













{kind=link}
[Дополнение от 2017.11.23: Для тех, кому неинтересно читать - в репозитории есть готовая portable сборка и выкладываются готовые скрипты.]
Подготовка
Для начала подготовим удобную и комфортную среду исполнения. Для этого потребуются
- Git Bash - эмулятор консоли bash со многоми дополнительными программами, важнейшей из который для нас является perl
- Notepad++ - удобнейший редактор кода, который вместе с дополнением NppExec становится полноценной IDE для наших комфортного выполнения задач анализа
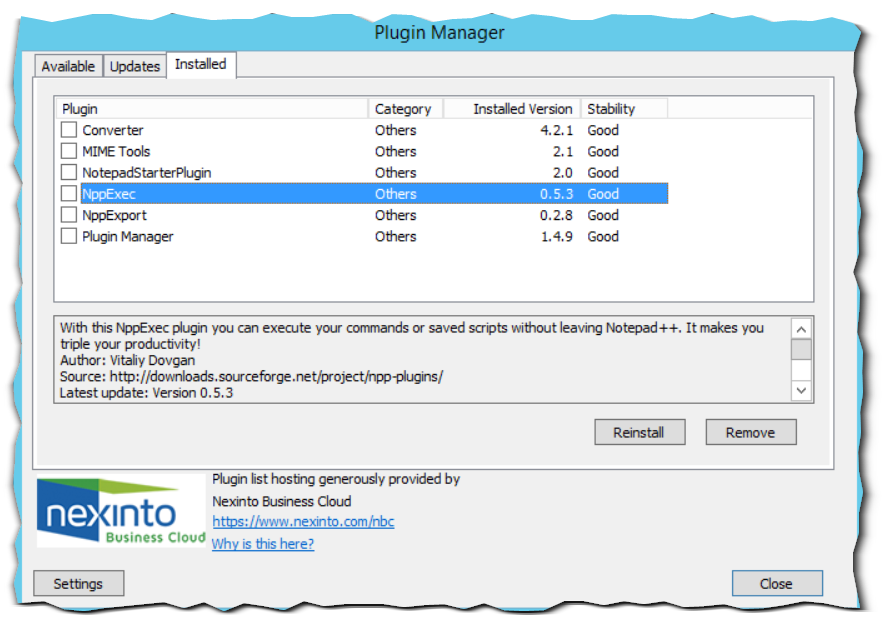
После скачивания и установки данных программ необходимо настроить. И настраивать понадобится только Notepad++. Идём в Plugin Manager и устанавливаем дополнение NppExec.

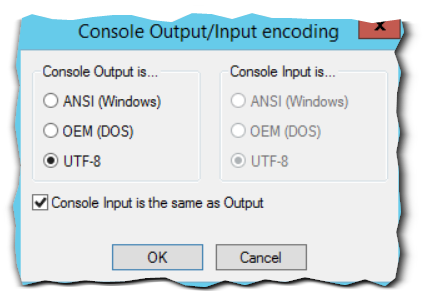
В его настройках выбираем формат локали (ConsoleOutput) - необходимо выбрать UTF-8 как для Input, так и для Output. (Plugins->NppExec->Console Output..)

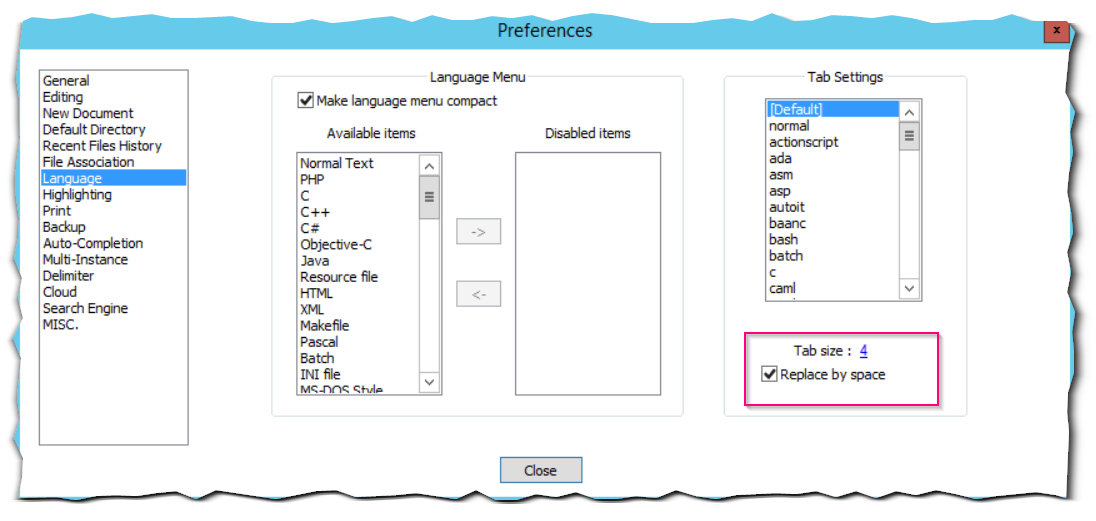
В настройках Notepad++ обязательно поставьте замену табов на пробелы, иначе ничего не будет нормально работать. Лучше, если табов в тексте скрипта вообще не будет.

Теперь может писать наш первый скрипт.
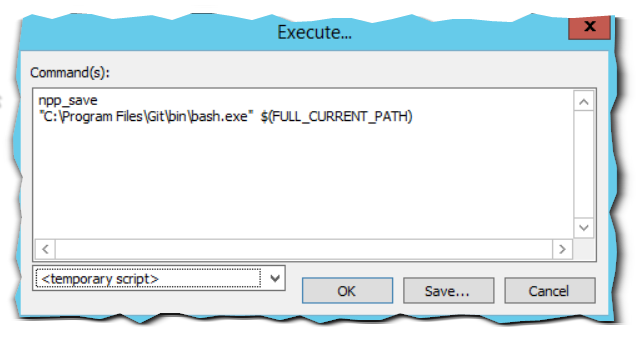
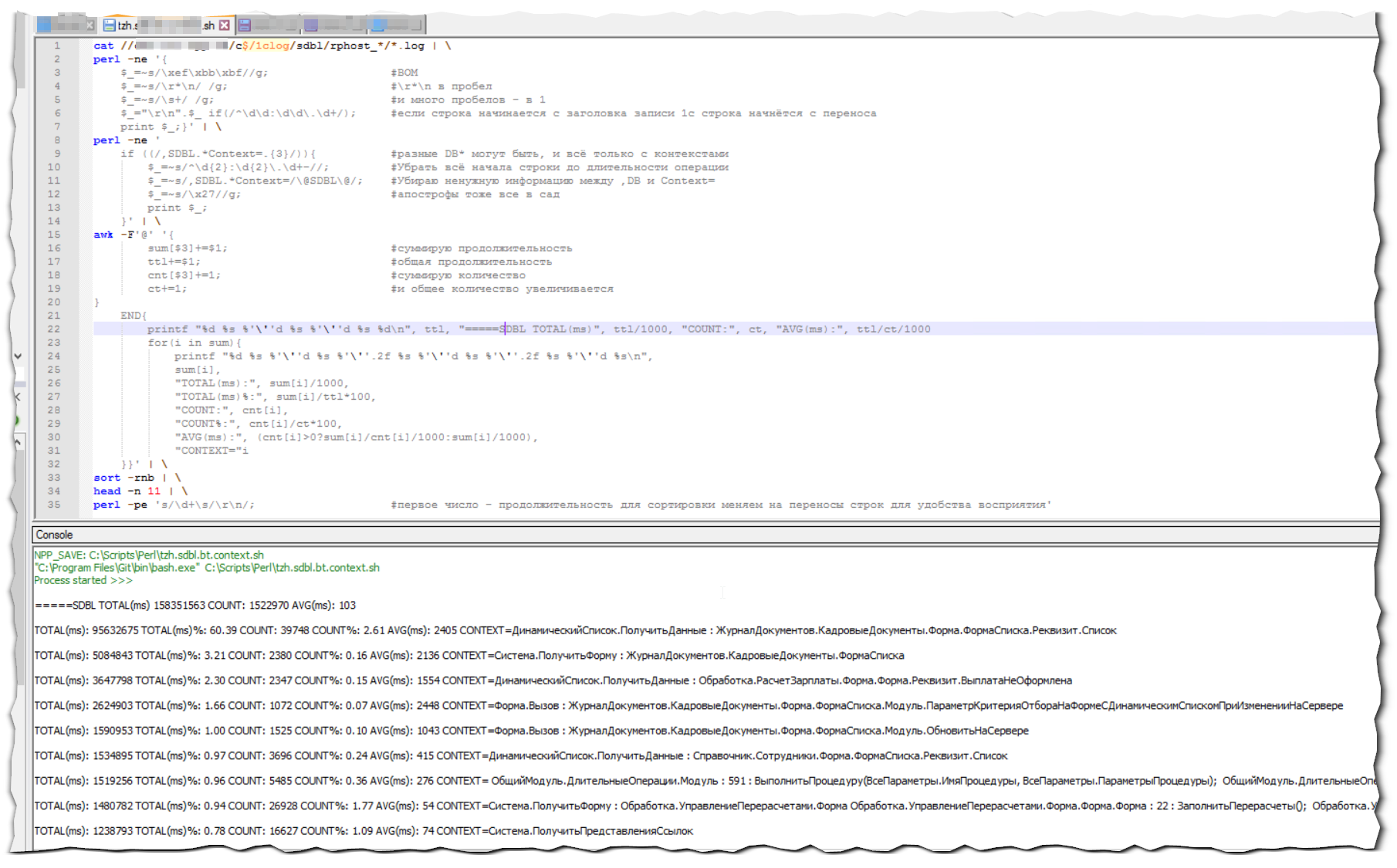
Напишем простую команду: ls -l, нажмём F6 для запуска и настроим его команды:

npp_save - этот макрос сохранит текущий скрипт перед выполнением
"C:\Program Files\Git\bin\bash.exe" "$(FULL_CURRENT_PATH)" - запускаем bash и передаём в качестве аргумента имя открытого файла
Теперь результат выполнения операций будет отображаться внизу, в дополнительном окне самого Notepad++.

Обработка
Начнём обработку. Допустим, нас интересует суммарная продолжительность вызовов к СУБД (SDBL) в разрезе контекстов. Выбирать информацию мы будем из технологического журнала 1с (вопросы его настройки здесь рассматриваться не будут).
Так как полный текст одного события в ТЖ 1с может быть разбит на несколько строк, то нам сначала нужно склеить все строки, принадлежащие одинаковым событиям, чтобы в дальнейшем обрабатывать их уже построчно.
Я реализовал такой алгоритм склейки строк одного события:
- Заменяем все переносы строки на пробел (в других случаях это может быть любая необходимая последовательность)
- Если начало строки соответствует шаблону начала строки записи, то ставим перенос строки перед этой строкой.
perl -ne '{
$_=~s/\r*\n/ /g; #\r*\n в пробел
$_="\r\n".$_ if(/^\d\d:\d\d\.\d+/); #если строка начинается с заголовка записи 1с строка начнётся с переноса
print $_;}'
Таким образом мы получим список полного текста всех событий ТЖ.
