Цели и структура мониторинга
Меня зовут Петр Назаров, я эксперт по технологическим вопросам в компании «ИТ-Экспертиза». В этой статье я расскажу о теории задач и объектов мониторинга – зачем нужно следить за системой и что именно важно контролировать. Также коснемся работы внутренних механизмов, состояния базы данных и приложения. Кроме того, будет немного практики: разберем ключевые метрики, способы их получения и инструменты для постоянного мониторинга.
За чем же нам нужно наблюдать? За внутренними механизмами PostgreSQL, такими как:
-
буферный кэш,
-
WAL,
-
фоновые процессы,
-
репликация.
Буферный кэш (Shared buffers)
Начнем с буферного кэша. Его назначение очевидно: данные, считанные с диска, сохраняются в кэше, чтобы при повторном обращении не читать их снова с диска. Это позволяет снизить нагрузку и повысить производительность системы.
Главный вопрос здесь – хватает ли нам объема кэша для текущих нагрузок или он избыточен. Отслеживать поведение и состояние кэша помогают представления pg_buffercache и pg_stat_database. Дополнительно можно использовать расширение pg_shmem_allocations, чтобы понять, какие еще объекты PostgreSQL находятся в памяти и сколько места они занимают.
Примеры подходящих скриптов будут приведены ниже.
Важный момент: почему мы не можем выделить под кэш всю оперативную память?
Прежде всего, это двойное кэширование. Линукс кэширует данные, поэтому, возможно, данных нет в кэше Postgres, но они есть в кэше операционной системы.
Точно также необходима память под другие процессы операционной системы, в том числе и под другие процессы Postgres.
Чем плох недостаток кэша? Больше нагрузки на диск, дольше выполняются запросы, ниже производительность информационной системы.
А чем может быть плох избыток кэша? Это не столь критично, как нехватка, но все же есть нюансы. Во-первых, растут накладные расходы на его обслуживание, например на вытеснение данных. Во-вторых, если у вас слишком много свободной оперативной памяти, возможно, ее будет разумнее передать другим сервисам.
Общая рекомендация по настройке буферного кэша – около 25% от объема оперативной памяти. Это базовая рекомендация для начала, потом в случае эксплуатации ее можно подрегулировать: поднять или опустить.
Метрики и диагностика состояния буферного кэша
Важная метрика при анализе буферного кэша – это cache hit ratio, показатель процента попаданий в кэш. Он отражает, откуда мы читаем данные: напрямую из кэша или с диска.
Пример скрипта для получения показателя процента попаданий в кэш
SELECT
now(),
datname,
round(100 * sum(blks_hit) / sum(blks_hit + blks_read), 3) as cache_hit_ratio
FROM pg_stat_database
where blks_hit + blks_read > 0
GROUP BY datname
Хорошей ситуацией считается, когда процент попаданий в буферный кэш близок к 100 – значит, почти все данные читаются из памяти, и система работает максимально эффективно. Но если это не так, есть всего несколько вариантов:
-
Увеличить размер ОЗУ
-
Увеличить shared_buffers
-
Оптимизировать запросы

На графике показан пример, где в определенный момент времени буферный кэш проседает. Такие ситуации требуют внимания как администраторов, так и разработчиков. Полезно в этот момент посмотреть активные запросы в базе, выяснить, какие именно операции выполнялись, и при необходимости оптимизировать их.
Процент попадания в буферный кэш можно получить не только для всей базы (pg_stat_database), но на уровне отдельных таблиц и индексов (с помощью системных представлений pg_statio_all_tables, pg_statio_all_indexes и т.д.).
С помощью pg_buffercache можно посмотреть, чем в настоящий момент занят кэш: какие в нем находятся таблицы и индексы, насколько он прогрет или, наоборот, остается холодным. Это позволяет глубже понять состояние системы и эффективность использования памяти. В 16-й версии в расширение добавили функции pg_buffercache_summary() и pg_buffercache_usage_counts(), сокращающие время получения информации о состоянии буферного кэша.
Пример запроса для получения информации о состоянии буферного кэша:
SELECT now() AS timestamp,
count(*) FILTER (WHERE reldatabase IS NULL) AS free,
count(*) FILTER (WHERE isdirty = 'f') AS clean,
count(*) FILTER (WHERE isdirty = 't') AS dirty
FROM pg_buffercache

На этом графике можно увидеть состояние буферного кэша по категориям: количество свободных, занятых, грязных буферов и т.д.
Журнал предзаписи (WAL): назначение и мониторинг
Сам по себе буферный кэш – отличная вещь, но данные из него все равно нужно периодически сбрасывать на диск и синхронизировать для сохранения согласованности.
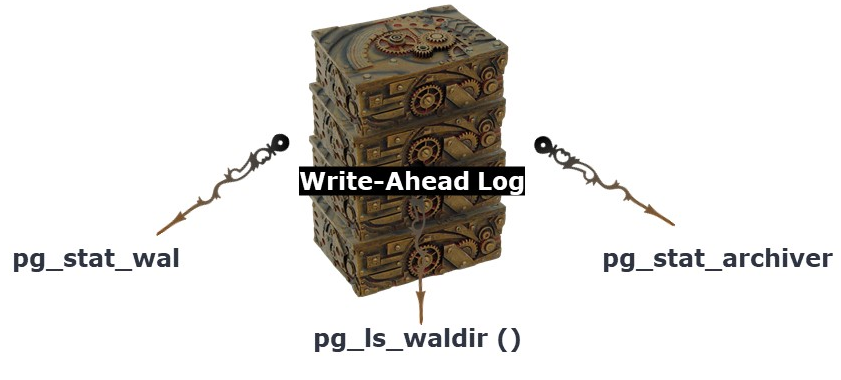
В этом помогает журнал предзаписи (WAL). Механизм работает так: сначала информация об изменениях записывается в журнал, а затем выполняются сами изменения. Это обеспечивает корректную репликацию, позволяет восстанавливаться после сбоев и возвращать систему к состоянию в прошлом. Поэтому WAL крайне важен и, как и другие механизмы, требует мониторинга.
Что именно мы отслеживаем:
-
скорость работы журнала предзаписи,
-
статистику операций,
-
мониторим архивацию журнала.
Представления, с помощью которых мы мониторим архивацию журнала:
SELECT sum(size)
FROM pg_ls_waldir()
Здесь важным является размер файлов журнала предзаписи. Если они вдруг начинают накапливаться, есть риск, что диск быстро заполнится, и в итоге кластер просто перестанет работать. Это можно отслеживать, например, через функцию pg_ls_waldir.
Помочь с ограничением роста журналов может параметр max_slot_wal_keep_size (появился в 13-й версии).
Причины накопления файлов могут быть разными:
-
репликация была настроена, но перестала работать,
-
ошибка в archive_command,
-
слишком медленная запись WAL.
Поэтому важно также следить за самой скоростью записи – и в плане количества операций, и в плане объема данных (байт в секунду). Получаем эти данные с помощью pg_stat_wal при включенном параметре track_wal_io_timing, представление появилось в 14-й версии PG). Такие метрики позволяют увидеть нагрузку на систему и вовремя реагировать.


На графиках, построенных по этим метрикам, хорошо виден значительный пик нагрузки. Он пришелся на момент восстановления одной из баз данных в кластере.
Фоновые процессы: checkpointer и background writer
Помимо журнала предзаписи есть еще процесс checkpointer, который фиксирует контрольные точки на диске. Благодаря этим точкам в случае сбоя можно быстрее и надежнее восстановить данные.
Также существует процесс фоновой записи background writer (bgwriter). Его задача – разгрузить работу с буфером, записывая на диск грязные (но уже неиспользуемые в данный момент) буферы. За счет этого снижается нагрузка на те процессы, которым не нужно тратить ресурсы на запись буферов в момент выполнения запросов. В итоге, если требуется принести новые данные в буфер, это происходит быстрее.
Основная цель мониторинга в этой области – добиться такой настройки системы, при которой:
-
бэкенды не выполняют «грязную работу» по записи буферов на диск,
-
фоновые процессы справляются с задачами без избыточной нагрузки на диск.
Для этого мы используем данные из представлений pg_stat_bgwriter и pg_stat_database. Они позволяют оценить количество сброшенных буферов в разрезе разных процессов, а также собрать статистику по контрольным точкам и фоновой записи.
SELECT now() AS timestamp,
checkpoints_timed,
checkpoints_req,
checkpoint_write_time,
checkpoint_sync_time,
buffers_checkpoint,
buffers_clean,
buffers_backend,
maxwritten_clean,
buffers_backend_fsync,
buffers_alloc
FROM pg_stat_bgwriter
Здесь мы можем наблюдать за такими интересными неравенствами, как:
-
Соотношение чекпоинтов. Оптимальной считается ситуация, когда количество контрольных точек, выполненных по расписанию (checkpoints_timed), значительно превышает количество контрольных точек «по требованию» (checkpoints_req). Если наблюдается обратное, можно:
-
увеличить параметр max_wal_size, чтобы снизить нагрузку на диск,
-
или, если критична скорость восстановления после сбоя, скорректировать checkpoint_timeout.
-
Запись буферов. Хорошо, когда буферы в основном записываются при выполнении контрольных точек и процессом фоновой записи (bgwriter), а не пользовательскими процессами (buffers_checkpoint + buffers_clean >> buffers_backend).Если же пользовательские процессы берут на себя значительную часть этой работы, скорее всего, системе не хватает shared_buffers.
