Меня зовут Евгений Винниченко, я представляю компанию WiseAdvice.Tech
Хочу поделиться с вами историей развития системы логирования при разработке сервисного решения, которое предоставляется определенному сегменту клиентов.
Сразу скажу, что я предпочитаю проектировать интеграции исключительно через шины. С учетом того, что в 2022 году вышла 1С:Шина, мне кажется, это достаточно важная и хорошая тенденция. Хотя со мной многие могут и не согласиться.
С каждым годом нам приходится делать все больше и больше абсолютно разных интеграций. И все идет хорошо ровно до того момента, пока не возникает исключительная ситуация, которую приходится расследовать. И вот тогда нам нужны логи. И много логов не бывает, особенно в тот момент, когда необходимо искать причины возникновения исключения.

Мы для себя в определенный момент вывели следующие критерии идеальных логов:
-
Логи должны занимать как можно меньше места.
-
Процесс логирования должен минимально влиять на производительность продуктивной системы.
-
И информации в логах должно быть достаточно для расследования причин возникновения исключительных ситуаций.
Попробую рассказать, как мы своими шишками, собранными исключительно на практике, добивались этой идеальности.
Задача: агрегация и обмен статусами электронных документов от разных операторов ЭДО
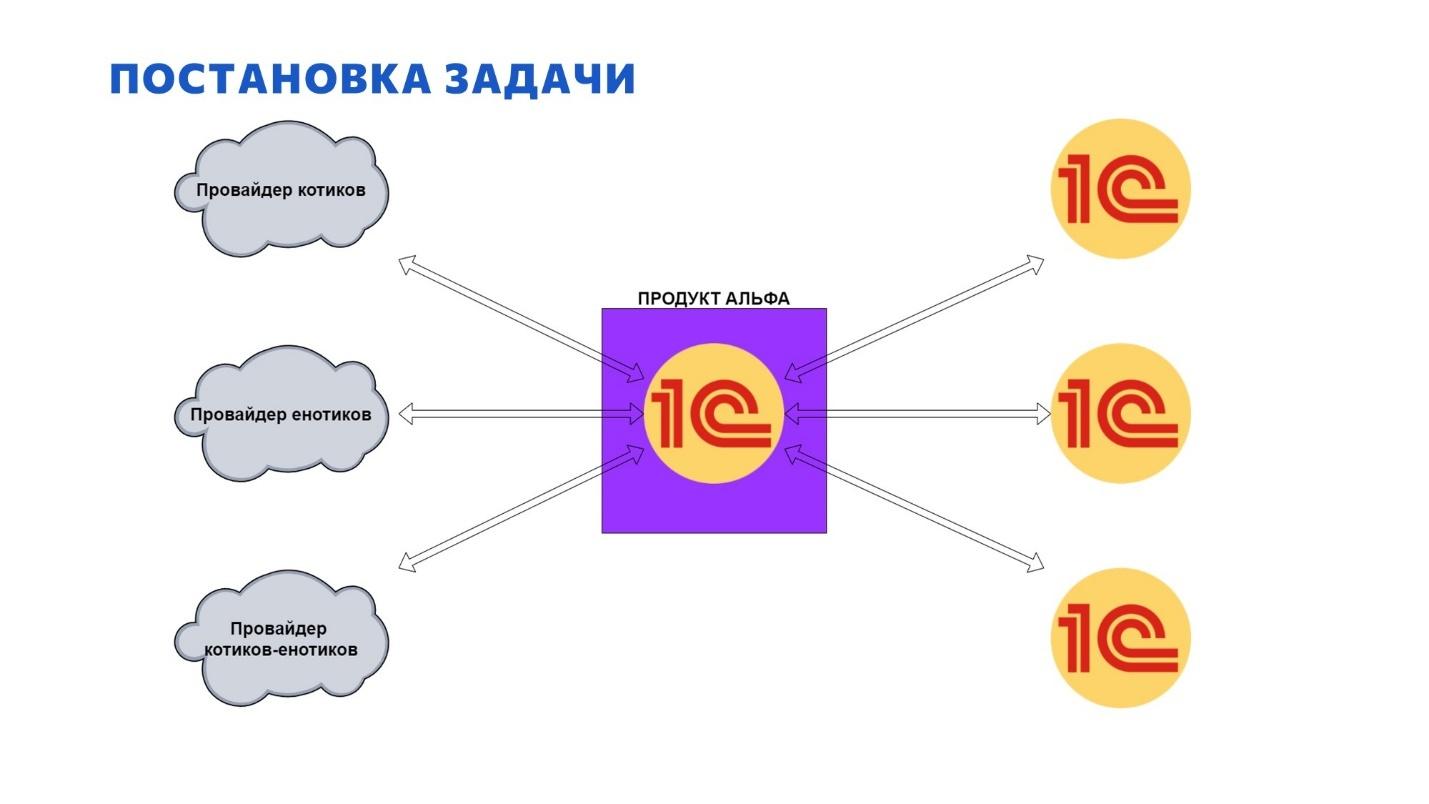
Три года назад у нас появилась идея одного продукта для электронного документооборота, который, как нам казалось на тот момент, можно реализовать быстро и получить от этого немалую технологическую выгоду.
Основное решение, на базе которого мы хотели реализовать свой продукт, было разработано и поддерживалось непосредственно вендором, фирмой «1С».
