Всем привет! Меня зовут Айдар Сафин. Я главный разработчик 1С в центре экспертизы 1С компании Magnit Tech. Мы активно переводим наши сервера приложений 1С на Linux и базы данных с Microsoft SQL Server на Postgres. Эта статья – часть серии докладов и статей об опыте внедрения Postgres и Linux. Тем, кто уже перевел свои сервера приложений 1С на Linux и тем, кто задумался о переводе в ближайшем будущем, она будет очень полезна.
Мы поделимся нашим опытом подготовки конфигурации 1С к переводу серверной части на Linux. Дадим рекомендации, что нужно учесть при подготовке конфигурации для работы на Linux. При этом речь пойдет только о серверной части конфигурации. Клиент у нас остается на Windows, и поэтому все, о чем я здесь пишу, относится только к серверной части.
Для начала я объясню, зачем вообще переводить серверную часть 1С на Linux, какой в этом профит. Поделюсь ключевыми моментами нашего опыта подготовки конфигураций к работе на Linux. Далее пройдусь по шагам, которые необходимо выполнить, чтобы подготовить конфигурацию к миграции серверной части на Linux, включая перевод базы данных. Поговорим о том, какие инструменты существуют для анализа и рефакторинга при подготовке конфигурации 1С к работе на Linux. Приведу несколько примеров анализа и рефакторинга. И в конце поделюсь чек-листом миграции, который мы выложили на GitHub, и объясню, как им пользоваться.
Зачем переводить 1С на Linux
Если вы задумались о переводе серверной части 1С на Linux, вам нужно сначала перевести вашу СУБД с Microsoft SQL Server на PostgreSQL.
Решения Linux и PostgreSQL обычно либо бесплатны, либо стоят значительно дешевле, чем их аналоги на Windows. Кроме того, можно снизить риски, связанные с зависимостью от определенных технологических поставщиков, а значит, снизить геополитические риски.
Есть еще несколько важных преимуществ. В Linux обеспечивается лучшая поддержка инструментов оптимизации серверных ресурсов, таких как Docker и Kubernetes, что позволяет более гибко масштабировать систему и повышает ее производительность.
Далее, используя инструменты Linux, можно ускорить процесс развертывания (деплой) как в тестовой, так и в продуктовой среде. Также появляется возможность более полно использовать инфраструктурный код (Infrastructure as Code, IaC) с такими инструментами, как Terraform или Ansible. Эти технологии лучше работают на Linux, поскольку компоненты там более совместимы.
Конечно, это возможно и на Windows, но на Linux использовать эти инструменты гораздо удобнее. При использовании IaC мы всегда уверены, что наша система после изменений соответствует целевому состоянию. Практически исключается влияние человеческого фактора, и весь процесс автоматизируется.
Опыт Magnit Tech и основные трудности
Мы, например, активно используем Ansible для установки платформы 1С на Linux и настройки сервера 1С на Linux. Об этом более подробно я рассказал в другой своей статье, если хотите – почитайте.
Более года назад мы начали процесс подготовки конфигураций 1С к работе на Linux, подготовили к переводу 20 информационных систем, на данный момент перевели 7 информационных систем. И на основе нашего опыта по подготовке конфигураций мы составили список ограничений и чек-лист, которые выложили на GitHub и которыми я поделюсь в конце статьи.
Основные трудности возникали из-за недостатка экспертизы сотрудников, необходимости разработки и подготовки инструментов, администрирования, обслуживания, а также из-за отсутствия инструментов мониторинга и различных скриптов. На Linux подобных инструментов либо не было вовсе, либо их было мало, либо приходилось все это самостоятельно искать и настраивать. То есть, если вы задумались о переводе серверной части 1С на Linux, то на этот аспект тоже нужно обратить внимание. Мы проводили различные нагрузочные тесты, в том числе Тест Гилева, Тест создания цепочек в ERP и так далее.
В процессе эксплуатации этих переведенных систем на Linux мы пришли к выводу, что сервер 1С на Linux работает ничуть не хуже, чем на Windows. То есть, в плане производительности проблем вообще нет.
Подготовка конфигурации к миграции
Итак, какие шаги нужно пройти, чтобы перевести нашу конфигурацию 1С с сервера приложений 1С на Windows на сервер приложений 1С на Linux.

Первое и самое важное: проверить, что ваша база 1С не использует Microsoft SQL Server. Это является блокирующим фактором. Если ваша СУБД на Microsoft SQL Server, то вы не сможете перевести сервер приложений 1С на Linux. Прежде чем переводить сервер приложений 1С, нужно сначала перевести СУБД на PostgreSQL.
Проверка внешних компонентов
Еще один совет. Если вы, например, сегодня перевели вашу базу данных с СУБД Microsoft SQL Server на Postgres, то переводите сервер приложений 1С на Linux не раньше, чем через месяц. Потому что все равно что-то может вылезти: какие-то проблемы с запросами, с производительностью, будут появляться ошибки и так далее. Поэтому пожалейте себя и свой бизнес – планируйте перевод сервера приложений 1С на Linux не раньше, чем через месяц после того, как вы перевели базу данных на СУБД Postgres.
Следующий шаг уже относится к проверкам конфигурации. Необходимо проверить, используются ли внешние компоненты, поддерживающие Linux. О каких компонентах вообще идет речь? Это те, которые подключаются через "Подключить внешнюю компоненту", `AttachAddIn` или, например, из макета средствами "Общего модуля".
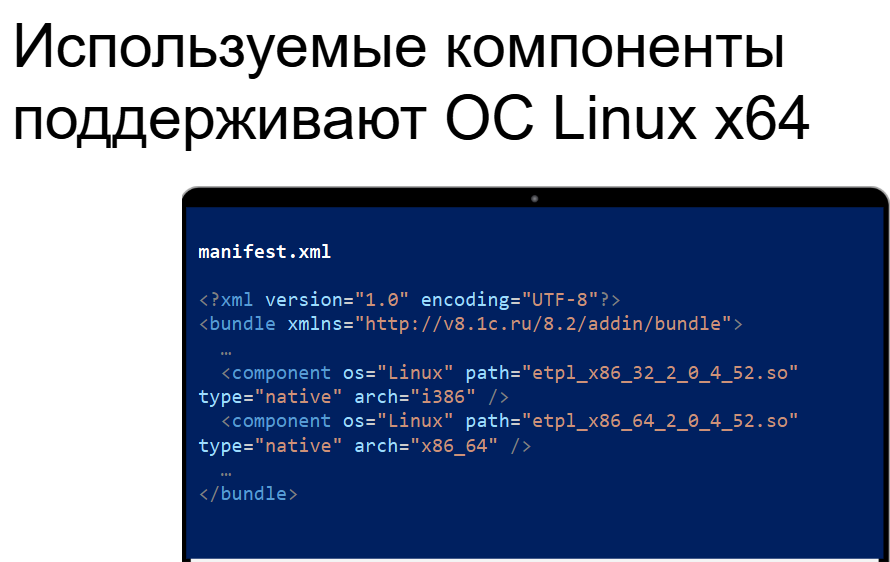
Одна из простых проверок – это взять внешнюю компоненту из конфигурации, выгрузить ее в какую-нибудь папку и посмотреть ее манифест (файл `manifest.xml`). Видим, что в манифесте есть поля, например, `OS Linux x86-32`, `OS Linux x86-64`, и видим, что `type="native"`. Это означает, что данная компонента поддерживает технологию Native API. С большой долей вероятности такие компоненты будут совместимы и будут работать на Linux.
Вы должны проверить все внешние компоненты, которые важны для вас и которые вы будете использовать, на предмет их совместимости с Linux. Если они не совместимы, в первую очередь нужно искать компоненты, которые поддерживают технологию Native API. Если аналогов не найдете, тогда уже нужно задуматься о рефакторинге кода. Но это уже дело вкуса и специфики задачи.
Рефакторинг COM-объектов
Следующий важный пункт – это COM-объекты. COM-объекты на Linux не работают. Это требует стопроцентного рефакторинга. Но если вы, как и мы, например, оставляете клиентскую часть на Windows, то есть временный выход – перенести часть серверного кода на клиент. Например, это может быть работа с Word. Обычно работа с Word инициализируется под конкретным пользователем – почему бы это не перенести на клиент. Другой пример рефакторинга COM-объектов – это перевод COM-обменов, то есть обменов между базами 1С через COM, на HTTP-сервисы.
Еще один пример, который я приведу позже, покажет, как можно, используя встроенные библиотеки Linux, отказаться от COM.
Теперь о COM из внешних систем. Например, мы перевели какую-то базу на сервер приложений 1С на Linux, там COM-объектов нет. Но могут быть другие на Windows, внешние по отношению к ней базы, которые обращаются к ней через COM. И они будут работать, но в контексте вызова COM из внешней базы в базу, которая, например, работает на Linux, может выполняться абсолютно любой код, и он может быть несовместим с Linux. COM – коварная вещь, никогда не знаешь заранее, какой код будет внутри выполняться.
Работа с путями и сетевыми каталогами
Вы можете одним из способов, например, через технологический журнал, собрать статистику: какие обращения через COM были к вашей базе за определенный период, откуда они выполнялись. Затем можно подправить контекст этих вызовов, изменить передаваемые параметры или логику, чтобы все стало совместимо с Linux.
Конкретный пример: у нас была внешняя база, которая управляла другими базами. Она передавала данные в базу на Linux, а именно инициировала выгрузку в некий сетевой каталог обмена, но передавала некорректный путь с точки зрения Linux.
Соответственно, обмен падал с ошибкой. Когда мы это обнаружили, мы в той внешней базе на Windows изменили настройки, а именно подкорректировали пути, чтобы они корректно передавались для Linux. После этого все заработало.
Вообще, независимо от того, переходите вы на Linux или нет, я рекомендую вводить политику отказа от использования COM. COM – это устаревшая технология, и от нее по-хорошему нужно отказываться. Например, можно использовать SonarQube для проверки соблюдения этой политики отказа от COM. Но об этом речь пойдет чуть позже.
Значения констант и реквизитов, содержащих пути
В Linux есть особенности работы с каталогами. Подробнее вы можете посмотреть в документации по заполнению поля "Полный путь", но суть я объясню. В Linux сетевые шары Windows не работают напрямую. Их нужно смонтировать как локальный каталог, и только потом с ними работать.
Пример, как мы монтируем сетевой каталог. В `cron` добавляется строка:
@reboot mount -t cifs //server111/obmen_1c/Обмен /mnt/obmen -o credentials=/etc/cifs-useradmin,vers=3.0,uid=usr1cv8,gid=grp1cv8
`cron` – это планировщик заданий в Linux. `@reboot` означает, что команда будет выполняться при каждой перезагрузке системы, потому что сетевая шара может отвалиться. Чтобы гарантировать доступ к сетевому каталогу, мы добавили задание в `cron`.
При каждой перезагрузке системы выполняется команда `mount` (монтировать). `-t cifs` означает, что мы используем Common Internet File System, по сути это протокол SMB/CIFS (Samba). Сетевую шару `//server111/obmen_1c/Обмен` нужно смонтировать в локальный каталог `/mnt/obmen`.
В файле `/etc/cifs/user-admin` содержатся учетные данные сервисной учетной записи, у которой есть доступ к этой шаре. И указываем, что каталог нужно смонтировать с правами для пользователя `usr1cv8` и группы `grp1cv8`, чтобы наша служба сервера 1С, под которой запускается `ragent`, имела к ней доступ.
Если у вас по каким-то причинам нет возможности после монтирования сетевого каталога в `/mnt/obmen` пройтись по всей вашей базе и изменить все значения констант и реквизитов, содержащих старые пути, – например, путь приходит из внешней базы, а прод вы, допустим, обновляете раз в неделю, – то я покажу в примерах небольшой лайфхак, как можно временно обойтись без этих изменений и использовать старый путь без каких-либо правок в коде конфигурации. Но это временное решение.
Другие проверки совместимости
Почта Mail -> ИнтернетПочта
Первое – это объект `Почта или Mail`. Этот объект не работает на Linux, но здесь все не так страшно. Есть встроенный объект языка `ИнтернетПочта`, который отлично работает на Linux, просто нужно переписать код на его использование.
ИнтернетСоединение InternetConnection
Далее – `ИнтернетСоединение` (InternetConnection). Он требует Internet Explorer 5.0 или выше, соответственно, он не будет работать на Linux.
Выполнить Execute. Поиск в EDT: [^\.]\bВыполнить\(\b
Следующее – `Выполнить` (Execute). В коде, передаваемом в `Выполнить`, может содержаться что-то, несовместимое с Linux, например, вызов каких-то `.exe` или `.bat` файлов, которые не будут работать на Linux. Поэтому нужно проверить весь код, передаваемый в `Выполнить`. Если он не адаптирован под Linux или не кроссплатформенный, его нужно отрефакторить.
Если вы, как и мы, используете EDT, то удобнее использовать поиск с регулярными выражениями. Например, с помощью регулярного выражения [^\.]\bВыполнить\(\b вы найдете все вхождения, где используется `Выполнить`, и сможете по списку проверить, что там совместимо с Linux, а что – нет.
КомандаСистемы System
`КомандаСистемы` (System) – эта функция запускает на исполнение команду операционной системы. Здесь самое важное – в первую очередь проверить права пользователя `usr1cv8`, под которым запускается эта команда. У службы `srv1cv8` (или `ragent`) должны быть соответствующие права на запуск этой команды ОС. Еще раз отмечу, все это подробно описано в нашем чек-листе. Я сейчас пробегаюсь по основным моментам.
Итак, по `КомандаСистемы` первое – это права пользователя `usr1cv8`, второе – нужно проверить, что сама команда операционной системы совместима с Linux. В ней не должно запускаться чего-то вроде `.exe` или `.bat` файлов и других специфичных для Windows команд.
ЗапуститьПриложение RunApp
Следующее – `ЗапуститьПриложение RunApp`, то есть запуск внешнего приложения либо открытие файла. Здесь также, в первую очередь, нужно проверить права. Классический вариант использования – это запуск shell-скрипта в Linux по SSH.
Есть еще один важный нюанс в Linux: у запускаемого скрипта должны быть установлены права на исполнение. Это особенность ОС. Есть полезный лайфхак по этой теме. Мы можем в коде 1С сначала выполнить `КомандаСистемы` вида `"chmod 740 " + ПолныйПутьКФайлу`, чтобы дать право на исполнение файлу скрипта, а следующей строкой уже использовать `ЗапуститьПриложение` для его выполнения.
ФайловаяСистема.ЗапуститьПрограмму
ОбщегоНазначенияКлиентСервер.ЗапуститьПрограмму
Следующее – это `ОбщегоНазначенияКлиентСервер.ЗапуститьПрограмму` (или аналоги из других библиотек). Это тоже нужно проверить, здесь те же рекомендации: проверить права пользователя `usr1cv8` и убедиться, что вызываемая программа или команда совместима с Linux.
Работа с криптографией
Чтобы ускорить процесс, сначала можно проверить, установлены ли криптопровайдеры, необходимые для работы с криптографией, на вашем текущем сервере 1С на Windows, с которого вы будете переводить базу на сервер 1С на Linux. Обычно на Windows используется Microsoft Crypto API, в большинстве случаев. На Linux и macOS также во многих случаях будет использоваться интерфейс КриптоПро CSP (CryptoAPI по ГОСТ).
В коде можно поискать использование, например, `Новый МенеджерКриптографии`. Подробнее, как это работает, в том числе на Linux, описано в статье на ИТС. Этот шаг позволяет понять, как нужно рефакторить код для Linux, и здесь можно использовать EDT для поиска.
Изображения в форматах WMF и EMF
Следующий пункт – это изображения в форматах `.Wmf` и `.Emf`. Это Windows метафайлы (Metafiles). Они не будут работать на Linux. Здесь нужно просто заменить их на растровые форматы, например, `.png`, `.jpeg` или другие, поддерживаемые в Linux.
Перенос SSH-ключей
Если вы, как и мы, работаете с GitLab или вообще используете SSH-ключи для различных задач, нужно не забыть перенести их с Windows на Linux. На Windows они обычно лежат в каталоге `.ssh` профиля пользователя, например, `C:\Users\usr1cv8\.ssh`, если служба сервера 1С запускается под пользователем `usr1cv8`.
В Linux, если служба также запускается под пользователем `usr1cv8`, ключи должны находиться в домашней директории этого пользователя: `/home/usr1cv8/.ssh`.
Также необходимо перенести файл `known_hosts`, который также находится в каталоге `.ssh`. Это файл с отпечатками серверов. Если его не перенести, то первое обращение к серверу, например, GitLab, придется выполнять интерактивно в консоли Linux под пользователем `usr1cv8`, чтобы подтвердить отпечаток сервера.
Инструменты анализа и рефакторинга
Инструментов анализа и рефакторинга существует множество, но я расскажу о тех, которыми пользуемся мы.

Наш основной инструмент – 1С:EDT. В нем значительно расширены возможности поиска, удобно отображается иерархия вызовов, можно анализировать интерфейсно. Ниже я покажу пример, как мы этим пользуемся.
Следующий инструмент – Конфигуратор. Это привычный и понятный инструмент, с которым многим комфортно работать, это наше родное. Однако по сравнению с EDT его возможности поиска слабее: он менее глубокий и довольно медленный. Тем не менее, если задача простая, конфигурация небольшая и вы точно знаете, где нужно внести правки, Конфигуратор вполне подойдет.
Также у нас есть Visual Studio Code, который используется для решения специфических задач. Приведу пример: когда конфигурация очень большая, даже в EDT поиск может занимать продолжительное время. В такой ситуации, если вы точно знаете, что ищете, можно сначала выполнить поиск в VS Code – он очень быстро ищет по файлам.
Затем можно локализовать нужные участки кода, разбить их на логические блоки и уже в EDT проводить более точный поиск, формировать список задач и планировать рефакторинг.
И, конечно, SonarQube. Он, помимо прочего, позволяет отслеживать количество COM-объектов в конфигурации. Это помогает придерживаться установленных стандартов качества кода.
Например, мы ввели политику отказа от COM-объектов и решили использовать SonarQube для контроля. Посмотрели, что на данный момент у нас, скажем, 1 000 COM-объектов. Прошел месяц или два – смотрим, сколько у нас теперь COM-объектов. Если комов стало больше – значит, политика отказа от COM не работает. Если же количество уменьшилось или осталось на прежнем уровне – значит, все в порядке. Отчасти для таких целей мы и используем SonarQube.
Примеры анализа и рефакторинга
Теперь приведу несколько примеров. Первый – это поиск в EDT.
Допустим, у нас есть некая процедура или функция, содержащая код, который не будет работать на Linux. Прежде чем ставить задачу на рефакторинг, мы сначала находим все вхождения – то есть отображаем иерархию вызовов, анализируем строки и смотрим, какие вызовы происходят.


Что особенно удобно – здесь можно интерфейсно посмотреть, откуда это вызывается: из кнопки, меню и так далее. В таком виде мы передаем информацию нашим аналитикам, которые либо сами, либо вместе с бизнесом выясняют, используется ли этот код. Если нам повезло, и код не используется – мы просто ставим заглушку (пример): Если Linux x86_64, тогда ничего не делаем.
Если код используется, тогда мы ставим задачу на рефакторинг, которую позже выполняет разработчик. Это первый пример использования поиска в EDT.
Следующий пример – отказ от COM, то есть рефакторинг COM-объектов. У нас была конкретная задача по работе с доменом. До рефакторинга мы использовали COM-объект ADODB.Connection.
В Linux есть пакет ldaputils, и в частности – команда ldapsearch, которая позволяет работать с доменом без дополнительных объектов.
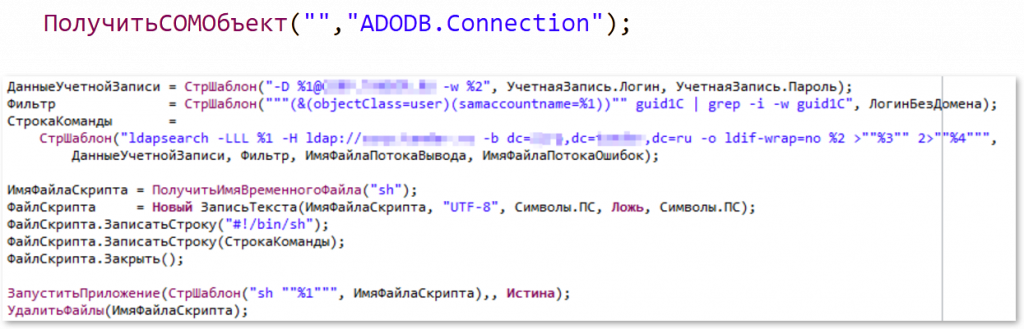
Здесь мы формируем команду, в которой указываем ldapsearch, затем задаем сервер и передаем серверную учетную запись с логином и паролем, имеющими доступ к домену. Далее мы формируем код и запускаем его через "Запустить приложение". Таким образом, мы обходимся без дополнительных инструментов, используя только пакет ldaputils и команду ldapsearch.
Мы работаем с доменом, запускаем приложение, а затем уже обрабатываем результаты. Таким образом, мы отказались от COM-объекта ADODB.Connection и выполнили рефакторинг.
Последний пример – работа с каталогами в Linux. Сетевые шары не работают, их нужно монтировать как локальные. Однако есть лайфхак, позволяющий временно обойтись без этого.
Можно создать локальный каталог, например: server111, в нем – obmen_ 1c, папка "Обмен". Затем создать символическую ссылку и указать, что `/mnt/obmen` ссылается на `/server111/obmen_1c/Обмен`.
С учетом особенностей того, что обратные слэши и прямые слэши 1С интерпретирует одинаково, если мы укажем такой путь, для 1С он будет эквивалентен вот такому пути.

Соответственно, обмен будет работать без изменений. Однако не стоит постоянно использовать такой подход. Так можно выйти из положения, например, когда вы не можете сразу обновить прод и какое-то время вам нужно продержаться.
Чек-лист миграции и репозиторий на GitHub
Мы выложили на GitHub наш список ограничений и сам чек-лист в репозитории Magnit Tech GitHub.
https://github.com/magnit-tech/cfg-1c-analysis-checklist-linux
В нем есть два md-файла. Первый – это просто readme с чек-листом, а второй – limitations (ограничения).
В файле limitations (ограничения) мы описали ограничения конфигурации 1С.

Это начальная логика, по которой мы проводили анализ ограничений, прикидывали, как их обойти, и на основе этого создали чек-лист. Здесь вы можете посмотреть нашу логику и, возможно, если у вас есть какие-то специфические проблемы, на основе этой логики выстроить свой процесс.
Затем мы создали сам чек-лист и продолжили его дополнять. Это ссылка на сам чек-лист:
https://github.com/magnit-tech/cfg-1c-analysis-checklist-linux/blob/master/README.md
В нем есть два временных этапа: предварительный анализ и анализ перед миграцией, когда инфраструктура уже получена и настроена.
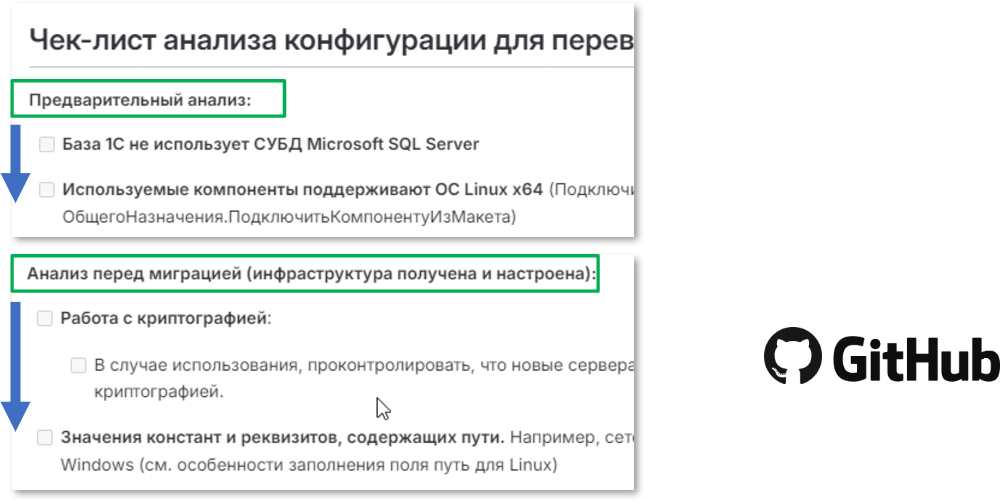
Как работать с чек-листом. Просто проходим по каждому пункту и выполняем его. Либо проверяем – например, база 1C не использует СУБД MS SQL Server, используемые компоненты поддерживают ОС Linux x64 и т.д.
По каждому пункту мы должны пройтись и проверить нашу конфигурацию или базу – как в первом случае.
Самое замечательное, что на этапе предварительного анализа мы можем прикинуть затраты, составить список работ, рассчитать бюджет проекта, определить, сколько нужно людей, какие будут затраты и так далее. То есть уже на начальном этапе мы можем полностью рассчитать бюджет проекта.
На этапе анализа перед миграцией есть дополнительные пункты, а также те же пункты, но с дополнениями – то, что нужно выполнить непосредственно перед миграцией.
Самое главное – благодаря этому чек-листу мы не пропустим ничего важного, и теперь вы тоже.
Подводя итоги, хочу подчеркнуть, что успешная миграция сервера приложений 1С на Linux требует тщательного анализа, использования современных инструментов и накопленного опыта, которым мы с радостью поделились с вами.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт