Хочу начать с простой мысли: все ошибаются. Если мы занимаемся разработкой программного обеспечения и создаем что-то чуть сложнее, чем Hello, world!, ошибки неизбежны. Вопрос лишь в том, какие это ошибки.
Отношение к ошибкам часто бывает неправильным: за них могут ругать, наказывать, искать виноватых. Но на самом деле с ошибками нужно работать и разбираться в них. Даже такие гиганты, как Microsoft или Google, регулярно выпускают обновления и исправления – просто потому, что ошибок не избежать.
Начнем мы со всем знакомой картинки.
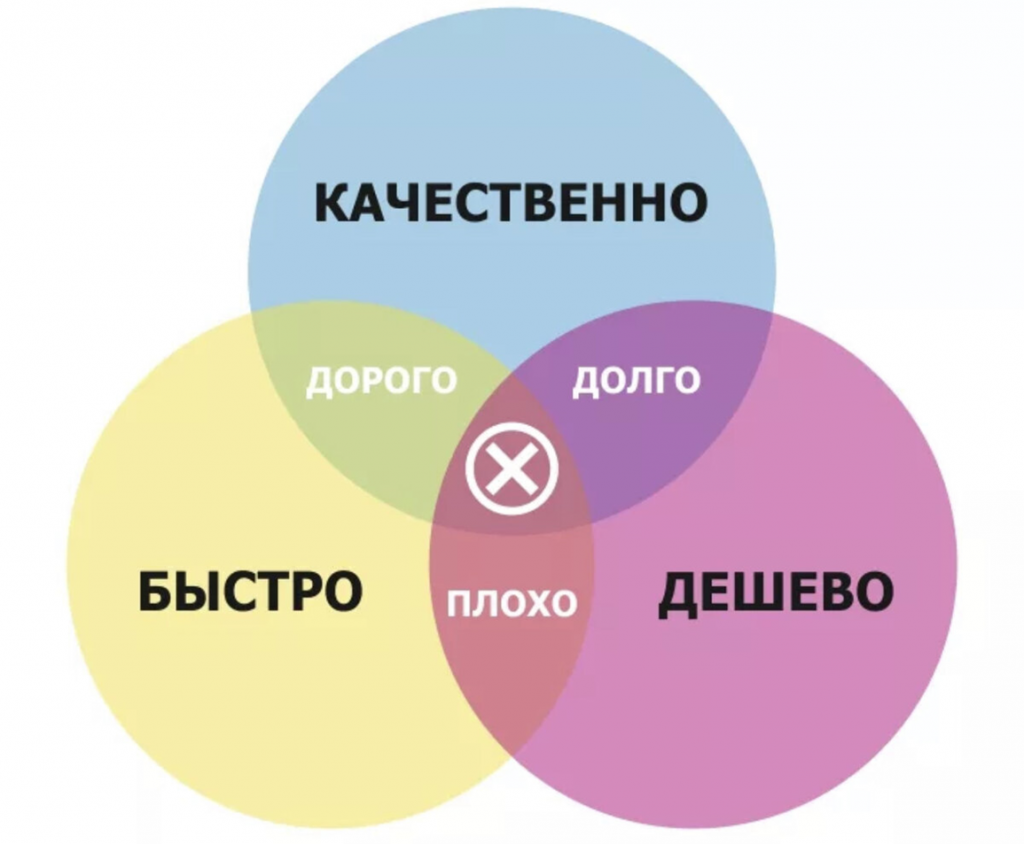
Здесь мы видим, что качественный продукт не может быть одновременно быстрым и дешевым, как того хочет заказчик. Быстрый и дешевый продукт при экономии ресурсов в итоге отнимает их больше, чем хотелось бы. Ошибки, накопленные из-за такой экономии, приводят к еще большим затратам – как со стороны заказчика, так и со стороны нашей компании, так как мы тратим время, деньги, ресурсы специалистов и не можем перейти к следующему проекту. Возникает парадокс: когда пытаемся сделать быстро и дешево, тратим больше денег и времени.
Хаотичный подход и его недостатки
Разберемся, как можно сэкономить ресурсы. Экономия в первую очередь зависит от подхода, который используется при разработке продукта. Здесь представлена схема известного процесса:
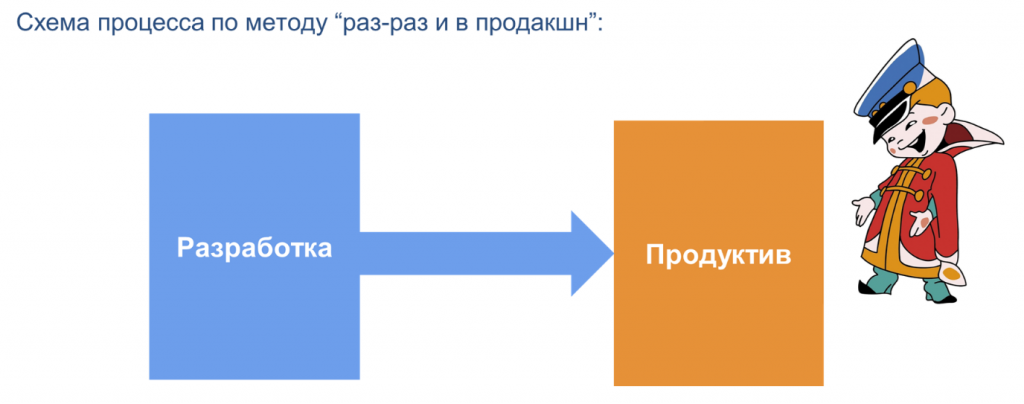
Такой процесс многим знаком: подстраиваясь под требования заказчика, мы стараемся как можно быстрее внести изменения и адаптироваться, но в итоге тратим больше сил и времени и получаем не тот результат, который ожидали.
Что в этом подходе должно настораживать? Ручное управление и хаотичность процессов, когда разработчики беспорядочно выкладывают изменения в продуктив, и спустя несколько итераций становится непонятно, что осталось от исходного продукта.
Упорядоченный подход: использование Git и код-ревью
Что отличается в нашем подходе? Он не инновационный, я просто рассказываю о практиках, которые мы применяем, и они действительно работают.
Во-первых, чтобы навести порядок в коде, мы используем Git-хранилище – конвертируем проект в Git. Это дает нам новые возможности:
-
проведение код-ревью,
-
оповещение тех. архитектора о коммитах,
-
удобный и быстрый просмотр изменений,
-
обратная связь от тех. архитектора разработчику.
Мы видим каждое изменение и можем контролировать процесс.
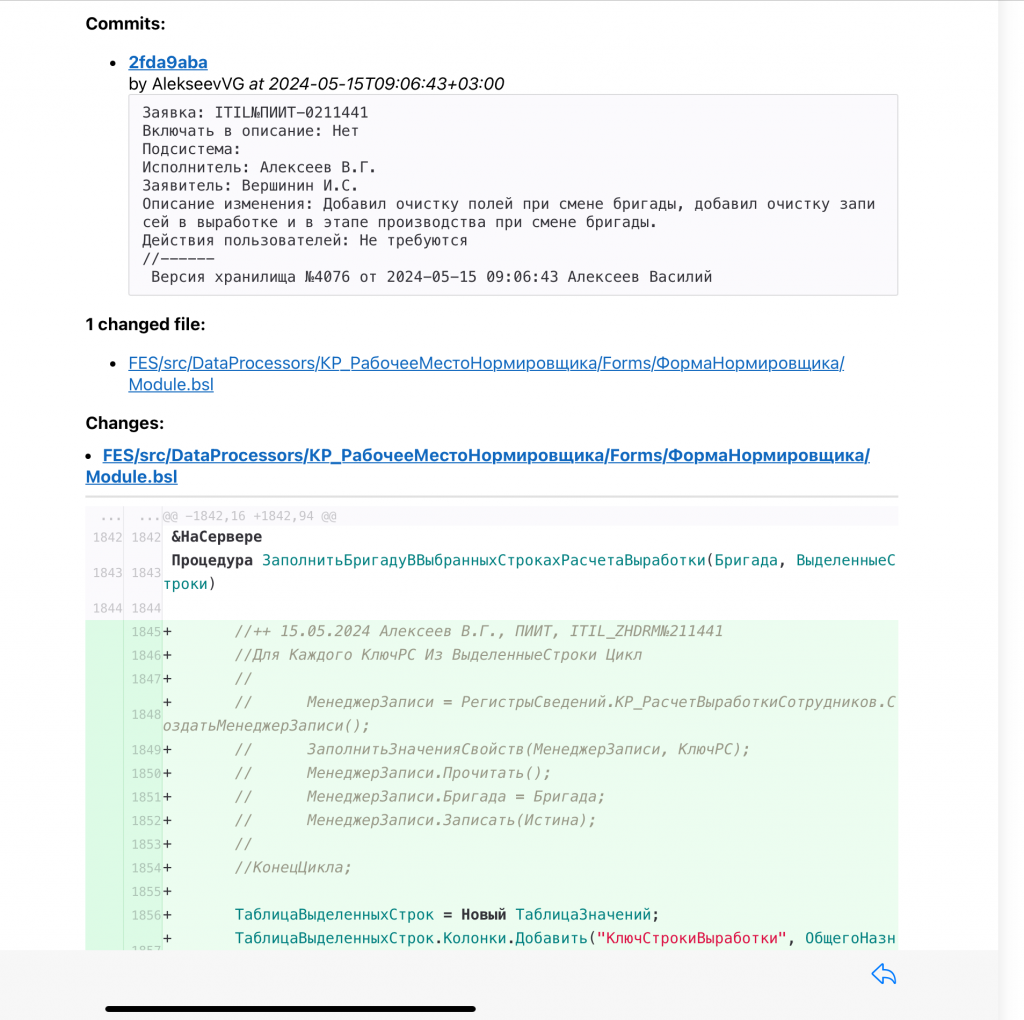
Вот так выглядит письмо об изменениях, которое получает технический архитектор.
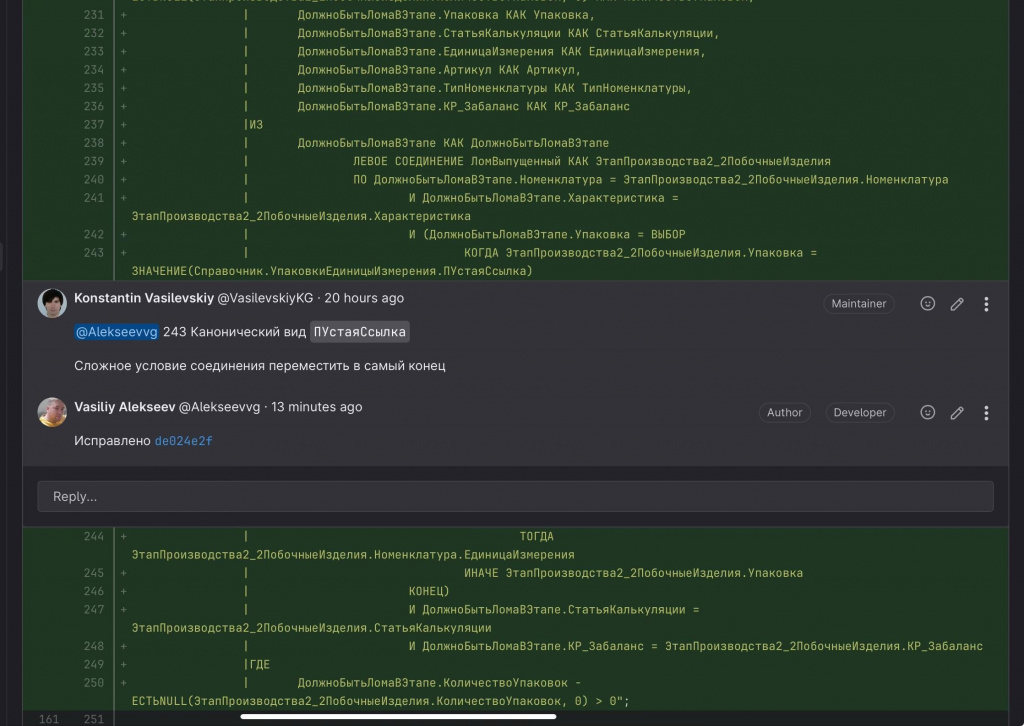
А так – обратная связь архитектора к разработчику: комментарии, видны участки измененного кода и обсуждение.
Статическое и динамическое тестирование
Чтобы управлять кодом, мы используем не только GitLab-хранилище, но и проводим синтаксические и статические тесты на SonarQube. Это полезно: мы видим, что коммит разработчика оформлен правильно и не содержит критичных ошибок. Но статические тесты не показывают, что код действительно работает – он может быть написан без ошибок, но при этом не выполнять нужную логику. Поэтому дальше требуется динамическое тестирование.
Для этого мы создали группу тестирования. Ребята с энтузиазмом начали использовать Vanessa Automation и сценарные тесты, но сразу столкнулись с первыми проблемами. Очень сложно выстроить эффективное взаимодействие между тестировщиком и аналитиком или консультантом. Тестировщик не знает предметную область, а консультант тратит много времени на объяснения и может неправильно понимать суть теста. В итоге тестировщик не до конца понимает бизнес-логику, а консультант – техническую часть. Из-за этого тесты получаются хрупкими и дают нерелевантные результаты. Вместо анализа результатов тестирования команда занимается исправлением ошибок падения тестов.
Выводы, которые мы сделали:
-
начинать тестирование нужно с дымовых тестов,
-
тесты должны быть независимыми.
Типы тестов
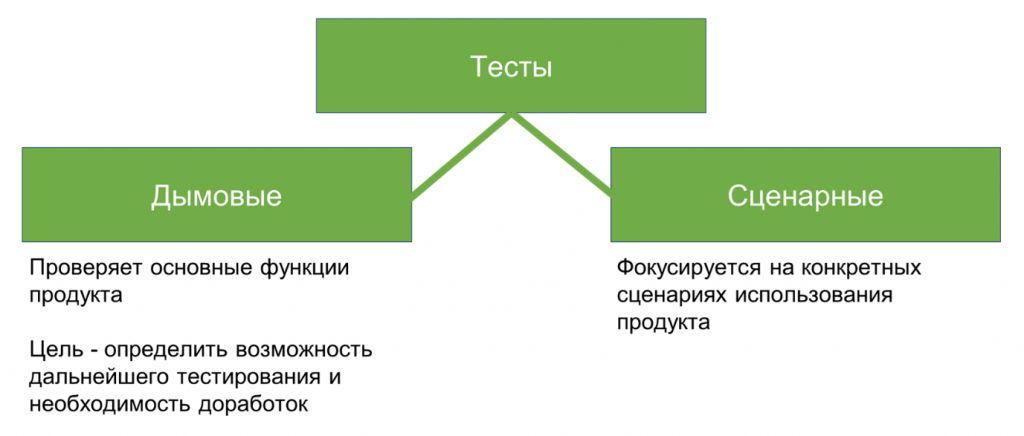
Дымовые тесты проверяют, что существующий функционал системы работает, хотя результат их выполнения мы заранее не знаем. По сути, они показывают, что система работоспособна и готова к дальнейшему, более детальному тестированию.
Сценарные тесты, наоборот, более точечные – они проверяют конкретные сценарии использования программы, в том числе наши специфичные доработки. Полностью покрыть ими всю систему невозможно.
Мы уже обсудили, почему начинать стоит с дымовых тестов. Теперь – от чего тесты должны быть независимыми:
-
от базы данных, на которой они происходят, чтобы можно было получить результаты на любой копии предпродакшена;
-
от пользовательских данных, потому что копия базы может сниматься с разного среза, и мы не должны к ним привязываться;
-
от настроек системы – значений констант, переменных, предопределенных данных, которые может изменить администратор. Тест должен уметь подготовить базу под себя;
-
от других тестов. При проверке цепочек документов, других сценариев или в дымовом тесте результаты одних тестов не должны влиять на результаты других.
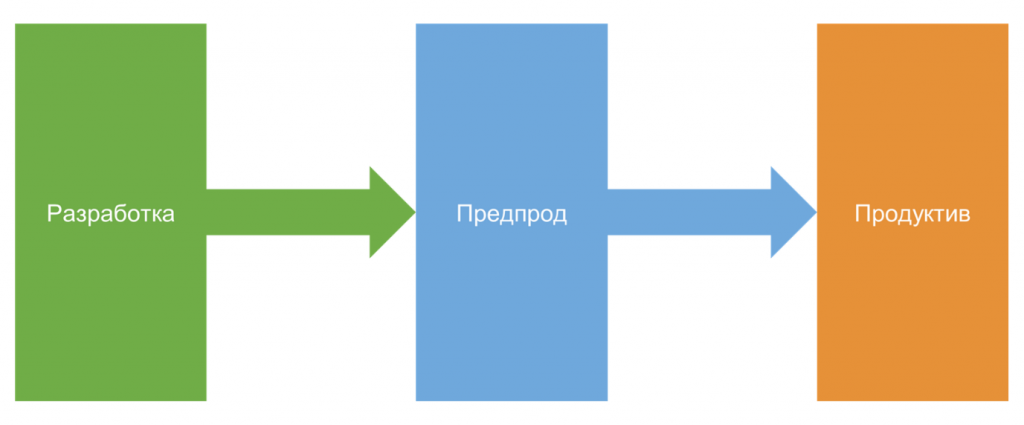
Что в нашем подходе отличается от того, что я показывал вначале, – это этап, который называется предпрод.
На этом этапе разработчик передает изменения, и мы получаем копию системы, которую можем тестировать. У нас есть копии, с которыми можно делать все необходимое. По сути, они идентичны рабочей базе, но пока не передаются заказчику.
Автоматизация рутины и дашборд релизов
Все, что мы делаем, направлено на избавление от рутинных задач.
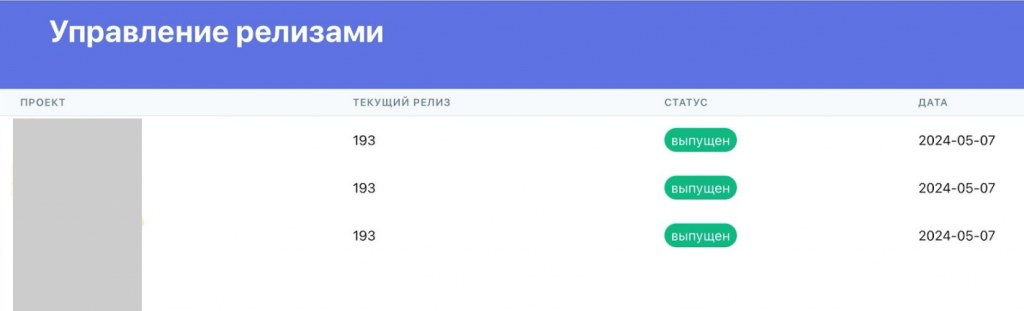
Для начала мы автоматизировали процесс создания релиза и разработали дашборд, где отображаются проекты, номер текущего релиза (наша внутренняя версия), статус и дата выпуска.
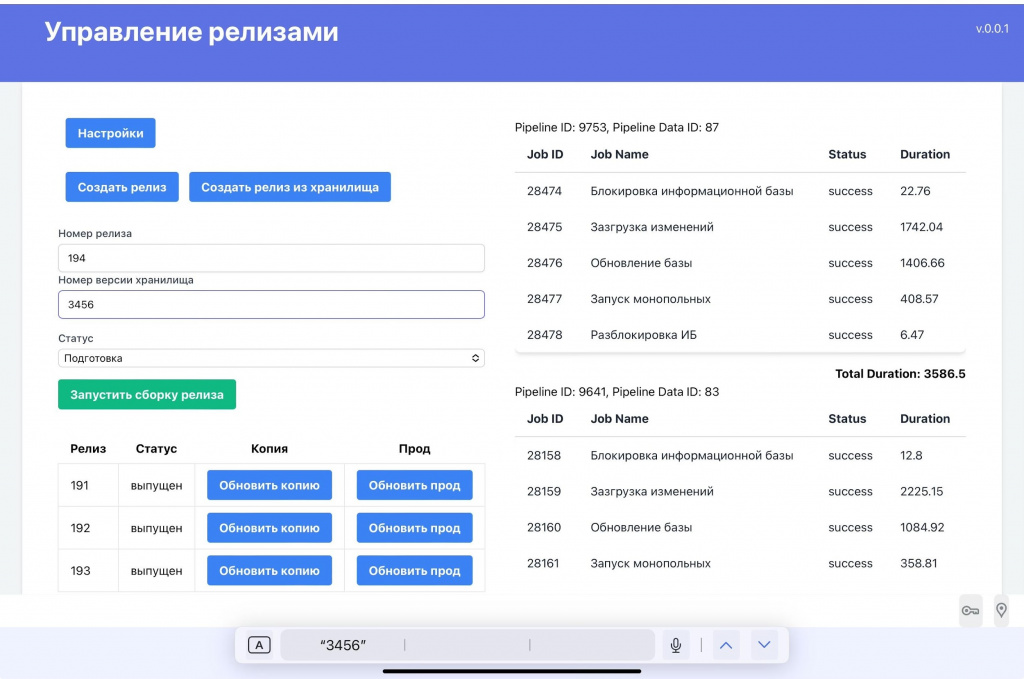
Если открыть проект, можно увидеть его настройки, все данные, обновить копию до нужного релиза и просмотреть статистику по времени обновления базы.
Таким образом мы получили инструмент, который позволяет любому заинтересованному сотруднику получить нужную копию системы без сложных взаимодействий с администраторами и разработчиками.
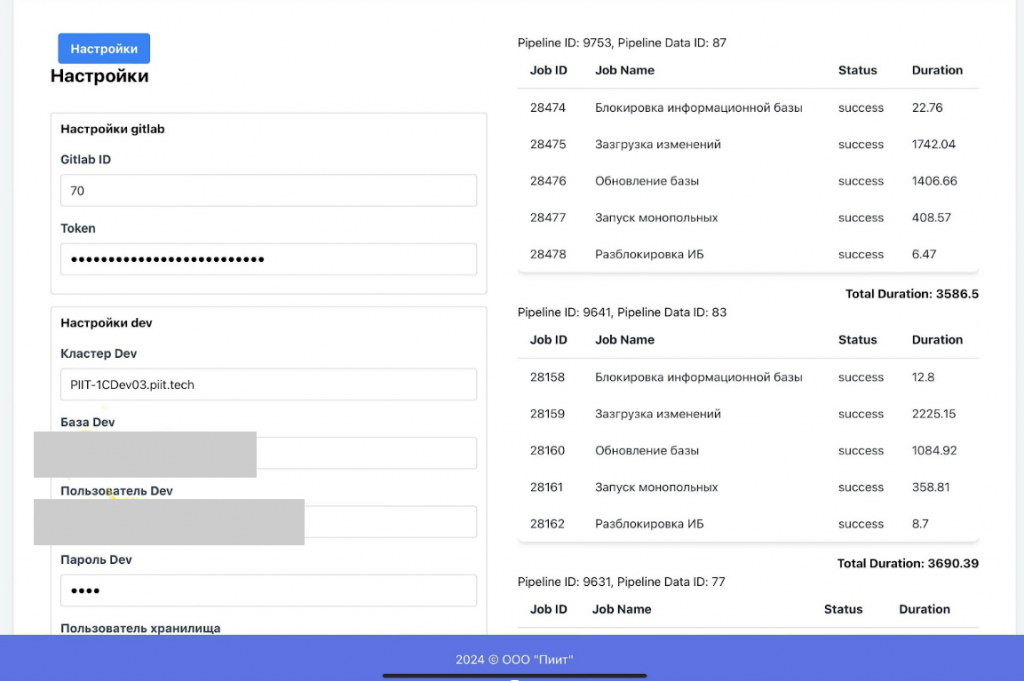
Второй шаг – возможность прямо через дашборд накатывать релиз и запускать тестирование.
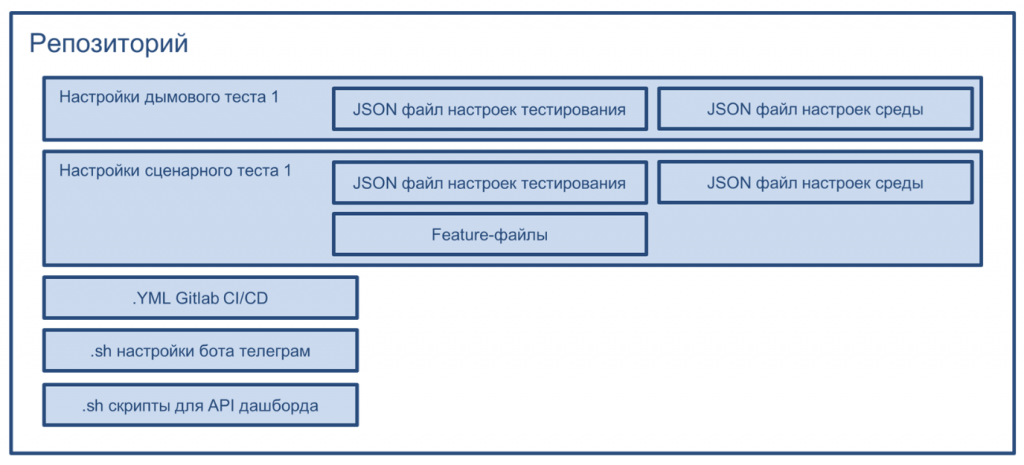
Тестирование мы начинаем без захода в обработки или саму 1С, потому что создали шаблон тестового прогона и разместили его в репозитории на GitLab.
В репозитории содержатся:
-
настройки дымовых тестов – параметры тестирования и настройки среды (в какой базе, под каким пользователем и т.д. выполняются тесты);
-
настройки сценарных тестов – где они применяются, а также feature-файлы, содержащие сами сценарии тестирования;
-
YML-файл GitLab, который позволяет использовать механизмы автоматизации GitLab (о них я расскажу ниже);
-
различные скрипты для взаимодействия с другими системами и выполнения дополнительных действий: например, бот в Telegram и API нашего второго дашборда, о котором тоже расскажу ниже.
Инструменты тестирования: Vanessa ADD и Vanessa Automation
Дымовое тестирование мы выполняем с помощью Vanessa ADD. Этот инструмент позволяет быстро получать результаты и проверять большие конфигурации.
Сценарные тесты создаются в Vanessa Automation. Здесь стоит отметить, что сценарные тесты – это сложная работа, и мы стараемся максимально атомизировать сценарии.
Например, если проверяем цепочку документов, связанных с ТМЦ, то передача материалов на склад зависит от множества других документов: заказов поставщику, ПТС, ПТУ и т.д., а также от большого числа элементов НСИ – складов, номенклатуры, цен и других справочников.
Чтобы дойти до теста документа перемещения, у нас предусмотрен отдельный сценарий подготовки базы: настройки, константы, загрузка необходимых справочников – номенклатуры, складов и т.п., которые требуются именно для данного сценария.
Кроме того, независимо от проверяемого документа, мы заранее загружаем корректные документы – ПТС, КПТУ, заказы поставщику – со всеми их движениями и ссылками. Например, в регистрах, где хранятся связи между документами, мы тоже подставляем нужные данные. Таким образом, система всегда получает все необходимые данные для теста, даже если их не было в базе изначально. Это позволяет избежать падений тестов.
CI/CD на GitLab и виртуальные машины
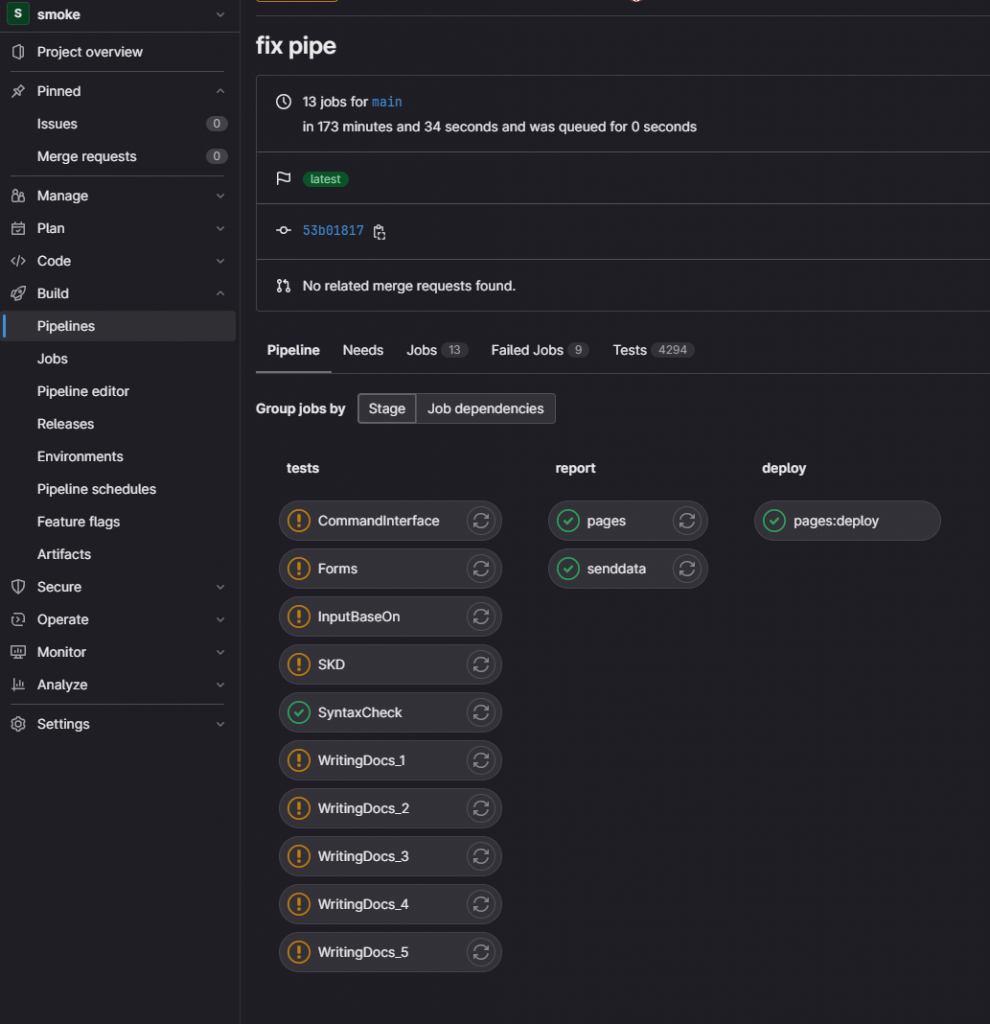
Для автоматизации с помощью GitLab мы используем пайплайн CI/CD – инструментарий, который позволяет запускать разные типы тестов отдельно друг от друга, в зависимости от их назначения. Например, отдельно запускаются дымовые тесты проверки форм, отдельно – репорт-задачи, собирающие отчеты и передающие данные в Telegram и другие системы.
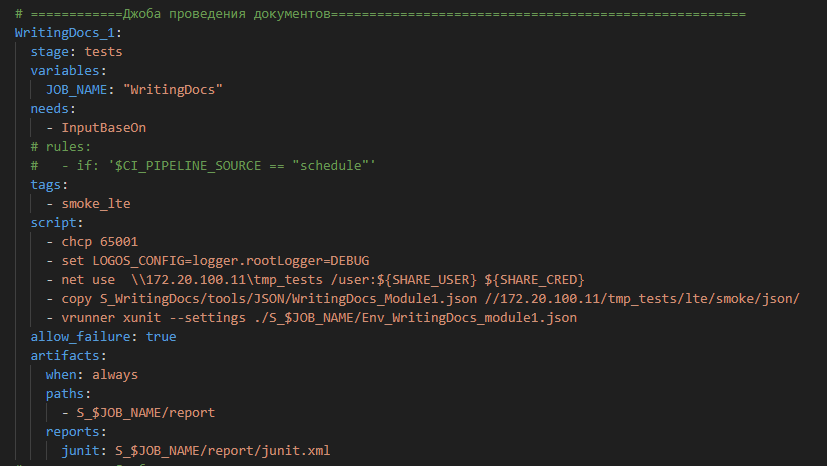
Вот так выглядит скрипт для запуска дымового теста. В данном случае – это проведение документов. Мы используем стандартный язык GitLab, но на этом участке видим скрипты из командной строки. Эти скрипты говорят нам о том, что на текущий момент мы используем виртуальные машины на Windows. Для каждого проекта выделена своя виртуальная машина, на которой запускаются 1С, тест-менеджер, тест-клиент и выполняются тесты. После завершения теста виртуальная машина закрывается и ожидает следующего шага – следующего теста.
Отчетность и дашборд Allure
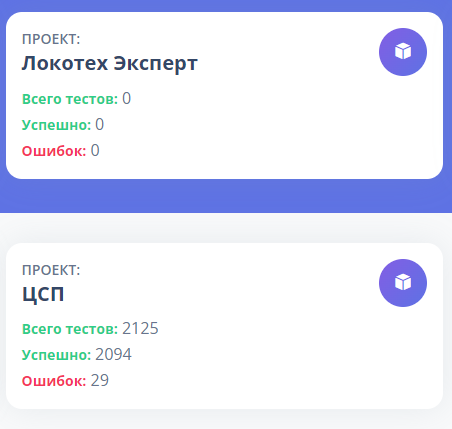
В конце, на шаге report, формируется отчет, который передает данные на другой наш дашборд.
На дашборде отображаются карточки проектов. Например, у нового проекта статистика пока по нулям, а у уже действующего видно, сколько тестов прошло, сколько из них успешных и сколько завершились ошибками. Это позволяет быстро выявить проблемные базы и начать работу с ними в первую очередь.
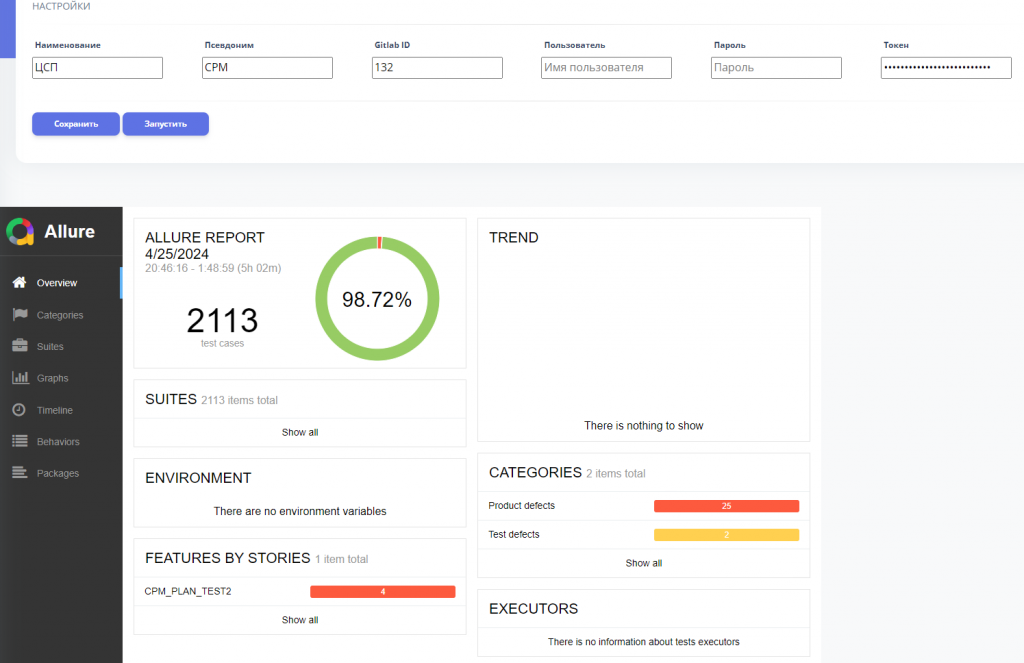
Если открыть карточку проекта, можно увидеть настройки доступа к пайплайну и отчет Allure, который показывает общую успешность прохождения тестов – например, 98%.
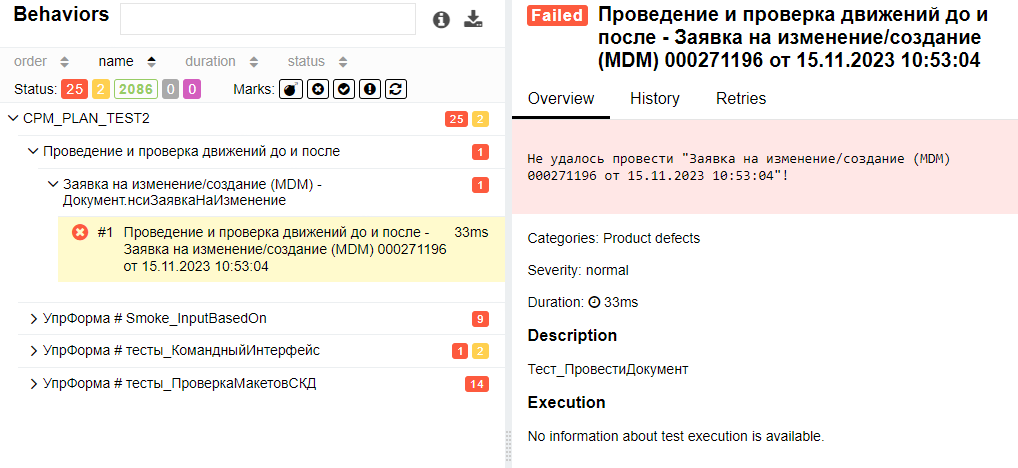
Если нужно понять, что в системе пошло не так, для каждой ошибки доступен подробный отчет. В нем, например, может быть указано, что при проверке движений документ не удалось провести. Нажав на розовую карточку, можно раскрыть полный текст ошибки и понять, в чем проблема.
Эти данные передаются разработчикам, либо они сами отслеживают отчеты и фиксируют найденные ошибки как заявки на изменения.