Называть решение не буду, лишь скажу, что потенциал у продукта нами пока еще не исчерпан, и мы его потихоньку развиваем. Фактически мы даже вышли с этим решением на рынок, хотя родился он как внутренний продукт.
Функциональное назначение продукта – это агрегация данных об электронном документообороте. Быстрая цель, которую мы преследовали на начальном этапе – это сделать обмен статусами электронных документов из нашего продукта в систему бухгалтерского учета, где эти статусы должны быть видны, чтобы пользователи с ними могли работать.
Итерация 1. Обмен через Enterprise Data. Логи в журнале регистрации
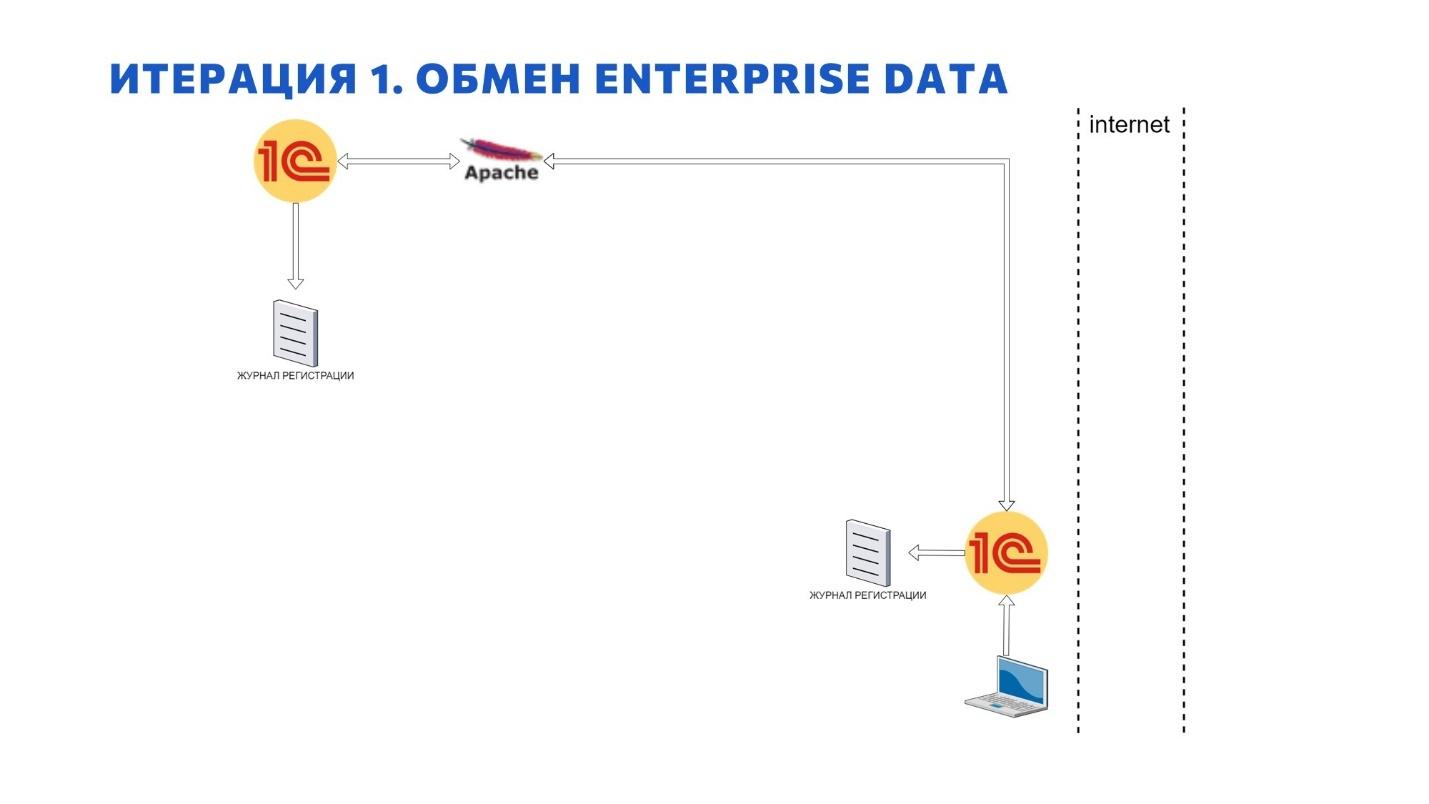
Поскольку в основе решения лежал типовой продукт, разработанный фирмой 1С, туда из коробки был заложен механизм EnterpriseData.
И мы решили – зачем нам городить огороды, сейчас немного напильником обработаем, добавим пластилина по вкусу, украсим это все россыпью желудей и будем радоваться осени. Это – отсылка к одноименной библиотеке, написанной на OneScript, которая совращает умы 1С-ников уже не первый месяц.
И мы решили, что EnterpriseData – это, по сути, киллер-фича, а нам нужно буквально чуток времени, и у нас уже будет готовый механизм синхронизации с потребителями сервисов по статусам электронного документооборота.
Но по итогу с точки зрения обмена через EnterpriseData, как мне кажется, мы собрали вообще все существующие грабли:
-
Это и отсутствие разбиения пакета на порции – сколько изменений на плане обмена зарегистрировано, столько и будет выгружено. Поэтому итоговый файл обмена может быть в пару гигабайт XML, который не каждая система прожует.
-
Это и недоработки правил обработки данных, по которым выполняется заполнение файла обмена.
Мы собрали откровенно много граблей. Ожидали, что все уже реализовано за нас, но по факту напоролись на все, что можно.
Напомню, что решение было реализовано на основе типовой конфигурации от вендора. Но поддерживалось это решение, мягко говоря, не очень активно. Мы в то время еще верили в правильность нашего подхода, много писали в 1С, баг-репортили. Но когда решения для наших баг-репортов попадали в код не ранее чем через 9 месяцев, становилось немного грустно. А еще грустнее становилось, когда в процессе обмена возникали исключительные ситуации.

Как вообще реализовать логи при таком обмене? Честно скажу, что никак.
Ты можешь явно видеть, что обмен между системами прошел, но докопаться до исходных причин достаточно сложно.
Не стоит забывать о явной транзакции при начале работы загрузки, при использовании EnterpriseData. И это, если что, правильный паттерн. Просто для цели нашего продукта эта ситуация была губительной. Допустим, если у нас в обмене заходят 10 документов, мы получаем их статусы, и один из них не загружается, то падает весь обмен – девять других тоже не загружаются. С точки зрения обмена, квитирования сообщения, это все правильно. Но с точки зрения нашего сервиса – нет.
Давайте оценим по пунктам наших идеальных логов, что мы здесь имеем.
-
Логи должны занимать как можно меньше места – здесь все ок, так как логов нет. Какой-то минимум информации пишется в журнал регистрации, и места эти данные практически не занимают.
-
Процесс логирования должен минимально влиять на производительность – здесь тоже все ок. Так как логов мало, за их запись отвечает сам сервер, а точнее, менеджер рабочих процессов. Влияние на производительность системы минимальное – вроде никому не мешает.
-
Ну, и информации в логах должно быть достаточно всегда – вот тут, конечно, все не так. Информации, которую БСП пишет в журнал регистрации при работе с EnterpriseData, для расследования абсолютно всех исключительных ситуаций явно недостаточно. Точку начала транзакции или момент падения можно найти, а получить достаточное количество деталей бывает сложно.
И, если честно, на первой итерации без нормальных логов было очень тяжело.
Разработчикам продукта 50% времени приходилось тратить на отладку, в попытке найти те или иные ошибки. И только 50% времени на саму разработку. Это было непродуктивно.
Итерация 2. Обмен через REST API. Логи в справочнике «Логи»
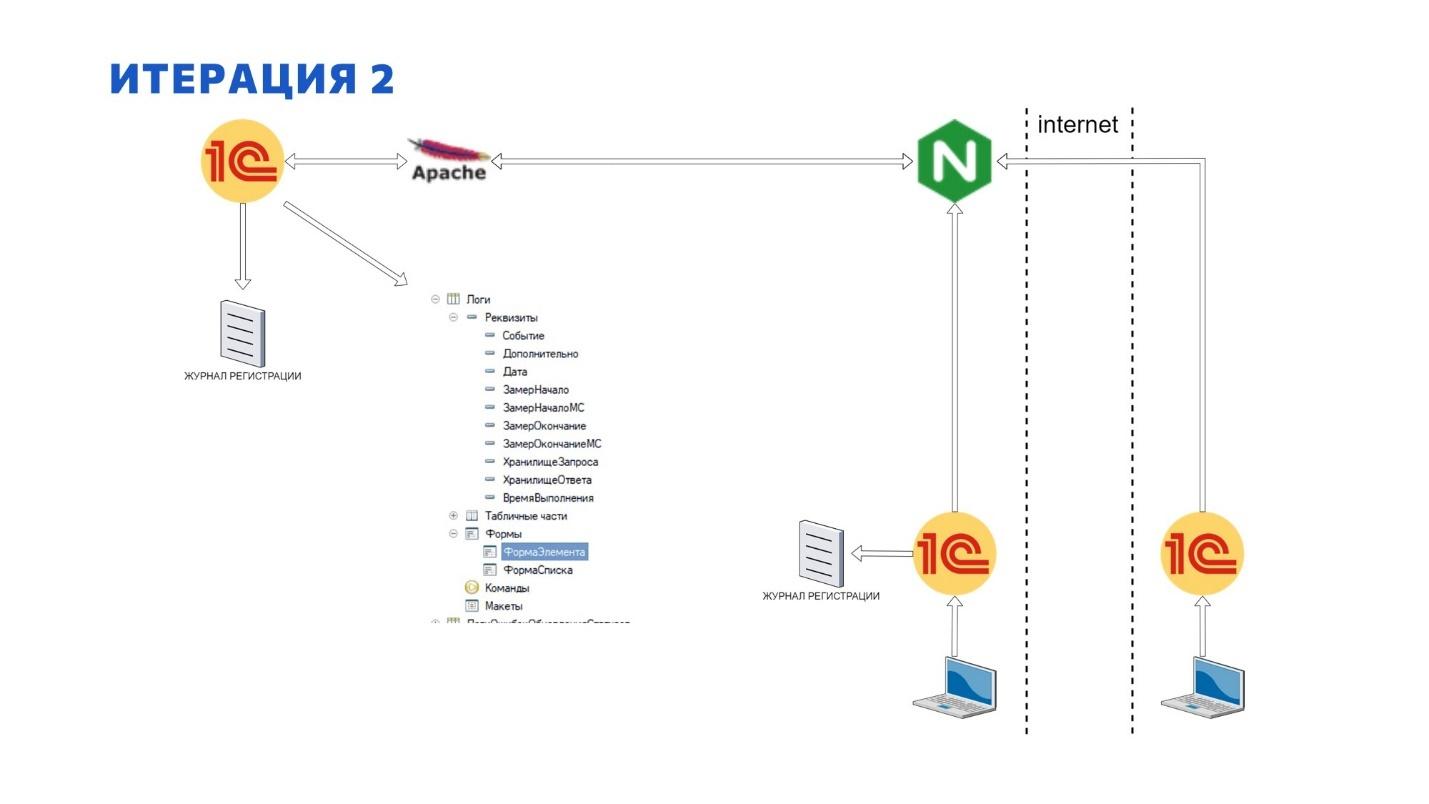
Слона надо есть по частям, гласит одна поговорка. И наевшись EnterpriseData целиком, мы ушли в сторону классического REST API. При этом не забыли и о логах, конечно.
Причем нам в тот момент не понравилась работа с типовым механизмом логирования, с журналом регистрации, и мы захотели записывать все логи внутрь базы.
Мне кажется, такое решение мы приняли из-за негативного опыта логирования через EnterpriseData – решили в объектную модель попихаться.
Мы создали справочник «Логи», куда писали: запрос, параметры, моменты, ответ. Структура этого справочника как раз представлена на слайде.
Мы решили логировать все – каждый запрос сначала отправлялся в логи, и только потом начинал обрабатываться. Для оценки в логи попадали еще и ответы – до того, как быть отправленными на сторону источника запроса.
Причем на тесте это все показало достаточно хорошие показатели производительности – поскольку прикладной логики по записи данных не было, все проходило быстро. И с минимальными нагрузками этот механизм работал идеально.
И забыл упомянуть, что наш продукт работает в режиме разделения, когда каждому клиенту предоставляется своя область. По такому же принципу работает технология 1C: Fresh, БТС (Библиотека технологии сервиса).
Так вот логи, конечно же, уходили в область того же самого клиента. И со временем мы начали замечать тенденцию, что почему-то размеры бэкапа в области стали занимать все больше и больше места. А значит, они выполнялись дольше и увеличивали время недоступности области. Недоступность возникала из-за того, что в то время, когда мы это все использовали, сервис-менеджер, входящий в пакет Библиотеки технологии сервиса, еще блокировал область ночью для того, чтобы скачать оттуда бэкап.
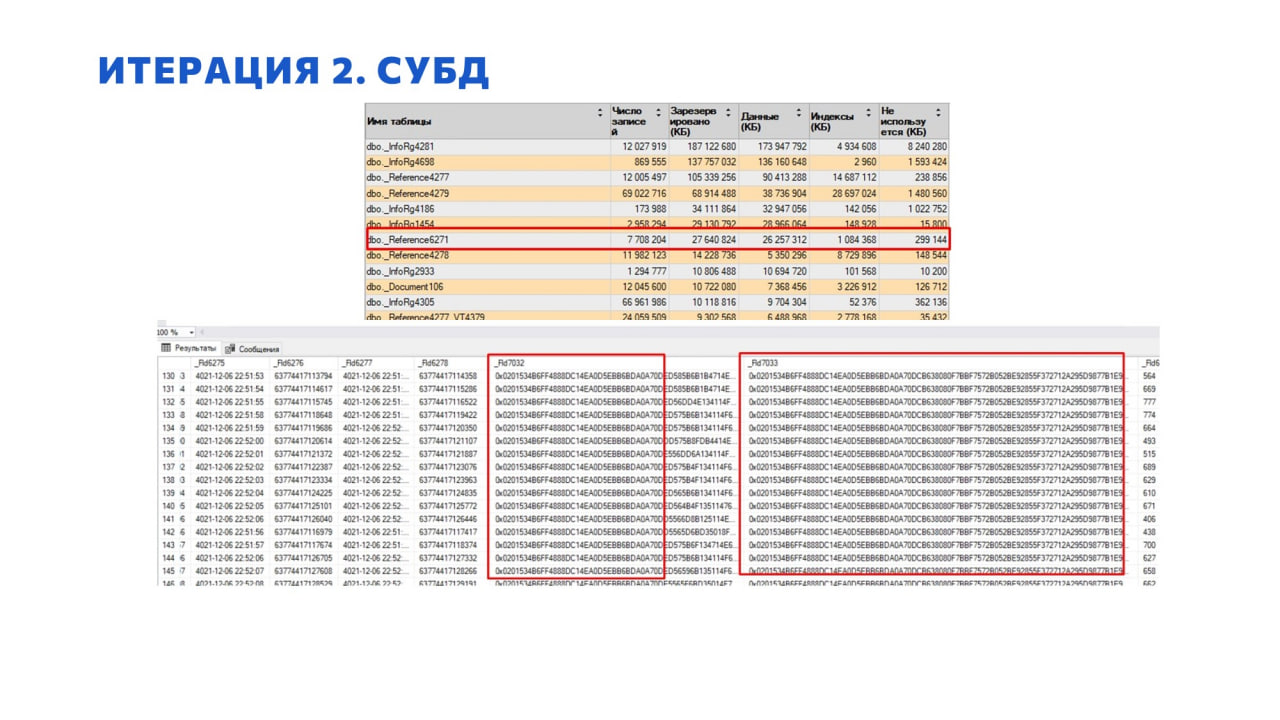
На слайде показано, как это выглядело на уровне СУБД. Это – отчет о занятости верхними таблицами дискового пространства.
Я здесь выделил таблицу, которая соответствовала справочнику «Логи» – она попала в топ-10 после первых трех месяцев эксплуатации. С учетом того, что продукт сам по себе ворочает электронными документами, это выглядело как минимум недальновидно.
Если оценивать саму структуру итоговых байтиков, можно заметить, насколько они друг другу очень сильно соответствуют.

Посмотрев на эту таблицу, мы задались вопросом – зачем нам столько логов? Может, не надо? Горшочек, пожалуйста, не вари!
Давайте опять оценим такой вариант хранения по критериям идеальных логов:
-
Логи должны занимать как можно меньше места. Ага, как же. Логи механизма синхронизации выскочили в топ таблиц по размеру. При том, что в них от бизнеса ничего нет. Но они находятся внутри базы клиента.
-
Процесс логирования должен минимально влиять на производительность продуктивной системы. Тоже нет. Сначала логи пишутся внутрь базы, на уровне запроса. Потом это все в рамках одного потока выполняется. И только после этого выполняется бизнес-логика. Еще и ответ тоже в том же потоке сначала помещается внутрь базы. Это явно влияет на производительность, и еще как влияет.
-
И информации в логах должно быть достаточно всегда для расследования причин возникновения. Зато с этим пунктом все ок. Логов более чем достаточно на каждый чих. На каждый чих создается элемент справочника. Там фиксируется вообще абсолютно все. Вся возможная телеметрия, которая пришла в голову разработчику, реализовавшему данный механизм.
Итерация 3. «Клиентище». Обмен через шину. Логи в ElasticSearch

И все бы было хорошо, но потом у нас появился клиентище. Опять же, не буду называть никаких имен, названий, но:
-
У клиента в сутки было порядка 50 000 операций.
-
Вследствие его лавинообразного роста все эти транзакции были в «Бухгалтерии предприятия». Причем, когда они к нам пришли, они были еще в «Бухгалтерии предприятия ПРОФ», и размеры базы этого клиента вследствие его роста были в пределах 1 ТБ. 1 ТБ для «Бухгалтерии» – это много.
-
Клиент был очень заинтересован в актуальном состоянии статусов обмена его документов с контрагентами по ЭДО – на тот момент это было чуть ли не единственным способом обмениваться с контрагентами юридически значимыми документами.
А наш сервис не справлялся с возросшей нагрузкой. Да и база нашего сервиса начала пухнуть фактически не по дням, а буквально за пару часов она могла прирасти гигов на 50.
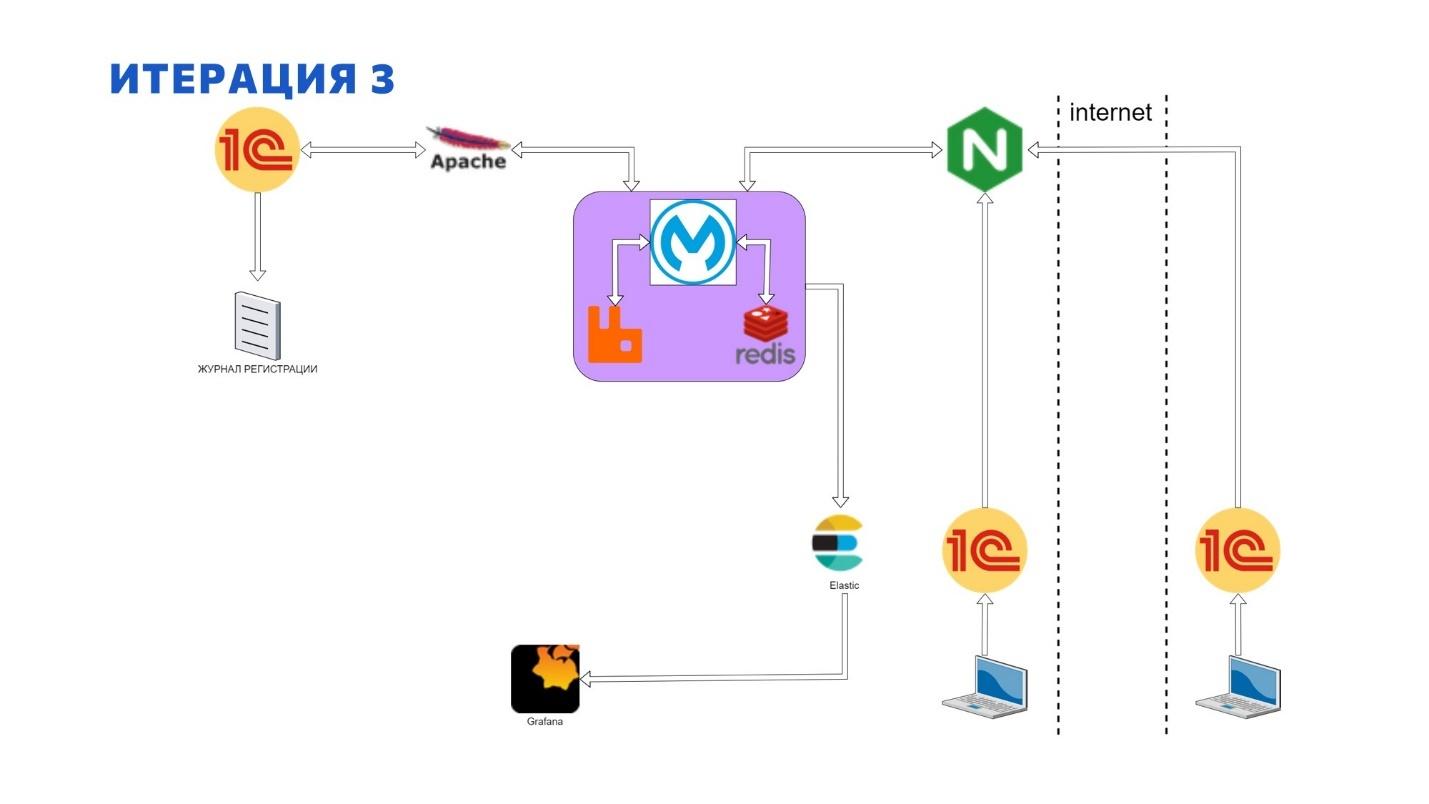
Третья итерация по работе с логами проходила в очень сжатые сроки. Фактически у нас была всего пара недель на решение проблем производительности нашего продукта в интеграционной плоскости.
Конечно, еще надо было оставить и запас прочности на будущее.
И мы пошли по проторенной ранее дорожке и для начала реализовали асинхронное взаимодействие на базе Mule ESB, Redis, RabbitMQ. Механизм был построен следующим образом:
-
Клиент отправляет запрос в Шину Mule ESB, проверяя, есть ли какая-то новая информация для него.
-
Шина Mule ESB генерирует уникальный идентификатор на сообщение, возвращает его клиенту, а сообщение кладет в RabbitMQ.
-
Клиент у себя сохраняет этот идентификатор.
-
А в другом потоке Шина Mule ESB вычитывает сообщение из того же RabbitMQ, идет в продукт, получает информацию о том, что нового для данного клиента есть.
-
Там простой план обмена, в котором регистрируются изменения. А результатом работы будет непосредственно номер сообщения, который там присваивается. И количество зарегистрированных объектов для пагинации и управления количеством потоков для итоговой загрузки.
-
И когда это все возвращается на Шину Mule ESB, оно помещается в Redis с точки зрения горячего кэша. Но уже с тем же самым идентификатором запроса, который был ранее отправлен клиенту.
-
Клиент через некоторое время обращается к Шине Mule ESB и спрашивает – что там есть с моим идентификатором.
-
И Шина Mule ESB уже обращается не к базе 1С, а идет в горячий кэш, где эти данные по данному идентификатору уже хранятся. И возвращает его клиенту.
-
А на клиентской стороне реализована многопоточная схема загрузки итоговых данных, которая в зависимости от количества документов или атомарных сущностей в сервисе разбивает это на определенное количество потоков и многопоточно это себе забирает.
При решении проблемы производительности механизма логирования мы пошли на небольшую авантюру, поэтому логи у нас собираются по такому же сценарию, только в еще одном изолированном потоке на Шине Mule ESB.
-
Каждый запрос по факту уже имеет свой идентификатор, а Шина Mule ESB просто отправляет копию запроса в асинхронном потоке в отдельную очередь в RabbitMQ, который потом вкладывается в систему хранения логов.
-
А уже система визуализации позволяет это все свести по идентификатору, реализуя тем самым возможность прослеживания всего запроса при прохождении через все системы от момента входа в интернет до момента получения результата.
На слайде я попытался представить, как строятся потоки:
Как видно, Шине Mule ESB отводится центральная оркестровочная роль в данной архитектуре – в парадигме ESB, централизованного управления и централизованной интеграции.
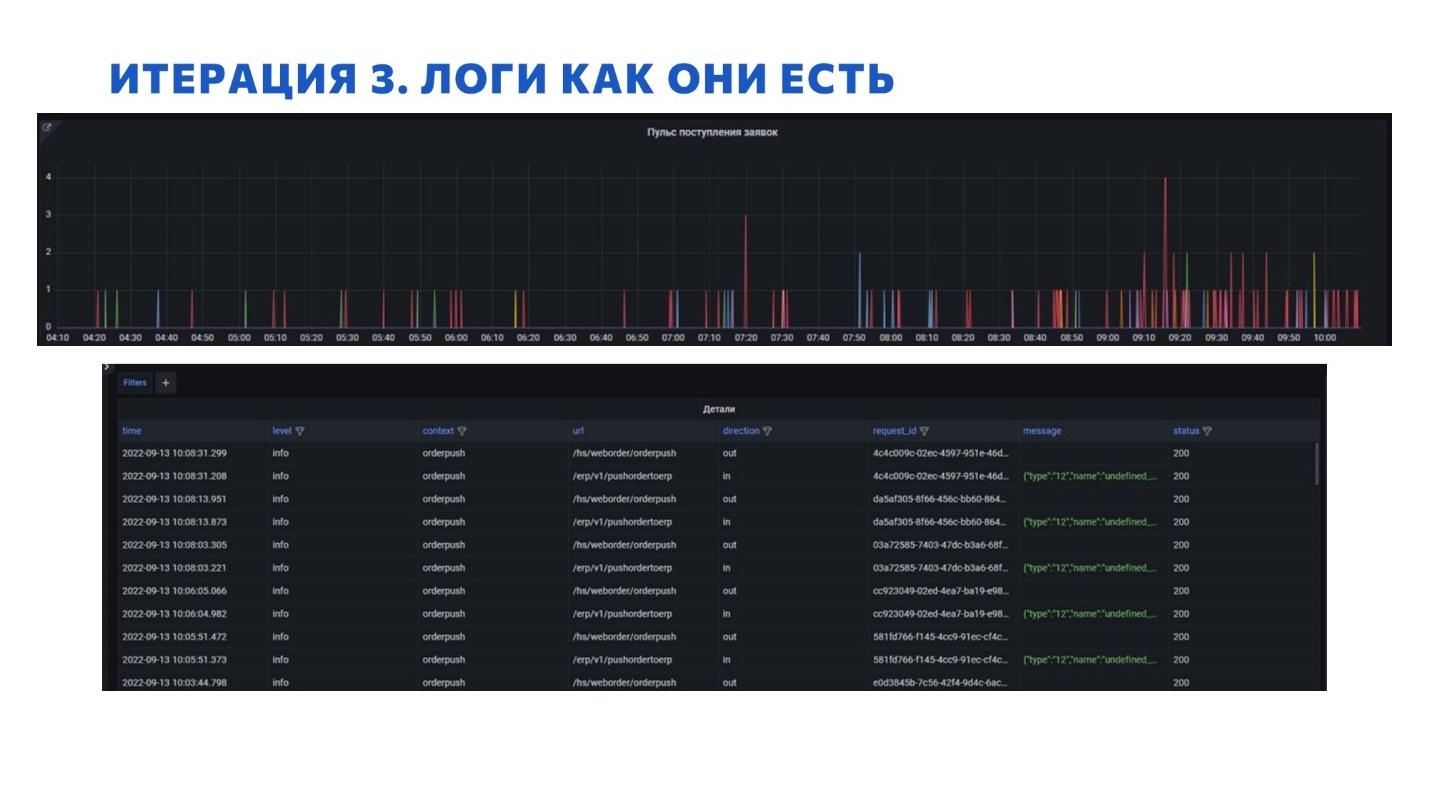
Когда у нас появился этот «клиентище», мы начали использовать в качестве системы логирования ElasticSearch, который из коробки позволяет нам использовать данные логи в связке с полнотекстом.
Визуализируем мы это все в Grafana – это идеальный инструмент для визуализации из разных источников. Самое крутое то, что можно все это свести из разных источников в рамках одного дашборда и показывать это все целиком.
Как раз на слайде и показаны:
-
пульс заявок, которые к нам падают;
-
в них можно провалиться и посмотреть детали – вход, выход, на какие URL-ы падали, какие детали есть, какие статусы получали, с какими идентификаторами и все такое.

Подведу итог третьей итерации с точки зрения логирования:
-
Мы уже говорили, что логи должны занимать как можно меньше места. Место не резиновое. А ElasticSearch в нашем концепте – тот еще проглот, поскольку ему приходится чуть ли не по буквам разбивать те данные, которые могут быть использованы для полнотекста. Но раз тут целей несколько, откровенно можно и смириться. В крайнем случае всегда можно за один-два дня перенаправить эти логи из ElasticSearch в ClickHouse, и они будут занимать фактически ничего. Поэтому я бы дал этому пункту плюс-минус, хотя я допускаю, что это – условно «натягивание совы на глобус».
-
Процесс логирования должен минимально влиять на производительность продуктивной системы. Да он вообще не влияет, так как логирование происходит вообще не в системе, а до нее. И влияния никакого – система будет работать самостоятельно, и процесс создания записи каких-то логов вообще не влияет никак на продуктив.
-
Ну и информации в логах должно быть достаточно всегда для расследования причин. Да, мы снимаем максимальный уровень логирования. Да, мы храним его месяц, потом удаляем. Да, мы храним это все в ElasticSearch. Но этого достаточно для того, чтобы расследовать любую проблему, возникающую в сервисе. Будь то проблема взаимоблокировок или недоступности сервиса по причине резко возросшей нагрузки.
Логируй это
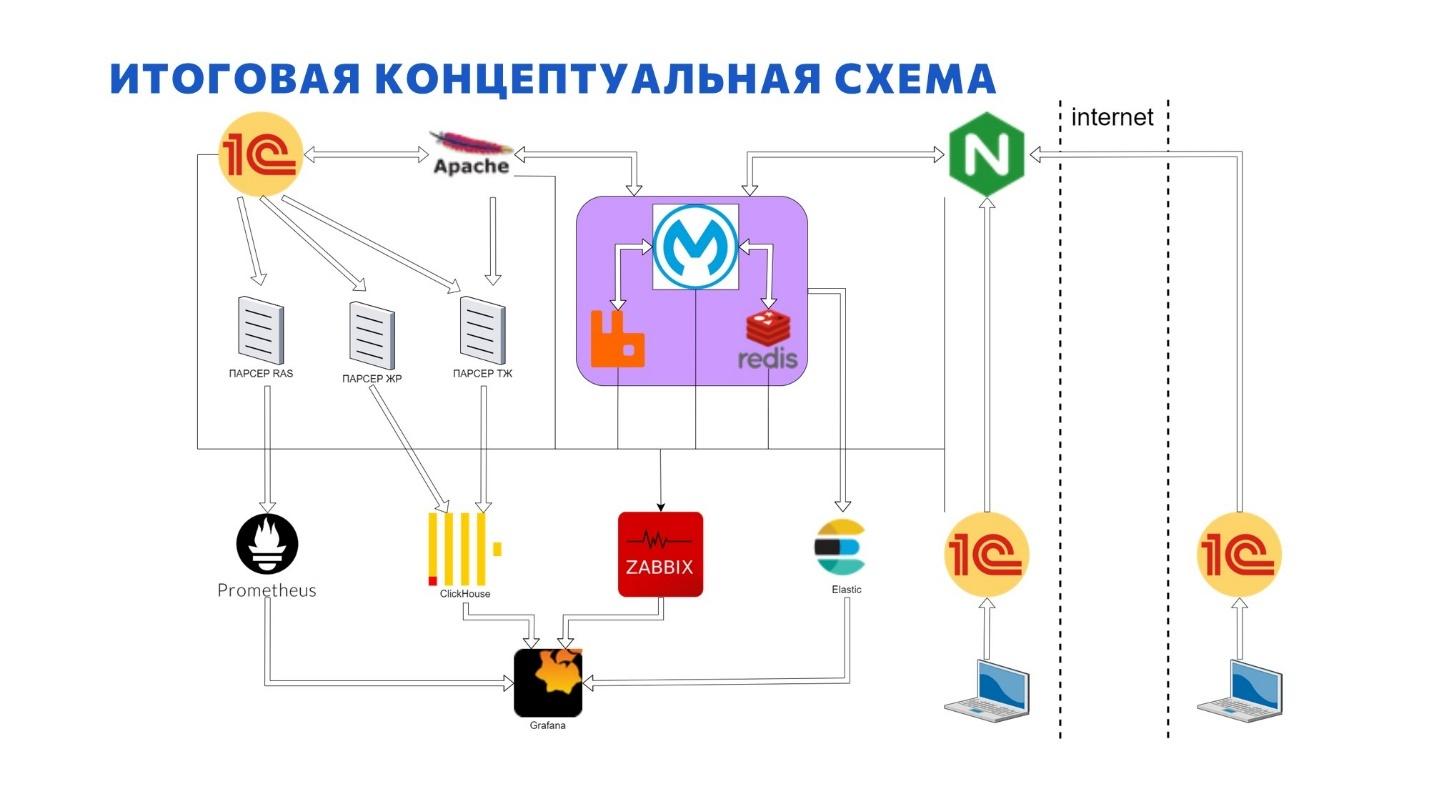
Но это даже еще не конец. Мы логируем вообще все, что можно.
На слайде – принципиальная схема логов в рамках нашей инфраструктуры.
-
В рамках шины собираем логи определенных сервисов.
-
Плюс мы еще собираем 1С-ные технологические журналы, причем не только с серверов 1С, но даже с Apache, где опубликованы базы.
-
Все разобранные данные мы храним внутри ClickHouse. Журнал регистрации отдельных критических баз мы тоже парсим отправляем в тот же ClickHouse.
-
Все сервера 1С мы мониторим внутри через RAS и результаты помещаются в Prometheus. Там в Prometheus крутится еще что-то не 1С-ное, админы для себя тоже что-то делали.
-
Сейчас поставили новую Kibana для ElasticSearch. И там из коробки можно прям настраивать Logstash, чтобы забирать классические логи Apache, NGINX. Там прям все по шагам берешь и далее, далее, далее. Кроме этого, Kibana позволяет настроить cron, который будет самостоятельно забирать логи из NGINX с Apache и засовывать их в ElasticSearch. Все, что типовое, все уже давно забирается.
-
Плюс на каждом сервере админами еще установлен Zabbix-агент, который собирает данные по загрузке операционной системы, дисковым очередям, занятости оперативной памяти и всему остальному. Все это мы тоже визуализируем в Grafana.
По итогу у нас получается многоцелевая система сбора логов, которая собирает логи вообще отовсюду. Собирает, аккумулирует, визуализирует и позволяет с ними работать.
Не изобретайте «велосипеды». Чтобы найти идеальное решение – оглянитесь вокруг
В очередной раз призываю всех, кто занимается интеграциями – оглянитесь вокруг. Весь спектр программного обеспечения уже используется у вас в компании с высокой долей вероятности.
-
Возьмем тот же Redis, который используется в standalone GitLab – если у вас есть GitLab, то у вас по-любому есть Redis.
-
ElasticSearch, как и PostgreSQL в базовом варианте, идут вместе с тем же самым SonarQube – если вы занимаетесь статанализом, у вас по-любому есть уже ElasticSearch и, скорее всего, PostgreSQL.
-
Zabbix тоже, если что, работает на базе PostgreSQL.
-
RabbitMQ поднимается вообще за 5 минут и может работать годами.
-
Шина Mule ESB тоже поднимается за пару часов и настраивается в IDE, очень похожей на EDT (тоже на базе Eclipse). Но она работает и работает нормально.
У любой задачи или проблемы всегда существует целый веер решений. От откровенно плохих до оптимальных. И почти у каждой задачи существует идеальное решение. В части интеграции оно существует почти всегда.
С каждым днем количество сфер, где применяется система на базе 1C, растет. Это значит, растет и количество интеграций, которые нам необходимо делать.
Прежде чем браться за большую задачу интеграции, оцените, что уже есть. И как оно хотя бы устроено. Это с высокой долей вероятности избавит вас от изобретения собственных велосипедов, которые не всегда ездят в правильном направлении.
Все теоретические материалы, которые помогут вам построить аналогичную систему логирования, собраны по ссылкам:
-
ссылка на скачивание MULE ESB (kernel)
-
ссылка на скачивание Anypoint Studio
-
доклад All inclusive или как «ослики, кролики и редиски» уживаются вместе с 1С
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт