Меня зовут Артем Кузнецов, я тимлид 1С. В 2021 году на конференции Инфостарта я выступил с докладом о том, как мы обеспечиваем быстрый фронт на большой базе. Тогда у нас база была 7 терабайт, сейчас ее размер уже больше 9 терабайт. И сегодня я расскажу про стандарты, которые мы применяем при разработке именно компонентов для нашей системы.
Во вложении к докладу вы можете скачать презентацию, чтобы, во-первых, посмотреть код слайдов поближе, а, во-вторых, часть информации находится в заметках к слайдам. Там тоже достаточно большой кусок, который будет полезно почитать, чтобы использовать для своих нужд.

Для чего мы применяем эти стандарты? По идее, без стандартов можно писать код, решать задачи бизнеса, получать деньги, и все нормально работает.
Но техдолг легаси-объектов, которые написаны без стандартов, всегда возвращается – через месяц, три года, пять лет. И ресурсы, которые потребуются на его исправление, в разы выше, чем сразу написать хорошо.
Поэтому мы применяем стандарты и контролируем их исполнение.
Подписки на события

Первый компонент, про стандарты разработки которого я расскажу – это подписки на события. Это довольно старый механизм, и у него есть ряд проблем:
-
Не гарантируется порядок выполнения кода между несколькими подписками – мы никак не можем задать порядок выполнения подписок, если они на одинаковое событие;
-
Сложность чтения логики поведения, потому что код фрагментирован, он находится в различных модулях, возможно, вообще в других подсистемах, и мы не можем полноценно собрать, что же происходит при том или ином событии;
-
Ограниченные возможности расширения логики – у подписок ограниченный набор событий.

В результате мы пришли к тому, что стараемся вообще не использовать подписки на события – если и используем, то по минимуму.

Например, мы используем подписки на события, чтобы подключить объект к другой подсистеме – в нашем случае, к подсистеме интеграции с бюро кредитных историй.
Когда происходит какое-то событие, в регистр этой подсистемы, который отвечает за очередь к обработке, падает запись – при этом никакой логики, никаких проверок в этой подписке на событие не происходит. Это позволяет не влиять на тот процесс, который вызвал срабатывание подписки. Потому что запись регистра – это быстро, и не замедляет основной процесс.
А дальше подсистема сама с этой очередью поработает и все, что ей нужно, сделает. Это тот случай, когда мы допускаем использовать подписки.
Обработчики обновления

Следующий компонент – это обработчики обновления. Мы разрабатываем продукт не для одного конкретного заказчика – у нас их несколько, у каждого своя функциональность, и иногда люди пользуются функциональностью других заказчиков.
Поэтому у нас есть ряд требований, которые мы соблюдаем при работе с обработчиками обновления:
-
В обработчиках обновления не должно быть никакого «найти по коду», «найти по наименованию». Только если в обработчике обновления нужно что-то обработать в конкретной базе - допускается работа с ID-шниками.
-
Для обработчиков обновления следует фиксировать прогресс выполнения и версию, обновление на которую нужно выполнить – «звездочку» в версии не оставляем ни в коем случае, уже обработанные элементы не должны попадать в выборку повторно.
-
У нас активно используется программная доработка непоставляемых профилей доступа. Когда появляется новая функциональность, и нужно в дополнение к какой-то роли выдать еще дополнительные права на эту новую функциональность, никто руками непоставляемые профили в базе не правит. Это все происходит в обработчиках обновления.

У обработчиков обновления есть несколько режимов выполнения: монопольный и отложенный. Есть еще оперативный, но его мы стараемся не использовать.
-
Монопольные обработчики обновления предназначены для тех данных, которые нужно обновить до того, как первые пользователи эту систему.
-
Отложенные обработчики обновления могут выполниться уже после входа пользователей.
У нас есть требование максимально использовать отложенные. Это требование появилось не так давно, тем не менее, все, что можно, мы обновляем отложено, чтобы уменьшить технологическое окно. Чтобы база, которая одновременно является бэком для личного кабинета, включилась обратно как можно скорее, чтобы монопольные обработчики обновления ее не задерживали.

У нас на базе 9 терабайт 5 релизов в неделю, технологическое окно требуется как можно меньше, поэтому мы используем обработчики обновления в первую очередь для минимизации ручного труда.
Релиз-менеджер – специалист, который в полночь накатывает обновления – вообще не программист, даже не технарь, он просто запускает скрипты. Соответственно все должно происходить автоматически, никаких «после накатки обновления подключите обработку, выполните ее» и так далее – ничего этого не должно происходить. Только автоматизация, никакого ручного труда, потому что это риски, потому что ручной труд – это плохо.

В качестве примера покажу код обработчика обновления, который мы используем для программной доработки непоставляемых профилей доступа.
У нас есть своя подсистема, которая позволяет управлять правами доступа. Например, есть метод, чтобы к существующей роли добавить новые роли на новые объекты, которые появились в базе.
Этот код выполняется отложено, чтобы люди уже могли спокойно работать с другими подсистемами. Тем самым пользователям обеспечивается доступ к новой функциональности. И это все без участия людей, без какого-либо ручного труда.
Это работает для пользователей с непоставляемыми профилями – для тех, у кого они еще остались, мы сейчас стараемся уже всех на поставляемые переводить.
Регламентные задания

При разработке регламентных заданий обязательно нужно ознакомиться с документацией БСП. Мы стараемся ее придерживаться в этом блоке по максимуму. Основные наши моменты:
-
Настройки регламентных заданий мы определяем на уровне конфигуратора: расписание, флаги «Использование», «Предопределенное» и так далее. Потому что, когда новое регламентное задание появляется в системе, у нас есть требование, чтобы дежурному не надо было в него заходить, включать и настраивать расписание – в момент релиза регламентное задание должно начать работать. Если требуется его включить только в конкретных базах, это все рулится на уровне обработчиков обновлений и ID-шников. Все регламентные задания завязаны на функциональные опции – либо включающие видимость подсистемы, в которую включено регламентное задание, либо же ФО конкретно на само регламентное задание;
-
Обработчик регламентного задания должен размещаться в подсистеме, к которой относится это регламентное задание. Не должно быть никаких больших общих модулей, в которых сваливают все регламентные задания. У регламентного задания есть подсистема, он к ней относится. И обработчик должен лежать там же;
-
И у нас есть определенные требования к структуре метода регламентного задания – про них я чуть позже подробнее расскажу.

Как мы определяем настройки для регламентных заданий на уровне конфигуратора:
-
Для добавленных регламентных заданий мы ставим флаг «Предопределенное», чтобы ими можно было рулить с помощью функциональных опций и они были бы доступны в списке регламентных заданий из 1С:Предприятия.
-
При необходимости включения регламентного задания во всех базах продукта ставим флаг «Использование». Если на уровне продукта включать регламентное задание не надо, дальше все рулится кодом через функциональные опции включения и выключения.
-
Если у регламентного задания есть доступ к внешним ресурсам, то поскольку у нас база имеет достаточно много интеграций, при разворачивании копии все регламентные задания, у которых есть этот признак (это наш признак, он задается в коде метода переопределяемого модуля), отключаются скриптом. Это обязательно контролируется, чтобы у нас не было такого, что с копии отправили миллион sms клиентам с какими-то кракозябрами.
-
Регламентное задание всегда привязано к функциональной опции. Или это функциональная опция конкретного регламентного задания, или это функциональная опция целой подсистемы – если регламентное задание идет в комплекте с подсистемой.
-
Обязательно фиксируем информацию по регламентному заданию в документации. И помимо описания указываем ответственных от бизнеса или разработчиков. Поскольку все регламентные задания выполняются от имени 1С, если оно упало, то непонятно, к кому бежать. У нас в документации зафиксировано, кто из бизнеса или разработчиков отвечает за то или иное регламентное задание.

По обработчику регламентного задания. У нас обработчик регламентного задания в идеале состоит из трех блоков: сначала идет БСП-проверка (в каждом регламентном задании мы проверяем возможность запуска стандартными методами БСП), затем подготовка параметров, и далее вызов с этими параметрами каких-то других методов. В самом обработчике регламентного задания никакой логики быть не должно. Чаще всего, это вызов какого-то открытого API, открытого программного интерфейса, который доступен и для других потребителей, не только для регламентного задания – вызов универсального метода, к которому обращаются и пользователи, и регламентные задания. У нас есть методы API, которые находятся в том же служебном модуле, но их не очень много. Почти для всех регламентных заданий мы стараемся делать возможность вызова руками, чтобы при необходимости не нужно было регламентное задание перезапускать, а можно было обработкой дернуть тот же самый метод с теми же самыми параметрами;
Если говорить про размещение обработчиков регламентных заданий, то для этого должны использоваться отдельные служебные общие модули подсистем, к которым относятся задания. Сам метод, к которому привязано регламентное задание, должен быть размещен только в области #СлужебныйИнтерфейс. К этому методу не должно быть обращений в конфигурации нигде, кроме как из самого объекта регламентного задания в дереве – в коде мы никогда не обращаемся к методу регламентного задания.

И у нас есть Legacy-модуль, достаточно старый, большой, куда в течение нескольких лет сваливались все регламентные задания. Сейчас там сами понимаете, что происходит.
Туда сваливались не только методы регламентных заданий, но и вся логика, что они выполняют, все действия – работа с регистрами, с данными, интеграция – все в одном модуле.
Там сейчас дохреллион строк, и мы туда просто не ходим – вообще не заглядываем.
Оно как-то работает, иногда мы там какой-то рефакторинг делаем, оттуда что-то выдергиваем, но ничего нового мы туда, естественно, не добавляем. Это плохой подход, от которого мы ушли.

На слайде – пример построения логики регламентного задания, построения структуры метода.
-
Сначала идет БСП-шная проверка.
-
Потом – подготовка параметров.
-
И далее вызов методов – в данном случае эти методы находятся в этом же служебном модуле. Но поскольку методы, судя по названиям, немного с разными назначениями – выгружаются текущие и прошлые периоды, вероятнее всего, внутри какие-то более параметры докручиваются – более сложные, чем просто параметры логирования, и после этого уже идет вызов какого-то внешнего открытого программного интерфейса.
Массовая обработка данных

Следующий компонент, к которому у нас есть требования – это массовая обработка данных, она применяется, когда требуется заполнить ретроданные или что-то исправить.
Любая массовая обработка данных всегда имеет какие-то риски – или это косяк в самой логике обработки, или косяк в виде падения базы, когда не учли каких-то нюансов, сделали выборку на 500 миллионов строк и погнали ее обрабатывать за раз. Если не соблюдать требования, можно легко уронить базу.
Мы стараемся минимизировать возможные риски через использование шаблонов и типовых процессов:
-
Единообразие архитектуры. У нас есть шаблон для массовой обработки со всей обвязкой – разработчик пишет только запрос и логику обработки результата запроса. Вся остальная обвязка, включая отключение регламентного задания после завершения обработки, в шаблоне уже готова. Очень рекомендую иметь такой шаблон, которым можно пользоваться.
-
У нас есть определенные рекомендации – сколько выбирать, как обрабатывать. Чуть позже о них скажу.
-
Перед запуском обработки на рабочей базе ее нужно обязательно протестировать. И самое важное – это уведомления команды. Если даже по какой-то случайности массовая обработка данных уронила базу или замедлила какую-то работу, вызвала какой-то всплеск, если уведомление было, то это очень быстро найти, очень быстро исправить и минимизировать длительность простоя и риски. Обычно за это никакой кары нет, это быстро очень отключается, рефакторится и снова запускается. Если уведомления не было, значит запустивший разработчик, обычно дежурный, сам виноват, что не уведомил о подключении и запуске. Дальше уже с ним идет какая-то работа.

Архитектура массовой обработки данных – то, что внутри шаблона:
-
Обязательное выполнение в фоне. Никаких кнопок «Выполнить» дежурный не нажимает – он подключает обработку, настраивает расписание и забывает про нее.
-
За тем, как двигается обработка, программист следит с помощью Graylog. Уровень логирования – каждый шаг будет логироваться или только начало и конец – определяется внутри обработки.
-
И мы используем сохранение прогресса между запусками – оно тоже есть в шаблоне. Чтобы в случае, если обработка упала, нельзя было выбрать те данные, которые уже были обработаны. Такое иногда бывает. Мы этот прогресс тоже сохраняем. Это очень полезная функциональность.

Требования к коду массовой обработки данных:
-
Должны соблюдаться те же требования, что и к обработчикам обновления: при выборе объектов для обработки не должно быть никаких «Найти по наименованию», «Найти по коду» – только ID-шники.
-
Если при массовой обработке перепроводятся документы, обязательно регулируем срабатывание подписок. Если подписок много, с этим начинаются сложности.
-
Регулируем дополнительные свойства типа проводок и выгрузки в другие системы – это обязательно контролируется еще во время разработки.
-
У нас есть рекомендуемые параметры выборки и обработки данных. Например, мы рекомендуем выбирать в одном запросе не более 50 тысяч элементов за раз, чтобы tempdb в процессе обработки не раздувало.
-
Обработку данных в транзакции мы используем, только если несколько зависимых элементов изменяется, чтобы посередине процесса, посередине одной итерации цикла, если будет падение, то не было частичной потери данных. Но если надо обработать один справочник, мы не запихиваем в одну транзакцию 50 элементов. Мы сначала пробовали, но потом пришли к тому, что выхлопа от этого никакого нет, а если упал один элемент, то упала вся транзакция.

Как я уже сказал, реальной необходимости пакетных транзакций для одиночных объектов нет. Мы пробовали, тестировали – разницы никакой нет. Это лишний код, лишнее открытие-закрытие транзакции, упаковка атомарных объектов в более крупные транзакции.
Если сначала было: «Не дрочите базу транзакциями, зачем вам 50 тысяч элементов обрабатывать? Сделайте транзакции по 100 и обработайте это 500 раз. 500 транзакций лучше, чем 50 тысяч транзакций». Оказалось, нет. 50 тысяч транзакций база прекрасно переваривает, и никакого выигрыша мы от этого не получали вообще.

Пример многопоточной обработки данных, когда одна обработка является и управляющим потоком, и дочерними:
-
Здесь формируется список периодов для обработки.
-
Для каждого периода в цикле вызываются дочерние потоки этой же обработки в фоне.
-
В начале обработки проверяется: если передан период, значит это дочерний поток, если не передан период, значит это управляющий поток.
-
У нас бывают достаточно большие заполнения ретроданных – в многопоточном режиме мы такими методами запускаем 15, 20, 50 потоков.

И пример выборки – здесь тоже достаточно простой код.
Изначально стоит «ВЫБРАТЬ РАЗРЕШЕННЫЕ ПЕРВЫЕ 1», мы не используем рваные запросы типа «ВЫБРАТЬ РАЗРЕШЕННЫЕ ПЕРВЫЕ ” + Количество + “». Любой запрос должен всегда открываться в конструкторе.
И дальше мы заменяем «ПЕРВЫЕ 1» на переданный параметр. Параметр размера порции определяется в настройках обработки – именно в секции параметров.
Такое разделение блоков кода очень важно для последующего удобства.
Разработка расширений

Расширениями пользуемся очень активно.
-
В первую очередь мы пользуемся расширениями для хотфиксов, потому что динамические обновления рано или поздно роняют кластер, а хотфиксов у нас достаточно много. Чтобы их контролировать, у нас к ним есть определенные требования.
-
Кроме этого, расширения могут применяться для тестирования гипотез бизнеса.
-
И для доработки типовой функциональности в каких-то постоянных расширениях – чтобы не снимать с поддержки и легко обновлять типовой код.
-
И еще бывает, что бизнесу один день до релиза – это слишком долго. Он хочет функциональность прямо сейчас. Для этого мы тоже активно используем расширения.
Основные моменты:
-
Выбор верного вида расширения. Существует несколько видов, главное выбрать правильный вид, чтобы потом это все было удобно мониторить и контролировать.
-
Контролируем свойства расширения – наименование, синоним, все галочки. Все это нужно обязательно отследить, и есть определенные правила, как это надо правильно расставить, чтобы все хорошо работало. Если это не постоянное расширение, а хотфикс, никакого описания, что делает расширение, мы практически никогда не пишем – в имени мы всегда указываем номер задачи в Jira. Как показала практика, так удобнее всего ориентироваться – у нас есть атомарное расширение, которое привязано к одной задаче, у него этот номер задачи указан в имени и синониме. Все методы и объекты расширения обязательно имеют префикс этого расширения, и в случае ошибок или каких-то вопросов очень легко найти задачу и автора. По нашей практике, это самый простой способ;
-
И у нас есть нюансы при работе с разными типами метаданных в расширениях.

Виды расширений:
-
Дополнение – новая функциональность. Это как раз досрочный релиз или тестирование гипотезы;
-
Адаптация – это изменение текущей уже существующей функциональности. Это не хотфикс, не исправление ошибки, это именно доработка функциональности для какого-то тестирования – как правило, для тестирования гипотезы;
-
Исправление – хотфиксы при ошибках.

Ключевые моменты:
-
Мы запрещаем добавлять в расширениях новые объекты метаданных, которые вызывают в базе данных создание таблиц или реквизитов существующих таблиц. Мы запрещаем это делать, потому что при обращении к таблице создаются лишние левые соединения, и это все очень медленно работает.
-
Весь код принадлежит разработчику расширения. Если ты выдернул метод из типовой конфигурации и засунул в свое расширение целиком, а не через &ИзменениеИКонтроль, изволь привести его в порядок – по SonarQube и по нашим требованиям.
-
Все объекты и методы расширения должны иметь префикс этого расширения.
-
При переопределении методов мы по максимуму используем &ИзменениеИКонтроль, потому что это позволяет контролировать в расширении изменение кода конфигурации. Это особенно актуально при пересечении задач разработчиков в одном и том же модуле. Если в конфигурации изменился код, который был доработан в расширении, расширение падает, и мы тут же реагируем и определяем, что нужно сделать. Поэтому &ИзменениеИКонтроль используется по максимуму.

«Демонические» обновления мы, слава Богу, больше не используем – как раз благодаря расширениям. Потому что раньше 2-3 динамических обновления роняли нам кластер.

Пример простого хотфикса через &ИзменениеИКонтроль – вставка необходимой проверки, вызывающий исключение в обработчике, если в процессе работы произошел кейс, который во время тестирования не обработался.
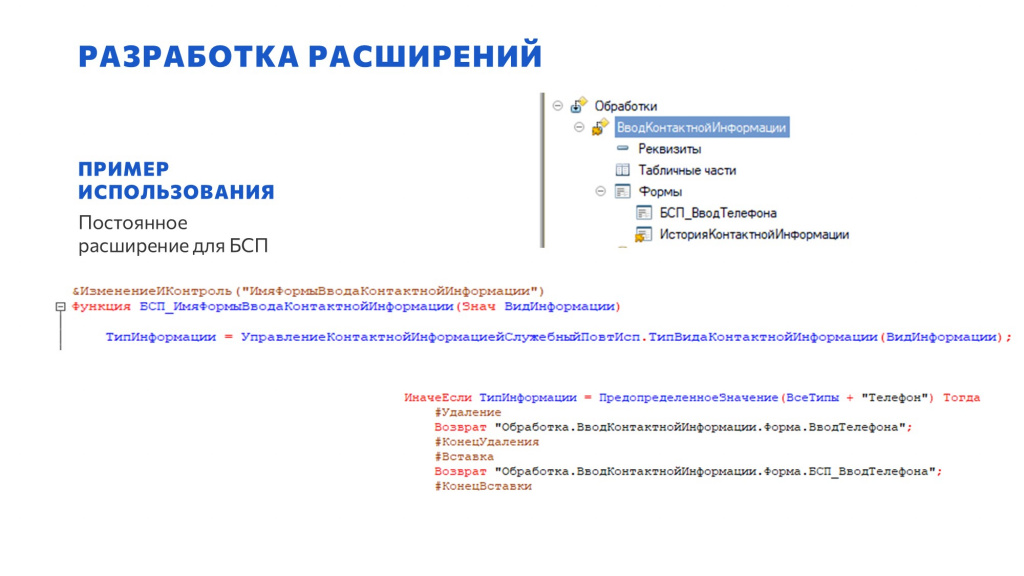
И пример нашего расширения типовой функциональности – это постоянное расширение для БСП. Мы через расширение добавили здесь свою форму ввода номера телефона – через &ИзменениеИКонтроль мы удалили типовой вызов и вставили свой.
Обновление самой конфигурации БСП не вызывает проблем, потому что все лежит в расширении. Если расширение упадет из-за того, что что-то изменилось в этой части - мы будем его фиксить.
Архитектура СКД отчетов

Про запросы для отчетов я говорил на своем прошлом докладе, поэтому про них я здесь говорить не буду, но про саму архитектуру именно СКД я немного расскажу.
-
Бизнес очень любит отчеты, их много делают постоянно, и поэтому у нас есть ряд требований для того, чтобы эти отчеты не роняли базу. Они очень любят большие выборки – например, недавно бизнес захотел выгрузить себе 500 миллионов записей в Excel и там ВПР-ом поработать с ними. Мы стараемся такие запросы как-то отслеживать, ограничивать, но не всегда получается. Все ограничения, естественно, были на основании факапов. Почти все наши стандарты написаны слезами разработчиков, которые попали на факап.
-
Необходимо помнить, что есть пользовательские варианты отчетов. Добавляете поле – учитывайте, что нужно как-то обработать пользовательские варианты, если оно им нужно. И не удалять поля, иначе пользовательские варианты могут упасть.
-
И у нас есть программная доработка отчетов. Например, мы помогаем RLS – в некоторых ключевых отчетах на первую таблицу запроса кодом добавляем отбор, определяемый по типу должности пользователя. Если пользователь – менеджер, у него должно быть ограничение по подразделению, и мы сразу в первую таблицу пихаем отбор по подразделению, чтобы ограничить количество данных, которые идут дальше по запросу. Не ждем срабатывания RLS, а сразу программно ставим отбор в первую таблицу.

Коротко про поля отчета:
-
Запрещается использовать роли Период и Остаток. Они запрещены, потому что они деградацию вызывают в некоторых случаях.
-
«.*» мы не используем для пользователя. Все поля, которые хочет пользователь, мы ему явно определяем в списке полей, доступных для выбора.
-
Роль Обязательное можно использовать, потому что если ее не использовать, и поле не выбрано в пользовательских полях, то оно может быть исключено из запроса и могут измениться данные – поехать группировки.

Вычисляемые поля отчета:
-
Запрещается использовать разыменование в вычисляемых полях.
-
ВЫБОР КОГДА в вычисляемых полях стараемся не использовать, потому что это добавляет дополнительные вычисления при расчете условий.
-
Используем внешние функции, только если нет обращения к СУБД – если это какая-то внешняя математика.
-
Любые математические расчеты у нас разрешены.

Особенности настроек отчета:
-
Заранее готовим все доступные поля.
-
Для полей и группировок отчета – никакого разыменования.
-
Реквизиты полей нельзя использовать для отборов – для условий реквизиты нужно отключать.
-
Списки для полей составного типа тоже нельзя – по понятным причинам: это вызывает лишние соединения и лишние проверки, которые утяжеляют отчет.
-
Все остальное, что душа заказчика пожелает – можно, если не противоречит всему, что сказано выше.
Про оптимизацию запросов рекомендую прочитать мой прошлогодний доклад – это статья на Инфостарте. Там очень много и структурно рассказано про запросы.

И пример той самой программной установки отборов в первой таблице запроса.
По RLS мы получаем его тип должности и список доступных подразделений пользователя и устанавливаем отбор компоновки данных по значениям «Команда», «Кластер», «Подразделение» – чтобы в первой же таблице отбор наложился автоматически и дальше это все шло уже в виде каких-то маленьких данных.
Настройки подсистем

-
Раньше у нас был хаос из констант – когда появлялась какая-то новая функциональность, на ее включение-выключение добавлялась новая константа. Теперь для настроек подсистем мы константы не используем. Для непериодических настроек используем справочник с версионированием, а для периодических – периодический регистр сведений с регистратором-документом, где приведены все настройки подсистемы. Даже если добавляется одна галочка, она все равно пакуется или в справочник, или в регистр.
-
Объект, который хранит настройки, должен принадлежать самой подсистеме.
-
Для справочника, хранящего настройки подсистем, обязательно используем версионирование, а для регистра – регистратор.

-
Для включения-выключения подсистемы в целом – когда меняются не внутренние настройки, а включается-выключается вообще вся подсистема – мы используем константы и функциональные опции. Для этого константы все еще используем.
-
Для непериодических настроек используется справочник, для периодических – регистр сведений с регистратором-документом, к которому у определенных людей есть доступ.
-
У нас есть требования к реализации метода, который возвращает не ссылку на текущую настройку, а именно фиксированную структуру с настройками.

Мы нашли свое решение для того хаоса из десятков и сотен констант, который невозможно настроить – раньше при создании новой базы под нового клиента, чтобы все заработало, нужно было выставить 50-60 констант. Сейчас мы это пакуем.

Пример метода для получения текущей настройки подсистемы.
В модуле повторного использования мы размещаем экспортный метод, возвращающий структуру с текущими настройками, которые сейчас актуальны для конкретных переданных параметров. В зависимости от подсистемы такие методы могут быть с параметрами, могут быть без параметров.

Например, подсистема бюро кредитных историй, она достаточно большая и настроек у нее тоже много. Констант в ней нет. Есть некоторые функциональные опции, но это отдельные блоки, которые могут самостоятельно включаться и выключаться – кому-то нужны, кому-то не нужны.
Индексация таблиц баз данных

-
Ключевой момент в индексации – планируйте индексацию заранее. При создании любого объекта необходимо планировать его использование на шаг, на два, на три вперед. Многие говорят: «Нам нужно отобрать данные в регистре по двум ресурсам. Как это сделать?» Если такое произошло, значит вы неправильно спланировали метаданные. Вам нужно или реструктурировать текущую таблицу, что обычно проблематично, или создать рядом новую и там этот составной индекс сделать в виде измерений. Именно так мы обычно и делаем, поэтому у нас и база такая большая – мы любим создавать новые таблицы. Это позволяет нам быстро выполнять отчеты, потому что у нас для каждого отчета есть данные своего формата, которые можно использовать;
-
Обязательно анализируем необходимость индексов – лишние индексы не добавляем, потому что это лишние таблицы в СУБД, которые никому не нужны;
-
Избегаем индексации полей с типами «Строка» и «Число» – у них очень низкая селективность, индекс там практически всегда бесполезен. Кроме того момента, если это идентификаторы – идентификаторы типа «Строка» и «Число» можно индексировать.

Ключевой момент в этом блоке – это всегда думать вперед, планировать. Если бизнес говорит: «Я хочу хранить такие данные», сразу вопрос: «А как вы их будете использовать? Отчеты, выгрузки, еще что-то?» И от этого уже планируется именно разработка объектов.

На слайде пример анализа необходимости индекса. Ключевой момент: здесь забыли индекс, потом индекс добавили, но это не помогло, и запрос продолжал падать. Подробнее об этом можно прочитать в заметках к слайду в презентации из вложения к докладу.
Реструктуризация базы

-
На больших таблицах у нас бывают большие реструктуризации. Обязательно тестирование на копии с замером времени.
-
Используем вторую версию механизма реструктуризации – она работает прекрасно, мы, по-моему, с нее уже даже не уходим.
-
Крупные реструктуризации лучше релизить отдельно от основной задачи.

Критерии обязательного тестирования реструктуризации таблиц:
-
Если размер таблицы более одного миллиона строк.
-
Если в таблице есть реквизит с типом Строка неограниченной длины или типом ХранилищеЗначений.
-
При изменении состава индексов – даже если просто поменяли измерение, это тоже изменение состава индексов.
-
Если итоги включили или выключили – это тоже обязательно требует тестирования реструктуризации таблиц.

Важно правильно готовиться к реструктуризации в условиях малого технологического окна.
Релиз базы на таком объеме у нас занимает 15 минут, по крайней мере мы стараемся в это указываться. Большая реструктуризация – до 30 минут.
И помните, что это наши стандарты, это не панацея, не «серебряная пуля», но часть из них может вам помочь.
Вопросы и ответы
У вас объекты для хранения настроек подсистем привязаны к включению самих подсистемам – это все понятно и удобно. А как вы относитесь к собственной ПВХ для хранения?
У нас самописная конфигурация на БСП, мы не используем ПВХ, насколько я знаю.
А в принципе, как вы к этой идее относитесь?
Даже не рассматривали ее. Есть удобные справочники, есть удобные регистры с регистратором, есть версионирование, есть автор. Нас устраивают существующие объекты.
Зачем проверять «а будет ли лучше?», когда это и так работает, и работает хорошо?
У вас огромная база данных – вы говорите, что запускаете обработки на 50 тысяч транзакций. Сколько времени уходит, когда надо поменять какой-то глобальный массив данных? Например, произошло что-то странное и надо поменять пул документов с кучей регистров.
Если мы меняем документы, мы меняем их без движений.
А движения?
А все нужные движения, как правило, дописываем явно руками.
Сколько времени занимает 50 тысяч транзакций на то, чтобы все поменять?
Минуты две-три, совсем немного. 50 тысяч – это очень мало.
А сколько потом уходит на изменение движений?
Так это все в одной обработке происходит.
Получается, что у вас шаблон на изменение документов, где движения отдельно ручками дописываются?
Нет, движения прямо в этом же шаблоне зашиты. Как правило, это все происходит именно так.
50 тысяч – это не очень много. У нас проблема, когда надо поменять 500 миллионов строк. Вот в этом случае у нас возникают проблемы. Мы делали многопоточность, запускали, и это работает несколько дней.
Я к этому и спрашиваю. Что делать, если нужно обработать именно большой массив данных, и заказчика не устраивает, что это будет длиться несколько дней?
Увеличиваем количество потоков. Но у нас просто не было такого, чтобы заказчика совсем не устроило.
А вы когда-нибудь пробовали эти массивы данных менять напрямую в SQL-таблицах?
Мы не лезем в SQL. Мы закрываем всю оптимизацию компетенциями 1С-разработчиков. Да, можно в SQL миссинги добавить, можно залезть туда напрямую запросами, можно еще много чего прикольного сделать, для этого есть DBA. Но мы этим не пользуемся. У нас основная цель, что все закрывается компетенциями стандартного 1С-разработчика. Он должен суметь любую оптимизацию решить средствами 1С.
Я так понимаю, у вас в обработках активно используются фоновые задания. Сейчас в платформе есть промисы, await. Вы планировали на них переходить, подсчитывали какие-то риски? Есть ли смысл всю текущую функциональность вынести с фоновых заданий на асинхронные методы, которые сейчас есть.
Асинхронные методы – это клиентский контекст, а у нас все обработчики выполняются на сервере. Как правило, это обработчики очередей интеграции с другими внешними сервисами, с RabbitMQ и дальше пошли всякие регуляторы и прочее. Это все обрабатывается в фоне.
Плюс всякие нейронки – проверки паспорта и всего остального.
Вы несколько раз проговорили, что у вас для обмена с внешними системами организованы внутренние очереди на регистрах сведений. Это совсем банальные регистры сведений или уже настоящие очереди с контролем, со статусами и еще с чем-то?
Задача той же подписки положить в регистр данные и уйти обратно, чтобы основной процесс не замедлился. При проведении документа менеджер не должен почувствовать, что во время нажатия кнопки что-то еще куда-то записалось – в какой-то регистр, который потом дальше сам это все обработает.
А дальше внутри регистра там бывает, что еще и вторая очередь есть, куда из основной очереди с обогащением данными, с дополнительными запросами кладется что-то побольше. Там есть контроль статусов и так далее.
Но точка входа в подписке должна быть быстрой и максимально простой. Там должна быть только та информация, которая позволит дальше с этим как-то это все развить. Потому что основной процесс никак не должен замедлиться – это ключевой момент.
Почему я и говорю про быстрый фронт, что мы уделяем основное время именно быстродействию.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.

Вступайте в нашу телеграмм-группу Инфостарт