Отдельное внимание стоит уделять показателю maxwritten_clean. Если его значение постоянно высокое, есть смысл подкорректировать настройки bgwriter – например, увеличить параметры bgwriter_lru_maxpages или bgwriter_lru_multiplier. В PG 17 представление pg_stat_bgwriter было изменено и запрос из примера не работает.

На этом примере видно, что количество чекпоинтов по расписанию оказалось значительно меньше, чем чекпоинтов «по требованию». Ситуация не критическая, но требует внимания – возможно, параметры системы сконфигурированы не совсем корректно.

На этом графике показан случай, когда в определенный момент объем буферов, записанных пользовательскими процессами, оказался значительно больше объема буферов, сброшенных чекпоинтом и процессом фоновой записи. Такие ситуации тоже требуют анализа: важно понять, что именно происходило в базе данных, какие запросы выполнялись в этот период, и по возможности их оптимизировать.
Автоочистка (autovacuum): назначение и мониторинг

PostgreSQL – версионная СУБД: изменения данных создают новые версии строк в таблицах, что ведет к увеличению занимаемого места на диске, замедлению выборок. Автоочистка (autovacuum) – механизм, назначение которого: обновлять статистику, удалять «мертвые» версии строк и поддерживать таблицы в актуальном состоянии. Однако он создает дополнительную нагрузку на диск.
Важно помнить, что autovacuum не возвращает память обратно операционной системе. Неправильные настройки или слишком длинные транзакции могут привести к разбуханию таблиц (bloat) – ситуации, когда в таблицах много пустых страниц или страниц с минимальным количеством данных. Это негативно сказывается на производительности запросов и увеличивает размер базы данных.

С помощью представлений pg_stat_database, pg_stat_activity, pg_stat_progress_vacuum, pg_stat_user_tables, pg_stat_progress_analyze мы мониторим работу bloat и минимизируем влияние автоочистки на систему.
Для понимания того, насколько у нас агрессивен автовакуум, мы получаем данные из представления pg_stat_progress_vacuum и сравниваем с максимально разрешенным количеством процессов автоочистки. Если в любой момент времени процессов автовакуума меньше разрешенного количества, то у нас относительно хороший автовакуум. Если же постоянно работает максимальное количество процессов автовакуума, то, возможно, стоит сделать его более агрессивным.
Кроме того, фрагментацию и bloat отслеживают с помощью расширения pgstattuple и его функций, которые показывают долю полезной информации в таблицах и степень фрагментации индексов.
Ниже приведен краткий список основных параметров настройки автовакуума. Это лишь часть доступных в PostgreSQL инструментов для поддержания базы данных в хорошем состоянии:
-
autovacuum = on
-
log_autovacuum_min_duration
-
autovacuum_naptime = 20s
-
autovacuum_max_workers ="CPU"cores/4..2
-
autovacuum_vacuum_scale_factor = 0.01…0.05
-
autovacuum_analyze_scale_factor = 0.005…0.02
-
autovacuum_vacuum_insert_scale_factor = 0.01
-
autovacuum_vacuum_cost_limit
-
autovacuum_vacuum_cost_delay = 2ms
-
autovacuum_work_mem = 1GB
И три утилиты, с помощью которых можно бороться с bloat:
-
pg_repack
-
pgcompacttable
-
vacuum full
Чуть ниже расскажу о них чуть подробнее.

На данной метрике можно увидеть работу автовакуума. Здесь количество процессов автовакуума в крайних пиках достигает трех, что равно по дефолту количеству максимального автовакуума (на базе не было каких-то отдельных настроек). По этому графику мы можем сделать краткий вывод, что на данном отрезке времени автовакуум со своей работой в принципе справляется.
Про bloat и борьбу с ним
В PostgreSQL есть три основных инструмента: vacuum full, pg_repack и pgcompacttable.
Vacuum full идет «в коробке» и умеет все: полностью очищает таблицу и возвращает место обратно ОС. Главный минус – полная блокировка таблицы во время работы. Для высоконагруженных систем без технологических окон это недопустимо.
Поэтому используются более «щадящие» решения: pg_repack и pgcompacttable. Они блокируют таблицу только в начале и в конце операции, но имеют свои ограничения. Например, для работы pg_repack требуется, чтобы таблица имела непустой уникальный индекс. Еще при прерывании работы иногда необходимо убирать «следы» его работы.
Отличие pgcompacttable от других инструментов в том, что он не требует длительных блокировок, создает меньшую нагрузку на систему и позволяет регулировать интенсивность работы. При этом его скорость ниже, и хотя он создает значительную нагрузку на диск, эту нагрузку можно корректировать с помощью параметров.
Репликация: мониторинг и управление отставанием
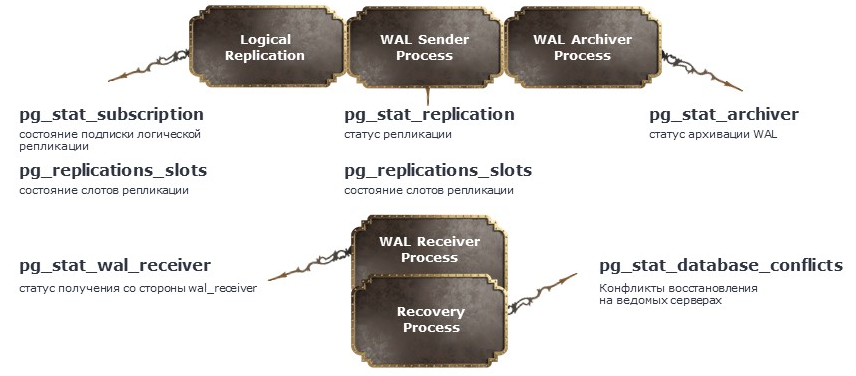
Еще один важный процесс в Postgres – репликация. Ее можно не использовать, но если она задействована, и если она еще и синхронная (synchronous_commit <> off, synchronous_standby_names <> ''), то ее необходимо мониторить. В первую очередь отслеживается отставание реплики, фиксируются ошибки, а также разрешаются возможные конфликты.
Репликация применяется, когда нужен резервный кластер или, например, когда хочется вынести на него формирование тяжелых отчетов. Поэтому мониторинг реплик критически важен. Для этого в Postgres предусмотрено множество представлений, среди которых ключевыми являются pg_stat_replication и pg_replication_slots.
В задачах восстановления данных полезно использовать представление pg_stat_database_conflicts, которое позволяет получать информацию об ошибках на ведомом сервере. Ниже приведен пример запроса, с помощью которого можно отследить отставание реплики от ведущего сервера.
SELECT now() AS timestamp,
EXTRACT('epoch'
FROM write_lag) AS write_lag,
EXTRACT('epoch'
FROM flush_lag) AS flush_lag,
EXTRACT('epoch'
FROM replay_lag) AS replay_lag,
sync_priority,
sync_state,
state,
backend_xmin,
backend_start,
sent_lsn,
write_lsn,
flush_lsn,
replay_lsn
FROM pg_stat_replication
write_lag - задержка, возникающая при фиксации транзакции, когда synchronous_commit = remote_write (ведомый сервер записал данные WAL).
flush_lag - задержка, возникающая при фиксации транзакции, когда synchronous_commit = on (ведомый сервер записал и сбросил записи WAL на диск).
replay_lag - задержка, возникающая при фиксации транзакции, когда synchronous_commit = remote_apply (ведомый сервер записал, сбросил на диск и применил записи WAL).
Эти задержки особенно важны в случае синхронной репликации, так как влияют на общее время выполнения транзации и, как следствие, на производительность СУБД. Если отставание большое, есть риск, что при сбое на основном сервере часть данных не будет доставлена на ведомый.Причины задержек обычно связаны с высокой нагрузкой на реплику, недостаточной производительностью оборудования или проблемами в сети.

На графике показан пример метрики лагов: в конце заметен рост значения replication flush_lag. Это сигнализирует о проблемах на ведомом сервере – перегрузке или сбоях в работе. В любом случае такие ситуации требуют внимания.
Ожидания и блокировки: диагностика производительности
SELECT now() AS timestamp,
db.datname,
COUNT(*) FILTER (
WHERE wait_event_type = 'Lock') AS wait_lock,
COUNT(*) FILTER (
WHERE wait_event_type = 'LWLock') AS wait_lwlock,
COUNT(*) FILTER (
WHERE wait_event_type = 'BufferPin') AS wait_bufferpin,
COUNT(*) FILTER (
WHERE wait_event_type = 'Activity') AS wait_activity,
COUNT(*) FILTER (
WHERE wait_event_type = 'Extension') AS wait_extension,
COUNT(*) FILTER (
WHERE wait_event_type = 'IPC') AS wait_ipc,
COUNT(*) FILTER (
WHERE wait_event_type = 'IO') AS wait_io,
COUNT(*) FILTER (
WHERE wait_event_type = 'Timeout') AS wait_timeout
FROM pg_database db
LEFT JOIN pg_stat_activity pg_stat ON pg_stat.datname = db.datname
AND state='active'
AND wait_event_type IS NOT NULL
WHERE db.datname NOT IN ('postgres',
'template0',
'template1')
GROUP BY db.datname
Поскольку Postgres изначально рассчитан на многопользовательский режим, он активно использует систему блокировок, которые приводят к ожиданиям. Мониторинг ожиданий важен, чтобы понимать, чем заняты процессы в данный момент: выполняют ли они полезную работу или находятся в состоянии простоя.
Кроме того, типы ожиданий могут указывать на проблемы в аналитических механизмах. Для их анализа можно обращаться к представлению pg_stat_activity, с помощью которого можно получить количество ожиданий на текущий момент.
