Файлы и файловые группы базы данных
Каждая база данных состоит из одного или нескольких файлов журнала транзакций и одного или нескольких файлов данных. В журнале транзакций хранятся сведения о транзакциях базы данных и обо всех изменениях данных, которые выполняют сеансы. Каждый раз, когда данные меняются, SQL Server сохраняет информацию об операции в журнал транзакций, чтобы отменить (откатить) или повторить (воспроизвести) эти действия. Эта информацию позволит SQL Server привести базу данных в согласованное состояние, в случае непредвиденного сбоя или аварии.
У каждой базы данных есть один основной файл данных, который по умолчанию имеет расширение .mdf. Кроме того, каждая база данных может также иметь дополнительные файлы базы данных. Эти файлы, по умолчанию имеют расширение .ndf.
Все файлы базы данных объединяются в файловые группы. Файловая группа - это логическая единица, которая упрощает администрирование базы данных. Она позволяет логически отделить объекты базы данных от физических файлов. При создании объектов базы данных (например, таблицы) указывается, в какую файловую группу они должны быть помещены, не беспокоясь о структуре самих файлов данных.
В листинге 1 показан сценарий, который создает базу данных с именем OrderEntryDb . Эта база данных состоит из трех файловых групп. Основная файловая группа содержит один файл данных, хранящийся на диске M. Вторая файловая группа (Entities), имеющая один файл данных, хранится на диске N. Последняя файловая группа (Orders), состоит из двух файлов данных, размещенных на дисках O и P, а на диске L хранится файл журнала транзакций.
Листинг 1. Создание базы данных
create database [OrderEntryDb] on
primary
(name = N'OrderEntryDb', filename = N'm:\OEDb.mdf'),
filegroup [Entities]
(name = N'OrderEntry_Entities_F1', filename = N'n:\OEEntities_F1.ndf'),
filegroup [Orders]
(name = N'OrderEntry_Orders_F1', filename = N'o:\OEOrders_F1.ndf'),
(name = N'OrderEntry_Orders_F2', filename = N'p:\OEOrders_F2.ndf')
log on
(name = N'OrderEntryDb_log', filename = N'l:\OrderEntryDb_log.ldf')
На рис.1 изображена физическая структура базы и файлы данных (пять дисков с четырьмя файлами данных и одним файлом журнала транзакций). Прямоугольниками из пунктирных линий изображены файловые группы.
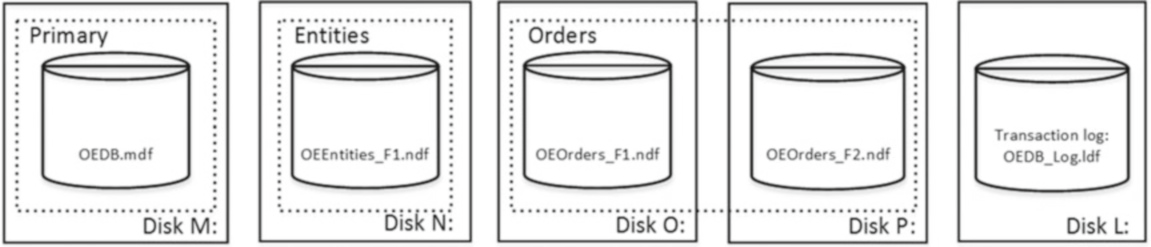
Рисунок 1. Физическая структура базы данных и файлов
Возможность поместить несколько файлов в файловую группу позволяет распределить нагрузку между различными дисками, что может улучшить производительность системы ввода-вывода. Однако при этом следует учитывать, что база данных станет полностью или частично недоступной в случае сбоя одного из дисков.
С другой стороны, производительность журнала транзакций не зависит от количества файлов. SQL Server последовательно работает с журналами транзакций, и только один файл журнала будет доступен в любой момент времени.
Создадим несколько таблиц (листинг 2). Таблицы Customers и Articles создаются в файловой группе Entities. Таблица Orders находится в файловой группе Orders.
Листинг 2. Создание таблиц
create table dbo.Customers
(
/* Table Columns */
) on [Entities];
create table dbo.Articles
(
/* Table Columns */
) on [Entities];
create table dbo.Orders
(
/* Table Columns */
) on [Orders];
На рис.2 показана физическая структура таблиц в базе данных и на дисках

Рисунок 2. Физическая структура таблиц
Разделение связи между логическими объектами в файловых группах и физическими файлами базы данных позволяет нам точно настроить структуру файла базы данных, чтобы получить максимальную выгоду от подсистемы хранения, не беспокоясь, что это как-то повредит систему.
При создании базы данных или добавлении новых файлов в существующую базу данных можно указать начальные размеры файлов и параметры автоматического роста. Файл для записи SQL Server выбирает пропорционально свободному месту в нем.
Совет. Не используйте основную (primary) файловую группу ни для чего, кроме системных объектов. Создание отдельной файловой группы или набора файловых групп для пользовательских объектов упрощает администрирование базы данных и аварийное восстановление, особенно для больших баз данных.
Вы можете указать начальные размеры файлов и параметры автоматического увеличения во время создания базы данных или при добавлении новых файлов в уже существующую базу данных. В SQL Server используется алгоритм равномерного заполнения при выборе файла, в который он собирается записать данные. Объем записываемых данных пропорционален свободному пространству, доступному в файле — чем больше свободного места в файле, тем больше операций записи обработается.
Совет. Для систем OLTP и файловых групп с часто меняющимися данными лучше создавать несколько файлов данных независимо от основной конфигурации хранилища. Оптимальное количество файлов зависит от рабочей нагрузки и используемого оборудования. Как правило это четыре файла данных, если на сервере имеется до 16 логических процессоров, далее соотношение должно быть 1/8 между файлами и процессорами.
Установите одинаковые параметры начального размера (Initial Size) и размер автоматического увеличения (Autogrowth), при этом автоувеличение укажите в мегабайтах, а не в процентах для всех файлов одной файловой группы. Это поможет алгоритму пропорционального заполнения равномерно распределять операции записи по файлам данных.
Установки одинакового начального размера и параметров автоматического увеличения для всех файлов в файловой группе обычно достаточно для эффективной работы алгоритма пропорционального заполнения. Но даже с такими настройками файлы в файловой группе могут расти неравномерно.
В SQL Server 2016 добавлено два параметра: AUTOGROW_SINGLE_FILE и AUTOGROW_ALL_FILES. Эти параметры управляют автоматическим ростом размера файлов в файловой группе. По умолчанию устанавливается параметр AUTOGROW_SINGLE_FILE. В этом случае будет увеличиться только один файл. С параметром AUTOGROW_ALL_FILES будут увеличиваться одновременно все файлы файловой группы, когда один из файлов выходит за границы доступного места. В более старших версиях SQL Server такого поведения можно было добиться включив флаг трассировки T1117. Включение этого флага аналогично указанию параметра AUTOGROW_ALL_FILES.
При увеличении размера файла SQL Server заполняет выделяемое место нулями. При этом блокируются все сеансы, которые работают с данным файлом. Тоже самое касается и файла журнала транзакций.
Файл журнала транзакций всегда заполняется нулями при инициализации и это поведение нельзя изменить. Однако, для файлов данных можно включить мгновенную инициализацию файлов. Это ускорит процесс инициализации при увеличении размера файлов данных и сократит время, необходимое для создания или восстановления базы данных.
Примечание. При мгновенной инициализации файлов существует небольшой риск, связанный с безопасностью. Если этот параметр включен, выделенная, но еще не использованная часть файла данных может содержать информацию из ранее удаленных файлов ОС. Администраторы баз данных могут просматривать такие данные.
Для включения мгновенной инициализации необходимо для учетной записи, под которой запускается SQL Server, добавить разрешение "Perform Volume Maintenance Task". Это можно сделать в приложении по настройке локальной политики безопасности (secpol.msc) (рис.3).
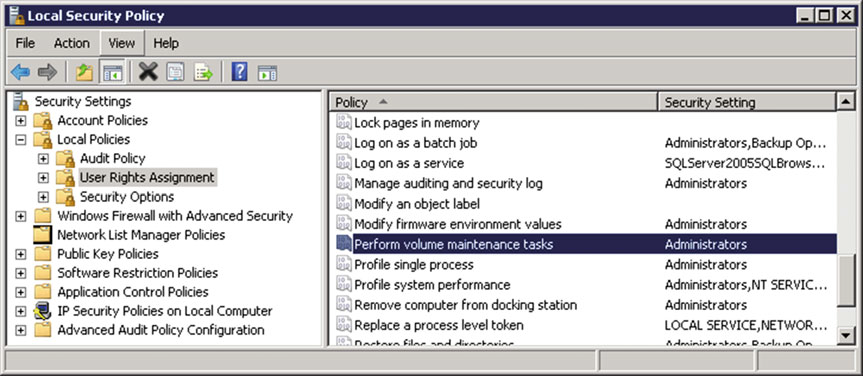
Рисунок 3. Включение мгновенной инициализации файлов в secpol.msc
Совет. SQL Server проверяет, включена ли мгновенная инициализация файлов в момент запуска службы. Вам необходимо перезапустить службу SQL Server после предоставления соответствующего разрешения учетной записи SQL Server.
В SQL Server 2016 добавили возможность включения мгновенной инициализации во время установки на этапе настройки сервера:
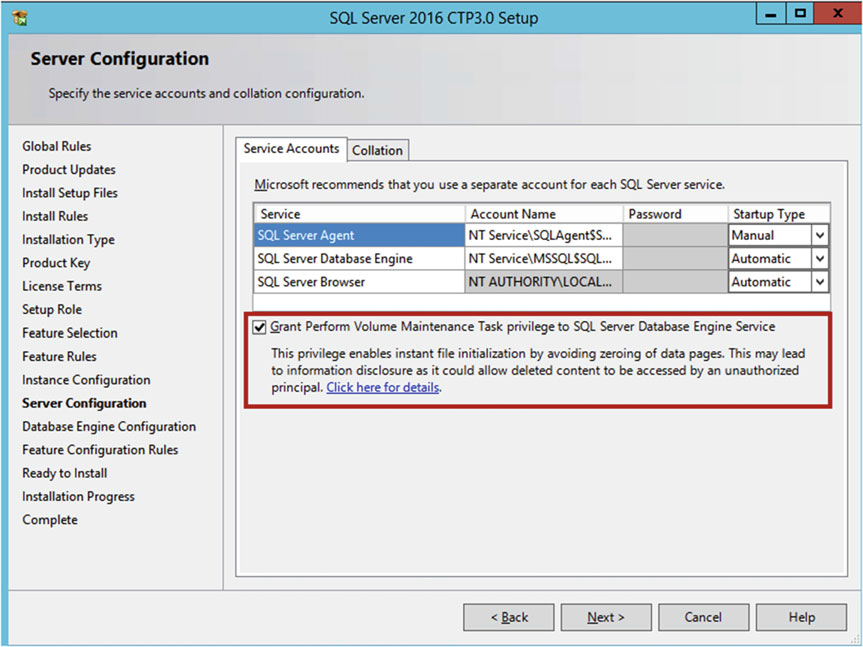
Рисунок 4. Включение мгновенной инициализации файлов во время установки SQL Server 2016
Чтобы проверить, что мгновенная инициализация включена, можно воспользоваться кодом из листинга 3. Этот код включает два флага трассировки, чтобы вывести в лог ошибок дополнительную информацию, создает базу данных и читает содержимое лога.
Листинг 3. Проверка включения мгновенной инициализации файлов
dbcc traceon(3004,3605,-1)
go
create database Dummy
go
exec sp_readerrorlog
go
drop database Dummy
go
dbcc traceoff(3004,3605,-1)
go
Если мгновенная инициализация файлов выключена, то в логах будут события заполнения нулями файлов данных (.mdf) и файла журнала транзакций (.ldf) (рис. 5). Если мгновенная инициализация включена, то будет только событие для файла журнала транзакций.
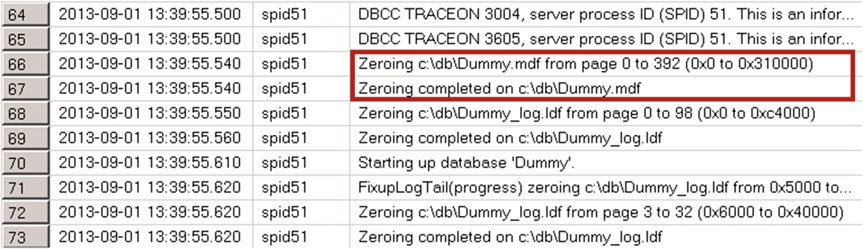
Рисунок 5. Проверка включения мгновенной инициализации файлов - события журнала ошибок
Другим важным параметром базы данных, которое управляющей размером файлов базы данных, является автоматическое сжатие (Auto Shrink). Если этот параметр включен, SQL Server сокращает файлы базы данных каждые 30 минут, уменьшая их размер. Эта операция очень ресурсоемкая и малополезная, т.к. файлы базы данных все изменении данных все равно растут. Кроме того, это сильно увеличивает фрагментацию индексов в базе данных. Автоматическое сжатие всегда должно быть выключено (Microsoft удалит этот параметр в будущих версиях SQL Server).
Страницы и строки
Все пространство в базе данных разделено на логические 8-килобайтные страницы. Все страницы нумеруются последовательно начиная с нуля. Нумерация страниц всегда непрерывная, поэтому когда SQL Server увеличивает файл базы данных, новой странице присваивается номер бОльшей страницы в файле плюс один. Аналогично, когда SQL-сервер сжимает файл, он удаляет из файла страницы с самыми большими номерами.
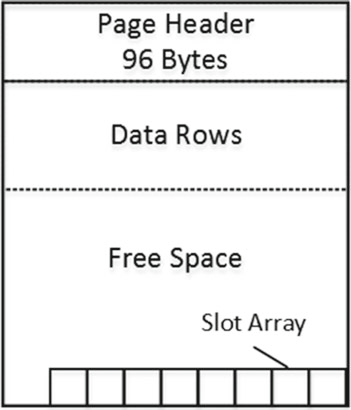
Рисунок 6. Структура страницы
96-байтовый заголовок страницы содержит различную служебную информацию о странице. Например, объект, к которому принадлежит страница, количество строк и объем свободного места на странице, ссылки на предыдущую и следующую страницы, если страница находится в цепочке страниц индекса, и др.
После заголовка располагается область, в которой хранятся непосредственно данные. Затем идет свободное пространство. В самом конце страницы располагается таблица смещений, которая представляет собой блок двухбайтовых записей, указывающих смещение, с которого начинаются соответствующие строки данных на странице.
Таблица смещений определяет логический порядок строк данных на странице. Если данные на странице необходимо отсортировать в порядке ключа индекса, то SQL Server физически не сортирует сами строки данных на странице, а заполняет таблицу смещений в соответствии с порядком сортировки индекса. Запись 0 (крайняя справа на рисунке 6) хранит смещение для строки данных с наименьшим значением ключа текущей страницы, запись 1 - второе по величине значения ключа, и т.д.
SQL Server предлагает богатый набор системных типов данных, которые можно разделить на две группы: фиксированной длины и переменной длины. Типы данных фиксированной длины, такие как int, datetime, char и другие, всегда занимают один и тот же объем памяти независимо от значения, даже если оно равно NULL. Например, колонка int всегда использует 4 байта, а колонка nchar(10) всегда использует 20 байтов для хранения информации.
Типы данных переменной длины, такие как varchar, varbinar и некоторые другие, используют столько места для хранения, сколько требуется для хранения данных, плюс два дополнительных байта. Например, колонка nvarchar(4000) будет использовать только 12 байтов для хранения строки из пяти символов и, в большинстве случаев, два байта для хранения значения NULL.
Случай, когда значения переменной длины не используют место для хранения значений NULL, будет рассмотрен позже.
Рассмотрим структуру строки данных (рис.7).
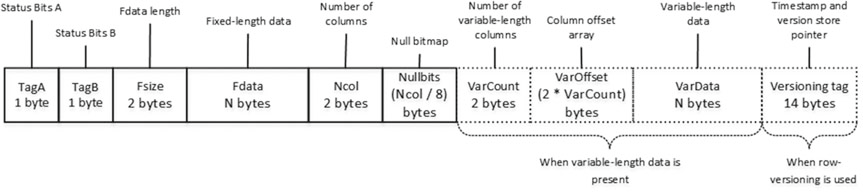
Рисунок 7. Структура строки данных
Первые два байта строки, называются битами состояния A и битами состояния B. Это битовые карты (bitmap), которые содержат информацию о строке, такую, как тип строки, информацию о том, что строка была логически удалена (скрыта), строка имеет значения NULL, колонки переменной длины и тег контроля версий.
Следующие два байта в строке используются для хранения размера данных фиксированной длины. За ними следуют сами данные.
После данных фиксированной длины идет битовая карта, содержащая признаки, может ли в колонке храниться значение NULL, которая состоит из двух частей. Первые два байта содержат значение количества колонок в строке. Вторая часть - массив. Этот массив использует один бит для каждого столбца таблицы, независимо от того, можно ли оно принимать значение NULL или нет.
Битовая карта всегда присутствует в строках данных в таблицах-кучах и в конечных узлах кластерного индекса, даже если в таблице нет колонок, которые могут принимать значение NULL. Однако битовая карта отсутствует в строках индекса, не являющихся конечными узлами, а также на конечных узлах в строках некластерных индексов, если в индексе нет колонок, которые могут хранить значение NULL.
После битовой карты следуют данные переменной длины. Сначала идут два байта со значением числа колонок переменной длины строки, за которыми следует массив смещений этих колонок. SQL Server хранит двухбайтовое значение смещения для каждой колонки переменной длины, даже если значение равно NULL. Далее следуют сами данные. В самом конце строки располагается необязательный 14-байтовый тег контроля версий. Этот тег используется во время операций, требующих контроля версий строк, таких как онлайн перестроение индекса, блокировки при оптимистичных уровнях изоляции, триггеры и некоторые другие.
Создадим таблицу, заполним ее некоторыми данными и посмотрим на фактическое содержимое этих строк. Код показан в листинге 4 . Функция "Replicate" десять раз повторяет символ, указанный в качестве первого параметра.
Листинг 4. Формат строки данных: создание таблицы
create table dbo.DataRows
(
ID int not null,
Col1 varchar(255) null,
Col2 varchar(255) null,
Col3 varchar(255) null
);
insert into dbo.DataRows(ID, Col1, Col3) values (1,replicate('a',10),replicate('c',10));
insert into dbo.DataRows(ID, Col2) values (2,replicate('b',10));
dbcc ind
(
'SQLServerInternals' /*Database Name*/
,'dbo.DataRows' /*Table Name*/
,-1 /*Display information for all pages of all indexes*/
);
Недокументированная, но многим хорошо известная команда DBCC IND возвращает информацию о размещении страниц таблицы. Вывод этой команды показан на рис. 8.

Рисунок 8. Вывод команды DBCC IND
Имеются две страницы, относящиеся к нашей таблице. Первая страница с PageType=10, является специальным типом страницы, которая называется картой распределения IAM (Index Allocation Map). Эта страница отслеживает страницы, принадлежащие определенному объекту. Не будем заострять на этом внимание сейчас, т.к. страницы карт распределения будут рассмотрены ниже.
Примечание. В SQL Server 2012 есть другая недокументированная функция управления данными (DMF), sys.dm_db_database_page_allocations, которая может использоваться в качестве альтернативы команды DBCC IND. Выходные данные этой функции предоставляют больше информации по сравнению с DBCC IND.
Страница с PageType=1 - это страница, содержащая непосредственно данные. Колонки PageFID и PagePID показывают номера файлов и страниц. Можно использовать другую недокументированную команду - DBCC PAGE, для изучения ее содержимого, как показано в листинге 5 .
Листинг 5. Формат строки данных: вызов DBCC PAGE
-- Redirecting DBCC PAGE output to console
dbcc traceon(3604);
dbcc page
(
'SqlServerInternals' /*Database Name*/
,1 /*File ID*/
,214643 /*Page ID*/
,3 /*Output mode: 3 - display page header and row details */
);
В листинге 6 показан результат выполнения команды DBCC PAGE, которая соответствует первой строке данных. SQL Server хранит данные в обратном порядке байтов. Например, двухбайтовое значение 0001 будет сохранено как 0100.
Листинг 6. Вывод команды DBCC PAGE для первой строки данных
Slot 0 Offset 0x60 Length 39
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 39
Memory Dump @0x000000000EABA060
0000000000000000: 30000800 01000000 04000403 001d001d 00270061 0................'.a
0000000000000014: 61616161 61616161 61636363 63636363 636363 aaaaaaaaacccccccccc
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
ID = 1
Slot 0 Column 2 Offset 0x13 Length 10 Length (physical) 10
Col1 = aaaaaaaaaa
Slot 0 Column 3 Offset 0x0 Length 0 Length (physical) 0
Col2 = [NULL]
Slot 0 Column 4 Offset 0x1d Length 10 Length (physical) 10
Col3 = cccccccccc
Рассмотрим данные строки более детально (рис.9).

Рисунок 9. Первая строка данных
Строка начинается с двух байт битовых состояний, за которыми следует двухбайтовое значение 0800. Это значение с обратным порядком байтов 0008, которое является смещением для значения количества колонок в строке. Это смещение указывает SQL Server, где заканчивается часть данных с фиксированной длиной.
Следующие четыре байта используются для хранения данных фиксированной длины, которые в нашем случае относятся к колонке "ID". После этого идет двухбайтовое значение, которое показывает, что строка данных имеет четыре столбца, за которыми следует один байт, содержащий битовую карту. Т.к. колонок всего 4, то достаточно всего одного байта для хранения этой информации. Она содержит значение 04, которое является 00000100 в двоичном формате. Это означает, что третий столбец в строке содержит значение NULL.
Следующие два байта хранят количество столбцов переменной длины в строке, которое равно 3 (0300 в обратном порядке байтов). За ним следует массив смещений, в котором каждые два байта хранят смещение, где заканчиваются данные столбца с переменной длинной. Как вы можете заметить, даже если колонка Col2 имеет значение NULL, то для нее все равно есть запись в массиве смещений. Далее в конце строки располагаются сами данные колонок переменной длины.
Теперь давайте посмотрим на вторую строку данных. Листинг 7 показывает результат выполнения команды DBCC PAGE, а на рис.10 приведены данные строки.
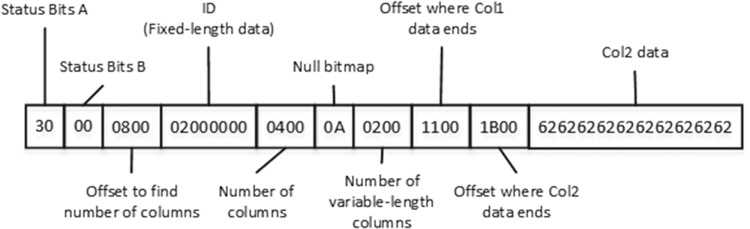
Рисунок 10. Вторая строка данных
Листинг 7. Вывод команды DBCC PAGE для второй строки данных
Slot 1 Offset 0x87 Length 27
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 27
Memory Dump @0x000000000EABA087
0000000000000000: 30000800 02000000 04000a02 0011001b 00626262 0................bbb
0000000000000014: 62626262 626262 bbbbbbb
Slot 1 Column 1 Offset 0x4 Length 4 Length (physical) 4
ID = 2
Slot 1 Column 2 Offset 0x0 Length 0 Length (physical) 0
Col1 = [NULL]
Slot 1 Column 3 Offset 0x11 Length 10 Length (physical) 10
Col2 = bbbbbbbbbb
Slot 1 Column 4 Offset 0x0 Length 0 Length (physical) 0
Col3 = [NULL]
Битовая карта во второй строке имеет значение 00001010, которое показывает, что столбцы Col1 и Col3 равны NULL. Несмотря на то, что таблица имеет три столбца переменной длины, в массиве смещений есть записи только о двух. SQL Server не хранит информацию о последних колонках переменной длины, которые имеют значение NULL.
Совет. Можно уменьшить размер строки данных, создав таблицы таким образом, чтобы столбцы переменной длины, в которых обычно хранятся значения null, определялись как последние в инструкции CREATE TABLE. Это единственный случай, когда порядок столбцов в инструкции CREATE TABLE имеет значение.
Размер данных фиксированной длины включая внутренние атрибуты должны быть не более 8 060 байт, что соответствует размеру данных, умещаемых на одной странице данных. SQL Server не позволит создать таблицу, если это условие не выполняется. Например, код в листинге 8 выдаст ошибку.
Листинг 8. Создание таблицы строки данных с размером, превышающим 8 060 байт
create table dbo.BadTable
(
Col1 char(4000),
Col2 char(4060)
)
Msg 1701, Level 16, State 1, Line 1
Creating or altering table 'BadTable' failed because the minimum row size would be 8,067,
including 7 bytes of internal overhead. This exceeds the maximum allowable table row size of
8,060 bytes.
Хранение больших объектов (LOB)
Несмотря на то, что данные фиксированной длины и внутренние атрибуты строки должны помещаться на одной странице, SQL Server может хранить данные переменной длины на разных страницах данных. Существует два различных способа хранения таких данных, в зависимости от типа и длины.
Хранение строк, превышающих размер
SQL Server может хранить данные столбцов переменной длины, не превышающие 8000 байт, на специальных страницах, называемых "страницы данных с переполнением строк" (row-overflow pages). Давайте создадим таблицу и заполним ее данными, как показано в листинге 9.
Листинг 9. Данные переполнения строк: Создание таблицы
create table dbo.RowOverflow
(
ID int not null,
Col1 varchar(8000) null,
Col2 varchar(8000) null
);
insert into dbo.RowOverflow(ID, Col1, Col2) values
(1,replicate('a',8000),replicate('b',8000));
SQL Server создаст таблицу и вставит строку данных без каких-либо ошибок, даже если размер строки данных превышает 8 060 байт. Рассмотрим распределение страниц таблицы с помощью команды DBCC IND. Результаты показаны на рис.11.

Рисунок 11. Данные переполнения строк: результат DBCC IND
Теперь можно увидеть два разных набора страниц для IAM и данных. Страница с параметром PageType=3 представляет собой страницу данных, на которой хранятся данные строк, превысивших размер.
Давайте посмотрим на страницу 214647, которая хранит данные главной строки. Частичный вывод команды DBCC PAGE для страницы (1: 214647) показан в листинге 10.
Листинг 10. Данные переполнения строк: результат команды DBCC PAGE для IN_ROW данных
Slot 0 Offset 0x60 Length 8041
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 8041
Memory Dump @0x000000000FB7A060
0000000000000000: 30000800 01000000 03000002 00511f69 9f616161 0............Q.i%6;aaa
0000000000000014: 61616161 61616161 61616161 61616161 61616161 aaaaaaaaaaaaaaaaaaaa
<Skipped>
0000000000001F40: 61616161 61616161 61616161 61616161 61020000 aaaaaaaaaaaaaaaaa…
0000000000001F54: 00010000 00290000 00401f00 00754603 00010000 .....)…@…uF.....
0000000000001F68: 00
По результату выполнения команды видно, что SQL Server хранит данные Col1 в строке. Но в колонке Col2, вместо данных указано 24-байтовое значение. Первые 16 байт хранят метаданные хранилища, в котором хранятся данные (вне строки), таких как тип, длина данных и прочие атрибуты. Последний фрагмент из 8 байт - это указатель на строку страницы, которая непосредственно хранит данные, и состоит из файла, страницы и номера записи. На рис.12 показано это подробнее. Не забудьте, что вся информация хранится в обратном порядке байтов.
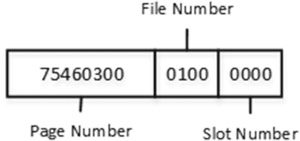
Рисунок 12. Данные переполнения строк: структура указателя страницы с переполнением строк
Номер записи равен 0, номер файла - 1, а номер страницы - шестнадцатеричное значение 0x00034675, или десятичное 214645. Номер страницы соответствует результатам DBCC IND, показанным на рис.10.
Частичный вывод команды DBCC PAGE для страницы (1: 214645) показан в листинге 11.
Листинг 11. Данные строки с переполнением: результат команды DBCC PAGE для IN_ROW данных
Blob row at: Page (1:214645) Slot 0 Length: 8014 Type: 3 (DATA)
Blob Id:2686976
0000000008E0A06E: 62626262 62626262 62626262 62626262 bbbbbbbbbbbbbbbb
0000000008E0A07E: 62626262 62626262 62626262 62626262 bbbbbbbbbbbbbbbb
Данные столбца Col2 хранятся в первой записи страницы.
Хранилище LOB-объектов
Для данных с типом text, ntext или image, SQL Server хранит данные вне строки. Используетя другой вид страниц, называемых LOB-страницами (LOB data pages).
Совет. Вы можете управлять этим поведением с помощью опции таблицы "text in row". Например,
exec sp_table_option dbo.MyTable, 'text in row', 200
заставляет SQL Server хранить LOB-объекты размером менее или равным 200 байтам в строке. Данные LOB, превышающие 200 байт, будут храниться на LOB-страницах.
Логическая структура данных LOB показана на рис.13.
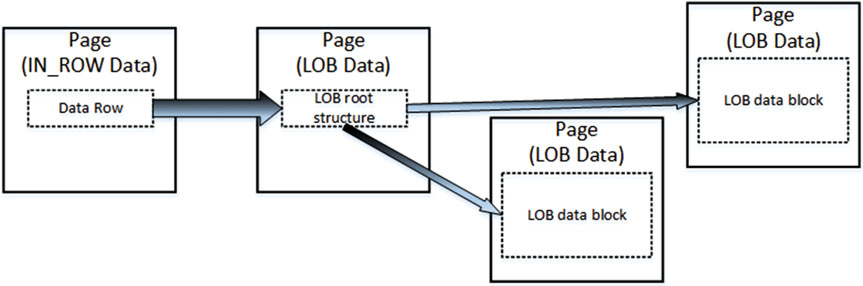
Рисунок 13. LOB-объекты: Логическая структура
Как и в случае с переполнением строк, существует указатель на другую часть информации, называемую корневой структурой LOB, которая содержит набор указателей на другие страницы и строки данных. Если объем данных LOB меньше 32 КБ и может поместиться на пяти страницах данных, корневая структура LOB содержит указатели на фактические фрагменты данных LOB. В противном случае дерево LOB начинает включать дополнительные промежуточные уровни указателей, аналогичные B-дереву, используемому в индексах.
Давайте создадим таблицу и вставим одну строку данных, как показано в листинге 12. Нам нужно привести первый аргумент функции репликации к varchar(max). В противном случае результат функции репликации был бы ограничен 8000 байтами.
Листинг 12. Данные LOB: Создание таблицы
create table dbo.TextData
(
ID int not null,
Col1 text null
);
insert into dbo.TextData(ID, Col1) values (1, replicate(convert(varchar(max),'a'),16000));
Распределение страниц для таблицы показано на рисунке 14.

Рисунок 14. LOB-данные: результат вывода DBCC IND
Как вы можете видеть, в таблице есть одна страница для данных, хранящихся в строке и три страницы, хранящие LOB-объекты. При размещении LOB-объектов, указатель хранит меньше информации и использует 16 байт, а не 24 байта, как в случае с указателем для строк, превышающих размер.
Результат выполнения команды DBCC PAGE для страницы, на которой хранится корневая структура LOB, показан в листинге 1-13.
Листинг 13. LOB-объекты: результат вывода команды DBCC PAGE для страниц с корневой структурой LOB
Blob row at: Page (1:3046835) Slot 0 Length: 84 Type: 5 (LARGE_ROOT_YUKON)
Blob Id: 131661824 Level: 0 MaxLinks: 5 CurLinks: 2
Child 0 at Page (1:3046834) Slot 0 Size: 8040 Offset: 8040
Child 1 at Page (1:3046832) Slot 0 Size: 7960 Offset: 16000
Как вы можете видеть, есть два указателя на страницы с блоками данных LOB, которые похожи на данные, показанные в листинге 11.
Формат, в котором SQL Server хранит данные из столбцов, таких как varchar(max), nvarchar(max) и varbinary(max), зависит от фактического размера данных. SQL Server хранит данные в строке, когда это возможно. Когда размещение в строке невозможно, а размер данных меньше или равен 8000 байтам, они хранятся как страницы данных с переполнением строк. Данные, размер которых превышает 8000 байт, хранятся в виде LOB-объектов.
Важно. Типы данных text, ntext и image устарели, и они будут удалены в будущих версиях SQL Server. Вместо этого используйте varchar(max), nvarchar(max) и varbinary(max).
Также стоит упомянуть, что SQL Server всегда хранит строки, которые помещаются на одной странице, используя размещение в строке. Если на странице недостаточно свободного места для размещения строки, SQL Server выделяет новую страницу и хранит все данные в ней, а не помещает часть информации на исходной странице, а часть на новой.
SELECT * и операции ввода/вывода
Существует множество причин, по которым выбор всех столбцов из таблицы с помощью оператора SELECT * является плохой идеей. Это увеличивает сетевой трафик за счет передачи данных в столбцах, которые не нужны клиентскому приложению. Это также усложняет оптимизацию производительности запросов и приводит к побочным эффектам при изменении схемы таблицы.
Рекомендуется избегать таких конструкций и вместо этого явно указывать список столбцов, необходимых клиентскому приложению. Это особенно важно для строк с переполнением и LOB-объектов, когда одна строка может содержать данные, хранящиеся на нескольких страницах данных. SQL Server должен прочитать все эти страницы, что может значительно снизить производительность запросов.
В качестве примера предположим, что у нас есть таблица dbo.Employees, в одном столбце которой хранятся фотографии сотрудников. Листинг 14 создает таблицу и заполняет ее данными.
<Листинг 14. Select * и I/O: Создание таблицы
create table dbo.Employees
(
EmployeeId int not null,
Name varchar(128) not null,
Picture varbinary(max) null
);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N2 as T2) -- 1,024 rows ,IDs(ID) as (select row_number() over (order by (select null)) from N5) insert into dbo.Employees(EmployeeId, Name, Picture)
select
ID, 'Employee ' + convert(varchar(5),ID),
convert(varbinary(max),replicate(convert(varchar(max),'a'),120000))
from Ids;
Таблица содержит 1024 строки с двоичными данными объемом 120 000 байт. Предположим, что у нас есть код в клиентском приложении, которому требуется идентификатор сотрудника и имя для заполнения раскрывающегося меню. Невнимательный разработчик может написать конструкцию select с использованием конструкции SELECT *, даже если изображение не требуется для данного конкретного случая.
Давайте сравним производительность двух выборок — одна выбирает все колонки данных, а другая выбирает только идентификатор и имя сотрудника. Код показан в листинге 15. Время выполнения и количество операций чтения показаны в таблице 1.
Листинг 15. Select * и I/O: Сравнение производительности
select * from dbo.Employees;
select EmployeeId, Name from dbo.Employees;
Таблица 1. Время выполнения для двух операций выбора
| Операций чтения | Время выполнения | |
|---|---|---|
| select EmployeeId, Name from dbo.Employees | 7 | 2 мс |
| select * from dbo.Employees; | 90895 | 3343 мс |
Как вы можете видеть, первый select, который считывает данные LOB и передает их клиенту, на несколько порядков медленнее, чем второй select. Один из случаев, когда это становится чрезвычайно важным, связан с клиентскими приложениями, которые используют платформы объектно-реляционного сопоставления (ORM). Разработчики, как правило, повторно используют одни и те же объекты сущностей в разных частях приложения. В результате приложение может загружать все атрибуты/столбцы, хотя в большинстве случаев они ему не нужны.
Лучше определять различные сущности с минимальным набором необходимых атрибутов для каждого конкретного случая. В нашем примере лучше всего было бы создать отдельные сущности/классы, такие как "Список сотрудников" и "Свойства сотрудника". Сущность "Список сотрудников" будет иметь два атрибута: Идентификатор и Имя сотрудника. "Свойства сотрудника" будут включать атрибут изображения в дополнение к двум предыдущим. Такой подход может значительно повысить производительность систем.
Экстенты и страницы карт распределения
В SQL Server восемь страниц, сгруппированных логически, образуют блоки размером 64 КБ, называемые экстентами. Доступны два типа экстентов: смешанные экстенты хранят данные, принадлежащие разным объектам, в то время как однородные экстенты хранят данные для одного и того же объекта.
По умолчанию при создании нового объекта SQL Server сохраняет первые восемь страниц объектов в смешанных экстентах. После этого все последующее распределение пространства для этого объекта выполняется с однородными экстентами. SQL Server использует особый тип страниц, называемый картами распределения (allocation maps), для отслеживания экстента и используемых страниц в файле.
В SQL Server существует два типа карты распределения.
Глобальная карта распределения (GAM) позволяет отслеживать, были ли экстенты выделены какими-либо объектами. Данные представлены в виде битовых карт, где каждый бит указывает статус выделения экстента. Нулевые биты указывают на то, что соответствующие экстенты используются. Биты со значением 1 указывают, что соответствующие экстенты свободны. Каждая страница GAM охватывает около 64 000 экстентов, или почти 4 Гб данных. Это означает, что каждый файл базы данных содержит по одной странице GAM для примерно каждых 4 Гб.
Общая глобальная карта распределения (SGAM) содержат информацию о смешанных экстентах. Подобно страницам GAM, это битовые карты с одним битом на экстент. Бит имеет значение 1, если соответствующий экстент является смешанным экстентом и имеет по крайней мере одну доступную свободную страницу. В противном случае бит устанавливается равным 0. Как и страница GAM, страница SGAM содержит информацию о примерно 64 000 экстентах, или почти 4 ГБ данных.
SQL Server может определить статус распределения экстента, просмотрев соответствующие биты на страницах GAM и SGAM. В таблице 2 показаны возможные комбинации битов.
Таблица 2. Статусы распределения экстентов
| Статус | GAM-бит | SGAM-бит |
|---|---|---|
| Свободный, не используется | 0 | 1 |
| Смешанный экстент с по крайней мере одной доступной свободной страницей | 1 | 0 |
| Однородный или заполненный смешанный экстент | 0 | 0 |
Когда SQL Server необходимо выделить новый однородный экстент, он может использовать любой экстент, для которого бит на странице GAM имеет значение 1. Когда SQL Server необходимо найти страницу в смешанном экстенте, он выполняет поиск в обеих картах распределения экстента со значением бита, равным 1, на странице SGAM и соответствующий нулевой бит на странице GAM. Если таких доступных экстентов нет, SQL Server выделяет новый свободный экстент на основе страницы GAM и устанавливает соответствующий бит в один на странице SGAM.
Несмотря на то, что смешанные экстенты могут сэкономить незначительное количество места в базе данных, они требуют, чтобы SQL Server выполнял больше модификаций страниц карт распределения, что может стать источником разногласий в загруженной системе. Это особенно важно для баз данных tempdb, где небольшие объекты обычно создаются с большой интенсивностью.
SQL Server 2016 позволяет управлять распределением пространства смешанных экстентов на уровне каждой базы данных, установив параметр базы данных MIXED_PAGE_ALLOCATION. По умолчанию он включен для пользовательских баз данных и отключен для базы данных tempdb. Такой конфигурации должно быть достаточно в большинстве случаев.
В SQL Server до 2016 года можно отключить выделение пространства для смешанных экстентов для всего экземпляра с помощью флага трассировки T1118. Установка этого флага может значительно снизить конкуренцию страниц карт распределения на загруженных OLTP–серверах, особенно для базы данных tempdb. Я рекомендую вам установить этот флаг в качестве параметра запуска на каждом экземпляре SQL Server.
У каждого файла базы данных есть своя собственная цепочка страниц GAM и SGAM. Первая страница GAM всегда является третьей страницей в файле данных (страница с номером 2). Первая страница SGAM всегда является четвертой страницей в файле данных (страница с номером 3). Следующие страницы GAM и SGAM отображаются каждые 511 230 страниц в файлах данных, что позволяет SQL Server быстро перемещаться по ним при необходимости.
SQL Server отслеживает страницы и экстенты, используемые различными типами страниц (IN_ROW_DATA, ROW_OVERFLOW и LOB), которые принадлежат объекту, с помощью другого набора страниц карт распределения, называемого картой распределения индекса (IAM). Каждая таблица/индекс имеет свой собственный набор страниц IAM, которые объединены в отдельные связанные списки, называемые цепочками IAM. Каждая цепочка IAM охватывает свою собственную единицу распределения — IN_ROW_DATA, ROW_OVERFLOW_DATA и LOB_DATA.
Каждая страница IAM в цепочке охватывает определенный интервал GAM. Страница IAM представляет собой битовую карту, где каждый бит указывает, хранит ли соответствующий экстент данные, принадлежащие определенной единице распределения для конкретного объекта. Кроме того, на первой странице IAM для объекта хранятся фактические адреса страниц для первых восьми страниц объекта, которые хранятся в смешанных экстентах.
На рис.15 показана упрощенная версия битовой карты страниц карты распределения.
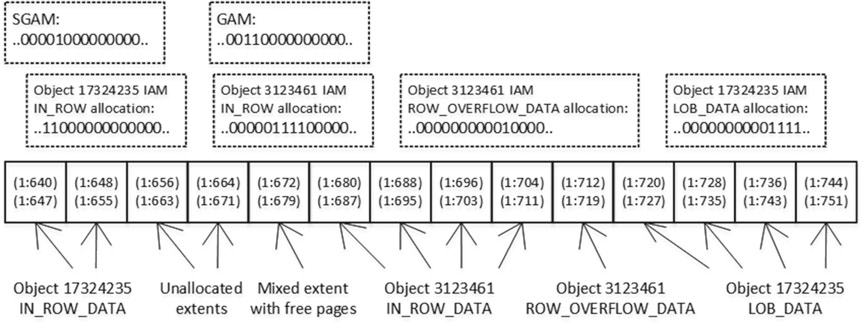
Рисунок 15. Страницы карт распределения
Существует еще один тип страницы карты распределения, называемый page free space (PFS). Несмотря на название, страницы PFS отслеживают несколько разных вещей. Мы можем представить PFS как байтовую маску, где каждый байт хранит информацию о конкретной странице, как показано на рис.16.
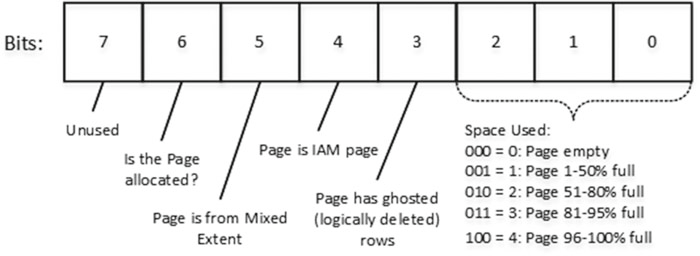
Рисунок 16. Байт состояния страницы на странице PFS
Первые три бита в байте указывают на процент используемого пространства на странице. SQL Server отслеживает используемое пространство для строк с переполнением и LOB-данных, а также для данных в строках в таблицах кучи. Это единственные случаи, когда количество свободного места на странице имеет значение.
Когда вы удаляете строку данных из таблицы, SQL Server не удаляет ее со страницы данных, а помечает эту строку как удаленную. Бит 3 указывает, есть ли на странице логически удаленные (скрыте) строки. Мы поговорим о процессе удаления ниже.
Бит 4 указывает, является ли страница страницей IAM. Бит 5 определяет, находится ли страница в смешанном экстенте или нет. Наконец, бит 6 показывает, выделена ли страница.
Каждая страница PFS отслеживает 8 088 страниц, или около 64 МБ пространства данных. Это всегда вторая страница (страница 1) в файле и каждые 8 088 страниц после нее.
Существует еще два типа страниц карт распределения. Седьмая страница (страница 6) в файле называется картой разностных изменений (DCM). Эти страницы отслеживают экстенты, которые были изменены с момента последнего ПОЛНОГО резервного копирования базы данных. SQL Server использует страницы DCM при выполнении ДИФФЕРЕНЦИАЛЬНОГО резервного копирования.
Последняя карта распределения называется картой массовых изменений (BCM). Это восьмая страница (страница 7) в файле, и она указывает, какие экстенты были изменены в операциях с неполным протоколированием с момента последнего резервного копирования журнала транзакций. Страницы BCM используются только в модели восстановления базы данных BULK-LOGGED.
Обе страницы DCM и BCM являются битовыми масками, которые охватывают 511 230 страниц в файле данных.
Изменение данных
SQL Server не читает и не изменяет строки данных непосредственно на диске. Каждый раз, когда вы обращаетесь к данным, SQL Server сначала считывает их в память.
Давайте рассмотрим, что происходит во время модификации данных. На рис.17 показано начальное состояние базы данных перед операцией обновления. Существует кэш-память, называемая буферным пулом, которая кэширует некоторые страницы данных.
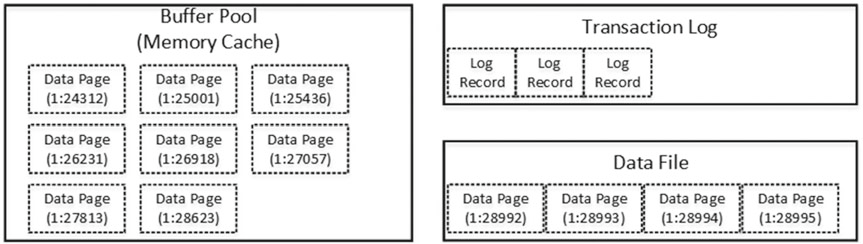
Рисунок 17. Изменение данных: исходное состояние
Предположим, что вы хотите обновить строку данных со страницы (1:28992). Этой страницы нет в буферном пуле, и SQL Server необходимо считать страницу данных с диска.
Когда страница находится в памяти, SQL Server обновляет строку данных. Этот процесс состоит из двух этапов. Сначала SQL Server генерирует новую запись журнала транзакций и синхронно записывает ее в файл журнала транзакций. Затем он изменяет строку данных и помечает страницу данных как измененную (грязную). Рис.18 иллюстрирует этот момент.
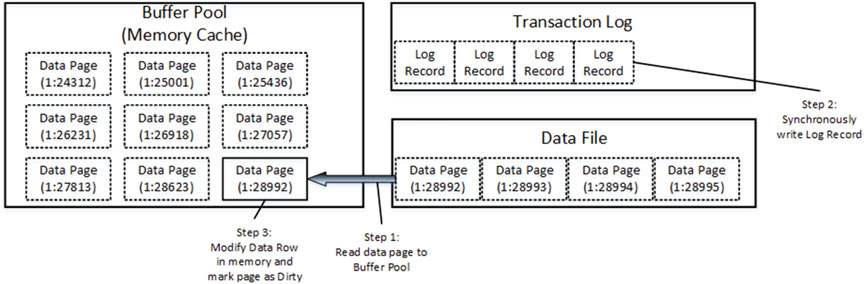
Рисунок 18. Изменение данных: обновление данных
Даже если новая версия строки данных еще не сохранена в файле базы данных, запись журнала транзакций содержит достаточно информации, чтобы при необходимости восстановить (повторить) эту операцию.
Наконец, в определенный момент SQL Server асинхронно сохраняет грязные страницы данных в файл данных и добавляет специальную запись в журнал транзакций. Этот процесс называется созданием контрольной точкой (checkpoint). На рис.19 показана эта операция.
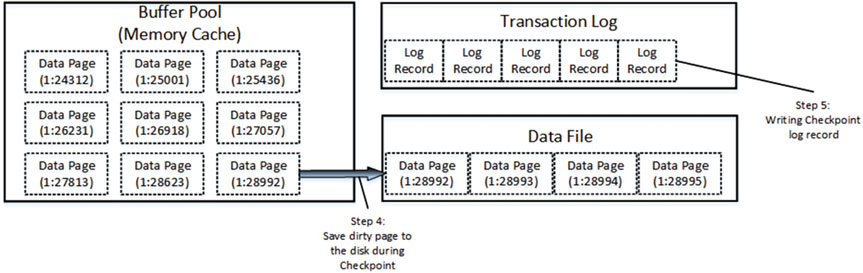
Рисунок 19. Изменение данных: создание контрольной точки
Процесс вставки работает аналогичным образом. SQL Server считывает страницу данных, в которую нужно вставить новую строку данных, из буферного пула или выделяет новый экстент/страницу, если это необходимо. После этого SQL Server синхронно добавляет запись в журнал транзакций, вставляет строку в страницу и асинхронно сохраняет страницу данных на диск.
Аналогично происходит и удаление записей. Как уже упоминалось, при удалении строки SQL Server не удаляет ее физически из страницы. Он помечает удаленные строки как скрытые (удаленные) в битах состояния. Это ускоряет удаление и позволяет SQL Server быстро отменить его при необходимости.
В процессе удаления также устанавливается флаг на странице PFS, указывающий на то, что на странице есть скрытые (удаленные) строки. SQL Server удаляет таки строки в фоновом режиме с помощью задачи под названием "ghost cleanup".
Существует еще один процесс SQL Server под названием "lazy writer", который также может сохранять грязные страницы на диске. В противоположность контрольной точке, которая сохраняет грязные страницы данных, удерживая их в буферном пуле, lazy writer обрабатывает давно неиспользуемые страницы данных (SQL Server отслеживает использование страниц внутри буферного пула), освобождая их из памяти. Он освобождает как грязные, так и чистые страницы, сохраняя грязные страницы данных на диске во время процесса. Как вы могли догадаться, lazy writer запускается в случае нехватки памяти или когда SQL Server необходимо прочитать много страниц данных в буферный пул.
Есть два ключевых момента, которые необходимо запомнить. Во-первых, когда SQL Server обрабатывает запросы DML (SELECT, INSERT, UPDATE, DELETE и MERGE), он никогда не работает с данными без предварительной загрузки страниц данных в буферный пул. Во-вторых, когда вы изменяете данные, SQL Server синхронно записывает операцию в журнал транзакций. Измененные страницы данных записываются в файлы данных асинхронно в фоновом режиме.
О размере строк с данными
Как вы уже знаете, SQL Server - это приложение с очень интенсивным вводом-выводом. SQL Server может генерировать огромное количество операций, особенно когда он имеет дело с большими базами данных, к которым одновременно обращается большое количество пользователей.
Существует множество факторов, влияющих на производительность запросов, и количество операций ввода-вывода стоит во главе списка. Чем больше операций ввода-вывода нужно выполнить запросу, тем больше страниц данных ему нужно прочитать, и тем медленнее он работает.
Размер строки данных влияет на то, сколько строк поместится на странице данных. Большие строки данных требуют больше страниц для хранения и, как следствие, увеличивают количество операций ввода-вывода при сканировании (чтении). Кроме того, объекты будут использовать больше памяти в буферном пуле.
Рассмотрим следующий пример и создадим две таблицы, как показано в листинге 16. Первая таблица, dbo. LargeRows для хранения данных используется тип данных фиксированной длины char(2000). В результате на одну страницу данных можно поместить только четыре строки, независимо от размера данных, которые содержатся в колонке Col. Вторая таблица - dbo.SmallRows, использует тип данных переменной длины varchar(2000). Давайте заполним обе таблицы одинаковыми данными.
Листинг 16. Размер строки и производительность: Создание таблицы
create table dbo.LargeRows
(
ID int not null,
Col char(2000) null
);
create table dbo.SmallRows
(
ID int not null,
Col varchar(2000) null
);
;with N1(C) as (select 0 union all select 0) -- 2 rows
,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows
,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows
,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows
,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) – 65,536 rows ,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.LargeRows(ID, Col)
select ID, 'Placeholder' from Ids;
insert into dbo.SmallRows(ID, Col)
select ID, 'Placeholder' from dbo.LargeRows;
Теперь запустим операции выбора (select), сканирующие данные, и сравним количество операций ввода-вывода и время выполнения. Вы можете увидеть код в листинге 17. Результаты, которые я получил на своем компьютере, показаны в таблице 1-3.
Листинг 17. Размер строки и производительность: Операторы SELECT
select count(*) from dbo.LargeRows;
select count(*) from dbo.SmallRows;
Таблица 3. Количество чтений и время выполнения запросов
| Операций чтения | Время выполнения | |
|---|---|---|
| select count(*) from dbo.SmallRows | 227 | 5 мс |
| select count(*) from dbo.LargeRows | 16384 | 31 мс |
Как вы можете видеть, SQL Server необходимо выполнить примерно в 70 раз больше чтений при сканировании данных dbo.LargeRows, что приводит к увеличению времени выполнения.
Вы можете повысить производительность системы, уменьшив размер строк данных. Одним из способов сделать это является использование типа данных, требующего меньше места для хранения, но при этом покрывает необходимый диапазон данных объекта. Например:
- Для хранения булевых значений используйте bit вместо tinyint, smallint или int. Тип данных bit использует один байт памяти на восемь столбцов.
- Используйте соответствующий тип данных даты/времени в зависимости от требуемой точности. Например, система ввода заказов может использовать smalldatetime (четыре байта) или datetime2(0) (шесть байт), а не datetime (восемь байт) для хранения информации о том, когда заказ был размещен в системе, если достаточно точности в одну минуту или одну секунду.
- По возможности используйте decimal или real, а float. Аналогично, для хранения денежных значений используйте типы данных money или smallmoney, а не float.
- Не используйте большие типы данных фиксированной длины char/binary, если только данные не заполнены всегда и не имеют статический размер.
В качестве примера рассмотрим таблицу 4, в которой показаны два варианта дизайна таблицы, хранящей информацию о местоположении.
Таблица 4. Таблица, с информацией о местоположении
| create table dbo.Locations ( ATime datetime not null, -- 8 bytes Latitude float not null, -- 8 bytes Longitude float not null, -- 8 bytes IsGps int not null, -- 4 bytes IsStopped int not null, -- 4 bytes NumberOfSatellites int not null, -- 4 bytes ) |
create table dbo.Locations2 ( ATime datetime2(0) not null, -- 6 bytes Latitude decimal(9,6) not null, -- 5 bytes Longitude decimal(9,6) not null, -- 5 bytes IsGps bit not null, -- 1 byte IsStopped bit not null, -- 0 bytes NumberOfSatellites tinyint not null, -- 1 byte ) |
| Total: 36 bytes | Total: 18 bytes |
Таблица dbo.Locations2 использует на 18 байт меньше места для хранения каждой строки данных. Это не кажется особенно впечатляющим в масштабах одной строки, однако, если система ежедневно собирает 1 000 000 местоположений, то 18 байт на строку дают экономию пространства около 18 МБ в день, и 6,11 ГБ в год. Помимо пространства базы данных, это влияет на использование памяти буферного пула, размер файла резервного копирования, пропускную способность сети и некоторые другие вещи.
В то же время с таким подходом нужно быть осторожным. Например, выбор smallint в качестве типа данных для столбца CustomerId не является правильным решением. Даже если 32 768 (или даже 65 536) клиентов кажется достаточным, то когда вы начнете доработку системы, стоимость рефакторинга кода и изменения типа данных с smallint на int может оказаться очень высокой.
Изменение структуры таблицы
Давайте рассмотрим, что происходит при изменении структуры таблицы. Существуют три различных варианта:
- Меняются только метаданные. Изменения включают удаление столбца, замену not-nullable столбца на nullable или добавление nullable столбца в таблицу.
- Меняются только метаданных, но SQL Server должен просканировать таблицу, чтобы убедиться, что значения в столбце соответствуют новому типу значения. В качестве примера можно привести изменение nullable столбца на not-nullable. Перед изменением метаданных SQL Server должен просмотреть все строки в таблице, чтобы убедиться, что в конкретном столбце не хранится значение null. Другой пример - изменение типа данных столбца на тип с меньшим диапазоном значений. Если вы измените столбец int на smallint, SQL Server должен проверить, есть ли строки со значениями, которые выходят за пределы границ smallint.
- Кроме изменения метаданных требуется изменение каждой строки данных. Примером такой операции является изменение типа данных столбца, которое требует либо другого формата хранения, либо преобразования типа. Например, когда вы изменяете столбец char фиксированной длины на varchar, SQL Server должен переместить данные из раздела строки фиксированной длины в раздел переменной длины. Другой пример - изменение типа данных char на int. В этом случае SQL Server должен физически обновить каждую строку данных в таблице, преобразуя данные.
Стоит отметить, что поведение блокировки таблицы при изменении ее структуры зависит от версии и издания. Например, корпоративная версия SQL Server 2012 позволяет добавить новый столбец с типом NOT NULL, мгновенно сохраняя информацию на уровне метаданных без изменения каждой строки в таблице. Другой пример - SQL Server 2016 добавляет возможность изменения столбцов, добавления и удаления первичных ключей в режиме онлайн, используя ту же технику, что и онлайн-перестройка индексов.
К сожалению, изменение структуры таблицы никогда не уменьшает размер строки данных. Когда вы удаляете столбец из таблицы, SQL Server не восстанавливает пространство, которое использовал столбец.
Когда вы изменяете тип данных сужая диапазон значения, например, с int на smallint, SQL Server продолжает использовать то же самой размер, что и раньше, проверяя при этом соответствие значений строк новым значениям типа данных.
Когда вы изменяете тип данных расширяя диапазон значения, например, с int на bigint, SQL Server добавляет новый столбец и копирует исходные данные в новый столбец во всех строках данных, оставляя нетронутым пространство, используемое старым столбцом.
Рассмотрим следующий пример. В листинге 18 создается таблица и проверяются смещения столбцов таблицы.
Листинг 18. Д
create table dbo.AlterDemo
(
ID int not null,
Col1 int null,
Col2 bigint null,
Col3 char(10) null,
Col4 tinyint null
);
select
c.column_id, c.Name, ipc.leaf_offset as [Offset in Row]
,ipc.max_inrow_length as [Max Length], ipc.system_type_id as [Column Type]
from
sys.system_internals_partition_columns ipc join sys.partitions p on
ipc.partition_id = p.partition_id
join sys.columns c on
c.column_id = ipc.partition_column_id and
c.object_id = p.object_id
where p.object_id = object_id(N'dbo.AlterDemo')
order by c.column_id;
На рис.20 показаны результаты запроса. Все столбцы в таблице имеют фиксированную длину. Столбец Смещение в строке указывает начальное смещение столбца данных в строке. В столбце Max Length указывается, сколько байт данных использует столбец. Наконец, столбец Column Type показывает тип данных столбца.
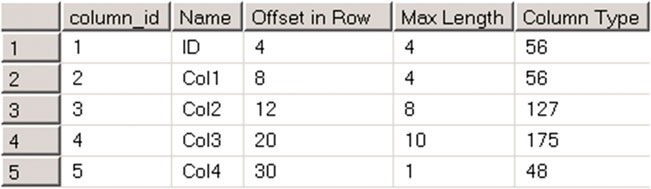
Рисунок 20. Изменение таблицы: Смещение столбцов до изменения таблицы
Теперь давайте выполним несколько изменений таблицы, как показано в листинге 19.
Листинг 19. Изменение таблицы: Модификация таблицы
alter table dbo.AlterDemo drop column Col1;
alter table dbo.AlterDemo alter column Col2 tinyint;
alter table dbo.AlterDemo alter column Col3 char(1);
alter table dbo.AlterDemo alter column Col4 int;
Если вы снова проверите смещение столбцов, вы увидите результаты, показанные на рис.21.
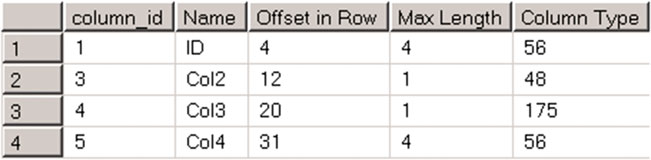
Рисунок 21. Изменение таблицы: Смещение столбцов после изменения таблицы
Несмотря на то, что мы удалили столбец Col1, смещения столбцов Col2 и Col3 не изменились. Более того, для хранения данных в столбцах Col2 и Col3 требуется всего один байт, хотя это не влияет на смещение обоих столбцов.
Наконец, было изменено смещение столбца Col4. Длина данных столбца была увеличена, и SQL Server создал новый столбец для размещения данных с новым типом значений.
До внесения изменений для хранения данных в строке требовалось 27 байт. Изменение увеличило требуемое пространство для хранения до 31 байта, хотя фактический размер данных составляет всего 10 байт. 21 байт дискового пространства на строку расходуется впустую.
Единственный способ восстановить пространство - это перестроить таблицу кучи или кластеризованный индекс.
Если вы перестроите таблицу с помощью команды ALTER TABLE dbo.AlterDemo REBUILD и снова проверите смещение столбцов, вы увидите результаты, показанные на рис.22.
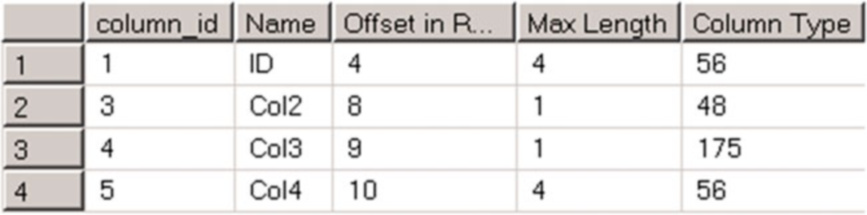
Рисунок 22. Изменение таблицы: Смещение столбцов после перестройки таблицы
Как вы можете видеть, перестройка таблицы возвращает неиспользуемое пространство из строк.
Также изменение таблицы накладывает блокировку модификации схемы (SCH-M) на таблицу. Это делает таблицу недоступной для другого сеанса на время изменения.
Резюме
SQL Server хранит данные в базах данных, которые состоят из одного или нескольких файлов журнала транзакций и одного или нескольких файлов данных. Файлы данных объединяются в файловые группы. Файловые группы абстрагируют файловую структуру базы данных от объектов базы данных, которые логически хранятся в файловых группах, а не в файлах базы данных. Следует рассмотреть возможность создания нескольких файлов данных для любых файловых групп, в которых хранятся часто изменяемые данные.
SQL Server всегда заполняет журналы транзакций нулями во время восстановления базы данных и при автоматическом росте файла журнала. По умолчанию он также заполняет нулями файлы данных, если не включена мгновенная инициализация файлов. Мгновенная инициализация файлов значительно сокращает время восстановления базы данных и делает автоматический рост файлов данных мгновенным. Однако мгновенная инициализация файлов связана с небольшим риском для безопасности, поскольку неинициализированная часть базы данных может содержать данные из ранее удаленных файлов ОС. Тем не менее, рекомендуется включить мгновенную инициализацию файлов, если такой риск является приемлемым.
SQL Server хранит информацию на 8-микилобайтных страницах данных, объединяемых в экстенты. Существует два типа экстентов. Смешанные экстенты хранят данные из разных объектов. В однородных экстентах хранятся данные, принадлежащие одному объекту. SQL Server хранит первые восемь страниц объектов в смешанных экстентах. После этого при распределении пространства объектов используются только однородные экстенты. Следует включить флаг трассировки T1118, чтобы предотвратить распределение пространства смешанных экстентов и уменьшить количество страниц карт распределения.
SQL Server использует специальные страницы карты для отслеживания распределений в файле. Существует несколько типов карт распределения. Страницы GAM отслеживают, какие экстенты выделены. Страницы SGAM отслеживают доступные смешанные экстенты. Страницы IAM отслеживают экстенты, которые используются единицами распределения на уровне объектов (разделов). PFS хранит несколько атрибутов страницы, включая свободное пространство, доступное на странице, в таблицах кучи и в страницах переполнения строк и LOB.
SQL Server хранит фактические данные в строках. Существует два различных вида типов данных. Типы данных фиксированной длины всегда используют одно и то же пространство для хранения данных, независимо от значения, даже если оно NULL. При хранении данных переменной длины используется фактический размер значения данных.
Часть строки фиксированной длины и служебные данные должны помещаться на одной странице данных. Данные переменной длины могут храниться на отдельных страницах данных, таких как страницы переполнения строки и LOB, в зависимости от фактического размера и типа данных.
SQL Server считывает страницы данных в кэш памяти, называемый буферным пулом. Когда данные изменяются, SQL Server синхронно записывает запись в журнал транзакций. Он сохраняет измененные страницы данных асинхронно во время процесса создания контрольной точки и lazy writer.
SQL Server является приложением с интенсивным вводом-выводом, и уменьшение количества операций ввода-вывода помогает повысить производительность систем. Полезно уменьшить размер строк данных за счет использования оптимальных типов данных. Это позволяет поместить больше строк в страницу данных и уменьшает количество страниц данных, обрабатываемых во время операций сканирования.
При изменении таблиц нужно быть осторожным, т.к. при этом никогда не уменьшается размер строк. Неиспользуемое пространство строк можно вернуть, перестроив таблицу или кластеризованный индекс.
--------------------------------
При написании статьи использовались материалы книги Дмитрия Короткевича «Pro SQL Server Internals» (2 изд. 2016 г.)
Вступайте в нашу телеграмм-группу Инфостарт