Друзья, проблема общеизвестна, и вы знаете что делать, но с нами это случилось внезапно и в продуктивной среде.
Простой запрос в регистр сведений с периодичностью "По позиции регистратора", параметры виртуальных таблиц заполнены, индекс используется, но время выполнения – 100 секунд.
"ВЫБРАТЬ
| РегистрСведений1.Измерение1 КАК Измерение1,
| РегистрСведений1.Измерение2 КАК Измерение2,
| РегистрСведений1.Измерение3 КАК Измерение3,
| РегистрСведений1.Измерение4 КАК Измерение4
|ПОМЕСТИТЬ Таблица1
|ИЗ
| РегистрСведений.РегистрСведений1.СрезПоследних(
| &ДатаОкончания,
| Измерение1 В (&Измерение1)
| И Измерение2 В (&Измерение2)) КАК РегистрСведений1
|ГДЕ
| РегистрСведений1.Ресурс1"
Здесь нужно обратить внимание, что запрос прочитал 37501246 страниц, из которых 99,997% приходится на один оператор. Давайте запрос выполним в тестовой базе с расшифровкой полей индекса и выбора. Далее уже будут планы только из тестовой базы, цифры будут отличаться, но проблема та же.
Insert on pg_temp.tt2 (cost=13660.85..27305.24 rows=49647 width=107) (actual time=453.678..1572.453 rows=72542 loops=1)
Output: 0
Buffers: shared hit=584808, local hit=75763 read=2 dirtied=1614 written=1613
I/O Timings: shared read=0.031
-> Nested Loop (cost=13660.85..27305.24 rows=49647 width=107) (actual time=453.380..1487.572 rows=72542 loops=1)
Output: t6.[Измерение1]rref, t6.[Измерение2]rref, t6.[Измерение3]_type, t6.[Измерение3]_rtref, t6.[Измерение3]_rrref, t6.[Измерение4]rref, ''4f5a5692-4c5c-42c9-b2b8-361618fda809''::mvarchar(36)
Buffers: shared hit=584808
-> HashAggregate (cost=13660.68..13739.02 rows=6528 width=147) (actual time=453.240..505.780 rows=78849 loops=1)
Output: t4.[Измерение1]rref, t4.[Измерение2]rref, t4.[Измерение3]_type, t4.[Измерение3]_rtref, t4.[Измерение3]_rrref, t4.[Измерение4]rref, (max(t4.[Period])), substr(max((t5.[Recorder]tref || t5.[Recorder]rref)), 1, 4), substr(max((t5.[Recorder]tref || t5.[Recorder]rref)), 5, 16)
Group Key: t4.[Измерение1]rref, t4.[Измерение2]rref, t4.[Измерение3]_type, t4.[Измерение3]_rtref, t4.[Измерение3]_rrref, t4.[Измерение4]rref, (max(t4.[Period]))
Batches: 1 Memory Usage: 21521kB
Buffers: shared hit=2963
-> Hash Join (cost=6225.73..10175.74 rows=32268 width=105) (actual time=199.048..306.638 rows=78871 loops=1)
Output: t4.[Измерение1]rref, t4.[Измерение2]rref, t4.[Измерение3]_type, t4.[Измерение3]_rtref, t4.[Измерение3]_rrref, t4.[Измерение4]rref, (max(t4.[Period])), t5.[Recorder]tref, t5.[Recorder]rref
Hash Cond: ((t5.[Измерение2]rref = t4.[Измерение2]rref) AND (t5.[Измерение3]_type = t4.[Измерение3]_type) AND (t5.[Измерение3]_rtref = t4.[Измерение3]_rtref) AND (t5.[Измерение3]_rrref = t4.[Измерение3]_rrref) AND (t5.[Измерение4]rref = t4.[Измерение4]rref) AND (t5.[Period] = (max(t4.[Period]))))
Buffers: shared hit=2957
-> Index Only Scan using [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность] on [РегистрСведений.РегистрСведений1] t5 (cost=0.22..3222.59 rows=80848 width=105) (actual time=0.163..37.679 rows=78871 loops=1)
Output: t5.[Измерение1]rref, t5.[Измерение2]rref, t5.[Измерение3]_type, t5.[Измерение3]_rtref, t5.[Измерение3]_rrref, t5.[Измерение4]rref, t5.[Period], t5.[Recorder]tref, t5.[Recorder]rref, t5.[НомерСтроки], t5.[Активность]
Index Cond: ((t5.[Измерение1]rref = ''\\x80cf000c2919e55c11e8d61eaaea174b''::bytea) AND (t5.[Измерение2]rref = ANY (''{"\\\\x85fcae3f76020e634abe34361ea16c54","\\\\xb06b3591e74f5c99473419f0f221ec78","\\\\x93686b029a3b5c134dd1fe1dcbafb48c","\\\\x9aa12f953a91661047a2a767adf88234","\\\\x8e41f52f837660434a77036e0ec0b113","\\\\xaac76213c87946894f191ed61563b4b1","\\\\xb7a8a9d944a1d51a49cfbef4ad46e374","\\\\xa3762b7e71fb14284058c5aaebe110f4"}''::bytea[])) AND (t5.[Активность] = true))
Heap Fetches: 11
Buffers: shared hit=1480
-> Hash (cost=5180.99..5180.99 rows=65282 width=83) (actual time=198.134..198.136 rows=78849 loops=1)
Output: t4.[Измерение1]rref, t4.[Измерение2]rref, t4.[Измерение3]_type, t4.[Измерение3]_rtref, t4.[Измерение3]_rrref, t4.[Измерение4]rref, (max(t4.[Period]))
Buckets: 131072 (originally 65536) Batches: 1 (originally 1) Memory Usage: 10265kB
Buffers: shared hit=1477
-> HashAggregate (cost=3875.35..4528.17 rows=65282 width=83) (actual time=120.418..145.653 rows=78849 loops=1)
Output: t4.[Измерение1]rref, t4.[Измерение2]rref, t4.[Измерение3]_type, t4.[Измерение3]_rtref, t4.[Измерение3]_rrref, t4.[Измерение4]rref, max(t4.[Period])
Group Key: t4.[Измерение1]rref, t4.[Измерение2]rref, t4.[Измерение3]_type, t4.[Измерение3]_rtref, t4.[Измерение3]_rrref, t4.[Измерение4]rref
Batches: 1 Memory Usage: 17425kB
Buffers: shared hit=1477
-> Index Only Scan using [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность] on [РегистрСведений.РегистрСведений1] t4 (cost=0.22..3309.42 rows=80848 width=83) (actual time=0.051..56.114 rows=78871 loops=1)
Output: t4.[Измерение1]rref, t4.[Измерение2]rref, t4.[Измерение3]_type, t4.[Измерение3]_rtref, t4.[Измерение3]_rrref, t4.[Измерение4]rref, t4.[Period], t4.[Recorder]tref, t4.[Recorder]rref, t4.[НомерСтроки], t4.[Активность]
Index Cond: ((t4.[Измерение1]rref = ''\\x80cf000c2919e55c11e8d61eaaea174b''::bytea) AND (t4.[Измерение2]rref = ANY (''{"\\\\x85fcae3f76020e634abe34361ea16c54","\\\\xb06b3591e74f5c99473419f0f221ec78","\\\\x93686b029a3b5c134dd1fe1dcbafb48c","\\\\x9aa12f953a91661047a2a767adf88234","\\\\x8e41f52f837660434a77036e0ec0b113","\\\\xaac76213c87946894f191ed61563b4b1","\\\\xb7a8a9d944a1d51a49cfbef4ad46e374","\\\\xa3762b7e71fb14284058c5aaebe110f4"}''::bytea[])) AND (t4.[Period] <= ''2026-01-26 00:00:00''::timestamp without time zone) AND (t4.[Активность] = true))
Heap Fetches: 11
Buffers: shared hit=1477
-> Index Scan using [Период, Регистратор, НомерСтроки] on [РегистрСведений.РегистрСведений1] t6 (cost=0.17..2.06 rows=1 width=105) (actual time=0.011..0.012 rows=1 loops=78849)
Output: t6.[Period], t6.[Recorder]tref, t6.[Recorder]rref, t6.[НомерСтроки], t6.[Активность], t6.[Измерение1]rref, t6.[Измерение2]rref, t6.[Измерение3]_type, t6.[Измерение3]_rtref, t6.[Измерение3]_rrref, t6.[Измерение4]rref, t6.[Ресурс1], t6.[СпособРасчета]rref, t6.[ВедущийИзмерение3]_type, t6.[ВедущийИзмерение3]_rtref, t6.[ВедущийИзмерение3]_rrref, t6.[Организация]rref, t6.[Комментарий]
Index Cond: ((t6.[Period] = (max(t4.[Period]))) AND (t6.[Recorder]tref = (substr(max((t5.[Recorder]tref || t5.[Recorder]rref)), 1, 4))) AND (t6.[Recorder]rref = (substr(max((t5.[Recorder]tref || t5.[Recorder]rref)), 5, 16))))
Filter: (t6.[Ресурс1] AND (t4.[Измерение1]rref = t6.[Измерение1]rref) AND (t4.[Измерение2]rref = t6.[Измерение2]rref) AND (t4.[Измерение3]_type = t6.[Измерение3]_type) AND (t4.[Измерение3]_rtref = t6.[Измерение3]_rtref) AND (t4.[Измерение3]_rrref = t6.[Измерение3]_rrref) AND (t4.[Измерение4]rref = t6.[Измерение4]rref))
Rows Removed by Filter: 4
Buffers: shared hit=581845
Query Identifier: -8919515384634747255
Planning:
Buffers: shared hit=132
Planning Time: 2.523 ms
Execution Time: 1593.110 ms
Итак, по плану запроса сначала выполнилось сканирование индекса [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность] оператором Index Only Scan с отбором по первым двум измерениям и периоду, заданному в параметрах. Полученный набор сгруппировался по четырем измерениям с вычислением максимума по периоду – таким образом был получен срез последних по периоду, но так как у регистра сведений периодичность "По позиции регистратора", сгруппированный набор снова соединяется с основной таблицей для последующего вычисления максимума уже по регистратору.
Мы сделали много, мало прочитали и имеем сгруппированный набор (Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор) – все хорошо. Осталось заново соединиться с основной таблицей для получения ресурса и последующей фильтрации по нему. Но планировщик выбирает сканирование индекса [Период, Регистратор, НомерСтроки] вместо существующего [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность], видимо ожидая, что в разрезе (Период, Регистратор) будет 1 строка, а по факту в среднем это 5 строк и более – такая структура данных в этом регистре. В итоге для каждой строки среза последних выполняется дополнительное чтение оператором Index Scan в среднем 5 строк с последующей фильтрацией.
Хорошо, планировщик ошибся, но суть немного в другом. Виртуальная таблица "Срез последних" выполняет отбор по ресурсу после получения среза, то есть, если отбор по ресурсу высокоселективный, то возможность максимально ограничить выборку на первых шагах использоваться не будет. Мы получим срез по заданным измерениям, а уже после применим фильтр по ресурсу, прочитав много лишнего.
А что если, сначала отфильтровать, а уже после проверять, являются ли записи последними или нет, вложенным подзапросом для каждой строки?
"ВЫБРАТЬ
| РегистрСведений1.Измерение1 КАК Измерение1,
| РегистрСведений1.Измерение2 КАК Измерение2,
| РегистрСведений1.Измерение3 КАК Измерение3,
| РегистрСведений1.Измерение4 КАК Измерение4
|ИЗ
| РегистрСведений.РегистрСведений1 КАК РегистрСведений1
|ГДЕ
| РегистрСведений1.Период <= &ДатаОкончания
| И РегистрСведений1.Измерение2 В(&Измерение2)
| И РегистрСведений1.Измерение1 В(&Измерение1)
| И РегистрСведений1.Ресурс1
| И РегистрСведений1.Активность
| И (РегистрСведений1.Период, РегистрСведений1.Регистратор, РегистрСведений1.Измерение1, РегистрСведений1.Измерение2, РегистрСведений1.Измерение3, РегистрСведений1.Измерение4) В
| (ВЫБРАТЬ
| МАКСИМУМ(РегистрСведений1.Период),
| МАКСИМУМ(РегистрСведений1.Регистратор),
| РегистрСведений1.Измерение1,
| РегистрСведений1.Измерение2,
| РегистрСведений1.Измерение3,
| РегистрСведений1.Измерение4
| ИЗ
| (ВЫБРАТЬ
| МАКСИМУМ(РегистрСведений1.Период) КАК Период,
| РегистрСведений1.Регистратор КАК Регистратор,
| РегистрСведений1.Измерение1 КАК Измерение1,
| РегистрСведений1.Измерение2 КАК Измерение2,
| РегистрСведений1.Измерение3 КАК Измерение3,
| РегистрСведений1.Измерение4 КАК Измерение4
| ИЗ
| РегистрСведений.РегистрСведений1 КАК РегистрСведений1
| ГДЕ
| РегистрСведений1.Период <= &ДатаОкончания
| И РегистрСведений1.Активность
| СГРУППИРОВАТЬ ПО
| РегистрСведений1.Регистратор,
| РегистрСведений1.Измерение1,
| РегистрСведений1.Измерение2,
| РегистрСведений1.Измерение3,
| РегистрСведений1.Измерение4) КАК РегистрСведений1
| СГРУППИРОВАТЬ ПО
| РегистрСведений1.Измерение1,
| РегистрСведений1.Измерение2,
| РегистрСведений1.Измерение3,
| РегистрСведений1.Измерение4)"
План 1: Низкоселективный отбор по Ресурс1 = ИСТИНА. Даже в этом случае быстрее чем срез последних с ошибкой планировщика.
Insert on pg_temp.tt3 (cost=0.22..255373.97 rows=36442 width=107) (actual time=0.166..1261.598 rows=72542 loops=1)
Output: 0
Buffers: shared hit=338087, local hit=75763 read=2 dirtied=1614 written=1613
I/O Timings: shared read=0.036
-> Index Scan using [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность] on [РегистрСведений.РегистрСведений1] t1 (cost=0.22..255373.97 rows=36442 width=107) (actual time=0.084..1159.954 rows=72542 loops=1)
Output: t1.[Измерение1]rref, t1.[Измерение2]rref, t1.[Измерение3]_type, t1.[Измерение3]_rtref, t1.[Измерение3]_rrref, t1.[Измерение4]rref, ''4d3516d7-5cc4-4d5b-a011-745e6a1ddf77''::mvarchar(36)
Index Cond: ((t1.[Измерение1]rref = ''\\x80cf000c2919e55c11e8d61eaaea174b''::bytea) AND (t1.[Измерение2]rref = ANY (''{"\\\\x85fcae3f76020e634abe34361ea16c54","\\\\xb06b3591e74f5c99473419f0f221ec78","\\\\x93686b029a3b5c134dd1fe1dcbafb48c","\\\\x9aa12f953a91661047a2a767adf88234","\\\\x8e41f52f837660434a77036e0ec0b113","\\\\xaac76213c87946894f191ed61563b4b1","\\\\xb7a8a9d944a1d51a49cfbef4ad46e374","\\\\xa3762b7e71fb14284058c5aaebe110f4"}''::bytea[])) AND (t1.[Period] <= ''2026-01-26 00:00:00''::timestamp without time zone) AND (t1.[Активность] = true))
Filter: (t1.[Ресурс1] AND (SubPlan 1))
Rows Removed by Filter: 6329
Buffers: shared hit=338087
SubPlan 1
-> GroupAggregate (cost=2.46..2.62 rows=1 width=79) (actual time=0.014..0.014 rows=1 loops=72564)
Output: 1, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Group Key: t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Filter: ((t1.[Period] = max((max(t3.[Period])))) AND (t1.[Recorder]tref = substr(max((t3.[Recorder]tref || t3.[Recorder]rref)), 1, 4)) AND (t1.[Recorder]rref = substr(max((t3.[Recorder]tref || t3.[Recorder]rref)), 5, 16)))
Rows Removed by Filter: 0
Buffers: shared hit=290267
-> GroupAggregate (cost=2.46..2.48 rows=1 width=105) (actual time=0.011..0.011 rows=1 loops=72564)
Output: max(t3.[Period]), t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Group Key: t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Buffers: shared hit=290267
-> Sort (cost=2.46..2.47 rows=1 width=105) (actual time=0.010..0.010 rows=1 loops=72564)
Output: t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref, t3.[Period]
Sort Key: t3.[Recorder]tref, t3.[Recorder]rref
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=290267
-> Index Only Scan using [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность] on [РегистрСведений.РегистрСведений1] t3 (cost=0.22..2.44 rows=1 width=105) (actual time=0.007..0.007 rows=1 loops=72564)
Output: t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref, t3.[Period]
Index Cond: ((t3.[Измерение1]rref = t1.[Измерение1]rref) AND (t3.[Измерение2]rref = t1.[Измерение2]rref) AND (t3.[Измерение3]_type = t1.[Измерение3]_type) AND (t3.[Измерение3]_rtref = t1.[Измерение3]_rtref) AND (t3.[Измерение3]_rrref = t1.[Измерение3]_rrref) AND (t3.[Измерение4]rref = t1.[Измерение4]rref) AND (t3.[Period] <= ''2026-01-26 00:00:00''::timestamp without time zone) AND (t3.[Активность] = true))
Heap Fetches: 9
Buffers: shared hit=290267
Query Identifier: -3825323334523442618
Planning:
Buffers: shared hit=10
Planning Time: 0.512 ms
Execution Time: 1268.596 ms
План 2: Высокоселективный отбор по Ресурс1 = ЛОЖЬ.
Insert on pg_temp.tt2 (cost=0.22..255373.97 rows=3982 width=107) (actual time=0.152..185.638 rows=6307 loops=1)
Output: 0
Buffers: shared hit=73052, local hit=6586 read=1 dirtied=142 written=141
I/O Timings: shared read=0.012
-> Index Scan using [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность] on [РегистрСведений.РегистрСведений1] t1 (cost=0.22..255373.97 rows=3982 width=107) (actual time=0.106..178.188 rows=6307 loops=1)
Output: t1.[Измерение1]rref, t1.[Измерение2]rref, t1.[Измерение3]_type, t1.[Измерение3]_rtref, t1.[Измерение3]_rrref, t1.[Измерение4]rref, ''4d70c57e-a096-44b1-9fa9-130dd3432bc3''::mvarchar(36)
Index Cond: ((t1.[Измерение1]rref = ''\\x80cf000c2919e55c11e8d61eaaea174b''::bytea) AND (t1.[Измерение2]rref = ANY (''{"\\\\x85fcae3f76020e634abe34361ea16c54","\\\\xb06b3591e74f5c99473419f0f221ec78","\\\\x93686b029a3b5c134dd1fe1dcbafb48c","\\\\x9aa12f953a91661047a2a767adf88234","\\\\x8e41f52f837660434a77036e0ec0b113","\\\\xaac76213c87946894f191ed61563b4b1","\\\\xb7a8a9d944a1d51a49cfbef4ad46e374","\\\\xa3762b7e71fb14284058c5aaebe110f4"}''::bytea[])) AND (t1.[Period] <= ''2026-01-26 00:00:00''::timestamp without time zone) AND (t1.[Активность] = true))
Filter: ((NOT t1.[Ресурс1]) AND (SubPlan 1))
Rows Removed by Filter: 72564
Buffers: shared hit=73052
SubPlan 1
-> GroupAggregate (cost=2.46..2.62 rows=1 width=79) (actual time=0.014..0.014 rows=1 loops=6307)
Output: 1, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Group Key: t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Filter: ((t1.[Period] = max((max(t3.[Period])))) AND (t1.[Recorder]tref = substr(max((t3.[Recorder]tref || t3.[Recorder]rref)), 1, 4)) AND (t1.[Recorder]rref = substr(max((t3.[Recorder]tref || t3.[Recorder]rref)), 5, 16)))
Buffers: shared hit=25232
-> GroupAggregate (cost=2.46..2.48 rows=1 width=105) (actual time=0.011..0.011 rows=1 loops=6307)
Output: max(t3.[Period]), t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Group Key: t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref
Buffers: shared hit=25232
-> Sort (cost=2.46..2.47 rows=1 width=105) (actual time=0.010..0.010 rows=1 loops=6307)
Output: t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref, t3.[Period]
Sort Key: t3.[Recorder]tref, t3.[Recorder]rref
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=25232
-> Index Only Scan using [Измерение1, Измерение2, Измерение3, Измерение4, Период, Регистратор, НомерСтроки, Активность] on [РегистрСведений.РегистрСведений1] t3 (cost=0.22..2.44 rows=1 width=105) (actual time=0.007..0.007 rows=1 loops=6307)
Output: t3.[Recorder]tref, t3.[Recorder]rref, t3.[Измерение1]rref, t3.[Измерение2]rref, t3.[Измерение3]_type, t3.[Измерение3]_rtref, t3.[Измерение3]_rrref, t3.[Измерение4]rref, t3.[Period]
Index Cond: ((t3.[Измерение1]rref = t1.[Измерение1]rref) AND (t3.[Измерение2]rref = t1.[Измерение2]rref) AND (t3.[Измерение3]_type = t1.[Измерение3]_type) AND (t3.[Измерение3]_rtref = t1.[Измерение3]_rtref) AND (t3.[Измерение3]_rrref = t1.[Измерение3]_rrref) AND (t3.[Измерение4]rref = t1.[Измерение4]rref) AND (t3.[Period] <= ''2026-01-26 00:00:00''::timestamp without time zone) AND (t3.[Активность] = true))
Heap Fetches: 2
Buffers: shared hit=25232
Query Identifier: 3379024635153412838
Planning:
Buffers: shared hit=10
Planning Time: 0.461 ms
Execution Time: 186.303 ms
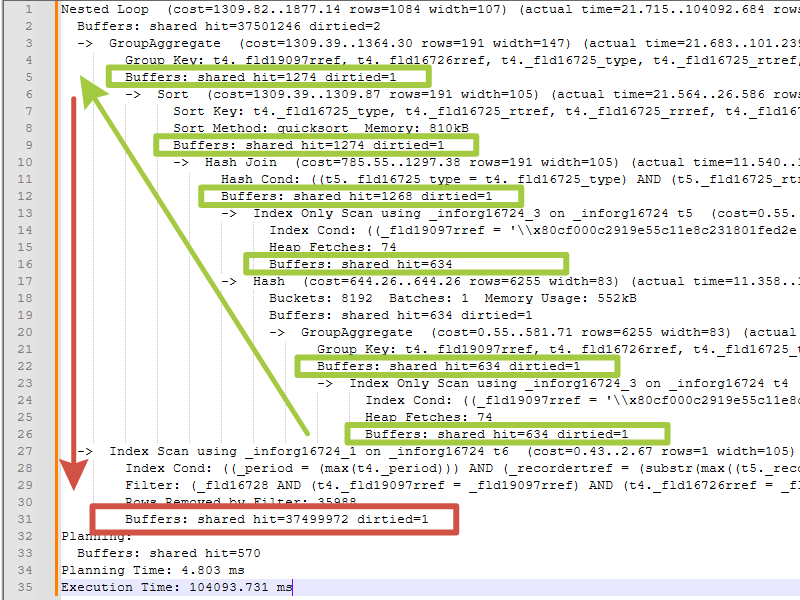
План 3. В продуктиве. После внесения изменений со 100 секунд ушло в диапазон до 100 миллисекунд.
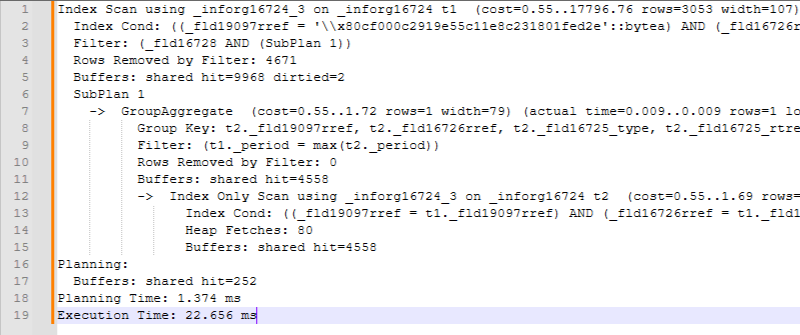
И главный нюанс:
Применимо только к регистрам, в которых в среднем менее двух записей по периоду для одной комбинации измерений. Если подзапрос (SubPlan 1), например, найдёт десять записей, ситуация ухудшится.
Как видите, все просто, данная разработка в помощь!
Вступайте в нашу телеграмм-группу Инфостарт