Для базового мониторинга этого достаточно, но при расследовании проблем удобнее использовать расширение pg_wait_sampling. Оно позволяет накапливать статистику и собирать данные с большей частотой, чем pg_stat_activity. Тем не менее даже в pg_stat_activity можно заметить резкий рост числа сессий в режиме ожидания, что бывает признаком глобальных проблем.
SELECT a.backend_type,
a.application_name AS app,
p.event_type,
p.event,
p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
ORDER BY p.count DESC;
Состояние БД
Помимо внутренних механизмов, стоит отслеживать и состояние самой базы – анализировать размер базы данных, таблиц и индексов:
-
pg_database_size()
-
pg_table_size()
-
pg_index_size()
SELECT
schemaname||'.'||tablename AS table_name,
pg_class.reltuples as rows,
pg_total_relation_size(schemaname||'.'||tablename) / 1024 AS reservedKB,
pg_table_size(schemaname||'.'||tablename) / 1024 AS dataKB,
pg_indexes_size(schemaname||'.'||tablename) / 1024 as index_sizeKB,
pg_total_relation_size(schemaname||'.'||tablename)
- pg_table_size(schemaname||'.'||tablename)
- pg_indexes_size(schemaname||'.'||tablename) as unusedKB
FROM pg_catalog.pg_tables, pg_catalog.pg_class
where pg_tables.tablename = pg_class.relname
and schemaname = 'public'
ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC
LIMIT 50
Эти показатели также выводятся в метрики, чтобы понимать, насколько быстро растет база и достаточно ли места на сервере, а также вовремя заметить возможные проблемы с нехваткой дискового пространства.
Про pgstattuple я уже упоминал ранее. С его помощью, в частности, можно мониторить фрагментацию и «распухание» таблиц.

На примере видно нагрузку на базу данных: фиксируются все изменения – количество удаленных, вставленных и измененных записей. На графике заметен всплеск вставок: в тот момент проводилось нагрузочное тестирование (НТ), при котором создавалось большое количество документов. Даже такие естественные пики стоит анализировать, чтобы понять, не скрывается ли за ними аномалия.
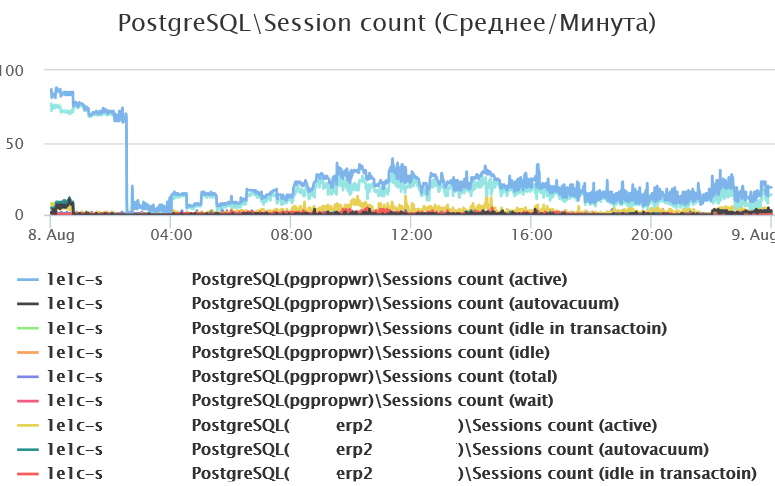
Помимо самих данных, важно отслеживать соединения, которые напрямую влияют на нагрузку на СУБД. Здесь обращаем внимание на:
-
общее количество соединений – резкий рост может указывать на проблемы в СУБД (хотя не всегда);
-
количество активных соединений – их всплески сигнализируют о потенциальных перегрузках;
-
сеансы в состоянии idle in transaction – они мешают автоочистке и могут удерживать блокировки;
-
активные соединения в ожидании – полезно отслеживать, чтобы выявлять узкие места.
Начиная с версии 14 в Postgres появились два конфигурационных параметра, позволяющие автоматически отключать сеансы по тайм-ауту: как в состоянии idle in transaction, так и в обычном idle. Это помогает предотвращать «зависание» соединений и снижает нагрузку на систему.
Анализ запросов: pg_stat_statements и оптимизация
SELECT substring(query, 1, 50) AS short_query,
round(total_exec_time::numeric, 2) AS total_time,
calls,
round(mean_exec_time::numeric, 2) AS mean,
round((100 * total_exec_time / sum(total_exec_time::numeric) OVER ())::numeric, 2) AS percentage_cpu
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 20
(с 13-й версии PostgreSQL, ранее названия колонок были другими)
Значительную нагрузку на СУБД создают именно пользовательские процессы – то есть выполняемые ими запросы. Чтобы получать информацию о таких запросах и оценивать их влияние на систему, используется расширение pg_stat_statements. С его помощью можно:
-
отслеживать статистику выполнения запросов,
-
выявлять запросы с высоким или низким потреблением CPU,
-
анализировать нагрузку на ввод-вывод,
-
смотреть, какие запросы выполнялись особенно часто за выбранный период,
-
собирать другую полезную статистику.