После этого отрежем всю информацию от начала события до его длительности:
$_=~s/^\d{2}:\d{2}\.\d+-//;
и уберём весь текст от SDBL до контекста
$_=~s/,SDBL.*Context=/\@SDBL\@/;
После этих нехитрых манипуляций события на выходе приобретут следующий вид:
(длительность события)@(названия события-SDBL)@(и его контекст)
Небольшое пояснение по используемым в Perl конструкциям:
- команда perl -ne означает лишь только выполнить программу, указанную в кавычках и передавать ей на вход строки на вход.
- принимаемые строки попадают в системную переменную Perl - $_
- операция $_=~s/123/321/g; есть ни что иное, как присвоение переменной $_ результатов замены содержимого $_ в соответствии с регулярным выражением s/123/321/g. В данном контексте 123 меняется на 321.
Теперь при помощи AWK можно просуммировать длительность и количество событий по контексту.
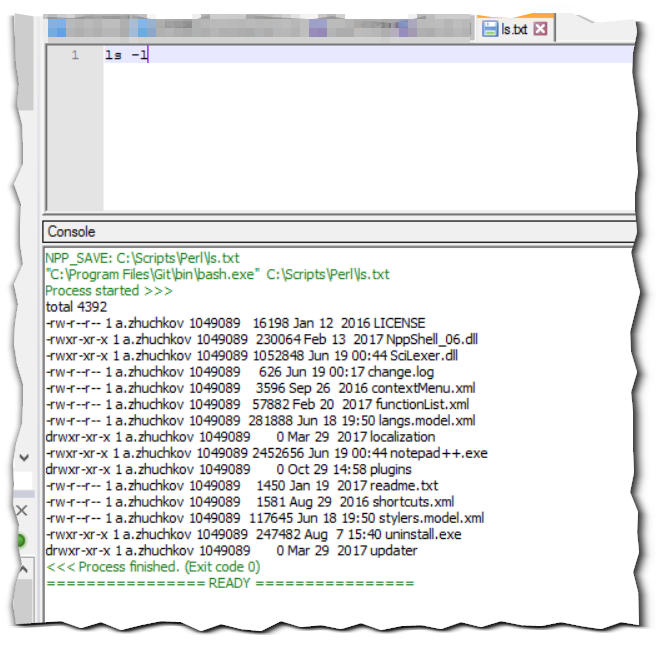
Результирующий скрипт будет примерно таким:
cat //server/c$/1clog/sdbl/rphost_*/*.log | \
perl -ne '{
$_=~s/\xef\xbb\xbf//g; #BOM
$_=~s/\r*\n/ /g; #\r*\n в пробел
$_=~s/\s+/ /g; #и много пробелов - в 1
$_="\r\n".$_ if(/^\d\d:\d\d\.\d+/); #если строка начинается с заголовка записи 1с строка начнётся с переноса
print $_;}' | \
perl -ne '
if ((/,SDBL.*Context=.{3}/)){ #по событиям SDBL
$_=~s/^\d{2}:\d{2}\.\d+-//; #Убрать всё начала строки до длительности операции
$_=~s/,SDBL.*Context=/\@SDBL\@/; #Убираю ненужную информацию между ,SDBL и Context=
$_=~s/\x27//g; #апострофы тоже все в сад
print $_;
}' | \
awk -F'@' '{
sum[$3]+=$1; #суммирую продолжительность
ttl+=$1; #общая продолжительность
cnt[$3]+=1; #суммирую количество
ct+=1; #и общее количество увеличивается
}
END{
printf "%d %s %'\''d %s %'\''d %s %d\n", ttl, "=====SDBL TOTAL(ms)", ttl/1000, "COUNT:", ct, "AVG(ms):", ttl/ct/1000
for(i in sum){
printf "%d %s %'\''d %s %'\''.2f %s %'\''d %s %'\''.2f %s %'\''d %s\n",
sum[i],
"TOTAL(ms):", sum[i]/1000,
"TOTAL(ms)%:", sum[i]/ttl*100,
"COUNT:", cnt[i],
"COUNT%:", cnt[i]/ct*100,
"AVG(ms):", (cnt[i]>0?sum[i]/cnt[i]/1000:sum[i]/1000),
"CONTEXT="i
}}' | \
sort -rnb | \
head -n 11 | \
perl -pe 's/\d+\s/\r\n/; #первое число - продолжительность для сортировки меняем на переносы строк для удобства восприятия'
Небольшое пояснение по используемым в AWK конструкциям:
- -F'@' - означает что в качестве разделителя полей выступает символ @. Разделителем можно назначить как символ, так и последовательность.
- значения между разделителями в awk попадают в переменные служебные переменные $1, $2, $3 итд. (в зависимости от количества полей). В $0 приходит вся строка, без разбивки по разделителям.
- команда printf в первом параметре определяем типы выводимых значений и их форматирование, так:
%s - строка
%d - целое, %'\''d означает группировку по 3 частей целого числа (123456 = 123 456, для удобства восприятия)
%f - float, %'\''.2f означает группировку по 3 частей числа с округлением до двух знаков после запятой (123456,1234 = 123 456,12 для удобства восприятия)

Таким незамысловатым образом, мы можем увидеть, что 2,46% обращений к СУБД контекста "ДинамическийСписок.ПолучитьДанные : ЖурналДокументов.КадровыеДокументы.Форма.ФормаСписка.Реквизит.Список" создали 60,36% процентов нагрузки.
Ныряем глубже
Так как в записях журналов регистрации 1с не содержится информация о часе и дате, а мне очень бы хотелось использовать для отборов и их, то попробуем получить и эти данные:
grep -r ".*" -H /c/rphost_*/*.log
В таком формате команда grep будет выводить перед каждой строкой имя файла, в пути и имени которого содержится дополнительная информация:

Но, имя файла будет выводиться и перед склеиваемыми строками. Значит нужно убрать его из склеиваемых строк. И, для начала, изменить формат строки события на более читабельный.
Здесь на помощь снова приходит Perl со своими мощными регулярными выражениями.
grep -r ".*" -H /c/rphost_*/*.log | \
perl -ne '{
$_=~s/\xef\xbb\xbf//g; #BOM
$_=~s/\r*\n/ /g; #\r*\n
$_=~s/\x27//g; #убираю апострофы
$_=~s/\s+/ /g; #сворачиваю последовательности пробелов в один
if(/\d\d:\d\d\.\d+/){
while(s/^.*_(\d+)\/(\d{2})(\d{2})(\d{2})(\d{2})\.log\:(\d+:\d+\.\d+)\-(\d+),(\w+),(\d+)//){
$_="\r\n"."dt=20".$2.".".$3.".".$4.",time=".$5.":".$6.",pid=".$1.",dur=".$7.",evnt=".$8.",ukn=".$9.$_ ;
}
}else{$_=~s/^.*log://;} #из перенесённых строк просто вытираю начало
print $_;}'| \
head -n 150
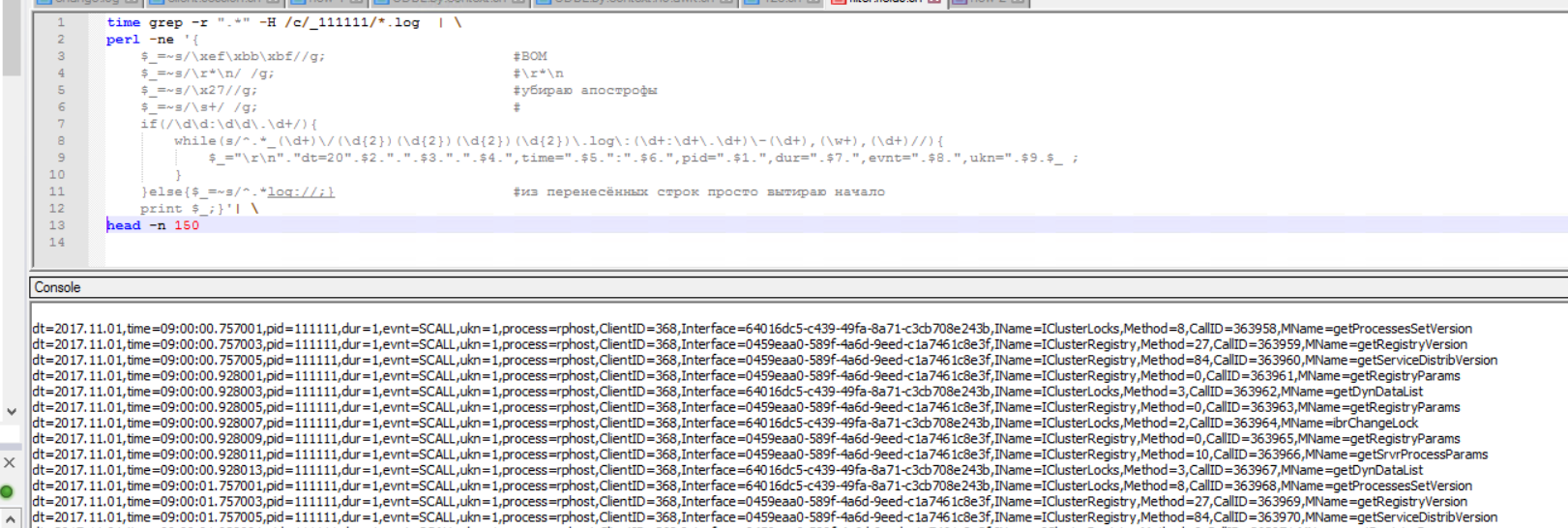
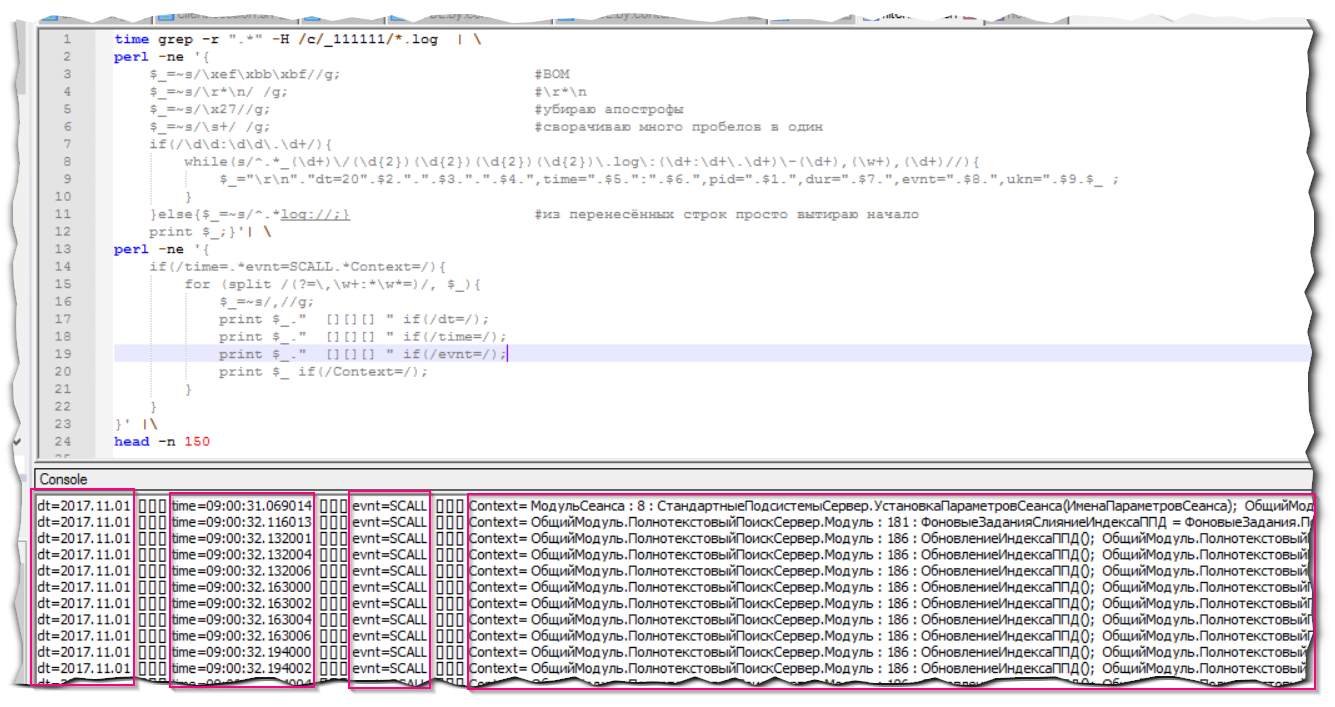
Результатом такой обработки строк будет удобный и читаемый вид:

Теперь становится возможным разделить поля по разделителю(то есть выводить только те поля, что нам реально нужны). Например, необходимо вывести только дату, время и контексты всех SCALL'ов
grep -r ".*" -H /c/rphost_*/*.log | \
perl -ne '{
$_=~s/\xef\xbb\xbf//g; #BOM
$_=~s/\r*\n/ /g; #\r*\n
$_=~s/\x27//g; #убираю апострофы
$_=~s/\s+/ /g; #сворачиваю много пробелов в один
if(/\d\d:\d\d\.\d+/){
while(s/^.*_(\d+)\/(\d{2})(\d{2})(\d{2})(\d{2})\.log\:(\d+:\d+\.\d+)\-(\d+),(\w+),(\d+)//){
$_="\r\n"."dt=20".$2.".".$3.".".$4.",time=".$5.":".$6.",pid=".$1.",dur=".$7.",evnt=".$8.",ukn=".$9.$_ ;
}
}else{$_=~s/^.*log://;} #из перенесённых строк просто вытираю начало
print $_;}'| \
perl -ne '{
if(/time=.*evnt=SCALL.*Context=/){
for (split /(?=\,\w+:*\w*=)/, $_){
$_=~s/,//g;
print $_." [][][] " if(/dt=/);
print $_." [][][] " if(/time=/);
print $_." [][][] " if(/evnt=/);
print $_ if(/Context=/);
}
}
}' |\
head -n 150
Результат будет весьма наглядным:

В представленных выше группировках по полям всё ещё используется AWK, хотя в самом Perl есть не менее мощные возможности для оперирования данными.
Можно убрать и AWK, и сортировку при помощи команды sort -rnb, и вывод только 10 строк при помощи head.
Попробуем же только средствами Perl подсчитать количество и продолжительность событий SDBL в разрезе контекстов:
time grep -r ".*" -H /c/rphost_*/*.log | \
perl -ne '{
$_=~s/\xef\xbb\xbf//g; #BOM
$_=~s/\r*\n/ /g; #\r*\n
$_=~s/\x27//g; #убираю апострофы
$_=~s/\s+/ /g; #сворачиваю много пробелов в один
if(/\d\d:\d\d\.\d+/){
while(s/^.*_(\d+)\/(\d{2})(\d{2})(\d{2})(\d{2})\.log\:(\d+:\d+\.\d+)\-(\d+),(\w+),(\d+)//){
$_="\r\n"."dt=20".$2.".".$3.".".$4.",time=".$5.":".$6.",pid=".$1.",dur=".$7.",evnt=".$8.",ukn=".$9.$_ ;
}
}else{$_=~s/^.*log://;} #из перенесённых строк просто вытираю начало
print $_;}'| \
perl -ne ' #perl умеет работать как AWK
if(/dur=(\d+),evnt=SDBL.*Context=(.*)/){
$dur_ttl+=$1/1000;
$dur{$2}+=$1/1000;
$cnt_ttl+=1;
$cnt{$2}+=1;
}
END{
printf("=====TIME TOTAL(ms):%.2f COUNT:%d AVG(ms):%.2f\r\n",
$dur_ttl,
$cnt_ttl,
$dur_ttl/$cnt_ttl); #формирую заголовок
foreach $k (sort {$dur{$b} <=> $dur{$a}} keys %dur) {
printf "[][][] TIME(ms):%d [][][] TIME(%):%.2f [][][] COUNT:%d [][][] COUNT(%):%.2f [][][] BY:%s \r\n",
$dur{$k},
$dur{$k}/$dur_ttl*100,
$cnt{$k},
$cnt{$k}/$cnt_ttl*100,
$k; #сортирую массив по убыванию длительности и вывожу его
last if ($_+=1)>10; #но только первые 10 строк
}
}'
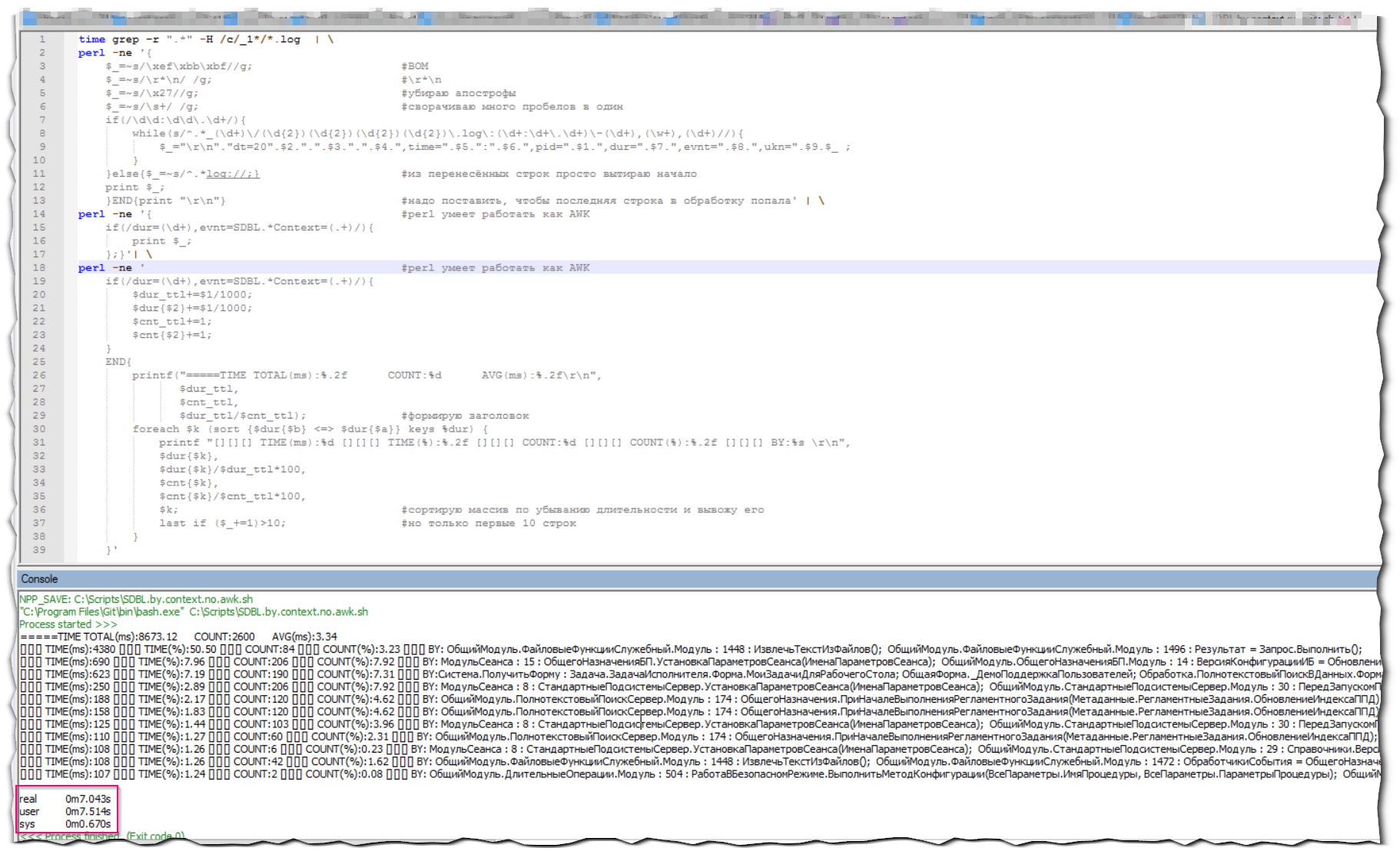
Результатом будет очень быстрая обработка всего массива ТЖ для получения интересующей нас информации.
Оценить скорость выполнения всегда можно командой time в самом начале выполнения.

Пояснения по конструкция Perl:
if(/dur=(\d+),evnt=SDBL.*Context=(.*)/){ #если у строки есть dur=\d+, его evnt=SDBL И у него есть контекст
$dur_ttl+=$1/1000;
$dur{$2}+=$1/1000; #суммируем продолжительность - $1 (первые круглые скобки(\d+)) по контексту - $2 (Context=(.*))
$cnt_ttl+=1;
$cnt{$2}+=1; #суммируем количество контекстов - $2 (Context=(.*))
}
foreach $k (sort {$dur{$b} <=> $dur{$a}} keys %dur) { #сортировка массива и обход по всем его ключам
last if ($_+=1)>10; #каждый проход мы увеличиваем на 1 переменную $_. Выходим, если число проходов превысило 10
Оптимизация
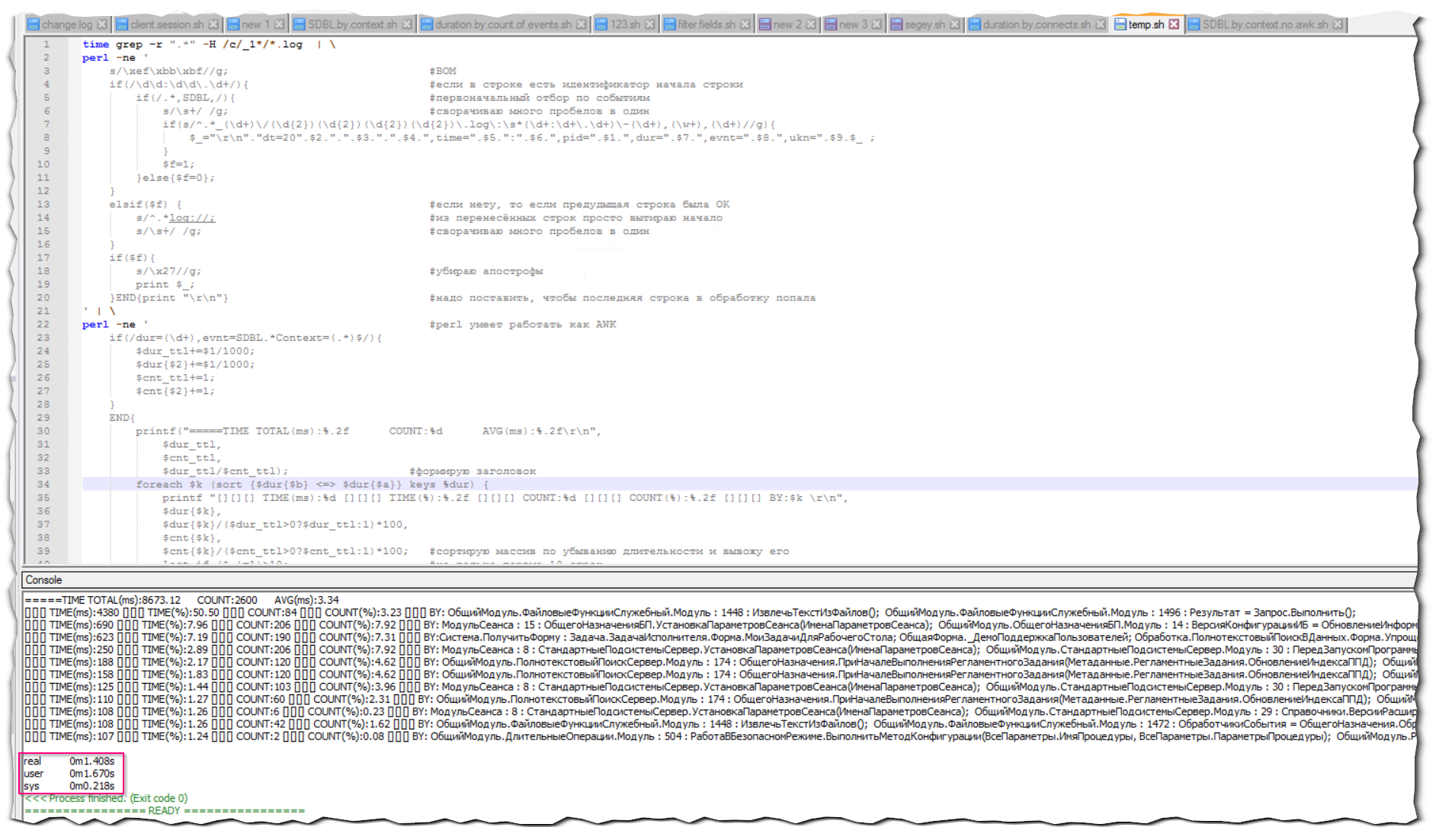
Обработка(парсинг) ТЖ - чрезвычайно ресурсоёмкое занятие. ТЖ запросто могут достигать нескольких десятков (а то и сотен) гигабайт. И выборка информации из них может занимать ОЧЕНЬ продолжительное время.
Поэтому весь код для парсинга должен быть максимально эффективным.
В предыдущем примере в первом вызове Perl склеиваются все строки, даже не отбираемые во втором вызове (подсчёт). То есть мы обрабатываем в первом проходе те строки, которые не понадобятся во втором.
Немного модифицируем отбор для того, чтобы склеивать строки только по нужному событию. Справедливости ради стоит заметить, что сразу всё необходимое - SDBL с контекстом - мы отобрать не сможем, потому что перед склейкой строк контекст может находиться на разных строчках с событием.
echo "Длительность событий SDBL в резрезе контекстов"
time grep -r ".*" -H /c/v8/logs/*/*.log | \
perl -ne '
s/\xef\xbb\xbf//; #BOM - обязательно в начале, иначе с певой строкой будут проблемы
if(/log:\d\d:\d\d\.\d+-\d+,(\w+),/){ #если в строке есть идентификатор начала строки и это наш тип события
if($1 eq "SDBL"){ #первоначальный отбор по событиям
s/\s+/ /g; #сворачиваю много пробелов в один, и перенос строки тоже здесь улетит в пробел
if(s/^.*_(\d+)\/(\d{2})(\d{2})(\d{2})(\d{2})\.log\:\s*(\d+:\d+\.\d+)\-(\d+),(\w+),(\d+)//){
$_="\r\n"."dt=20".$2.".".$3.".".$4.",time=".$5.":".$6.",pid=".$1.",dur=".$7.",evnt=".$8.",ukn=".$9.$_ ;
}
$f=1;
}else{$f=0};
}
elsif($f) { #если наше событие, то обрабатываем эту висячую строку
s/^.*log://; #из перенесённых строк просто вытираю начало
s/\s+/ /g; #сворачиваю много пробелов в один, и перенос строки тоже здесь улетит в пробел
}
if($f){
s/\x27//g; #убираю апострофы
print;
}END{print "\r\n"} #надо поставить, чтобы последняя строка в обработку попала
' | \
perl -ne ' #perl умеет работать как AWK
if(/dur=(\d+),evnt=SDBL.*Context=(.*)$/){
$dur_ttl+=$1/1000;
$dur{$2}+=$1/1000;
$cnt_ttl+=1;
$cnt{$2}+=1;
}
END{
printf("=====TIME TOTAL(ms):%.2f COUNT:%d AVG(ms):%.2f\r\n",
$dur_ttl,
$cnt_ttl,
$dur_ttl/$cnt_ttl); #формирую заголовок
foreach $k (sort {$dur{$b} <=> $dur{$a}} keys %dur) {
last if ($_+=1)>10; #но только первые 10 строк
printf "$_: [][][] TIME(ms):%d [][][] TIME(%):%.2f [][][] COUNT:%d [][][] COUNT(%):%.2f [][][] BY:$k \r\n",
$dur{$k},
$dur{$k}/($dur_ttl>0?$dur_ttl:1)*100,
$cnt{$k},
$cnt{$k}/($cnt_ttl>0?$cnt_ttl:1)*100; #сортирую массив по убыванию длительности и вывожу его
}
}'
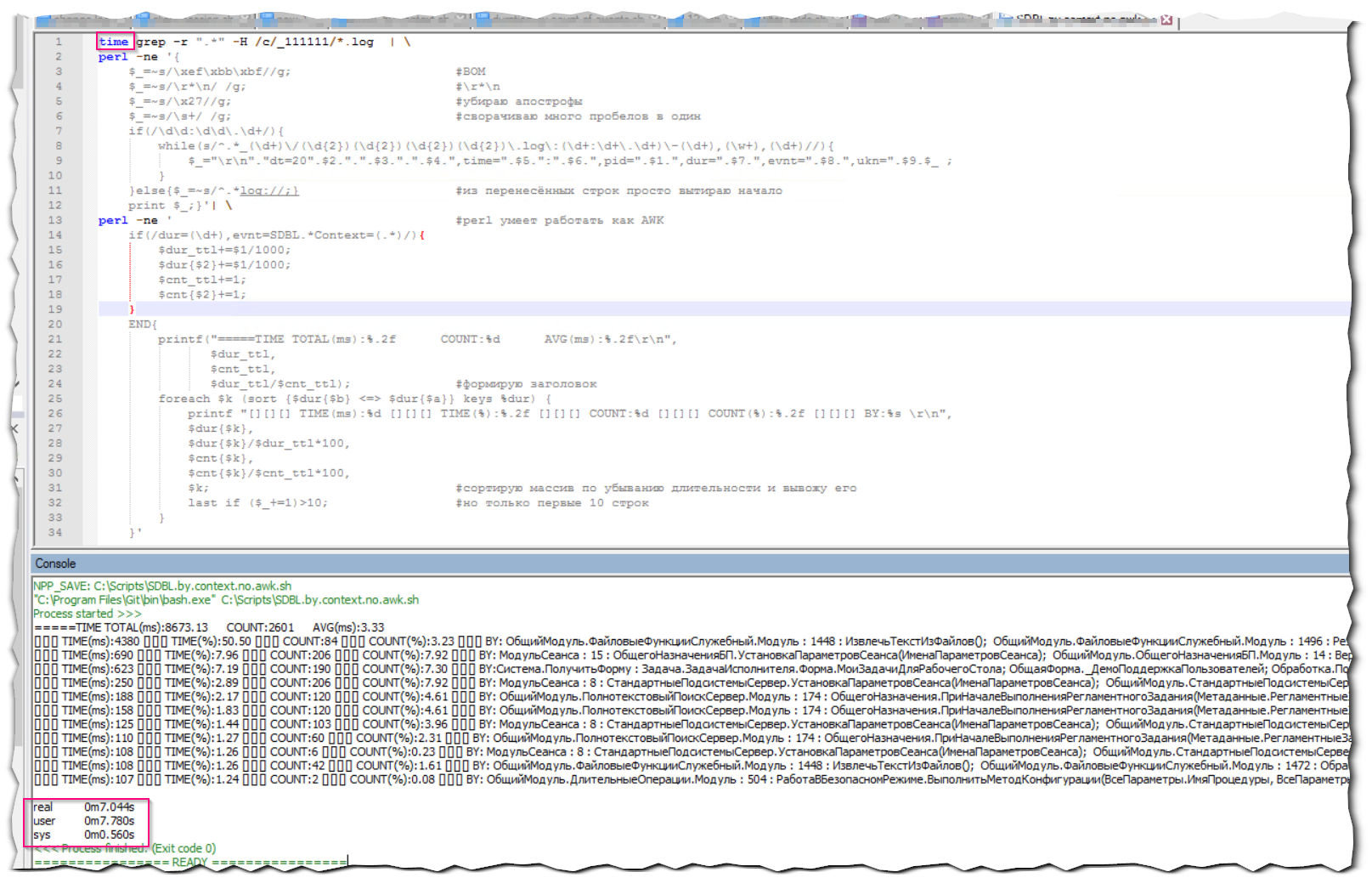
Теперь оценим скорость выполнения:

Скорость отбора той же самой информации увеличилась в 5 раз!
Вместо заключения
Надеюсь, данная статья поможет Вам раскрыть новые возможности и измерения анализа ТЖ 1с.
Если какие-то моменты остались непонятными, то напишите о них в комментариях. Я постараюсь описать их более подробно.
Рабочие примеры скриптов парсинга ТЖ по описанным выше методикам доступны в открытом репозитории Bash1C. Присоединяйтесь!
Вступайте в нашу телеграмм-группу Инфостарт