Рамка

На экране можно разместить одну рамку программным способом. Анализируются только те объекты, которые попадают в рамку. Это сделано для того, чтобы указать, где читать, и в целом, для ускорения работы алгоритмов.
Рамка задается в процентах от объекта ActiveCV (окошка предпросмотра) вот так:
hashMap.put("CameraSetFrame","20_45_80_55")
Раньше было несколько рамок, но теперь ActiveCV вписано в экраны и опыт взаимодействия изменился. В этой гифке оператор держит рамку, в которой происходит непрерывное считывание и запись в поле ввода на экране (несколько раз в секунду). По сути одной рамки более чем достаточно, так как ее двигают по кадру.
Распознавание лиц

Распознавание лиц уже было, но сейчас оно сделано по-другому. В обработчик падает массив ID и base64-изображений лиц и дальше в обработчике уже сами решайте, что с ними делать и куда отправлять на распознавание (на гифке в примере нет никакого распознавания - изображения просто выводятся в список). Также как и остальные объекты ActiveCV, лица можно подсвечивать и подкрашивать, например, можно красным показать лица, которые не должны находиться на объекте в эту смену, а зеленым – остальных.
Сканер документов

Отличный сканер документов от Google. Назначение – получать подготовленные (выровненные, обрезанные, выровненные по тону) изображения документов. Либо с целью дальнейшего распознавания, либо просто с целью прикрепить в БД для хранения как есть.
Сканер работает как в base64, так и передает ссылки на файлы (в режиме mm_local). В примерах оба варианта.
Дополнительное распознавание текста с помощью EasyOCR. Распознавание русского алфавита и трудночитаемого текста
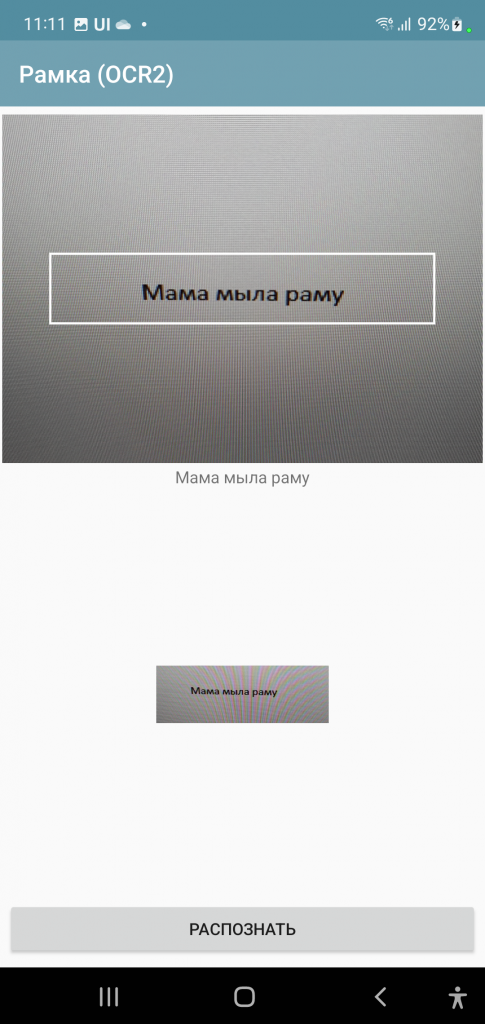
Адаптировал EasyOCR для Андроид и специальную модель CRAFT (с измененной архитектурой и переобученной на дополнительном датасете) для лучшего распознавания точечной маркировки.
Все это выпускается не виде версии из плей-маркета, а в виде отдельного apk ввиду большого объема (GooglePlay имеет ограничение)
Минус данного подхода - работает долго. Поэтому тут не используется концепция ActiveCV (псевдо-дополненной реальности и подсветки бизнес-данных в кадре). Вместо этого просто навел рамку, отсканировал, подождал, получил результат. Ну либо можно получать картинки (например, со сканера документов выше) и распознавать оффлайн на устройстве.
Предполагаю, что LLM скорее всего вытеснят классические OCR, но не полностью. За ORC – скорость и возможность оффлайновой работы. Какие функции остаются на стороне Simple, как мобильного фронта:
- Распознавание в видеопотоке артикулов или других текстовых идентификаторов – тут нужна и скорость и оффлайн. Т.е. реализация концепции ActiveCV - подсветка бизнес-данных в кадре. Ну и прочая оффлайн-идентификация
- Подготовка изображения для передачи для распознавания (например, сканер документов выше)
Для работы примеров понадобится версия 14.42.00, ее можно скачать на моем сайте https://simpleui.ru/
Конечно же, Телеграмм-канал проекта, в котором масса всего полезного: https://t.me/devsimpleui
Вступайте в нашу телеграмм-группу Инфостарт