На основании этих данных определяются запросы, которые в первую очередь стоит оптимизировать.
Пример изменения конфигурационного файла postgresql.conf для использования расширения pg_stat_statements:
-
postgresql.conf shared_preload_libraries = 'pg_stat_statements'
-
pg_stat_statements.max = 10000
-
pg_stat_statements.track = all
-
track_io_timing = 'on'
-
compute_query_id = 'on' # или 'auto'
Индексы: анализ использования и рекомендации
Postgres позволяет собирать статистику по чтению таблиц и индексов отдельно через системные представления с префиксом pg_stat_ – например, pg_stat_all_tables, pg_stat_all_indexes, pg_stat_user_tables и другие. С их помощью можно определить:
-
Отсутствующие индексы – когда количество последовательных чтений по таблице значительно превышает количество обращений к индексам. Такие таблицы – главные кандидаты на индексацию.
SELECT relname,
seq_scan - coalesce(idx_scan, 0) AS too_much_seq,
CASE
WHEN seq_scan - coalesce(idx_scan, 0) > 0 THEN 'Нет индекса?'
ELSE 'OK'
END AS Message,
pg_relation_size(relname::regclass) AS rel_size,
seq_scan,
coalesce(idx_scan, 0) AS idx_scan
FROM pg_stat_all_tables
WHERE schemaname='public'
AND pg_relation_size(relname::regclass)>10000 -- ограничение на размер анализируемых таблиц
ORDER BY too_much_seq DESC;
-
Неиспользуемые индексы – когда индекс существует, но по статистике к нему нет обращений.
SELECT relname,
indexrelname
FROM pg_stat_all_indexes
WHERE idx_scan = 0
AND schemaname = 'public'
Почему важно следить и за отсутствующими, и за неиспользуемыми индексами?
-
Если индекс отсутствует, выполняется последовательное сканирование таблицы. Это приводит к избыточным чтениям и замедляет выполнение запросов, особенно при больших объемах данных.
-
Если индекс есть, но не используется, он зря занимает дисковое пространство и память, а также увеличивает время вставки и обновления строк, так как данные нужно поддерживать в актуальном состоянии. В таких случаях индекс лучше удалить.
Блокировки: диагностика и разрешение конфликтов
Как и любая другая СУБД, Postgres использует механизм блокировок. Иногда они необходимы, но в ряде случаев могут мешать, особенно если оказываются избыточными.
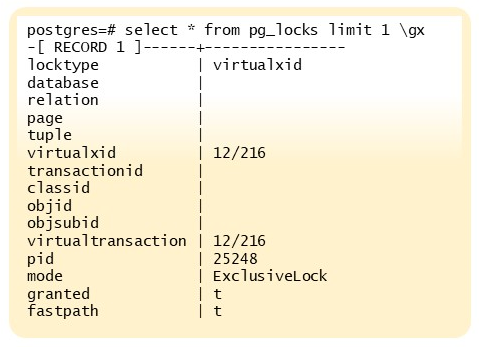
Для анализа наложенных блокировок существует представление pg_locks. С его помощью можно получить информацию о том, какие блокировки установлены, какими процессами они удерживаются и какие ресурсы затронуты.
Дополнительно полезен инструмент дерево блокировок: он позволяет в случае конфликтов определить инициатора блокировки, пострадавшие процессы, а также запросы, которые они выполняли.
Еще один важный показатель – количество взаимоблокировок в СУБД. Эту статистику можно получить из представления pg_stat_database.
Инструменты мониторинга: решения вендоров
Мы уже обсудили, что именно стоит мониторить, теперь поговорим о том, с помощью каких инструментов это можно делать. Существуют готовые решения от вендоров:
-
Postgres Pro Enterprise Manager,
-
Платформа Tantor,
-
Platform V Kintsugi.
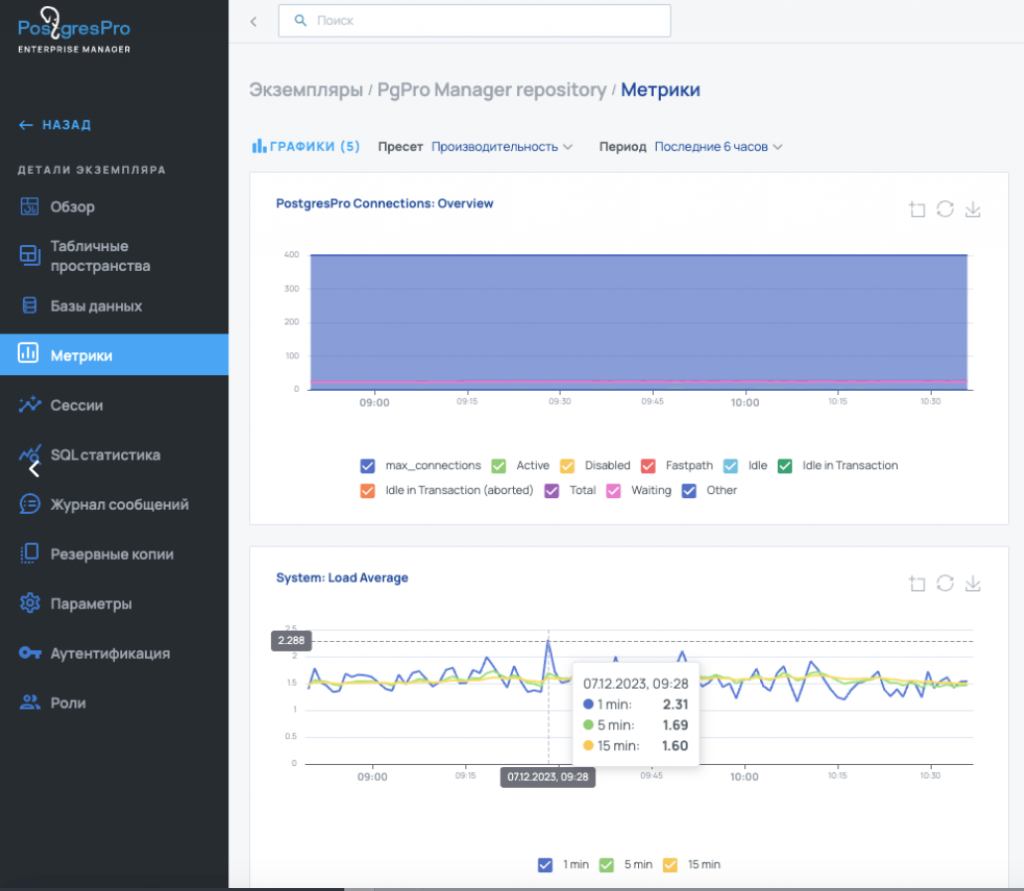
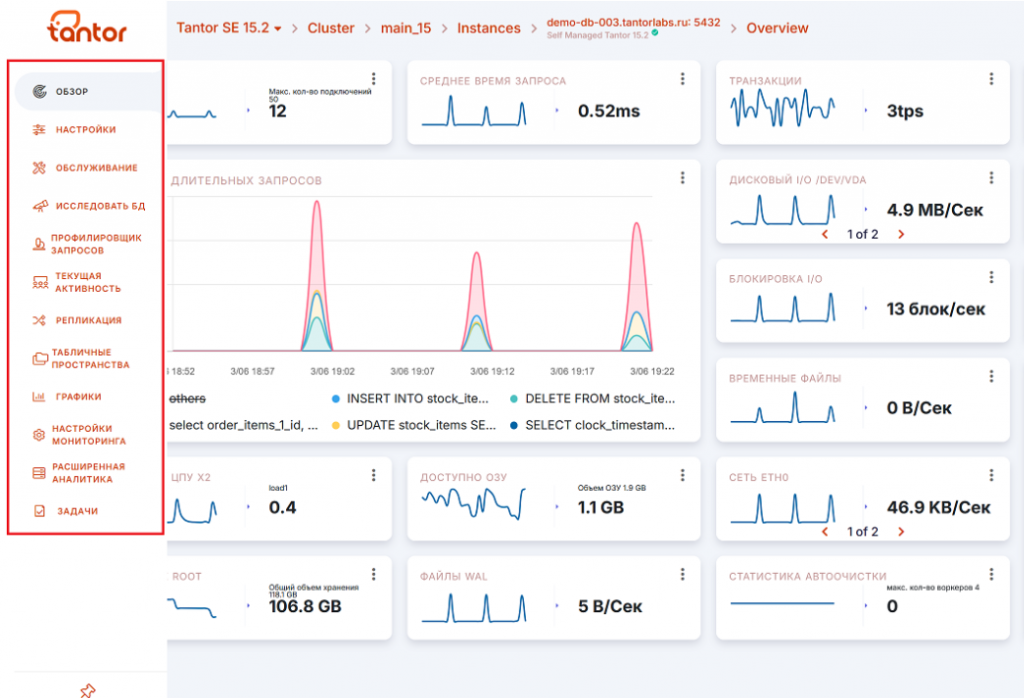

Все эти системы похожи по функциональности. Они умеют собирать метрики работы СУБД, метрики работы приложений, метрики загрузки оборудования, статистику запросов, управление серверами, настройку и мониторинг регламентных операций, возможность просмотра логов, выполнять автотюнинг, предоставлять отчеты о работе.
Pазличия несущественные. Например, у Tantor пока нет консоли запросов (но ее планируют добавить), а у Postgres Pro отсутствует механизм алертинга. В остальном они решают примерно одни и те же задачи. Если у вас есть возможность использовать такие инструменты, настоятельно рекомендую это делать.
Альтернативные инструменты: pg_profile и скрипты
Что делать, если нет возможности использовать полноценную систему мониторинга? В этом случае пригодится расширение pg_profile или его более новая версия – pg_pwr. Эти инструменты позволяют собрать практически всю информацию, о которой мы говорили ранее.
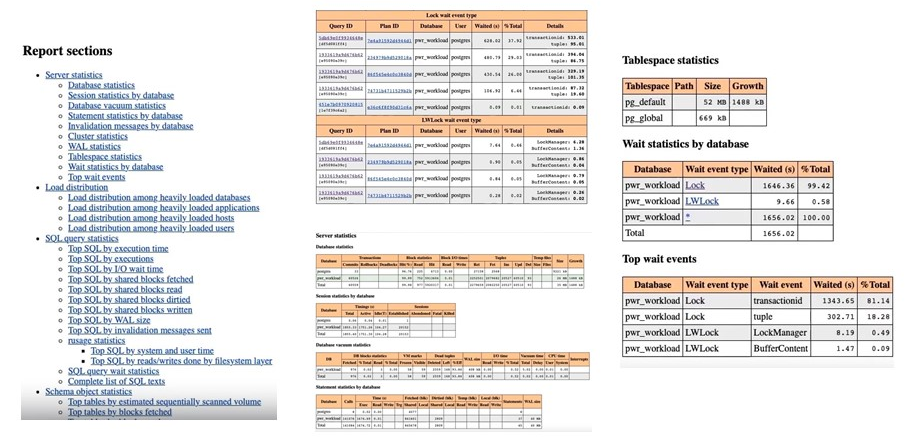
На примере отчета видно, что можно получить данные за определенный период работы СУБД: нагрузку, активность запросов, статистику по объектам и многое другое.
Если использование pg_profile по каким-то причинам недоступно (например, действуют ограничения информационной безопасности или требуется быстрое решение «здесь и сейчас»), метрики можно получить с помощью собственных скриптов. Их легко оформить в сценарии и выводить в удобном для вас формате, а затем визуализировать.
Отдельно стоит упомянуть умный мониторинг. Решение также позволяет отслеживать работу СУБД, собирать метрики оборудования и при необходимости кастомизировать их: добавлять произвольные запросы и строить по ним графики, работать с ТЖ, ЖР и так далее.
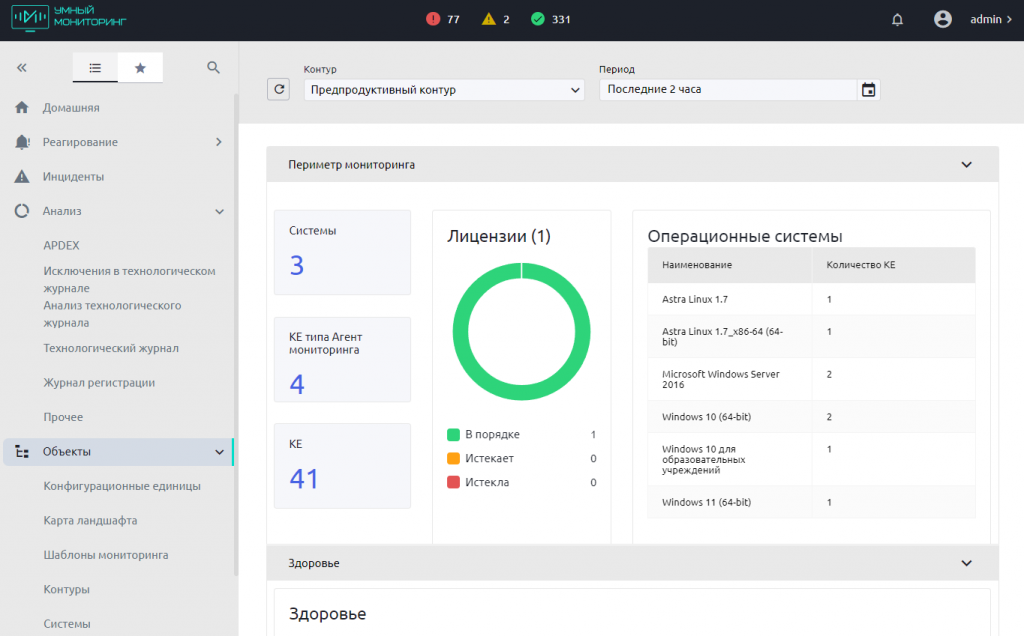
Надеюсь, информация из этой статьи пригодится вам в решении возникающих задач при работе с СУБД Postgres. А каждая новая версия отечественных вариантов этой системы будет облегчать вашу жизнь и упрощать задачи администрирования.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт