Меня зовут Станислав Баташов. Я старший разработчик в подгруппе разработки прикладных решений в группе финансовых решений департамента ERP. Мы занимаемся одной из основных 1С-систем в OZON – системой УКФ (Управление корпоративными финансами), которая представляет собой конфигурацию на обычных формах платформы 1С.
-
Это одна из самых нагруженных систем.
-
Наша команда разработки состоит более чем из 10 человек, которые постоянно коммитят код.
-
Размер нашей базы составляет более 10 терабайт и постоянно растет.
-
Конфигурация на обычных формах.
-
Конфигурация используется с 2012 года, поэтому вы можете представить объем изменений, внесенных за это время.
-
Кроме того, у нас много интеграций по HTTP и com, а также используются хранимые процедуры в соседних системах.
Выбор фреймворка и общие принципы unit-тестирования
Мы тестируем с помощью решения YAxUnit – open-source фреймворка, разработанного компанией BIA Technologies.
https://github.com/bia-technologies/yaxunit
Модульное тестирование, блочное тестирование или unit-тестирование (англ. unit testing) – это процесс в программировании, который позволяет проверить на корректность отдельные модули исходного кода программы, наборы из одного или более программных модулей вместе с соответствующими управляющими данными, процедурами использования и обработки.
Для разработчика это, прежде всего, быстрая проверка на регрессионные ошибки. Тестирование происходит непосредственно на машине разработчика, в конфигурации и базе разработчика, с помощью кода, который он понимает и может сопровождать самостоятельно.
Наша система критически важна для бизнеса, и нам необходимо обеспечить ее стабильность на длительной дистанции. Unit-тестирование – один из ключевых инструментов для достижения этой цели.
У Татьяны Головкиной была статья, в которой она рассказывала про наш тестовый контур. Одной из частей этого контура является unit-тестирование. Мы тестируем на копии продуктовой базы, то есть полноценной копии прода. Кроме того, на этой среде выполняются и другие основные тесты. Наши тесты запускаются в контейнере, поэтому код должен корректно работать как на Linux, так и на Windows.
Проблемы внедрения: технические и человеческие факторы
Хочу рассказать о проблемах, с которыми мы столкнулись при внедрении этого процесса – в частности, при работе с обычными формами.
На самом деле, серьезных сложностей не возникло. Время от времени появлялись проблемы во фреймворке. Однако благодаря отзывчивой команде разработчиков фреймворка мы оперативно получали помощь и быстро устраняли неполадки. У них есть удобный чат в Telegram, где можно задать вопросы и получить поддержку.
Отдельной проблемой оказалась работа с людьми. У них возникает множество вопросов. Один из них: «Зачем unit-тестирование разработчику?»

Самое главное преимущество unit-тестирования заключается в том, что ошибки обнаруживаются до того, как код попадет в хранилище. Это обеспечивает более быструю и тщательную проверку кода, а также сокращает объем ручного тестирования для самого разработчика. Можно оперативно проверить изменения и сразу отправить их, не тратя дополнительного времени.
Правда, писать тесты сначала может быть долго – нужно привыкнуть к стилю написания кода по правилам фреймворка. Однако со временем это становится гораздо проще, главное – набить руку и привыкнуть. Кроме того, если создать собственные вспомогательные инструменты и использовать их при тестировании, это значительно ускорит процесс написания тестов.
Что касается самого синтаксиса фреймворка, его называют «текучим интерфейсом» (fluent interface). Некоторых разработчиков он сначала пугает, они задают вопрос: «Это вообще 1С?» и называют его «не 1С-овским-кодом».

На самом деле это именно текучий интерфейс, который упрощает чтение кода в тестовом расширении. По факту, каждый метод возвращает контекст выполнения, поэтому следующий метод можно вызывать по цепочке.
Также возникал вопрос: «Можно ли использовать существующие данные из базы?» Разработчикам часто лень создавать много тестовых данных, требующих написания большого объема кода, поэтому они предпочитают искать и использовать уже имеющиеся данные по идентификаторам или номерам. Однако лучшей практикой является использовать те данные из базы, которые необходимы для запуска системы – не для конкретного теста, а просто для запуска, чтобы она могла работать. Остальные тестовые данные правильнее создавать.
Следующей проблемой стало управление процессом тестирования. Для эффективного управления тестированием необходимо выделить ответственного человека или инициативную группу. Эта группа должна определить общий подход к тестированию, заниматься сопровождением и обновлением инструментов, а также обучать сотрудников, чтобы вся команда двигалась в одном направлении. Без такой организующей инициативы добиться результата сложно.
Кроме того, возникли сложности при разработке непосредственно в конфигураторе. Основная проблема здесь – это текучий интерфейс фреймворка. Из-за отсутствия подсказки синтаксиса в конфигураторе работать с ним неудобно. Приходится либо копировать код, либо запоминать названия методов, либо использовать сторонние инструменты. Расскажу, как мы пытались решить эту проблему.
Решения проблем с написанием тестов в конфигураторе
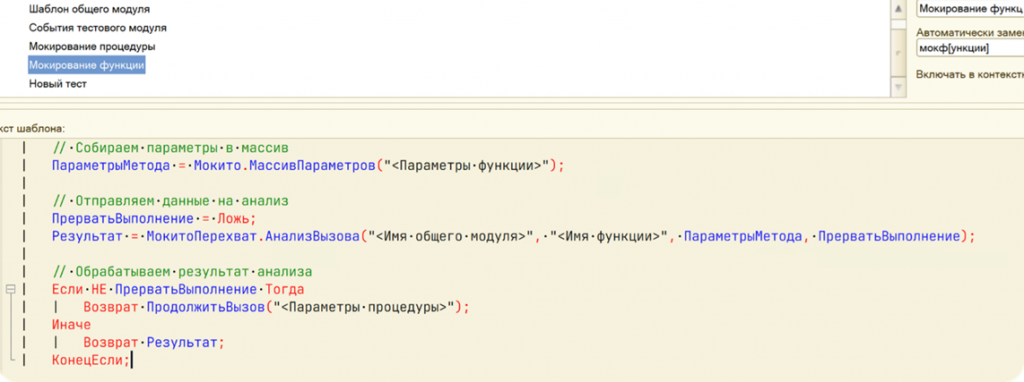
Один из вариантов решения – использование шаблонов. Это стандартный механизм подсказок в конфигураторе, который можно применить для улучшения ситуации. В шаблоны можно добавить как большие фрагменты кода, так и небольшие конструкции, которые будут автоматически подставляться при вводе определенных символов.

Другой подход – использование модулей-помощников. На изображении показаны модули проверок, куда мы поместили общие проверки, например, для тестирования проведения документов. Это что-то общее, что нет необходимости переписывать каждый раз.

Модули-помощники также применяются для централизованного создания и управления тестовыми данными. Такой подход позволяет сократить объем кода в самих тестах и сделать его более читаемым и понятным.
Еще один вариант – использование внешних инструментов. Например, решение TurboConf работает напрямую с исходным кодом конфигурации и обеспечивает подсказку синтаксиса изнутри. TurboConf видит достаточно много контекста, что позволяет получать подсказки по нажатию клавиш.
Принципы написания тестируемого кода и unit-тестов
Теперь о том, что нам потребовалось сделать, чтобы наша команда начала тестировать.

Необходимо было сделать так, чтобы код был тестируемым. Это значит, что входные параметры должны быть понятными и читаемыми, их не должно быть 10-20. Они должны быть хорошо скомпонованы, и мы должны понимать, что они делают.
Так же было бы хорошо, чтобы код был чистым и понятным, и чтобы метод выполнял не все сразу, а делал одно конкретное назначение: мы создаем документ, отправляем почтовое сообщение, может быть что-то еще, но он должен делать что-то одно.
Давайте вспомним, какими вообще должны быть unit-тесты.
-
Unit-тест должен проверять одну единицу поведения. В нашем случае это, например, проверка проведения документа или отправка сообщения. Это не обязательно какой-то один маленький метод, а скорее набор методов, объединенных одним бизнес-действием.
-
Unit-тест должен быть быстрым. По метрикам, которые рекомендуют при тестировании – это 2 секунды. Однако для 1С, где тесты работают непосредственно с базой данных, допустимо немного больше – до 5 секунд. Но все зависит от вашей системы, кода и нагрузки.
-
Кроме того, тесты должны быть изолированы друг от друга, то есть не должны влиять на результаты других тестов. Они должны быть атомарными – выполняться независимо и не мешать друг другу.
Мы используем паттерн AAA для написания тестов. Тест делится на три части. Это не техническое разделение на функции, а скорее визуальное или методологическое деление кода теста.
-
Первая часть – подготовка (Arrange). Здесь происходит подготовка тестовых данных и среды,
-
Вторая часть – действие (Act). Это непосредственно вызов тестируемого метода.
-
Третья часть – проверка утверждений (Assert). Здесь мы проверяем, соответствуют ли результаты работы кода нашим ожиданиям.
Теперь разберемся, какой код нужно тестировать.
-
Первое, что нужно тестировать – это программный интерфейс. Это экспортные методы из области программного интерфейса. Есть служебный программный интерфейс, а мы говорим именно о программном интерфейсе, который планируется поддерживать и не изменять в дальнейшем.
-
Также следует тестировать события объектов: проверка проведения, запись, обработка заполнения и т. д.
Что еще можно тестировать? С некоторыми оговорками:
-
Сложную бизнес-логику. Если логика сложная, то она важна, и ею определенно нужно заняться.
-
Важная бизнес-логика. Даже если она не сложная, но важна для бизнеса, ее тоже необходимо поддерживать и регулярно проверять.
-
Части сложных механизмов. Это может быть что-то из первого и из второго пункта. Разбиваем сложные механизмы на части для упрощения сопровождения и тестирования. Важно понимать, что скорее всего это не программный интерфейс. Эти методы нужно будет вынести в расширение, как экспортные. Но нужно сделать оговорку, что это не самая хорошая практика. В дальнейшем придется делать это по-другому: делать эти методы экспортными и заниматься рефакторингом и изменением этого кода.
А теперь посмотрим, что тестировать не нужно.
-
Тривиальный код. Это код, выполняющий простые действия, результат которых очевиден. На тестирование такого кода тратить время не стоит.
-
Неиспользуемый код. Поскольку мы часто работаем с конфигурациями вендоров или имеем дело с большим объемом легаси (напомню, нашей конфигурации уже 12 лет), в системе много неиспользуемого кода. Это может быть функционал, от которого бизнес отказался, или ставший ненужным со временем.
-
Приватные (неэкспортные) методы, которые не входят в предыдущие пункты. Это неэкспортные методы, которые будут покрыты тестами при вызове их из экспортного, поэтому на них не стоит обращать внимание.
Когда и как писать unit-тесты
Существует два основных подхода к написанию тестов:
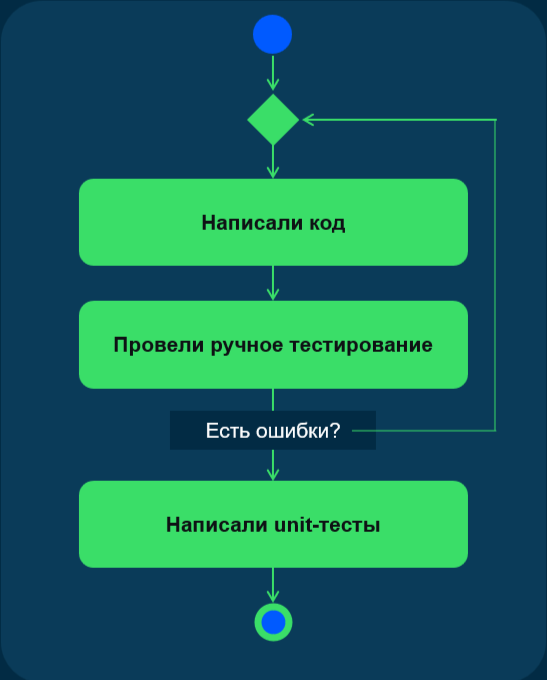
После написания кода. Разработчик пишет функционал, проверяет его работу вручную. Если находятся ошибки, код переписывается и дорабатывается до рабочего состояния. Только после успешной ручной проверки пишутся unit-тесты. К этому моменту у разработчика уже есть понимание, как работает код, и есть практический пример его использования, который можно положить в основу тестов.
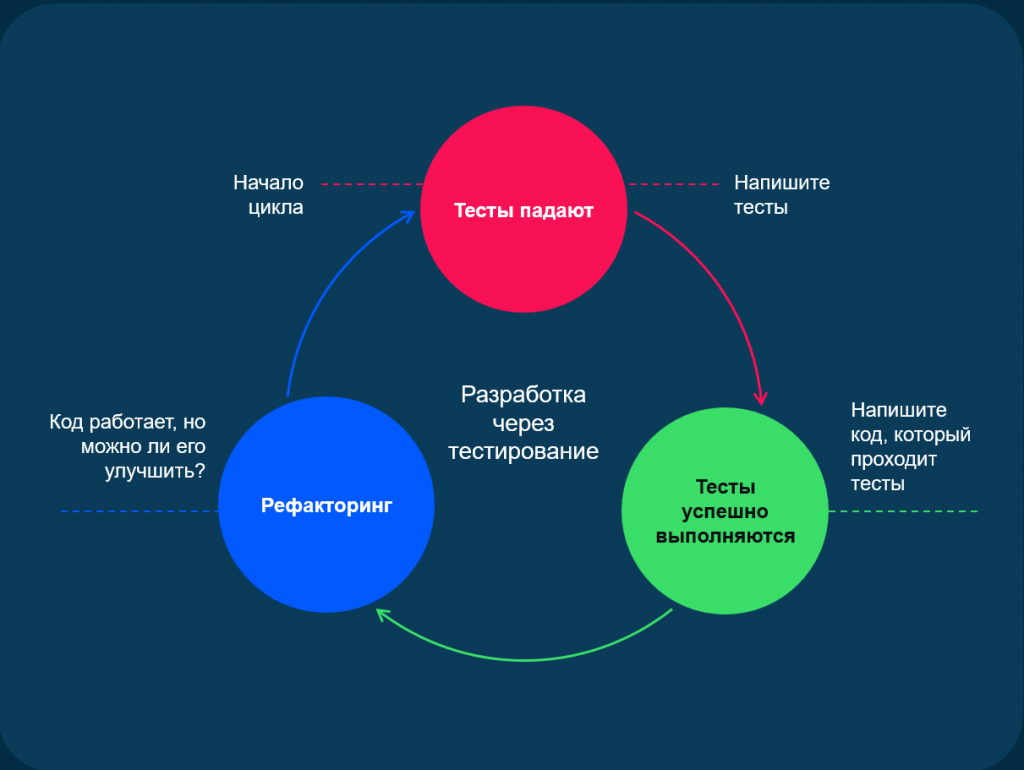
До написания кода. Этот алгоритм чуть более сложный, он заставляет разработчика поменять подход к написанию кода.
Сначала пишется тест, запуск метода, который мы планируем написать. Определяем сигнатуру и ожидаем результат, то есть то, что мы ждем в начале. Затем можно вручную подготовить тестовые данные или создать их с помощью кода.
После этого начинается написание самого кода проверяемого метода. Пока тест «падает» в красное (не выполняется), мы пишем код, чтобы тот удовлетворил условиям теста. После того как тест проходит успешно, проводится рефакторинг кода – он дорабатывается, чтобы соответствовать стандартам разработки компании и внутреннему чувству «красоты» разработчика. Дальше мы можем поменять тест – допустим, добавить создание тестовых данных, либо отрефакторить его, чтобы он соответствовал стандартам. И так по кругу, пока внутреннее чувство прекрасного у разработчика не будет удовлетворено.
Мы разобрались, как подходить к тестированию нового кода. Теперь поговорим о существующем коде.
Первый шаг – определить, можно ли его тестировать. Код должен быть тестируемым: должны быть понятны входные параметры и логика работы.
Поскольку наша кодовая база очень большая, необходимо расставить приоритеты тестирования и выбрать процессы, которые будут покрываться тестами в первую очередь:
-
Важный для бизнеса функционал. Это критический функционал, какие-то глобальные, важные механизмы, которые влияют на работу бизнеса, например, интеграции.
-
Часто используемый функционал. Это могут быть внутренние библиотеки или общие механизмы, которые вызываются очень часто. Чаще всего это какая-то библиотека.
-
Код из первых двух категорий, требующий рефакторинга. Такой код стоит оставить на потом, так как на его тестирование потребуется больше времени. Либо его можно не покрывать unit-тестами, а использовать другие виды тестирования.
Практические примеры: тестирование HTTP-сервисов
Наш путь в unit-тестировании начался с тестирования HTTP-ручек. Расскажу, как мы к этому подходили.
-
Сначала потребовалась подготовка кода. Исходный код находился внутри объекта конфигурации – это был HTTP-сервис. С этим кодом требовалось провести определенные манипуляции. Мы перенесли его в общий модуль и сделали необходимые методы экспортными. Таким образом, код был приведен к критериям тестируемости, о которых мы говорили ранее.
-
Мы изучили документацию, чтобы понять принцип работы сервиса, особенно учитывая, что конфигурация старая и содержит множество интеграций. Мы проанализировали входные параметры, определили тест-кейсы и поняли общую логику работы кода.
-
После этого мы написали тесты.

На картинке пример тестирования относительно простого метода, который выполняет поиск контрагентов по запросу. Посмотрим на структуру теста.
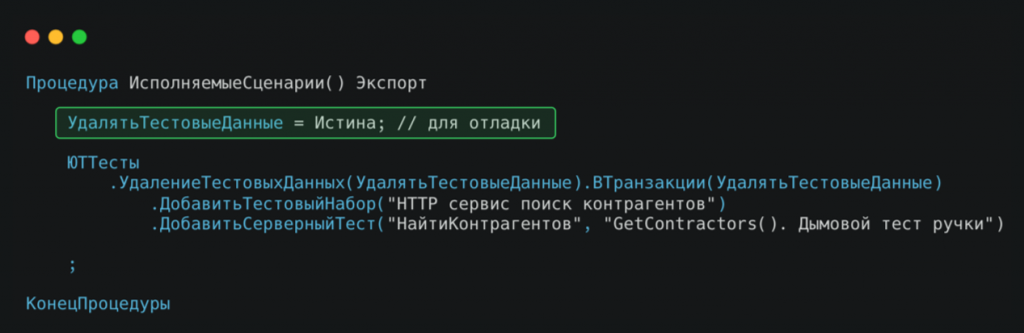
В событии ИсполняемыеСценарии происходит подключение тестовых сценариев.
Хочу обратить внимание на переменную УдалятьТестовыеДанные. Ее значение в конфигураторе можно временно изменить на Ложь, чтобы случайно не забыть вернуть исходное значение. Это необходимо потому, что разработчик в спешке или увлеченный процессом кодинга может отправить код в хранилище конфигурации, и в результате на тестовой базе могут остаться ненужные данные.
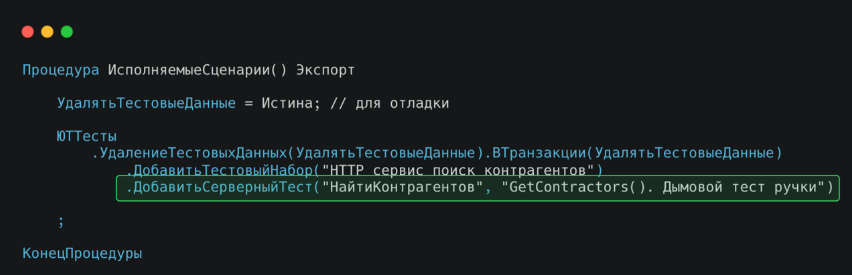
При добавлении серверного теста обязательно указывайте понятное человеку описание самого теста. Это нужно для того, чтобы при работе с большим количеством тестов было легко разобраться, понять их назначение и быстро определить источник ошибки.

Теперь рассмотрим сам код теста. Отмечу несколько интересных моментов
Название теста важно для формирования понятного и читаемого сообщения об ошибке. Мы заранее объявляем текст сообщения об ошибке, чтобы его можно было переиспользовать и чтобы все ошибки имели единый формат сообщений.
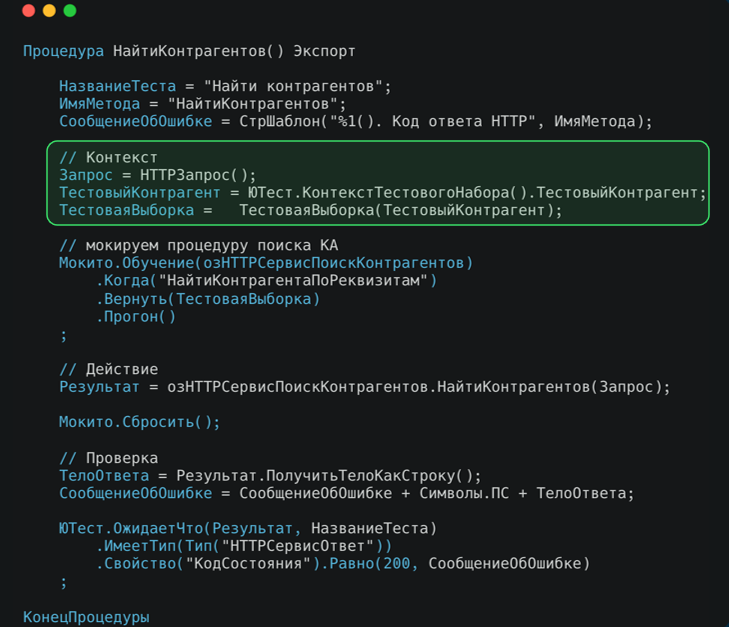
Также мы используем хранение тестовых данных в контексте. Мы используем событие перед тестовым набором, чтобы подготовить и поместить необходимые данные в контекст. Контекст – это механизм фреймворка, позволяющий передавать информацию между отдельными тестами или наборами тестов.
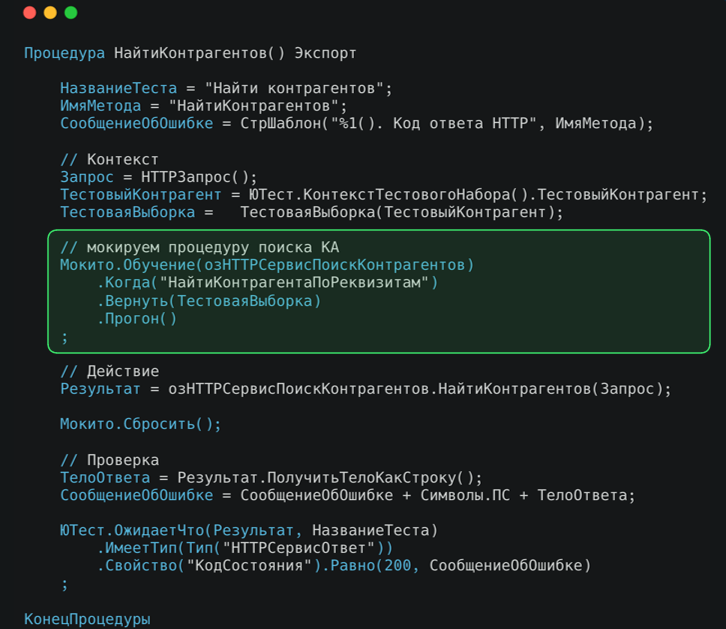
Также при тестировании мы активно используем Мокито. Мокито – это механизм, позволяющий перехватить выполнение какого-то метода и подменять возвращаемые значения или прекратить выполнение конкретного кода при определенных параметрах. В данном случае Мокито используется для перехвата вызова метода и возврата заранее подготовленной тестовой выборки.

Сам тест выполняет следующие шаги: вызывает тестируемое действие сбрасывает Мокито, чтобы избежать влияния на последующие тесты, и выполняет проверки.
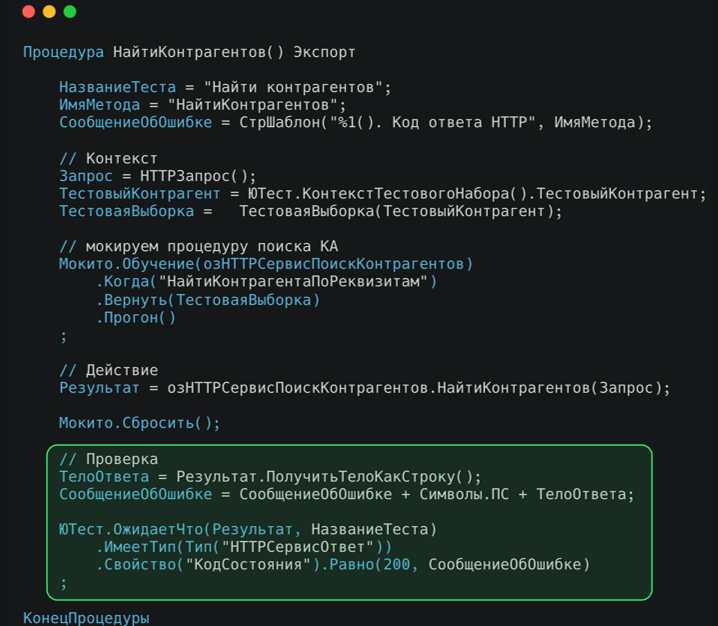
Как видите, здесь снова используется текучий интерфейс. Проверка достаточно простая: убеждаемся, что сообщение вернулось, отсутствует сообщение об ошибке и возвращается правильный код состояния.
С таких относительно простых тестов мы и начали. Написали базовые тесты, обучили сотрудников и перешли к более сложным сценариям.
Практические примеры: тестирование событий документов
Далее мы начали осваивать тестирование событий документов и объектов.
Рассмотрим проведение документа списания дебиторской и кредиторской задолженности. Этот документ требует подготовки большого объема данных: остатков, ввода документов и какой-то предыдущей информации для корректной работы. Кроме того, документ поддерживает несколько видов операций.

Сам тест реализован как параметризированный тест – один тестовый метод, которому передаются различные параметры, соответствующие разным видам операций. Давайте разберем его подробнее.

Как и прежде, используется переменная УдалитьТестовыеДанные.
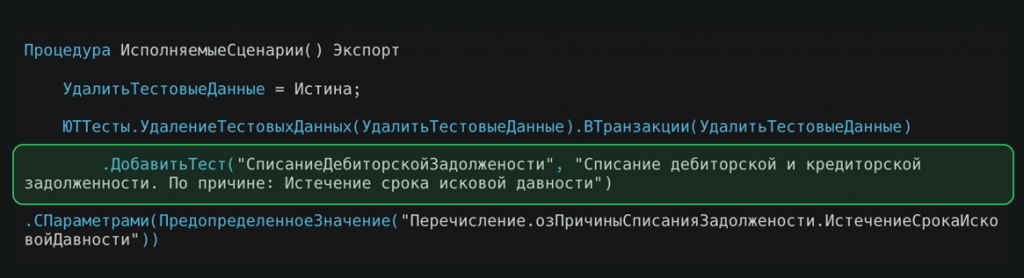
Добавление теста с человекочитаемым описанием.
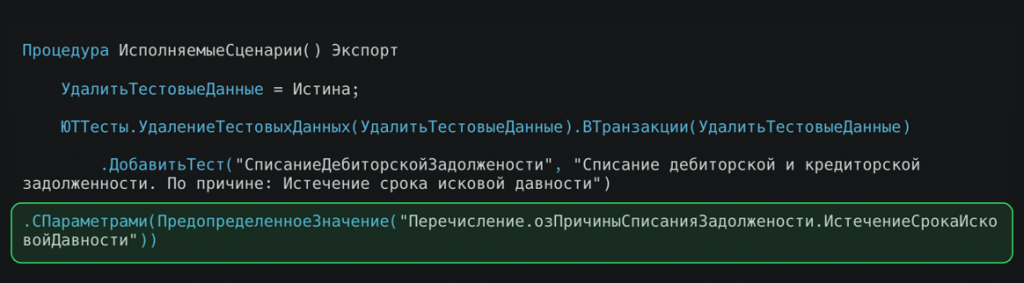
Параметры, которые мы передаем, чтобы тест работал корректно.
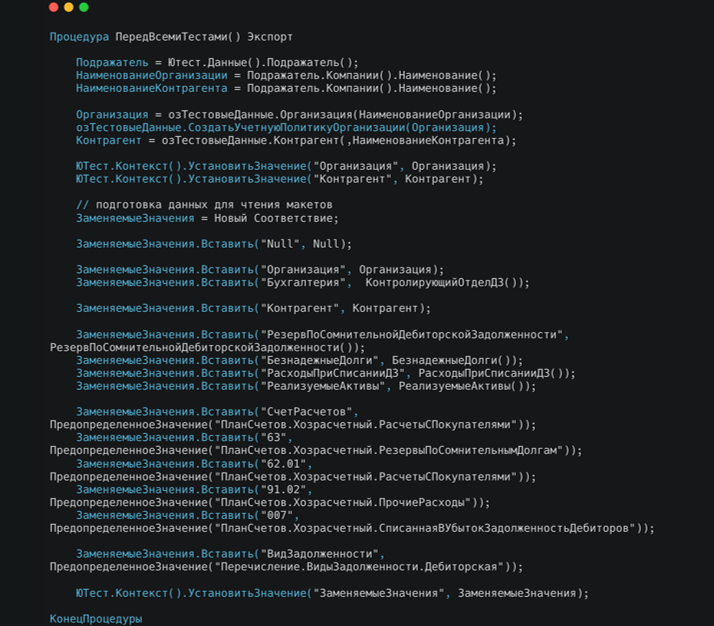
Ключевым моментом является использование события ПередВсемиТестами. Это событие, которое позволяет нам создавать достаточно большой объем тестовых данных и экономить время на использование тестов, которые используют одни тестовые данные для всех.
Механизмы подготовки данных:

Механизм Подражатель – это возврат человекочитаемых тестовых данных для названий, физлиц и, например, банковских счетов.

Далее мы используем свои модули-помощники для создания базовых элементов: организации, учетной политики, контрагентов. Если, например, учетная политика поменяется, мы поменяем ее в тестовых данных, и все тесты начнут работать по-новому.
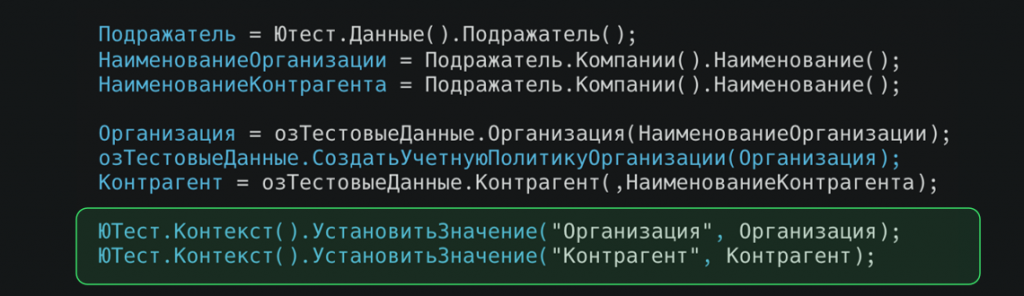
Потом мы все это подкладываем в контекст для того, чтобы использовать в следующих тестах.
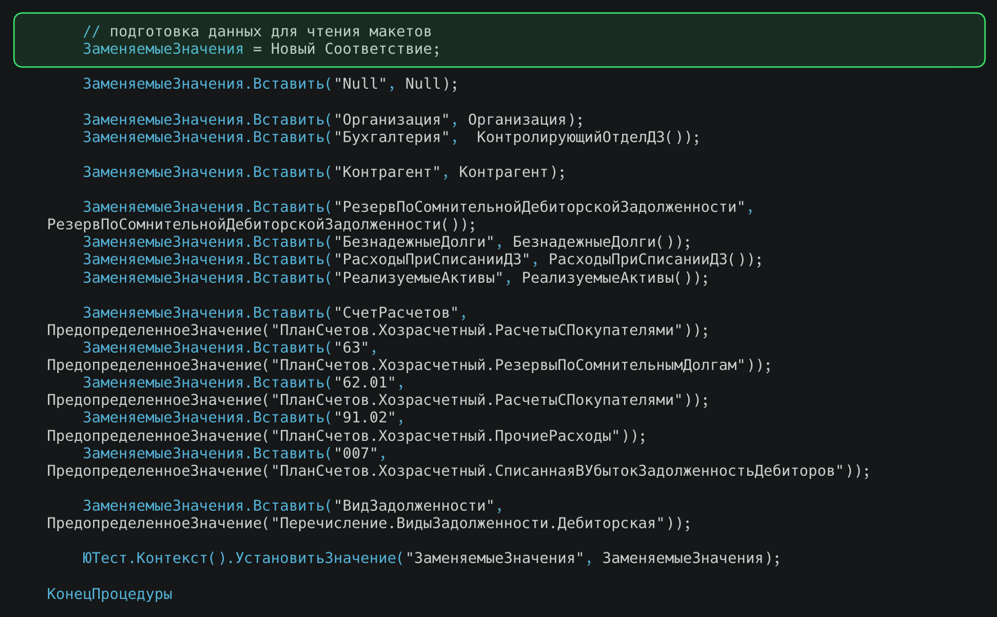
Также мы используем здесь чтение из макета. Для этого мы подготавливаем соответствие заменяемых значений. Это те значения, которые будут заменены в табличном документе, который используется как макет данных. Это строковая константа, которую вы указываете в табличном документе и в дальнейшем при чтении этого табличного документа идет замена на ссылочный тип или на то, что вы подставите.
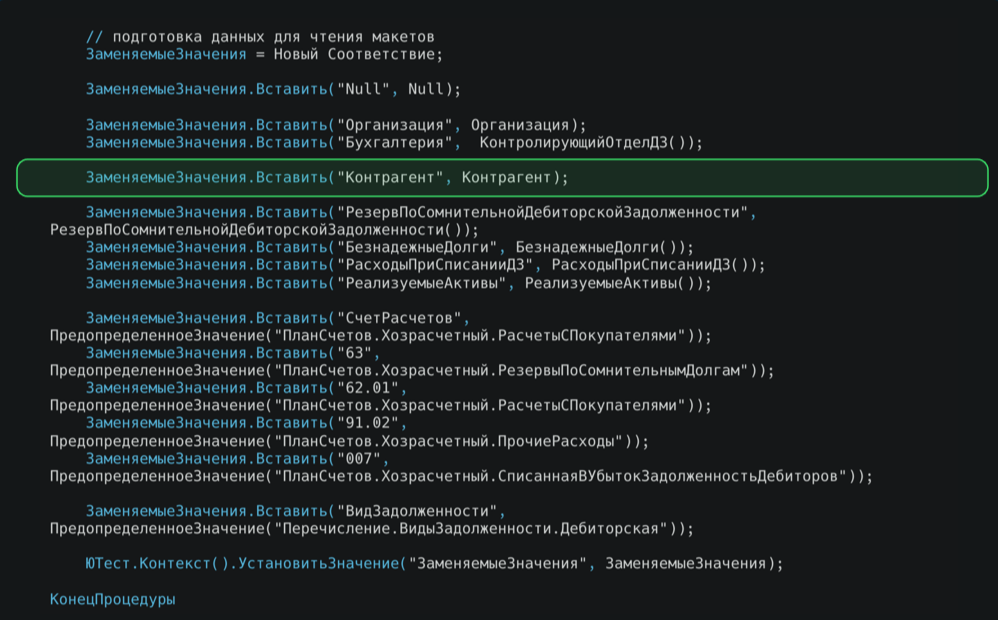
Мы складываем туда контрагентов, и ссылочная константа Контрагент будет заменена. И установка значений в контекст.

Так как для этого документа достаточно много тестовых данных, мы решили использовать хранение в табличном документе, о котором упоминал ранее.
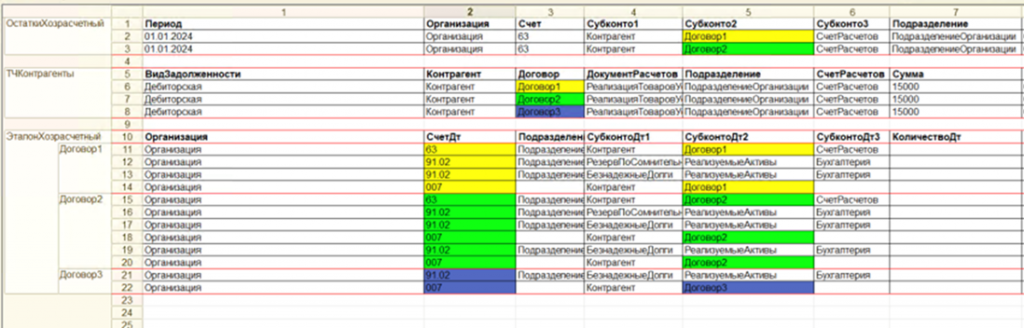
На рисунке показан пример табличного документа. У нас есть хранение остатков, которое мы загружаем, табличная часть Контрагенты и проверка ЭталонХозрасчетный.
Цветом в макетах мы выделяем различные тест-кейсы. При разборе функциональных требований или технического задания прямо в макете указывали, что будет использоваться. То есть он не несет какой-то практической пользы, кроме как для проверки разработчиком себя.
У нас много видов операций, и мы договорились, что для хранения этих макетов мы используем обработки.

Наименование обработки указывается следующим образом: просто «Макеты». И по рекомендациям разработчика фреймворка мы используем название общих тестовых модулей. Складываем макеты во встроенную категорию «Макеты» в обработке. Если необходимо уменьшить код загрузки, то его можно сложить в обработку. То есть это мультитул для работы с тестовыми данными – складываете туда какие-то методы, которые в дальнейшем будете использовать для загрузки конкретного документа. Это уменьшит код теста и улучшит его читаемость, так как код загрузки сам по себе достаточно объемный.
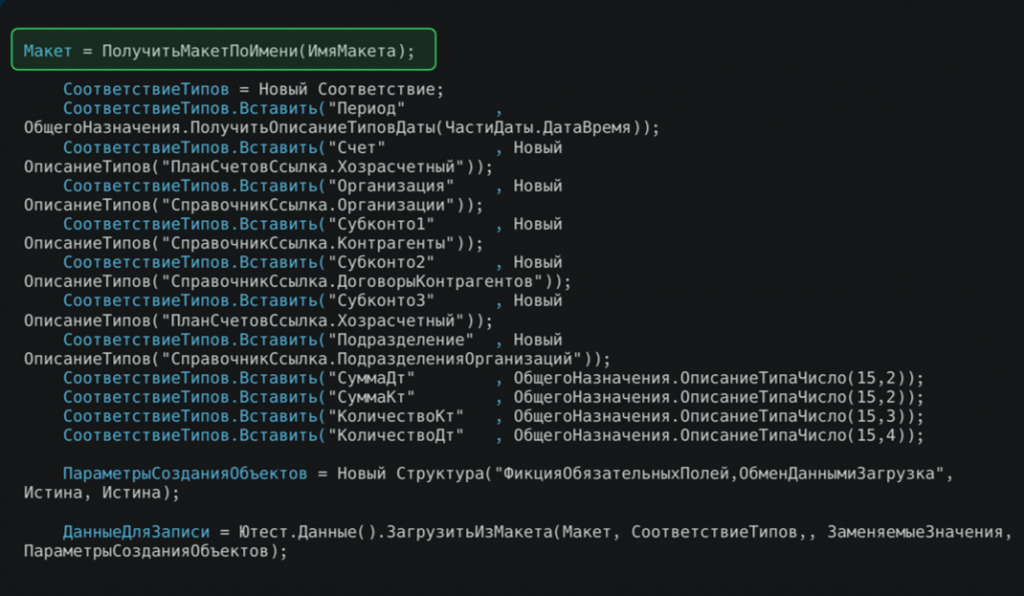
На рисунке пример кода загрузки. Метод ПолучитьМакетПоИмени – это дописанный под наши потребности метод, который по имени извлекает необходимую информацию из табличного документа.
Далее мы формируем СоответствиеТипов – это специальный механизм фреймворка, позволяющий подставить в колонки конкретные типы значений (например, ссылки на объекты) вместо строковых констант при загрузке данных из макета. Если для какой-то ячейки нет заменяемого значения, фреймворк создаст фиктивные данные.
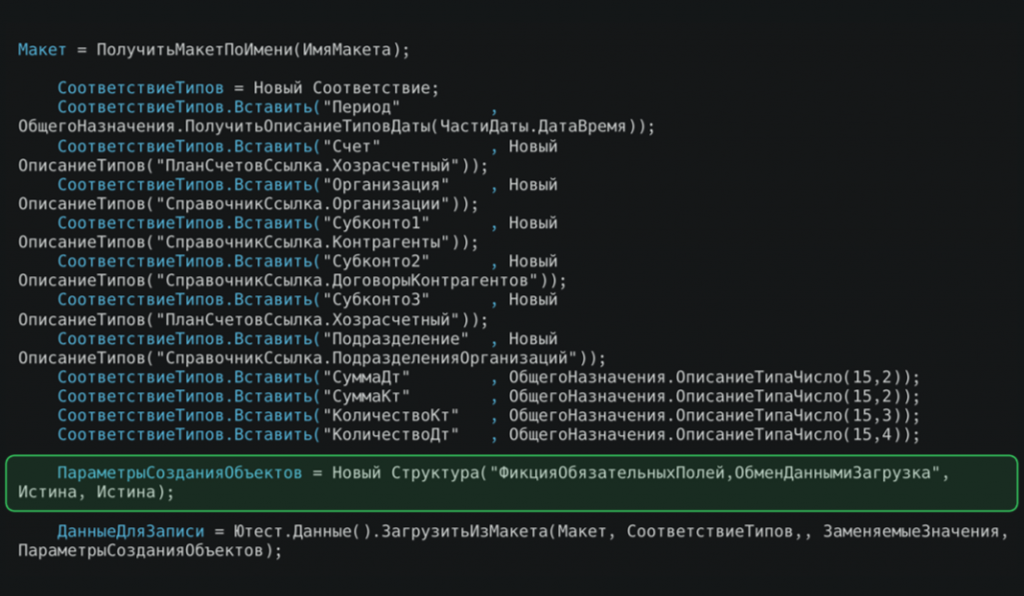
Мы также используем ПараметрыСозданияОбъектов, устанавливаем параметр ФикцияОбязательныхПолей в значении истина. При включенном режиме при создании объекта все обязательные поля будут автоматически заполнены фиктивными значениями, созданными фреймворком (в случае ссылочных типов – будут созданы соответствующие объекты).
Также применяется параметр ОбменДаннымиЗагрузка в значении Истина, чтобы используемые механизмы не мешали процессу создания тестовых данных.
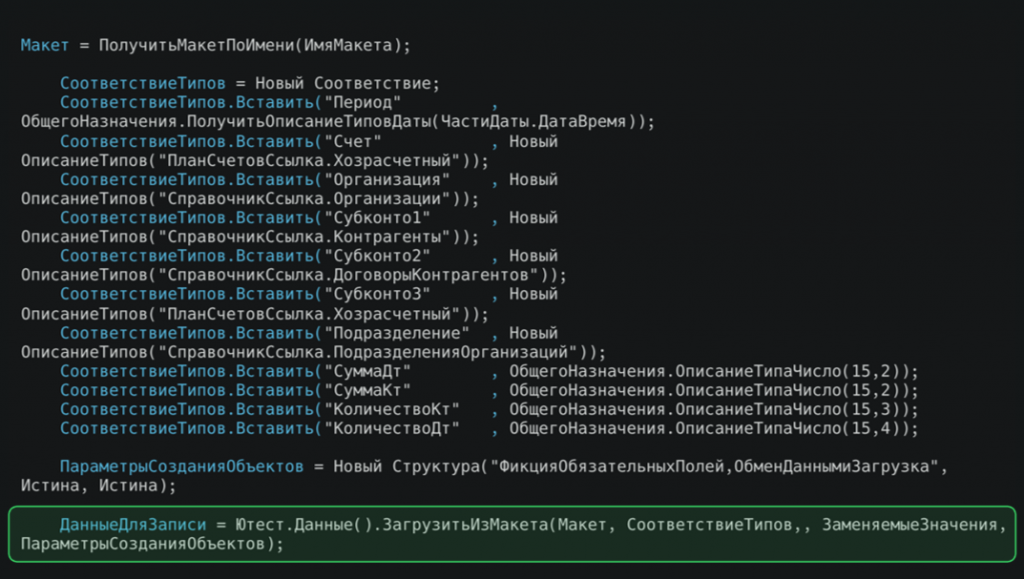
Загрузка из Макета:
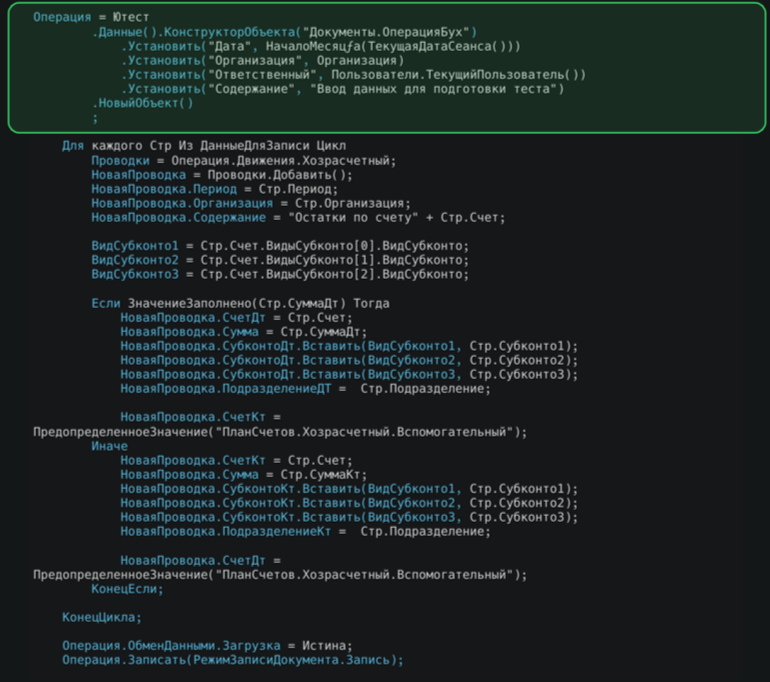
Загрузка данных бухгалтерского учета (хозрасчетного). Один из вариантов загрузки данных бухгалтерского учета (остатков) имеет свои особенности. Мы используем создание записей через бухгалтерскую операцию. Однако важно понимать, что такие объекты необходимо создавать с учетом их последующего удаления – либо через конструктор объекта, либо используя механизмы фреймворка для работы с тестовыми данными. Поскольку тестовые данные в дальнейшем сохраняются в контексте теста и подлежат удалению, мы учитываем это при их создании.
Далее следует загрузка через стандартную обработку циклом загруженной табличной части.

Теперь перейдем непосредственно к тесту и разберем его по частям.
Подготовка тестовых данных

Здесь, как и ранее, для каждого конкретного тест-кейса мы можем подготавливать свои тестовые данные. Общие данные уже были подготовлены заранее, а данные, специфичные для конкретного теста, создаются внутри него.
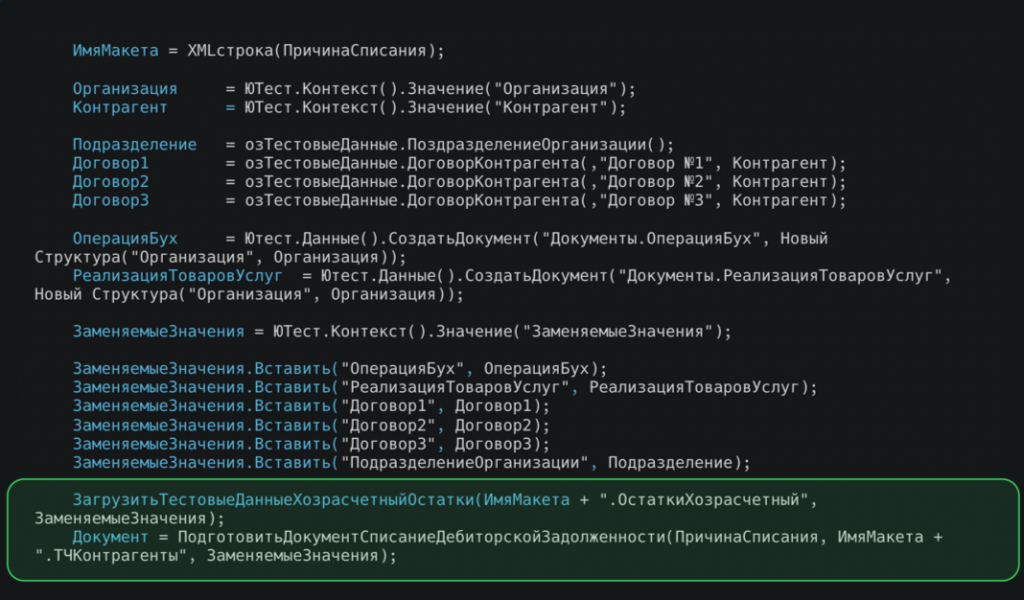
Все эти данные добавляются в коллекцию заменяемых значений, которая используется в процессе загрузки. Существует отдельный метод ПодготовитьДокументСписания, который отвечает за создание тестовых данных документа.
Тест проведения документа

Здесь снова используется Мокито. Этот инструмент позволяет нам отсечь ненужные для конкретного теста проводки – в данном случае это проводки по МСФО и налоговому учету. После выполнения теста необходимо сбросить Мокито, чтобы избежать влияния на последующие тесты.
Проверка утверждений
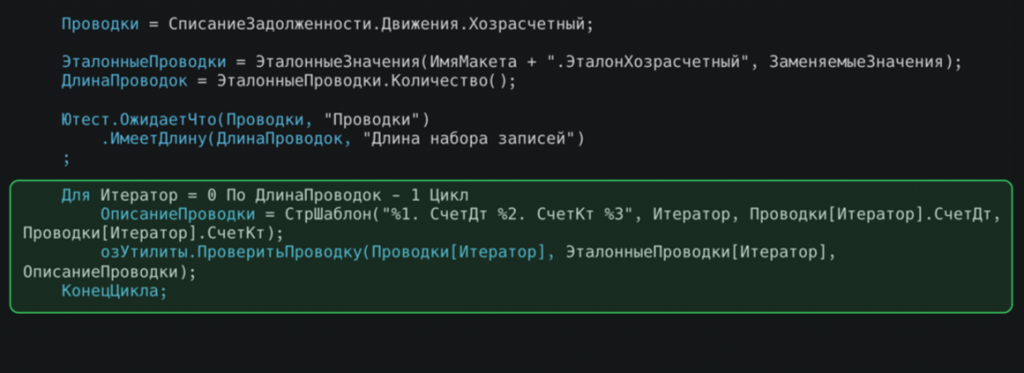
В этом блоке мы загружаем проводки и получаем эталонные проводки. Затем, в цикле, происходит сравнение каждой проводки. Предварительно проверяем длину. Чтобы не уходить в длительную процедуру проверки – если у нас что-то поменялось, то на самой простой проверке это все отлетит.
Для проверки проводок снова используем наши модули-помощники. Код проверки достаточно простой, но емкий – он сверяет значения проводок с эталонными. Однако, поскольку в бухгалтерском учете используются счета, которые в зависимости от различных показателей могут требовать проверки разных реквизитов (валюта, количество, сумма и т.д.), мы вынесли эту логику в модуль-помощник.
Выводы и рекомендации
Подведем итоги того, что у нас получилось:
-
Мы выяснили, что нет разницы между тестированием управляемых и обычных форм, потому что мы тестируем просто код.
-
При работе необходимо донести до коллег мысль о реальной пользе тестирования, так как не все разработчики изначально хотят этим заниматься. Нужно назначить ответственных, которые будут продвигать эту инициативу и оказывать помощь коллегам.
-
Нужно будет писать тестируемый код и рефакторить старый. Для того, чтобы лучше понимать и проверять код, он должен быть тестируемым и чистым
-
Писать тесты – это не так страшно и сложно, как может показаться. Поэтому не бойтесь, применяйте тестирование в своей работе и приносите пользу.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт