – все ваши внешние источники данных, заливки через ODBC и прочее в Greenplum засунуть можно.
В обычный PostgreSQL – не стоит, потому что обычный PostgreSQL – это OLTP.
Greenplum – это DWH. В Яндексе он тоже есть, и уже, по-моему, не превью.
Поэтому Greenplum для DWH тоже советую узнать – это штука прикольная и важная.
Вопросы
Смотрели ли вы в сторону Yandex database?
Yandex database – это что-то, близкое по нагрузке к OLTP, он нужен, чтобы в него писать данные. Напрямую 1С с Yandex database не работает, у нас для OLTP PostgreSQL или MS SQL.
Получается, что у PosgtreSQL есть несколько вариантов репликации для 1С?
Да, в PostgreSQL есть потоковая репликация. Она классно работает, но в реплику нельзя записать, она стоит в read-only. Зато бэкапы с нее снимать классно.
Логическая репликация в PostgreSQL решает этот вопрос, более того, она решает одну из главных болей 1С – она разрешает вам зеркалировать хоть табличку. Есть подписчик, есть источник, подписался, получай. И более того, она разрешает потом писать на реплику. Там, правда, есть параметр, что делать, если данные разошлись– остановить реплику либо продолжить. Но зато в целом писать можно.
Соответственно, механизм копий базы данных может работать с помощью логической репликации.
FDW – это еще один механизм. С его помощью тоже можно таблички реплицировать, но он не такой быстрый, хотя он быстрее, чем то, как пытается сделать копию 1С.
Потому что 1С, когда делает копию в механизме копии баз данных, делает простой обмен – она просто ставит на регистрацию, потом накатывает. Это РИБ.
Главное, что я хотел вам донести – если вам кто-то говорит, что 1С не потянет такие объемы, мощности, количество транзакций – нет такого. У вас всегда есть способ масштабироваться.
Кластер 1С масштабируется вообще влегкую. 1С потянет, в принципе, все.
Кластер СУБД масштабировать сложнее. Нужно выучить, что такое репликация, что такое копии баз данных. Возможно, шардинг сделать через FDW. Крайний случай – это Citus.
Но, в принципе, у вас нет ограничения на горизонтальное масштабирование. Мы с 1С потянем почти любой объем.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.

Вступайте в нашу телеграмм-группу Инфостарт