Введение
Я думаю, что данная статья опоздала по времени своей публикации примерно на год-два. Именно тогда на Инфостарте была волна статей, касающихся возможностей "нетрадиционных" (для разработчиков в экосистеме 1С, прежде всего) способов версионирования исходных кодов конфигураций, обработок и всего остального. Примерно в то же время начался наш проект полноценного версионирования правил обмена между информационными базами 1С.
В этой статье я расскажу о принципах работы вспомогательных скриптов, которые позволяют максимально эффективно использовать преимущества программы контроля версий git и подхода gitflow.
Основная идея
Перейдем к сути. Главная проблема ведения истории правил обмена - это единый файл. Версионировать его, конечно, можно, но всех возможностей gitflow уже не применить. В этом случае использование git ненамного отличается от содержания файла в виде макета в стандартном хранилище 1С, хотя и дает по сравнению с последним много плюсов. Тем не менее, исходя из публикации "Конвертация данных" + Git, становится понятно, что и такой вариант имеет место быть.
Следовательно, чтобы задействовать возможности git в части разрешения конфликтов с одним фалом (когда их по факту и нет), нужно этот многострочный файл разделить на более мелкие.
Что же мы видим, когда изучаем содержимое файла правил обмена? Мы видим фиксированную структуру XML-узлов. Это узлы ПравилаКонвертацииОбъектов, Алгоритмы, Запросы, Параметры, обработчики и др.
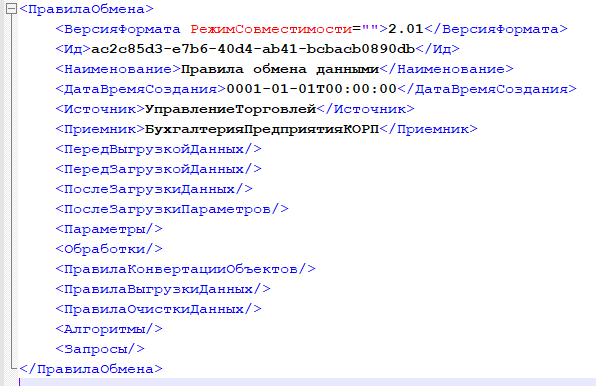
Логично разделить этот файл на несколько по именам узлов, чтобы все подчиненные элементы были перенесены в другие файлы. Дальше - больше. Как насчет выделения каждого Параметра, каждого ПравилаКонвертацииОбъекта (ПравилаВыгрузкиДанных, ПравилаОчисткиДанных), а также, Свойств и Значений в отдельные файлы? Хочется, чтобы два (и более, конечно) разработчика могли отредактировать два разных параметра и два разных свойства одного правила конвертации, а я потом мог это автоматически слить без конфликтов, которые обязательно будут при работе с единым файлом.
Реализация
Для реализации поставленной задачи прекрасно подошла библиотека Microsoft XML Parser и ее класс XML Document Object Model (DOM). Это известный большинству разработчиков правил обмена COM-объект MSXML2.DOMDocument. Он позволяет работать с XML-документом как с объектом, а также использовать XPath, модифицировать данные, извлекать любой подчиненный узел для вставки в новый самостоятельный объект и наоборот.
Таким образом, необходимо найти узлы и их коллекции, каждый самостоятельный элемент записать в файл, а исходную структуру максимально очистить от вынесенных из ее подчинения элементов. Казалось бы, ничего сложного. Но все было бы очень просто, если бы не множество мелких нюансов. Вот один из них.
Дело в том, что в файле с правилами обмена, который создает конфигурация Конвертация данных, не соблюдается единый подход к правилу оформления коллекции элементов. Коллекция может начаться следом за перечислением всех свойств текущего узла или классически, когда вся коллекция обрамляется заранее известным тэгом.

Такие различия делают код менее стройным и понятным, приводят к появлению дополнительных ветвлений, которых можно было бы избежать.
Или другой пример. При загрузке правил обмена в конфигурацию Конвертация данных им присваивается уникальный идентификатор (это же элемент справочника, куда ж без него?). А при сохранении измененного файла этот идентификатор прописывается в узел Ид корневого элемента ПравилаОбмена (см. первый скриншот). Если разработчиков несколько, а их несколько, то при слиянии мы всегда будем получать конфликт, хотя от этого как раз и уходили. Поэтому было принято решение ничего не значащий реквизит просто очищать. Та же участь постигла элемент ДатаВремяСоздания. Зачем хранить дату в файле, когда есть история в git?
А еще были проблемы с непечатаемыми символами в наименовании объектов, отличающимися символами перевода строки внутри разных элементов одного файла, проблема с неправильной работой правил для платформы 7.7 и некоторые другие.
Результат
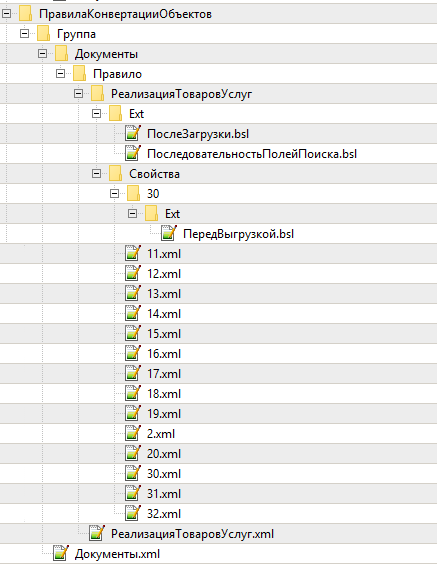
Собственно, при помощи подхода, изложенного выше, удалось разделить выгружаемый из Конвертации данных файл на максимально мелкие фрагменты. При этом структура каталогов и расположение файлов максимально повторяет выгрузку обычной конфигурации/расширения в XML. В корне каталога располагается файл ПравилаОбмена.xml, а для каждой коллекции объектов создается отдельный каталог. Все обработчики выгружаются в отдельную папку Ext в папку того объекта, к которому они относятся. На скриншоте представлены глобальные обработчики правил конвертации.
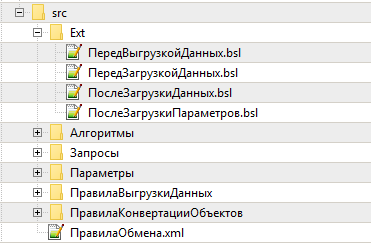
Все Параметры располагаются в одном каталоге, так как у них отсутствует иерархия и дополнительные свойства. Это, пожалуй, самый простой пример парсинга.
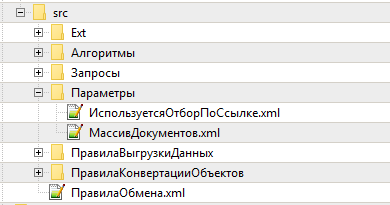
Немного сложнее разбираются на файлы Алгоритмы и Запросы, так как у каждого такого элемента есть не только определяющие свойства, но и несущее основной смысл подчиненный элемент Текст. Последний может быть внушительных размеров, и поэтому хранится отдельно.
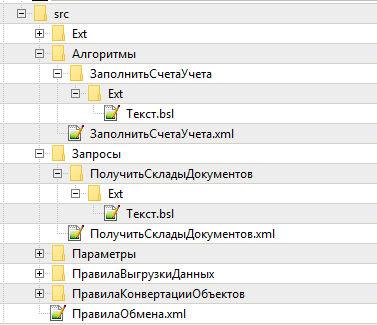
И самая сложная ситуация это ПравилаКонвертацииОбъектов. В этом случае у объекта помимо служебных свойств, которые хранятся в одноименном корневом файле, могут присутствовать Обработчики (папка Ext), а также наверняка будут использоваться свойства-реквизиты. Последние из-за недопустимых символов в наименовании (которое может быть еще и пустым) приходится хранить под номерами (он же соответствует коду элемента справочника, поэтому повторяться они не могут). На скриншоте показано, что у свойства с кодом 30 есть еще обработчик ПередВыгрузкой.
Полученные мелкие файлы, каждый из которых по факту представляет собой некий объект со своими свойствами, отлично версионируются. Вероятность возникновения конфликтов при слиянии снижается значительно.
Разработчик после получения изменений "собирает" правила обмена и загружает их в Конвертацию данных, а по окончании работы выполняет "разбор" и фиксирует изменения. При этом существует возможность и непосредственного редактирования. В структуре каталогов найти нужный файл проще, чем в одном большом xml-файле. Можно открыть нужный обработчик или нужное свойство и внести исправления без участия специализированной конфигурации.
Вместо заключения
Системные требования
Скрипт разрабатывался для работы под операционной системой Microsoft Windows и гарантированно работает на корпоративных версиях 7, 8 и 10. Сам скрипт написан на OneScript.
Планы по развитию проекта
В последнее время проект не развивается, хотя есть несколько направлений, которые могут его улучшить. Эта часть посвящена мыслям по этому поводу.
- Проекту решительно не хватает автоматизированных тестов. Ни один публичный проект не должен существовать без этой очень важной составляющей.
- При выполнении скриптов никак не обрабатываются ошибки. Из-за чего приходится контролировать результат разбора "глазами". Может так случиться, что разбор завершился ошибкой, не успев начаться, тогда все файлы git считает удаленными. С непривычки можно такой результат и запушить.
- На момент публикацию разбираются не все элементы XML-файла, хотя, возможно, кому-нибудь они очень будут нужны.
- Скрипты не работают автоматически (не используется хук precommit). Приходится запускать bat-ники вручную (хотя мы, на самом деле, уже привыкли и не жалуемся).
- Возможно, стоит разработать библиотеку, которую можно будет встраивать в Конвертацию данных и выполнять разбор прямо из конфигурации.
Исходный код проекта опубликован в репозитории на GitHub. Поэтому пользуйтесь, участвуйте и изучайте новое!
Вступайте в нашу телеграмм-группу Инфостарт