
Владислав: Меня зовут Владислав Маковеев, я выступаю вместе с моим коллегой Виталием Черкасовым.

Расскажем о том, как мы разрабатываем: что к нам пришло вместе с EDT, как мы вообще пытаемся адаптироваться в этом мире.

Владислав: Особенность нашей разработки в том, что мы дорабатываем облачные решения, поэтому все наши информационные базы обязательно должны быть опубликованы на сервере 1C и взаимодействовать между собой.
Исходя из этого, локальные базы на машинах наших разработчиков в плане тестирования не валидны, так как локальная база не взаимодействует с серверными.
И нашим разработчикам сначала приходится прогонять у себя тестирование локально, а потом еще искать где-то серверный стенд, чтобы протестировать это взаимодействие.

Владислав: Мы вывели несколько подходов к тому, как можно с этим работать.
-
Первый из этих подходов – это когда стенд разработки относится к конкретному техническому проекту.
-
Второй – когда свой стенд есть у каждого разработчика.
-
И третий подход – это когда существуют только основные и тестовые серверные стенды, а все доработки этого облака ведутся на локальных машинах разработчиков. У каждого из них на ПК развернута виртуальная машина с мини-сервером для локальной разработки.
Мы выбрали первые два подхода и сейчас про них расскажем.
Распределение серверных стендов: когда под каждый технический проект выделяется отдельный стенд разработки
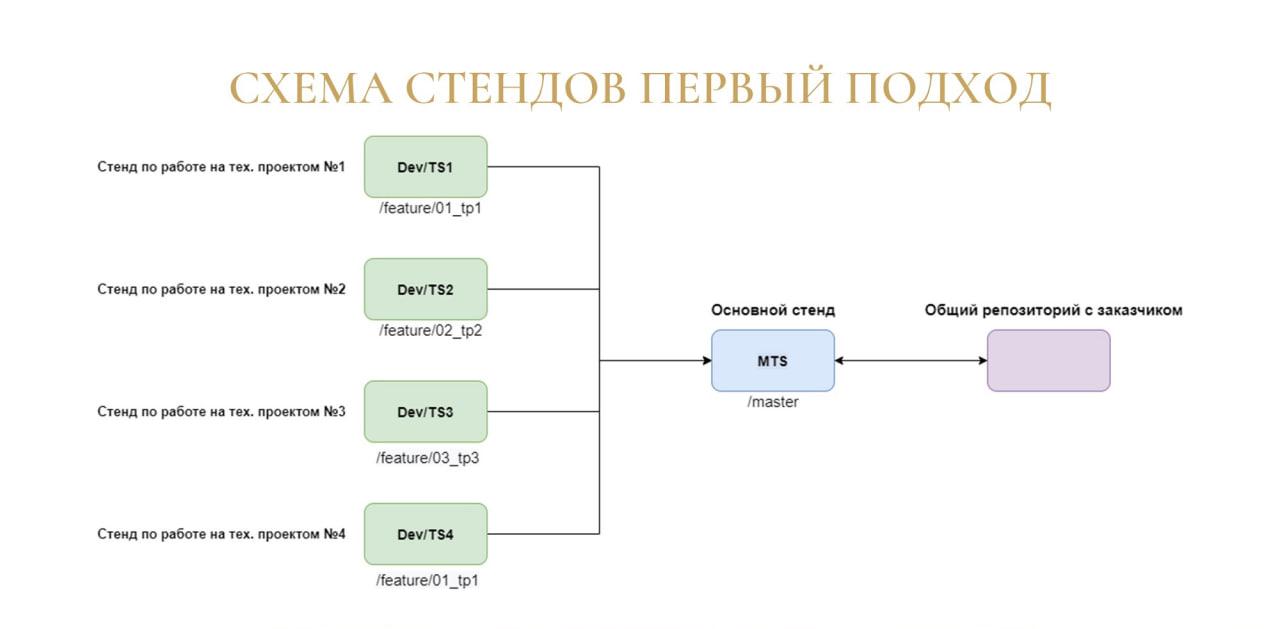
Виталий: Наша команда разработки пошла по первому пути – у нас на один стенд назначен один технический проект.
Но мы используем эту схему только тогда, когда в рамках проекта необходимо вносить изменения сразу в несколько конфигураций, либо когда нужны какие-то обмены. Во всех других случаях мы используем просто локальные базы.
Схема работает следующим образом:
-
Руководитель назначает стенды под техпроекты и распределяет задачи между разработчиками.
-
При получении задачи разработчику необходимо создать ветку и связать ее с соответствующим стендом.
-
Когда разработка завершена, разработчик выполняет слияние с веткой master, которая находится на основном стенде.
-
И потом изменения в ветке master, в свою очередь, вливаются в общий с заказчиком репозиторий.

Виталий: Схема сама по себе достаточно простая, но хочется затронуть ее недостатки:
-
Первый, достаточно критичный, недостаток – если над одним техпроектом работает группа разработчиков, возникает конкуренция за конфигуратор. Приходится распределять задачи таким образом, чтобы они между собой не пересекались.
-
Второй минус – если много активных технических проектов, нужно разворачивать новые стенды. А когда мы разворачиваем новые стенды, возрастает нагрузка на сервер.

Виталий: Теперь о плюсах.
-
Возникает единое пространство для разработчика и тестировщика. После того как разработчик завершил внесение изменений на стенд, к работе подключается тестировщик и выполняет проверку. Они вместе работают на одном стенде и друг другу никак не мешают.
-
Второе – это экономия времени при переключении веток. Так как ветки привязаны к информационным базам, разработчик может свободно между ними переключаться. При этом не теряется время на полную загрузку из проекта в информационную базу.
-
Третий плюс – это высокий уровень мобильности разработчика и возможность одновременно работать сразу над несколькими техническими проектами. Как раз за счет того, что есть жесткая привязка ветки к базе, при оповещении о результатах тестирования разработчик может быстро переключиться, внести исправления, сделать коммит и пойти обратно работать над другим техпроектом.
-
Четвертый плюс – при переключении веток не затираются данные. Поскольку ветки жестко привязаны к информационным базам и состав объектов метаданных не меняется, данные не затираются.
Схема достаточно простая, и она нас сейчас полностью устраивает.
Но что делать в том случае, если сложность технических проектов возрастет и уже не получится распределить задачи таким образом, чтобы каждый разработчик сидел в своей конфигурации?
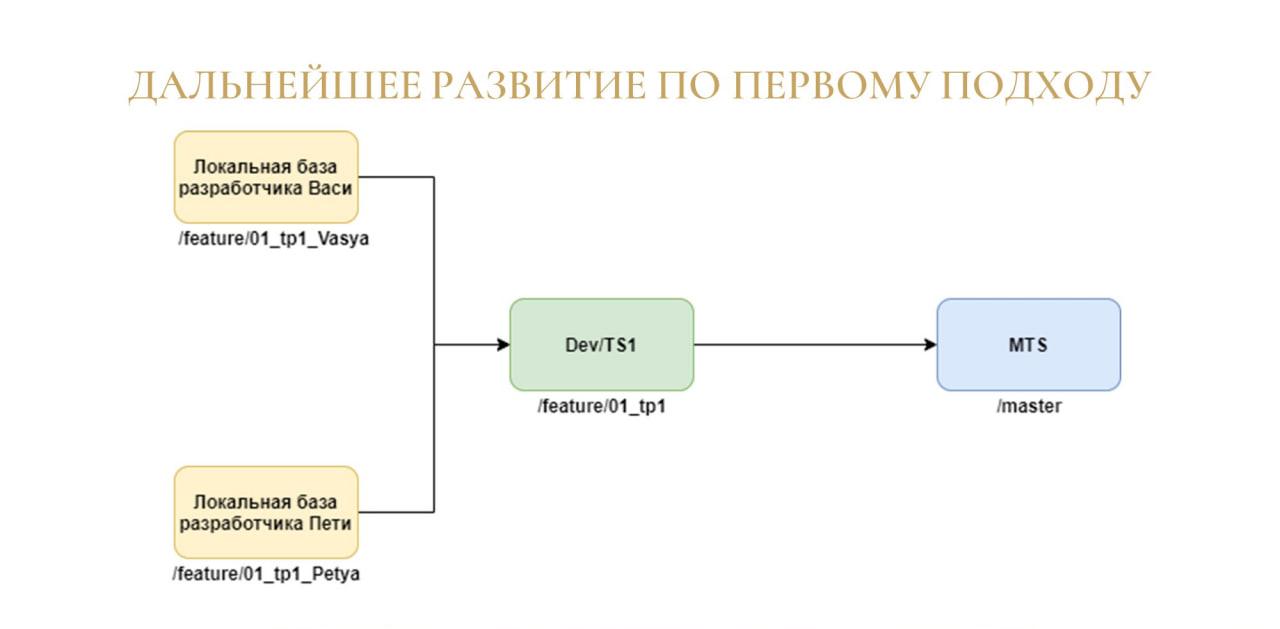
Виталий: В случае распределения стендов техпроектов на нескольких разработчиков, все выполняется точно так же, как при обычной схеме, только:
-
добавляются локальные базы, где разработчики добавляют свою функциональность;
-
после чего они делают мерж-реквест в ветку, которая привязана к основному тестовому стенду;
-
и опять-таки выполняется слияние с мастер-веткой.
