Меня зовут Юрий Былинкин. Я работаю с 1С уже, наверное, лет 15 – обожаю, люблю и никогда не буду заниматься чем-то другим.
Я – архитектор 1С. Это такое размытое понятие, но один из смыслов, вкладываемых в этот термин – это контроль качества программирования, контроль качества исходного кода.

Для контроля исходного кода 1С есть прекрасные инструменты – например, EDT. Но я ей пока не пользуюсь, несколько раз делал подходы, у меня не идет. И во всех командах, в которых я работал, EDT не прижилась.
Еще можно выгружать конфигурацию в исходный код через стандартные средства конфигуратора, а потом использовать внешние системы версионирования и контроля качества кода. Платформа 1С научилась выгружать конфигурацию в исходный код 10 лет назад, возможность появилась в релизе 8.3.4. Есть инструмент GitSync, который позволяет это автоматизировать. Я всегда во всех командах это пропагандирую и делаю, и мне живется хорошо.
На слайде вы видите скриншот из программы Git Extensions, с помощью которой я вижу все изменения конфигурации.

Ты видишь, кто изменил код.
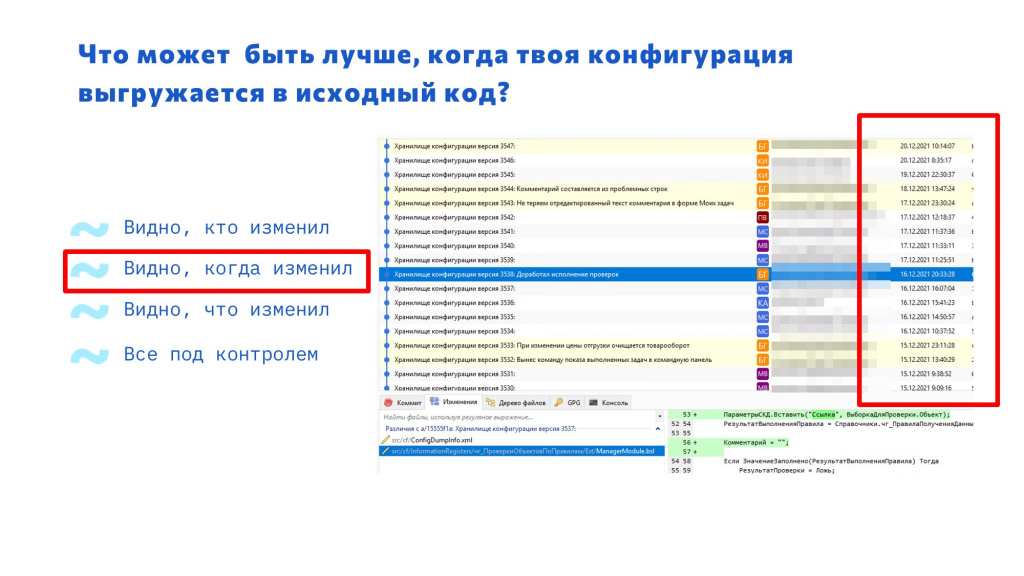
Ты видишь, когда было изменение.

Ты видишь, что именно изменили. Все офигенно, все очень хорошо. Кажется, что все под контролем.
Все ли под контролем?
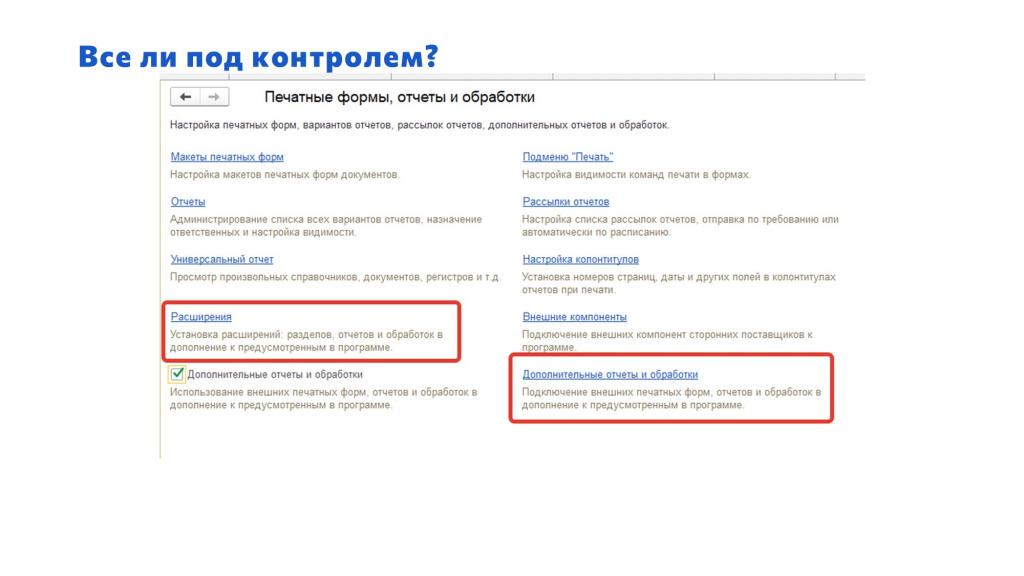
Но все ли под контролем?
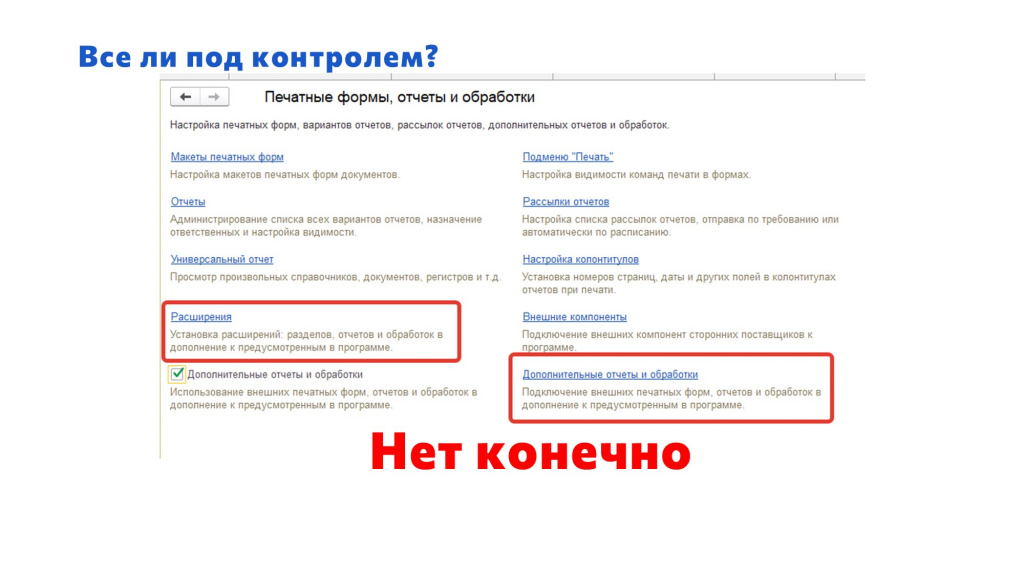
В БСП у нас есть возможность использовать внешние отчеты и обработки. Но кто-нибудь задумывался о том, что их тоже надо версионировать и следить за их состоянием?
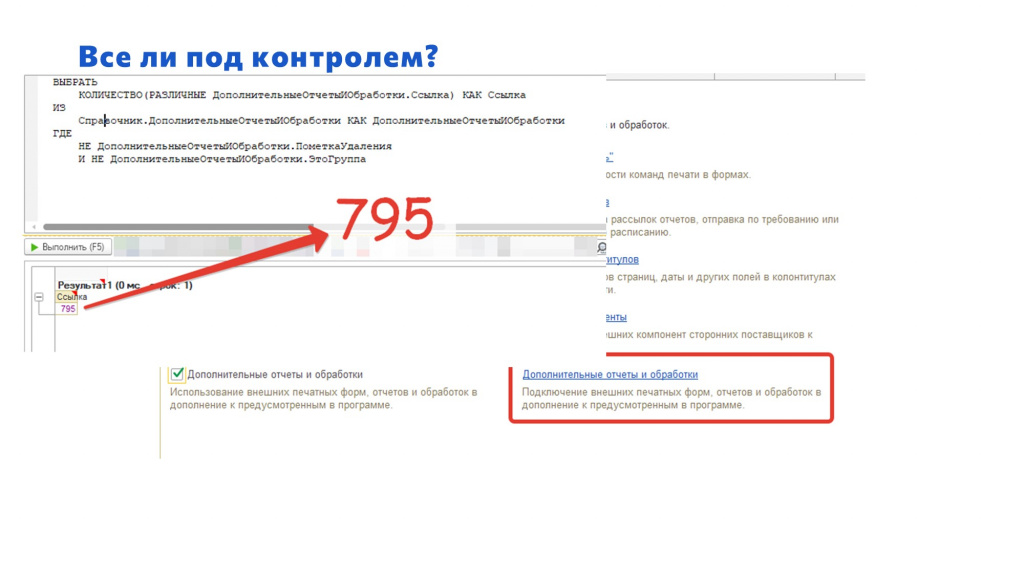
В нашей базе внешних обработок много. Я думал, что их штук 100.
Но когда я сделал запрос, чтобы узнать количество не помеченных на удаление элементов справочника «ДополнительныеОтчетыИОбработки», оказалось, что их у нас около 800. И это произошло буквально за три года.
Представляете, какой колоссальный объем доработок проходит мимо, и я за ними не слежу? Даже если я знаю, что там что-то меняется, я не могу отследить, что конкретно.
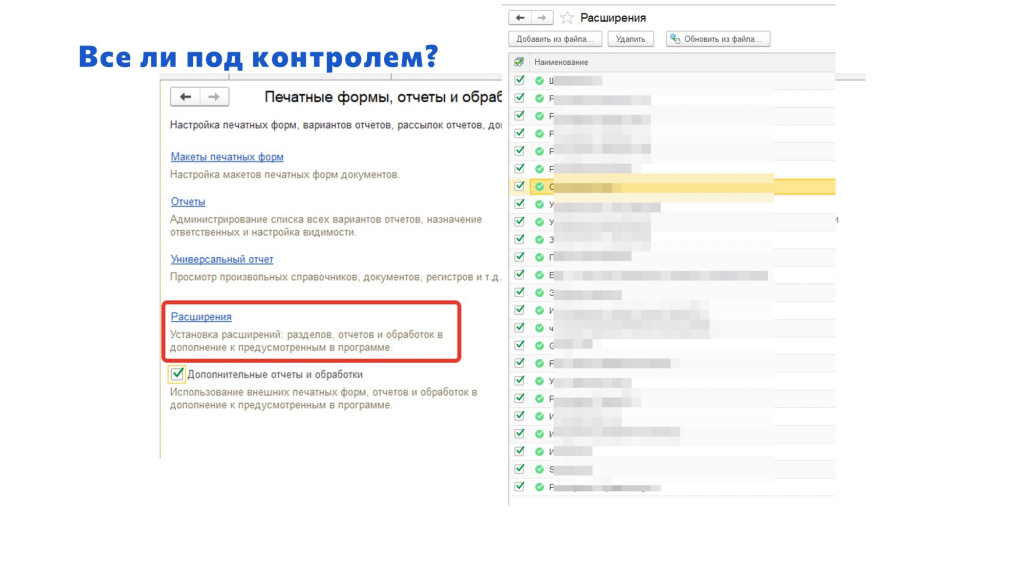
Расширения – это, опять же, странная вещь.
Они, с одной стороны, облегчают нам жизнь, потому что с их помощью можно на лету подправить программу, и это очень круто в случае критической ошибки. Да и вообще можно разрабатывать с помощью расширений, не меняя основную конфигурацию.
Но расширения – это, в том числе, и недостаток для архитектора, потому что следить за этим тяжело.
Пару лет назад на одном из митапов Инфостарта был доклад «Как выжить, если у тебя в базе больше 50+ расширений» – о том, какие сложности возникают при администрировании расширений, что приходится придумывать что-то, чтобы контролировать качество их кода, следить за тем, чтобы код в одной процедуре не перекрывал код в такой же процедуре в другом расширении и так далее. В общем, бардак.
Решение и инструменты

Исходя из этого, я поставил себе задачу – нужно как-то справиться с этим бардаком, с расширениями и внешними обработками.
Есть один подход, который я не очень приветствую – это административное решение задачи. Когда делают регламент, говорят: «Мы разрабатываем внешние обработки, и помещаем в базу только после каких-то процедур». Это все хорошо, но никто же не мешает человеку с админскими правами молча зайти в базу и поместить свою обработку. Конечно, есть организации, в которых разработчики не имеют доступа в рабочие базы, но таких мало, и я в таких не работал.
Поэтому я решил – раз ты не можешь справиться с этим бардаком, надо как-то его систематизировать, упорядочить.
И поставил задачу, что на сервер исходного кода должны попадать изменения не только конфигурации, но и расширений и внешних обработок.

Какие инструменты для этого использовать?
-
На стороне сервера исходного кода – конечно же, православный OScript. Некоторые его называют OneScript, кто-то еще говорит 1Script (ОдноСкрипт). Большое спасибо создателям OScript за то, что он теперь у нас есть.
-
На стороне базы 1С – я буду использовать http-сервис. Почему http? Потому что это просто.
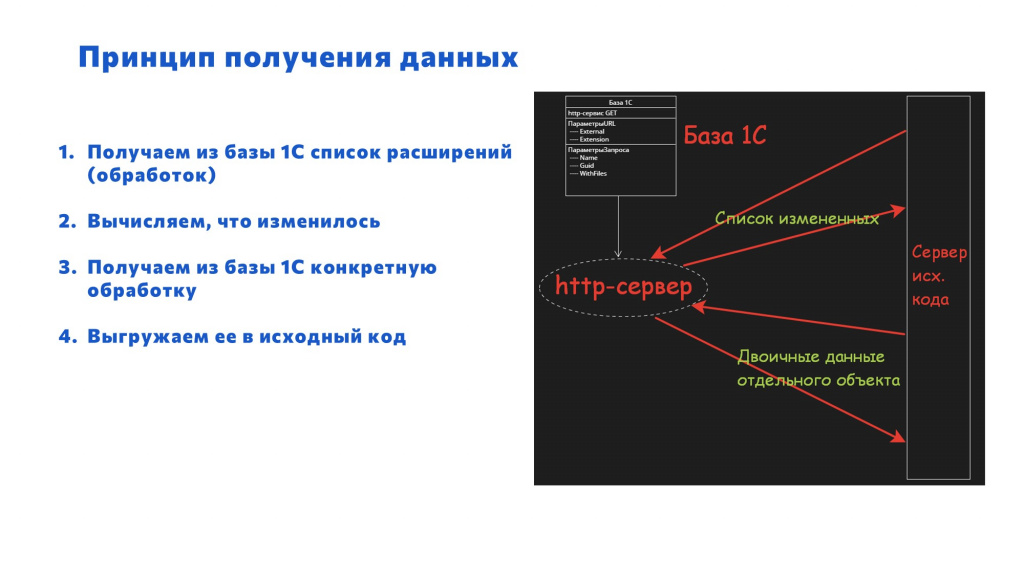
Схема такая:
-
Я буду собирать данные о внешних обработках и расширениях напрямую из рабочей базы – так у меня всегда будет актуальная информация.
-
В базе создаем свой http-сервис, он опубликован на http-сервере.
-
А скрипт, который располагается на сервере исходного кода, периодически опрашивает базу, что там появилось нового, и затягивает данные.
Выглядит интересно.
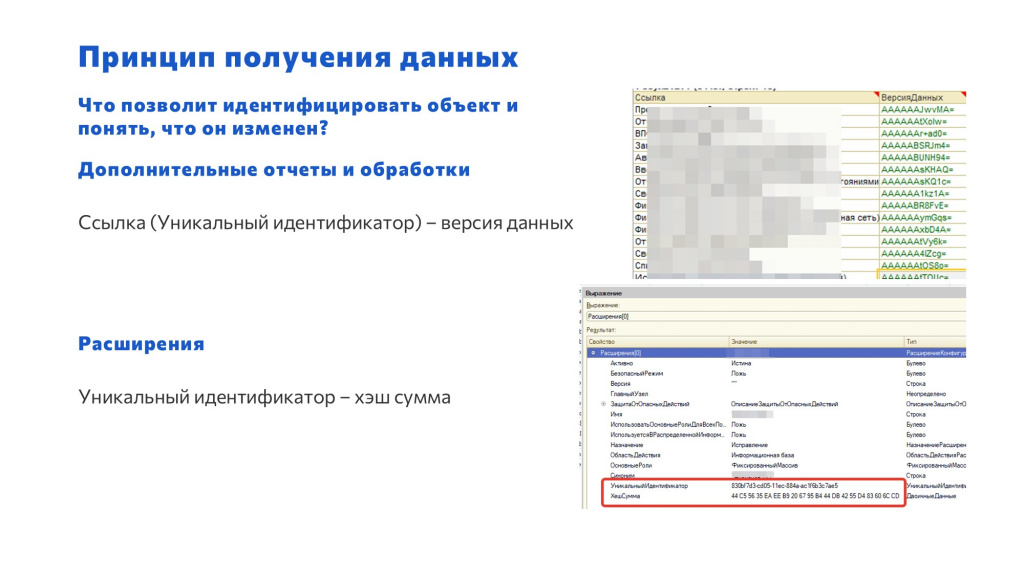
Итак, нам нужно решить один из основных вопросов – что будет являться главным идентификатором для внешней обработки или расширения?
-
И у внешних обработок, и у расширений, конечно же, есть наименование, но его можно поменять.
-
У элемента справочника «ДополнительныеОтчетыИОбработки» есть ссылка, из которой через метод УникальныйИдентификатор() мы можем получить уникальный идентификатор внешней обработки.
-
А у расширений для этой цели есть свойство УникальныйИдентификатор.
А как же я и сервер исходного кода поймем, что что-то изменилось? Хорошо, мы обратились к элементу внешней обработки, а как понять, что она изменилась?
-
Вспоминаем, что у всех ссылочных объектов 1С есть стандартный реквизит ВерсияДанных, и при его записи он автоматически меняется.
-
А у расширений есть не реквизит, а свойство, которое называется ХэшСумма.
Следовательно, если мы соберем данные о парах GUID – ВерсияДанных или GUID – ХэшСумма и запишем себе, то мы будем иметь некий слепок текущего состояния. И при следующем запросе данных из базы 1С мы можем получить только те объекты, которые изменились, и уже целенаправленно запросить их двоичные данные, чтобы дальше их как-то обработать.
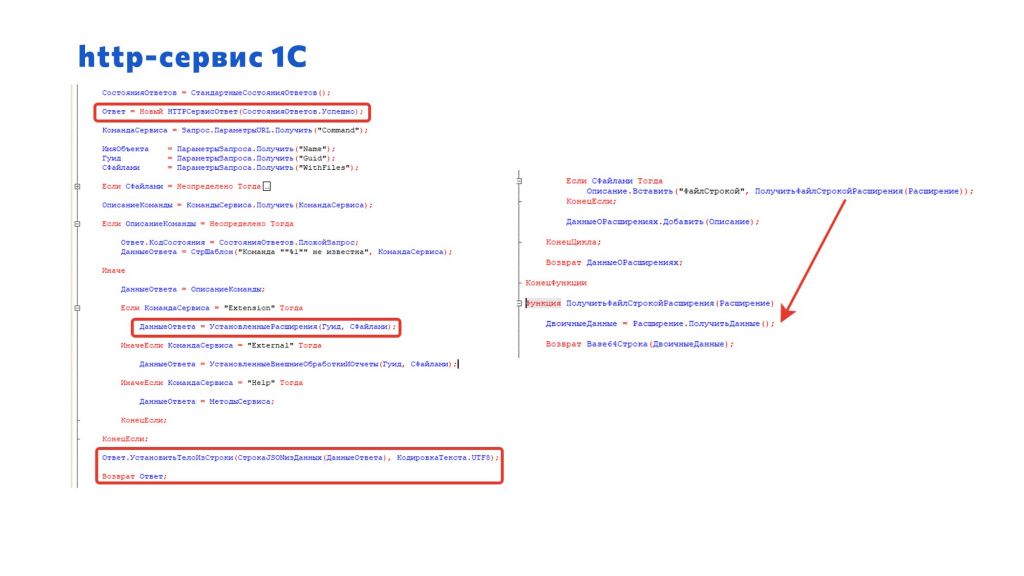
На стороне 1С код http-сервиса элементарный.
-
Мы анализируем свойства запроса, который к нам пришел.
-
В зависимости от команды, которую мы запрашиваем – «Extensions» для расширения или «Externals» для внешней обработки – мы передаем скрипту текущее состояние конкретного расширения или обработки.
-
После того как скрипт на стороне сервера исходного кода по изменению ВерсииДанных или ХэшСуммы распознает, что что-то изменилось, он уже целенаправленно запрашивает двоичные данные, которые мы шифруем через Base64Строка.
Код здесь действительно минимальный.

Что нам нужно сделать на стороне сервера исходных данных? Конечно, нам надо иметь установленный OScript, с этим проблем нет. И используем всего лишь пять библиотек, из которых три – основные:
-
1connector – это штука, которая позволяет в пару строчек обратиться к http-сервису и получить из него данные.
-
v8runner – это библиотека, которая позволяет в пару строчек прочитать изменения внешней обработки.
-
Git Runner – позволяет выгрузить все это дело в Git.
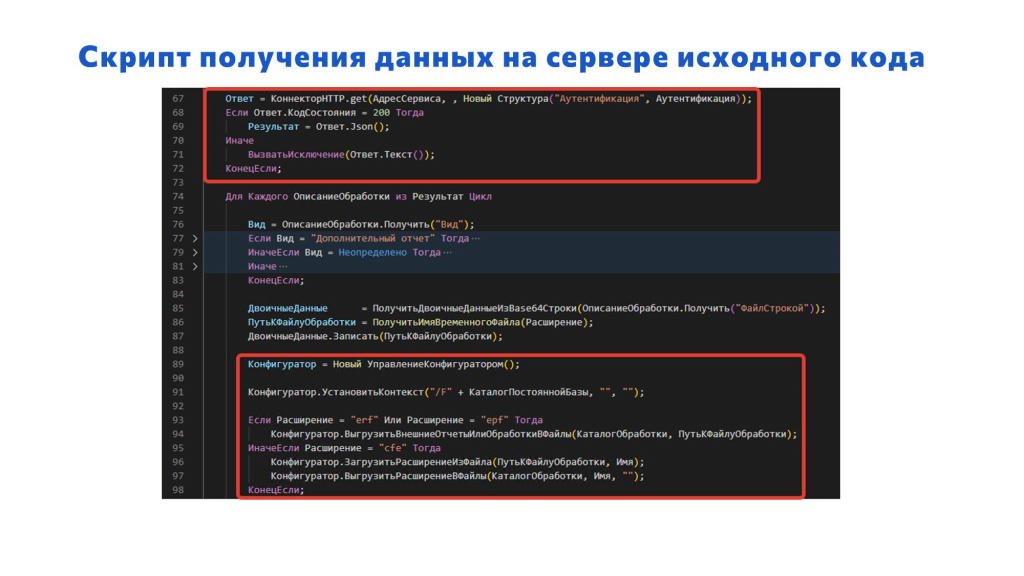
На слайде пример использования этих библиотек на стороне OScript.
-
Мы передаем HTTP-коннектору адрес HTTP-сервера, куда обращаемся и данные авторизации – куда же без нее:
Ответ = КоннекторHTTP.get(АдресСервиса, , Новый Структура(“Аутентификация”, Аутентификация)) -
В переменную «Результат» записываем ответ в формате JSON:
Результат = Ответ.Json() -
Дальше – работа с конфигуратором:
Конфигуратор = Новый УправлениеКонфигуратором(), -
Устанавливаем базу для него, чтобы все работало быстрее – считается, что на пустой базе внешние обработки могут выгружаться некорректно:
Конфигуратор.УстановитьКонтекст(“/F” + КаталогПостояннойБазы, “”, “”); -
Если это внешний отчет или внешняя обработка, вызываем метод ВыгрузитьВнешниеОтчетыИлиОбработкиВФайлы
-
Если это расширение, тогда нам надо сделать две операции: сначала загрузить расширение в эту базу методом ЗагрузитьРасширениеИзФайла, а потом выгрузить в файлы методом ВыгрузитьРасширениеВФайлы.
Всю низкоуровневую работу делают библиотеки OScript – большое спасибо их создателям. Мы сосредотачиваемся только на нашей прикладной логике: как понять, что объект изменен, выбрать папку, куда положить все это дело, и так далее.
Структура хранения данных
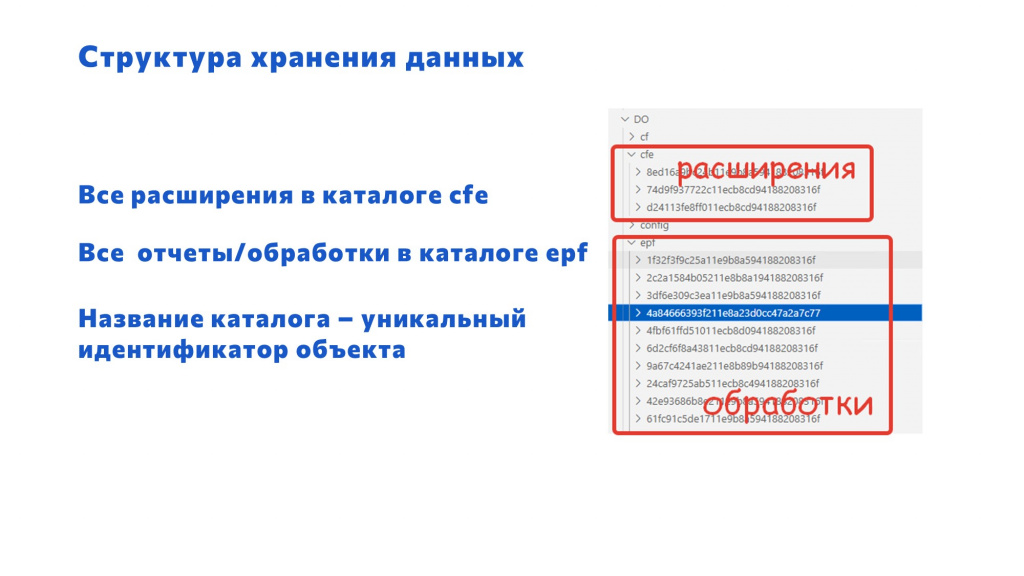
Какая структура хранения данных выбрана? Сначала идет каталог с проектом (ERP, или в данном случае на картинке у нас ДО – 1С:Документооборот). В нем есть три каталога:
-
cf – это стандартная выгрузка конфигурации в исходный код;
-
cfe – это расширения;
-
epf – это внешние обработки.
Причем в папках cfe и epf лежит столько каталогов, сколько внешних обработок и расширений.
И тут для человека не очень понятная штука – эти каталоги конкретных расширений и внешних обработок названы нечеловекочитаемо. Они названы GUID-ами. Объясню, почему так сделано:
-
Во-первых, обработку могут переименовать, и мы потом запутаемся – мы не поймем, куда ее класть.
-
А во-вторых, есть обход этого дела – сейчас я его покажу.
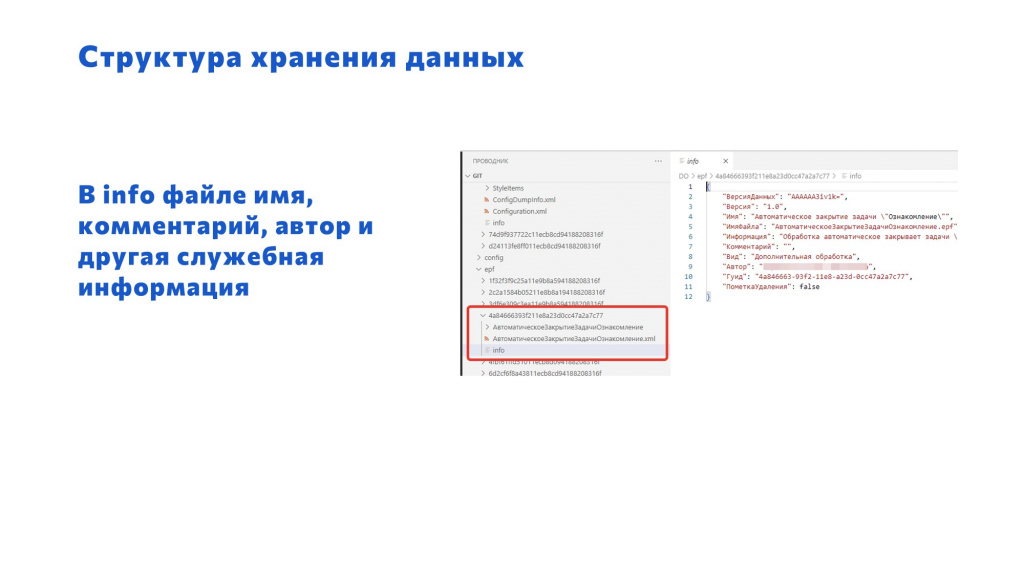
В каждой папке для расширения или внешней обработки лежит файл info, который мы добавляем сами с помощью OScript – это не стандартная выгрузка 1С, это наша доработка.
В этом файле info как раз и лежит вся информация о расширении и внешней обработке:
-
Имя;
-
Информация;
-
Комментарий;
-
Вид;
-
Автор;
-
Гуид;
-
и всякое другое.
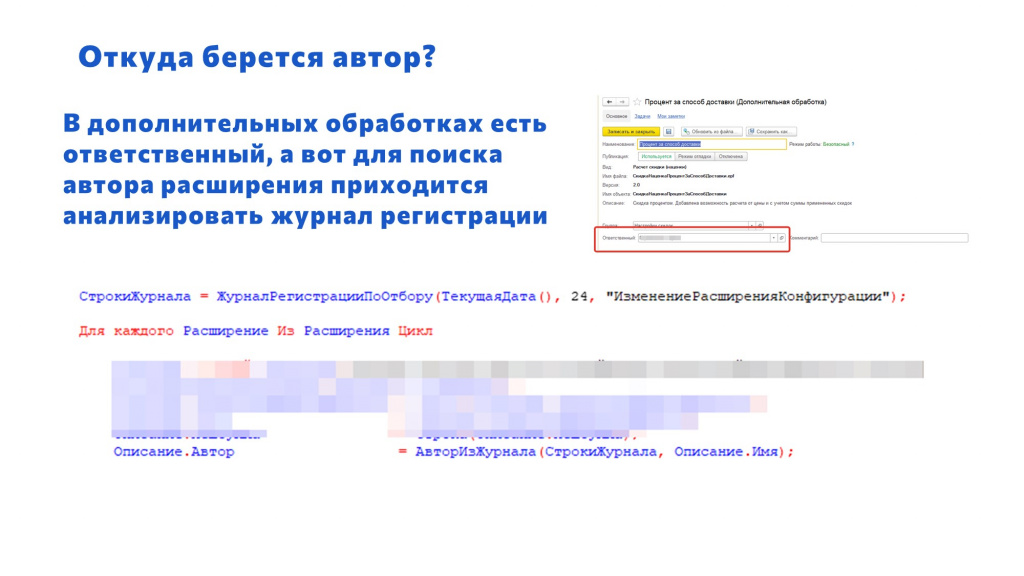
Вы, наверное, спросите – откуда возьмется автор? Мы же знаем, что для коммита в Git нужен автор. И тут у нас только два выхода:
-
либо использовать служебного автора – но тогда мы потеряем информацию о том, кто именно из разработчиков сделал эту доработку,
-
либо мы пойдем хитрым путем:
-
Для внешней обработки здесь все проще, потому что там есть реквизит «Ответственный» – он заполняется из последнего пользователя, который записал эту внешнюю обработку.
-
А чтобы понять, кто из пользователей поместил расширение, я в коде http-сервиса обращаюсь к журналу регистрации и ищу, кто последний менял расширение с таким-то наименованием.
-
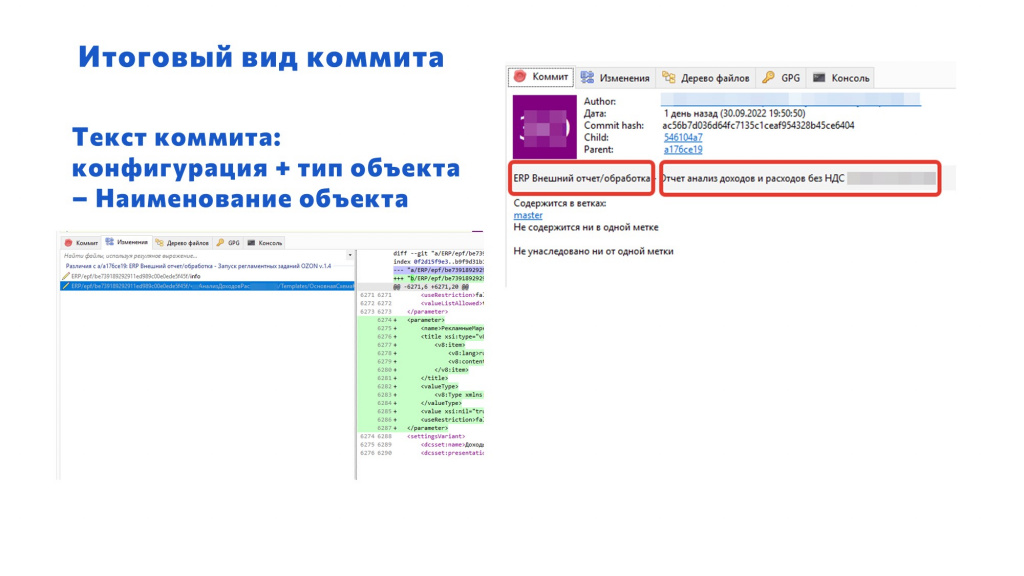
В конце концов в репозитории проекта появляются коммиты, в тексте которых есть:
-
название конфигурации;
-
обозначение, что это внешний отчет или обработка, или же расширение;
-
и название внешнего отчета, обработки и расширения.

Теперь в списке изменений за день видно не только изменения, полученные из выгрузки версий хранилища, но и изменения расширений и внешних обработок.
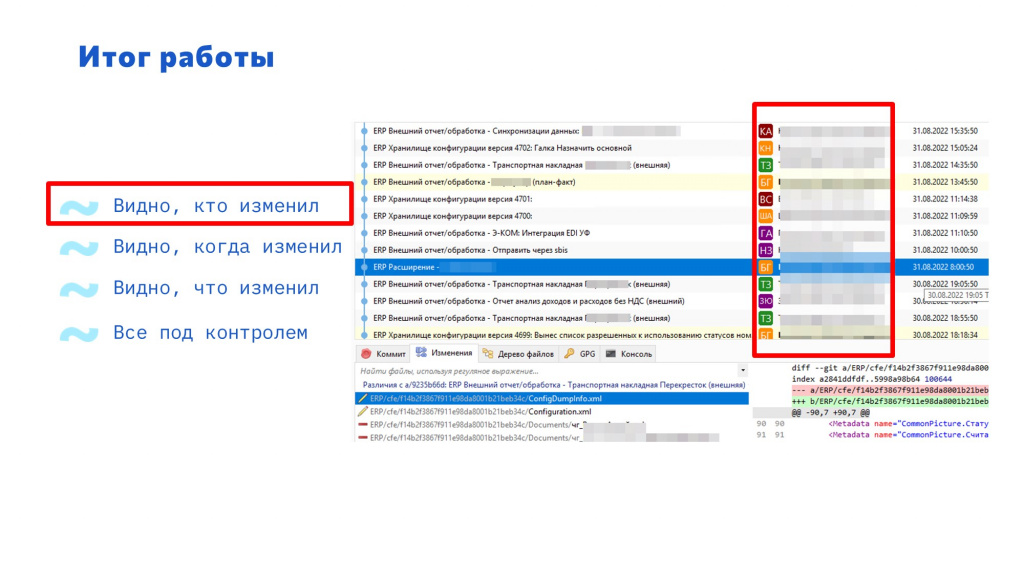
Опять же видно, кто это сделал.
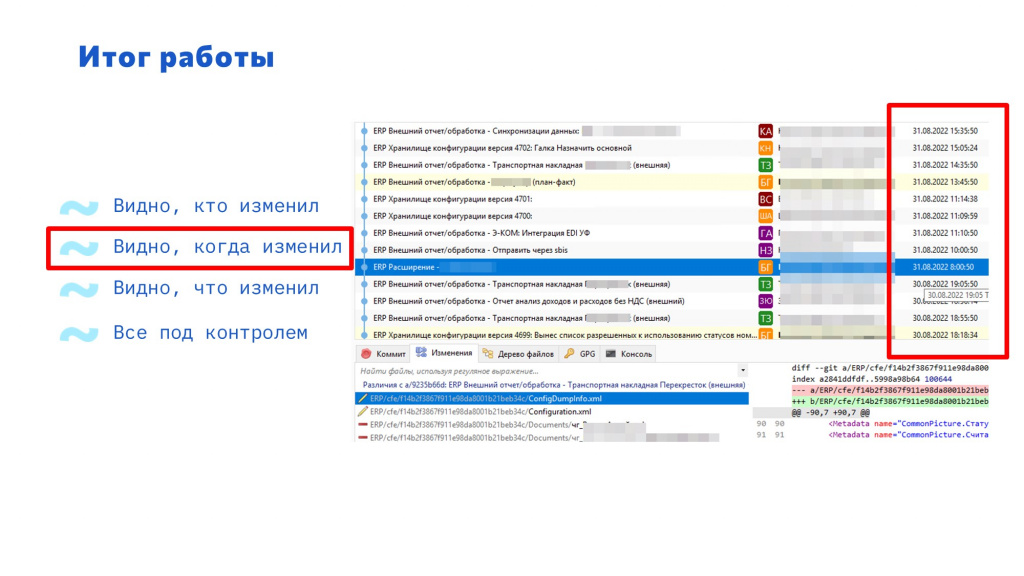
Когда произошли изменения.
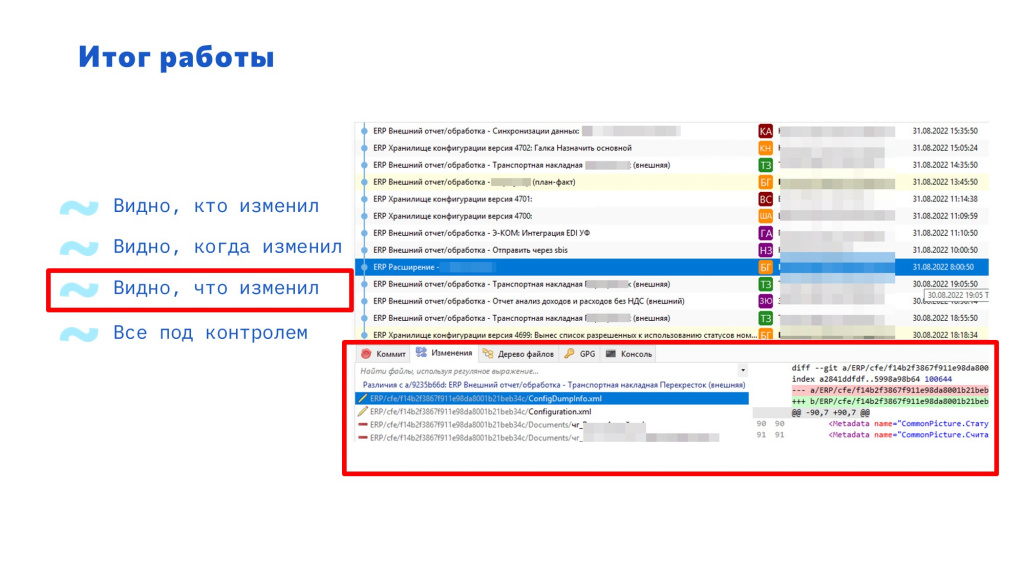
Что именно изменилось.
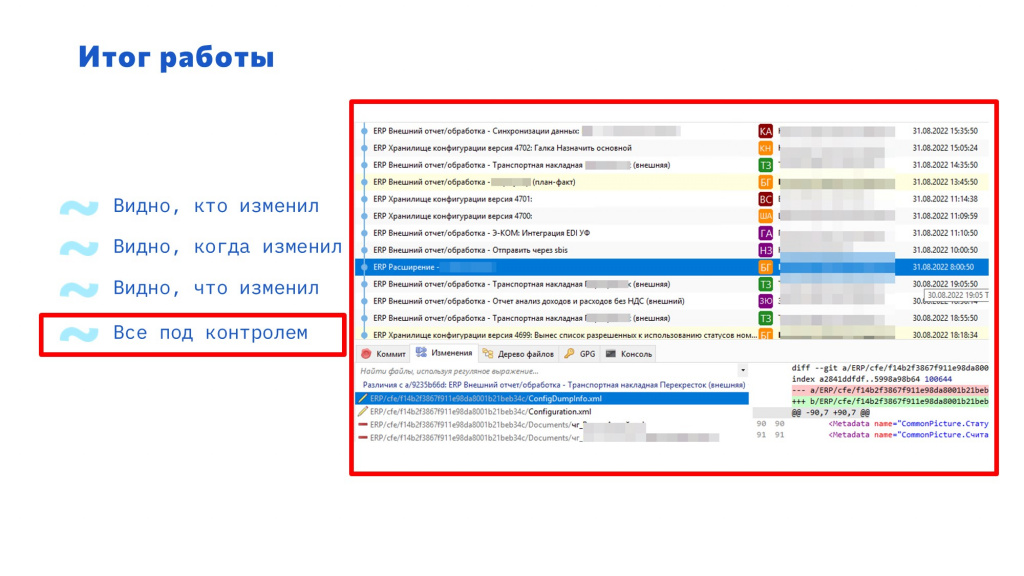
И теперь, наконец-то, все под контролем.

Получается, что релиз происходит каждый день, потому что, если в хранилище версии помещаются не каждый день, и не каждый день мы обновляем конфигурацию из хранилища, то внешние обработки и расширения меняются просто со страшной силой, со страшной скоростью. И это все теперь видно.

Немного обратимся к терминологии. В книгах есть определение:
Релиз – это набор артефактов, передаваемых пользователю.
Получается, что внешняя обработка или печатная форма, которую мы доработали и поместили в базу, чтобы пользователи могли ей пользоваться – это релиз в классическом его понимании.
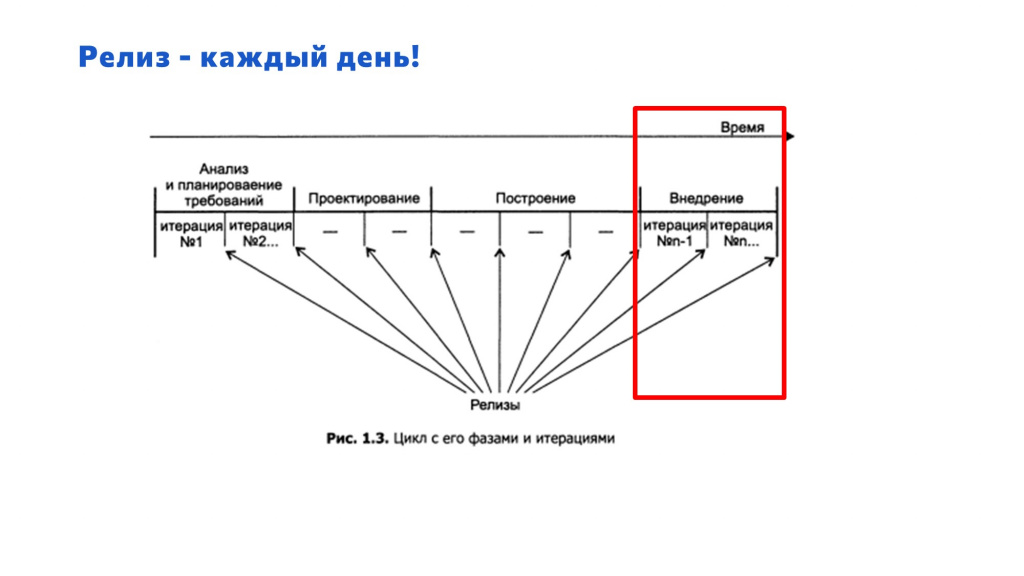
И итерации в разработке программного обеспечения, когда у нас сначала происходит планирование, потом разработка, потом поддержка, в том числе, итерации в ходе поддержки – это все тоже называется релизами.
Результаты

Что нам дало применение такого подхода:
-
Теперь я знаю вообще все, что происходит в базе;
-
Вижу вклад каждого программиста. При этом видны и забавные ситуации – например, вижу, что самый сильный программист в команде регулярно дорабатывает какую-нибудь печатную форму, потому что его просят. Я могу сделать выводы и убедить пользователей больше его не просить – пусть он лучше делает другие, более важные вещи.
-
Ускорилась реакция на проблемы. Раньше после обновления техподдержка иногда “взрывалась” тем, что что-то не работает. И искали, а кто же у нас менял конфигурацию? А кто же у нас последний работал с этим? Сейчас ничего искать не надо – открываешь Git и смотришь, все это есть.
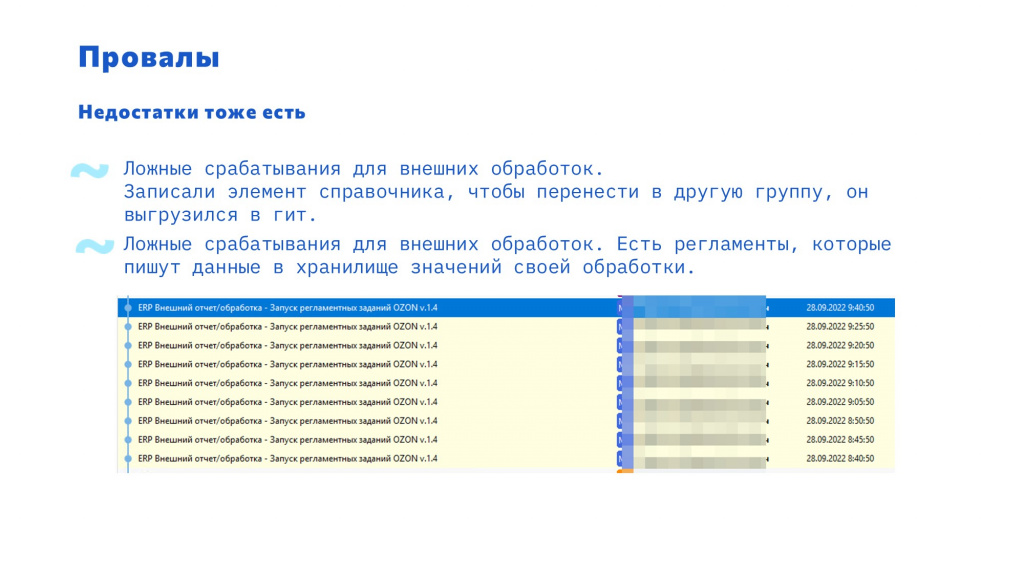
Также у этой схемы есть и недостатки.
-
У меня, как у архитектора, появилось немного больше работы, потому что я вижу больше информации. Но в моем положении, чем больше информации я вижу, тем мне легче потом работать;
-
И с такой схемой бывают казусы – например, переложили внешнюю обработку в другую папку, изменений нет, но происходит выгрузка в Git.
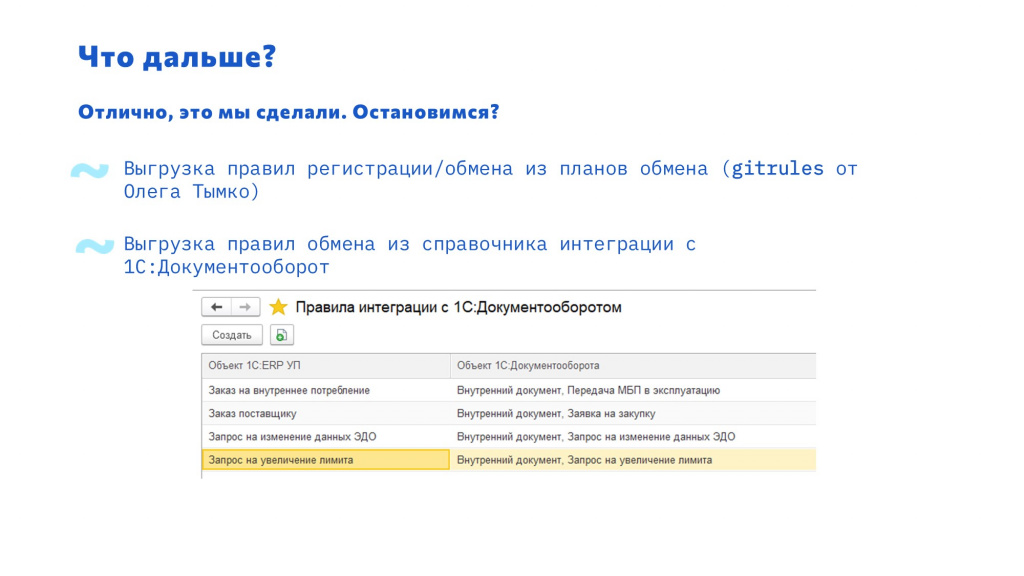
Что с этим делать дальше?
-
Дальше этот подход можно распространить вообще на все. Например, наши программисты меняют правила обмена. У нас есть прекрасный проект на OScript, называется gitrules, с помощью которого можно выгружать стандартные xml-правила обмена 1С в иерархическую структуру, состоящую из отдельных файлов на каждый объект метаданных и анализировать их изменения.
-
Или же, например, у нас есть обмен с интегрированным в ERP 1С:Документооборотом, где правила обмена описываются просто в справочнике – изменения в обмен вносятся и в режиме предприятия. Если возникает какая-то проблема, мы стандартно можем анализировать только исключения, возникающие при обмене с 1С:Документооборотом – но по ним невозможно понять, кто же что-то изменил. Можно использовать этот же подход – выгружать данные и версионировать их.
Заключение

Посыл моего доклада очень простой.
-
Многие сейчас уже научились выгружать конфигурацию в исходный код и этим пользуются. Это очень круто.
-
Но еще можно начать выгружать в Git внешние обработки и расширения и от этого словить тоже много пользы.

Попробуйте сделать это сами. Для этого ничего особенного не нужно – это все очень просто.
Вопросы и ответы
Получается, что мы сейчас можем составить слепок конфигурации, включая внешние обработки, сохранить в Git, и отследить изменения?
Да, конечно.
А вернуться к какой-то версии автоматически есть возможность или нет? Увидели мы изменения, дальше мы увидели, что кто-то сломал обработку, откуда мы возьмем предыдущую версию?
Естественно. Если мы говорим о версии конфигурации, то вообще нативно есть возврат к версии хранилища. Если мы говорим о версии расширения или внешней обработки, то мы получаем нужную версию Git и собираем обработку назад из тех данных, которые есть в Git.
Так как они выгружены через стандартные функции 1С по выгрузке в исходный код, их также можно и собрать.
Все это – задокументированные стандартные методы платформы?
Да, это все работает.
Получается, у вас внешние обработки заливаются централизованно. А разработчики следят за изменениями? Мержат как-то свои версии? Или один разработчик забрал версию, две недели с ней работал, а пока он с ней работал, другие разработчики уже оттуда ушли?
Такое тоже бывает, да. Это как раз инструмент для того, чтобы разобраться, что произошло.
А не было желания заставить разработчиков самостоятельно коммитить и мержить?
Были, но я не готов обучать людей на таком уровне.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.
Вступайте в нашу телеграмм-группу Инфостарт