Выгоды OpenSource
Итак, зачем использовать OpenSource в целом и Linux в частности?
Я намеренно не собираюсь затрагивать вопросы денег и открытого исходного кода, мне просто хочется рассказать, какие преимущества при использовании альтернативных OpenSource-инструментов открылись лично мне:
- Первое из этих преимуществ заключается в том, что в мире OpenSource и открытых исходников нет и быть не может версий программ с ограниченной функциональностью и подобными искусственными ограничениями. Как правило, общедоступные в OpenSource разработки будут одинаково вести себя как на учебном (или тестовом стенде), так и в продуктиве.
- Второй плюс, который я для себя открыл – это то, что использование альтернативных инструментов, как ни крути, заставляет нас повышать свои собственные компетенции и взглянуть на выполнение наших задач несколько иначе.
В использовании OpenSource-программ, конечно, есть и минусы:
- То, что нужно поменять подход к решению задач – это одновременно и плюс, и минус.
- На пути к цели вам нужно будет четко понимать, что вы хотите сделать и как это сделать.
- Найти решение методом «тыка», скорее всего, не получится – вам неизбежно придется некоторое время потратить на поиск и изучение материалов.
Это те затраты, которые потребует использование альтернативных инструментов.
Но здесь есть нюанс:
- Можно платить на регулярной основе вендору коммерческого ПО.
- А можно вкладывать средства в повышение компетенции собственных специалистов, а уже они, следуя инженерному подходу, будут автоматизировать рутинные операции, такие как настройка и обслуживание инфраструктуры; подготовка тестовых площадок, автоматическое тестирование создаваемых продуктов.

В этом случае использование OpenSource-продуктов поможет научиться инженерному подходу:
- Сами продукты бесплатны и общедоступны, их можно легко скачать и попробовать.
- Так как исходные коды доступны, есть возможность изучить внутренности, посмотреть, как это работает (или не работает), применить эти возможности на своих проектах и при желании что-то к этому добавить.
Это к вопросу обмена компетенциями.
Несколько слов об эффективности – я всегда готов агитировать за автоматизацию рутины: сделал что-то руками два раза подряд, подумай, как это можно автоматизировать.
- Можно использовать для автоматизации какие-то bat-ники, shell, cmd-скрипты.
- Но лучше реализовать автоматизацию на более высоком уровне – такую, как на слайде.
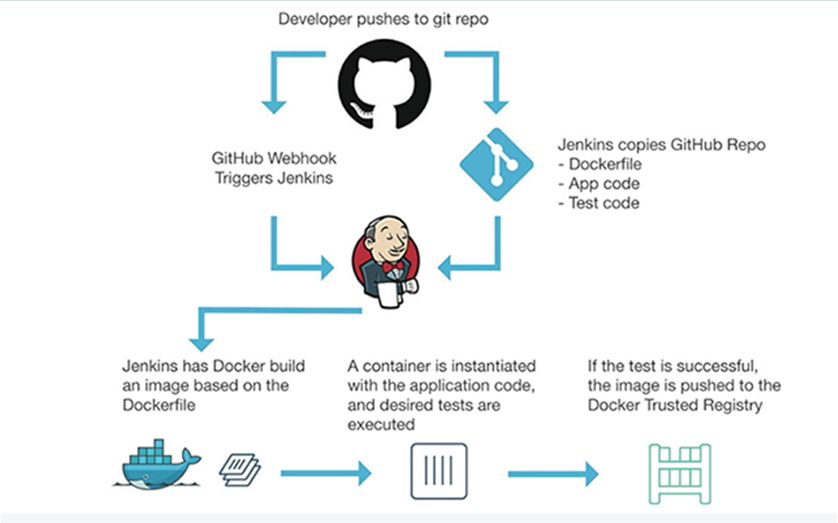
Это все, что я хотел сказать про идеологию.
Инфраструктура
Теперь про конкретные инструменты и то, где их можно использовать.
Вот всем известная картинка, где показана типовая схема инфраструктуры при работе с кластером серверов 1С.
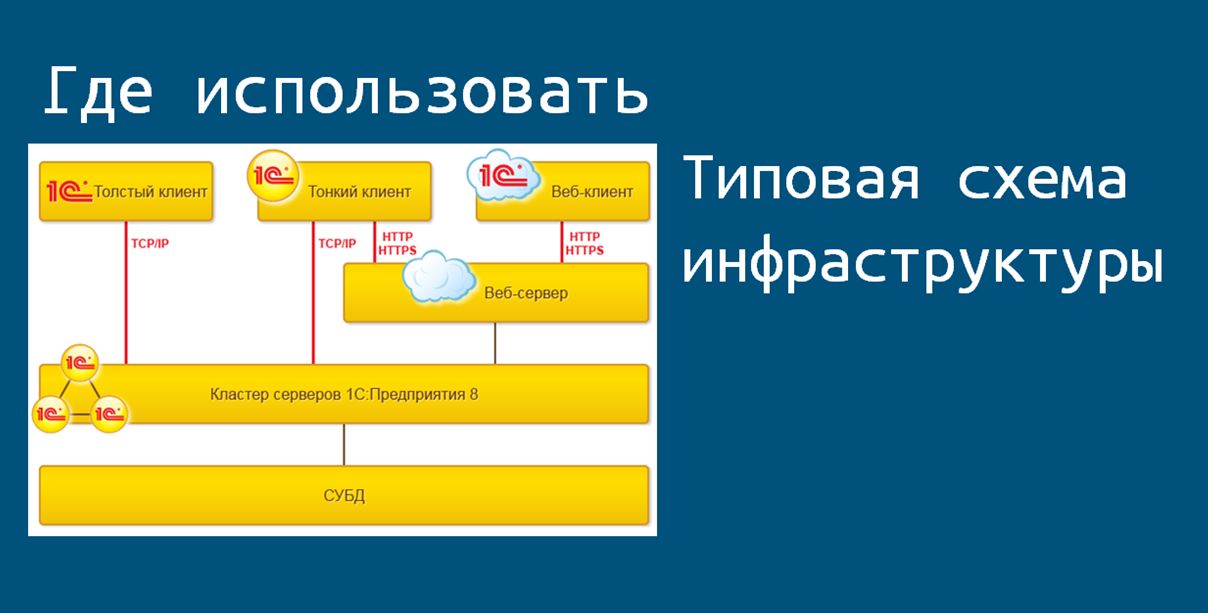
Какие составляющие этой схемы мы можем перевести на платформу Linux?
Оставим в стороне рабочие станции пользователей, пусть они работают на Windows, как привыкли (хотя и здесь есть примеры успешного перехода). И остановимся на серверном ПО – использование альтернативной платформы в этой области, как правило, наименьшим образом может повлиять на работу любимых бухгалтеров.

Развернем эту схему горизонтально и рассмотрим ее в разрезе конкретных используемых OpenSource-разработок. Здесь мы видим только один слой, где находится продуктивное окружение.
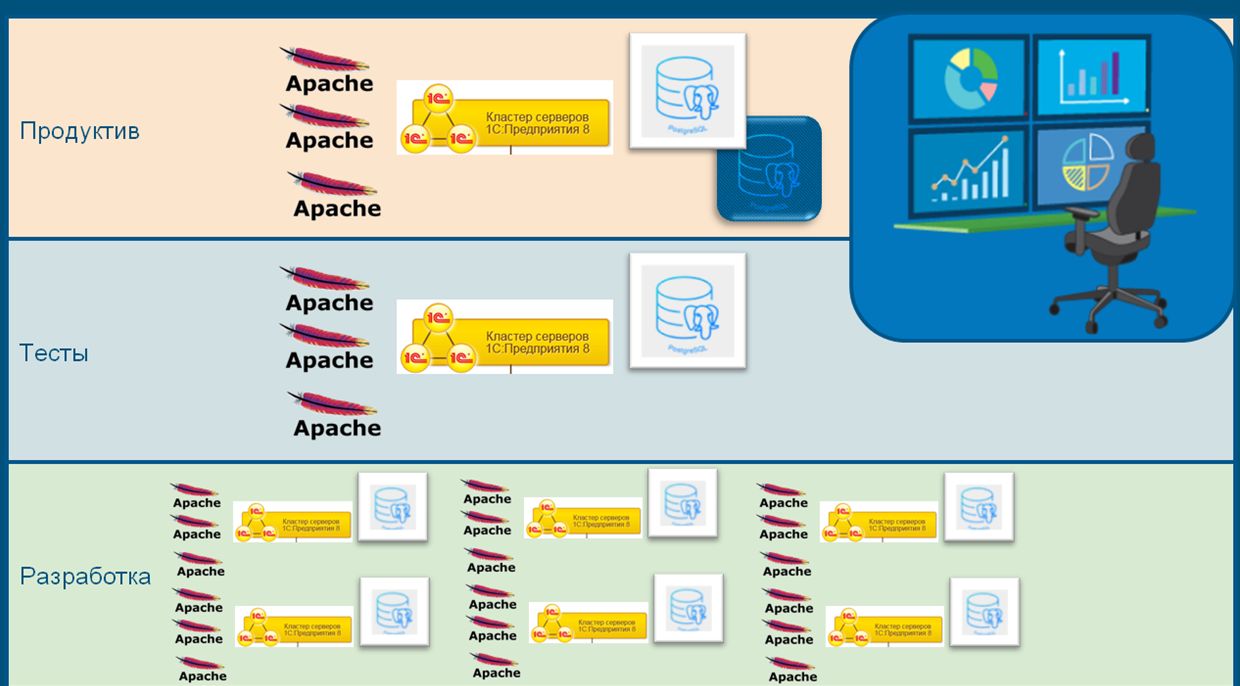
Но в реальности слоев гораздо больше:
- Есть еще и тестовое окружение, где производится приемочное тестирование.
- Также у каждого разработчика есть отдельная «песочница», где он может проводить эксперименты и работать, не мешая остальным.
- И еще неплохо бы все эти слои покрыть мониторингом и сбором статистики.
Соответственно, на выходе мы получаем несколько типов используемого ПО. Давайте по порядку их рассмотрим.
Виртуализация
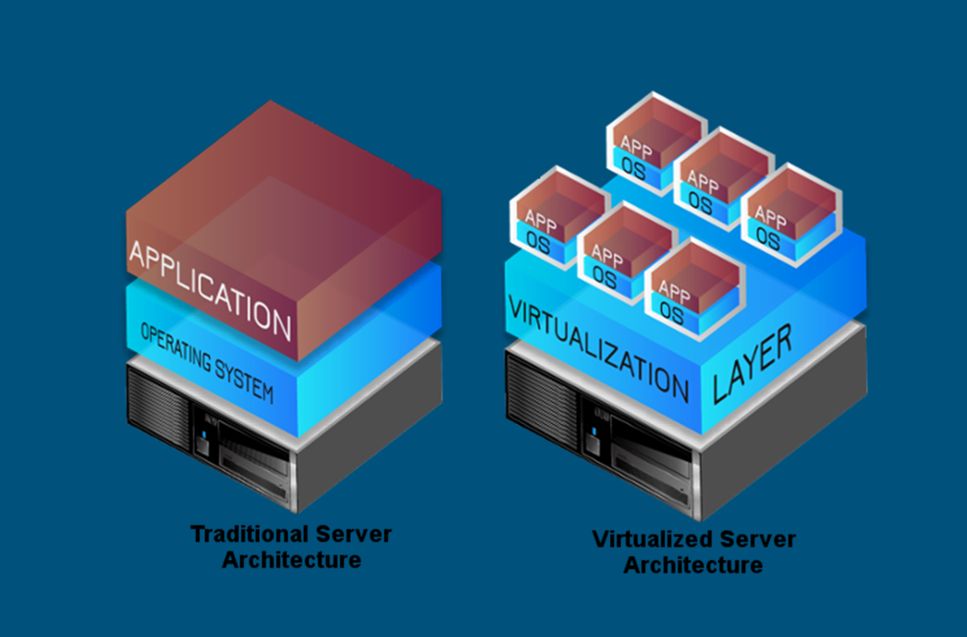
Начнем с самого нижнего уровня – с голого железа.
Сейчас повсеместно наблюдается тренд по использованию виртуализации – с этим можно даже, наверное, не спорить. Мы виртуализацию используем.

Есть большой выбор OpenSource-продуктов, которые можно попробовать и, если не страшно, внедрить у себя в Production.
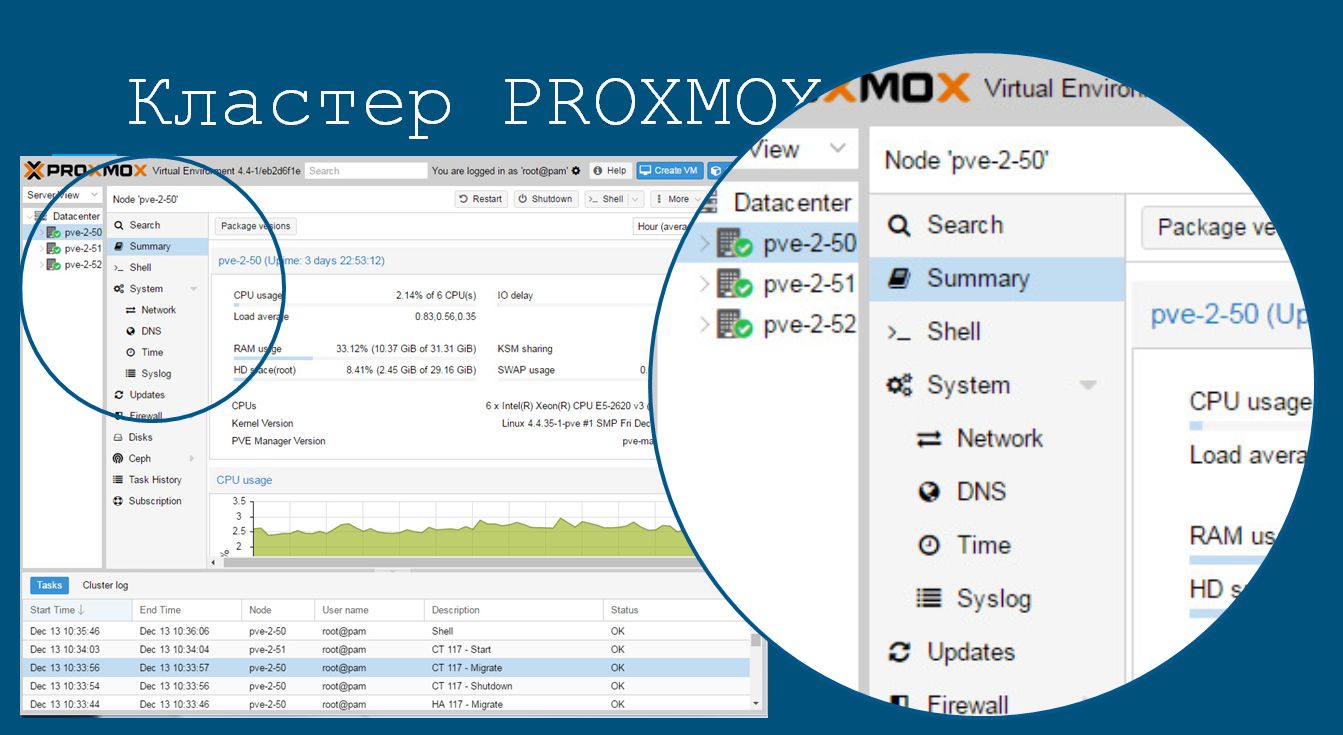
Для быстрого развертывания кластера виртуальных серверов можно взять дистрибутив Proxmox. Его установка на один узел занимает около 15 минут, умножаем на количество необходимых узлов и прибавляем еще минут 30 на настройку кластера. При этом лист аппаратной совместимости у Proxmox шире аналогов.
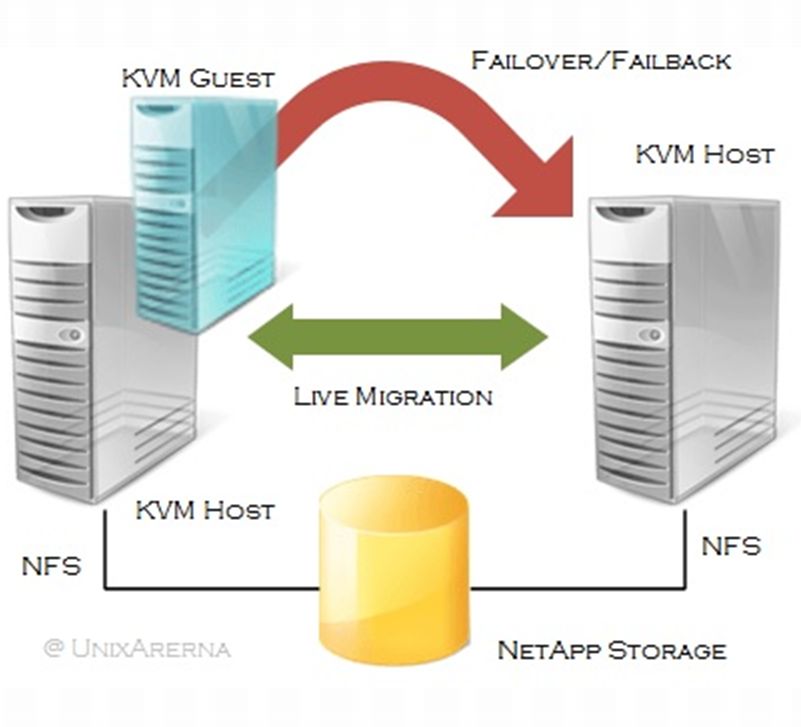
После перевода рабочих серверов в виртуальную среду процесс их обслуживания сводится к миграции виртуальных машин с одной аппаратной «железки» на другую практически без прерывания работы, возможно даже в режиме безостановочной миграции. Proxmox это умеет.
Виртуальные машины позволят вам не переживать при возникновении проблем с оборудованием: особенно это касается решений с использованием программных лицензий, которые привязываются к оборудованию. И такие лицензии есть не только у 1С.
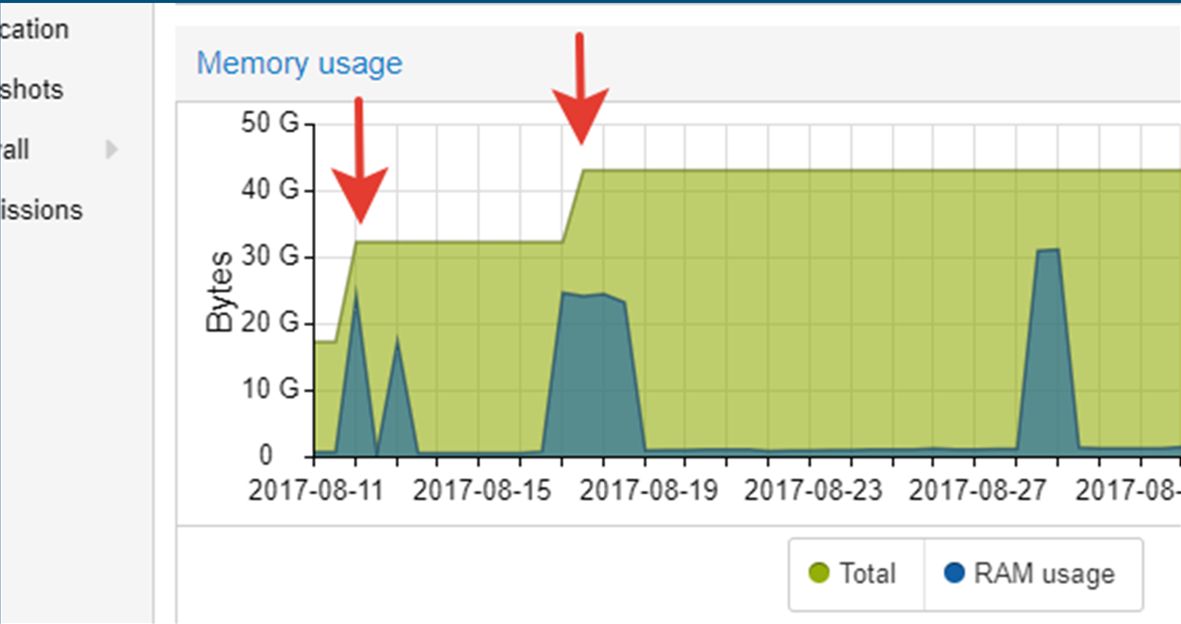
Есть еще одна интересная особенность – это возможность увеличения ресурсов, отдаваемых приложению, «на лету», без остановки работы. Это в Proxmox также доступно «из коробки», все работает.
Конфигурационное управление

Несколько слов об управлении рабочими серверами в Production.
Скрипты bat, shell – это, конечно, здорово, но если бы с ними не было проблем, то SCM-системы (системы управления конфигурациями) не получили бы такое большое распространение.
Существует множество SCM-систем, доступных на основе той или иной открытой лицензии. Наибольшее распространение среди них получили те, что представлены на слайде. Это:
- Представители «второй волны» систем управления конфигурациями – Chef, Puppet.
- А также представители «третьей волны» – Ansible и SaltStack.
Каждая последующая «волна» появляется, как ответ на несовершенства предыдущей.
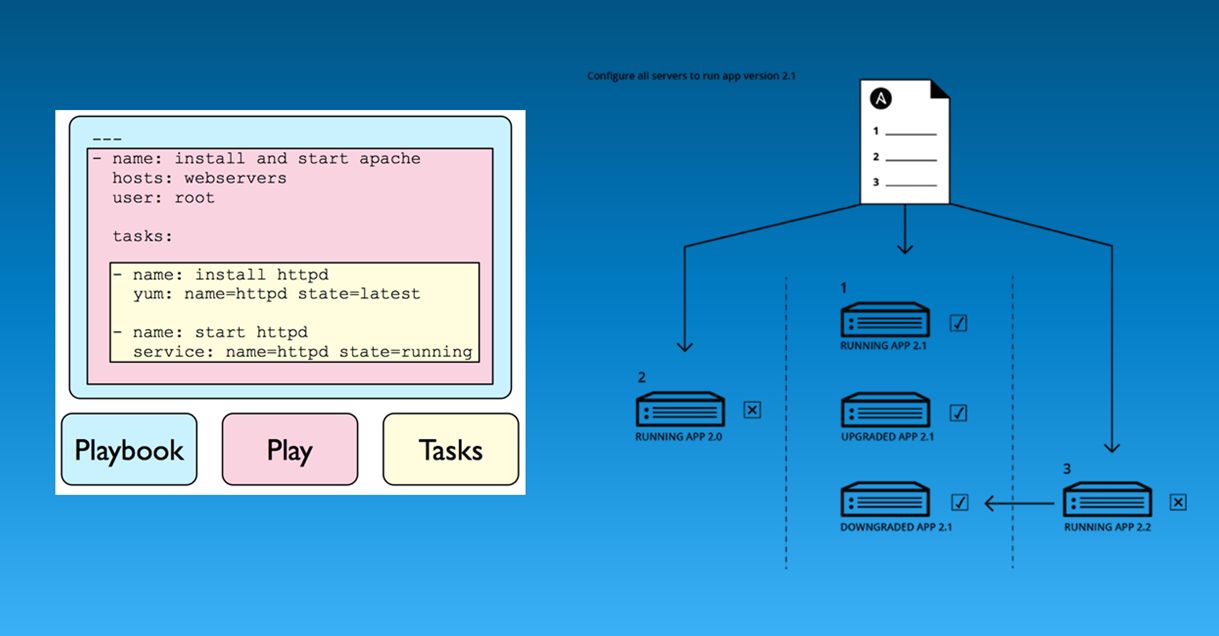
Отдельно хочу немного рассказать про Ansible.
- Он задумывался как простой ответ более сложным SCM-системам. Его главное преимущество – он крайне прост в освоении и имеет низкий порог входа.
- Второе его преимущество – на управляемые хосты не нужно устанавливать никаких агентов, никакого дополнительного ПО.
- В Ansible мы в некотором Playbook просто описываем то требуемое состояние или те команды, которые нам нужны. Пример со слайда выше: установим web-сервер последней версии и запустим его службу.
- И потом эту настройку мы можем применить как для одного сервера, так и для десятка или даже тысячи серверов.
Основной посыл такой: нужно обеспечить работающий сервис, имея только резервную копию данных, голое железо и описание конфигурации.
Рабочие серверы
Сервер приложений 1С
Переходим к рабочим серверам – непосредственно к серверу 1С.

Чтобы система управления конфигурации могла взаимодействовать с сервером 1С, обязательно создаем и запускаем службу RAS-сервера удаленного администрирования «1С:Предприятия».
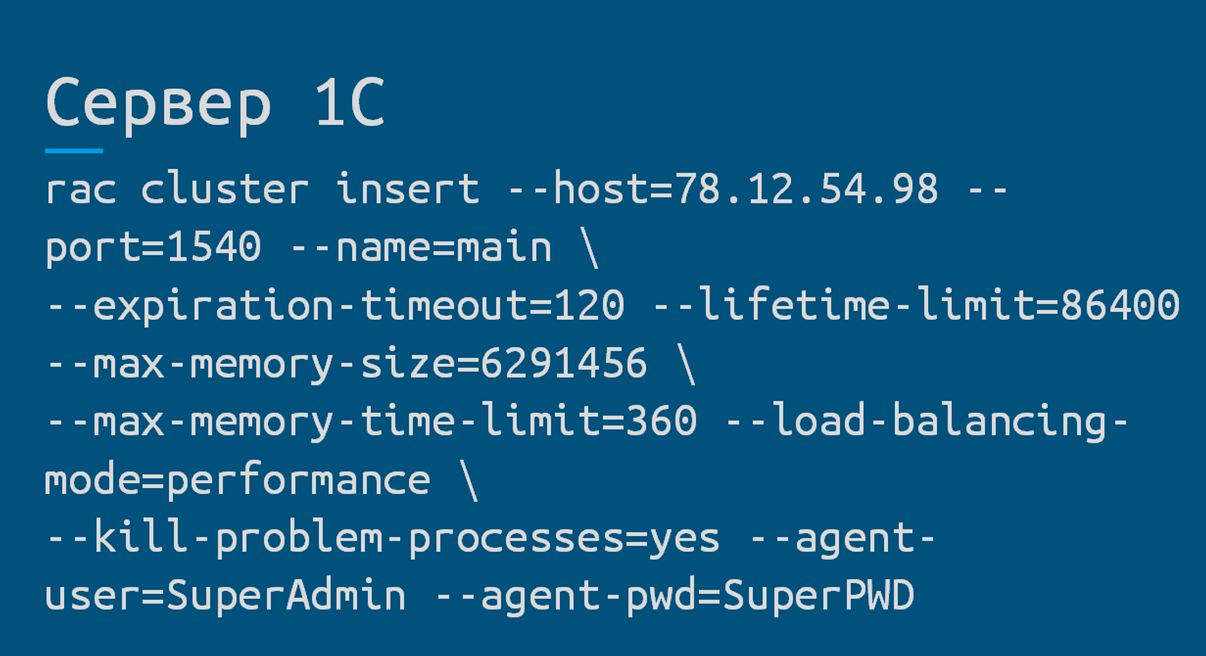
После этого в SCM-системе выполняем настройки кластера, вызывая команду, аналогичную показанной на слайде.
А фирме «1С» хочу сказать отдельное спасибо, что не забывают про ленивых системных администраторов и реализовывают возможность автоматизации управления.
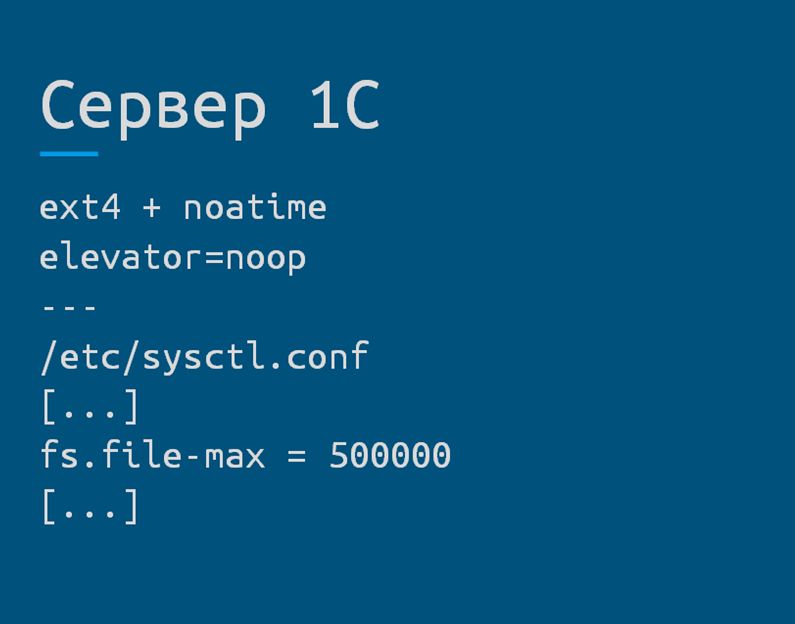
Чтобы не столкнуться с узким местом в значениях «по умолчанию» нужно внимательно посмотреть показатели операционной системы Linux:
- Тип используемой файловой системы и опции ее монтирования;
- Какой используется планировщик запросов;
- Настройки ядра по умолчанию.
При необходимости эти показатели нужно изменить, чтобы не упереться в «бутылочное горлышко».
Сервер СУБД
Переходим к серверу баз данных. С ним все немного проще – тут выбор не так велик.
В качестве сервера СУБД используем PostgreSQL, а точнее сборку от компании PostgresProfessional.

Настройка под конкретные задачи выполняется с помощью онлайн-утилиты PgTune от Алексея Васильева. В его книге «Работа с PostgreSQL» есть рекомендация: «Использовать настройки по умолчанию в PostgreSQL крайне не рекомендуется, нужно всегда делать настройки под конкретное программно-аппаратное обеспечение». В принципе это справедливо для многих ИТ-продуктов.
На слайде показан интерфейс PgTune. С помощью этой утилиты вы можете привести конфигурацию сервера PostgreSQL в соответствие с выделенными аппаратными ресурсами и расчетной рабочей нагрузкой.
В диалоговом окне этой утилиты нужно указать:
- Исходные параметры вашей системы;
- Количество выделяемой оперативной памяти;
- Ожидаемое максимальное количество клиентских соединений.
На выходе получаем готовый конфигурационный файл.

Также можно воспользоваться рекомендациями на портале ИТС – они будут примерно такие же, как и в сервисе PgTune.
В настройки операционной системы, помимо тех рекомендаций, которые были для сервера приложений, можно добавить настройки работы с памятью. В частности:
- Для версий PostgreSQL > 9.4 можно включить поддержку больших страниц памяти;
- Также следует обратить внимание на параметры работы с «грязными» страницами и файлом подкачки.
Веб-сервер
Теперь по тюнингу веб-сервера.
- На текущий момент максимальная поддерживаемая версия Apache для 1C – 2.4. Соответственно, если используется 2.2, надо бы уже поменять.
- Для использования параллельной обработки запросов нужно обязательно включить режим worker (вместо prefork) и настроить его:
- MaxClients – указываем исходные данные по расчетной нагрузке (те же самые, что и для Postgres);
- GZIP – включаем сжатие;
- KeepAlive – включаем ожидание соединений.
Если про ожидаемую нагрузку пока что ничего не известно, обратимся к собранной статистике работы или настроим логирование операций, чтобы выставить окончательное значение позже. О том, как это сделать, я покажу в блоке анализа.
Резервное копирование
Сейчас нужно не потерять данные – поэтому перейдем к разделу резервного копирования.
PostgreSQL позволяет выполнять три типа резервного копирования:
Первый тип – это pg_dump, полный дамп кластера серверов, либо отдельной базы. Он подходит для редко изменяющихся баз, где безопасная глубина потери данных может доходить до суток и более. В топе выдачи поисковых систем, вы, как правило, увидите примеры именно такого типа резервного копирования.
Чаще всего для его использования предлагаются различные консольные команды и прочая, не сразу понятная магия. Однако для этого типа резервного копирования есть достаточно удобный менеджер с графическим интерфейсом – это PostgreSQL Backup. Также можно использовать такие консольные программы, как PgBackMan и UrBackup. Они тоже упрощают работу с этим типом резервного копирования.
Второй тип резервного копирования – это pg_basebackup, физический бэкап файлов БД. В этом случае у нас уже появляется возможность копировать только изменения, делать инкрементальное резервное копирование. Но этот, как и предыдущий тип резервного копирования, имеет недостаток в том, что глубина потери данных, особенно с большими базами, все равно еще достаточно велика – сутки и более.
Если же на проекте требуется что-то более серьезное и нужно обеспечить минимально возможную потерю данных, используется встроенный механизм PostgreSQL – стратегия непрерывной архивации и восстановление на конкретный момент времени (point in time recovery – PITR). В этом случае глубина потери данных будет стремиться к нулю.

Для того чтобы упростить настройку непрерывной архивации PITR есть инструмент PgBarman (PostgreqsSQL Backup And Recovery Manager).
Он позволяет:
- Выполнять настройку архивации;
- В автоматическом режиме отслеживать изменения;
- Выполнять архивацию в соответствии с принятой стратегией резервного копирования;
- Следить за выполнением архивации.

- А также позволяет реализовать восстановление:
- На конкретный момент времени;
- На конкретную транзакцию;
- На конкретную метку (если была сделана метка бэкапа).
Анализ логов
С бэкапами разобрались. Переходим к анализу логов.

Настройка логов требует отдельной большой обзорной статьи, но если коротко – то логи нужны независимо от используемого типа ПО. Их можно и нужно анализировать.
Логирование лучше не выключать, тем более что сервер баз данных и сервер приложений позволяют получить очень подробный вывод в лог-файл о своей работе именно.
Давайте посмотрим, как можно анализировать логи.
Набор «Инструменты разработчика»
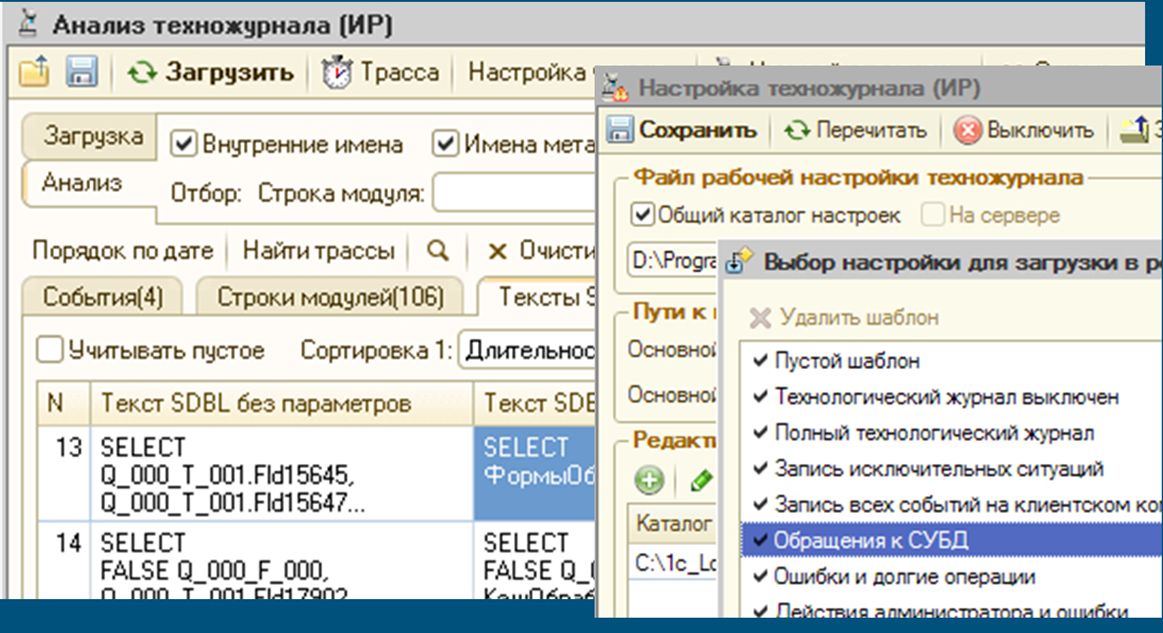
Существует такой замечательный набор «Инструменты разработчика». В нем есть как минимум две кнопки, которые будут полезны администраторам. Это:
- Настройка технологического журнала;
- И анализ технологического журнала.
Для оперативного расследования проблем, чтобы быстро выявить какие-то проблемные запросы и что-то еще, эти инструменты подойдут как нельзя лучше.
Стек ELK
Если нужно провести более серьезный анализ поведения в системе, берем стек ELK, и настраиваем на рабочих серверах ротацию журналов и их архивацию.

Отмечу, что классически для работы с логами используется Logstash, но его клиент достаточно тяжеловесный в этом стеке, поэтому от тех же разработчиков, компании Elastic, был выпущен легковесный набор клиентов Beats, которые работают гораздо быстрее и занимают крошечное количество ресурсов (около 0,5 Мб оперативной памяти).
А для удобного отображения результатов анализа есть инструмент Grafana, к которому в качестве источника подключается база ElasticSearch, откуда могут быть выведены какие-либо данные.
PgHero

Для оперативного анализа проблем на уровне СУБД можно взять инструмент PgHero, который на основе собранной внутренней статистики сервера СУБД PostgreSQL в режиме алертов выведет ключевые показатели и покажет самые проблемные места:
- Здесь не хватает такого-то индекса;
- Здесь длинный запрос – надо посмотреть туда-то.
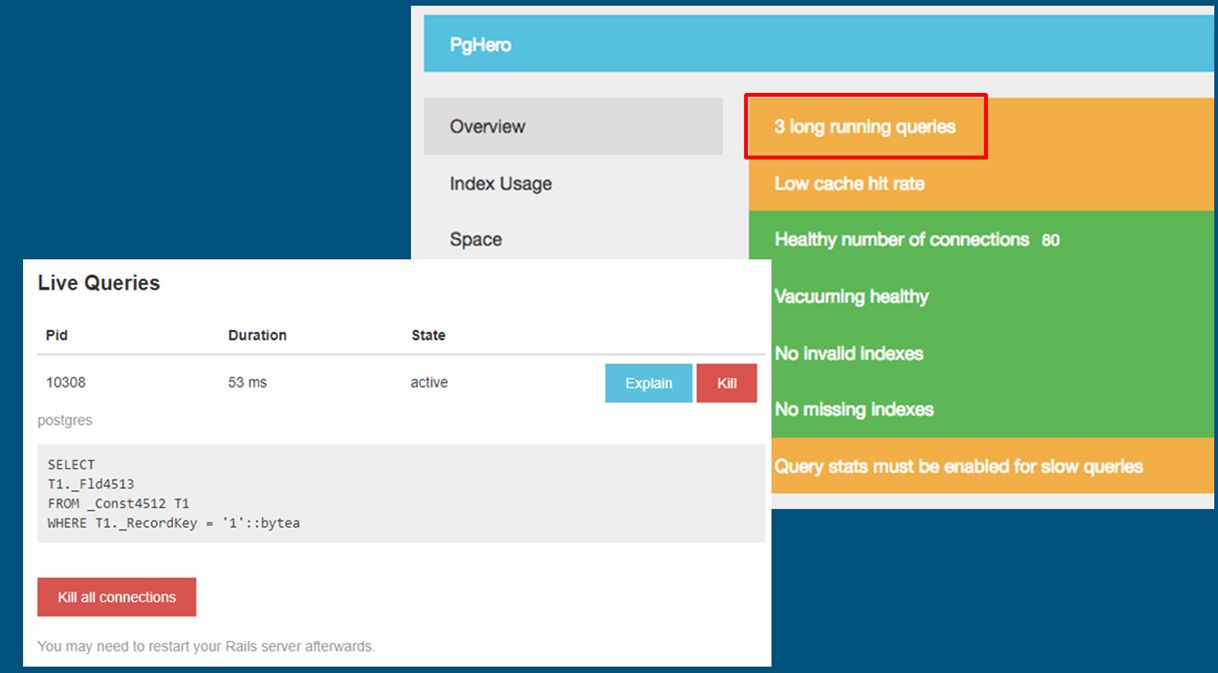
При использовании этого инструмента приходит понимание, где в базе беда и куда нужно посмотреть более пристально.
POWA
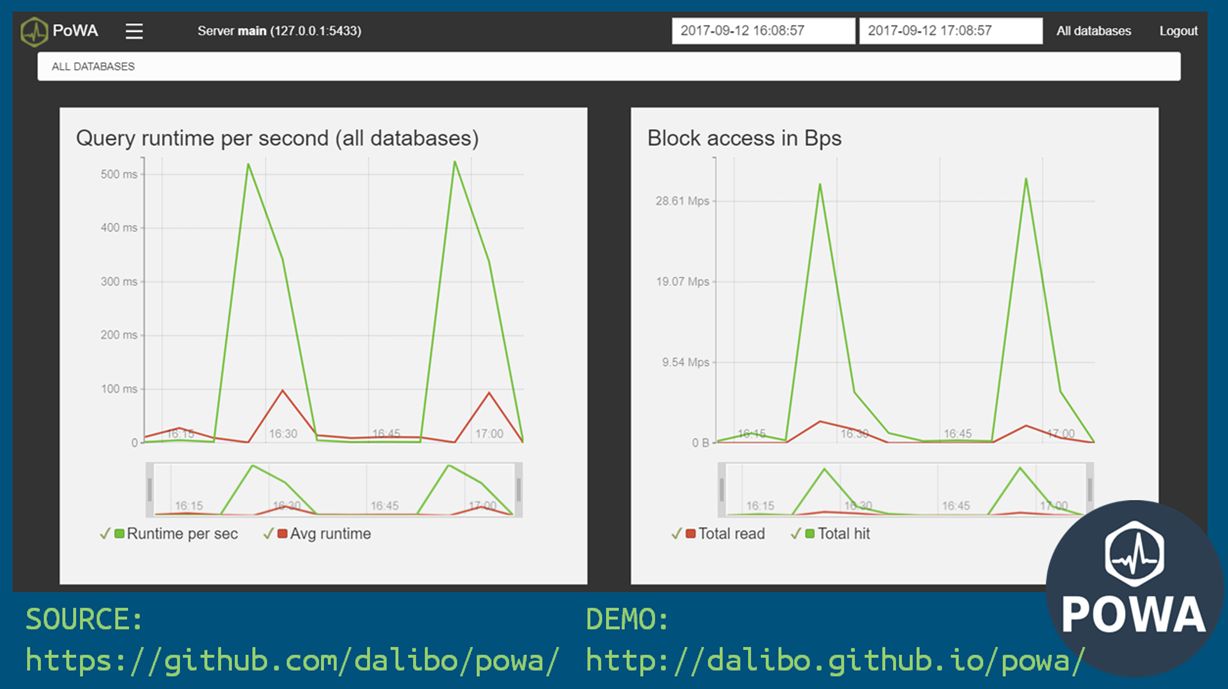
Для анализа динамики показателей работы за период удобно использовать графический инструмент POWA – он также показывает блокировки и длительные запросы.
HypoPG
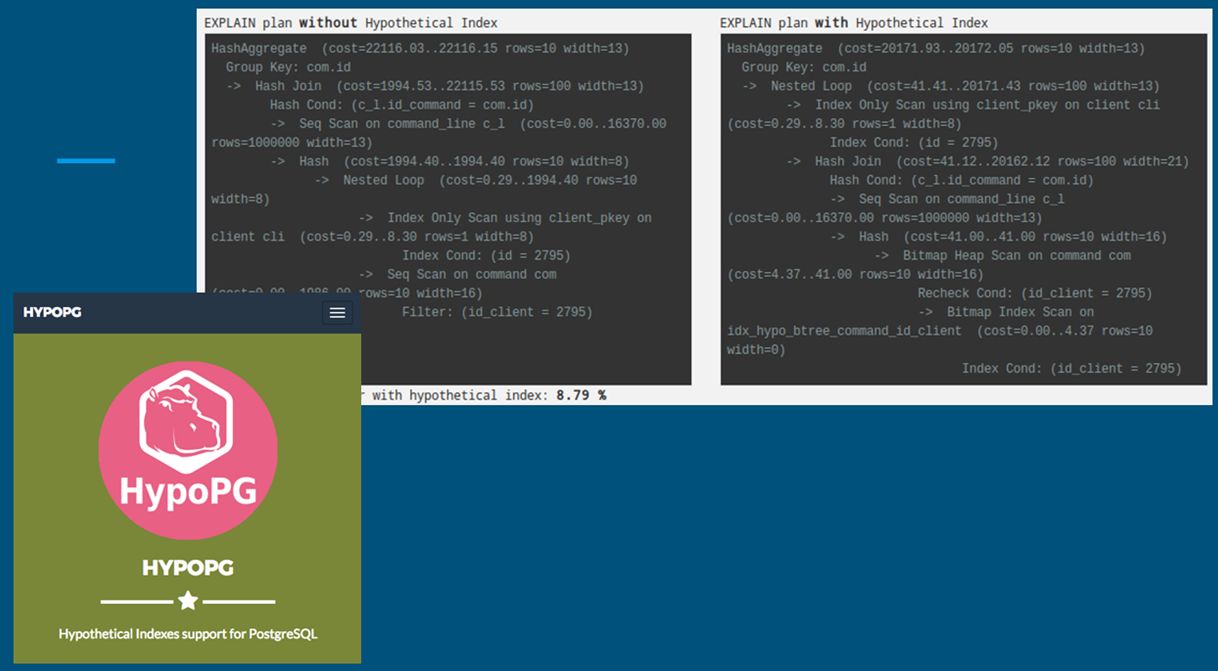
С помощью расширения HypoPG в процессе выполнения запросов сервером СУБД производится их анализ, и составляются рекомендации по созданию недостающих индексов, которые могут существенно ускорить выполнение запроса.
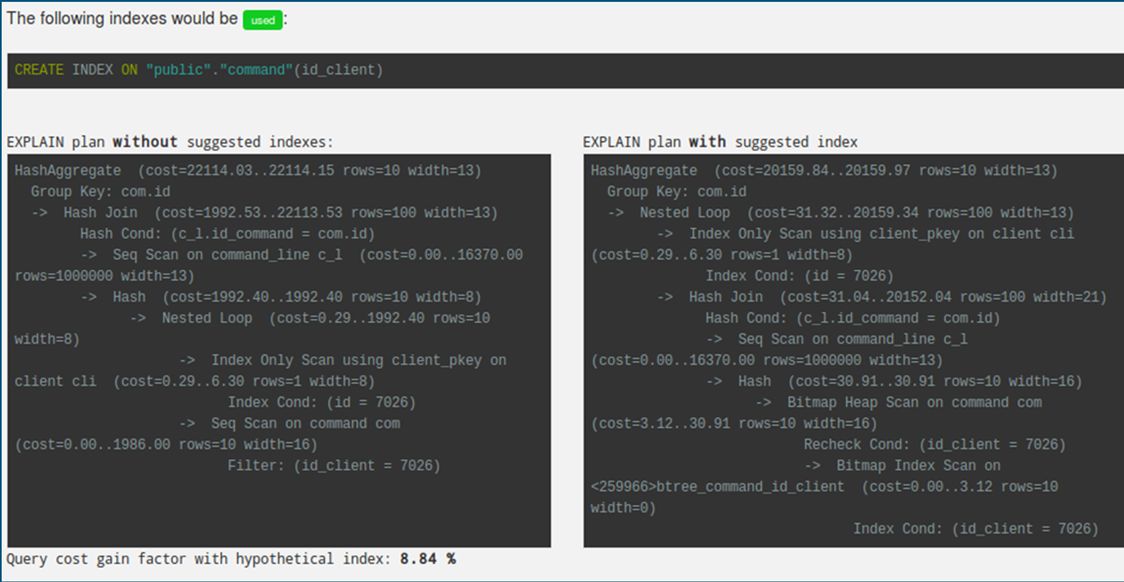
Сразу же выдается предложение рассчитать показатели с учетом добавленного индекса. Самое важное, что этот индекс не создается, а только предварительно рассчитывается. Соответственно, нет тяжелой операции записи на диск. На слайде показано, как выглядит расчет для предлагаемого индекса.
pgBadger
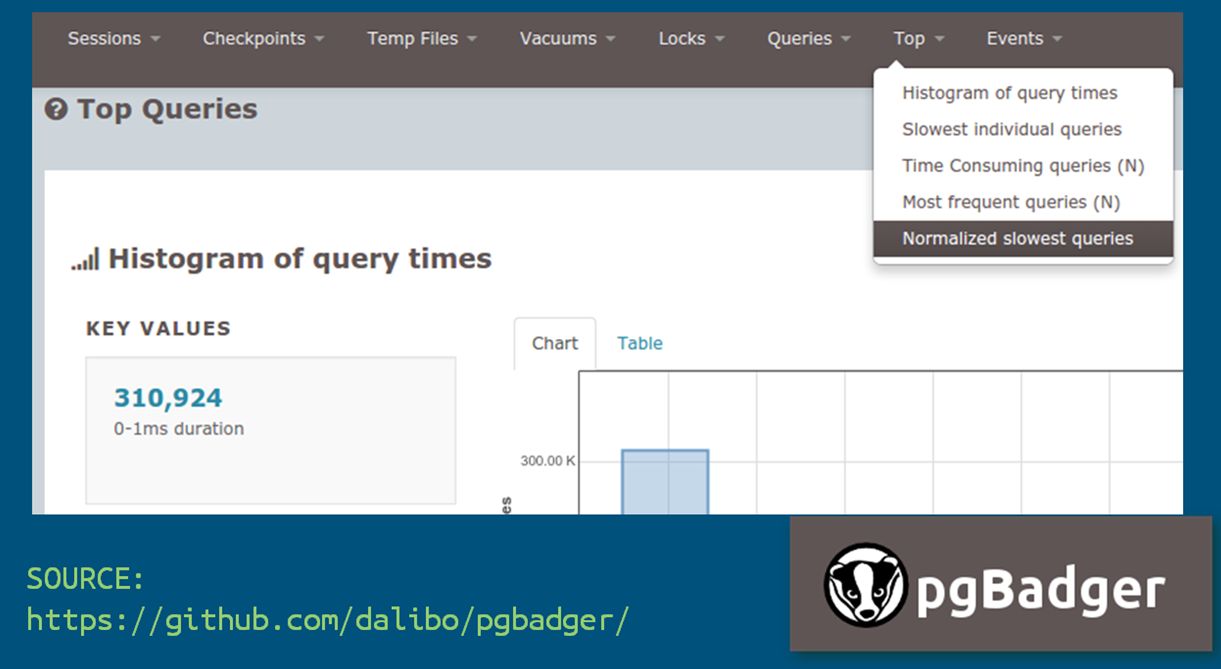
Еще один инструмент – pgBadger показывает агрегированную статистику, полученную на основе логов работы с СУБД. Его данные могут быть использованы для расследования поведения сервера в длительном периоде. Формируется страничка HTML, на которой можно выбирать период и смотреть, анализировать.
Специализированные инструменты анализа логов от 1С
Конечно, для анализа работы платформы есть специальные инструменты от самой фирмы «1С» – все о них знают. Но они имеют два минуса:
- Эти инструменты платные;
- Они требуют определенной компетенции.
Счетчики и уведомления

Еще один существенный недостаток у специализированных инструментов – в них нельзя получить агрегированную статистику по всему ландшафту, включая инфраструктуру и сетевые соединения.
Для этого собираем различные метрики и на основании показателей счетчиков настраиваем уведомления о проблемах (по содержимому, по общему состоянию). Это позволит нам «спать спокойно», вернее, просыпаться от SMS-сообщения о том, что назревает проблема, а не от звонка руководителя, спрашивающего, почему встала работа.
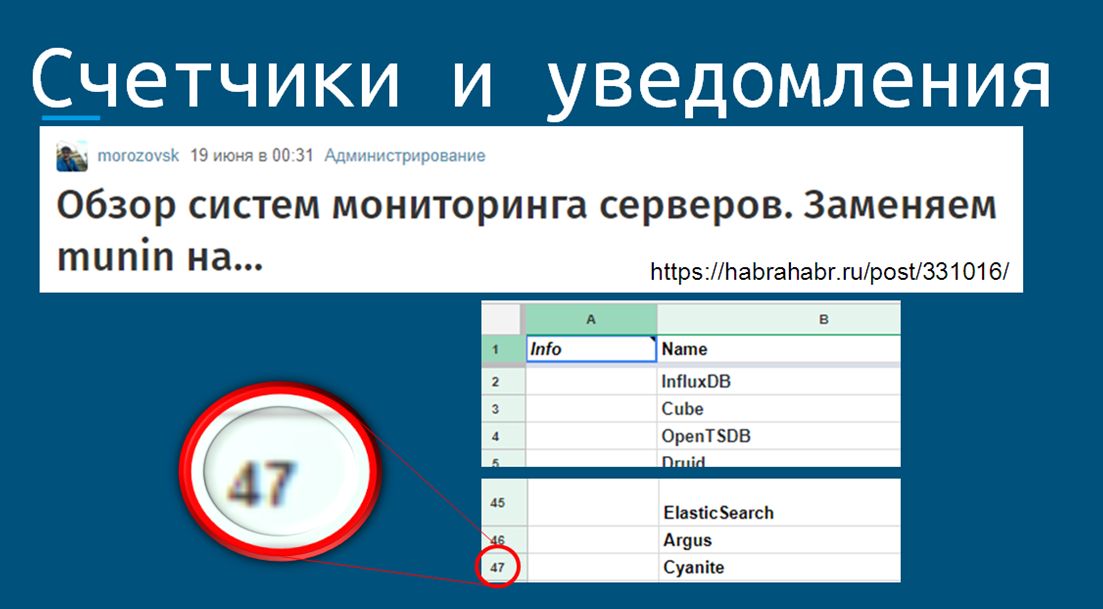
Для работы с этими счетчиками и уведомлениями существует большое количество OpenSource-систем мониторинга. Их многообразие создает проблему выбора. Недавно на Хабре вышла статья «Летний обзор OpenSource-систем мониторинга». Их набралось 47 штук. Чтобы выбрать что-то конкретное под себя – нужно постараться.
Zabbix
Я давно работаю с системой Zabbix (с версии 1.8). Соответственно, и мониторинг я предпочитаю тоже заводить на него.
Zabbix – это кроссплатформеная система мониторинга, которая обладает огромными возможностями по аналитике и уведомлениям пользователя. У нее есть документация на русском языке, и разработчики тоже русскоговорящие.
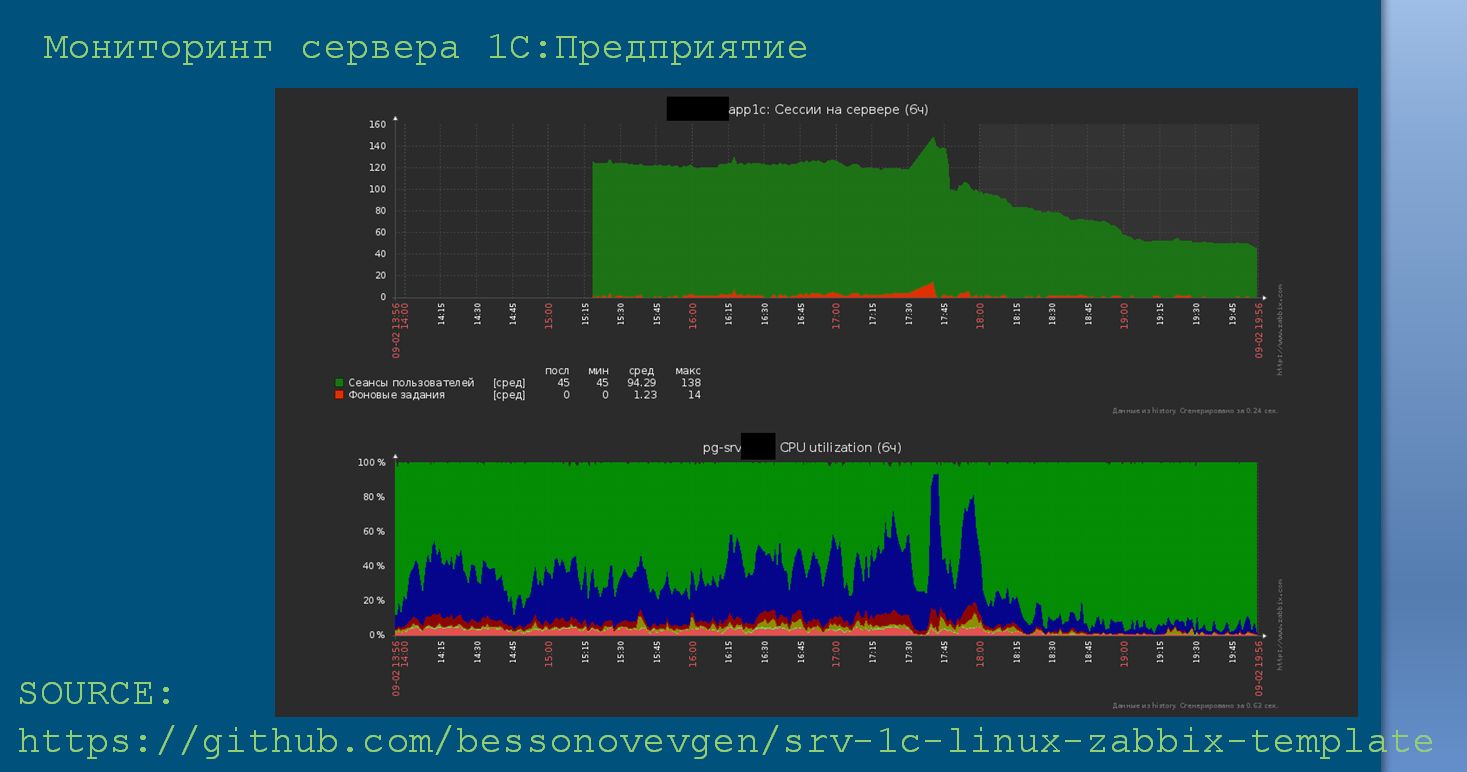
Для мониторинга сервера приложений 1С я создал репозиторий, в котором есть пример конфигурационного файла и готовый шаблон для импорта в Zabbix.
- Взаимодействие агента мониторинга и сервера приложений 1С обеспечивает сервер удаленного администрирования.
- Используется загрузка уведомлений по событиям.
- Проект доступен на GitHub.
- Порядок работы следующий:
- Настраиваете свой сервер приложений;
- При необходимости добавляете в шаблон свои метрики;
- Получаете по ним значения и историю.
Чтобы вручную не настраивать множество узлов для мониторинга, у Zabbix есть инструменты автообнаружения. А также, когда необходимо сделать какой-то более сложный мониторинг, можно воспользоваться возможностями встроенного API.
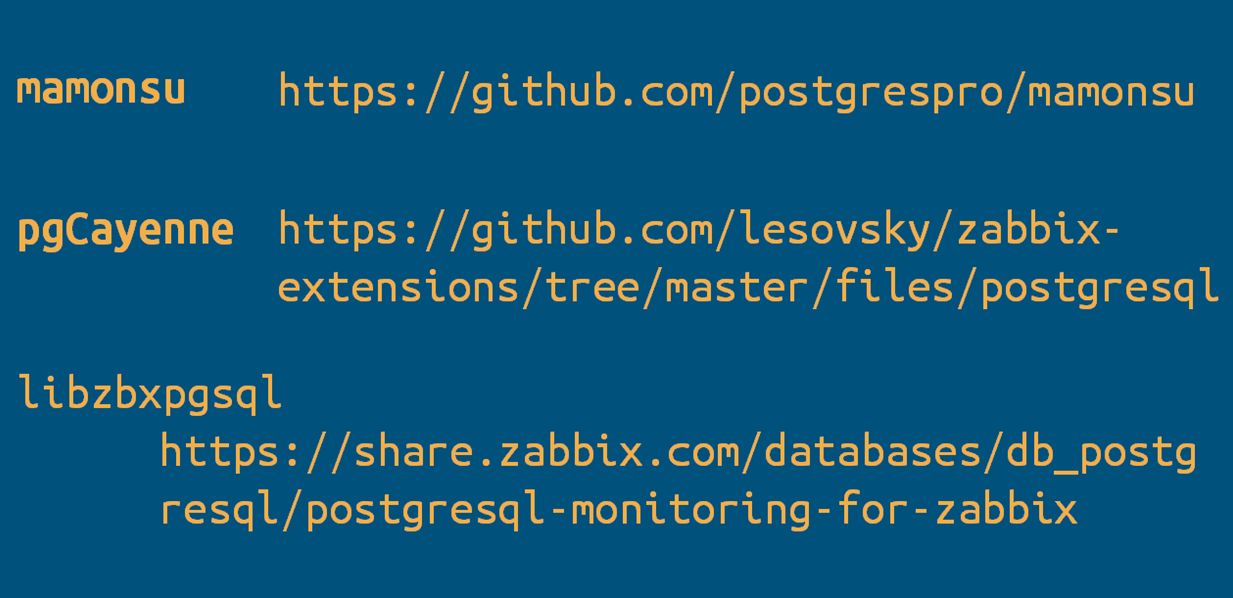
Для Zabbix есть готовые шаблоны по мониторингу сервера СУБД PostgreSQL:
- mamonsu от компании PostgresProfessional;
- pgCayenne;
- libzbxpgsql;
- И множество других готовых шаблонов, которые можно будет загрузить и настроить по ним уведомления (мониторинг).
Проблемы при переездах

При переходе организации с Windows на альтернативную платформу могут возникнуть некоторые проблемы. Они особенно обостряются, если в совершенно другую среду переводится все «скопом» – сервер СУБД, сервер приложений и, не дай Бог, рабочие станции. В этом случае взаимное влияние особенностей может дать грандиозный эффект синергии и породить множество проблем, о которых даже не подозревают.
Поэтому при переходе на использование альтернативных инструментов всегда нужно:
- Провести планирование того, как все это будет происходить.
- Обязательно организовать какую-то тестовую площадку, на которой проверять поведение системы при новых условиях.
- Сам перевод серверов на Linux можно сделать в два этапа – сначала перевести сервер СУБД, затем – сервер приложений.
- При переводе сервера приложений могут возникнуть проблемы из-за использования каких-либо решений, которые завязаны на Windows. Переделка таких механизмов может потребовать большое количество времени и ресурсов.
- После этого делаются уже окончательные расчеты стоимости перевода всего ландшафта из Windows в Linux. В различных ситуациях может потребоваться разная детализация расчетов.
Другими словами, примерный план перехода следующий:
- Планирование;
- Настройка тестового окружения;
- Проверка поведения системы;
- Корректировка изначального плана;
- Расчет стоимости.
В процессе переезда возникает еще и глобальная проблема – это нежелание специалистов изучать новое. Гораздо привычнее делать так, как всегда делали. Понятно, что выход из зоны комфорта может не приносить большой радости в процессе, но результаты, как мы знаем, могут быть очень интересные.
Заключение

И в заключение я хочу сказать, что в принципе неважно, на какой платформе работать и какое программное обеспечение использовать. Важно делать это продуманно, используя инженерный подход. Работать должны системы, а люди должны организовать этот процесс.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2017 COMMUNITY.

Вступайте в нашу телеграмм-группу Инфостарт