



Часть первая, художественная.
Вступление
История решения проблемы, с которой ежедневно сталкивается разработчик 1С при решении прикладных задач, связанных с оперативным учетом на предприятии.
Для начала определимся с тем, что такое оперативный учет. Оперативный учет, проще говоря, это когда решения на основе предоставляемых системой данных принимаются здесь и сейчас. Где нет "пометить на удаление" и "отменить проведение". Где вся структура учета строится исключительно из потребностей бизнеса без учета ПБУ, НК и проч-проч-проч.
Такие решения не очень популярны на сегодняшних день на платформе 1С, но тем не менее, потихоньку набирают обороты и, надеюсь, будут только шириться.
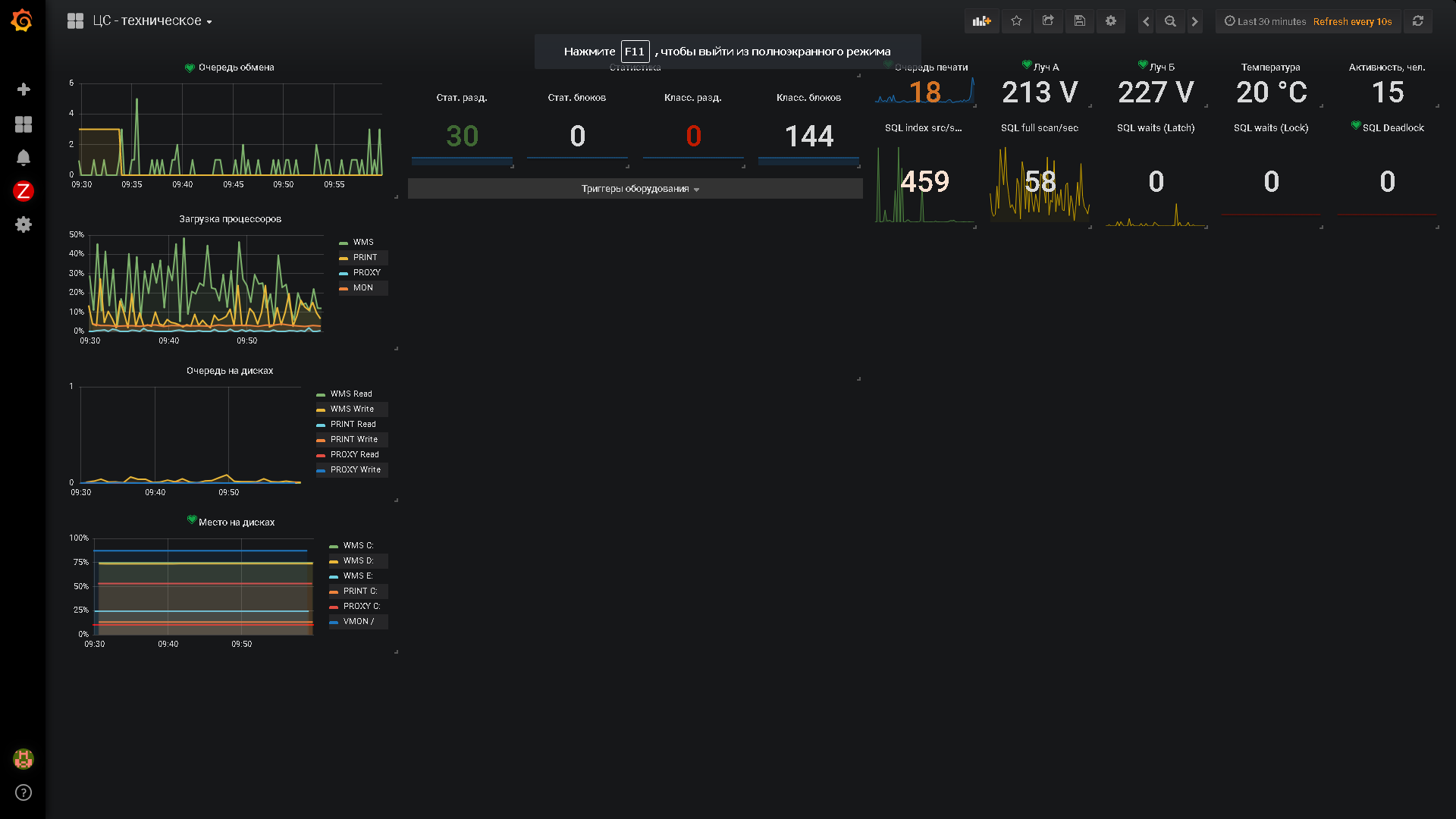
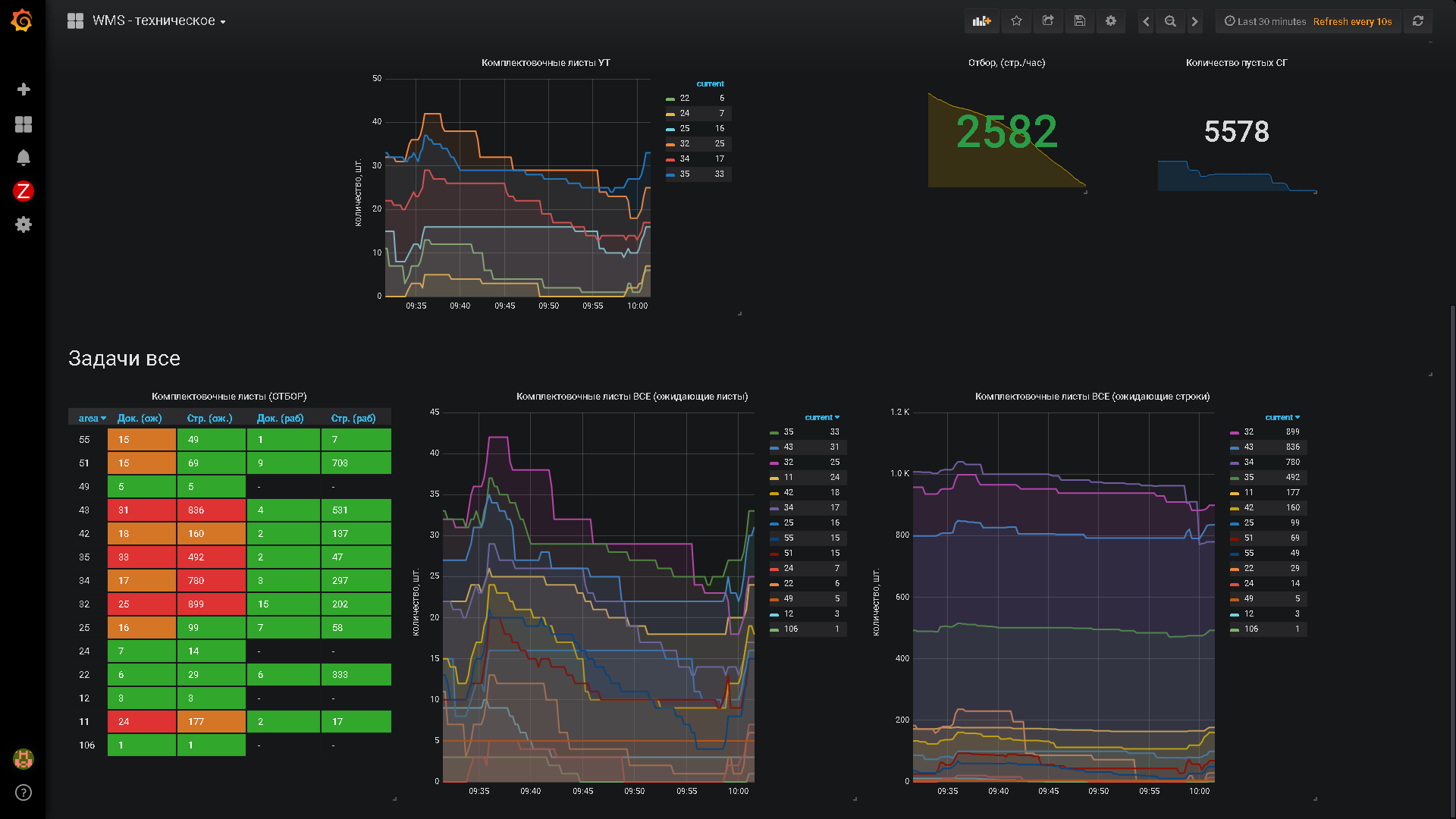
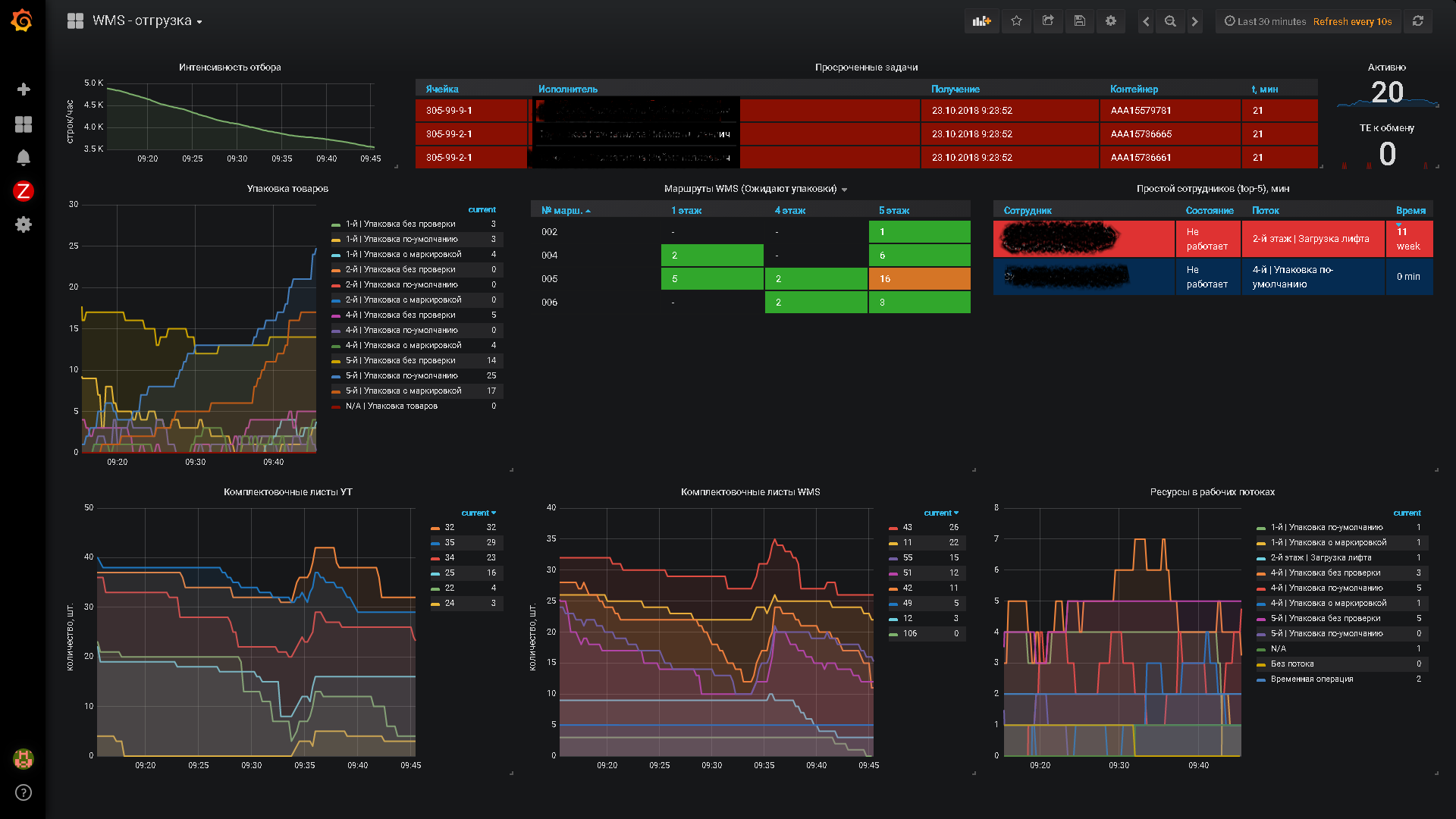
Самый простой пример оперативного учета - это складская деятельность при достаточно высоком уровне автоматизации склада. Высоким уровнем автоматизации давайте договоримся считать способность системы принимать решения и отдавать задачи исполнителям в режиме on-line. Подобный подход продемонстрирован компанией Axelot в конфигурации 1С:WMS Логистика. Управление складом.
В рамках разработки таких систем узким местом является сбор и наглядное представление данных для принятия управленческих решений и при контроле за исполнением задач в силу высокой динамики изменения входных данных.
Стандартные отчеты плохо подходят наличием кнопки "Сформировать" и весьма скромными графическими возможностями.
Разнообразные варианты форм с автообновлением по обработчикам ожиданий весьма прилично нагружают систему при мало-мальски существенном объеме выводимой информации.
Хочется чего-то легкого, красивого и понятного...
Завязка
К предлагаемому варианту решения проблемы подтолкнула, как не странно, квалификация инженеров на проекте. В рамках крупного проекта ежедневно приходится сталкиваться не только с проблемным поведением 1С, блокировками на СУБД, кривым кодом и нелепыми бизнес-процессами. Есть еще основа всего этого - локальная сеть с кучей оконечного оборудования. Начиная от свитчей и заканчивая терминалами сбора данных. А если копнуть еще глубже - то и у энергоснабжающих организаций бывают проблемы. И все это заканчивается банальным: "1С не работает".
В современных реалиях существует огромное множество систем мониторинга оборудования. Но у нас ее не было. И с нее пришлось начать. На первом этапе - завели Zabbix, начали собирать статистику со всего до чего смогли дотянуться. Потом потребовалось собирать данные с удаленных филиалов. И снова Zabbix, но расположенный на другом сервере и нам доступный только read-only. А потом возникло желание видеть данные единовременно с обоих серверов мониторинга. И тут на помощь пришла совершенно потрясающая платформа для мониторинга и аналитики - Grafana.
Лирическое отступление первое
После настройки системы мониторинга и выводом информации о жизненно важном аппаратном слое системы, жить на проекте стало несколько легче. Шишки перестали падать с такой частотой и с таких высот.
Однако решение проблем административного персонала было в зачаточном состоянии. Управление многоэтажным складом посредством отчетов и полубумажной технологией делало несчастными администраторов.
Попытки построения системы мониторинга процессов на внешних обработках делало несчастными разработчиков и сервер с СУБД.
А чувство прекрасного продолжало настойчиво требовать легкости и понятности.
Кульминация
По результатам созерцания аккуратных метрик в Grafana логично была предпринята попытка вытащить туда данные напрямую из 1С. Благо, есть плагин, позволяющий дергать данные непосредственно с помощью JSON. При обновлении дашбордов с метриками раз в 10 секунд (ибо отказы железа по-прежнему хочется видеть оперативно), начала проседать база 1С. Попытки выливать данные в Zabbix и работать от него закончились порванным бубном и стесанной до кости сушеной заячьей лапкой.

Начали подбирать варианты. Взгляд адепта красно-желтой литературы, отринув мысли о MSSQL и Postgree, начал обращаться в направлении сторонних продуктов. И после череды проб и ошибок остановился на проекте Prometheus.
Лирическое отступление второе
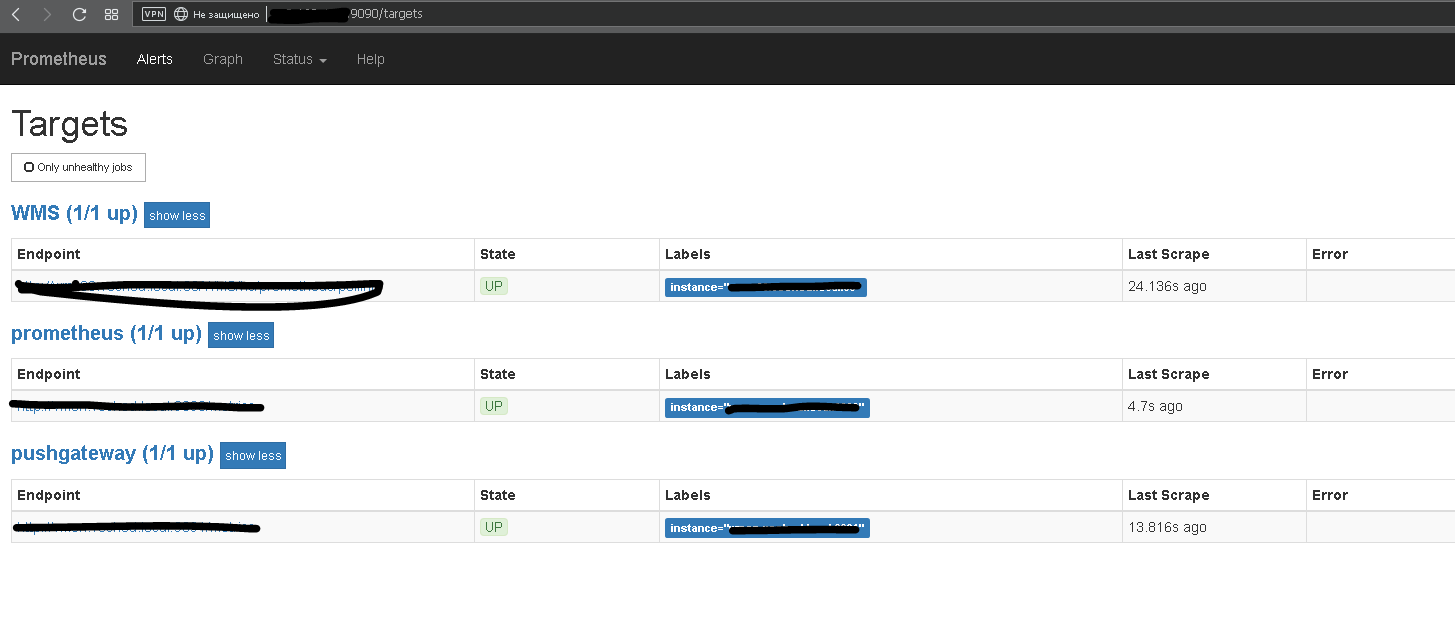
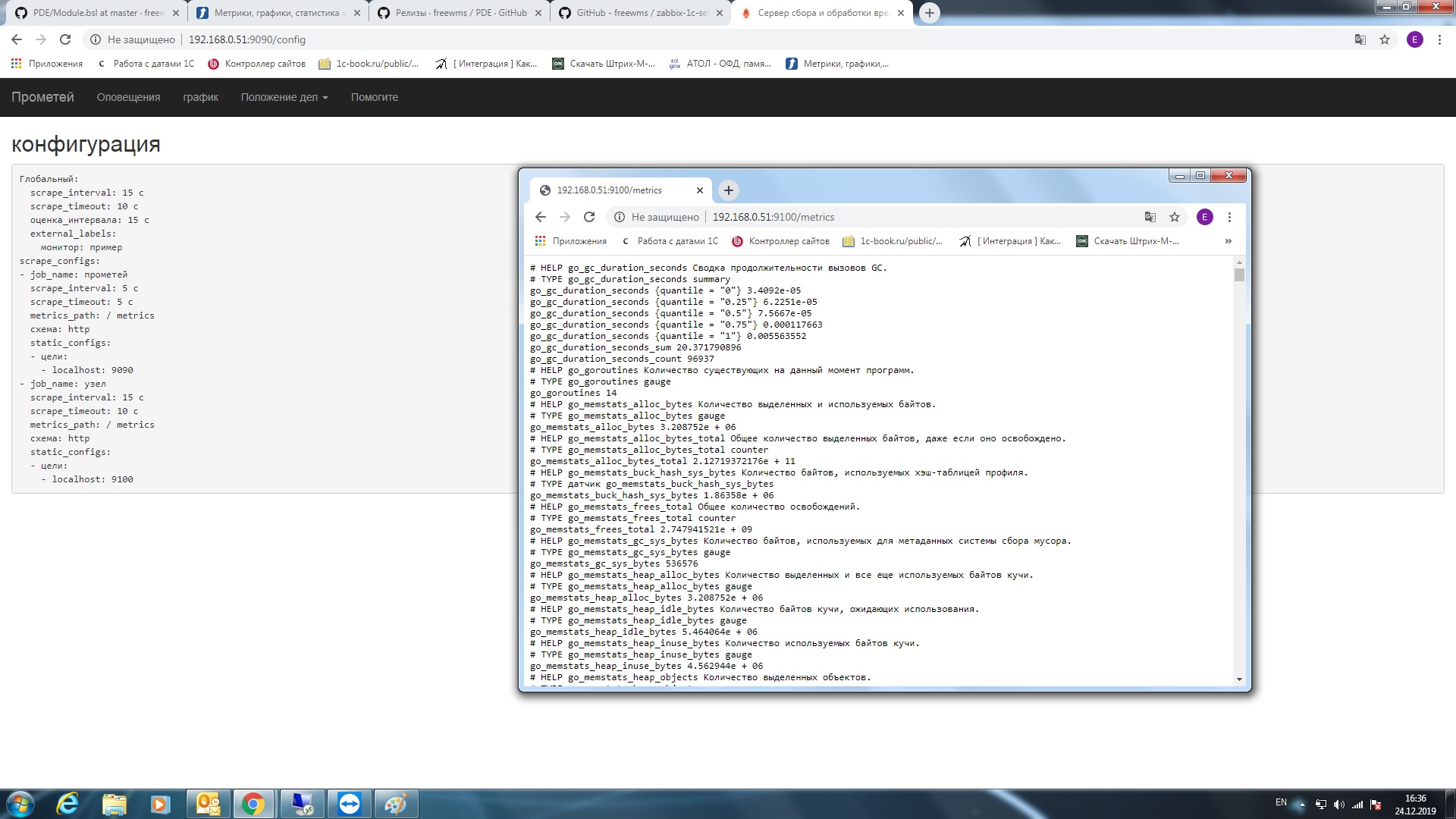
Prometheus - это, грубо говоря, TSDB (Time series database) - база данных формата NoSQL, организованная для хранения временных рядов, т.е. метрик. Плюс весьма неплохой ассортимент внешних плагинов для сбора данных. Плюс автоочистка истории. Плюс весьма скромные системные требования. Важное различие сборщиков метрик - это разделение на т.н. "pull" сборщиков - которые сами куда-то стучатся и требуют выдать им метрики и "push" сборщики, которые сидят и ждут, что к ним постучатся и принесут данные на блюдечке. Prometheus - pull сборщик, но при использовании плагина Pushgateway становится способен работать и в режиме push. В этом режиме отправка данных инициируется клиентом плагину, которого, в свою очередь, опрашивает Prometheus. И все это добро, как у нас принято, абсолютно free!
В терминах платформы Prometheus, сбор данных называется "scrape" - "соскоб". Т.е. берется срез данных на момент времени, ему присваивается timestamp (время взятия соскоба) и данные убираются в собственное хранилище Prometheus. Одно из выгодных отличий Prometheus является необязательность присвоения timestamp'а при отправке пакета с данным. При отсутствии метки времени присвоение происходит автоматически при помещении данных в базу Prometheus.
Чувству прекрасного для экстаза не хватало только понятности.
Развязка
Понятность пришла после конструирования подсистемы, обеспечивающей формирование метрик простыми кодом на родном языке.

Источником данных по-прежнему является 1С, однако хранение данных осуществляется в сторонней базе, а сбор данных происходит "соскобами", исключающими запросы с большой глубиной периода. "Соскобы" осуществляются двумя способами:
1) При построении данных статистики, необходимой для принятия решений (а мы помним - оперативный учет, да) происходит непосредственный push при самом выполнении регламентов или операций, что не требует повторного обращения к регистрам, да и вообще ничего больше не требует, поскольку сформированные метрики больше не касаются 1С.
2) Для съема метрик по фактически занесенным данным в результате жизнедеятельности пользователей, используется pull метод, когда регламентным заданием снимается срез данных (условно - остатки, не обороты) и заботливо подготовленные метрики ожидают запроса от Prometheus.
Обоими способами снятые метрики отправляются на хранение в Prometheus, откуда их читает Grafana с нужной периодичностью и с нужными временными границами.


Часть вторая, техническая, теоретическая.
Предлагаемый механизм связки с Prometheus является абсолютно бесплатным, никаких ограничений на модификацию кода нет и быть не может.
Решение собрано отдельной конфигурацией для удобства слияния с рабочей базой. Существование как отдельной конфигурации не имеет практического смысла, поскольку предназначено для извлечения метрик из непосредственно рабочих данных. Однако, конфигурация может быть развернута отдельно для препарирования и изучения - в таком режиме она полностью работоспособна.
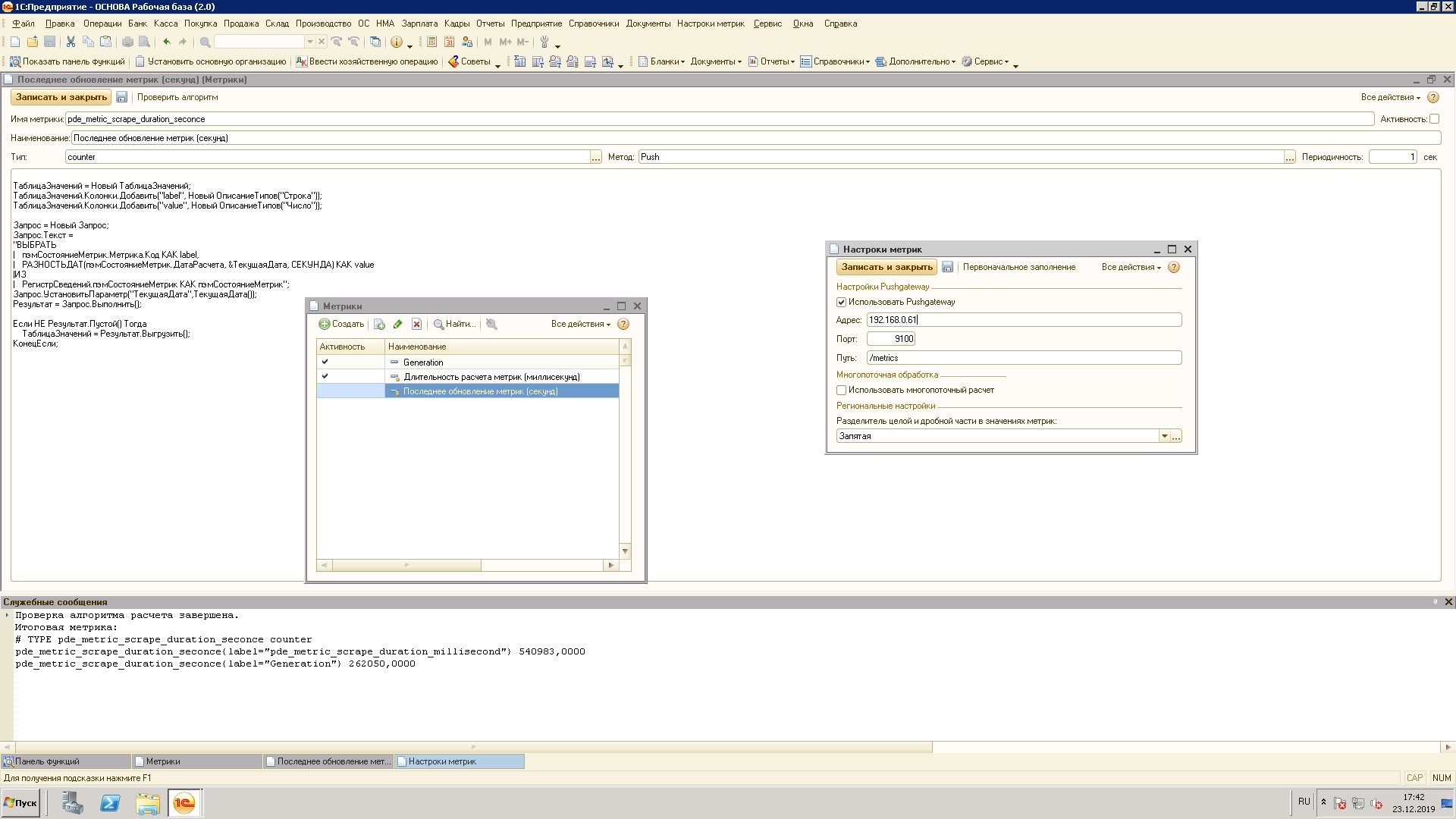
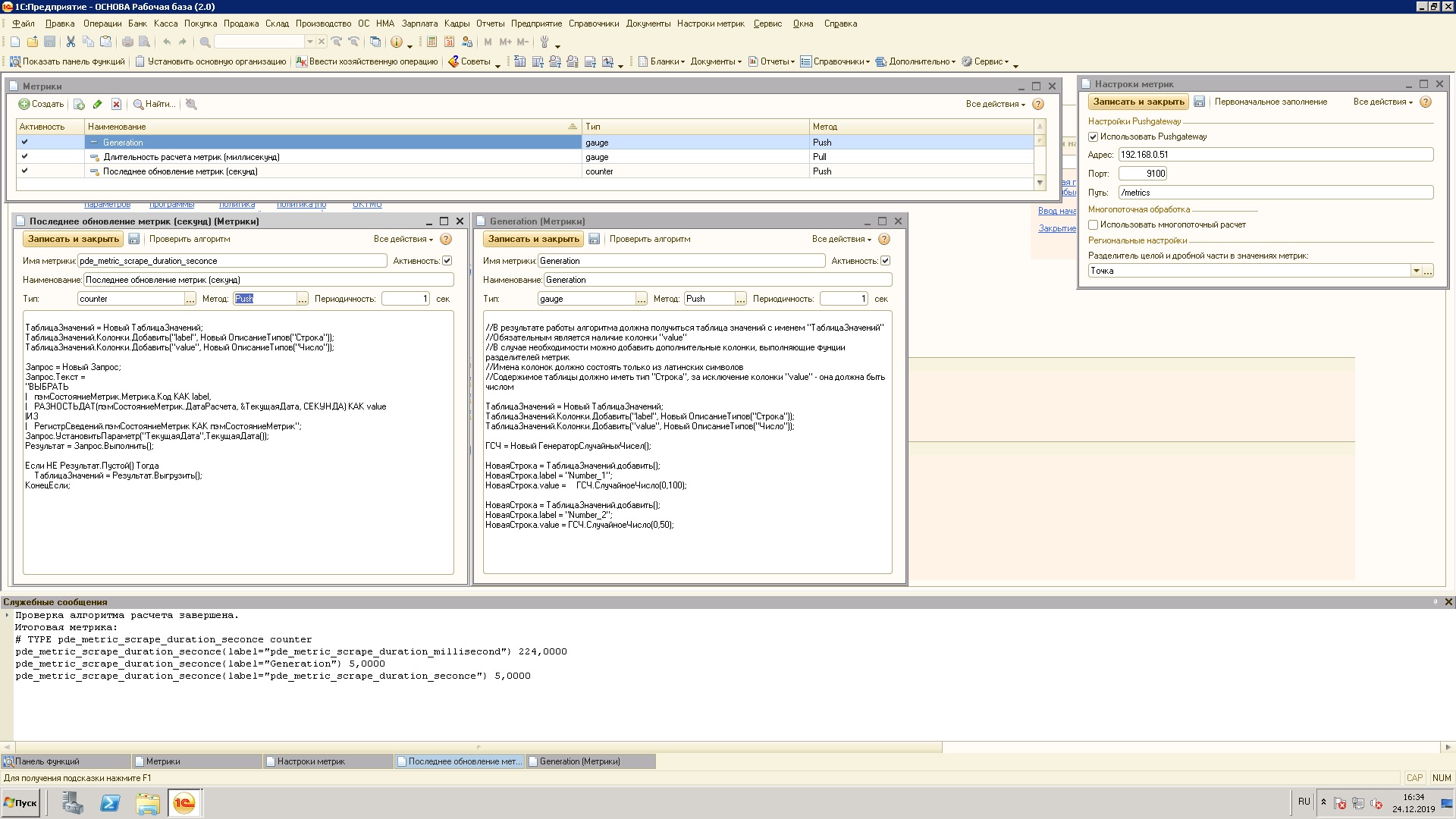
Основным элементом конфигурации является справочник "Метрики", в котором содержатся алгоритмы сбора метрик.
Процесс описания метрики заключается в написании произвольного кода на языке 1С. Выполняется на сервере. Входные параметры отсутствуют.
В результате выполнения алгоритма получения метрики, должна быть сформирована переменная с именем "ТаблицаЗначений" и одноименного типа. В таблице значений в обязательном порядке должна присутствовать колонка "ЗначениеМетрики", в которое записывается числовой показатель метрики. Дополнительные колонки таблицы значений расцениваются как ярлыки (в терминологии Phrometheus), где имя ярлыка = имя колонки, а значение = строковому значению в ячейке. Эти поля удобно использовать для фильтрации данных при выводе в Grafanа.
Вариант PULL:
Регламентное задание конфигурации через равные промежутки времени запускает на выполнение все алгоритмы из справочника "Метрики" с типом pull не помеченные на удаление. Результат выполнения раскладывается в регистр сведений в текстовом формате, понятном Prometheus. При обращении платформы Prometheus к HTTP-публикации базы 1С, происходит чтение данных из регистра, агрегация в единый пакет и выдача ответом на REST запрос.
Вариант PUSH:
По событию системы вызывается элемент справочника "Метрики" и выполняется его обработчик. По окончанию обработки метрики отправляются в Pushgateway.
ИЛИ
Подготовленная любым удобным способом таблица значений с данными передается входным параметром в экспортную процедуру, которая форматирует данные и отправляет их в Pushgateway.
Настройки конфигурации:
- Константа "URL Pushgateway": адрес сбора метрик службой Pushgateway
- Константа "Число повторных запросов метрики": количество раз, которое метрика будет отдана Prometheus при повторных обращениях. Каждое обновление метрики обнуляет счетчик. Используется для исключения провалов графиков в случае длительного формировании метрики и/или частого опроса Prometheus'ом.
P.S. Критика, пожелания, дополнения - горячо приветствуются!
UPD 24.02.19: Присоединяйтесь! Разработка обрела свой адрес

Infostart Dashboards — дашборды и метрики в 1С
Решение «Инфоборды» позволяет собрать все ключевые показатели и метрики прямо на главном экране 1С. Настраивайте панели с виджетами — выручка, долги, KPI, задачи, остатки и динамика продаж — всё в виде интерактивных дашбордов. Контролируйте эффективность компании в реальном времени без отчётов и сложных запросов.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}