Излюбленная тема последних двух лет «Как бы нам перейти на Postgres?» беспокоит всех только в части самого перехода рабочей базы. А о том, как потом эксплуатировать всю систему – редко кто думает.
РП-шникам главное перевести прод на Postgres и отчитаться перед начальством, что мы теперь импортозамещенные. Они не думают о том, как разработчикам теперь на новой среде разработки живется.
А дальше начинается масса страданий, потому что разработка и тестирование в большинстве случаев “временно” остаются на MS SQL. И это плохо, потому что нужно разрабатывать на той же среде, на которой потом будет работать прод. Все мы знаем, что MS SQL слишком любит 1С-ников и слишком многое им прощает. И ваш код, прекрасно и быстро работающий в MS SQL, при переносе из разработки и тестирования на прод с PostgreSQL может поставить базу колом. И вы никак это не отловите, пока разрабатываете на MS SQL.
Гетерогенная структура прода и контура разработки
В идеальном мире во время переезда прода с MS SQL на PostgreSQL в параллельном потоке точно так же с MS SQL на PostgreSQL переходят и среды разработки и тестирования.
Но в реальном мире вам вряд ли одобрят даже копию продовой площадки для PostgreSQL, потому что MS SQL еще не умер, он работает.
Я не говорю о тех продах, где переезжает одна база – там и так понятно, что контуры разработки и тестирования переедут синхронно с ней. Но на крупных площадках крайне редко бывает всего одна база – обычно баз много, не меньше 10. Они разные – типовые и нетиповые, маленькие и большие, некоторые из них работают 24/7, там куча нюансов. Из-за этого общий процесс переезда от самого начала и до конца может затянуться до года-полутора, а у некоторых еще дольше.
И получается гетерогенная структура. Для прода – PostgreSQL, для разработки – MS SQL.

Первыми с прода MS SQL на PostgreSQL обычно мигрируют небольшие типовые базы.
Там в целом все просто. Можно мигрировать через DT-шник. Не надо ничего выдумывать.
Небольшая база – понятие относительное. Небольшая база, по моему мнению, определяется не объемом, а тем, уложились вы в техокно ее переездом или нет.
-
Если у вас техокно – час, и вы за это время успеваете выгрузить из нее DT-шник и загрузить его в новую СУБД – у вас база небольшая.
-
Если выгрузка и загрузка через DT-шник не влезает в ваше техокно, у вас большая база, вам нужны другие решения – вам DT-шник не подходит.
-
Если у вас техокно – 3 дня, вы и 10 терабайт перегоните. Для вас тогда и 10 терабайт немного.
-
А если у вас техокно – 5 минут, для вас и 5 гигабайт критично. Вы не успеете за 5 минут перегнать DT-шником 5 гигабайт.
Поэтому нужно постепенно отвыкать от того, что «большая» или «небольшая» база – это размер. Большое и небольшое нужно измерять временем – его в отличие от дисков под базу не купить)
С версии платформы 1С 8.3.17 DT-шник загружается многопоточно. Количество потоков равно количеству ядер на сервере 1С, но на ПРОФ-лицензии платформы имеет ограничение в 12 ядер – она вам максимум может запустить 12 фоновых задач загрузки DT. Каждая фоновая задача будет брать свою табличку и DT-шник загружать в базу.
В итоге время загрузки DT-шника будет ограничено временем загрузки самой большой таблицы в вашей базе.
Либо можно упереться в то, что у средней по размеру таблицы будет много индексов – при разворачивании платформа должна будет создать все нужные индексы.
Чтобы понять планируемое время загрузки DT-шника, нужно сделать замеры в тестовом контуре. Желательно, чтобы железо тестового контура и прода было примерно одинаковое – тогда значение тестового замера не будет отличаться времени заливки на проде. Потому что выгрузка/загрузка DT-шника – монопольная операция. Там не существует блокировок и побочных нагрузок – просто взяли и перелили.
Таким образом, через перенос небольших баз, прод начнет постепенно мигрировать с MS SQL на PostgreSQL.
А что делать с разработкой? В идеальном мире вы должны в контуре разработки рядышком тоже поставить PostgreSQL.
Но не стоит забывать, что для PostgreSQL нужен Linux. Вы не можете на одной машине рядом с MS SQL поставить PostgreSQL – вам сначала нужно рядом Linux поставить.
Если вы в виртуализации – вам хоть как-то повезло, вы можете срезать мощность рядом на этом же хосте, дать мощность под Linux и на него поставить PostgreSQL.
А на железе вы ничего не обрежете и никак его не разделите – вам для разработки под PostgreSQL придется организовывать отдельный сервер.

Из-за того, что мы живем в реальном мире и в ограниченных бюджетах, разработчики остаются на MS SQL и по ночам выгружают себе DT-шники из Postgres-ового прода. Т.е. у нас разработка живет, нарушая правило – разрабатывать надо на той же среде, на которой работает прод.
Пока базы маленькие, не надо выдумывать какие-то огромные структуры – дампы или дейли-копии – всего лишь для того, чтобы у разработчика обновилась его копия базы.
Поэтому просто ночью блокируем базу на проде, выгружаем DT и затем при необходимости загружаем его в базу разработки и тестирования.

Когда у вас базы побольше (а мы уже договорились что такое большие и маленькие базы), и для их развертывания вы уже не укладываетесь в окно разработки, есть другой вариант той же самой операции.
Выгрузку и загрузку DT-шника в любом случае нужно делать монопольно.
На среде разработки, как ни странно, тоже может быть техокно, просто это другое техокно – это окно одного разработчика в ожидании, когда ему развернут базу.
Про это все забывают, но оказывается, когда разраб попросил обновить базу, он три часа вообще не работает. В развернутой базе он хотя бы смотрит в код и не работает)))), но он хотя бы думает о коде. А тут он вообще ничего не делает. Он сидит и гундит, что админы ничего не умеют делать – когда нет работы, у него срочно чешутся руки что-нибудь закодить.
И если ваш разработчик после заказа «Дай мне копию базы» ждет три дня (или больше) – это плохо. И когда вы в техокно разработки уже не влезаете, начинаются всякие схемы.
Смысл этой схемы в том, что:
-
Справа на присунке – реплика постгресового прода, куда у нас переехала база. Это не мастер, где работают пользователи. Мастер вообще никогда не должен знать, что такое бэкапы – все бэкапы делаются с реплики.
-
С реплики каждую ночь на отдельную машину с PostgreSQL льется полный бэкап кластера прода через pg_basebackup. Это происходит безусловно – без запросов со стороны разработчика, тестировщика и неважно кого.
-
Машина, которая будет получать полный бэкап, может быть не сильно мощной, но пространства на дисках у нее должно быть столько же, сколько у прода, а лучше – больше.
-
И так же ночью, после того как это закончилось, вы безусловно, без запроса разработки и тестирования, выгружаете DT-шник – тогда у вас каждую ночь есть выгруженный DT-шник с PostgreSQL. Важно, что выгрузка DT-шника в платформе 1С происходит в один поток. Это долго. Т.е. ваше техокно разработки тормозится не на загрузке DT-шника – загрузка многопоточная, ее можно распараллелить на имеющееся у вас количество ядер. А при выгрузке DT-шника ускориться нельзя. А теперь представьте, что в 1С:Бухгалтерии 6500 таблиц, и они выгружаются в один поток. Поэтому самая длительная операция для этого техокна – это выгрузка.
-
И потом, когда к вам приходит разработчик и говорит: «Обнови», у вас техокно состоит уже только исключительно из многопоточной загрузки DT-шника. Длительную однопоточную операцию вы выполнили ночью.
Почему здесь такая сложная схема? Потому что выгрузка и загрузка DT-шника – это монопольная операция. Чтобы выгрузить его с прода, надо выгнать пользователей из 1С. Не надо этого делать ради разработки.
Разработка – это фоновый процесс. Как бы странно это ни звучало, все разработчики нужны только для того, чтобы у пользователей все работало, а не для того, чтобы разработчикам платили деньги. Поэтому мешать пользователям ради процессов разработки нельзя. И если какая-то маленькая база, которую вы можете заблокировать на полчаса и никому не помешать в техокне прода, может еще сразу DT-шником выгружаться, то более-менее большую придется делать через какой-то буфер.
Среды разработки и тестирования отличаются от прода тем, что у них ужасно много занятого места на дисках. Они весят в 40-50 раз больше прода.
Потому что каждому разработчику нужно две базы: на первой он разрабатывает; а про вторую он год назад забыл, что она ему не нужна.
И у каждого тестировщика/консультанта тоже 2-3 базы. В первой базе у этого тестировщика месяц закрыт; во второй не закрывается; а про третью он тоже год назад забыл.
Поэтому для тех, кто занимается тестированием или разработкой, количество баз нужно смело умножать на 3-5. Если их 20 человек, на 3 умножили – объем дисков для разработки и тестирования должен быть в 60 раз больше прода.
В середине миграции, когда на прод PostgreSQL переехали не только маленькие и типовые, но и серьезные базы, сервер для PostgreSQL тоже становится больше.
Для серьезных баз процесс миграции с прода DT-шником практически невозможен – вы не уложитесь в техокно. Здесь на помощь приходит утилита от автономного сервера 1С – ibcmd.
У ibcmd есть параметр replicate – она вам среплицирует базу с MS SQL на Postgres.
Но есть несколько нюансов:
-
Критичные ошибки, которые не давали этой утилите корректно работать, убраны только в последних релизах платформы 8.3.23.
-
Хорошо то, что утилитой ibcmd версии 8.3.23 вы можете перегонять базы хоть от 8.3.17 – по соответствию версии платформы ограничений нет, потому что ibcmd не подключается к серверу 1С. Вообще. Она работает напрямую с СУБД.
-
Уровень совместимости конфигурации должен быть 8.3
-
Не получится запустить ibcmd на Linux и из нее подключиться к MS SQL. Сервер 1С, стоящий на Linux, не умеет подключаться к MS SQL. Поэтому при миграции с MS SQL на PostgreSQL ibcmd в обязательном порядке должна быть запущена на Windows.
-
Утилита ibcmd написана на Java. Она любит оперативную память, поэтому машинка, на которой запускается процесс репликации, не должна быть каким-то инвалидом. Это должен быть нормальный рабочий Core i9 и 64 Гб оперативной памяти. Пусть он у вас под столом, пусть он еще не сервер, но он должен быть мощным.
Почему она потребляет так много памяти? Это не утечка – это нормальная работа. Потому что она считывает данные с источника и не ждет, пока их запишет получатель – она их себе в память складывает. Она многопоточно тащит данные с источника, в нашем случае с MS SQL, и многопоточно отдает их в PostgreSQL.
Если у вас кончилась оперативка, то либо вы дали мало оперативки, либо не угадали с регулированием потоков.
Утилита ibcmd настолько крутая, что в ней можно регулировать количество потоков и на вход, и на выход, т.е. у источника можете указать количество потоков – сколько потоков читать, и у получателя – во сколько потоков писать.
Но здесь все равно нужно техокно – чтобы через ibcmd replicate получить консистентную выгрузку, база должна быть заблокирована. Это значит, что бизнес будет простаивать, а ваш SLA вместе с премией уйдет вниз. Поэтому нужно тестировать – смотреть, сколько времени занимает выгрузка, есть ли у вас столько времени, регулировать потоки, мудрить с этой машинкой, добавлять ей память и так далее.
Но в целом выгрузка через ibcmd сильно спасает. Дальше будет табличка, я покажу сравнение замеров перезаливки базы через DT-шник и ibcmd.
На этом этапе для контура разработки в большинстве случаев в целом ничего не меняется. Поэтому, через ibcmd с постгресового прода перегоняете базы, чтобы развернуть их в контуре разработки и тестирования. Тут уже базу блокировать не нужно. Да, разраб получит неконсистентную по мнению бизнес-логики базу. Ну и ладно. Разрабам не нужна 100% консистентность. Если нужна, вспоминаем сложную схему с тремя серверами: pg_basebackup, с него ibcmd и так далее. Но в большинстве случаев консистентность не нужна.
Пока утилита ibcmd не поддерживает исключение таблиц. Но если 1С реализует исключение таблиц, можно будет не гнать на разработку какие-нибудь тяжелые таблицы с вложениями файлов или таблицы версий и итогов.
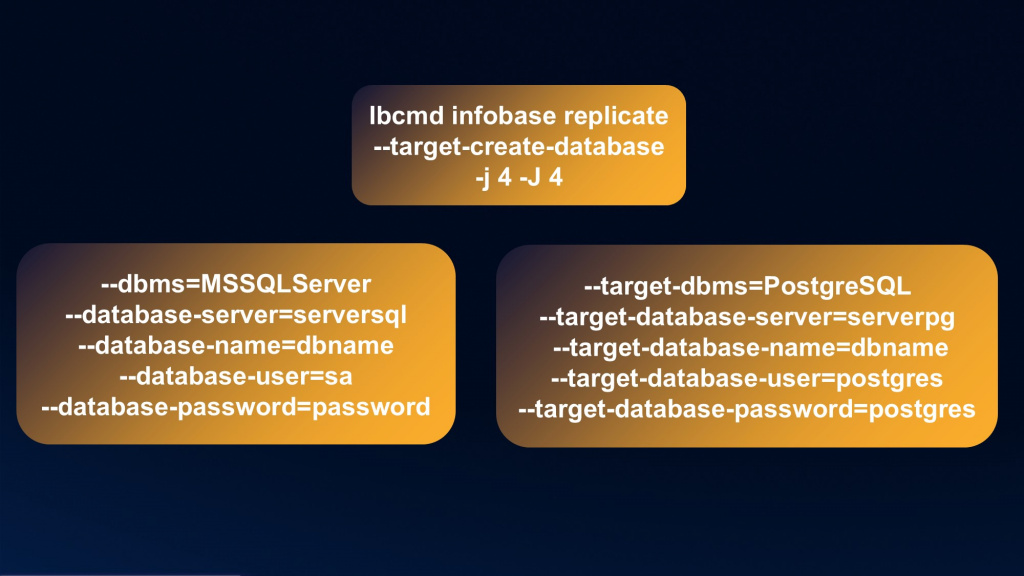
Еще раз про эту волшебную утилиту репликации ibcmd. На слайде – некоторые из ее параметров (не все). Полное описание параметров утилиты есть на ИТС.
Запускаем реплику через ibcmd infobase replicate
-
Если мы укажем параметр --target-create-database, утилита за нас сама на СУБД-приемнике создаст базу с указанными далее параметрами. Если не укажем – база уже должна существовать.
-
Есть возможность регулировки потоков для входа и выхода: j – у источника, J – у получателя. Можете с источника тащить в 16 потоков, а записывать в 4, и наоборот – как хотите. Очень крутая штука.
Параметры подключения к базе-источнику – в левой части слайда. Все пароли выдуманы и логины тоже. Обратите внимание, мы не указываем сервер 1С, а подключаемся к базе напрямую:
-
--dbms=MSSQLServer – указываем, что это MS SQL.
-
--database-server – имя сервера СУБД для источника.
-
--database-name – имя базы-источника.
-
--database-user – логин.
-
--database-password – пароль.
И то же самое – для базы-приемника:
-
--target-dbms=PostgreSQL.
-
--target-database-server – имя сервера СУБД для приемника
-
--target-database-name – имя базы-приемника.
-
--target-database-user – логин.
-
--target-database-password – пароль.
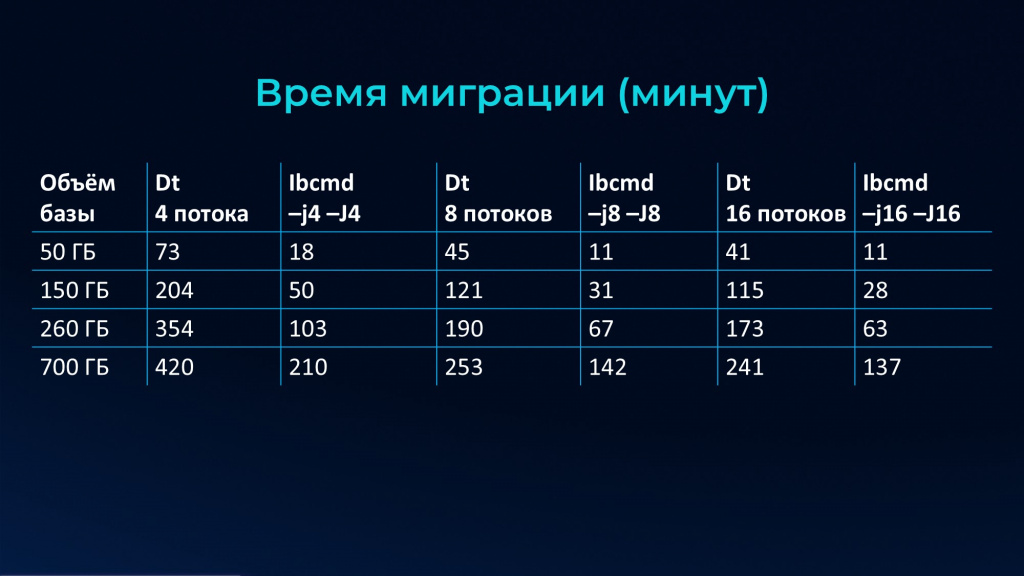
На слайде – таблица сравнения времени переноса базы через DT-шник и ibcmd. Специально указаны одинаковые потоки, чтобы все было по-честному.
Обратите внимание, что для выгрузки в 16 потоков разницы с 8-ю потоками почти нет – это потому что мы уперлись в одну таблицу.
Никто не предскажет, сколько вам надо указать потоков. Вы можете оттестировать это только на ваших данных, на вашем железе, на вашей сети.
Как можно предположить, со скольки потоков стоит начать?
-
Потоков не должно быть больше, чем ядер – на СУБД это логичное ограничение.
-
Посмотрите, из чего у вас состоит база, сколько у вас таблиц в топе по размерам. Если 80% места у вас занимает 10 таблиц, значит, вам нужно 11 или 12 потоков. Дальнейшее увеличение их количества ничем не поможет. Но и 4 потока будет явно мало, потому что каждому потоку придется по 2 раза большие таблицы переваривать.
Это прикидки для начала тестирования, каких-то волшебных цифр нет.
Но скорость у ibcmd потрясающая. Только представьте: выгрузка и загрузка базы 50 Гб через DT-шник теми же четырьмя потоками заливки занимает 73 минуты. Причем 50 Гб – это объем развернутой базы, не DT-шника – у DT-шника объем примерно в 8 раз меньше, чем база.
А перенос через ibcmd той же базы в те же четыре потока занимает 18 минут – в четыре раза быстрее.
Когда на PostgreSQL переведены почти все наши базы, наступает этап окончания миграции – на MS SQL осталась одна большая и самая страшная база.
Если позволяет техокно – берем ibcmd, и вперед.

И теперь, поскольку все базы в проде на PostgreSQL, разработка тоже переезжает с MS SQL на PostgreSQL.
Последнюю самую большую базу мы переносим через ibcmd с реплики прода (сервера, подключенного к проду через AlwaysOn). Вы помните, что у нас была обратная ситуация, когда мы с реплики PostgreSQL через ibcmd заливали на разработку. А для MS SQL реплика – это AlwaysOn, поэтому льем с него, пока все базы вообще не уедут с MS SQL.
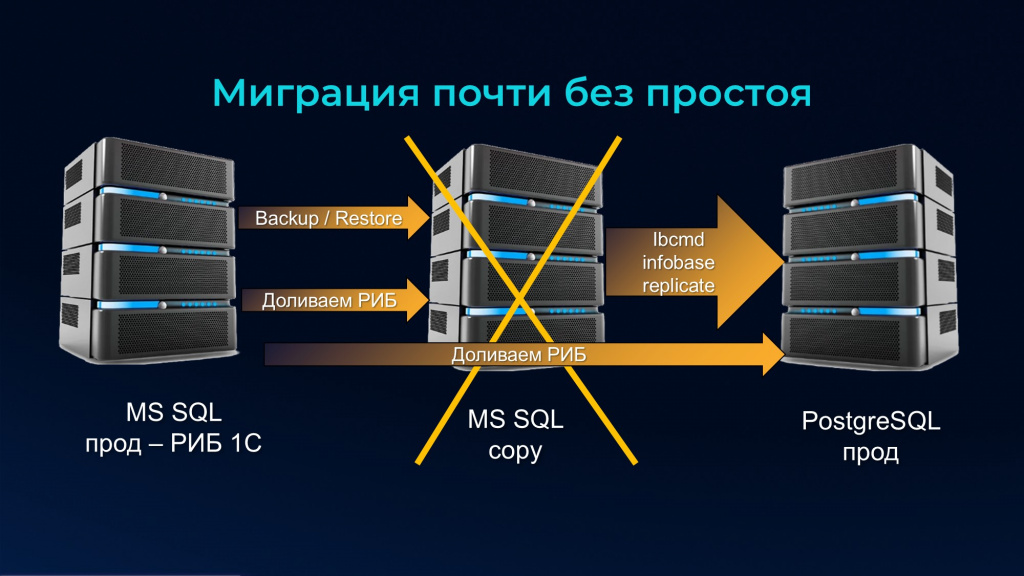
Но бывают ситуации, когда нам нужна миграция почти без простоя. Именно почти, потому что миграции вообще без простоя – это из ряда фантастики.
Если нужно мигрировать почти без простоя, делаем следующее:
-
В своей базе на MS SQL делаем РИБ 1С – объявляем узел, чтобы потом не создавать базу с нуля.
-
На отдельном сервере MS SQL мы из основной базы прода восстанавливаем бэкап с типом Full – уже с объявленным узлом обмена. Таким образом мы сразу избавляемся от формирования этого узла стандартным способом 1С.
-
Когда мы восстановили бэкап на копии MS SQL, мы эту базу подключаем к кластеру 1С с заблокированными регламентными операциями на уровне параметров базы в кластере 1С и настраиваем как периферийный узел. Поскольку мы сняли бэкап после того, как объявили здесь узел, у нас все изменения для узла в основной базе уже есть – она уже начинает копить все изменения в себе.
-
После того как мы восстановили бэкап и объявили его периферийным узлом, мы доналиваем его через РИБ. При этом у нас до сих пор все пользователи на MS SQL, мы никого не трогаем.
-
Дальше в нашей большой дружной семье появляется PostgreSQL. И мы его на него с копии MS SQL через ibcmd начинаем лить данные, предварительно заблокировав базу 1С на сервере 1С.
Еще раз: сделали РИБ, сделали бэкап, восстановили копию, доналили в ней данные через РИБ, остановили базу на уровне 1С, подключились к ней через ibcmd и перелили из нее данные на PostgreSQL. Причем сервер 1С для этого не нужен – ibcmd работает с базой напрямую.
-
После того как мы данные из копии MS SQL перелили на PostgreSQL она исключается из процесса – база копии на сервере 1С удаляется, все ее данные у нас уже на PostgreSQL.
-
Мы подключаем базу на PostgreSQL к серверу 1С и опять доливаем через РИБ– у нас в старом проде MS SQL зафиксированы все изменения с момента остановки копии и переноса ее через ibcmd на новый прод PostgreSQL. Даже если он у вас 3 дня льется – пусть льется.
До сих пор простой равен нулю! До сих пор мы не выгнали ни одного пользователя! Не остановили базу ни на одну секунду!
И только потом, когда все недостающие данные через РИБ перенесены, в самое низконагруженное время мы останавливаем базу прода MS SQL для пользователей – блокируем им туда доступ. Загружаем последние изменения на проде в PostgreSQL и назначаете его главным узлом. Это – все время простоя, которое есть.

С момента, когда все изменения перенесены, прод полностью переезжает на PostgreSQL, мы заменяем адрес и ип СУБД у продовой базы – все начинают работать там.
Причем базу MS SQL мы не удаляем, мы ее узел настраиваем как периферийный. И опять запускаем РИБ – на случай, если вы плохо протестировали работу своей основной базы под PostgreSQL. Тогда при проблемах, переключение обратно на MS SQL будет почти мгновенным – оно займет столько же времени, сколько вы переключали туда самый последний элемент.
Это, конечно, не чудо какое-то. Всего лишь, лучшая платформа в мире - 1С, предлагает нам такой сервис, и все работает. Поэтому:
-
Не забывайте, что у вас есть среда разработки и там техокно гораздо жестче.
-
Есть возможность реплицировать любые терабайты. Даже если у вас база в десятки терабайт, ее можно практически без простоя и с вариантом почти мгновенного отката реплицировать с MS SQL на PostgreSQL. Да, это требует большой подготовки, но бизнес почти ничего не заметит.
Дорошкевич Антон, с заботой о вас и вашей 1С.
Вопросы и ответы
Мы для периодического обновления контура разработки на MS SQL, помимо ночного архива, используем архив журнала транзакции. И если у программиста в течение дня возникает необходимость обновить или откатиться, мы с прода тащим только архив журнала транзакций.
Да, можно и так, но тут проблема в том, что на больших продах архив транзакций за день может превышать объем базы в несколько раз.
У PostgreSQL этот механизм работает с помощью WAL-файлов.
Да, механизм у обоих СУБД одинаковый
У нас есть один ночной архив. Но программистам нужны базы на разные моменты. Один просит состояние базы на два часа назад, другой просит на пять часов назад.
Вы разбаловали своих разработчиков))) Просто спросите: «Зачем?» Пусть укажет 10 пунктов ответа на «зачем». Для разработки такого не требуется почти никогда. Это мега редкий сценарий, я даже не могу его пока придумать сходу.
Вы говорите о том, что продуктив на PostgreSQL, а разработка на MS SQL, и от этого вся презентация идет дальше. А почему бы не сделать наоборот: разработку на PostgreSQL, и пускай программирует с учетом PostgreSQL? Заодно качество кода повысится.
Можете так сделать, какая разница – вы получите те же проблемы с миграцией баз, только наоборот. Как вы копии разрабам догонять будете, если прод на MS SQL? Все то же самое, только левую картинку с правой меняете.
Как побочный эффект – качество кода точно улучшится!
Когда утилита ibcmd создает базу сама, она корректно раскидает индексы и данные по табличным пространствам на PostgreSQL или лучше сначала создать базу средствами платформы?
Лучше это затестить – не знаю, учитывает ли ibcmd при инициализации базы данных настройки кластера v81c_data и v81c_index.
Если не учитывает, это похоже на ошибку платформы, и тогда надо об этом написать в 1С.
Вообще использование отдельных табличных пространств для данных и индексов – крайне редкий сценарий. Мало кто в реальности разгоняет индексы от базы по табличным пространствам, потому что все равно все упирается в одно СХД.
Но в целом сценарий живой, он поддерживается платформой.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.

Вступайте в нашу телеграмм-группу Инфостарт