Распределение серверных стендов: когда отдельный стенд разработки выделяется под каждого разработчика
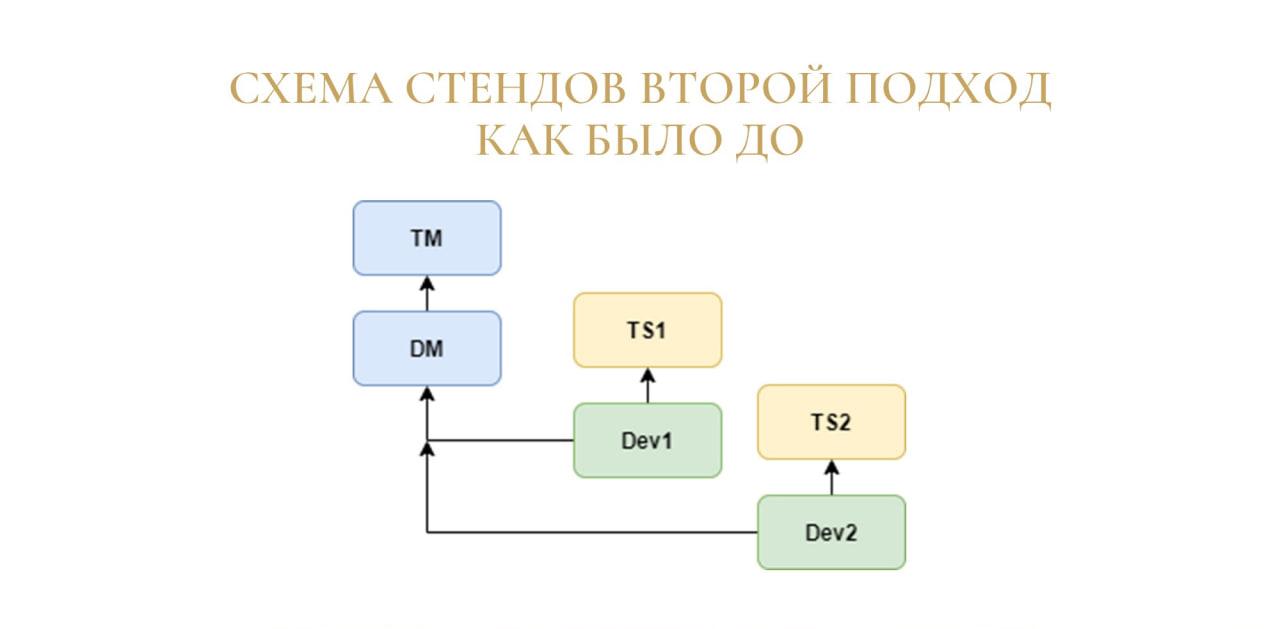
Владислав: Теперь о порядке разработки в нашей команде.
Изначально мы придерживались такого же подхода, и стенды у нас разворачивались под техпроект. Единственным отличием было то, что под каждый техпроект разворачивалось два стенда:
-
первый – для разработки, Dev;
-
и второй – тестовый сервер, TSN (Test Server N).
Это нужно было для того, чтобы разработчики могли на своем стенде ломать все, что хотят, а на тестовом стенде всегда находилась стабильная актуальная версия, где можно было бы спокойно зайти и протестировать.
Но таким образом получалось, что мы раздували серверное пространство, и у нас заканчивался ресурс. Поэтому мы решили перейти на схему, когда под конкретного разработчика разворачивается отдельный новый стенд.
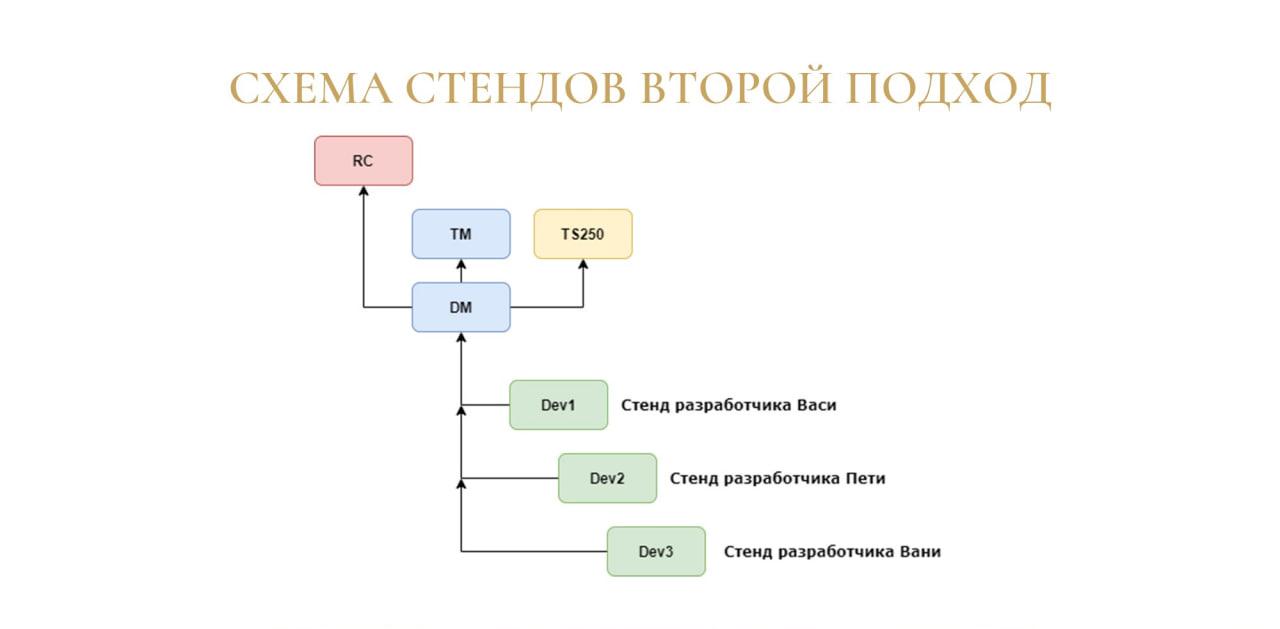
Владислав: Поэтапно пройдемся по этой схеме:
-
У нас появился стенд RC (Release Candidate), на котором содержится самая актуальная версия, выпущенная в релиз.
-
Также используются стенды DM (Develop Master) и TM (Test Master). На них также находится актуальная версия, но уже с внесенными доработками, исправлениями ошибок и прочим – с тем, что войдет в будущий релиз.
-
И далее к этим стендам уже присоединяются стенды DevN, которые относятся к конкретным разработчикам. Разработчики делают на них фиксы, фичи и потом отправляют мерж-реквест, чтобы влить это в Develop Master. Таких стендов может быть несколько, потому что разработчиков у нас много, и их количество может увеличиваться.
-
И последнее – могут создаваться отдельные тестовые стенды. Они временные и рассчитаны на то, что если какой-то проект вдруг обязательно нужно протестировать на сервере, для него может быть развернут еще один дополнительный стенд.

Владислав: Таким образом, мы столкнулись со следующими недостатками.
-
Первый недостаток проявляется, когда программист на своем стенде работает над несколькими проектами сразу. В этом случае ему нужно постоянно замещать проект у себя в EDT, а также импортировать конфигурацию в информационную базу, что занимает достаточно длительное время. В среднем на это тратится 30 минут, и ситуация может улучшаться или ухудшаться в зависимости от того, насколько мощный компьютер стоит у разработчика, и насколько это легкая или тяжелая конфигурация.
-
Исходя из первого минуса, появляется второй. Если мы замещаем конфигурацию, у нас и данные могут удалиться – у нас же на разных проектах объекты метаданных в большинстве случае будут меняться. А при изменении метаданных данные в информационной базе могут очищаться. Чтобы обойти этот эффект, мы пока что используем внешнюю обработку «Выгрузка и загрузка данных XML» и выгружаем нужные данные в XML, а потом при необходимости загружаем обратно. Но также думаем, как вообще можно оптимизировать данный шаг.
-
Третье – это то, что при увеличении размера команды у нас увеличивается количество стендов. Изначально мы пытались уйти от нехватки серверного пространства, чтобы под каждый проект, которых у нас много, не нужно было разворачивать отдельный стенд. И поскольку у нас разработчиков меньше, чем техпроектов, мы смогли решить эту проблему. Но если количество разработчиков в нашей команде увеличится, то и стендов станет больше. И места опять станет не хватать.
-
И последний недостаток – это то, что для QA в некоторых случаях нужны отдельные стенды, потому что стенды разработчиков могут не соответствовать тому, что нужно протестировать. А это опять же у нас сжирает место на сервере, за счет чего увеличивается потребление.

Владислав: Но было бы грустно закончить на недостатках, поэтому поговорим про преимущества данного подхода.
-
Первое из них – это то, что программист всегда знает, где ему работать. Выдавая задачу, мы не паримся о том, где ему работать, какой стенд ему выделить. Он просто работает на своем стенде.
-
Второе – это то, что мы экономим ресурс сервера. Мы не создаем лишних стендов, т.к. у нас их количество ограничено. А разработчиков меньше, чем техпроектов. Плюс мы также можем не все приложения разворачивать для разработчика, так как некоторые приложения фреша ему не нужны. В этом случае, опять же, экономится место. А если ему позарез понадобилось какое-то приложение, его развернуть не составит труда.
-
Третье – это то, что мы убрали боль из-за очереди в конфигуратор. Просто представьте: когда над одним проектом работают три программиста, у них начинается драка за то, чьи изменения нужно залить в первую очередь. Такие конфликты приходится решать либо тимлиду, либо они сами создают какую-то свою очередь. Мы убрали эту боль, и у нас нет драк за стенды – у нас все тестируют на своих стендах.
-
Четвертое – это то, что у каждого разработчика повышается чувство значимости. Представьте, junior-разработчик только пришел в 1С, и ему сразу дают целый серверный стенд. Конечно, на стенде можно делать не все, что хочешь – у нас есть некоторые регламенты по ведению этих стендов.
-
Первое – на стенде всегда должны быть валидные тестовые данные. Например, недопустимо, чтобы в справочнике «Контрагенты» элементы назывались просто «Тест1» и «Тест2».
-
Второе – версии конфигурации на стенде обязательно должны быть актуализированными и не отставать от релизных.
-
И последнее – нужно писать код так, чтобы не ушатать сервер.
-
-
И пятое преимущество – в такой парадигме удобно работать в небольшой команде. Мы всегда знаем, где кто работает.
Работа с ветками Git. Вариант доработанного GitFlow
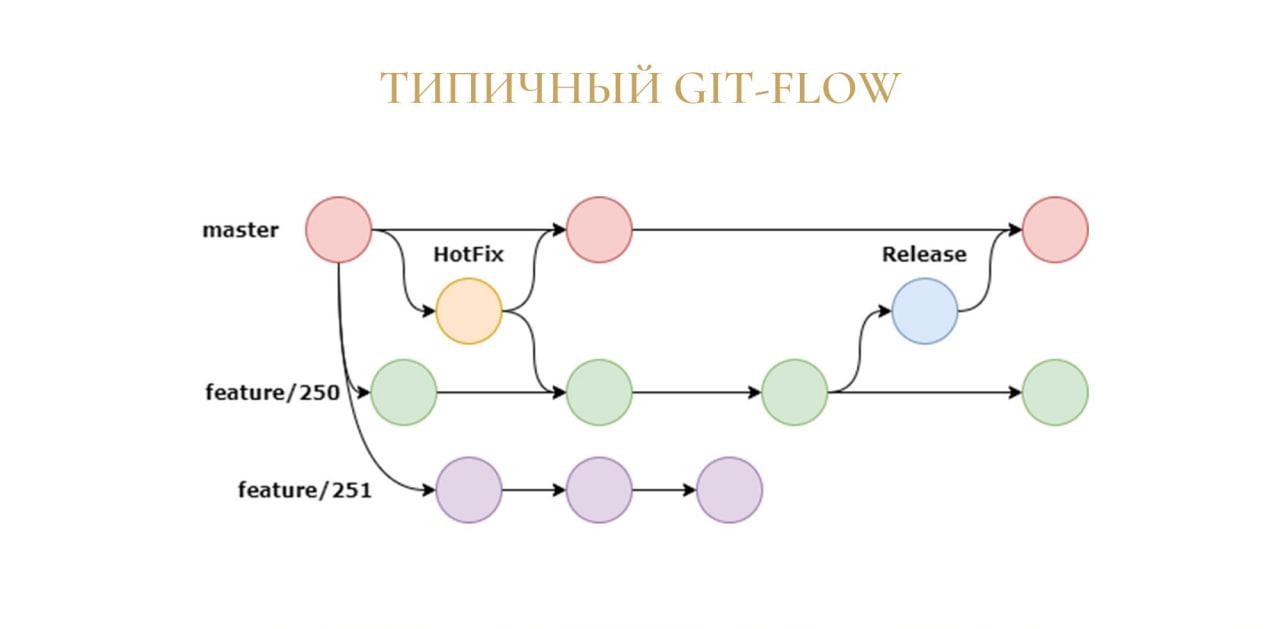
Владислав: Теперь немного поговорим про Git. В нашей команде разработки мы используем методологию GitFlow. Выглядит она примерно так, как на слайде, но с небольшими изменениями.
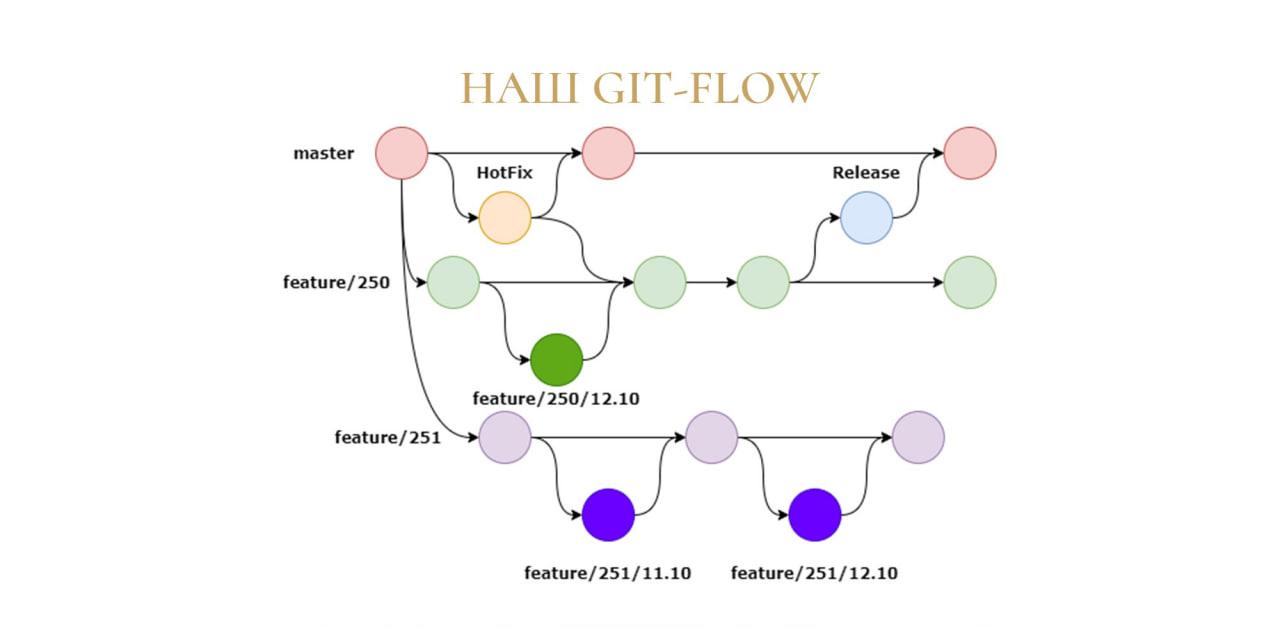
Владислав: Изменения состоят в том, что из веток future и веток HotFix у нас создаются дополнительные ветки. Они нужны, поскольку у нас есть джуниор-разработчики, которые иногда не понимают, как правильно писать код и допускают ошибки в оптимизации.
В этом случае они делают копию ветки, работают в ней и потом отправляют все это на мерж-реквест. В мерж-реквесте мы проводим код-ревью и дальше, если все ок, сливаем код, если нет, то возвращаем на доработку.
Для этих веток есть некоторый регламент:
-
они должны называться так же, как и основная ветка;
-
они не должны жить более одного рабочего дня – это важно, чтобы они у нас не плодились, иначе их будет очень много. Но есть исключения:
-
когда ветка не прошла мерж-реквест – тогда в нее сначала нужно внести исправления, а потом снова вливать;
-
и если задача занимает по длительности более чем один рабочий день – в этом случае ветка, опять же, живет дольше.
-
На подобных код-ревью мы джуниоров обучаем и не допускаем, чтобы они пушили в основные ветки (у них на это нет прав).
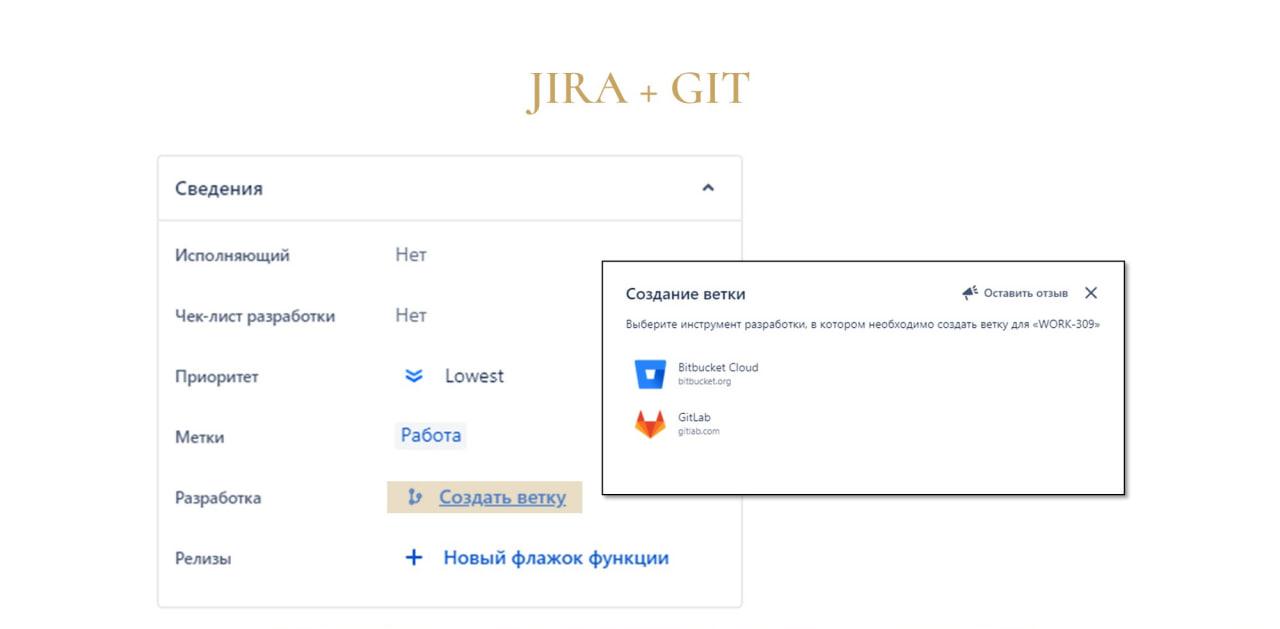
Владислав: Для трека задач мы используем Jira – в ней удобно работать, и у нее есть интеграция с Git-сервером:
-
можно использовать Bitbucket;
-
либо скачать в маркетплейсе Jira приложение для интеграции с GitLab и установить его для определенной доски – мы разрабатываем в GitLab, потому что там есть бесплатные закрытые репозитории, и нет ограничений по пользователям.
После настройки такой интеграции в карточке задачи появляется возможность «Создать ветку». При ее нажатии появляется окошко, где мы можем выбрать, какое приложение запустить, чтобы развернуть ветку.
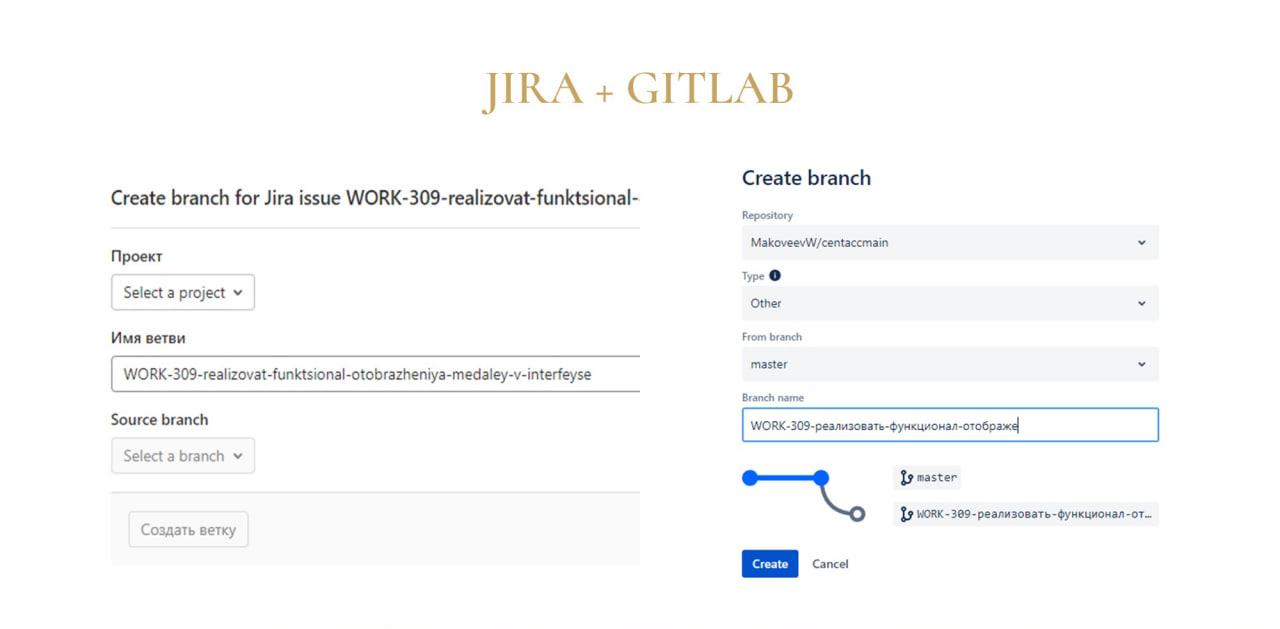
Владислав: После выбора открывается диалог создания ветки, где мы указываем, где ее создать и как назвать.
Интеграция автоматически подставляет наименование этих веток с единственным отличием:
-
в GitLab имя ветки пишется транслитом на латинице и полностью;
-
а в Bitbucket имя ветки пишется на кириллице, но при этом вставляется не полностью.
Эти особенности разворачивания следует учитывать.
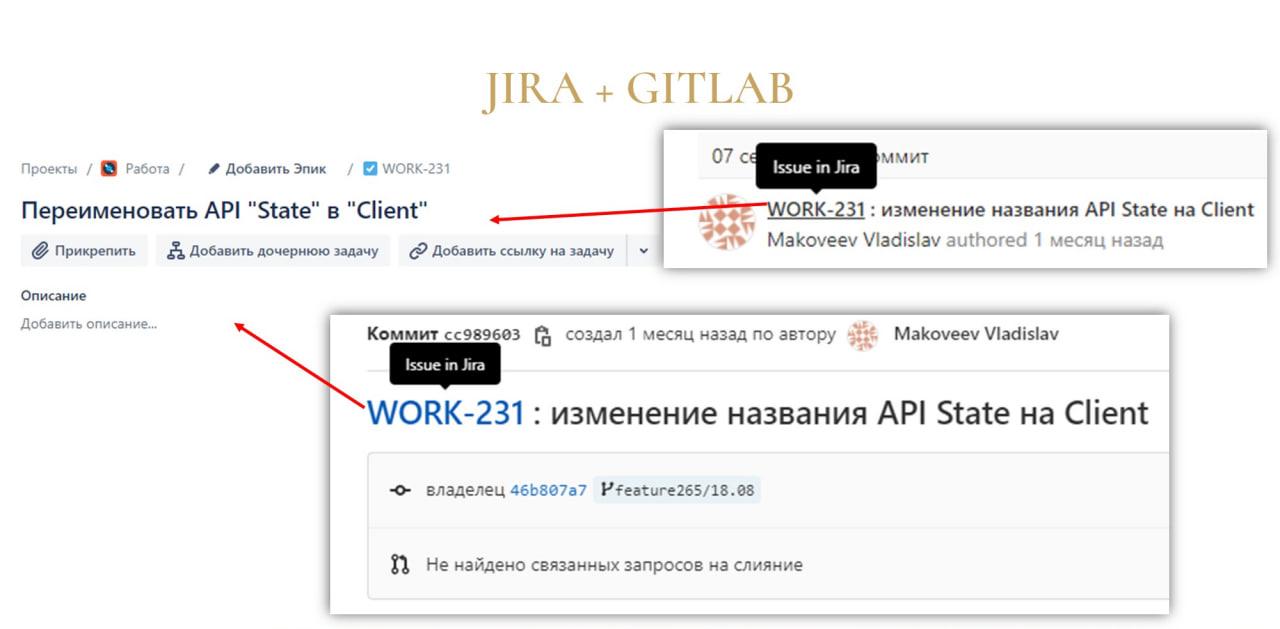
Владислав: В GitLab интеграция с Jira тоже встроена – там в коммитах можно указывать ссылки на задачи. При этом неважно, откуда вы сделаете коммит – из EDT или из консоли. Мы в коммите GitLab можем нажать на ссылочку, а дальше нас перекинет на карточку задачи.
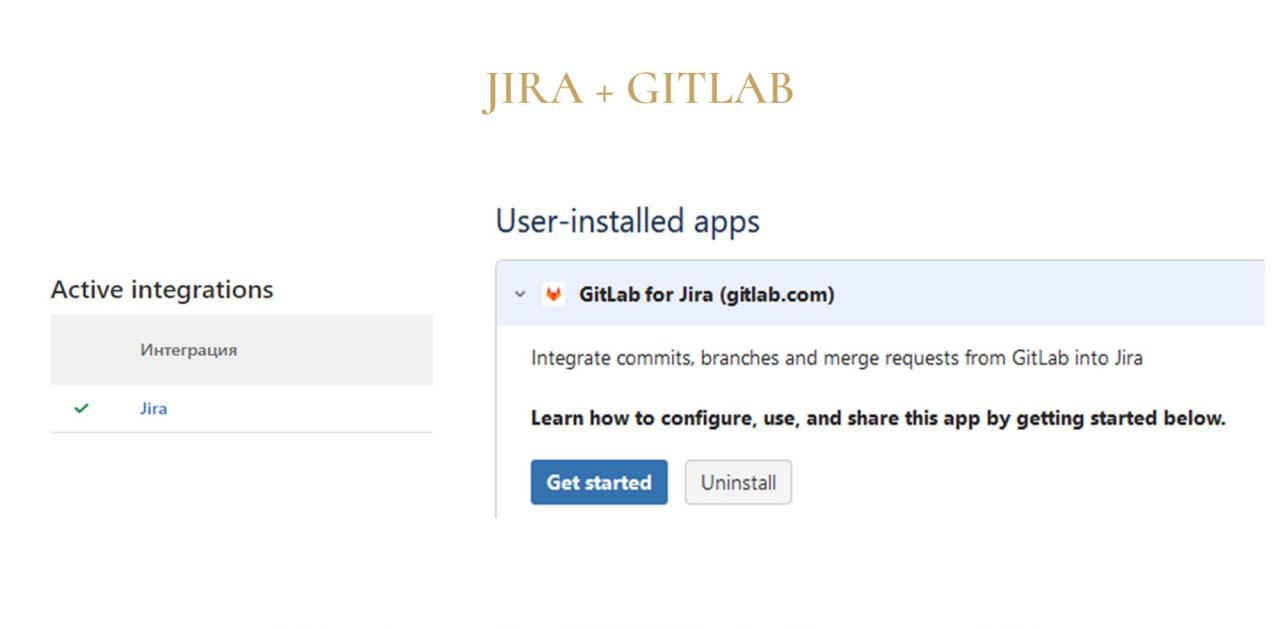
Владислав: Настроить такие интеграции в самом GitLab можно на вкладке «Интеграции». Если на стороне Jira интеграция настроена, там появится зеленая галочка, что все окей, и вы сможете указывать в коммитах ссылки на задачи.
Работа с ветками Git. Вариант доработанного GitHub Flow
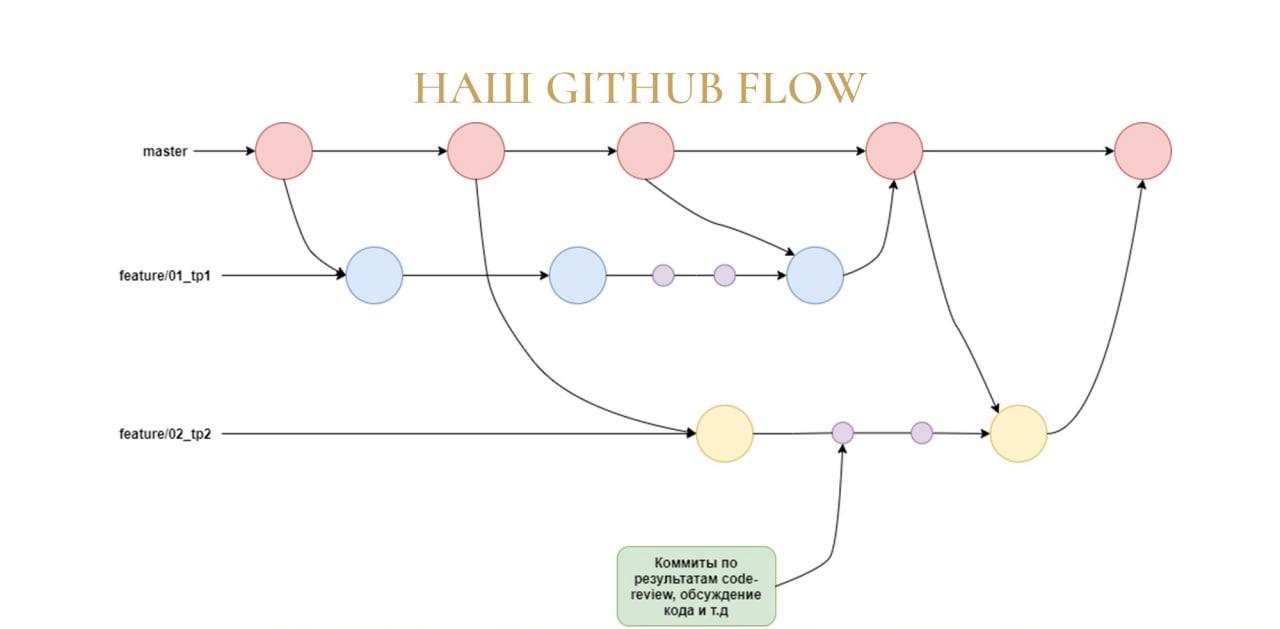
Виталий: Теперь про использование Git в нашем отделе.
Мы используем методологию GitHub Flow, только немного измененную. Причем мы используем GitHub Flow для GitLab.
Особенность нашего GitHub Flow в том, что мы не делаем мерж-реквесты в мастер-ветку, а делаем слияние в ветку разработки – почему мы так делаем, я расскажу чуть позже.
У нас есть небольшой регламент по наименованию веток для техпроектов:
-
сначала идет feature – то есть мы добавляем что-то новое;
-
дальше идет код технического проекта в СППР;
-
и через знак подчеркивания идет наименование самого техпроекта, чтобы можно было читаемо это все увидеть.
CI/CD. Подход через полный переход на EDT и Git
Владислав: Пока мы разбирались с EDT и разворачивали Git, нам пришла мысль: почему бы нам не организовать у себя CI/CD?
Мы подошли к этому основательно, поскольку у нас уже были свои написанные приложения, которые позволяют нам: администрировать кластер; автоматически разворачивать в нем информационные базы; загружать туда dt-шники или конфигурации. В общем, все, что нужно, чтобы пройти автотесты либо еще что-то.
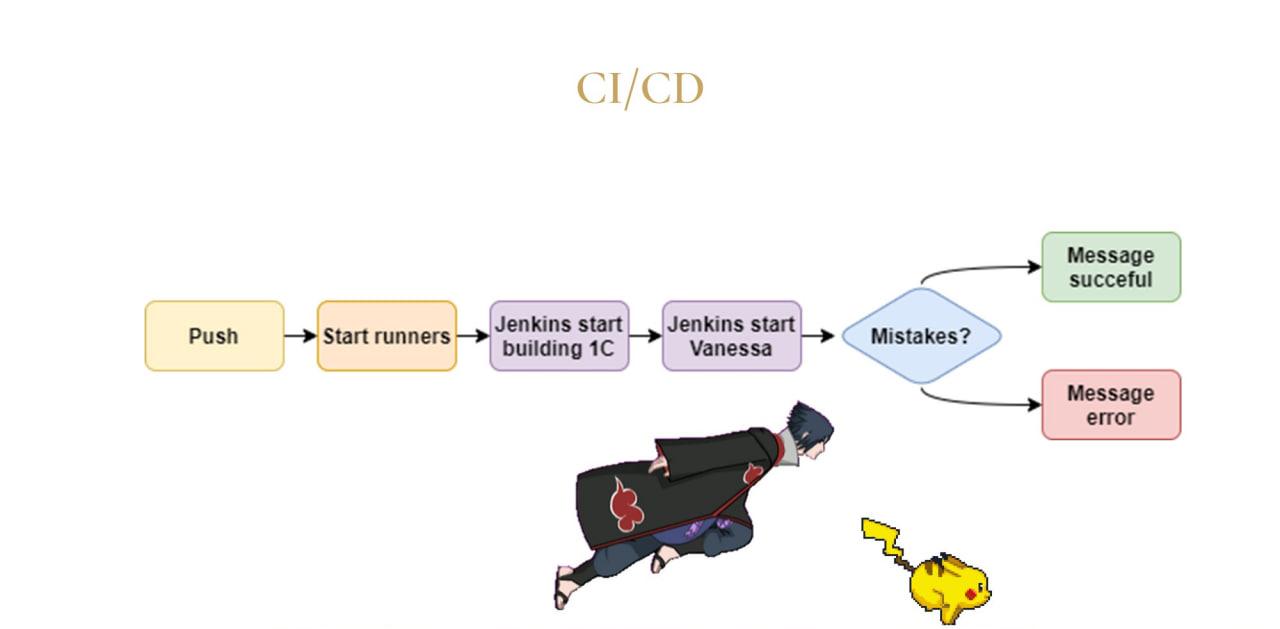
Владислав: Пока что у нас CI полностью не реализован, но я с вами поделюсь планами, каким он будет:
-
Первое, что у нас происходит – это push либо merge request. Таким образом, мы сначала что-то мержим.
-
Далее у нас запускаются ранеры от GitLab, которые у нас развернуты на сервере, и эти ранеры уже начинают запускать скрипты Jenkins.
-
Jenkins в первую очередь у нас на сервере разворачивает тестовый стенд, на котором поднимается актуальная демобаза, и в нее загружается конфигурация.
-
После того как все это было успешно развернуто, запускается скрипт Jenkins, использующий фреймворк тестирования Vanessa, который начинает прогонять на этом новом стенде сценарии тестирования.
-
И далее уже по исходу у нас приходит сообщение от специального telegram-бота, что мерж-реквест успешно прошел автотест, его можно заливать.
-
Или, если все плохо, то он пишет, какие ошибки есть, их количество. В будущем потом это можно будет посмотреть в отчете Allure либо в СППР.
-
После того как у нас мерж-реквест проверен, и мы приняли решение, что все окей, мы можем это релизить – у нас есть автоматическая сборка поставки, которая в дальнейшем уже отправляет ее в 1С и публикует. Но про этот процесс я вам подробно рассказывать не буду, потому что он у каждого может быть свой.
CI/CD Подход с использованием хранилищ и 1С:ГитКонвертер

Виталий: Теперь немного про CI/CD в нашем отделе.
-
Первым пунктом я выделил то, что мы не отказываемся от хранилищ конфигурации, потому что общий репозиторий с заказчиком у нас выполнен как раз-таки с помощью хранилища.
-
Исходя из этого, у нас вытекает второй пункт – мы используем 1С:ГитКонвертер, чтобы выполнять синхронизацию наших репозиториев в Git и хранилищ.
-
Третий пункт – разработку мы выполняем с помощью EDT в рамках технических проектов. Hotfix выполняем с помощью расширений с прямой установкой на прод руками и помещением напрямую в хранилище.
-
Четвертый пункт – как я уже говорил в блоке про Git, слияние мы выполняем не в мастер-ветку, а в ветку разработки. Это важно, чтобы использовать полную функциональность EDT для разрешения конфликтов Git – мы сначала делаем слияние, затем получаем итоговую конфигурацию, выгружаем ее, и дальше уже выполняется стандартная работа по перемещению доработок в хранилище.

Виталий: Для проверок мы используем SonarQube. Это удобно, потому что:
-
Он работает с исходниками ровно так же, как и EDT. Не нужно ничего конвертировать, выгружать. Взяли локальный репозиторий, запустили проверку SonarQube, и все хорошо работает.
-
У него есть фильтр по автору ошибки – это работает, когда SonarQube используется в связке с Git.
-
У него есть большое количество проверок – там есть проверки как на сам код, так и на восприятие (когнитивная и цикломатическая сложность)
-
И в SonarQube достаточно удобный просмотр замечаний – они выполнены в виде карусельки.
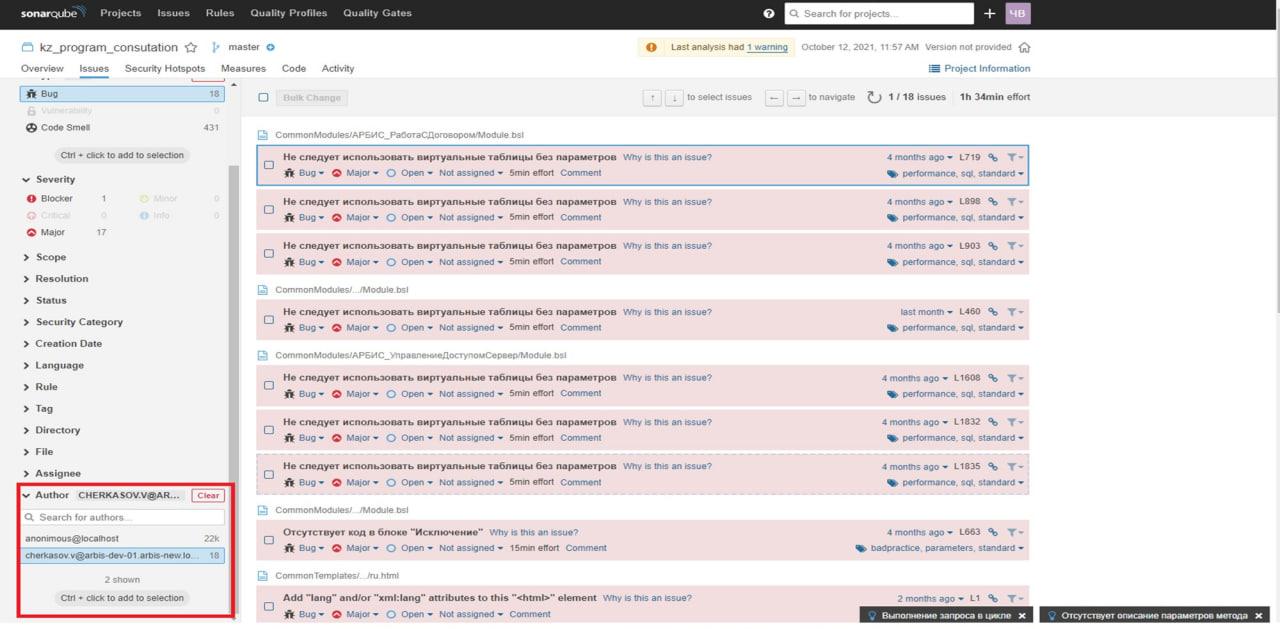
Виталий: Выглядит это так как на слайде. У нас есть проект SonarQube. В левом нижнем углу выделен блок с отбором по автору, который выводит в основную область мои косяки.
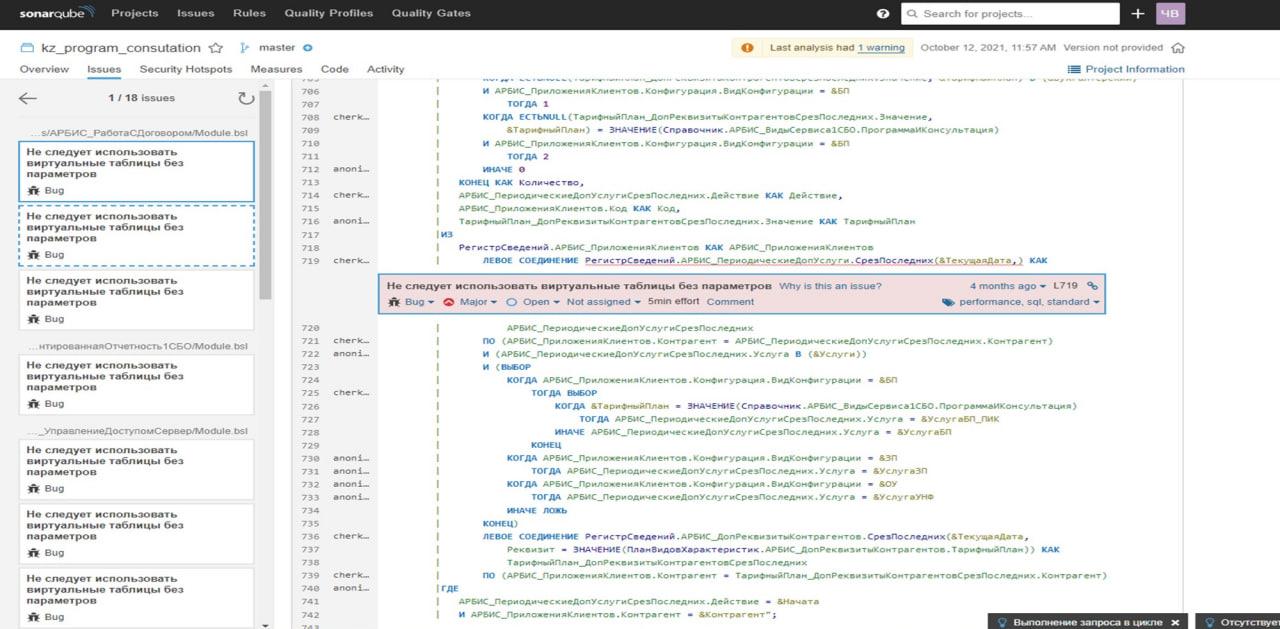
Виталий: Когда мы уже попадаем в само замечание, мы видим код с подсветкой синтаксиса, где можно оценить, какие ошибки у нас были допущены.
А слева предоставлена каруселька, где можно смотреть замечания.
Разработка в 1С:EDT. Плагины

Виталий: Теперь хочу поделиться опытом разработки непосредственно в EDT:
-
Первое – наша команда для проверок внутри EDT использует проект v8-code-style, который встроен в EDT, начиная с версии 2021.2 и выше. Плюс v8-code-style в том, что он проверяет соответствие стандартам не только кода, но и еще метаданных.
-
Второй плагин, который мы используем активно, это 1C:SSL – он хорошо помогает при работе с БСП.
-
Мы отказались от «Коннектора BSLLS для 1С:EDT», потому что он достаточно сильно тормозил систему и не всегда адекватно реагировал на исправление. Джунов это иногда вводило ступор – они бежали, спрашивали: «Что у меня произошло? Я ошибку исправил, она не исправляется». Смотрю – действительно, ошибка исправлена, но все равно помечено, что осталась.
-
И четвертый плагин – Open Editors. Он хорошо помогает, когда есть много открытых вкладок.
Владислав: Мы используем те же самые плагины. За исключением того, что у нас в отделе пока что пользуется спросом «Коннектор BSLLS для EDT», и на v8-code-style мы не перешли – но это на самом деле вопрос времени.
Также я пробовал использовать разные плагины для работы с GitLab, чтобы можно было внутри EDT автоматически проводить мерж-реквесты и не переходить при этом в отдельное приложение – не запускать ради проверки браузер. Но подходящего плагина пока что под себя не нашел и возможно в будущем уже сам напишу для себя плагин, при помощи которого можно будет выполнять мерж-реквесты внутри EDT.
Боли использования 1С:EDT

Виталий: Теперь про сам опыт.
Первое, что необходимо при работе с EDT – это добавить в исключение антивируса каталоги, которые он использует:
-
каталог программной среды;
-
каталог с локальными репозиториями;
-
и workspace.
Это нужно, потому что антивирус будет постоянно, на каждый чих, который происходит в этих папках, выполнять проверку, что может привести к замедлению системы.
Владислав: А второе – это то, что при работе с EDT могут происходить ошибки, которые вообще не очевидны.
Например, мы переименовали какую-нибудь общую команду в глобальном контексте, и у нас при импортировании проекта в конфигурацию информационной базы возникает ошибка: «Неверное имя команды формы».
Мы понимаем, что проблема в файле объекта, и, чтобы ее найти, воспользоваться обычным поиском по конфигурации не получится.
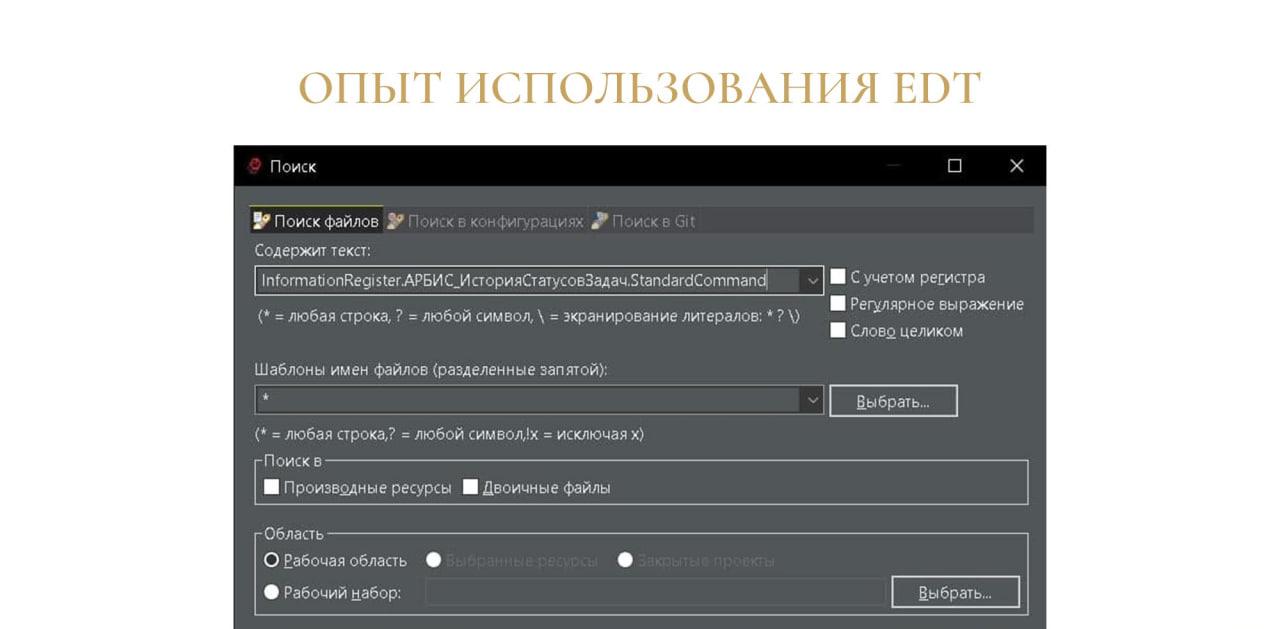
Владислав: В этом случае можно воспользоваться поиском по файлам. Ввести в поисковую строку имя этой команды, и далее она нам уже найдет, где это находится.
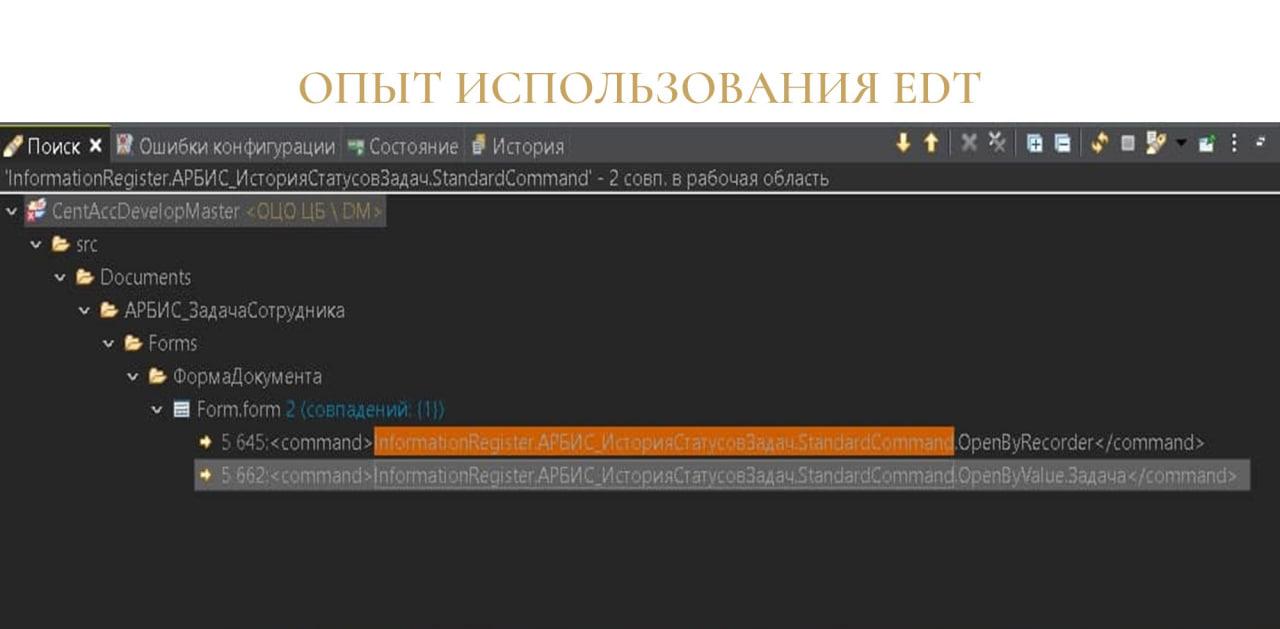
Владислав: Все, что здесь остается – это просто открыть этот файл объекта через текстовый редактор и поправить, в зависимости от того, что вы сделали – переименовали или удалили.

Владислав: Третий пункт – это добавить в конфигурацию Git параметры, которые предоставлены на слайде.
Немного о самих параметрах.
-
Первый – это core.quotePath в значении false. Он нужен, если используется команда Git, которая выводит какие-то пути, где используется кириллица. В мире 1С кириллица используется почти всегда, а Git по умолчанию преобразует символы кириллицы в нечитаемый вид.
-
Следующий параметр – это core.autocrlf в значении true. Очень помогает, если есть разработчики на разных операционных системах. Этот параметр преобразует все окончания строк в единый вид.
-
Следующий параметр – это core.safecrlf в значении true. Он работает в связке с параметром core.autocrlf и выполняет отмену. Когда у Git не получается выполнить преобразование окончаний строк, он делает откат.
Следующий пункт – при слиянии важно выполнять полную загрузку из проекта в базу данных. Если этого не сделать, возникнет ошибка о том, что в базе каких-то данных не хватает. Поэтому при обновлении мы просто ставим галочку, что мы выгружаем ее полностью.
Следующий пункт стал у нас в команде регламентом – это не обновлять EDT до самой последней версии. Это связано с тем, что самые актуальные версии выходят в бете, и при работе с ними могут возникнуть критические ошибки, которые либо очень сильно замедлят работу с EDT, либо вообще ее застопорят. Поэтому мы держимся хотя бы за одну версию до актуальной.
Еще из общих моментов хочу сказать, что в EDT:
-
пока достаточно тяжело работать с макетами табличных данных;
-
и достаточно тяжелая отладка при больших конфигурациях.
Вопросы
В каком интерфейсе разработчик делает запрос на мерж-реквест? В GitLab заходит?
Владислав: Да, заходит в GitLab.
И ответственный за мерж-реквест выполняет это код-ревью тоже в интерфейсе GitLab?
Владислав: У нас это можно трекать либо в задаче Jira, либо он проводит код-ревью в интерфейсе GitLab.
А не было идеи, чтобы все это было в Jira – чтобы в Jira можно было и запрос сделать, и получить задачу на выполнение?
Владислав: Идеи были. Но мы сейчас с Jira работаем как с экспериментальным продуктом, потому что все равно пользуемся СППР. Нам удобно дорабатывать СППР под свои нужды при необходимости.
А Jira для нас пока – не обследованный до конца объект, мы там пока что нарабатываем опыт и улучшаем процессы. Возможно, позже, как вариант, реализуем.
Поделитесь опытом, как много времени нужно, чтобы перевести разработку из конфигуратора на EDT? В масштабе одного разработчика.
Владислав: Я не буду говорить о масштабе одного разработчика. У нас все же целая команда, и если мы переходим, то все.
В нашей команде мы разрабатываем облачный продукт, и я его смог перевести на EDT полностью за две недели. В это входил импорт исходников из хранилища в Git с помощью 1С:ГитКонвертер.
И в дальнейшем мы проводили обучение наших сотрудников, чтобы они полностью вникли, как работать с EDT и как работать с GIT – до этого они EDT видели, но не работали в ней полноценно.
У нас на это ушло две недели со всеми ошибками. В первую неделю я вникал сам, а во вторую неделю уже передавал своим сотрудникам, чтобы что-то им подсказывать, если у них будут ошибки.
Мы занимаемся проектами, и у нас, как правило, разработка идет на среде заказчика – мы разрабатываем чисто в хранилищах. Что можно предложить заказчику, чтобы мы на его среде разрабатывали с использованием CI/CD-технологий?
Виталий: Тут можно использовать переходную схему работы EDT, когда хранилища остаются, а 1С:ГитКонвертер конвертирует хранилища в Git. Тогда и заказчик остается со своими хранилищами, и вы организуете CI/CD на основе исходников в Git.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт