Меня зовут Валерий Дыков, я расскажу о том, как можно разрабатывать для 1С:ERP с использованием Git и расширений, практически не используя EDT. Это продолжение доклада с конференции Infostart Event 2021 Post-Apocalypse – расскажу, что изменилось за 2021-2022 год.
Я уже давно занимаюсь 1С – наверное, лет 20. У меня был собственный франчайзи, я работал в фирме «1С» и уже более 10 лет – в компании «Первый БИТ», офис Савеловский (он же БИТ.ERP).
Несколько слов про наш офис, чтобы было понятно, как мы работаем с Git, и почему именно так.
-
Офис у нас чисто проектный – мы делаем свои коробочные продукты, занимаемся проектами по ERP и еще немного промышленной автоматизацией.
-
Мы все удаленщики – уже 10 лет вся наша команда работает на удаленке.
-
Мы любим экспериментировать с разными интересными технологиями. И клиентов к себе на проекты выбираем тоже тех, которые любят разные интересные современные технологии. Исходя из этого, мы выбираем и методы разработки.
-
Если вам интересно, как у нас построено автоматическое тестирование, можете посмотреть видеозапись с митапа Инфостарта – там я рассказывал про тестирование.
А сейчас я продолжу тему доклада 2021 года про разработку.

В подразделении БИТ.ERP есть несколько проектных команд и у каждой из них своя небольшая специфика.
-
У каждой проектной команды свой репозиторий, где лежит свой код и свои тесты.
-
У каждой команды свой набор эталонных баз, на которых команда разрабатывает и тестирует.
-
Есть незначительные отличия в процессе разработки.
При этом у всех команд есть общие подходы и общие инструменты для работы:
-
Все разработчики во всех наших командах работают на своих виртуальных машинах в нашем облаке. Сейчас это в основном Linux, раньше был Windows.
-
Весь исходный код мы храним в Git, используем GitHub. Хранилище сейчас не используем.
-
Для работы с Git мы используем два подхода – это заявки в Service Desk и прямая работа с Git.
-
Разработка по задачам ведется в отдельных ветках – в ветку master принимаются только протестированные изменения.
-
Для тестирования используем Vanessa Automation.
-
Каждый разработчик в любой момент времени может через заявку запустить автотесты – они выполняются в фоне и никак не отвлекают разработчика. Результаты автотестов обязательно прикладываются ко всем пул-реквестам.
-
В результате мы в любой момент времени имеем в ветке master только протестированный релиз и можем отдавать заказчику релизы из ветки master максимально часто, в идеале каждый день – в этом как раз и заключается цель всех этих наших доработок и автоматизации.

В докладе мы пошагово рассмотрим типичный рабочий день нашего разработчика:
-
День начинается с подключения к рабочему месту.
-
Потом разработчик выбирает задачу из трекера – раньше он это делал в Jira, сейчас в Яндекс.Трекере. И создает окружение для разработки на своей виртуальной машине.
-
Дальше вносит доработки – далее я расскажу про наши принципы внесения доработок.
-
Помещает изменения в Git.
-
Запускает тесты и убеждается, что все тесты зеленые.
-
Делает pull-request по задаче в ветку master.
В результате путь разработки от задачи до релиза составляет один день – сразу после попадания этого изменения в ветку master клиент может забрать его к себе на продуктив.
Шаг 1. Подключение к рабочему месту

Начнем с виртуального рабочего места, поскольку это важно для нашей автоматизации.
У нас есть возможность автоматического создания и пересоздания этих рабочих мест в любых количествах.
-
В качестве рабочих мест используются виртуальные машины на Linux. Мы создаем эти рабочие места программно – берем типовой образ Ubuntu и через Ansible ставим нужное программное обеспечение.
-
Состав установленных программ у всех сотрудников одинаковый – лучше мы поставим лишнее, чем не поставим что-то нужное, и потом придется это доставлять.
-
Создать или пересоздать рабочее место сотрудника можно в любой момент через заявку в Service Desk – нажали, и машинка создалась.
За счет того, что у разработчиков используются виртуальные машины, мы можем их глубоко интегрировать в нашу инфраструктуру.
-
Для внутренней автоматизации мы используем Jenkins – разворачиваем на каждой машине разработчика Jenkins-ноду, чтобы иметь возможность выполнять там свой код.
-
Все машины подключены к общему мониторингу/алертингу.
-
И все машины имеют доступ к общим ресурсам – таким, как клиент-серверные базы данных, необходимые для работы.
Единая для всех инфраструктура хороша тем, что возникает меньше вопросов к DevOps. Раз виртуальные машины у всех все одинаковые, то и проблемы у всех одинаковые, и ответы для всех одинаковые – DevOps можно держать гораздо меньшего размера.
Единственное, что у каждого из сотрудников уникально – это способ подключения к виртуальной машине. Это особенно актуально в последнее время при подключении сотрудников из Казахстана или Узбекистана – при стандартном подключении у них могли возникать проблемы.

Как мы обеспечиваем полностью программное развертывание?
-
Как правило, любой облачный провайдер предоставляет некий WEB API для работы с виртуальными машинами – через это WEB API мы можем программно создавать, удалять, добавлять новые машины.
-
Часто поверх этого WEB API можно использовать разные инструменты вроде Terraform – раньше мы пользовались Terraform.
Дальше мы устанавливаем необходимое ПО.
-
Как я сказал, мы используем Ansible. На Linux это вообще просто, но на Windows с помощью Ansible тоже можно необходимое ПО устанавливать.
-
Все пакеты мы ставим из локального репозитория – мы имеем локальное зеркало для всех программ, которые устанавливаем. Это полезно, потому что при установке из интернета могут возникать различные ошибки, когда что-то недоступно.
-
Ставим на виртуальные машины все нужные нам программы – диски стоят дешево, поэтому это несложно сделать.
-
При этом мы стараемся делать плейбуки максимально короткими, отделимыми друг от друга. Например, для установки каждой версии платформы у нас свой плейбук. И мы можем через Ansible централизованно доставлять свежую вышедшую версию платформы всем сотрудникам сразу на все их рабочие места.
На наших виртуальных машинках мы делаем для сотрудников в терминах Linux – два дисплея, в терминах Windows – два сеанса. Один – для человека, другой – для робота. Человек работает на одном дисплее, а Jenkins-нода – на другом дисплее или в другом сеансе.
-
В результате, когда Jenkins-нода запускает сеанс 1С или что-нибудь выгружает из конфигуратора, человек при своей работе этого не видит – для него это прозрачно.
-
При этом есть возможность через VNC подключиться к другому сеансу и посмотреть, что там делает Jenkins-нода.

По подключению к рабочему месту разработчика.
Раньше мы, как и многие, для подключения к своей корпоративной сети использовали VPN. А потом прочитали статью на Хабре и перешли к другой схеме – используем SSH с авторизацией по сертификатам.
Как это в целом работает?
-
Запускается SSH, он идет к нашему облачному провайдеру пользователей – мы, например, используем Okta.
-
Через OpenID Connect пользователь авторизуется, мы получаем ключик и дальше выписываем пользователю временный сертификат, по которому человек авторизуется через SSH. В статье подробно расписано, как это можно сделать.
-
Поскольку мы не публикуем напрямую в интернет IP-шники каждой машины, а пользуемся SSH-шлюзом, каждый пользователь подключается именно к своей машине, а не к общей сети.
-
И дальше внутри сети мы можем гибко управлять правами – к каким ресурсам внутри сети наши корпоративные пользователи имеют доступ.
Для подключения к рабочему столу мы используем xRDP:
-
Так как при подключении к SSH мы уже авторизовались, а на каждой виртуальной машине – один пользователь, дополнительной авторизации там не требуется.
-
Фактически мы сделали для пользователей один командный файл, который можно запустить, ввести логин-пароль и дальше через RDP-клиент работать на своей виртуальной машине.

На слайде я привел список ПО, которое мы ставим на машину – возможно, вам это будет полезно.
Шаг 2. Создания окружения для разработки

После того как наш сотрудник подключился к своей машинке, ему нужно начинать разрабатывать. Какие основные сущности или понятия при разработке мы используем?
У нас есть такая сущность как эталонные базы:
-
Набор эталонных баз – это полный набор баз, необходимых для разработки и тестирования на данном проекте.
-
Эталонные базы уже содержат данные – они могут быть набиты вручную, либо это могут быть какие-то обрезанные копии рабочих баз.
-
Главный смысл в том, что в этих базах уже выполнены все настройки – в них сразу можно тестировать свои доработки, ничего дополнительно не заполняя. Набор содержит все базы, которые нужны, и все необходимые данные в этих базах уже есть.
Исходный код конфигураций и расширений мы храним в репозитории.
-
Для репозиториев мы используем GitHub и код храним в формате EDT.
-
Для каждого проекта есть специальный yaml-файл, где мы описываем, какие именно расширения и какая конфигурация относятся к какой эталонной базе. Например, у заказчика есть основная база, нам нужно поставить туда два расширения и обновить конфигурацию. В этом yaml-файле описывается связь между эталонными базами и конфигурациями/расширениями.
У нас используется изолированное окружение, которое содержит:
-
Отдельную копию всех эталонных баз, обновленных из репозитория.
-
Копии всех вспомогательных сервисов, которые необходимы для работы этих баз. Например, если две базы нужно интегрировать между собой, и они обмениваются через RabbitMQ, в состав изолированного окружения еще входит отдельный vhost в RabbitMQ для их обмена.
Для тестирования разработанной функциональности мы пишем фичи и запускаем их на Vanessa Automation:
-
С помощью фич мы описываем BDD и интеграционные тесты на языке Gherkin.
-
Фичи у нас лежат в том же репозитории, где исходный код.

Расскажу подробнее про эталонные базы.
Для хранения эталонных баз мы используем Yandex object storage – это аналог S3 в Amazon.
-
Мы храним их в виде zip-архива с файловыми базами. На одном проекте у нас используется 6 баз, размер архива – 6 Гигабайт.
-
Чтобы получить эти базы на машину разработчика и, наоборот, измененные эталонные базы с машины разработчика загрузить назад в облако, нужно создать заявку в веб-интерфейсе Service Desk.
Предварительно мы в базах выполняем все настройки, чтобы каждый тест можно было выполнить независимо.
-
Например, у нас есть три теста «Заказ на эмиссию», «Печать марок» и «Отражение выпуска продукции». Мы могли бы выполнить эти тесты последовательно с одними и теми же марками, с одной и той же номенклатурой – они бы выполнились. Но это неудобно, потому что если нам нужно выполнить только второй тест или только третий, пришлось бы обязательно выполнять предварительные тесты.
-
Поэтому все эти три теста мы делаем с разными марками. А для этого предварительно вручную настраиваем эталонную базу – переводим эти марки в нужное состояние. В результате любой из этих тестов можно выполнить отдельно от других.
-
То же самое при ручном тестировании – это тоже полезно. Когда разработчик дорабатывает какую-то функциональность, он ищет соответствующую фичу и смотрит в ее описании: какие марки и какая номенклатура в ней используется. Поскольку в эталонной базе, которая у него скопирована, все эти исходные данные уже есть, он идет туда и руками тестит то, что ему нужно. Самому разработчику НСИ вводить не надо – никак готовиться не надо.
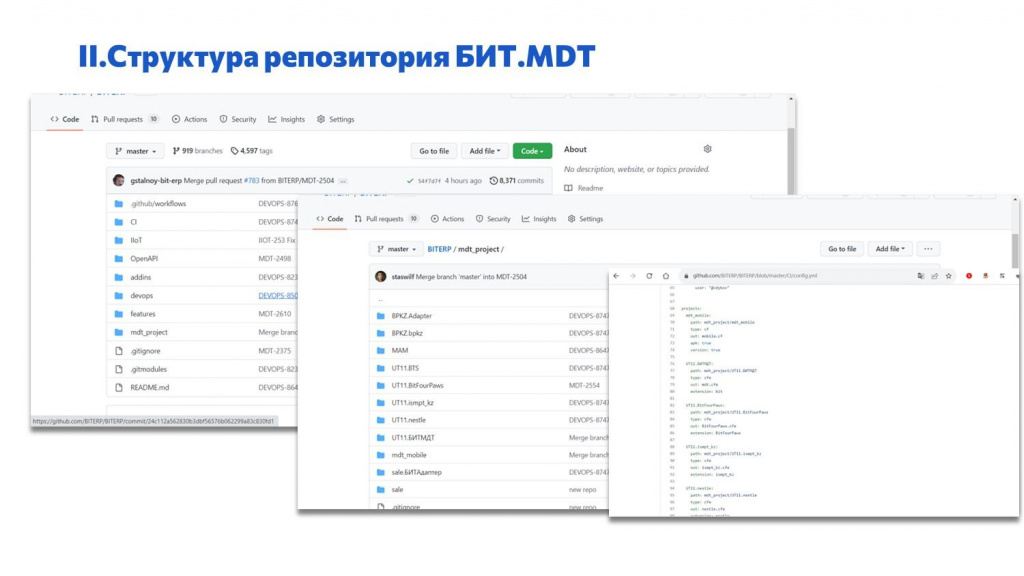
На слайде показана структура одного из репозиториев.
-
Здесь слева – общая структура. Обратите внимание, здесь много разных папочек, т.к. в репозитории лежит не только исходный код, но и внешние компоненты, фичи, CI-скрипты, скрипты для IIoT и т.д. Здесь весь исходный код, используемый на проекте – и 1С, и не 1С – все, что нужно.
-
Посередине – структура папки с 1С кодом. Тут куча каталогов – под все расширения и конфигурации, которые используются в проекте.
-
И справа – YAML-файл. В YAML-файле перечислены все конфигурации и расширения 1С, которые используются в проекте. И даны инструкции, как их собирать, на какие эталонные базы накатывать и так далее – вся структура проекта описана в виде YAML файла.

Про изолированное окружение.
Я уже сказал, что эталонные базы у нас лежат в S3 и там зафиксированы. А изолированное окружение – это отдельная копия эталонных баз, обновленная из Git, со всеми вспомогательными сервисами.
-
В результате мы получаем полностью независимое окружение, в котором можно разрабатывать, а также проверять любую функциональность и любые фичи.
-
В состав изолированного окружения для наших проектов входят нужные базы 1С, отдельный vhost для RabbitMQ и отдельные лицензии для разных наших продуктов.
-
Изолированное окружение у нас создается всегда, когда мы запускаем тесты. И разработчик может создать на своей машине любое количество этих изолированных окружений, чтобы параллельно работать над несколькими задачами – над каждой задачей в своем изолированном окружении.
Зачем нам нужно «Изолированное окружение»?
-
Мы хотели добиться повторяемости тестов. Чтобы утром тесты работали так же, как вечером, и у Вани работали так же, как у Пети. Чтобы это обеспечить, нужно все, что в тестах участвует, полностью изолировать от других тестов.
-
Приятный плюс от этого – мы можем создавать любое количество этих изолированных окружений, их количество ограничено только размером дисков.
Но есть ограничения:
-
Основное ограничение в том, что мы в основном ведем разработку и тестирование на файловых базах, потому что их проще изолировать. При этом остается возможность тестировать и в клиент-серверном режиме – такие базы для тестирования мы разворачиваем в общей сети.
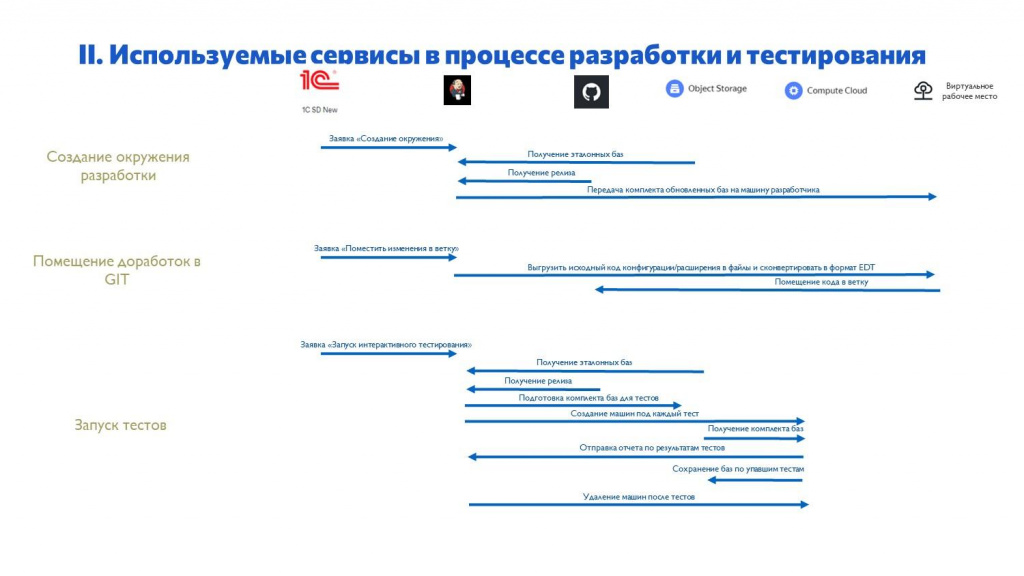
Немного про сервисы и про наши основные этапы разработки.
У нас используются три этапа. Они же дублируются в Service Desk через заявки.
-
Первая заявка – создание изолированного окружения разработки.
-
Дальше разработчик в нем разрабатывает, помещает доработки из него в Git – это тоже отдельная заявка.
-
И отдельная заявка запускает тесты.
На слайде перечислены сервисы, которые мы сейчас используем.
-
База 1С для Service Desk – наш Service Desk с веб-интерфейсом, откуда все запускается.
-
Jenkins – наша основная рабочая лошадка.
-
GitHub – мы там храним весь наш исходный код.
-
Yandex Object Storage – мы там храним эталонные базы.
-
Yandex Compute Cloud – подключаем виртуальные машины для тестирования.
-
Виртуальные рабочие места, на которых работают наши сотрудники, мы арендуем в Selectel.
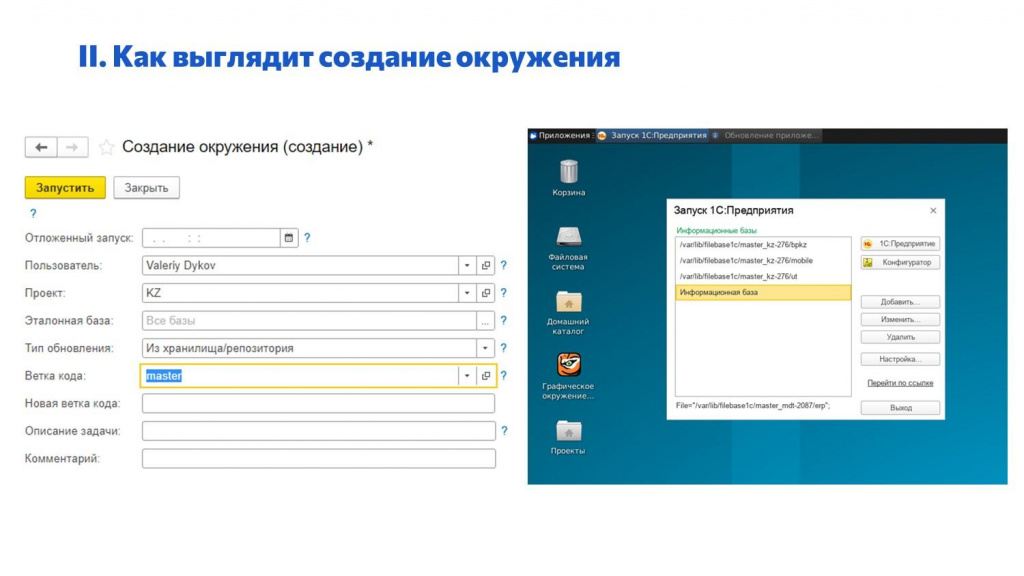
Вот так у нас выглядит заявка в Service Desk на создание окружения.
-
Указали проект.
-
Сказали, какие базы хотим дорабатывать.
-
Выбрали ветку, откуда хотим брать исходный код конфигурации и расширений для обновления.
-
Нажали кнопку и на рабочем месте сотрудника в списке баз появился набор баз по этой заявке – это скопированные эталонные базы, обновленные из той ветки, которую мы выбрали.
-
Дальше идем в конфигуратор и вносим нужные доработки в базу.
Шаг 3. Подходы к разработке

Расскажу, как у нас выглядят доработки типовых конфигураций:
-
Типовые конфигурации большие, и полная выгрузка-загрузка типовой конфигурации в исходные файлы может занимать много времени: для ERP, условно говоря – час.
-
У платформы есть возможность частичной выгрузки-загрузки, но она работает странно, не всегда и ненадежно.
-
Это и стало одним из основных препятствий к использованию EDT для доработки типовой конфигурации 1С:ERP.
Мы придумали несколько подходов, которые позволяют нам вообще не менять типовые конфигурации на ERP-шных проектах:
-
Это разработка в расширениях и использование «лысой» конфигурации – сейчас расскажу, что это такое.
-
И использование «типовых» расширений – мы сейчас на наших ERP-шных проектах типовую конфигурацию при разработке не меняем.

Первый прием – «лысая конфигурация».
-
Расширения сейчас пока не поддерживают добавление и изменение для всех объектов метаданных. Поддержку некоторых объектов метаданных в платформе 8.3.22 и 8.3.23 добавляют, но ERP пока еще в режиме совместимости с 8.3.16 (прим. ред. доклад от 6 октября 2022 года). Когда это дойдет до типовых – неизвестно, возможно, через три года.
-
Если мы все эти доработки будем вносить напрямую в ERP, то получим проблемы со скоростью разработки и обновляемостью.
В чем заключается подход?
-
Мы делаем отдельную чистую конфигурацию и делаем для нее XML-правила, которые можно выбрать в платформенном сравнении-объединении с типовой.
-
В эту «лысую» пустую конфигурацию мы добавляем:
-
свои новые объекты метаданных без реквизитов – это нужно, чтобы включить их в определяемые типы, которые в расширении мы пока менять не можем;
-
объекты, которые в расширении добавить нельзя – например, регламентные задания;
-
типовые объекты с реквизитами, содержащими определяемые типы, которые мы хотим расширить за счет своих объектов – для таких объектов в XML-файлике сравнения/объединения мы ставим режим «Объединять». В результате при сравнении/объединении с типовой состав типов будет объединен с типовым составом типов.
-
-
А весь код, формы и реквизиты мы уже добавляем в расширениях.
В результате, когда мы создаем изолированное окружение, наши скрипты автоматически накатывают эту лысую конфигурацию на типовую с использованием этого XML-файлика и дальше применяют расширение, и мы в расширении можем заимствовать объекты как из «лысой» конфигурации, так и из типовой.
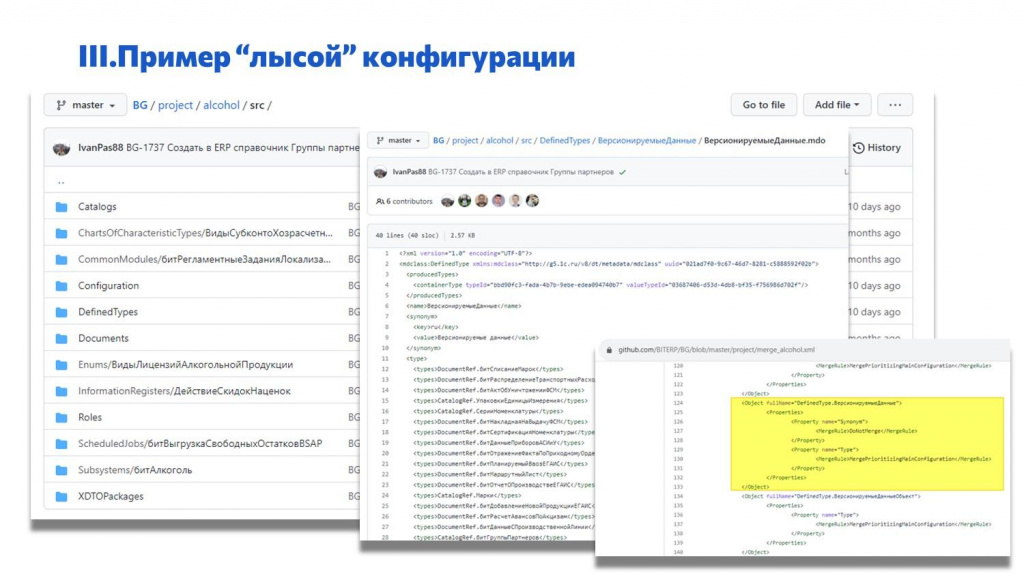
Конкретный пример – «лысая» конфигурация для проекта alcohol.
-
Мы в ней создали определяемый тип «ВерсионируемыеДанные» – он называется так же, как определяемый тип в типовой.
-
Добавили в этот определяемый тип свои объекты.
-
А в настроечном XML-файлике для сравнения-объединения указали, что этот определяемый тип нужно объединять с соответствующим объектом в типовой.
-
В результате, когда мы накатим эту конфигурацию на типовую, наши объекты добавятся в определяемый тип в типовой.

Следующий хитрый прием– это типовые расширения.
-
Мы одновременно ведем несколько проектов ERP, и у нас есть некая общая функциональность между разными проектами. Для этой общей функциональности мы делаем типовое расширение.
-
Плюс на каждом проекте делаем проектное расширение. И часто бывает, что в рамках проектного расширения нам нужно переопределить какие-то функции типового расширения.
Чтобы это сделать, мы используем подход, очень похожий на логику построения БСП:
-
В типовом расширении мы в рантайме проверяем, что в составе текущих общих модулей есть общий модуль с определенным названием – в данном случае, адаптер_ИнтеграцияПроектный. Если есть, то считаем, что в этом модуле, добавленном проектным расширением, переопределены методы данного текущего модуля.
-
Если нам нужно какие-то функции переопределить, добавляем модуль адаптер_ИнтеграцияПроектный в проектном расширении.
-
Если мы хотим переопределить бизнес-логику не с точностью до модуля, а с точностью до процедуры, добавляем в модуль адаптер_ИнтеграцияПроектный одну специально названную процедуру ПриОпределенииМодулейСПодписками, которая возвращает список методов, переопределенных в проектном расширении относительно типового.
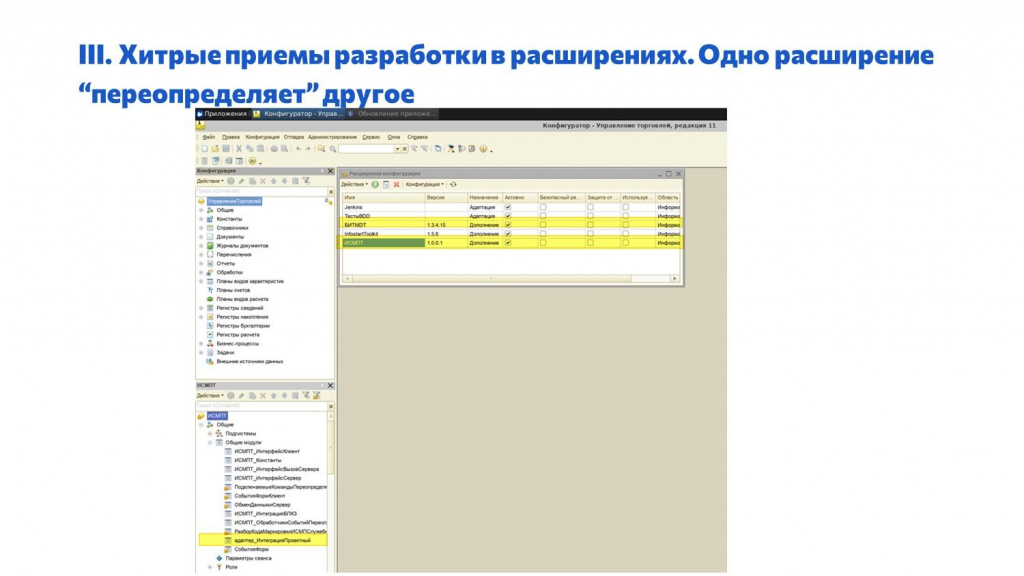
В конфигураторе это выглядит так.
-
внизу – проектное расширение ИСМПТ;
-
а вверху – типовое расширение БИТMDT.
В проектном расширении мы добавили модуль адаптер_ИнтеграцияПроектный, который переопределяет код из типового расширения.
Таким образом мы можем в проектных расширениях переопределять логику типовых расширений на каждом проекте.

Специальный слайд про EDT.
У нас сейчас есть два “геройских” сотрудника, которые полностью ведут разработку в EDT.
Поскольку использование двух подходов, о которых я рассказал, позволяет нам не менять типовую конфигурацию, обе главные проблемы использования EDT снимаются:
-
Поскольку мы не меняем типовую конфигурацию, не нужно выгружать и не загружать в EDT типовую ERP из исходных файлов, а загружать только расширение и маленькую конфигурацию. Выгрузка производится очень быстро, учитывая, что EDT позволяет одновременно работать в одном проекте с несколькими расширениями и несколькими конфигурациями.
-
Одновременно это решает и проблему медленной работы EDT.
Но большинство сотрудников все-таки пользуются конфигуратором.
Шаг 4. Помещение изменений в GIT
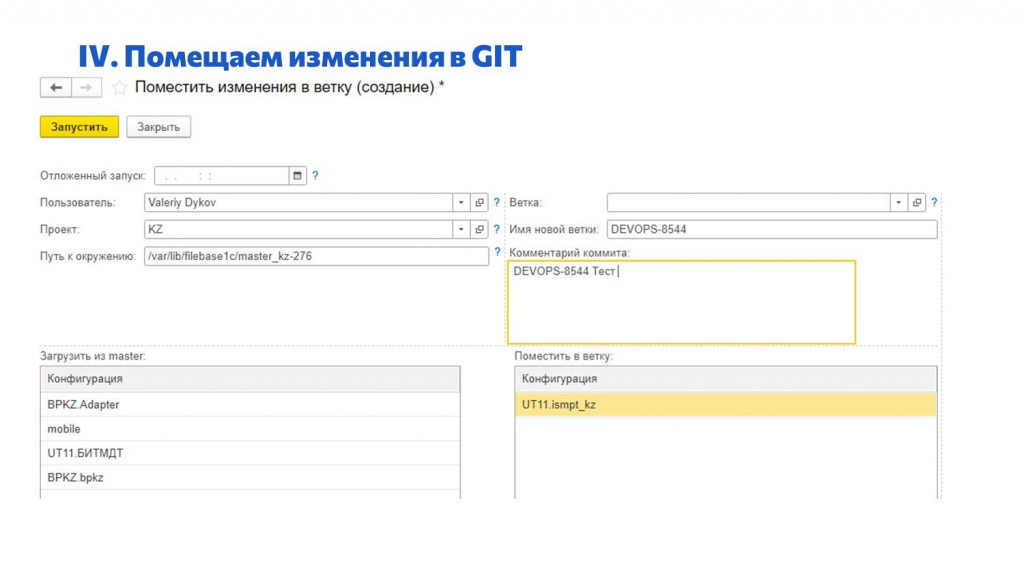
Когда мы в изолированном окружении внесли изменения в конфигуратор по задаче, дальше нам нужно закоммитить эти изменения в Git.
Есть разные способы.
Можно выгружать в исходники, конвертировать в EDT и командами в Bash загружать в Git.
Но для наших обычных сотрудников мы сделали заявку в Service Desk, которая делает все то же самое автоматически:
-
сотрудник говорит путь к папке, где лежит окружение;
-
какие конфигурации или расширения он менял;
-
в какую ветку нужно положить;
-
и с каким комментарием.
В большинстве случаев такой вариант подходит, всем понятен, и не надо ничего делать.
Физически в этот момент на отдельной Jenkins-ноде запускается код, который копирует базу, из копии делает выгрузку в исходный код, конвертирует в формат EDT и коммитит в Git. Ничего сложного.
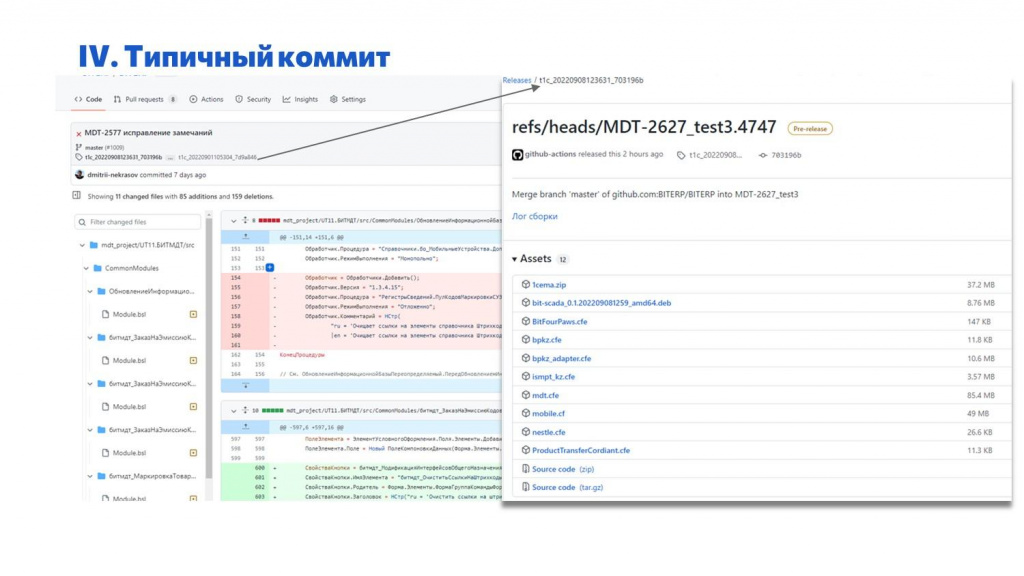
На слайде показано, как выглядит типичный коммит. Мы закоммитили код, на GitHub сразу видно, что получилось – в интерфейсе отображается дерево со структурой репозитория, очень удобно смотреть 1С-ные конфигурации.
По каждому коммиту мы, как правило, автоматически собираем релиз на GitHub Actions. Даже если это коммит в ветку, у нас собираются все CF, CFE, скрипты IIoT и прочее. Все, что относится к данному коммиту.
Это обратный процесс, после которого, если нам нужен свежий релиз, мы можем взять уже готовое – собирать дистрибутивы отдельно уже не нужно.
Шаг 5. Тестирование изменений
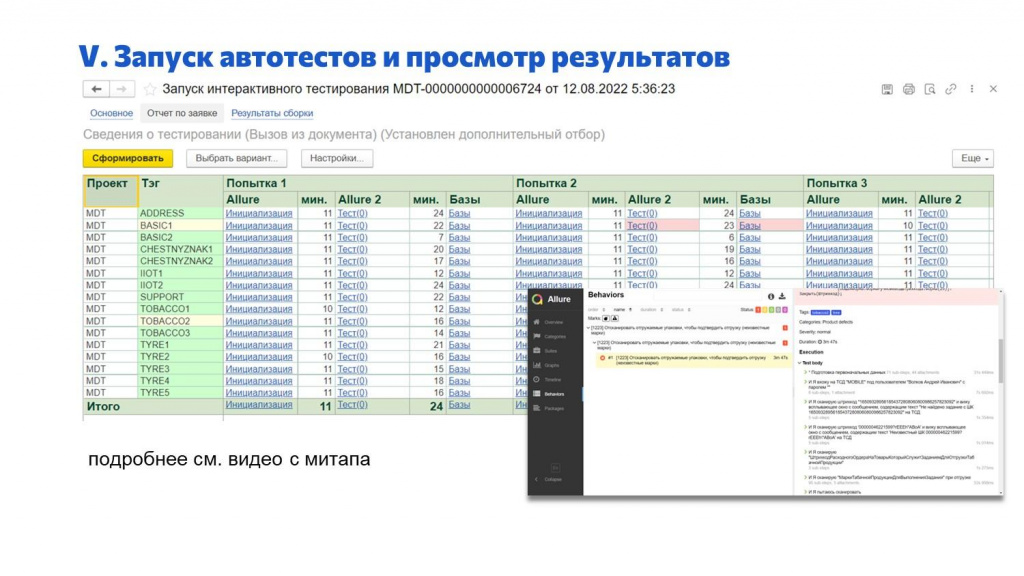
После того, как мы все закоммитили, запускаем тесты – про тесты я подробнее рассказал на митапе.
Тесты тоже запускаются по заявке в Service Desk – отчет по заявке с результатами тестов показан на экране.
Мы видим результаты тестирования по проекту.
-
Сценарии делятся по тегам. Плюс мы их запускаем в несколько попыток.
-
По каждому сценарию можно увидеть результаты, продолжительность.
-
Если нету «красных» итогов, значит, тесты прошли, и можно принимать.
Отсюда же открывается отчет Allure, который сгенерировала Vanessa Automation – там можно подробно посмотреть, где падало, и в чем была проблема.
Шаг 6. Пул-реквест
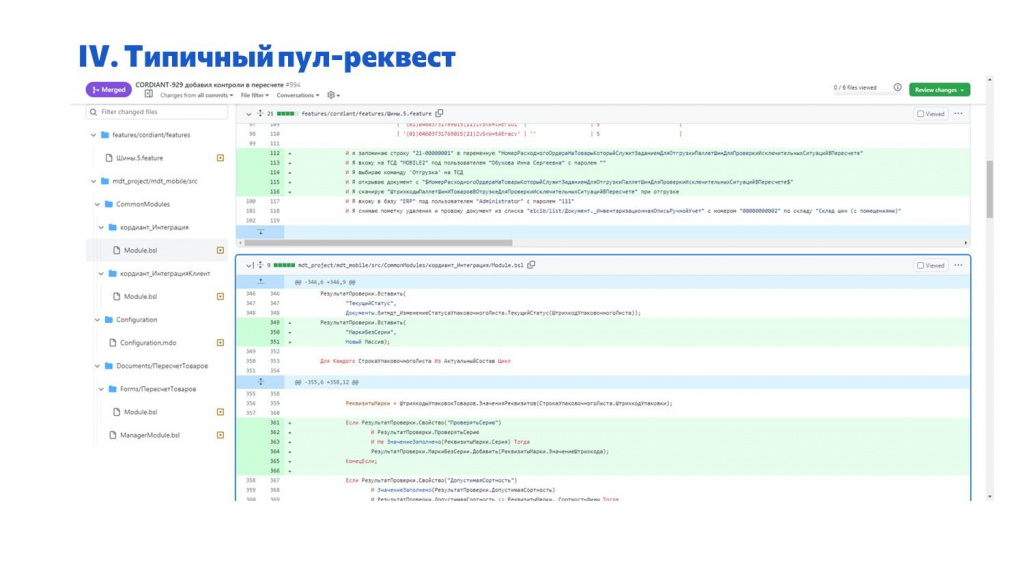
На слайде показано, как выглядит типичный pull request.
На что интересно обратить внимание.
Так как мы храним в одном репозитории и код, и фичи, и все вспомогательные инструменты, pull request мы тоже делаем общий, чтобы поместить консистентные данные в master. Т.е. здесь у нас разработчик и фичи поменял, и код накодил. Фичи у нас не всегда пишут разработчики, но в данном случае писал разработчик.
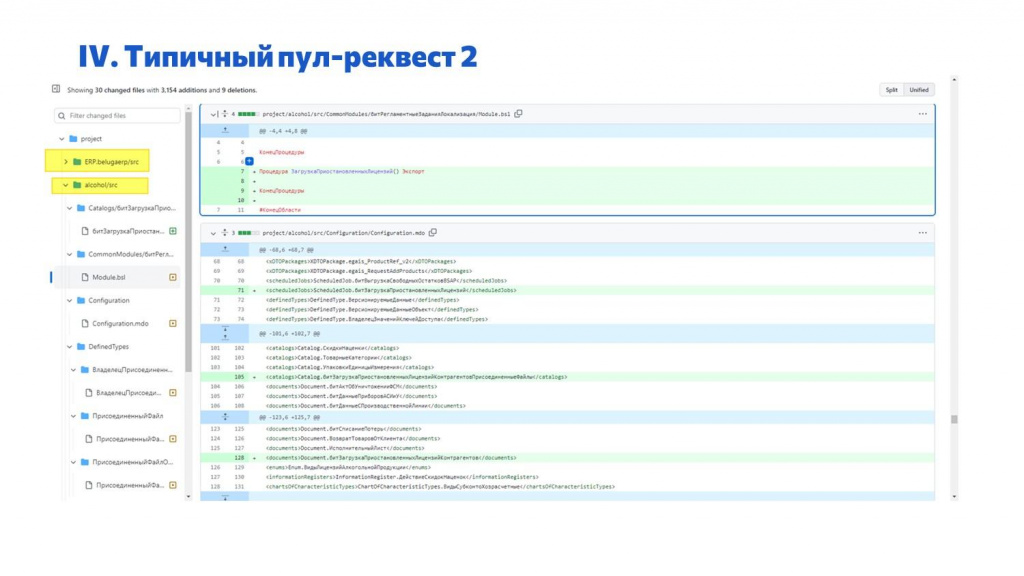
Еще один типичный pull request – это пример с «лысой» конфигурацией alcohol.
Здесь мы в «лысую» конфигурацию добавили регламентное задание и пустую процедуру в общий модуль с обработчиком для него.
Дальше мы в проектном расширении эту процедуру переопределим и напишем конкретный код, который должен выполняться по регламентному заданию.
Но поскольку репозиторий, где лежит эта «лысая» конфигурация и проектное расширение, общий, то и pull request тоже будет общий. И мы консистентно примем изменения – и в «лысой» конфигурации, и в расширении, где переопределен модуль из этой конфигурации.
Ключевые особенности

Вместо выводов давайте я еще раз перечислю особенности нашей инфраструктуры, которые позволили нам организовать разработку таким образом.
Первая особенность – сотрудники у нас разрабатывают на виртуальных машинах, а не на физических:
-
Эти виртуальные машины легко программно создавать и обновлять.
-
Кроме этого, мы можем выполнять код на этих машинах. Если бы разработчики у нас программировали на своих ноутбуках, мы бы не смогли выполнять код на их машинах – они не смогли бы делать через наш Service Desk такие заявки как «Создание окружения» или «Помещение в Git». А так как машинки виртуальные, то мы на них делаем, что хотим – можем сделать такую автоматизацию.
Мы используем Git и разрабатываем по подходу GitHub Flow – ветки develop у нас нет, у нас только feature-ветки и master.
-
С Git мы работаем либо напрямую, либо через заявки в Service Desk. Есть три основных способа.
-
Самый распространенный – это заявки в Service Desk.
-
Чуть более продвинутые товарищи работают в VS Code и оттуда коммитят.
-
И самые продвинутые товарищи работают в EDT, но их всего два человека.
-
-
Основная часть разработки у нас ведется в конфигураторе с использованием заявок.
Мы используем автосборку и автотесты.
-
Для автосборки – GitHub Actions, для автотестов – Vanessa Automation.
-
У нас есть возможность запускать тесты в любое время и в любом количестве.
-
В результате после каждого пул-реквеста мы имеем в мастере протестированный работающий код, и сразу же собирается релиз, который можно отдать заказчику. Все это позволяет очень быстро релизить фичи – дорабатывать функциональность и быстро отдавать релиз заказчику. К этому мы и стремились.
Эти подходы мы используем на всех проектах – в том числе, на ERP-шных. Даже там, где есть интеграция с УПП.
-
Два простых приема доработки, о которых я рассказал, позволяют нам не исправлять типовую конфигурацию и не хранить ее исходный код в Git. Это сильно все ускоряет.
-
В Git мы храним только наши доработки.
Вопросы
Какие параметры у хостовых (железных) машин, которые у вас используются? И какие параметры у виртуальных машин, которые вы создаете для разработчика – сколько ядер и сколько зон выделяете на каждую рабочую машину?
Что касается машин разработчиков, то:
-
Когда у нас были виртуальные машины разработчика на Windows, у нас было 4 ядра на 16Гб оперативки.
-
Когда мы стали использовать виртуальные машины на Linux, у нас сейчас 4 ядра на 24 Гб оперативки, а для некоторых особо крутых разработчиков 4 ядра на 32 Гб – т.е. потребление памяти с переходом на Linux в полтора раза выросло.
Для рабочих мест разработчиков мы в Селектеле арендуем именно виртуальные машинки, а не железные – на каких это железных машинках под капотом крутится, я не знаю.
Сколько виртуальных машин создается на одной хостовой машине?
Поскольку мы пользуемся виртуализацией, мы не видим, как это железно выглядит. Мы добавляем неограниченное количество виртуальных машинок, и все. А как и где это физически работает, для нас прозрачно.
А как вы решаете проблему с лицензиями, когда тестируете код на Vanessa Automation? Вы же когда подключаетесь к платформе, там должен быть ключ для пользователя и для менеджера тестирования.
Есть два способа: один, который у нас используется сейчас, и второй мы еще только планируем сделать.
Сейчас мы используем сетевые USB-шные ключи, которые втыкаются в один из компьютеров нашей сети. Так как у нас базы файловые, сетевой ключик со всех машинок видится.
Но компания «Первый БИТ» большая, и сейчас у нас лицензии тоже заканчиваются. Дальше мы планируем использовать возможность привязки программных лицензий к физическому сетевому ключу – будем просто программные лицензии на рабочее место к этому сетевому ключу привязывать, и все.
А вы не боитесь хранить код в GitHub?
У нас приватные репозитории.
Я про другое. Вы не боитесь, что GitHub заблокирует российских пользователей?
Мы настроили автоматическое клонирование в наш локальный репозиторий на GitLab. Даже если ужас случится, мы ничего не потеряем.
Как вы решаете проблему кроссплатформенности? Вы сказали, что у вас вся архитектура на Linux. Но что вы делаете, когда возникают задачи, требующие использования внешних компонент, написанных на Windows, или COM-объектов – например, если нужно читать Excel, Word и т.д. Как такую проблематику решать?
Сейчас у нас такой проблемы нет, потому что мы – проектный офис, и количество проектов у нас ограничено. Когда мы беремся за какой-то проект, мы смотрим, есть ли возможность запустить его на Linux или нет – будут ли от этого какие-нибудь проблемы. И все эти проблемы мы обходим до того, как с ними сталкиваемся.
А так как у нас количество клиентов измеряется десятками, а не сотнями или тысячами, мы можем заранее подготовиться.
Сейчас мы не используем компоненты, которые не работают на Linux. И в типовых конфигурациях COM тоже не используется.
Как вы сейчас обновляете конфигурацию поставщика? Типовыми средствами через «дважды измененные»?
Мы не вносим изменения в конфигурацию поставщика. Чтобы получить конфигурацию, какая нам нужна, мы берем типовую, накатываем на нее «лысую» конфигурацию и применяем расширения.
Если нужно обновиться, мы берем эту базу, обновляем ее с заменой всех объектов – просто загружаем поверх конфигурацию поставщика, затем накатываем лысую конфигурацию и применяем расширения.
Но если мы обновили конфигурацию вендора и накатываем на нее «лысую» конфигурацию, она же может не встать.
Теоретически – да, может, но состав тех объектов, которые мы переопределяем в лысой конфигурации, небольшой. Как правило, это какие-то базовые роли, определяемый тип «ВерсионируемыеОбъекты» и так далее. Их немного, они не часто меняются и даже между разными версиями БСП они одинаковые. Поэтому проблемы такой не возникает.
И если в конфигурации поставщика поменялся модуль, а мы его в расширении значительно кастомизировали, расширение же тоже не встанет.
Это же вопрос не к нашему подходу, а к любому использованию расширений.
Очевидно, что когда мы в расширении переопределяем функцию с директивой &ЗаменаИКонтроль, в случае, если она поменялась, расширение не применится, и нам нужно будет что-то у себя менять.
Как вы проводите операцию сравнения/объединения расширения с конфигурацией вендора, чтобы понять, что нужно доработать?
А зачем их сравнивать / объединять? Мы контролируем применимость и проверяем тестами. Тестами мы покрываем всю нашу функциональность. Те проблемы, которые не выявились при проверке применимости – допустим, количество параметров поменялось – выявятся при тестах.
А дальнейшие действия какие? Разработчик должен сам проанализировать код расширения на совместимость с обновленной конфигурацией?
Он прогнал тесты, посмотрел, где упало, посмотрел в исходный код, увидел, что удалили параметр в переопределенной функции типовой конфигурации и пошел менять расширение, потому что типовая поменялась.
Как вы боретесь с пересечением расширений, когда одну процедуру заимствует несколько расширений? Случается ли у вас такое?
Мы стараемся так не делать. У нас, как правило, два расширения на проекте – типовое и проектное. Проектное расширение мы стараемся делать одно. Максимум, багфиксы еще делаем отдельным маленьким расширением, но потом их удаляем.
Мы не делаем много расширений на одном проекте – обычно два, а лучше одно вообще.
Вопрос по поводу «лысой» конфигурации. Каким образом вы автоматизируете создание конфигурационного файла для объединения?
Не автоматизируем. Он лежит в гите рядом с этой «лысой» конфигурацией. Разработчик, который объекты в «лысую» конфигурацию добавляет, он же и этот файл дорабатывает.
Там обычный XML-ный файл, который можно выгрузить в процессе платформенного сравнения/объединения – в нем можно перечислять не все объекты, а только отличия от того, что по умолчанию установится. Его вполне руками можно править.
Так как лысая конфигурация у нас небольшая, объектов там немного, то разработчик просто руками его правит и все.
Непонятно, в чем заключается ускорение? Например, мы, когда делаем новую ветку для разработки задачи, выполняем команду: git flow feature start. При этом загружается конфигурация и расширения. У нас сейчас основная проблема – это долгая загрузка основной конфигурации.
У нас есть эталонная база, где уже загружена основная конфигурация – она более-менее свежая, автоматически раз в день обновляется из ветки master.
Мы ее просто копируем и на нее через сравнение/объединение накатываем маленькую «лысую» конфигурацию и ставим расширение. Основную конфигурацию мы не загружаем, она уже есть в той эталонной базе, которую мы берем за основу.
Сравнение/объединение – это интерактивная история?
Можно и программно делать без интерактивных действий – через командную строку с вызовом конфигуратора и указанием XML-файла с настройками сравнения/объединения.
Сколько времени у вас занимает подъем одного такого рабочего места для новой задачи?
Минут 20.
Вы упоминали, что тестовые базы обрезаются для удобства и экономии места. Чем пользуетесь? Как обрезается база?
У нас нет единого набора инструментов и подхода – каждая проектная команда выбирает свой инструмент сама.
Критерии обрезки такие:
-
с одной стороны, нам нужно, чтобы в эталонных базах были все данные для проведения тестов;
-
с другой стороны, эталонная база не должна быть слишком большой, потому что иначе тесты будут дольше запускаться и дольше будет создаваться окружение.
А вариантов как обрезать – сколько угодно. Тут уж кто во что горазд – единого подхода нет.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.
Приобретайте 1С:ERP в Инфостарт с бонусом 15%!
- Бесплатное демо продукта и консультация
- Команда экспертов 1С с опытом 10+ лет
- Оценка проекта, четкий план работ, документация, обучение и поддержка
Закажите расчет внедрения ERP - получите дорожную карту в подарок!


Вступайте в нашу телеграмм-группу Инфостарт