Архитектура системы и ее масштабируемость
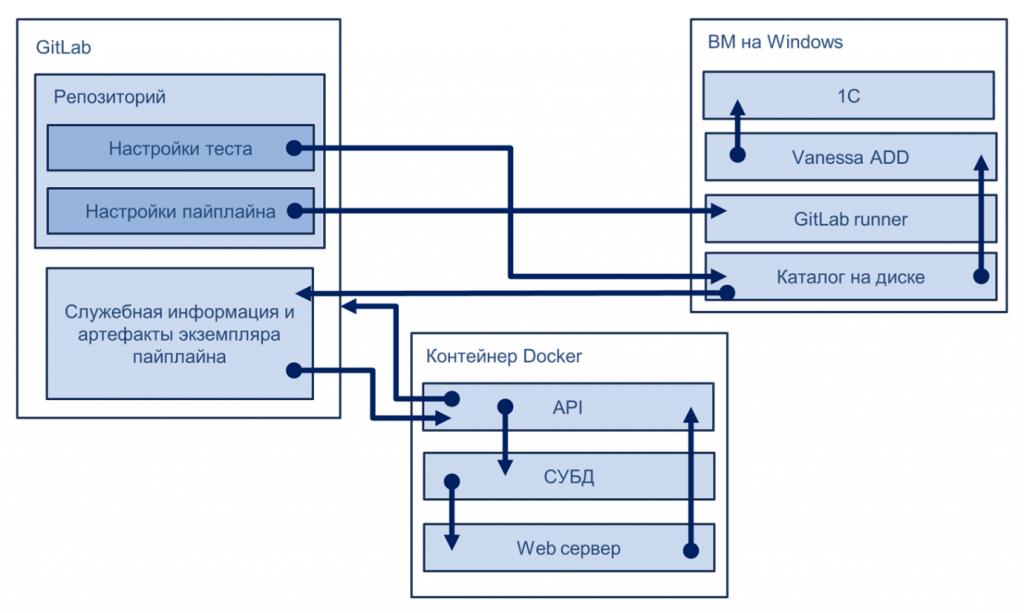
Наш продукт работает примерно так. У нас есть репозиторий на GitLab, виртуальные машины на Windows и контейнеры Docker.
Взаимодействие этих компонентов позволяет нам использовать удобный и масштабируемый инструмент, который можно быстро тиражировать на свои проекты. Например, ранее мне передали около десяти новых баз. Чтобы настроить для них тесты и получить первые результаты, достаточно одного рабочего дня с перекурами. Уже к вечеру или к утру следующего дня можно получить первые отчеты после запуска пайплайнов.
В нашем дашборде любой аналитик, разработчик и другой сотрудник, не вникая в архитектуру и особенности работы тестов, может самостоятельно запускать их в удобное время и получать результаты тогда, когда ему нужно, без ожидания нашей помощи.
Таким образом, мы создали инструмент, который позволяет быстро разворачивать релизы на нужных копиях, запускать тестирование и получать результаты без лишних действий. Мы даже не заходим в саму систему 1С – все выполняется автоматически, и пользоваться этим инструментом могут любые наши коллеги, независимо от платформы.
Ключевые принципы успешного тестирования

В чем секрет этого продукта? На самом деле никаких секретов нет. Успех – вещь эфемерная, но если следовать нескольким простым принципам, можно создавать действительно успешные решения:
-
Внедрять как можно больше автоматизации и современных практик.
-
Заниматься тестированием, как бы банально это ни звучало.
-
Добиваться релевантных результатов своих тестов. Это особенно важно, потому что можно получить ошибки и передать их разработчикам со словами: «Все сломано, разбирайтесь». Но при этом проблема может быть не в коде, а, например, в неверной подготовке базы или в некорректно написанном тесте. Тест должен показывать именно ту ошибку, которую проверяет, а не ошибку в самом тесте.
-
Упрощать работу с результатами для коллег. Не все готовы разбираться в том, как устроены репозитории или пайплайны GitLab. Уконсультантов и аналитиков просто нет на это времени, им важно быстро получить результат,
-
Максимально разбивать тесты, чтобы они не зависели друг от друга – каждую функцию лучше проверять отдельно.
Типичные проблемы внедрения тестирования
Даже если кажется, что все делается правильно, проблемы все равно появятся. Например:
-
Тесты написаны, все подготовлено – но ими никто не пользуется.
-
Тестирование сложно встроить в уже отлаженный процесс непрерывной разработки и вклиниться в работу разработчиков. Это организационно непросто.
-
Тесты могут выполняться формально: кто-то их запускает, смотрит на результаты, но не использует эти данные в работе. Результаты тестов нужно применять и анализировать.
-
Кроме того, тестирование может давать нерелевантные результаты. Например, после запуска тестов получаем кучу ошибок, все начинают паниковать, а причина оказывается в том, что просто была заблокирована копия базы или возник другой технический сбой.
Основные выводы
-
Тестировать необходимо, потому что ошибки в системе будут всегда. Вопрос в том, как быстро вы на них реагируете и умеете ли ими управлять.
-
Ошибка почти всегда обходится дороже, чем кажется, и чем дольше она живет в системе, тем выше ее стоимость.
-
Правильно тестировать свой продукт сложно, но можно. Особенно на начальных этапах – войти в тестирование, как показывает практика, достаточно просто.
-
Современные практики и инструменты значительно упрощают сам процесс и его настройку.
-
Нужно добиваться релевантных результатов тестов – это самое важное.
-
Пользоваться тестами должно быть удобно коллегам. Тестирование должно быть не инструментом «само в себе», а частью рабочего процесса, понятной, доступной и полезной для всех участников.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Анализ & Управление в ИТ-проектах.

Вступайте в нашу телеграмм-группу Инфостарт