Несмотря на то, что тема, о которой мы сейчас будем говорить – не основы CI/CD, а конкретные приемы по оптимизации пайплайнов, прежде чем углубляться в эти дебри, хочется дать небольшое предисловие о том, что вообще такое CI и GitLab CI в частности.

Continuous Integration и Continuous Delivery (CI/CD) – это неотъемлемая часть современной разработки, которая заключается в непрерывной автоматической интеграции изменений в кодовую базу продукта.
Под этой формулировкой мы понимаем все, что связано с автоматизацией разработки: проверка кода, тестирование, сборка, деплой и прочее.
На слайде показана знаменитая картинка, которая как раз раскрывает смысл этой «непрерывности» и описаны основные преимущества – зачем мы вообще этим занимаемся.
Подход – есть. Какой инструмент выбрать?

Итак, сам подход CI/CD мы уже приняли. Следующим делом нам нужно определиться с инструментом. Здесь выбор достаточно широкий: Jenkins, TeamCity, GitHub Actions, Azure DevOps и, конечно же, GitLab CI. И это только самые популярные решения, на самом деле их гораздо больше.
В сообществе 1С под многие из этих инструментов уже есть готовые библиотеки и наработки:
-
Например, для Jenkins есть библиотека Jenkins Lib за авторством Никиты Федькина.
-
Для GitHub Actions недавно появилась библиотека от Алексея Корякина.
-
Есть примеры файлов GitLab CI от Александра Стрижачука.
Вариантов действительно много. И если вы хотите этим заняться, уже точно есть на что посмотреть. За что, кстати, всему сообществу огромное спасибо. Я сам начинал с этих работ.
Когда меня спрашивают, почему в нашей компании используется именно GitLab CI, а не Jenkins, у меня на этот вопрос есть три коротких ответа:
-
«Так вышло»
-
«Нравится»
-
«А зачем мне что-то еще?»
Так что здесь все просто – каждый выбирает сам, никакой объективной таблицы сравнения с плюсами и минусами я вам не дам. Для меня решающим фактором выбора стало то, что наша компания и так использовала GitLab в качестве хранилища git-репозиториев, плюс у коллег уже был опыт работы с GitLab CI. Я посмотрел, попробовал – так и остался, зачем мне что-то еще.
Приземляем на 1С
С теорией разобрались. Теперь давайте посмотрим, какие шаги из большого CI/CD применимы к 1С, и какие инструменты для них характерны, согласно нашим 1С-ным особенностям:
-
Для тестирования (этап Test) в 1С используется YaxUnit, ADD и Vanessa Automation.
-
Для проверки кода (этап Code) – SonarQube, EDT, АПК.
-
Для сборки релиза через поставку или CF-файл (этап Build) нам нужен конфигуратор и EDT, если мы разрабатываем в EDT. Сейчас еще новинка – автономный сервер.
-
Для накатывания релиза на рабочий сервер, снятия бэкапов и прочее (этап Deploy) – конфигуратор, SQL tools, клиент 1С
Получается, что практически все шаги, которые используются в цикле большого CI, вполне применимы и для нашего мира 1С.

Настройка пайплайна в GitLab CI выполняется в файле .gitlab-ci.yml, который хранится в корне репозитория. В нем прописываются задания для так называемых gitlab-раннеров, устанавливаемых на сервер или компьютер разработчика.
Синтаксис файла .gitlab-ci.yml несложный. Конкретно на этом скриншоте указаны шаги проверки SonarQube для ветки и для merge-реквеста. И если открыть визуализацию этого пайплайна в GitLab, там будет один маленький этап checkcode, в котором в зависимости от условия выполняется один из двух этих шагов – sonar-job_MR или sonar-job_push.
Получается, что и для всех остальных шагов на нужно просто найти правильные CI-файлики, скопировать их на машины разработчиков, и все, можно считать себя DevOps инженером, зарабатывать 300к в секунду. Или все-таки нет?
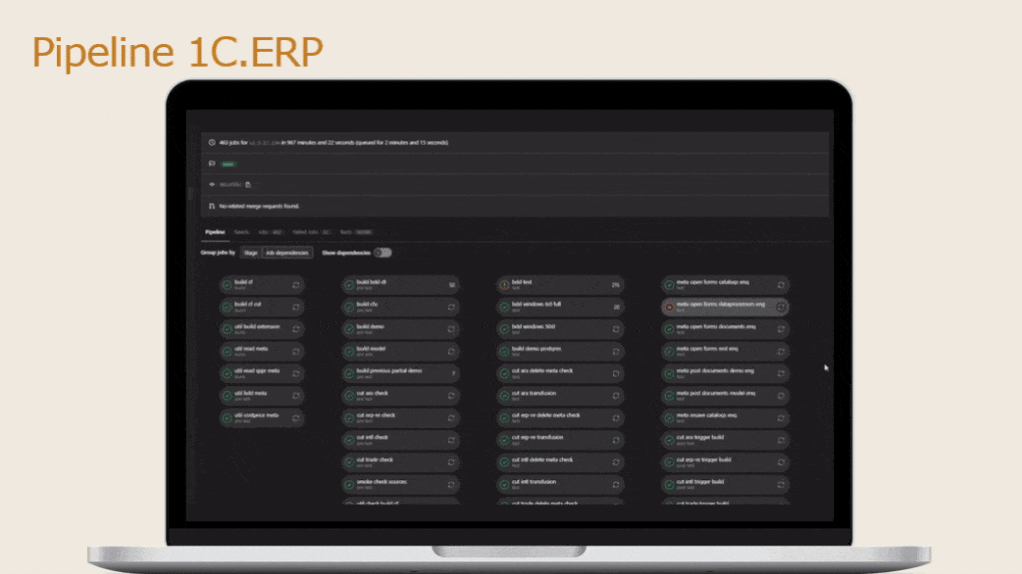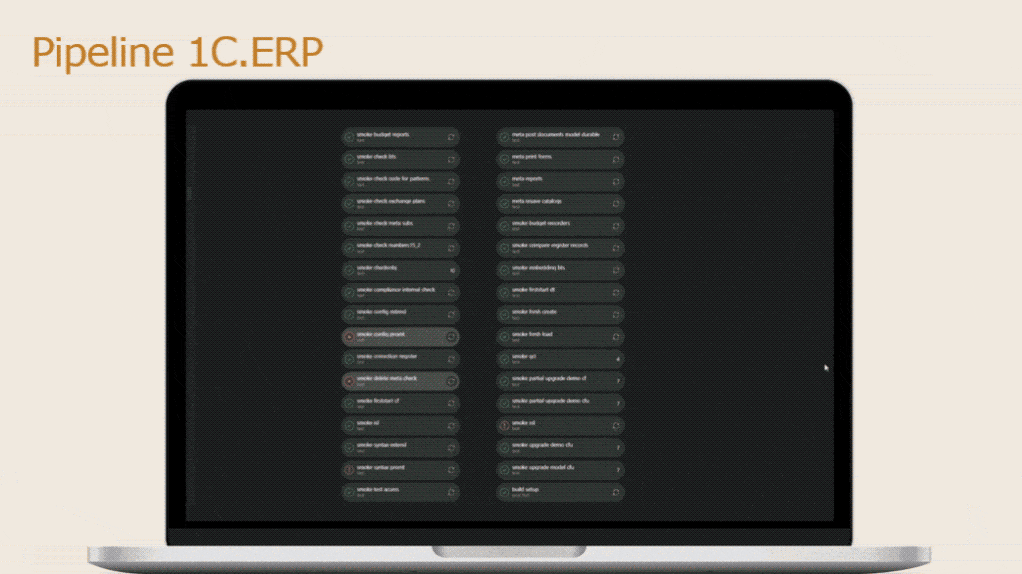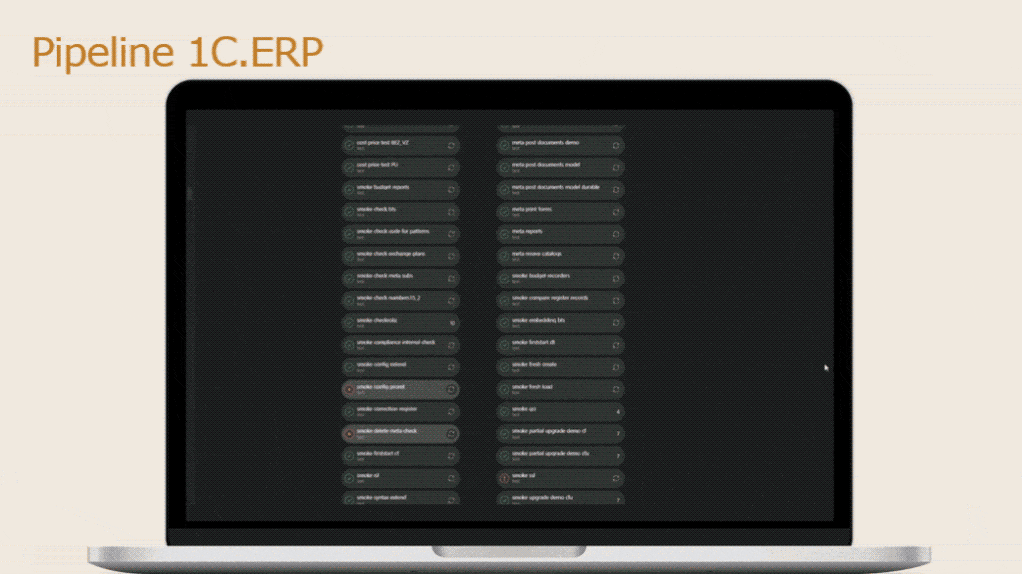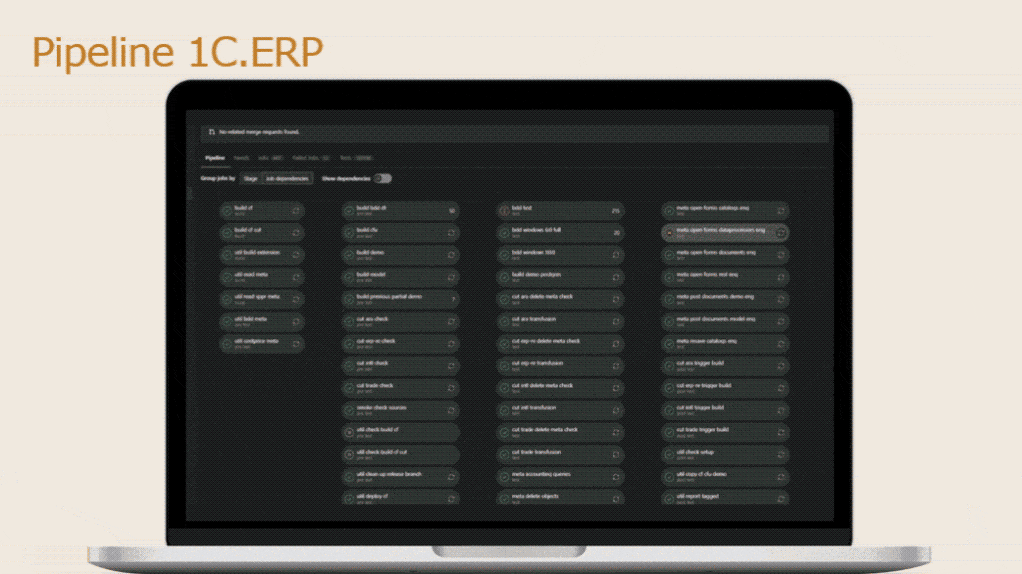
А теперь давайте посмотрим, какие пайплайны могут быть.
На слайде – пример пайплайна от команды 1С:ERP. У ребят 12 параллельно выпускаемых дистрибутивов, качество которых тщательно контролируется. Леонид Паутов в своем докладе рассказывал, что у них в пайплайне практически 500 заданий – я думаю, что для прогона такого пайплайна просто копированием настроечного файла не отделаешься.
Вы только представьте – у вас пайплайн из 500 задач, рассчитанный на несколько десятков часов выполнения. При том, что в день разработчик может создать примерно пять merge-реквестов. И все эти merge-реквесты проверяет один gitlab-раннер в один поток. Пока последний merge-реквест проверится, разработчик просто уже состарится – скажет: «Все, я увольняюсь, ухожу от вас».
Помимо этого разработчик может быть задействован на нескольких разных проектах, для сборки которых должны использоваться определенные версии платформы или EDT. А у его gitlab-раннера версия платформы и EDT совсем другая.

Все эти проблемы можно условно разделить на три категории:
-
Конфликты окружения. Например, при запуске задания мы ожидаем, что на раннере установлена версия EDT 2023.4, а оказывается, что кто-то уже перешел на 2024.1. В итоге все ломается, приходится все перенастраивать и запускать заново.
-
Увеличение длительности выполнения пайплайна – из-за большого размера конфигурации, большого количества одновременных merge-реквестов или большого количества проверяемых проектов.
-
Увеличение сложности сопровождения CI-файлов на каждом из проектов. Бывает, настроишь какую-нибудь фичу в CI для одного проекта, а потом начинаешь ее переносить на другие, и оказывается, что где-то это не работает, а почему – непонятно. Приходится тратить время, разбираться и не всегда успешно.
Решение проблем окружения
Все, о чем мы до этого говорили, было скорее введением в тему. А теперь мы наконец переходим к основному – как решать проблемы окружения.

Первое и самое важное – все, что можно запустить в контейнерах, должно запускаться в контейнерах. Это может быть докер, кубернетес или другие варианты.
И поверьте, в контейнерах уже можно запускать практически все. Есть редкие исключения в виде проверки COM-объектов или компонент. Но внешнюю компоненту мы как будто должны тестировать не в 1С, на нее должны быть написаны тесты кем-то другим где-то в другом месте. А тестировать COM-объект – это нужно быть сильным духом.
Контейнер – это маленькая виртуальная машина, которая быстро запускается сразу с предустановленным окружением (библиотеки, программы и т.д.). Весь необходимый код и зависимости уже упакованы вместе, все, что должно быть установлено, уже установлено.
Под каждую задачу в пайплайне поднимается новый контейнер, выполняет нужные действия и после завершения удаляется, не сохраняя изменений. При этом каждый такой запуск происходит «с нуля», на чистой среде, созданной с «заводскими настройками».
У контейнеров много преимуществ – основные из них приведены на слайде.
Чтобы что-то запустить в контейнере, нужен так называемый образ. Для 1С нам в целом достаточно трех образов:
-
Первый – это сама платформа разных версий.
-
Второй – это EDT, если вы разрабатываете на EDT.
-
Третий – это sonar-scanner-cli, чтобы запускать проверку SonarQube.
Самое приятное, что сообщество за нас уже постаралось и все эти образы уже подготовило, в частности:
-
В репозитории onec-docker есть образы для EDT и платформы.
-
В репозитории sonar-scanner-cli – образ sonar-scanner в докере для 1С.
Вам нужно будет собрать их самостоятельно, в проектах подробно написано, как это сделать. А остальные образы вы уже будете придумывать сами, входя во вкус.

И сразу дам небольшой совет, актуальный для сборки образа EDT вместе с установкой плагинов – например, с плагинами Language Tool или Disable Editing, который мы ставим, чтобы в EDT не изменялись объекты конфигурации на поддержке поставщика.
В EDT есть проблема – как только вы установите на него новый плагин, к следующему запуску сразу добавляется 5 минут. И если вы EDT предварительно при сборке образа не прогреете, вы на каждый шаг проверки будете тратить по 5-6 дополнительных минут. Например, на небольшой конфигурации конвертация из EDT в конфигуратор у нас занимала 12 минут, прогрели образ и уже занимает без кэша 6-7 минут.
Чтобы прогреть образ, просто вызовите команду:
ring edt platform-versions
И все – у вас образ прогрет.
Сразу предупреждаю, что это актуально для EDT с версиями ниже 2024.1, потому что в версии 2024.1 утилиту ring убрали, теперь вместо нее 1C:EDT CLI. И с 2024.1 это более не требуется, на новых версиях такой проблемы нет
Помимо прогрева, из образа EDT желательно еще удалить всякие ненужные jar-файлы, которые не обязательны для CI. Например, jar-файлы плагинов документации. На скорость запуска уменьшение размера образа кардинально не влияет, зато вы уменьшите нагрузку на docker registry – образ будет весить не 6 гигабайт, а 2.

Вернемся к GitLab CI. Чтобы запустить задание в контейнере, вам необходимо:
-
Взять сервер или виртуальную машину.
-
Установить на нее Docker (либо Kubernetes).
-
Установить и настроить в ней gitlab-раннер с типом Docker executor.
-
В настроечном файле .gitlab-ci.yml для нужного задания добавить одну строчку – прописать тег image и указать название образа, на котором этот шаг будет выполняться.
Gitlab-раннер запустит контейнер на основе этого образа и выполнит на нем ваше задание.
Но главное – если вы запускаете свой скрипт в контейнере, вам не надо заботиться об окружении: все необходимое уже упаковано в образ. Контейнер быстро запускается, выполняет задачу и завершает работу, не оставляя следов.
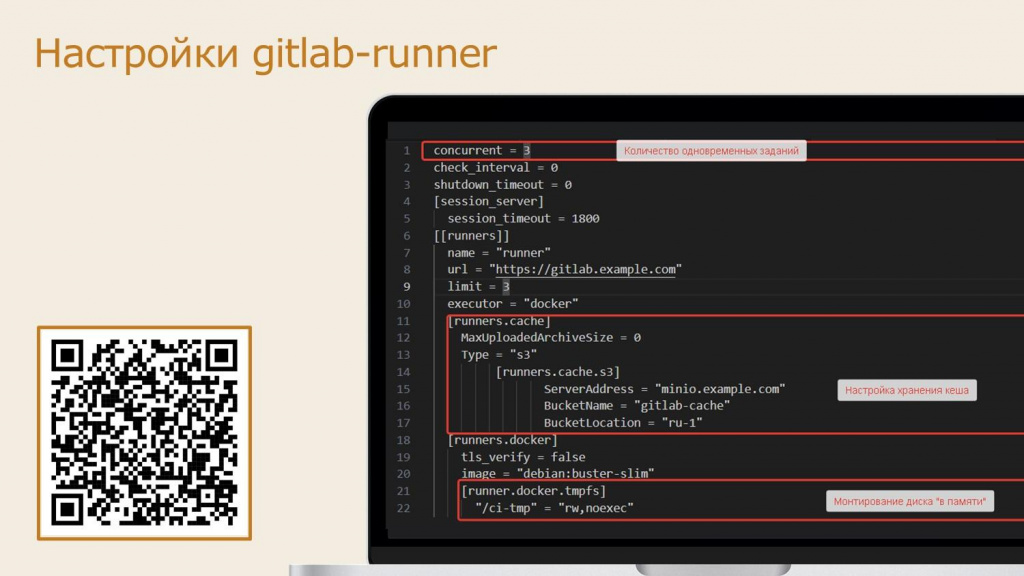
При установке gitlab-раннера вы тоже можете его настроить – для этого предусмотрен файл config.toml. Предлагаю обратить внимание на следующие настройки:
-
Флаг concurrent – определяет максимальное количество одновременно выполняемых заданий. Если выполнение ваших заданий не использует все ядра процессора, этот параметр имеет смысл увеличить. Например, скрипты OneScript или прогон тестирования по умолчанию запускаются на одном ядре, так как клиент работает на одном ядре, и их имеет смысл распараллелить, чтобы лучше утилизировать имеющиеся машинные ресурсы – выставить значение concurrent хотя бы 2-3. А EDT параллелится плохо, потому что она по умолчанию занимает все имеющиеся ядра – чтобы это учитывать, стоит распределять задания по разным раннерам, я скажу об этом чуть позже.
-
Второе – это настройка хранения кэша в секции [runners.cache]. Примеры использования кэша я приведу позднее, сейчас расскажу лишь об особенностях его хранения. GitLab Runner умеет кэшировать определенные директории, в том числе, использовать этот кэш совместно между разными пайплайнами. Но по умолчанию, когда кэш хранится в виде обычного docker volume, его использование GitLab не гарантируется, потому что при одновременном запуске нескольких заданий он может быть подключен к другому раннеру. Тем более – если раннеры запускаются на разных виртуальных машинах. Чтобы решить эту проблему, можно подключить S3 совместимые хранилища. Конкретно в нашем случае мы так же в докере подняли хранилище MinIO – подключили туда этот кэш, и он у нас относительно надежно шарится между всеми GitLab раннерами и, самое главное, между всеми контейнерами.
-
Ну и последнее – gitlab-раннер умеет монтировать каталог в оперативную память при запуске контейнера. Это настраивается в секции [runner.docker.tmpfs]. В нашем случае в каждый контейнер при запуске будет монтироваться RAM-диск /ci-tmp. Это может быть полезно для любых операций, в которых важна скорость диска – например, для инициализации или реструктуризации базы данных или любых других операций ввода-вывода, чтобы они выполнялись быстрее. В принципе, воркспейс EDT туда тоже можно положить.
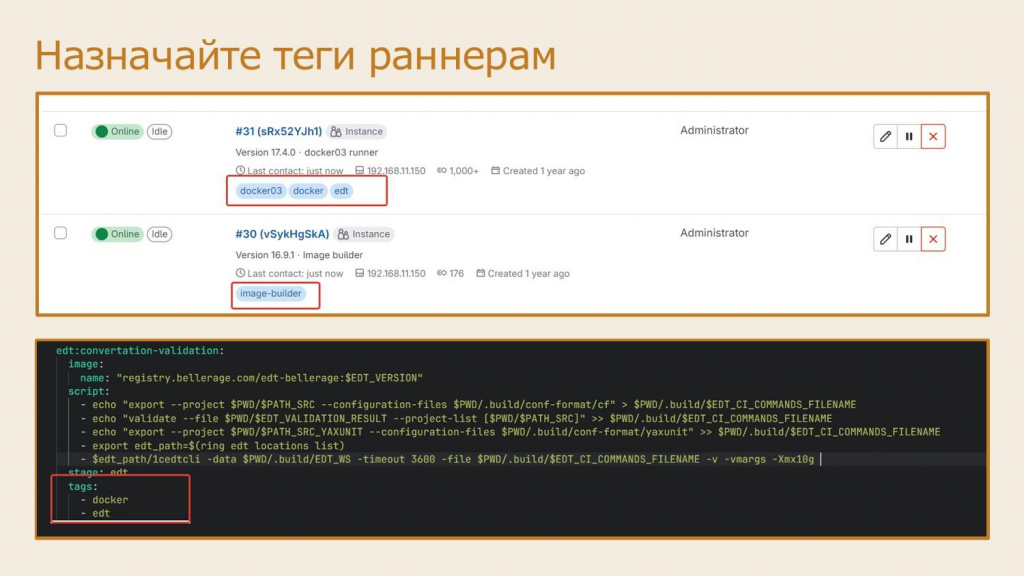
Если внимательно перечитать предыдущие пункты и вспомнить, что EDT может использовать все ядра процессора, а запуск тестов – только одно, может возникнуть логичный вопрос: как разделить шаги по EDT с тестами, чтобы они выполнялись параллельно?
Для этого в GitLab предусмотрена возможность разделить шаги по разным раннерам с помощью механизма назначения тегов.
Вы регистрируете несколько раннеров с назначением им тега, а далее в файле .gitlab-ci.yml для каждого задания указываете тег, на котором это задание может выполняться. В этом случае все задания по EDT могут быть выстроены на одном раннере в очередь по одному, а запуск тестов выполняться на другом раннере в параллель, не влияя на другие задания.
Теги можно использовать также для разделения заданий по разным операционным системам.
Важно: все теги, указанные для шага в файле .gitlab-ci.yml, должны быть одновременно на раннере. Если хоть какого-то из них нет, шаг на этом раннере не запустится. Если же в раннере есть все теги, а в файле .gitlab-ci.yml только один, который входит в этот набор, этот раннер для этого шага запустится.
Решение проблем длительности выполнения
Закончили с раннерами и окружением. Переходим к решению проблем производительности и увеличению скорости запуска.
Вообще в моем докладе будет везде прослеживаться общая мысль: «Максимально повышайте параллельность выполнения шагов, утилизируйте то железо, которое у вас есть. Чем больше параллельности вы сможете сделать в пайплайне, не потеряв в общей производительности, тем лучше».
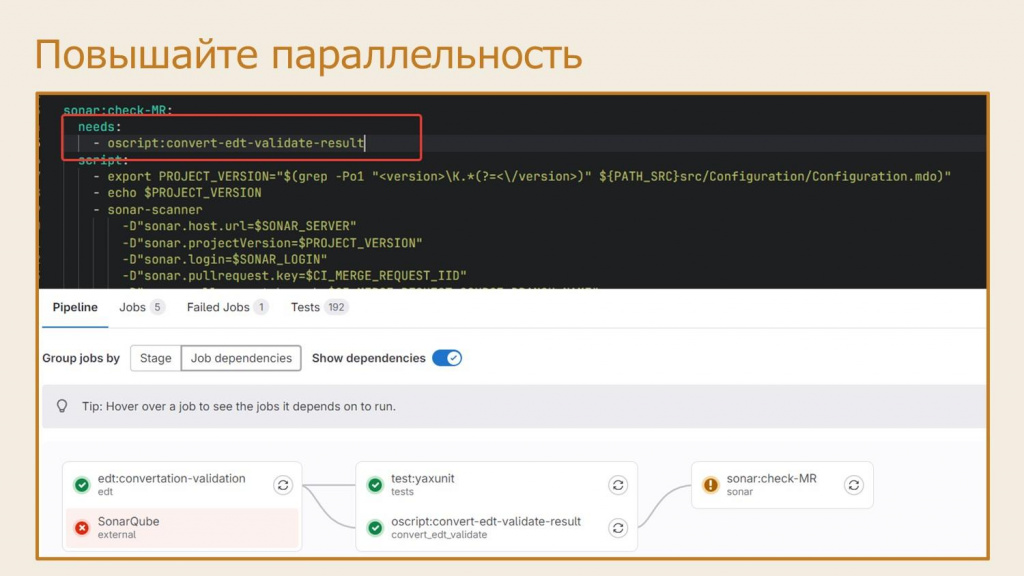
Разберем конкретный пример – на слайде показана часть нашего пайплайна:
-
на шаге edt:convertation-validation исходники в формате EDT конвертируются в формат конфигуратора и собирается CF-файл;
-
на шаге test:yaxunit запускаются тесты;
-
и на шаге sonar:check-MR стартует проверка SonarQube.
Очевидно, что SonarQube не надо ждать, чтобы запускались тесты – эти шаги могут запускаться параллельно. Для этого при описании шага в .gitlab-ci.yml можно использовать ключ needs, где вы указываете, какие шаги должны быть выполнены для выполнения текущего шага.
В этом случае прямо в визуализаторе GitLab CI по переключателю «Show dependencies» можно будет увидеть граф зависимостей шагов одного от другого – он покажет, что и как занято. Правда в нашем случае после запуска конвертации EDT еще есть конвертация и валидация для Sonar, но она быстрая, а сразу после нее запустится SonarQube.
Таким образом у нас параллельно запускаются тесты и SonarQube – мы не ждем их по очереди, уменьшая общее время выполнения.
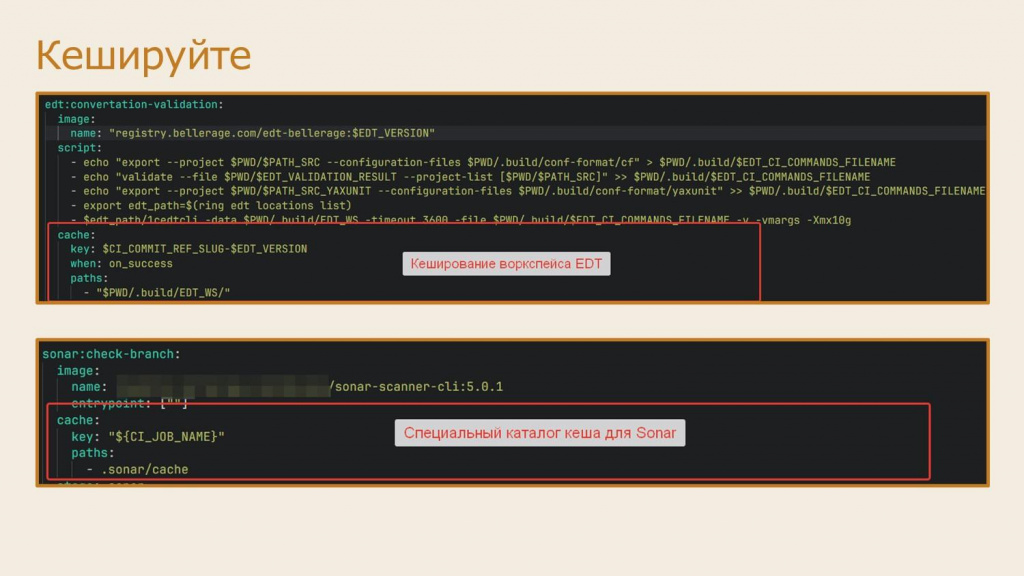
Второе – кэшируйте. Я уже рассказывал, как настраивается кэш для раннеров, теперь давайте обсудим, как этот кэш можно использовать.
-
Имеет смысл кэшировать воркспейс EDT – специальный каталог рабочего пространства EDT, где она хранит свои вторичные данные (НЕ сами исходные файлы). В большинстве случаев это дает примерно двух-трех-кратный прирост для повторной конвертации или проверки. Из советов – при описании раздела cache для шага следите за корректностью ключа кэша (параметра key). Ключ определяет уникальность кэша для конкретной задачи и при его указании можно использовать переменные. Обязательно включайте в ключ кэша версию EDT, потому что воркспейсы разных версий EDT несовместимы между собой. Мы еще включаем в этот ключ имя ветки – тогда первый прогон на ветке проходит полностью, а все последующие (допустим, после исправления замечаний на ревью) заметно быстрее: например, не 7 минут, а две.
-
Обязательно кэшируем шаги SonarQube – именно так требует его документация.
-
Можно кэшировать и шаги по инициализации пустых баз 1С, чтобы реструктуризация занимала меньше времени – например, можно кэшировать пустую базу для проверки синтаксиса или запуска юнитов.
-
То, что выполняется недолго, кэшировать не имеет смысла. Не забывайте, что мы переходили на контейнеры ради полной изоляции окружения, и кэш вам может это поломать. Поэтому кэшируйте только то, что нужно, и аккуратно.
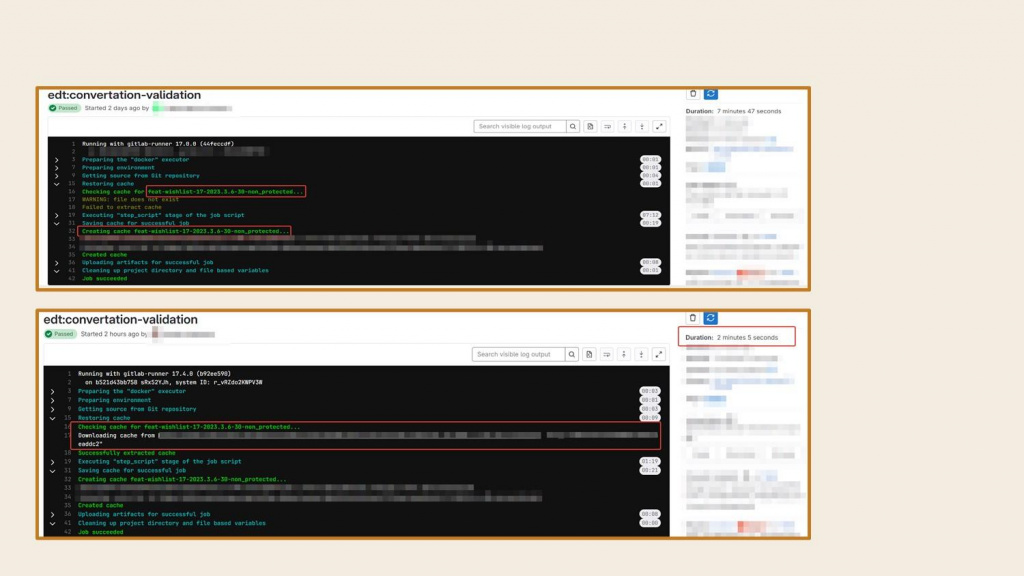
Здесь показан пример, как использование кэша EDT для небольшой конфигурации – при повторном запуске время шага уменьшается с 7-8 минут до 2-3.
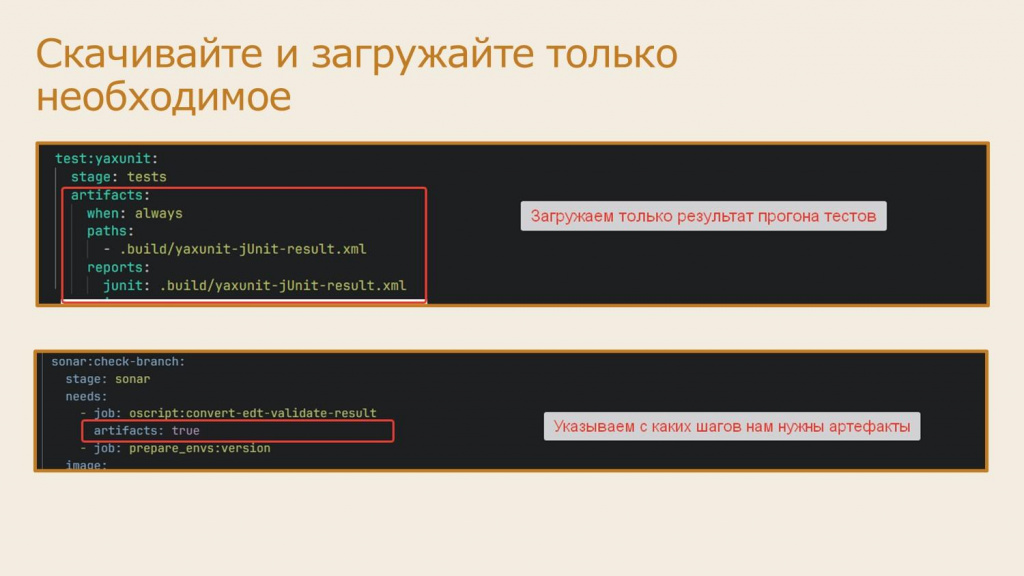
Обычно для передачи результатов с одного шага на другой используется механизм артефактов в GitLab – например, когда с шага конвертации исходников EDT нужно передать исходники в формате конфигуратора на следующие шаги. Однако для шага проверки SonarQube мне эти артефакты не нужны – SonarQube спокойно может обрабатывать исходники и в формате EDT, но система по умолчанию тратит время на передачу этих артефактов между шагами.
Поэтому скачивайте и передавайте на следующие шаги только необходимые артефакты, а для этого явно указывайте, какие артефакты на шаге вам нужно выгружать и скачивать.
-
Например, чтобы выгрузить с шага только конкретный артефакт, указывайте в разделе artifacts путь к нему в ключе paths.
-
А для скачивания конкретного артефакта на шаге можно использовать два ключа: ключ dependencies или needs:artifacts. Только учитывайте, что ключ dependencies несовместим с needs – если вы используете зависимость шагов через needs, он автоматически берет артефакты только от этих шагов. Но вы можете ему дополнительно сказать artifacts: false, если артефакты с этого шага скачивать не надо.
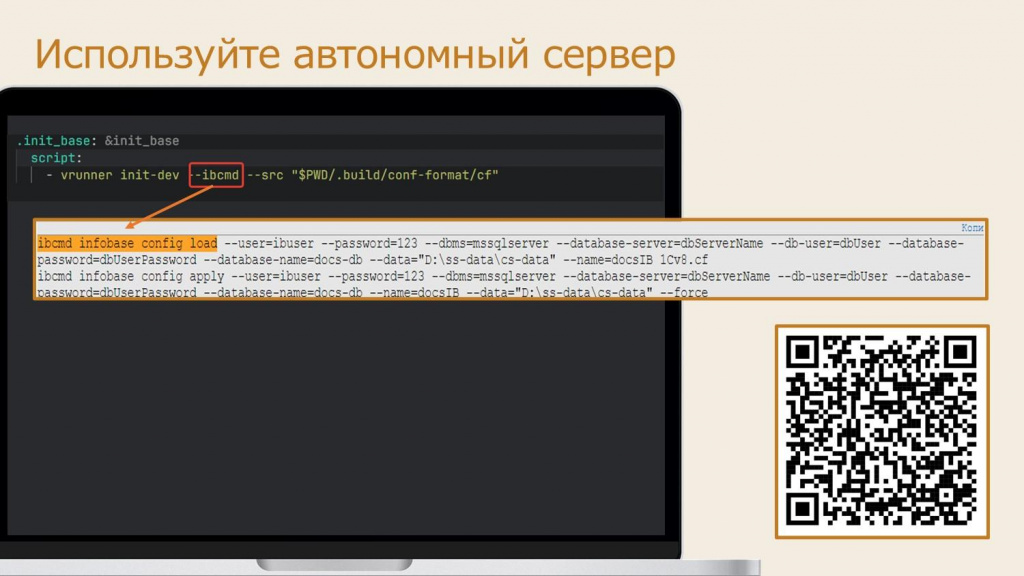
Для сборки CF-файла или загрузки в базу сконвертированных исходников чаще всего используется vrunner или прямой вызов конфигуратора. Но относительно недавно у нас появилась такая вещь как автономный сервер. По сравнению с обычным агентом конфигуратора автономный сервер работает многопоточно, что значительно ускоряет процесс подготовки базы – например, на ERP это получается в 4?5 раз быстрее.
Только учтите, что автономный сервер многопоточный, и его шаг на gitlab-раннере не нужно параллелить – если раньше вы делали сборку конфигуратором на одном gitlab-раннере и могли запустить параллельно несколько, то с автономным сервером так делать не рекомендуется.
Но главное, если вы используете в своих CI-скриптах vrunner, вам, чтобы начать использовать автономный сервер, всего лишь нужно добавить при вызове скрипта параметр --ibcmd. Например:
vrunner init-dev --ibcmd --src "<ПутьКПапкеИсходников>"
И все заработает. Всего шесть символов, а столько пользы. И, кстати, спасибо всем тем, кто реализовал это в vrunner – прям отдельный респект.

Бывают ситуации, когда в репозитории меняется не исходный код проекта, а прочие файлы – например, документация или настроечные файлы. Представьте: вы просто поправили опечатку в документации, а у вас запустился полный цикл работы с исходниками (тестирование, билд и т.д.). Согласитесь, это не имеет смысла.
Чтобы этого избежать, в файле .gitlab-ci.yml есть специальная секция rules:changes, где можно указывать маску пути к файлам исходников – например, мы можем указать, что этот шаг должен выполняться только в случае, если при коммите поменялись файлы по маске или конкретный указанный в этой секции файл.
Допустим, мы запускаем тесты и проверку SonarQube только если поменялись файлы в папке src – путь которых совпадает с маской src/**/*. Только тогда шаги запускаем. Если не поменялись – не запускаем.
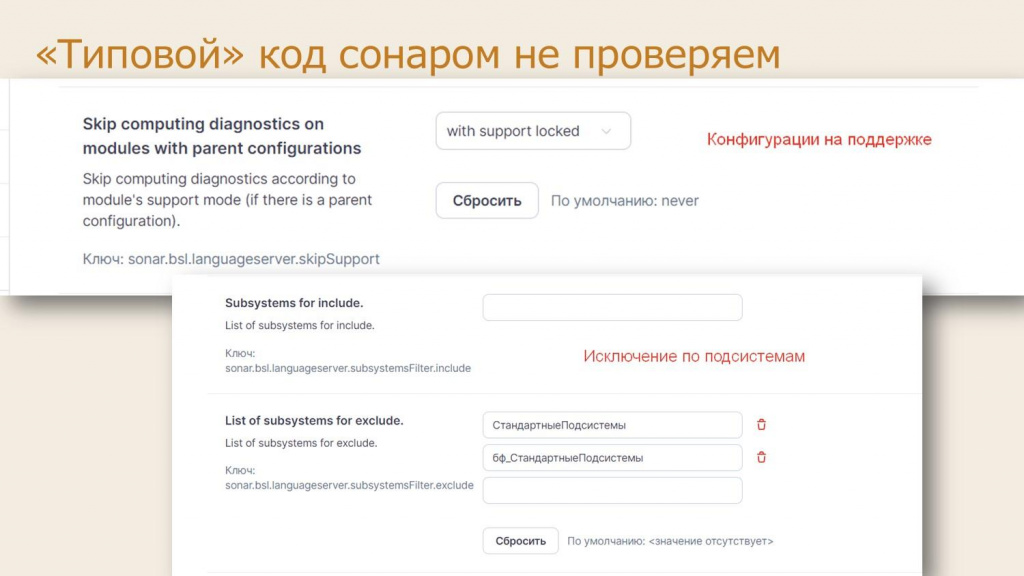
Ну и последний важный совет – типовой код, если вы его дорабатываете, с помощью SonarQube проверять не нужно. Ну зачем это вам? Я думаю, что почта 1c@1c.ru и так уже переполнена сообщениями, присланными со всех SonarQube. Им не надо это. Раз им это не надо, то и мы на это тоже время тратить не будем.
Если вы используете механизм поддержки, установите исключение в настройках плагина SonarQube через параметр «Skip computing diagnostics on modules with parent configurations». Либо настройте параметр skipSupport в файле .bsl-language-server.json и пропишите к нему путь в настройках плагина. Установите там один из двух вариантов, если не хотите проверять файлы на поддержке:
-
with support locked – исключить из анализа конфигурацию «на замке».
-
with support – исключить вообще файлы на поддержке.
А если вы не используете механизмы поддержки, вы можете указать исключения по составу подсистем – файлы каких подсистем вы проверять не хотите. Конкретно в нашем случае мы указали исключение для подсистем: СтандартныеПодсистемы и бф_СтандартныеПодсистемы (это наша библиотека, мы ее тоже пропускаем и не проверяем). На условных клиентских доработках «Комплексной автоматизации» это уменьшило время проверки с 40 минут до 2. Конечно, нам всем кажется, что мы столько в типовой допилили, но как только код стандартных библиотек исключаешь, оказывается, что вся наша работа укладывается в пару мегабайт.
Решение проблем сопровождения
И последний спектр проблем, которые хочется обсудить – это решение проблем сопровождения.
Мы с вами уже разбирали ситуации, когда нужно было многое править в файле .gitlab-ci.yml – указывать версии EDT, платформы и прочего. Часть кода в разных шагах может повторяться, но есть и различия. А теперь представьте, что у вас таких проектов не один, а десять – и для них тоже могут быть различия. Как все это поддерживать?
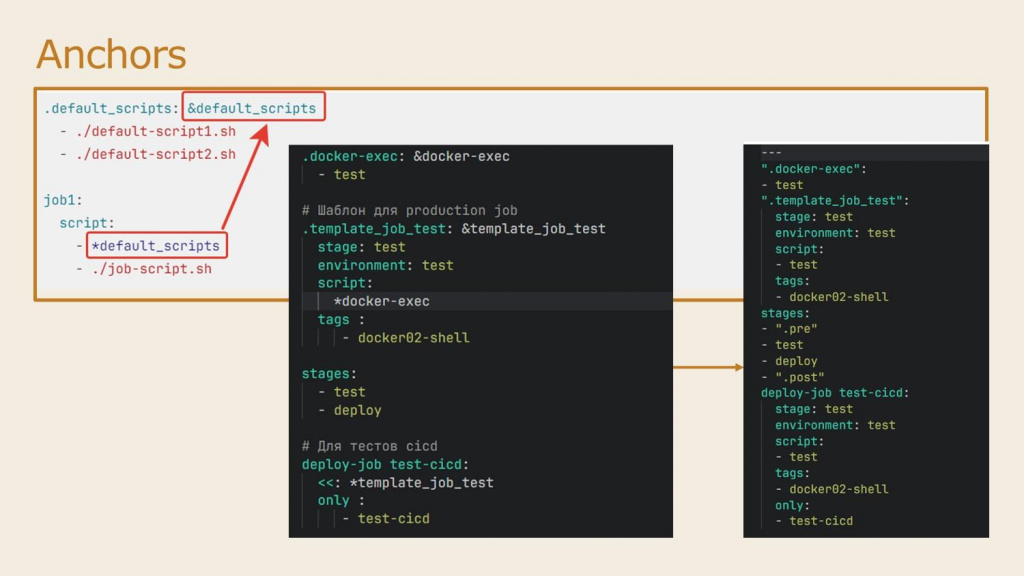
Чтобы избежать дублирования кода, в GitLab CI есть несколько возможностей.
Первое – это якори, так называемые anchors. По сути, это похоже на именованные функции, куда мы помещаем куски скриптов и любые другие настройки CI-файлов.
На слайде показан пример, как можно вынести в качестве якоря кусочек настройки &default_scripts. Мы его помечаем амперсандом, и потом в других скриптах можем его использовать через «звездочку» – он туда вмержится.
Справа – пример, как в итоге происходит мерж в конечный результат, который будет запускать раннер. Да, в этом примере скрипты получились одинаковые по размеру, но в реальности блок скрипта может быть на десятки, а то и больше строк.
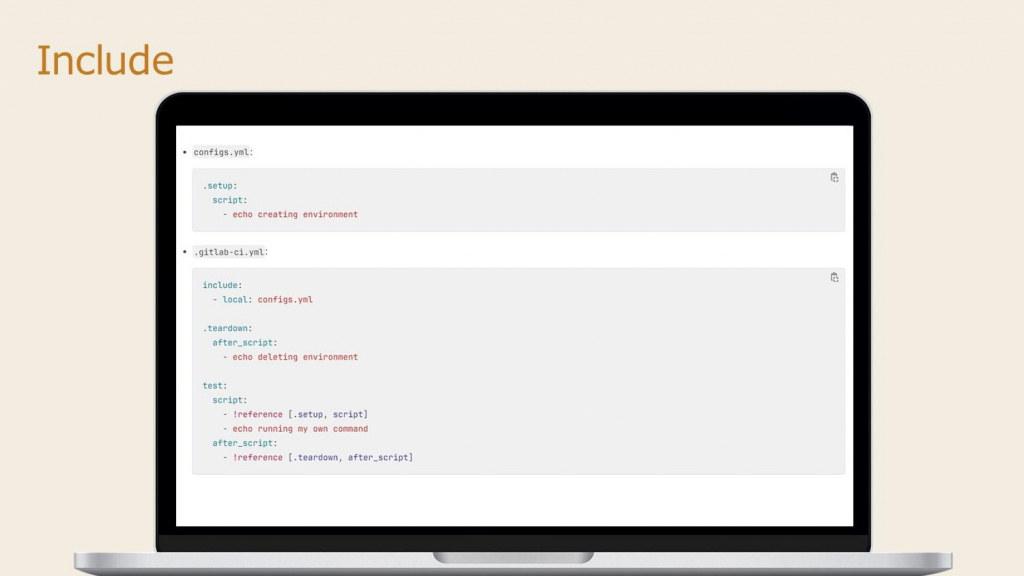
Кроме этого, для упрощения сопровождения больших CI-файлов есть возможность разбивать один пайплайн на несколько файлов.
Для этого используются механизм include, который позволяет импортировать указанный вами файл в ваш пайплайн и использовать его там.
На скриншоте показывается, как можно использовать те же именованные функции, но из другого файла, используя include и reference – допустим, у вас есть кусок скрипта в отдельном файле configs.yml, и вы используете его в основном пайплайне.
Общий совет – разбивайте ваши пайплайны логически: по шагам или по блокам шагов. Без фанатизма. Не надо делить на маленькие кусочки, иначе вы запутаетесь.
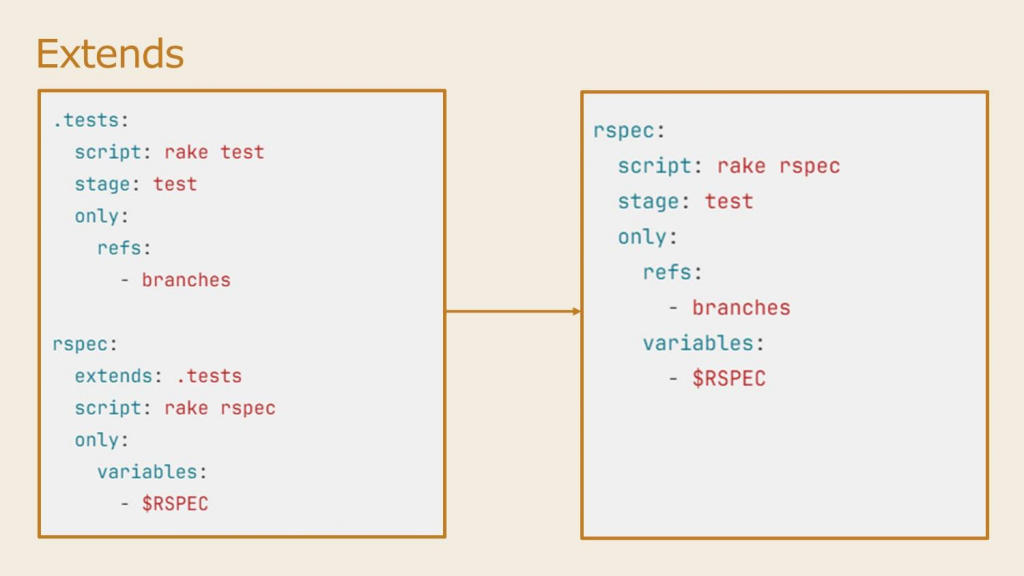
Если вам показалось, что механизм anchors – это что-то сложное и непонятное, вы не одиноки. Сами разработчики GitLab это тоже прекрасно понимают. И они придумали более гибкий, удобный и читаемый механизм ему взамен – extends.
По сути это то же самое – вы опять же выносите кусочек шага отдельно и даете ему имя. А потом в других шагах можете расширить этот оригинальный вариант, заменив в нем только те поля, которые в этом конкретном случае вам не подходят.
Причем include и extends можно использовать вместе, а исходный файл не обязательно должен быть в том же репозитории, он может находиться в другом проекте, и даже на другом Git-сервере по прямой ссылке.
CI/CD components
И хотя эти include, extend, якори и позволяют значительно упростить сопровождение пайплайнов, с ними все равно было как-то сложно – хотелось что-то наподобие библиотек. И действительно, в GitLab CI 17 из беты вышел механизм CI/CD components – компоненты GitLab CI, очень похожие на настоящие библиотеки.

Отличительные особенности компонентов CI/CD:
-
Они версионируются – вы можете указывать в своем репозитории, какую версию используете.
-
Указывается контракт их вызова – вы не просто абстрактными кусками их вызываете, а как функцию, у которой есть набор параметров, типы и прочее.
-
При описании этот контракт автоматически документируется – эту документацию можно вынести в отдельный репозиторий.
-
CI/CD компоненты могут использоваться во всех проектах GitLab-сервера.
-
В GitLab CI есть отдельный магазин компонент, которые можно использовать.
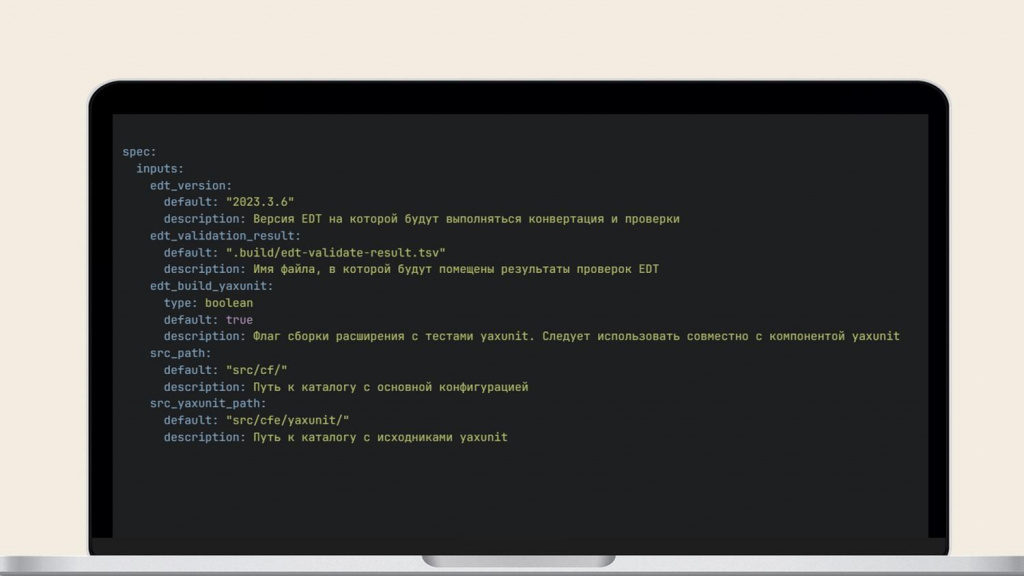
Обычно в компоненты зашивается конкретный шаг – запуск EDT, тесты, сборка и прочее. А описываются они в таких же YAML-файлах с некоторыми особенностями – нужно дополнительно описать контракт взаимодействия с компонентой.
На слайде – пример настройки такой CI-компоненты. Здесь указывается:
-
какую версию EDT нужно использовать;
-
где находятся исходники;
-
нужно ли конвертировать тесты и т.д.
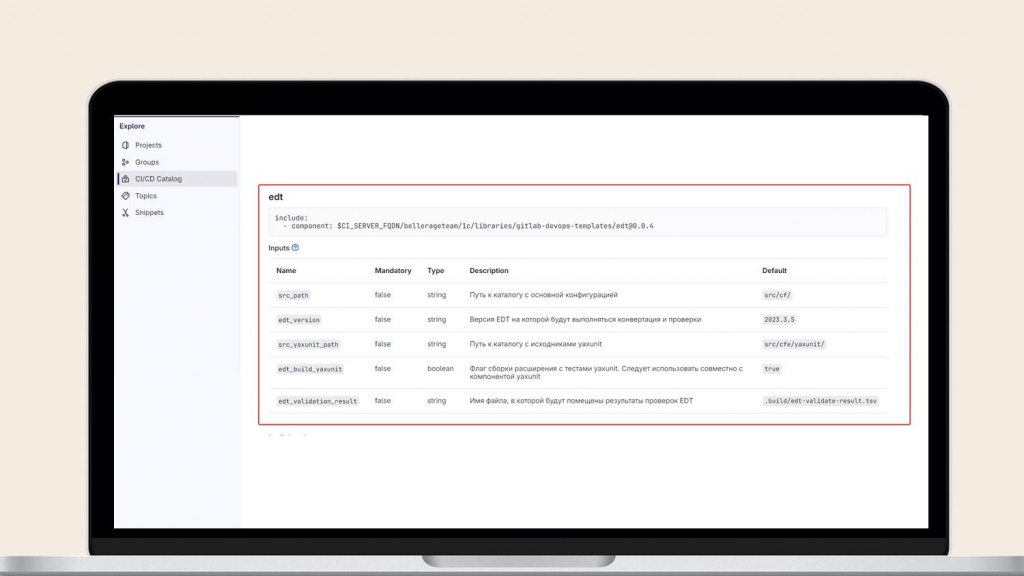
А потом GitLab это все автоматически преобразует в документацию, которую можно просто отдать другому разработчику.
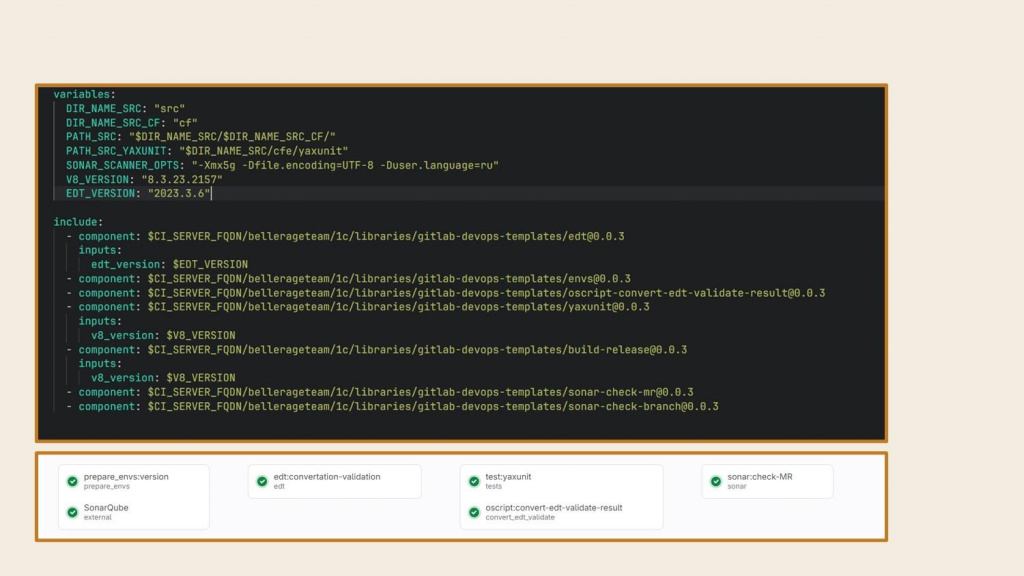
Вот так теперь выглядит наш пайплайн на 7 шагов – в нем всего лишь 20 строк. Сверху описаны все переменные, а в шагах указано, какие версии компоненты используются и какие переменные туда передаются. Вообще сказка.
Самое главное – если у вас много проектов, вы это просто раскатываете по всем репозиториям и никаких проблем с версионированием нет.
Я считаю, что это сейчас самый удобный способ для удобного сопровождения ваших CI-файлов на проектах. Причем в этих компонентах можно использовать те же самые include, extends, anchors и другое – комбинируйте.
Как долго хранить артефакты? Generic Package Registry
И напоследок я хотел рассказать о такой вещи, которая напрямую не относится к теме, но заслуживает отдельного внимания – Generic Package Registry.
Часто нам нужно сохранять артефакты в GitLab CI на долгое время – например, сборки релиза могут храниться годы.
Обычно для этого используется механизм артефактов, но он не надежный, артефакты могут удаляться автоматически из-за разных факторов. Я предлагаю использовать для этого специальный механизм – Generic Package Registry.
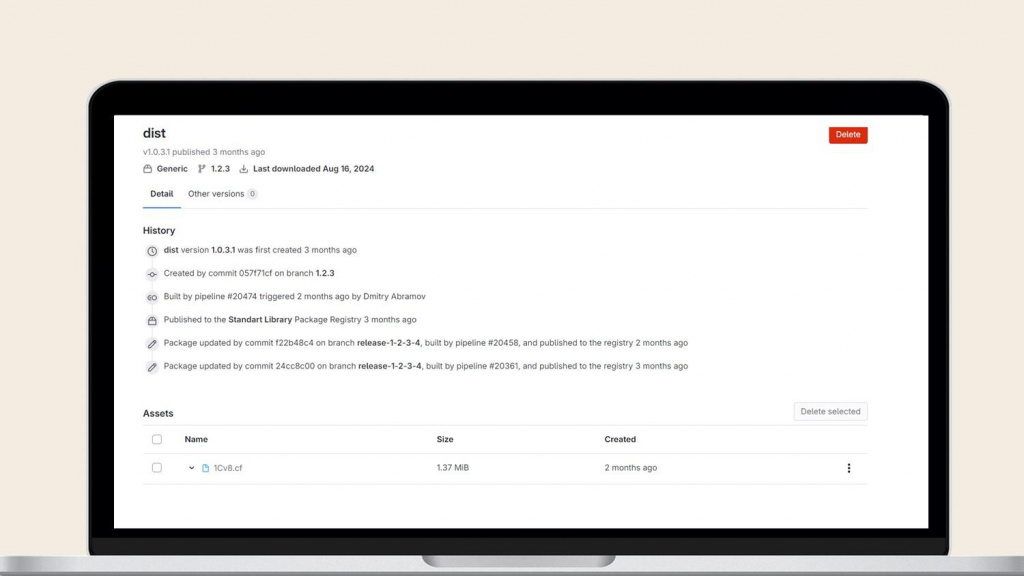
Этот механизм позволяет крепить к проекту любые файлы – загружать их из CI и крепить к релизам в GitLab.
По каждому файлу хранится история изменения. На слайде показано, что файл был загружен в package registry в конкретном CI-шаге сборки релиза – можно посмотреть, из какого пайплайна и коммита он был собран.
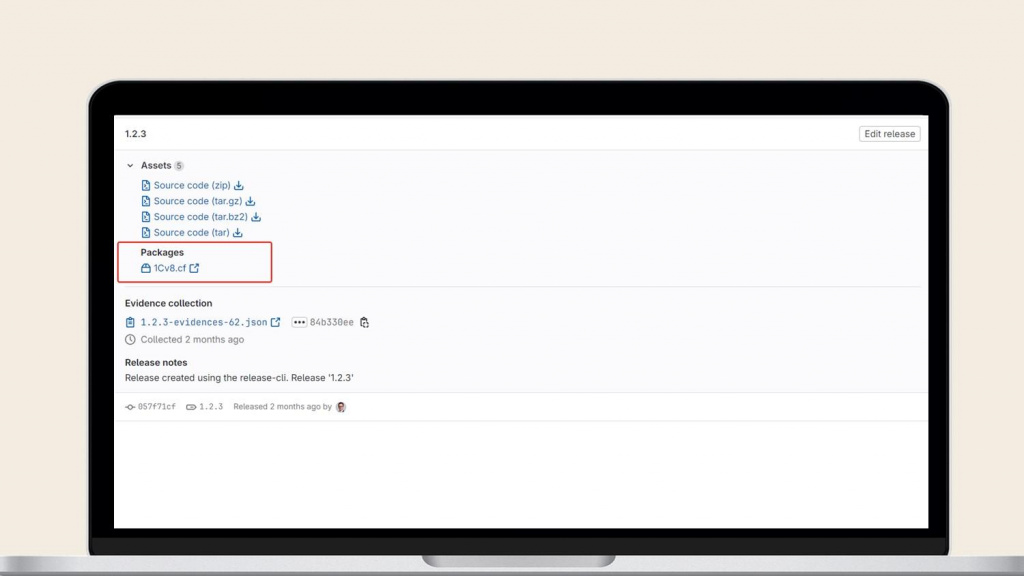
Далее ссылку на этот файл можно указать в релизе.
Мы сейчас исследуем, как сделать свой downloads.v8.1.ru, чтобы в конфигураторе указать адрес нашего GitLab и при ручном обновлении скачивать CFU прямо с GitLab.
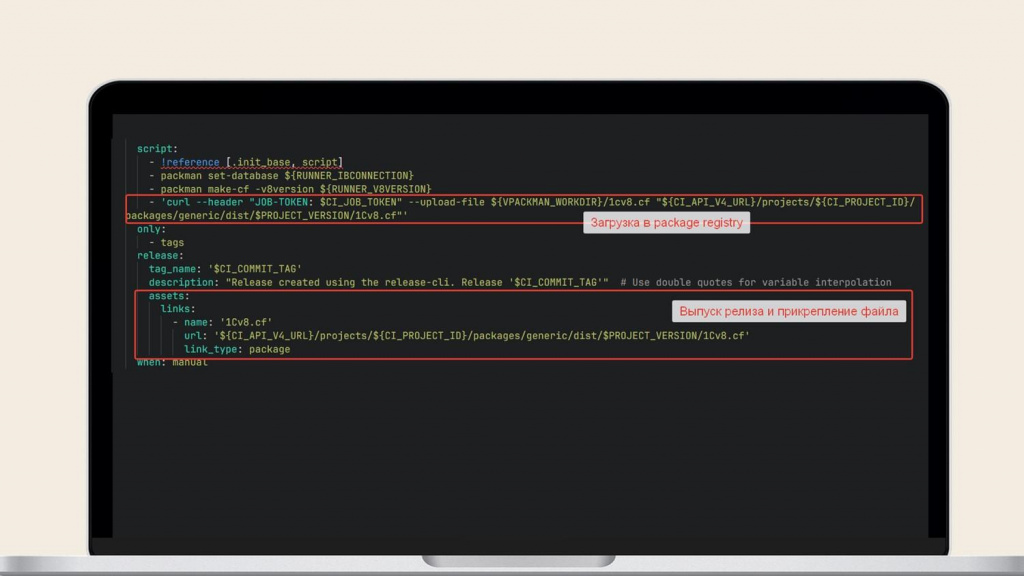
А вот так это выглядит в CI-файле компонента сборки:
-
мы ставим заданию тег релиза;
-
автоматически собирается релиз;
-
через curl загружается в package registry;
-
и далее к релизу крепится ссылка на файл в package registry.
Развитие нашего GitLab
Идеи для развития, которые мы сейчас прорабатываем:
-
Первое – это использование autoscaler. Допустим, если у нас в очереди скопились задания, мы арендуем виртуальные ресурсы у условного Яндекса. И у GitLab с 17-й версии появился аналогичный механизм Autoscaler, через который можно интегрироваться с ресурсами внешних клаудов. Уже есть плагины для Амазона и других клаудов, и мы сейчас тоже поработаем над этим.
-
И второе – это поднятие контуров для ручного тестирования на базе GitLab Environments. Такие контуры особенно распространены в веб-разработке: там при каждом изменении автоматически разворачивается мини-версия сайта, где можно сразу увидеть результат. Перейти на нее по ссылке из GitLab и оставить комментарий в этом же merge-реквесте.

DevOps-внедрение для 1С
Автоматизируем разработку и поставку решений 1С. Внедрим CI/CD, оптимизируем пайплайны и ускорим выход обновлений
Вопросы и ответы
Вопрос про размер контейнера EDT. У нас он состоит из трех слоев – первый слой копирует файл дистрибутива, второй слой начинает установку, третий – настраивает EDT. Но даже если мы в процессе установки удалим файл дистрибутива, размер контейнера остается прежним. Как это можно решить?
У вас сам дистрибутив лежит в слое внутри образа. Такого быть не должно. Чтобы такого не происходило, вам надо прямо в процессе создания образа этот дистрибутив скачать, установить и удалить. Тогда он у вас в образ не положится.
Вы можете заранее скачать дистрибутив EDT на свой корпоративный ресурс так, чтобы у вас была shared link для его скачивания. Или в корпоративный S3 его положить и открыть доступ по ссылке. А потом просто при создании образа через curl его скачиваете, распаковываете и удаляете все, что скачивали. Тогда это не попадет в ваш образ.
Вы сказали, что что-то отрезаете от EDT при создании образа. Как вообще понять, что можно отрезать, чтобы она живая осталось?
Практика. Практика и нервы. Но я вам не рекомендовал такое делать, если что.
Какого примерно размера у вас получается контейнер с EDT?
2,2 гигабайта с плагинами. Крохотный образ.
Где вы храните сами файлы .gitlab-ci.yml? Прямо в проекте или в отдельном репозитории? У GitLab же любые изменения этого файла отражаются в истории коммитов проекта.
Так и должно быть, если мы храним .gitlab-ci.yml внутри.
Можно создать отдельный DevOps-проект, где хранить всю структуру этих CI-файлов, включая include-файлы. А в настройках GitLab основного проекта подключить CI-файл из другого репозитория. Правда тогда изменения в этом DevOps-проекте могут сразу отразиться на всех связанных репозиториях – но вы же можете указывать не просто ссылку, а конкретную ветку (например, всегда брать настройки CI-файла только из master). Альтернативный вариант – использовать компоненты, ссылаться на конкретную версию.
Например, у нас около 15 проектов 1С – все, что связано с CI/CD, мы вынесли в отдельный репозиторий, и через переменные раскатываем нужные конфигурации на каждый проект.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт