


















{kind=link}
Смысл моей реализации – выполнение структурных изменений в базе SQL средствами самого SQL сервера с последующей заменой файлов 1cv7.md и 1cv7.dds в рабочей базе. Причем так, чтобы 1С не «догадалась», что эти изменения сделала не она сама.
Опытным путем можно проверить, что, например, изменение интерфейсов, прав, перечислений – не являются, по сути, структурными изменениями. Поэтому в данном случае достаточно просто подменить 1cv7.md.
Совсем по другому дело обстоит со справочниками, документами, регистрами и т.п.
Предупреждение: все алгоритмы проверяйте на тестовых базах и не забывайте про бэкап.
Помните: drop table и truncate table выполняются очень быстро 
Все скрипты приведены для MS SQL версии 2005 и выше. Для версии 2000 будут некоторые отличия в синтаксисе.
Итак, начнем. Будем двигаться от простого к сложному.
После каждого шага Вы можете подменять файлы md и dds в базе Тест и проверять работоспособность.
Для начала создадим самую простую конфигурацию (на sql сервере назовем ее Test). Это будет «рабочая база». Заполним ее немного данными.
Выгрузку конфигурации до изменений и после всех изменений, при желании, можно скачать в приложенном файле.
Через выгрузку-загрузку (для быстроты) создадим еще одну базу (на sql сервере назовем ее Test2). Это будет «копия». Причем копию при реальной работе можно и нужно делать без данных: т.е. просто скопировать 1cv7.md в пустую папку и запустить конфигуратор. Так изменения будут сохранятся гораздо быстрее.
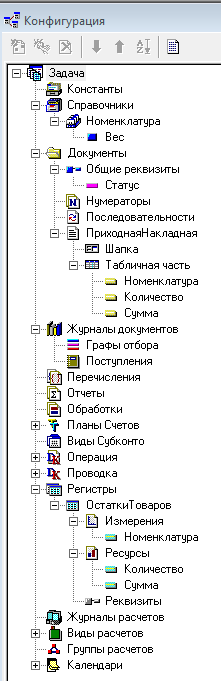
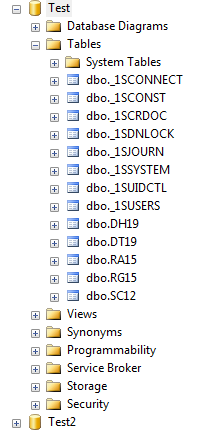
Теперь наши изменения: в конфигураторе изменения вносим в базе Тест2, скрипты выполняем в контексте базы Тест.
1. Добавление признака «Отбор для реквизита» для реквизита «Вес» справочника Номенклатура.
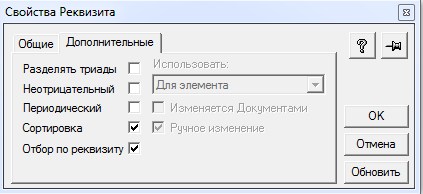
В зависимости от наличия владельца и/или родителя в этом случае могут быть созданы 1 или 2 индекса. В нашем случае создался один индекс «VI14» с полями «Вес», «Наименование» и «row_id».
Сравнение файлов dds до и после изменений:
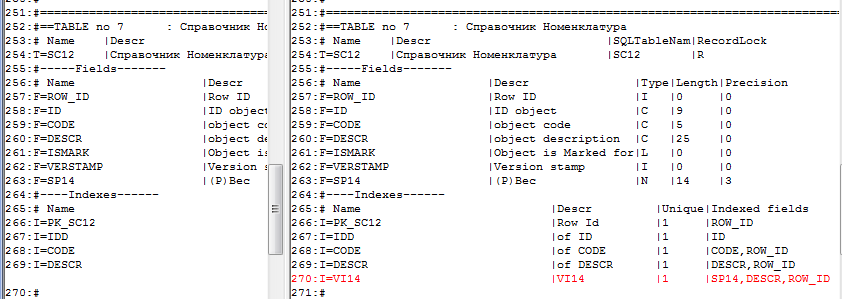
Задача самая простая: создать такой же индекс в рабочей базе. Предварительно проверяем его существование и удаляем, если он есть.
В этом, и некоторых последующих случаях, можно попросить SSMS сделать скрипт за нас. В нем будет много относительно лишнего кода – я постараюсь лишнее удалять, чтобы не путать.
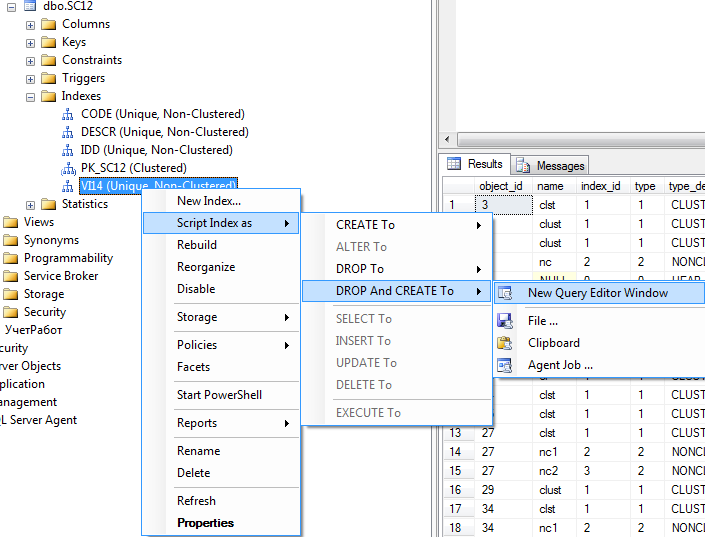
Текст скрипта:
USE Test
GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[SC12]') AND name = N'VI14')
DROP INDEX [VI14] ON [dbo].[SC12]
GO
CREATE UNIQUE NONCLUSTERED INDEX [VI14] ON [dbo].[SC12] ([SP14] ASC, [DESCR] ASC, [ROW_ID] ASC)
2. Добавление колонки «Поставщик» (Строка (50)) в справочник Номенклатура.
Здесь мы рассматриваем добавление колонки в существующий справочник, в котором уже есть данные.
Основной нюанс здесь в том, что 1С 7.7 не допускает хранение NULL в колонках таблицы. Поэтому создавая колонку, необходимо указать дефолтовое значение для добавляемой колонки.
В нашем случае это будет пустая строка: ‘’. Если бы тип данных был «Число», то пустое значение было бы 0.
У агрегатных объектов, например, если бы колонка была типа «Справочник.Контрагенты» - пустое значение было бы ‘ 0 ’, если просто «Справочник» - то ‘ 0 0 ’ и т.д.
Сохраним изменения в базе Тест2:
Посмотрим отличия в DDS:
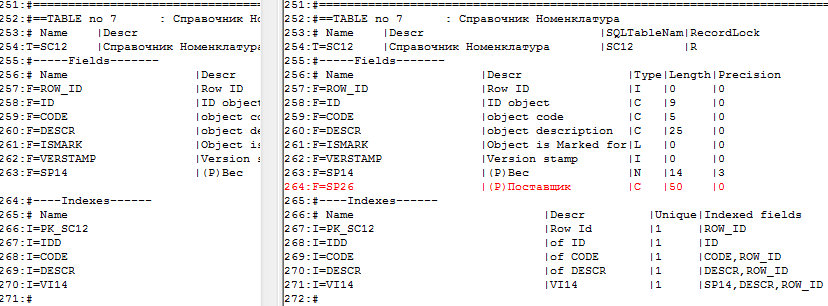
Дам некоторые пояснения по скрипту. В MS SQL указание значения по умолчанию – это создание объекта constraint в таблице.
Мой совет: чтобы данный скрипт можно было выполнить несколько раз в одной базе (например, в случае какого-либо сбоя) лучше давать констрейтантам явные имена. Если написать просто:
alter table SC12 add sp26 char(50) not null default ''
то констрейнт будет иметь сгенерированное имя, причем при каждом удалении и создании колонки имя констрейнта будет меняться.
Перед удалением колонки нужно удалять все объекты, в которых данная колонка задействована (кроме таблиц конечно), в т.ч. констрейнты (вот здесь и понадобится имя), индексы и т.п.
В нашем случае индексов по колонке нет, поэтому удаляем констрейнт, затем саму колонку (если они есть) и создаем новую колонку нужного типа.
Текст скрипта:
use Test
go
if exists(select 1 from sys.objects where name = 'df_sc12_sp26' AND parent_object_id = OBJECT_ID('dbo.SC12'))
alter table SC12 drop constraint df_sc12_sp26
go
if exists (select 1 from sys.columns where name = 'sp26' AND object_id = OBJECT_ID('dbo.SC12'))
alter table SC12 drop column sp26
go
alter table SC12 add sp26 char(50) not null constraint df_sc12_sp26 default ''
3. Изменение типа колонки «Поставщик» справочника Номенклатура
При изменении типа колонки, например изменении длины поля типа «строка», или изменение разрядности «числа», можно воспользоваться скриптом, приведенным ниже.
Поменяем длину поля Поставщик с 50 на 10 символов.
Обратите внимание: если в таблице уже есть строки больше 10 символов – преобразование на SQL из 50 в 10 не будет выполнено:
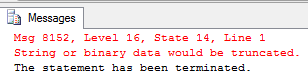
То же произойдет, если попытаться преобразовать колонку типа «Строка» в «Число» при наличии записей, которые не приводятся безусловно к типу число:
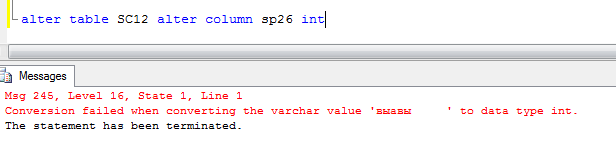
Если какая-то колонка не используется и Вы хотите задействовать ее под новые данные, то ее предварительно нужно удалить и создать новую с тем же идентификатором и в том же порядковом месте. Это будет рассматриваться при описании документов в следующей части статьи.
В скрипте проверяем наличие колонки и меняем тип.
Текст скрипта:
use Test
go
if exists (select 1 from sys.columns where name = 'sp26' AND object_id = OBJECT_ID('dbo.SC12'))
alter table SC12 alter column sp26 char(10) not null
go
4. Добавление справочника «Контрагенты»
И последний на сегодня пример: добавление справочника в конфигурацию. Добавляем справочник Контрагенты с одним реквизитом «ИНН».
Изменений в DDS гораздо больше:
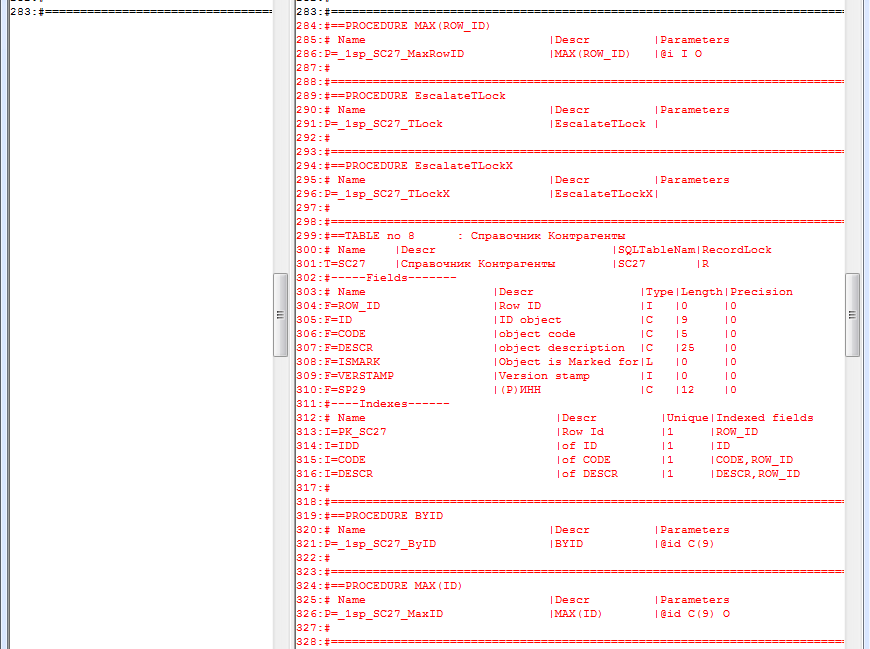
Здесь помимо создания самой таблицы в SQL, необходимо создать соответствующие индексы и процедуры.
В общем случае, достаточно создать только таблицу, подменить md и запустить базу монопольно – 1С остальное сделает сама. Но наши цели: 1. Понимание процесса; 2. Возможность запуска без монопольного режима.
При создании скриптов (в т.ч. получения текста сгенерированных процедур) удобно использовать функции SSMS, как это описано в шаге 1.
По самому скрипту: как обычно – проверяем наличие объекта, если есть удаляем, создаем объект. Проверку наличия индексов не проверяем, т.к. при удалении таблицы – индексы также удаляются.
Текст скрипта:
use Test
go
--Таблицы
if exists (select 1 from sys.objects where object_id = OBJECT_ID('dbo.SC27'))
drop table dbo.sc27
go
create table dbo.SC27(
[ROW_ID] [int] IDENTITY(1,1) NOT NULL,
[ID] [char](9) NOT NULL,
[CODE] [char](5) NOT NULL,
[DESCR] [char](25) NOT NULL,
[ISMARK] [bit] NOT NULL,
[VERSTAMP] [int] NOT NULL,
[SP29] [char](12) NOT NULL,
constraint [PK_SC27] primary key clustered ([ROW_ID] asc)
)
go
--Индексы
create unique nonclustered index CODE on dbo.SC27 (CODE ASC, ROW_ID ASC)
go
create unique nonclustered index DESCR on dbo.SC27 (DESCR ASC, ROW_ID ASC)
go
create unique nonclustered index IDD on dbo.SC27 (ID ASC)
go
--Процедуры
if exists (select 1 from sys.objects where object_id = OBJECT_ID('dbo._1sp_SC27_ByID'))
drop procedure [dbo].[_1sp_SC27_ByID]
go
create procedure dbo._1sp_SC27_ByID (@id CHAR(9)) AS
select * from SC27 with (nolock) where ID=@id
go
if exists (select 1 from sys.objects where object_id = OBJECT_ID('dbo._1sp_SC27_MaxID'))
drop procedure dbo._1sp_SC27_MaxID
go
create procedure dbo._1sp_SC27_MaxID (@id CHAR(9) OUTPUT) AS
set nocount on select @id=MAX(ID) from SC27 with (nolock) if @id is null select @id=' '
go
if exists (select 1 from sys.objects where object_id = OBJECT_ID('dbo._1sp_SC27_MaxRowID'))
drop procedure dbo._1sp_SC27_MaxRowID
go
create procedure dbo._1sp_SC27_MaxRowID (@i int OUTPUT) AS
set nocount on select @i=MAX(ROW_ID) from SC27 with (nolock) if @i is null select @i=0
go
if exists (select 1 from sys.objects where object_id = OBJECT_ID('dbo._1sp_SC27_TLock'))
drop procedure dbo._1sp_SC27_TLock
go
create procedure dbo._1sp_SC27_TLock AS
set nocount on declare @i int select @i=1 from SC27 with (tablock, holdlock) where 0=1
go
if exists (select 1 from sys.objects where object_id = OBJECT_ID('dbo._1sp_SC27_TLockX'))
drop procedure dbo._1sp_SC27_TLockX
go
create procedure dbo._1sp_SC27_TLockX AS
set nocount on declare @i int select @i=1 from SC27 with (tablockx, holdlock) where 0=1
go
Вступайте в нашу телеграмм-группу Инфостарт